Use (this Solvency II) Case! Neuronale Netze treffen auf Least Squares Monte Carlo - Dr. Christian Jonen, Dr. Tamino Meyhöfer Generali Deutschland ...
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Use (this Solvency II) Case! Neuronale Netze treffen auf Least Squares Monte Carlo Dr. Christian Jonen, Dr. Tamino Meyhöfer Generali Deutschland AG e-Herbsttagung, 17. Nov. 2020
e-Herbsttagung, 17. Nov. 2020 Agenda Motivation der Problemstellung Der zugrundeliegende Datensatz Neuronale Netze treffen auf Ordinary Least Squares Numerische Ergebnisse Ausblick 2
e-Herbsttagung, 17. Nov. 2020 Agenda Motivation der Problemstellung Der zugrundeliegende Datensatz Neuronale Netze treffen auf Ordinary Least Squares Numerische Ergebnisse Ausblick 3
e-Herbsttagung, 17. Nov. 2020 Solvency II Use Case - Überblick Berechnung der Solvenzkapitalanforderung (SCR) für ein Versicherungsunternehmen mit dem internen Modell unter Solvency II Im Sinne von Open Science wird der aktuariellen Community ein umfangreicher Datensatz zur Verfügung gestellt, der es erlaubt, moderne Datenanalyse-Methoden anhand einer realitätsnahen Problemstellung – der SCR Berechnung - zu erproben. Der Datensatz beruht auf einer umfangreichen Auswertung der Eigenmittel dreier fiktiver aber realitätsnaher Versicherungsportfolien für Lebens- und Krankenversicherungen auf Basis von fortgeschrittenen aktuariellen Projektionsmodellen (Abbildung Aktiva und Passiva, Managementregeln, regulatorische Anforderungen,…) und Szenariengeneratoren 4
e-Herbsttagung, 17. Nov. 2020 Verteilung der Eigenmittel am Risikohorizont Bilanz für Szenario 1 Verteilung der Eigenmittel Bilanz für Szenario 2 Basisfall: 0 Szenario 3 Bilanz 0 für Szenario 3 0 SCR Bilanz für Szenario 4 Wahrscheinlichkeit 99,5% Bilanz für Szenario 5 Wahrscheinlichkeit 0,5% „Nested Stochastic Problem“ 5
e-Herbsttagung, 17. Nov. 2020 Erläuterungen: Verteilung der Eigenmittel am Risikohorizont • Ein Szenario ist die Realisierung von D Risikofaktoren 1 , … , (z.B. Langlebigkeit, Storno, Zins, Aktien,…) und repräsentiert eine mögliche Entwicklung am Risikohorizont (Einjahresschritt); D=12 bzw. D=13 in dem zugrundeliegenden Datensatz • Die Bestimmung der Positionen der Marktwertbilanz (sowohl Basis als auch in den Stressszenarien) erfordert aufgrund komplexer Abhängigkeiten und Asymmetrien üblicherweise umfangreiche (stochastische) Simulationen geeigneter Projektionsmodelle Monte Carlo Auswertung Hieraus resultiert ein „Nested Stochastic“ Problem mit explodierendem Rechenaufwand (Simulation in einer Simulation) Um dies zu umgehen, können Datenanalyse-Techniken eingesetzt werden 6
e-Herbsttagung, 17. Nov. 2020 Agenda Motivation der Problemstellung Der zugrundeliegende Datensatz Neuronale Netze treffen auf Ordinary Least Squares Numerische Ergebnisse Ausblick 7
e-Herbsttagung, 17. Nov. 2020 Der Datensatz (1/4) 8
e-Herbsttagung, 17. Nov. 2020 Der Datensatz (2/4) 1. Das Trainingsset 215 äußere Szenarien mit jeweils ⋮ 2 inneren Szenarien t=0 t=1 t=N 9
e-Herbsttagung, 17. Nov. 2020 Der Datensatz (3/4) 1. Das Trainingsset 2. Das Validierungsset 215 äußere ⋮ 28 äußere Szenarien mit Szenarien mit ⋮ jeweils ⋮ jeweils 1000 ⋮ 2 inneren ⋮ inneren ⋮ Szenarien Szenarien t=0 t=1 t=N t=0 t=1 t=N 10
e-Herbsttagung, 17. Nov. 2020 Der Datensatz (4/4) 1. Das Trainingsset 2. Das Validierungsset 3. Der Basispunkt und die SCR Region 215 äußere ⋮ 28 äußere - Basispunkt mit 16k Simulationen Szenarien mit Szenarien mit ⋮ - 129 bzw. 50 äußere Szenarien jeweils ⋮ jeweils 1000 ⋮ ⋮ rund um das 0.5%- 2 inneren inneren ⋮ Quantilsszenario (SCR Region) Szenarien Szenarien mit jeweils 4k Simulationen t=0 t=1 t=N t=0 t=1 t=N Basispunkt SCR SCR Region 11
e-Herbsttagung, 17. Nov. 2020 Erläuterungen zum Datensatz Das Trainingsset Das Validierungsset • Ungenaue, dafür zahlreiche Auswertungen • Wenige, dafür genaue Auswertungen • Verteilung der äußeren Szenarien gemäß Niedrigdiskrepanzfolge • Validierungspunkte ebenfalls gleichmäßig im Risikotreiberraum verteilt Teil 1 • Varianzreduktion durch antithetische Simulationspaare • Einsatz statistischer Tests zur Beurteilung der Proxygüte (gemäß • Durch geeignete Regressions-, oder allgemeiner, Trainingsset). Dabei Unterscheidung zwischen Proxy-Fehler und Monte- Datenanalysetechniken kann auf dem Trainingsset eine Carlo-Fehler Proxyfunktion hergeleitet werden, die den Zusammenhang • Je nach gewähltem Ansatz zur Herleitung des Proxys können auch zwischen Risikotreibern und Own Funds beschreibt diese Punkte hierfür verwendet werden Basispunkt SCR Region • Datensatz enthält weitere Validierungspunkte (129 für Portfolio 1 und Stellt Referenzpunkt bei der Berechnung Teil 2 • 2, 50 für Portfolio 3) in der für die Problemstellung kritischen des SCR dar Risikotreiber-Region • Sehr exakte Auswertung mit 16000 • „Ex Post“-Validierung in Abhängigkeit eines gewählten Proxy-Ansatzes inneren Szenarien • exakte Auswertung mit 4000 inneren Szenarien um den Monte Carlo Fehler möglichst stark zu reduzieren • Teil 2 des Datensatzes erlauben genaue Validierung von Proxy-Ansätzen auf Basis von Teil1: „Nested Stochastics“ vs. Proxy-Modell • Bei einem produktiven Durchlauf eines geeigneten Proxy-Modells würde man gerade den Rechenaufwand für Teil 2 des Datensatzes versuchen zu vermeiden (oder zu reduzieren) 12
e-Herbsttagung, 17. Nov. 2020 Agenda Motivation der Problemstellung Der zugrundeliegende Datensatz Neuronale Netze treffen auf Ordinary Least Squares Numerische Ergebnisse Ausblick 13
e-Herbsttagung, 17. Nov. 2020 Ordinary Least Squares Ansatz • Praktikable Modellfunktion ist durch eine einfache Linearkombination von Basisfunktionen (∙) =1 mit Koeffizienten gegeben: 1 , … , = =1 ( 1 , … , ) • Werden für = 1, … , mit die Schätzwerte für Eigenmittel und mit 1 , … , N simulierte Risikofaktorvektoren (äußere Szenarien) bezeichnet, kann die Funktion mittels Least Squares bestimmt werden: 1 min ( − ( 1 , … , ))2 ∈ =1 14
e-Herbsttagung, 17. Nov. 2020 Aufbau neuronaler Netze Risikofaktoren Feedforward Eigenmittel ⋯ 1 ⋯ 2 ⋱ ⋮ = 1 , … , ⋮ ⋯ ⋯ Input Layer Hidden Layers Output Layer 15
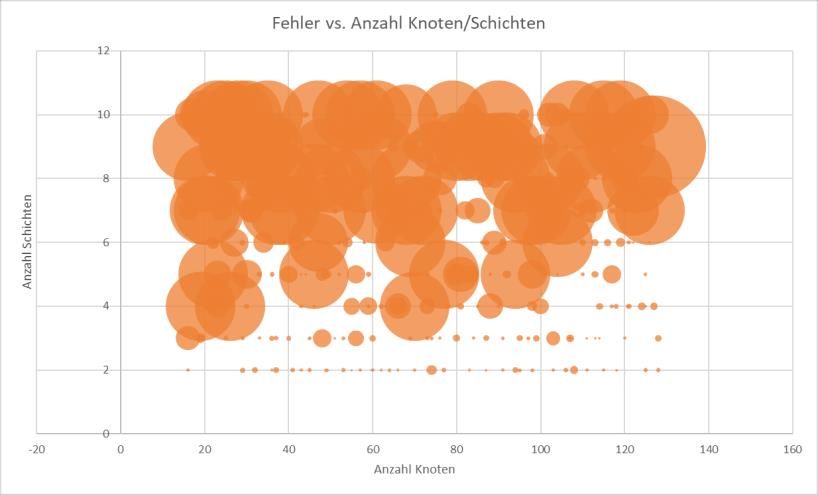
e-Herbsttagung, 17. Nov. 2020 Rezept für neuronale Netze – „Quantität statt Qualität“ Architektur: • Anzahl versteckter Schichten: 2-10 • Anzahl Knoten in einer Schicht: 16-128 • Aktivierungsfunktionen (innere Knoten): Sigmoid, Rectified Linear Unit (ReLU), Leaky ReLU mit -Werten zwischen 0 und 0,1 • Aktivierungsfunktion (Output): Linear, Sigmoid Optimierung: • Algorithmus: Adam, Adamax, Nadam • Lernrate: 0,0005 – 0,005 • „Dropout”-Rate: 0 – 0,4 • „Batch“-Größe: 100 – 1600 • Initialisierung Gewichte: Random Normal, Random Uniform, Glorot Uniform 16
e-Herbsttagung, 17. Nov. 2020 Agenda Motivation der Problemstellung Der zugrundeliegende Datensatz Neuronale Netze treffen auf Ordinary Least Squares Numerische Ergebnisse Ausblick 17
e-Herbsttagung, 17. Nov. 2020 „Trainieren geht über Studieren“ 300 verschiedene Hyperparameter 18
Effiziente Netze erkennen e-Herbsttagung, 17. Nov. 2020 19
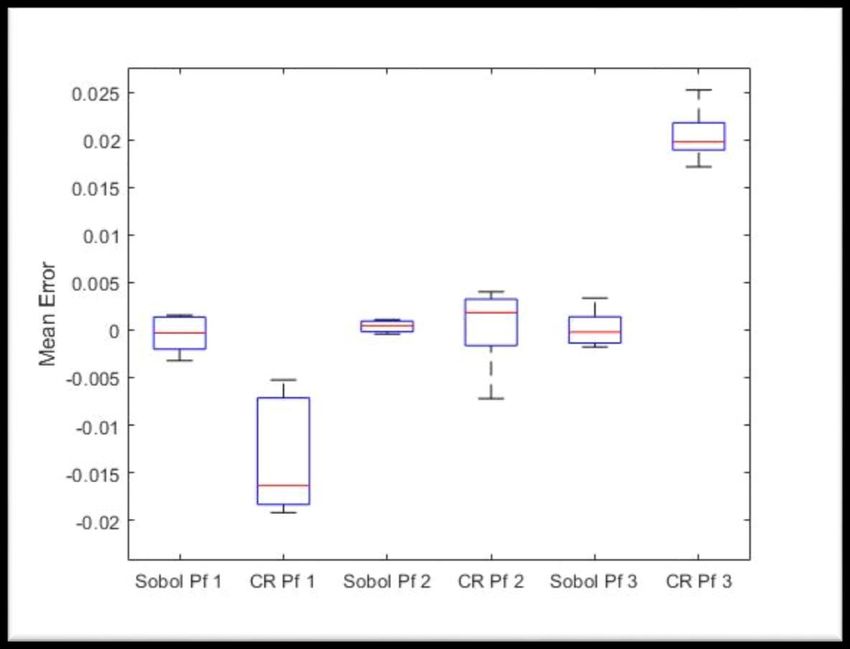
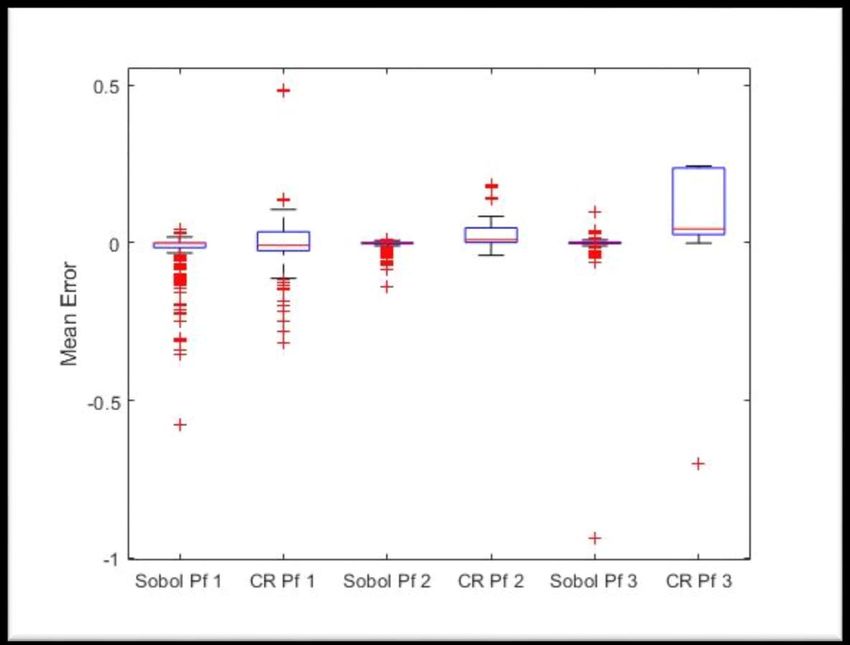
e-Herbsttagung, 17. Nov. 2020 „Crème de la Crème“ Top 10 20
e-Herbsttagung, 17. Nov. 2020 #Teamwork 21
e-Herbsttagung, 17. Nov. 2020 Visuelle Inspektion univariater Risikoprofile (1/2) univariates Risikoprofil 'PF1' - 'i1' Plausibilitätsprüfung anhand graphischer Analyse 2 von niedrigdimensionalen Risikoprofilen Glatte Verläufe oder Knicke im Risikoprofil als 1,5 möglicherweise wünschenswerte Eigenschaften 1 univariates Risikoprofil 'PF1' - 'i1' PF1 - o1 Differenzenquotient 2. Ordnung 2 0,5 1 0 0 -1 -0,8 -0,6 -0,4 -0,2 0 0,2 0,4 0,6 0,8 1 -1 -2 -0,5 ANN OLS ANN OLS 22
e-Herbsttagung, 17. Nov. 2020 Visuelle Inspektion univariater Risikoprofile (2/2) univariates Risikoprofil 'PF1' - 'i7' 3 2 Plausibilitätsprüfung anhand graphischer 1 Analyse von niedrigdimensionalen Risikoprofilen 0 -0,91 -0,72 -0,53 -0,34 -0,15 0,04 0,23 0,42 0,61 0,8 0,99 Wie verhält sich die -1 Proxy-Funktion außerhalb der Fitting- -2 Range? Ist eine Extrapolation sinnvoll -3 möglich? -4 ANN OLS 23
e-Herbsttagung, 17. Nov. 2020 Agenda Motivation der Problemstellung Der zugrundeliegende Datensatz Neuronale Netze treffen auf Ordinary Least Squares Numerische Ergebnisse Ausblick 24
e-Herbsttagung, 17. Nov. 2020 Use (this Solvency II) case! Python Code und Daten 25 https://aktuar.de/unsere-themen/big-data/anwendungsfaelle/Seiten/anwendungsfall2.aspx
e-Herbsttagung, 17. Nov. 2020 Ausblick Trainieren Sie effizienter als wir und schlagen Sie uns Fachliche und detaillierte Beschreibung des Use Case in Form eines Artikels Anwendung anderer Regressionstechniken auf Datensatz, u.a. weitere Machine Learning Algorithmen 26
e-Herbsttagung, 17. Nov. 2020 27
Sie können auch lesen

















































