BACHELORARBEIT Automatisierte Befehl-Ressourcen-Trennung einer Von-Neumann-Maschine - Publication Server of ...
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
BACHELORARBEIT
Herr
Felix Fischer
Automatisierte
Befehl-Ressourcen-Trennung
einer Von-Neumann-Maschine
am Beispiel der Sharp-LR35902-CPU
2020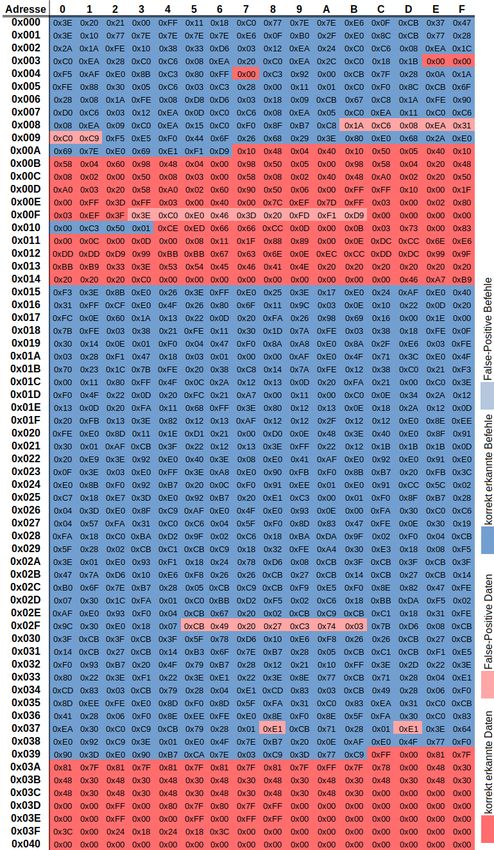
Fakultät Angewandte Computer- und
Biowissenschaften
BACHELORARBEIT
Automatisierte
Befehl-Ressourcen-Trennung
einer Von-Neumann-Maschine
am Beispiel der Sharp-LR35902-CPU
Autor:
Felix Fischer
Studiengang:
IT-Sicherheit - Angewandte Informatik
Seminargruppe:
IF17wI2-B
Erstprüfer:
Prof. Dr.-Ing. Wilfried Schubert
Zweitprüfer:
Dr. rer. nat. Rico Beier-Grunwald
Mittweida, 2020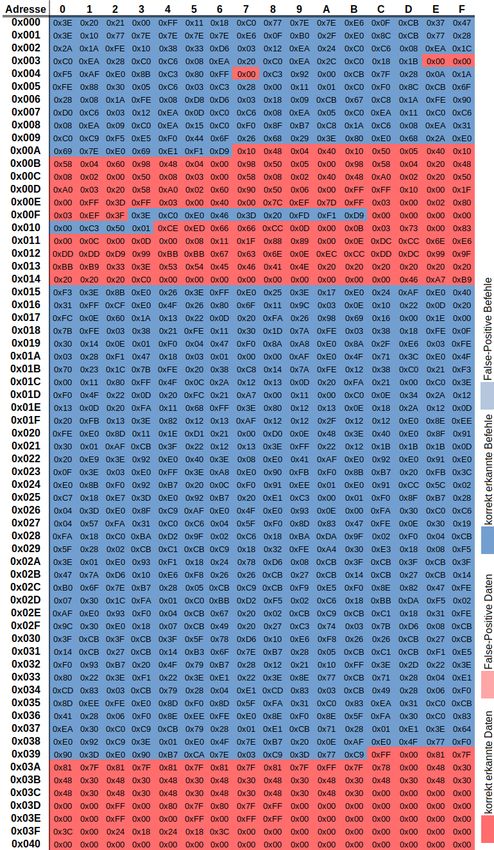
Bibliografische Angaben Fischer, Felix: Automatisierte Befehl-Ressourcen-Trennung einer Von-Neumann-Maschine, am Beispiel der Sharp-LR35902-CPU, 81 Seiten, 30 Abbildungen, Hochschule Mittweida, University of Applied Sciences, Fakultät Angewandte Computer- und Biowissenschaften Bachelorarbeit, 2020 Referat Ein Compiler oder Assembler wandelt Quellcode in ein ausführbares Programm um. Das resul- tierende Binary besteht aus Befehlen und Ressourcen, wie Bilder, Sounds oder anderen Infor- mationen. Ohne den Ausführungskontext kann jedoch nicht im Vorhinein mit absoluter Sicherheit eine Angabe gemacht werden, bei welchen Bytes es sich um Anweisungen und bei welchen Ab- schnitten im Programm es sich um Ressourcen handelt. Bei einer Untersuchung oder einem Dekompilierungsvorgang der binären Datei gestaltet sich diese bzw. dieser ohne vorliegenden Quellcode sehr schwierig. Als Beispiel für eine Von-Neumann-Architektur wurde in dieser Arbeit der Game Boy mit seiner Sharp-LR35902-CPU gewählt. Mit Banking verwendet die Architektur sowohl historische Tech- nologien, ähnelt aber dennoch sehr den derzeit häufig genutzten x86-64-CPUs von Intel oder AMD. Außerdem bieten die kleinen Programme von maximal zwei Mebibyte die Möglichkeit, auch in ineffiziente Ansätze auszuprobieren. In dieser Arbeit wurde anhand der folgenden sieben Lösungsansätze erläutert, wie man eine Befehl-Ressourcen-Trennung erzielen kann. • Manueller Ansatz (siehe Kapitel 3.1) • Metadaten-Ansatz (siehe Kapitel 3.2) • Alles-Befehle-Ansatz (siehe Kapitel 3.3) • Statistischer Ansatz (siehe Kapitel 3.4) • Emulationsansatz (siehe Kapitel 3.5) • Programmflussansatz (siehe Kapitel 3.6) • Brute-Force-Ansatz (siehe Kapitel 3.7) Insbesondere wurden drei automatisierte bzw. teilautomatisierte Ansätze implementiert und an- schließend mit einer manuellen Trennung als Referenzwert verglichen. Dabei erzielte, bei dem verwendeten Kontrollprogramm ”StefaN”, der Programmflussansatz ein gutes Ergebnis. Das mittels Emulationsansatz gewonnene Ergebnis schloss etwas schlechter ab. Der Brute-Force- Ansatz scheiterte an exponentiellen Wachstum und erzielte damit das schlechteste Ergebnis. Eine korrekte Trennung konnte nur mit dem manuellen Ansatz erreicht werden. In dieser Arbeit konnte keine vollautomatisierte Lösung für das Problem gefunden werden. Grundsätzlich kann festgehalten werden, dass eine Befehl-Ressourcen-Trennung einer ausführ- baren Binärdatei auch in Zukunft eine Herausforderung darstellt.
I I. Inhaltsverzeichnis Inhaltsverzeichnis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . I Abbildungsverzeichnis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . II Tabellenverzeichnis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . III Vorwort . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . IV 1 Einleitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 1.2 Zielsetzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 1.3 Abgrenzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 1.4 Bewertung der Quellen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 1.5 Dokumentaufbau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 2 Basiswissen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 2.1 Terminologie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 2.2 Halteproblem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 2.3 Von-Neumann-Architektur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 2.4 Disassemblieren / Dekompilieren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 2.5 Historischer Hintergrund . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 2.6 Game-Boy-Architektur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12 3 Lösungsansätze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19 3.1 Manueller Ansatz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 3.2 Metadaten-Ansatz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22 3.3 Alles-Befehle-Ansatz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23 3.4 Statistischer Ansatz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25 3.5 Emulationsansatz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26 3.6 Programmflussansatz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27 3.7 Brute-Force-Ansatz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
I 4 Implementierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31 4.1 Implementierung des Brute-Force-Ansatzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33 4.2 Implementierung des Programmflussansatzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35 4.3 Implementierung des Emulationsansatzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37 5 Ergebnisauswertung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41 5.1 Kontrollprogramm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41 5.2 Ergebnis des manuellen Ansatzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42 5.3 Ergebnis des Brute-Force-Ansatzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43 5.4 Ergebnis des Programmflussansatzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45 5.5 Ergebnis des Emulationsansatzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47 5.6 Ergebnisvergleich . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48 5.7 Fehlerquellen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49 5.8 Fazit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50 6 Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51 6.1 Implementierung weiterer Ansätze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51 6.2 Ansatzkombination . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51 6.3 Datenflussanalyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51 6.4 Zusätzliche Ansätze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52 6.5 Weitere Kontrollprogramme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52 6.6 Programmintegration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52 A Abbildungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53 A.1 Brute-Force-Ablaufdiagramm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53 A.2 Befehlssatz der Sharp-LR35902-CPU . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53 A.3 Programmflussgraphen des Spiels StefaN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56 A.4 SameBoy Änderungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58 A.5 Ergebnisse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58 B Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63 B.1 Programmfluss Trampolin . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63 B.2 Sprungtabelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
I B.3 Trail-Parameter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65 B.4 Befehlsubstitution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66 B.5 Programmfluss Kollision . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66 B.6 Typische Befehlsequenzen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67 B.7 Kollisionsabfrage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68 B.8 Knotenspaltung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70 B.9 Versetzte Interpretation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70 Glossar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71 Literaturverzeichnis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
II II. Abbildungsverzeichnis 2.1 Übersicht Umwandlungsbegriffe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8 2.2 Funktionsweise der Banks des Game Boys . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 2.3 Trampolin Programmbeispiel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 3.1 Übersicht aller Lösungsansätze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19 4.1 Wertebestimmung des Registers HL an einem Beispiel . . . . . . . . . . . . . . . . . . . . . . . 36 4.2 Übersicht der Prozesskette des Emulationsansatz . . . . . . . . . . . . . . . . . . . . . . . . . . 38 5.1 Speichern von zufälligen Werten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44 A.1 Ablaufplandiagramm der Brute-Force-Implementierung . . . . . . . . . . . . . . . . . . . . . . . 53 A.2 Befehlssatz der Sharp-LR35902-CPU . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54 A.3 Befehlssatz der Sharp-LR35902-CPU mit 0xCB Präfix . . . . . . . . . . . . . . . . . . . . . . . 55 A.4 Programflussgraph des Spiels StefaN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56 A.5 Programflussgraphgebiete im Spiel StefaN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57 A.6 Änderungen am Quellcode von SameBoy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58 A.7 Ergebnis des manuellen Ansatzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59 A.8 Ergebnis des Brute-Force-Ansatzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60 A.9 Ergebnis des Programmfluss-Ansatzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61 A.10 Ergebnis des Emulationsansatzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62 B.1 Programmflussdiagramm am Trampolinbeispiel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63 B.2 Sprungtabelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64 B.3 Beispiel von Trail-Parametern . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65 B.4 Normaler call-Befehl . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66 B.5 call-Befehl mittels push- und jp-Substitution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66 B.6 call-Befehl mittels push- und ret-Substitution . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66 B.7 Flussgraph an einem Codebeispiel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66 B.8 Beispiel bedingter Sprung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67 B.9 Beispiel Soundeffekt abspielen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67 B.10 Beispiel Kollisionsabfrage Teil 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68 B.11 Beispiel Kollisionsabfrage Teil 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
II B.12 Beispiel eines Programmflussgraphen mit notwendiger Knotenspaltung . . . . . . . . . . 70 B.13 Beispiel versetzte Interpretation der Bytes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
III III. Tabellenverzeichnis 2.1 Speicherbereiche der Game-Boy-Architektur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 3.1 Zusammenfassung des manuellen Ansatzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 3.2 Zusammenfassung des Metadaten-Ansatzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23 3.3 Zusammenfassung des Alles-Befehle-Ansatzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24 3.4 Zusammenfassung des statistischen Ansatzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26 3.5 Zusammenfassung des Emulationsansatzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27 3.6 Zusammenfassung des Programmflussansatzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28 3.7 Zusammenfassung des Brute-Force-Ansatzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29 4.1 Entscheidungsmatrix zur Programmiersprachenauswahl . . . . . . . . . . . . . . . . . . . . . . . 31 4.2 Entscheidungsmatrix zur Lösungsansatzauswahl . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32 5.1 Mögliche Zustände eines Blockes im Spiel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43 5.2 Übersicht der erzielten Ergebnisse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
IV IV. Vorwort Auf einem Glas Marmelade ist auf dem Etikett eine Kirsche als Serviervorschlag abge- bildet, auf der Milch eine Kuh. Diese witzigen Umstände sind nicht zuletzt ein Wunsch, begangene Aktionen rückgängig zu machen. Den Ausgangszustand zurückzuerhalten und mit einer Änderung eine neue Richtung einschlagen zu können. In der Informatik stellt der Compiler und Assembler mit dem jeweiligen Konterpart Decompiler und Di- sassembler keine Ausnahme dar. In dieser Arbeit wird betrachtet, wie schwer der erste Schritt das informatischen Äquivalent zum Umwandeln einer Marmelade zurück in eine Kirsche ist.
Kapitel 1: Einleitung 1 1 Einleitung 1.1 Motivation Nachdem ein Compiler oder Assembler einen Quellcode in eine ausführbare Binärdatei umgewandelt hat, besteht dieses nur aus einer Folge von Nullen und Einsen, die jedoch oft zur besseren Lesbarkeit in hexadezimaler Schreibweise dargestellt werden. Ohne Kontext betrachtet lassen sich diese Werte nicht einordnen. Folglich ist es unklar, ob ein Byte aus dieser langen Folge von Werten, einem Befehl oder einer im Programm ge- nutzten Ressource zuzuordnen ist. Die Trennung ergibt sich erst während der Laufzeit des Programms aus der Benutzung der Werte. Ebenjene Unterscheidung stellt jedoch für eine Analyse des Programms oder für einen gewünschten Dekompillierungsprozess eine wichtige Information dar [Eag11, S. 5, Abs. 5]. Daher sollen in dieser Arbeit Me- thoden überprüft werden, diese Differenzierung zwischen Befehlen und Ressourcen am Beispiel der Game-Boy-Architektur automatisiert zu realisieren. 1.2 Zielsetzung Ein ausführbares Programm besteht aus einer Folge von Bytes, welche Ressourcen oder Befehle darstellen können. Innerherhalb einer Von-Neumann-Maschine sind diese im Spiecher [VNe93, Abs. 14.1] nicht getrennt. Die Bytes des Programms an sich be- trachtet, können damit nicht einfach als Ressourcen oder Bytes klassifiziert werden. Für diese Arbeit wurde deshalb als generelles Ziel die automatisierte Ressourcen-Befehl- Trennung eines Programms angestrebt. Dafür soll ein Programm entwickelt werden, das für ein gegebenes Binary eine entsprechende Auflistung aller Ressourcen und Befehle liefert. Als Beispiel für eine Von-Neumann-Architektur wurde der Game Boy mit seiner Sharp-LR35902-CPU gewählt. Programme für diese Architektur zeichnen sich durch eine geringe Größe von maxi- mal zwei Mebibyte [DBGB, Abs. Memory Bank Controllers] aus. Daher wurde zunächst davon ausgegangen, dass mittels Brute-Force eine Trennung für Programme dieser geringen Größe umsetzbar ist. Im Laufe der Arbeit stellte sich diese Annahme als Fehl- schluss heraus. Daher wurden weitere Ansätze verfolgt und die Ergebnisse derer un- tereinander vergleichen. Aus der Perspektive, mehrere Ansätze analysieren zu wollen, wurde diese Arbeit geschrieben.
2 Kapitel 1: Einleitung 1.3 Abgrenzung Auf Grund der limitierten Zeit müssen jedoch Abstriche an dem Vorhaben vorgenom- men werden. Dazu zählen jegliche graphische Oberflächen zur Bedienung der in dieser Arbeit erstellten Software. Des Weiteren wird als Grundlage die Hardware des origi- nalen Game Boys angenommen. Folglich wird das vom Game Boy Color eingeführte Banking im RAM ignoriert. Ebenso wird eine Verbindung zweier Game Boys durch ein Linkkabel in dieser Arbeit nicht betrachtet. Zusätzlich wird auf jegliche Fortschrittsan- zeige innerhalb der in dieser Arbeit erstellten Programme verzichtet. Außerdem werden die Ressourcen nicht weiter analysiert. Das bedeutet, es findet keine Einordnung der Ressourcen in Bild, Audio oder anderen Kategorien statt. 1.4 Bewertung der Quellen Die Verwendung von wissenschaftlichen Quellen im Zusammenhang mit dieser Arbeit ließ sich nur begrenzt umsetzen. Die Game-Boy-Architektur wurde proprietär und nicht öffentlich dokumentiert. Ein Reverse-Engineering der Hardware fand vor allem im Um- feld von engagierten Hobbyprojekten statt. Infolgedessen sind viele Quellen diesbe- züglich Blogeinträge, welche mit unwissenschaftlichen Methoden geschrieben wurden. Dies resultiert jedoch nicht zwangsweise in falschen Aussagen, wie die Implementie- rungen von vielen Emulatoren beweisen. Bei der Durchführung dieser Arbeit wurde es jedoch offensichtlich, dass sich einige Quellen im Detail widersprechen. Aus diesen bei- den Gründen musste daher vermehrt auf Plausibilität der Quellen geachtet werden. Viele der in dieser Arbeit genannten Programme arbeiten ebenfalls auf einer proprietä- ren Codebasis. Angaben der Hersteller der Programme lassen sich damit nicht bzw. nur sehr aufwändig überprüfen. Eine korrekte Funktionsbeschreibung wird angenommen. Alle Quellen nichtwissenschaftlichen Ursprungs sind mit einem ’ gekennzeichnet. So- weit möglich, wurden bei unwissenschaftlichen Aussagen mehrere Quellen angege- ben. 1.5 Dokumentaufbau Auf diese kurze Einleitung folgend, erläutert das Kapitel Basiswissen zunächst einige Grundbegriffe und fachliche Kenntnisse. Insbesondere wird auf Problematiken des Di- sassemblierens eingegangen. Zusätzlich wird die Arbeitsweise der Game-Boy-Architektur erläutert. Anschließend werden im Kapitel 3 mögliche Lösungsansätze vorgestellt. Hier beschreibt je ein Unterkapitel die grundsätzliche Idee.
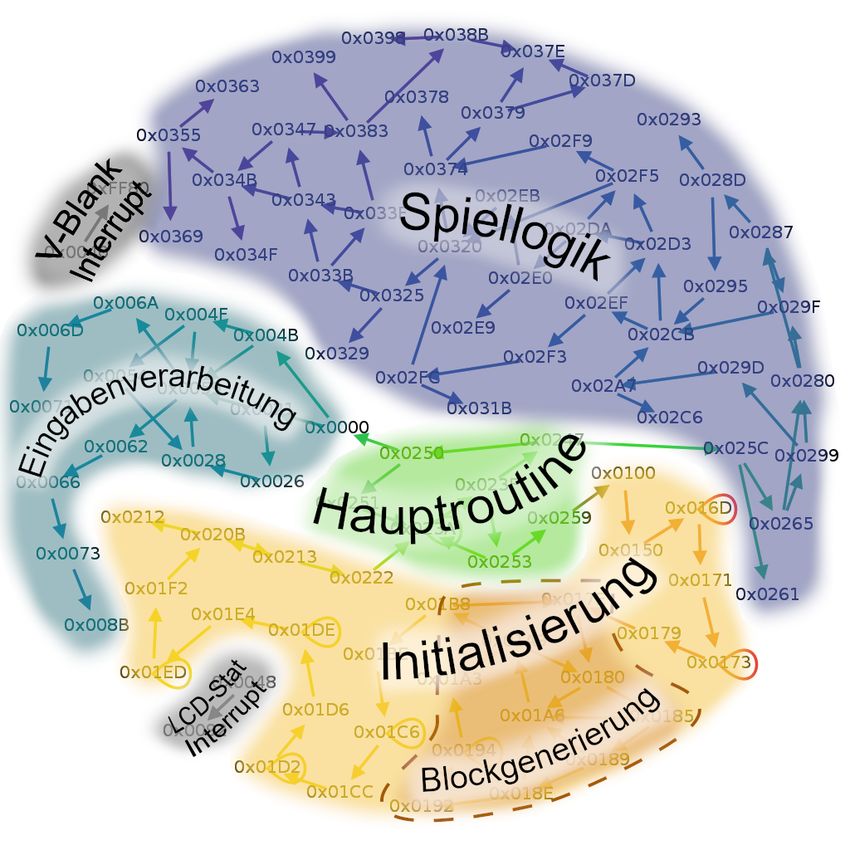
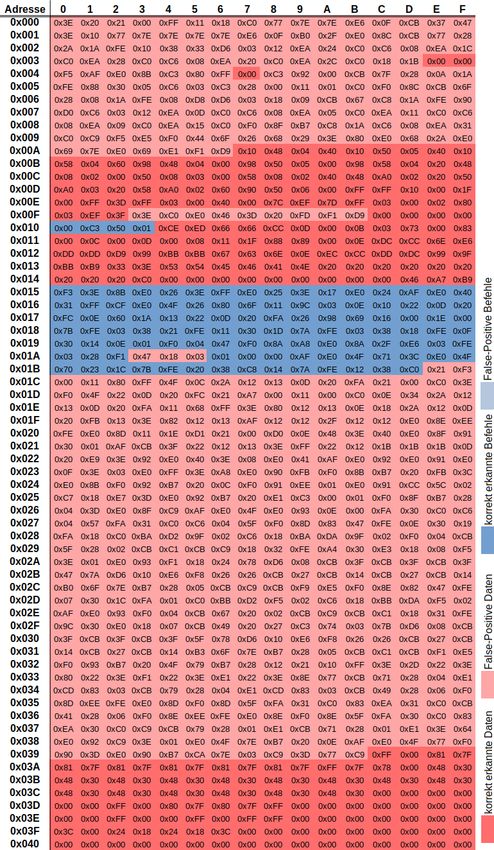
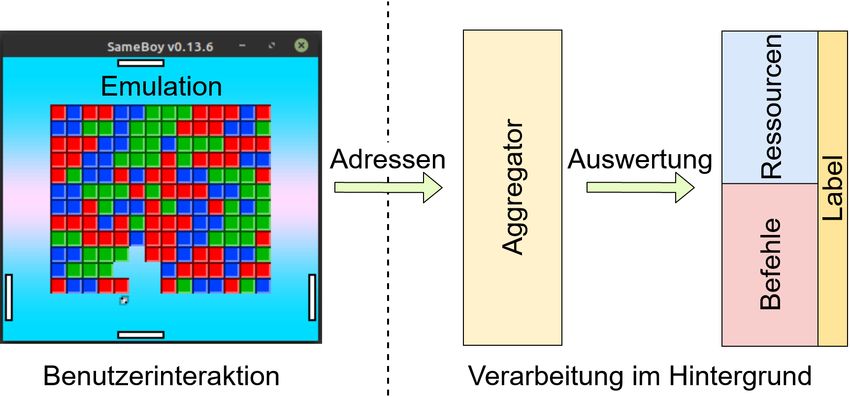
Kapitel 1: Einleitung 3 Darauf folgend wird im Kapitel 4 für ausgewählte Ansätze die Implementierungen be- schrieben. Innerhalb dieser Kapitel wird auf eingeflossene Überlegungen und Ideen eingegangen. Der Quellcode an sich wird nicht genauer erläutert. Danach werden die erzielten Ergebnisse im Kapitel 5 aufgezeigt und im Detail präsen- tiert. Es wird beschrieben, welche Programmbereiche erfolgreich aufgedeckt wurden. Außerdem werden Gründe für falsche Ergebnisse formuliert. Abschließend wird auf ei- nige Anregungen für fortführende Forschungsarbeiten eingegangen. Im Anhang wurden Abbildungen und Beispiele für ein besseres Verständnis, der in die- ser Arbeit erläuterten Sachverhalte, beigefügt. Ebenso befinden sich im Anhang Dar- stellungen der erzielten Ergebnisse. Diesen ist zu entnehmen, mit welchem Ansatz, welche Bytes des Kontrollprogramms, in welche Kategorie eingeordnet wurden.
4
Kapitel 2: Basiswissen 5 2 Basiswissen Das Disassemblieren und Dekompilieren stellt ein sehr spezialisiertes Feld der Infor- matik dar. Ebenso ist die Architektur der beliebten Konsole ”Game Boy” nicht allgemein bekannt. Zur Verbesserung der Verständlichkeit wird zunächst auf einige Begriffe und Hintergrundinformationen eingegangen. Jedoch wird ein allgemeines Informatikwissen vorausgesetzt. 2.1 Terminologie Viele, der in dieser Arbeit benutzten Begriffe werden, auch umgangssprachlich verwen- det. Um zu spezifizieren, was die folgenden Fachbegriffe aussagen, wird deren Bedeu- tung in diesem Kapitel präzisiert. Daten: Der Begriff Daten bezeichnet alle Bytes, welche einer oder mehreren Dateien angehören. Eine Datei ist ein gesamtheitliches Gefüge, welches Befehle oder Ressour- cen beinhalten kann. Beispielhaft ist ein ROM-Abbild eines Game-Boy-Programms eine Datei. Ressourcen: Unter Ressourcen versteht man alle verwendeten Informationen inner- halb eines Programms. Dazu gehören Zeichenketten, numerische Werte, Transforma- tionstabellen, Bilder und Soundeffekte, um die Wichtigsten zu nennen. Zusammenfas- send lässt sich festhalten, dass Ressourcen alle Informationen, welche durch Befehle verarbeitet werden, darstellen. Operations-Code: Ein Operations-Code, kurz OP-Code, ist eine als hexadezimaler Wert repräsentierte Zahl. Sie signalisiert dem Prozessor, um welchen Befehl es sich handelt. So steht beispielsweise die hexadezimale Zahl 0x81 bei der LR35902-CPU für die Addition der Register A und C mit anschließender Speicherung des Ergebnisses im Register A. Parameter: Bei einem Parameter handelt es sich um einen übergebenen Wert für eine Verarbeitung. Demzufolge wird in dieser Arbeit der Begriff sowohl für Befehle, als auch für die Übergabe von Werten an Funktionen, genutzt. So kann es sich bei einem Parameter für einen Befehl um eine Adresse, einen relativen Versatz oder numerischen Wert und bei einer Funktion um alle erdenklichen Ressourcen handeln. Befehl: Der Fachbegriff Befehl beschreibt den zusammenfassenden Begriff von OP- Code und Parameter. Ein Befehl stellt damit eine zusammenhängende Einheit bei der Ausführung des Programms dar. Obwohl der Befehlsbegriff OP-Codes und Parameter
6 Kapitel 2: Basiswissen vereint, spricht man auch von einem Befehl, wenn der entsprechende OP-Code keinen Parameter verlangt, wie im Beispiel des ret-Befehls. Bei der Schreibweise eines Be- fehls in hexadezimalen Werten spricht man von Maschinencode. Im Gegensatz dazu nennt man die Schreibweise eines Befehls in Assembler Mnemonic. Man spricht auch von der Mnemonic eines Befehls. Programm: Ein Programm, auch Software oder Anwendung genannt, stellt eine aus- führbare Datei dar, welche alle für die Ausführung notwendigen Befehle und Ressourcen beinhaltet. Bank: Die Technik des Banking ist ein in älteren Computerarchitekturen verwende- tes Konzept, um einem kleinen Adressbereich entgegenzuwirken. Der Begriff Bank be- zeichnet hierbei einen zusammenhängenden, austauschbaren Speicherbereich. 2.2 Halteproblem Das Halteproblem ist eine Fragestellung der theoretischen Informatik. Dabei wird nach einer Antwort gesucht, ob ein Algorithmus existieren kann, der für jedes erdenkliche Programm und dessen Eingabe ohne Ausführung des Programms im Vorfeld festge- stellt werden kann, ob dieses jemals sich beendet [ReGu]. Also kurz formuliert, ob ein Programm jemals zum halten kommt. Alan Turing bewies, dass es einen solchen Algorithmus nicht geben kann. Es ist also unmöglich für jedes Programm eine automatisierte Aussage über dessen Beendigungs- verhalten zu treffen. 2.3 Von-Neumann-Architektur Die Von-Neumann-Architektur stellt zum aktuellen Zeitpunkt die am häufigsten verwen- dete Hardwarearchitektur dar. Diese Bauweise wurde in der 1945 veröffentlichten Dok- torarbeit [VNe93] von Von-Neumann beschrieben. In seiner Dissertation beschreibt Von- Neumann die grundlegende Idee, Ressourcen und Befehle in einem geteilten Speicher abzulegen [VNe93, Abs. 14.1]. Die Harvard-Architektur verwendet im Kontrast dazu je einen eigenen Speicher für Ressourcen und Befehle. Hier limitiert die jeweilige Spei- chergröße, wie viele Ressourcen oder Befehle verwendet werden können. Folglich er- möglicht die Von-Neumann-Architektur im Gegensatz zur Harvard-Architektur die Nut- zung des Speichers mit mehr Ressourcen oder Befehlen je nach Anwendungsfall. Kon- sequenterweise kann ein Von-Neumann-Computer den verfügbaren Speicher effizienter ausnutzen. Ensprechend ist die Von-Neumann-Architektur vielseitiger einsetzbar, was maßgeblich zum Erfolg dieser Bauweise beigetragen hat.
Kapitel 2: Basiswissen 7 Der Speicher einer Von-Neumann-Maschine kann als ein langes Band mit hinterlegten Werten verstanden werden. Der Anfang dieses Bandes ist mit dem Ende zu einem Ring verbunden. Auf diesem kontinuierlichen Ring sind alle für das Programm notwendigen Ressourcen und Befehle abgelegt. Die Position dieser Werte unterliegt dabei keiner vorgegebenen Struktur. Ressourcen und Befehle können, wie vom Programmierer oder Kompiler vorgegeben, durchmischt sein. Ohne den entsprechenden Kontext betrachtet, ergeben diese numerischen Werte keinen Sinn. Somit lässt sich die Bedeutung die- ser numerischen Werte erst während der Ausführung ermitteln. Folglich bietet der ge- mischte Speicher erhebliche Herausforderungen beim Dekompilieren, wie die Beispiele B.2 und B.3 belegen. Eine Umwandlung einer Binärdatei in Quellcode ist demnach kei- neswegs trivial. Dementsprechend kann erst nach einer vollständigen Ausführung des Programms eine genaue Aussage über die zugehörige Art aller Speicherbereiche ge- troffen werden. Folglich ist allein diese Aufgabe äquivalent mit dem Halteproblem der Informatik. 2.4 Disassemblieren / Dekompilieren Für eine einfache Programmentwicklung und -pflege werden Programme nicht in Ma- schinencode geschrieben. Darum wurde bereits 1946 von Konrad Zuse mit Plankalkül eine höhere Programmiersprache umgesetzt [Zus45]. Die für Menschen verständliche- re Anweisungsbeschreibung wird mittels eines Programms (Compiler oder Assembler) in Maschinencode, also in Binärwerte umgewandelt. Bei diesem Prozess entfernt der Compiler oder Assembler Kommentare und ersetzt alphanumerische Bezeichnungen für Variablen, Sprungadressen und Zeigern durch die entsprechenden hexadezimalen Werte [Eag11, S. 5, Abs. 2]. Das Resultat ist ein ausführbares Programm, welches von Menschen schlecht gelesen werden kann. Der entgegengesetzte Schritt, also das Um- wandeln von binären Werten in Assembler oder in eine höhere Programmiersprache wird disassemblieren bzw. dekompilieren genannt. Die entsprechende Software heißt Disassembler bzw. Decompiler. Zusammengefasst ist der Zusammenhang dieser Be- griffe in der Abbildung 2.1 dargestellt. Seinen historischen Ursprung hat das Dekompilieren bei Programmen bei denen der Quellcode nicht mehr verfügbar ist, aber eine Übertragung auf eine neue Hardwarear- chitektur vorgenommen werden soll. Solch eine Portierung, von meist firmeneigenen Programmen, ist besonders in Unternehmen wichtig, bei denen diese Programme auf veralteten, nicht mehr produzierten Hardwarearchitekturen eingesetzt werden. Ein Aus- fall der Hardware würde eine lange Einschränkung des Unternehmens bedeuten. Infol- gedessen ist es für den zuverlässigen Betrieb der Software essentiell, dieses Ausfallri- siko zu eliminieren und die Software auf moderner Hardware weiter zu betreiben. Ein Decompiler ermöglicht die Wiederherstellung des Quellcodes und eine anschließende Rekompilierung auf die neue Hardwareumgebung.
8 Kapitel 2: Basiswissen
Abbildung 2.1: Übersicht Umwandlungsbegriffe
Auch in der Softwareentwicklung selbst kann ein Decompiler unterstützen. Für Program-
mierer von Compilern ist eine Kontrolle des erzeugten Programms auf Richtigkeit ein
wichtiger Kernpunkt der Entwicklung. Ein Decompiler kann die Kontrolle der binären
Datei vereinfachen [Eag11, S. 7, Abs. 3].
Ein weiterer wichtiger Anwendungsbereich ist aus sicherheitsspezifischer Betrachtung
die Möglichkeit, Schwachstellen und versteckte Zugänge in Programmen aufzuspü-
ren [Eag11, S. 6, Abs. 3]. Dies folgt aus der Tatsache, dass ein Decompiler die tat-
sächlichen Maschinenbefehle, welche auf der Hardware ausgeführt werden, auswertet.
Folglich kann auch ohne Einsicht in den Quellcode eine Software auf Angaben des
Herstellers überprüft werden. Des Weiteren kann die Korrektheit einer Anwendung vom
Programmierer oder Dritten sichergestellt werden. Beispielsweise kann mit der Analyse
der Befehle ein Berechnungsalgorithmus verifiziert werden, anstatt nur in einer Black-
Box-Überprüfung Eingaben und Ausgaben abzugleichen.
Ein zusätzlicher Aspekt des Dekompilierens ist das Verstehen der Funktionsweise von
Malware, welches zur Verbreitungseindämmung eingesetzt wird [Eag11, S. 6, Abs. 2]..
Beispielsweise müssen auch Malwareentwickler ihre Software testen, um deren Kor-
rektheit sicherzustellen. Während dieses Prozesses soll sich die Malware nicht in der
Öffentlichkeit verbreiten. Die Malware soll zu diesem Zeitpunkt noch unbekannt sein,
damit während der Verbreitungsphase eine große Anzahl an Computern infiziert wird.
Daher werden häufig sogenannte Kill-Switches eingesetzt. Dabei prüft das Programm
vor der Verbreitung eine Bedingung ab. Sofern diese erfüllt ist, findet keine Verbreitung
statt. Schaffen es Analysten der Malware diesen Kill-Switch zu entdecken und dessen
abgefragtes Ereignis dauerhaft auszulösen, so ist die Verbreitung der Malware gestoppt.Kapitel 2: Basiswissen 9 Nach diesem Prinzip konnte die Infizierung von Computern mit der Malware ”WannaCry” zeitweise gestoppt werden. Der Kill-Switch war in diesem Fall eine Abfrage nach einer speziellen Domainadresse. Wenn diese Domain einer IP-Adresse zugeordnet werden kann, verbreitet sich WannaCry nicht mehr. So konnte eine Eindämmung durch die Re- gistrierung dieser speziellen Domain erfolgreich erreicht werden [Cla17]’. Die Malwa- reentwickler waren daraufhin gezwungen, eine neue Variante ihrer Schadsoftware zu entwickeln und in Umlauf zu bringen. Infolgedessen bietet sich der Strafverfolgung eine neue Gelegenheit, die Täter ausfindig zu machen. Im Kontrast zu den vielen positiven Beispielen soll der Vollständigkeit halber genannt werden, dass das Verstehen und gezielte Manipulieren von Programmen es ermöglicht, Kopierschutzmechanismen zu umgehen und ausschalten. Das Analysieren von Algo- rithmen zur Überprüfung von Freischaltschlüsseln kostenpflichtiger Software erlaubt es, gültige Schlüssel selbst zu generieren. Diese kriminellen Absichten rücken das Disas- semblieren oder Dekompilieren in eine rechtliche Grauzone. Im deutschen Strafgesetz- buch ist daher unter § 202c.2 Vorbereiten des Ausspähens und Abfangens von Da- ten festgelegt, dass auch das Schreiben von Programmen zum Auslesen von Pass- wörtern unter Strafe gestellt ist [StGB]. Zusätzlich sind im Urheberrechtsgesetz § 69e Dekompilierung Fälle aufgelistet, unter welchen Umständen eine Dekompilierung ge- stattet ist. Dazu zählen vor allem Änderungen, um eine Interoperabilität zwischen Com- putern oder anderen Programmen zu gewährleisten [UrhG]. In diesem Fall ist sogar keine Genehmigung des Urhebers erforderlich [UrhG]. Nach der Betrachtung der verschiedenen Anwendungsmöglichkeiten gehen wir nun auf den Prozess des Dekompilierens genauer ein. Der Decompilationprozess lässt sich in folgende Abschnitte untergliedern [Cif94, S. 8, Abb. 1-10]: 1. Ressourcen und Befehle im Binärformat lokalisieren 2. Maschinenbefehle in Assemblersprache decodieren 3. Semantische Analyse der Ressourcen zur Typenbestimmung 4. Informationen in einer Übergangssprache anreichern 5. Datenflussanalyse 6. Programmflussanalyse 7. Erzeugen des Programmcodes in höherer Programmiersprache Die ersten zwei Teilschritte beschreiben den Prozess des Disassemblierens. Folglich stellt das Disassemblieren einen Teilprozess des Dekompilierens dar. Eine Vollstän- dige Disassemblierung wird häufig als Zwischenschritt verwendet, um anschließende Analysen für eine Decompilierung einfacher durchführen zu können. Abgrenzend zum Vollständigen Decompilierungsprozess wird in dieser Arbeit insbesondere der erste Teil- schritt betrachtet.
10 Kapitel 2: Basiswissen In dieser Arbeit wird vorrangig auf das automatisierte Disassemblieren eingegangen. Die Art der Analyse kann durch viele Programmiertechniken erschwert werden. So können beispielsweise Sprünge während der Ausführung des Programms dynamisch berechnet werden. Dies geschieht häufig im Zusammenhang mit sogenannten Sprung- tabellen. Beispielsweise wird in Abbildung B.2 eine solche dynamische Berechnung der Sprungadresse in kombinierter Nutzung einer Tabelle gezeigt. Eine weitere Herausfor- derung des Dekompilierens sind äquivalente Umsetzungen von Anweisungen mit unter- schiedlichen Befehlsketten. So wurden, um die Befehlsdichte auf dem Speichermedium zu erhöhen, häufig in Kombination genutzte Befehle zu einem neuen Befehl zusammen- gefasst. Das bekannteste Beispiel hierfür dürfte der call-Befehl sein. Dieser kopiert die Adresse des nächsten Befehls auf den Stack und springt anschließend zu der aufge- rufenden Adresse. Zur Verdeutlichung werden im Beispiel B.4 und zwei Möglichkeiten aufgezeigt, den call-Befehl durch eine Kombination verschiedener anderer Befehle zu substituieren. Obwohl alle Anweisungen vollkommen verschieden sind, erzielen sie im Endergebnis alle das gleiche Resultat. Ferner kann, wie im Beispiel B.6 zu sehen, sogar ein ret-Befehl in Kombination mit zwei push-Befehlen als call-Befehl umfunktioniert werden. Folglich kann die Eigenschaft, dass der call-Befehl die nächste folgende Adresse auf dem Stack speichert, auch zur Übergabe eines Parameters genutzt werden. So wird im Beispiel B.3 eine Subroutine aufgerufen, welche als Parameter dem Aufruf folgende Bytes als Parameter nutzt. Alle bisher genannten Beispiele lassen sich mit einigem Aufwand gut erkennen. Je- doch stellt bis heute die größte Herausforderung die Modifikation des Maschinencodes während der Laufzeit selbst dar. Fast ausschließlich wird diese Technik von Malware verwendet, um eine verschlüsselte Schadroutine vor der Ausführung durch einfache xor-Befehle mit einem Schlüssel umzuwandeln. Durch diese Maßnahme soll eine Ana- lyse der Schadsoftware erschwert werden. So wurde in der Vergangenheit diese Tech- nik auch eingesetzt, um Abgleiche von Virenscannern abzuwenden. Dafür wurde die gleiche Schadsoftware lediglich mit einem neuen Schlüssel verschlüsselt, erhielt damit einen komplett neuen Hashwert und ein neues Erscheinungsbild. In dieser Arbeit wird davon ausgegangen, dass das analysierte Programm unverändert ausgeführt wird. Auf dieses Problem des Disassemblierens wird nicht weiter eingegangen. Wie an den Beispielen B.2, B.3, B.5 und B.6 deutlich wird, ist die richtige Erkennung der Befehle und eine anschließende Decompilierung nicht einfach. Tatsächlich ist die- se Problematik äquivalent mit dem Halteproblem der Informatik und stellt damit auch heute noch ein kontinuierliches Forschungsfeld dar. Infolgedessen wird es eine absolut korrekte Decompilierung für alle erdenklichen Programme nie geben.
Kapitel 2: Basiswissen 11 2.5 Historischer Hintergrund Seinen historischen Ursprung hat das Dekompilieren im Jahr 1960. Zu diesem Zeitpunkt erschien mit dem D-Neliac-Decompiler der erste Decompiler der Geschichte [Hal62, S. 143ff]. Dieser wurde genutzt, um Programme mit dem NELIAC kompilieren zu können und logische Fehler im Programm aufzuspüren. Mit seiner Umsetzung demonstrierte er die Realisierbarkeit von Dekompilierern auf. Fortgeführt wurde die Forschung 1973 mit dem C.-R.-Hollander-Decompiler [Hol73]. Gegenüber vielen vorherigen Dekompilierern nutzte dieser erstmals ”Pattern-Matching”, um gezielt einen Maschinencodebereich aufgrund seiner spezifischen Befehlsverket- tung und Struktur zu erkennen und anschließend die Assemblerbefehle in eine Meta- sprache umzuwandeln. Die bekannte Arbeitsweise des Compilers ermöglichte es, die Anzahl der möglichen Befehlsketten einzugrenzen. Im gleichen Jahr veröffentlichte B. C. Housel seine Doktorarbeit über das Dekompilieren [Hou73]. In seiner Arbeit strebte er durch die Kombination von Graphen-, Compiler- und Optimierungstheorien, einen allgemein anwendbaren Dekompiler an. Im folgenden Jahr greift F. L. Friedman diese Arbeit auf und führt die Forschung von Housel fort. Er gliedert den Verarbeitungsprozess strukturierter in die vier Phasen Vorverarbeitung, Decompiler, Programmcodegenerierer und Compiler. Einige Jahre später beschreibt Cristina Cifuentes in ihrer 1994 veröffentlichten Dok- torarbeit die Einbindung von Wissen über den Compiler in den Dekompilierungspro- zess [Cif94]. Die meisten jüngst erschienenen Veröffentlichungen beziehen sich mehr auf die Um- wandlung von Assemblerquellcode in höhere Programmiersprachen. Zu diesen Veröf- fentlichungen zählt A. Mycroft’s ”Type Reconstruction for Decompilation”. In seiner Ar- beit geht Mycroft vor allem auf die Wiederherstellung von Datenstrukturen und deren Typen ein. Außerdem wurden in den letzten Jahren weitere Methoden mittels Plugin für die Software IDA-Pro demonstriert. Als Beispiele für Plugins sind Desquirr [Eri02] und das Hex-Rays-Decompiler-Plugin [Gui02] zu nennen. Für die Dekompilierung von auf aktuell genutzten Prozessoren ausgelegten Program- men können neben IDA-Pro [IDA] die Anwendungen Boomerang, radare2 [rad2], Bina- ry Ninja [BiNi] und Ghidra [Ghid] verwendet werden. Dabei stellen IDA-Pro und Binary Ninja zwei proprietäre Decompiler dar, bei denen die Funktionsweise und verwende- ten Algorithmen nicht öffentlich einsehbar oder dokumentiert sind. Dagegen fallen die restlichen genannten Decompiler in die Open-Source-Kategorie [Qboom] [Qrad2] [QG- hid]. Der öffentlich einsehbare Quellcode dieser Programme ermöglicht eine detaillierte Einsicht in deren Arbeitsweisen. Bei Bedarf können diese selbst modifiziert werden. Boomerang ist ein 2002 gestartetes Open-Source-Projekt unter der GNU GPL. Rada-
12 Kapitel 2: Basiswissen re2 stellt ein Reverse Engineering Framework mit vielen Kommandozeilenwerkzeugen dar. Ghidra, ursprünglich vom Geheimdienst NSA entwickelt, wurde jedoch nach den Shadow Broker Veröffentlichungen mit der Apache 2.0 Lizenz auf Open-Source-Basis weiterentwickelt [heis19]. 2.6 Game-Boy-Architektur Die Game-Boy-Architektur erscheint aus heutiger Betrachtung mit ihrer 8-Bit-Basis und der Verwendung von Banking historisch alt und irrelevant. Dennoch gibt es gute Gründe, eben jene 8-Bit-Architektur für die Analyse der verschiedenen Trennungsmethoden zu verwenden. 2.6.1 Auswahlgründe Monolithische Programme: Spiele für den Game Boy wurden auf austauschbaren Speichermedien verkauft, welche über einen Steckplatz ausgewechselt werden. Dabei beinhaltet jedes Speichermodul alle zur Ausführung notwendigen Ressourcen und An- weisungen. Genauer gesagt sind es ROM-Speicherchips, welche direkt in den Speicher des Computers eingebunden werden. Hierfür ist der Speicherbereich 0x0000 – 0x7FFF vorgesehen [DBGB, Abs. Memory Map]’. Zum Ausführungsbeginn liegt das ausführbare Programm in seiner Vollständigkeit zur Verfügung. Das bedeutet, es werden keine dyna- mischen Bibliotheken oder andere externe Ausführungsbereiche während der Ausfüh- rung nachgeladen. Damit ähnelt ein Game-Boy-Programm mehr einer Mikrokontroller- anwendung als einer Software auf Heimcomputern. Diese, sogenannten monolithischen Programme, erleichtern eine Demonstration der Lösungsansätze. Geringe Programmgröße: ROM-Module für den Game Boy sind, abgesehen von Banking (siehe Kapitel 2.6.4), theoretisch nicht in der Größe begrenzt. In der Praxis wurden nur drei verschiedene Controller eingesetzt, was die maximale Größe der Pro- gramme auf 2 MiB begrenzt [DBGB, Abs. Memory Bank Controllers]’. Deshalb sollte es mit modernen Heimcomputern möglich sein, auch ineffiziente Lösungsansätze zu demonstrieren. Quelloffene Programme: Für die Bewertung des Ergebnisses wird eine korrekte Tren- nung in Ressourcen und Befehle benötigt. Diese Trennung wird als Referenz manuell erstellt. Dabei erleichtert ein quelloffenes Programm das manuelle Vorgehen erheblich. Für die ausgewählte Hardware müssen daher Open-Source-Assemblerprogramme ver- fügbar sein. Trotz des Alters der Game Boy Architektur, existieren und entstehen wei- terhin selbsterstellte Demos und Spiele aus Hobbyprojekten [HoBr]’. Insofern existiert eine ausreichende Auswahl an untersuchbaren Programmen.
Kapitel 2: Basiswissen 13 Prozessorarchitektur: Die Sharp-LR35902-CPU ähnelt einem x86- und Z80-Prozessor [DUlti, 9min, 48s]’. Der x86-Befehlssatz ist mit seinen Erweiterungen die derzeit meist- genutzte Prozessorarchitektur. Folglich sollten sich daher die in dieser Arbeit umge- setzten Lösungsmethoden mit wenig Arbeit auch auf modernen Computern umsetzen lassen. Zusätzlich reduziert die Sharp-LR35902-CPU mit ihre 500 OP-Codes [DPast]’ den Implementierungsaufwand, gegenüber eines modernen Prozessors. So unterstützt beispielsweise ein Arm R v8-M über tausend unterschiedliche Befehle [Armv8, Kap. C2]. Außerdem beinhaltet sie durch den mit Banking erweiterten Adressbereich auch Kon- zepte von historischen Architekturdesigns. Infolgedessen ermöglicht diese Architektur, auf der Schwelle zwischen alten und modernen Designkonzepten, die Demonstration der ausgewählten Algorithmen an sowohl neuer, als auch veralteter Hardware. Diese Architektur stellt dadurch ein ausgezeichnetes Testfeld zum Erproben der ausgewähl- ten Techniken dar. 2.6.2 Sharp-LR35902-CPU Die Sharp-LR35902 CPU ist ein eigener für den Game Boy entworfener Prozessor. Er ist Teil des Game-Boy-Chips, welches als ”System on a Chip”, kurz SoC, produziert wurde. Hierbei werden verschiedene Komponenten auf einem einzigen Siliziumchip vereint. Im Falle des Game-Boy-Chips kommen neben der Sharp-LR35902-CPU noch der Interrupt Controller, Timer, flüchtiger Speicher, Boot ROM, Joypad Input Controller, Serial Data Transfer Controller, Sound Controller und die Pixel-Processing-Unit hinzu. Die Architektur der Sharp-LR35902-CPU ähnelt sehr den erfolgreichen vorangegan- genen Intel-8080- und Z80-Prozessorarchitektur und stellt damit eine der letzten 8- Bit-CPUs dar. Der genutzte Befehlssatz orientiert sich stark an x86 und dem Z80, ist jedoch keine absolute Obermenge von einer dieser Architekturen [DUlti, 9min, 47s]’. Ausgenommen weniger Befehle wurden die am häufigsten genutzten Anweisungen von der x86-Architektur übernommen. Zusätzlich wurde der Befehlssatz mit einigen Kom- mandos der Z80-Architektur und neuen, speziell an die Bildverarbeitungshardware des Game-Boys angepassten Befehle ergänzt [DUlti, 10min, 12s]’. Alle nutzbaren Anwei- sungen sind in der Abbildung A.2 abgebildet. Um mehr als 256 Befehle mit einer 8-Bit-Architektur verwenden zu können, ist eine Be- fehlslänge von mehr als einem Byte notwendig. Der Befehl 0xCB ermöglicht 256 weitere Befehle, indem der gewünschte Befehl nach dem Präfixbyte 0xCB angehängt wird. Die Abbildung A.3 listet alle möglichen Befehle nach einem 0xCB-Präfix auf. Die Kommandos 0xD3, 0xDB, 0xDD, 0xE3, 0xE4, 0xEB, 0xEC, 0xED, 0xF4, 0xFC und 0xFD sind nicht belegt [DPast]’. Bei Ausführung lösen diese einen Absturz des Sys- tems aus [DUlti, 15min, 11s]’. Der Prozessor verwendet die 8-Bit-Register A, B, C, D, E, H und L. Flags werden in einem eigenen 8-Bit Register gespeichert, bei dem nur die
14 Kapitel 2: Basiswissen
obersten vier Bits belegt werden können. Die 4 niedrigsten Bits sind stets Null. Die-
ses spezielle Register trägt die Bezeichnung F. Zusätzlich können die 16-Bit-Register
”Program-Counter” und ”Stack-Pointer”, kurz PC und SP, genutzt werden. PC speichert
die Adresse des nächsten Befehls und SP zeigt auf die aktuelle Stackposition. Aus den
oben genannten 8-Bit-Registern können die 16-Bit-Verbundregister AF, BC, DE und HL
konkateniert werden [DBGB, Abs. CPU Registers and Flags]’.
Bis auf De- und Inkrementierungen können arithmetische Operationen, wie add oder
sub, nur auf dem Register A ausgeführt werden. Ebenso können auch logische Ope-
rationen, wie xor oder and, nur auf dem Register A durchgeführt werden. Dabei über-
schreibt jeweils das Ergebnis den bisherigen Wert in Register A [DBGB, Abs. CPU In-
struction Set]’.
Ein guter Einstiegspunkt für weitere Details zu Befehlen und deren Auswirkungen sind
die Quellen [DUlti]’ [DBGB]’ [DDevW]’ [DOpen]’ [DGekk]’ und vor allem der Emulator
”SameBoy” [QSaBo], welcher sich als Ziel gesetzt hat, den Game Boy möglichst genau
zu emulieren.
2.6.3 Speicheraufbau
Der Sharp-LR35902-Prozessor verwendet einen 16-Bit-Adressbus und kann somit 64 KiB
an Speicher adressieren. Der Adressbereich bindet außerdem die externe Hardware ein
und stellt eine zentrale Schnittstelle dar. Der Adressraum gliedert sich wie folgt auf:
Anfang Ende Inhalt
0x0000 0x3FFF ROM Bank 0
0x4000 0x7FFF ROM Bank 1 - X
0x8000 0x9FFF Video-RAM (VRAM)
0xA000 0xBFFF Externer RAM
0xC000 0xCFFF Interner RAM (WRAM) Bank 0
0xD000 0xDFFF Interner RAM (WRAM) Bank 1
Bank 2 – 7 in Game Boy Color möglich
0xE000 0xFDFF Echo-RAM, entspricht 0xC000 – 0xDDFF
0xFE00 0xFE9F Object Attribute Table (OAM), Sprites
0xFEA0 0xFEFF Unbelegt
0xFF00 0xFF7F I/O-Ports
0xFF80 0xFFFE High-RAM (HRAM)
für häufig genutzte Variablen und OAM-Routine
0xFFFF 0xFFFF Register für aktivierte Interrupts
Tabelle 2.1: Speicherbereiche der Game-Boy-Architektur
[DBGB, Abs. memorymap]’, [DDevM]’, [DUlti, 17min, 6s]’, [DMong]’Kapitel 2: Basiswissen 15
Die Adress- und Datenleitungen für den ROM- und externen RAM-Adressbereich sind
direkt an das Speichermodul angebunden. Die dort angeschlossene Hardware definiert
das Verhalten dieser Speicherbereiche.
2.6.4 Banking
Der maximal adressierbare Speicher von 64 KiB limitiert die Größe der möglichen Pro-
gramme stark. Aus diesem Grund kommt bei dem Game Boy, wie bei vielen historischen
Architekturen, Banking zum Einsatz [DUlti, 18min, 24s]’. Als eine Bank bezeichnet man
einen zusammenhängenden Speicherbereich, welcher bei Bedarf mit einer atomaren
Anweisung ausgetauscht werden kann. Das bedeutet, dass bei jedem Befehl klar defi-
niert ist, welche Bank aktuell geladen ist. Konsequenterweise kann immer nur auf den
Speicher der derzeit geladenen Bank zugegriffen werden. Die Abbildung 2.2 zeigt die
Funktionsweise des Bankings im ROM-Bereich des Speichers.
Abbildung 2.2: Funktionsweise der Banks des Game Boys
Um den Wechsel zwischen den Banken einfacher handhaben zu können, bleibt die
Bank Null beim Game Boy immer geladen [DUlti, 18min, 40s]’. Es ist zu beachten, dass
ein direkter Sprung von der ersten Bank zur zweiten Bank bei sauberer Programmierung
nicht möglich ist. Aus diesem Grund werden in der Bank 0 häufig sogenannte Trampo-
line eingesetzt. Das in der Abbildung 2.3 gezeigte Beispiel verdeutlicht ein Trampolin,
welches einen beliebigen Bankwechsel ermöglicht. In dem Beispiel springt das Pro-
gramm in der Mainroutine der vierten Bank zur Subroutine in der siebten Bank, indem
es zunächst das Trampolin in Bank 0 aufruft. Dieses lädt anschließend die siebente
Bank und führt dort die gewünschte Subroutine aus. Anschließend nutzt die Subroutine
erneut das Trampolin, um zurück zur Mainroutine zu gelangen. Dieses Beispiel verdeut-
licht außerdem weitere Spezialfälle. Obwohl der Call-Befehl eingesetzt wird, kommt der
Return-Befehl hier nie zum Einsatz. In diesem Beispiel wurde der Stack zum Übergeben
der gewünschten Zieladresse und -bank genutzt. In der Praxis kommen viele verschie-
dene Arten von Trampolinen zum Einsatz. Neben dem hier gezeigten Beispiel gibt es
noch jene mit fest vorgegebenen Zielen und Trampoline, welche Register oder Spei-16 Kapitel 2: Basiswissen
cheradressen als Parameterübergabe nutzen. Je nach Anwendungsfall besitzen diese
Vor- und Nachteile, auf die hier nicht weiter eingegangen wird. Auch Kombinationen
zwischen fester Bank und variabler Adresse sind häufig in der Praxis zu beobachten.
1 BANK_SELECT equ $2100 ; write address for a bank change
2
3 section " Trampoline " , rom0 [ $0500 ]
4 Trampoline ::
5 ld [ BANK_SELECT ] , C ; C = target bank
6 jp HL ; HL = target address
7
8 section " Mainroutine " , romx [ $0100 ] , bank [ $4 ]
9 Mainroutine ::
10 ld HL , Subroutine ; target address
11 ld C , BANK ( Subroutine ) ; target bank
12 ld DE , BANK ( .continue ) ; load bank number of .continue
13 push DE ; push bank number of .continue
14 call Trampoline ; call Subroutine , push .continue
15 .continue :
16 ; more code here ...
17
18 section " Subroutine " , romx [ $0250 ] , bank [ $7 ]
19 Subroutine ::
20 ; do some stuff ...
21 .return :
22 pop HL ; load return address
23 pop BC ; load return bank
24 jp Trampoline ; return from subroutine
Abbildung 2.3: Trampolin Programmbeispiel
Ein Bankwechsel erfolgt durch das Schreiben der Banknummer in dem vordefinierten
Speicherbereich zwischen der Adresse 0x2000 und 0x3FFF [DUlti, 18min 50s]’ [DBGB,
Abs. Memory Bank Controllers]. Typischerweise wird die Adresse 0x2100 verwendet.
Weil der Controller auf dem Speichermodul selbst den Bankwechsel durchführt, ist der
Prozessor beim Bankwechsel nicht involviert. Mit dem Einsatz einer anderen Hardware
auf dem Speichermodul wären also auch andere Umsetzungen und Bankgrößen mög-
lich.
Banking wird beim Game Boy nicht nur beim geladenen Programm im ROM-Bereich
umgesetzt, sondern ist ebenfalls im internen RAM möglich [DUlti, 19min]’. Im Allgemei-
nen wurde die Umsetzung des Bankings im Game Boy hier vereinfacht, um das Konzept
zu erklären. Fortführend kann das exakte Verhalten des jeweilig eingesetzten Control-
lers in den Quellen [DBGB, Abs. Memory Bank Controllers]’ und [DOpen]’ nachgelesen
werden.Kapitel 2: Basiswissen 17 2.6.5 Sprites Das auf dem Bildschirm dargestellte Bild des Game Boys setzt sich aus acht mal acht Pixel großen Bereichen zusammen. [DBGB, Abs. VRAM Sprite Attribute Table (OAM)]’. Dafür werden im sogenannten Object Attribute Memory, kurz OAM, bis zu 40 Sprites im Speicher hinterlegt. Beim Zeichnen des Bildes auf dem Bildschirm werden die an- zuzeigenden Sprites nur noch mit einem Index angegeben. Die Game-Boy-Hardware stellt für das Kopieren von Bildressourcen in diesen Bereich eine eigene Lösung zur Verfügung. Jedoch kann die CPU während des Kopiervorgangs nur auf den HRAM des Speichers zugreifen. Daher wird von Programmen eine kurze Routine in diesen Spei- cherabschnitt geladen. Die darin abgelegte OAM-Direct-Memory-Access-Routine, kurz OAM-DMA-Routine, wird während der parallel ablaufenden Verschiebung der Bildres- sourcen ausgeführt [DBGB, Abs. LCD OAM DMA Transfers]’.
18
Kapitel 3: Lösungsansätze 19
3 Lösungsansätze
In diesem Kapitel werden mögliche Lösungsansätze mit ihren Vor- und Nachteilen er-
läutert. Zusammenfassend sind die Zusammenhänge der ausgewählten Ansätze in der
Abbildung 3.1 dargestellt. Ausgehend vom manuellen Ansatz lassen sich verschiedens-
te Lösungsansätze ableiten, indem an unterschiedlichen Punkten Annahmen oder In-
formationen eingebunden werden.
Abbildung 3.1: Übersicht aller Lösungsansätze
Wie in der Übersicht zu erkennen ist, lassen sich die Ansätze nach Automatisierungs-
grad und Betrachtungsweise der binären Daten, in Kategorien einteilen. Demzufolge
kann man die Lösungsansätze einem Automatisierungsgrad in den Abstufungen keine,
teilweise und vollständige Automatisierung zuordnen. Für den Anwender wünschens-
wert ist es, die Ansätze Brute-Force, Programmfluss und statistischer Ansatz umzu-
setzen. Hierbei entsteht der geringste manuelle Aufwand, da das Programm die Arbeit
komplett abnimmt.20 Kapitel 3: Lösungsansätze Neben dem Automatisierungsgrad lässt sich die Auswertung des binären Formats in drei Klassen einteilen. Einerseits können die aus Bytes erzeugten Befehle als eine Ein- heit betrachtet werden. Hierbei werden die Auswirkungen der Befehle in die weitere Be- trachtung mit einbezogen. Andererseits besteht die Möglichkeit, jedes Byte unabhängig vom Ausführungskontext zu betrachten. Folglich lässt sich erahnen, dass Algorithmen, welche nur Bytes auswerten, eine schnellere Analyse des Programms ermöglichen. Zu- sätzlich kann die manuelle Betrachtung mit zur Verfügung stehenden Hilfsmitteln verein- facht werden. Demzufolge entscheidet der Analyst ganz individuell, wie der untersuchte Bereich auszuwerten ist. Für alle Lösungsansätze übergreifend lässt sich festhalten, dass der Programmein- stiegspunkt bei allen Game-Boy-Programmen bei der Adresse 0x0100 festgelegt ist [DBGB, Abs. powerupsequence]’, [DUlti, 21min]’. Die Adresse ergibt sich aus den aus- geführten Befehlen des Boot-ROMs [DUlti, 19min 16s]’. Daraus lässt sich schließen, dass an dieser Stelle im Binary sich zwangsläufig ein Befehlscode befinden muss. Dar- über hinaus existieren per Hardware festgelegte Sprungadressen für rst-Befehle. Auf den entsprechenden Adressen 0x0000, 0x0008, 0x0010, 0x0018, 0x0020, 0x0028, 0x0030 und 0x0038 [DBGB, Abs. cpuinstructionset]’ befinden sich daher mit hoher Wahrscheinlichkeit Befehle. Dies muss jedoch nicht zwangsläufig der Fall sein. Die glei- che Aussage lässt sich für die Adressen der Interrupts bei 0x0040 (V-Blank), 0x0048 (LCD-STAT), 0x0050 (Timer), 0x0058 (Serial) und 0x0060 (Joypad) treffen [DBGB, Abs. interrupts]’. Wird ein Interrupt nicht verwendet, so können dort Ressourcen hin- terlegt werden. Selbst, wenn beispielsweise der Interrupt V-Blank verwendet wird, heißt das nicht zwangsläufig, dass es sich bei den Adressen von 0x0040 bis 0x0047 um Befehle handelt. Ein Sprungbefehl zur eigentlichen Interruptroutine kann beispielswei- se die drei Bytes 0x0040 bis 0x0042 belegen. Folglich könnten nun 0x0043 bis 0x0047 mit Ressourcen befüllt werden. Typischerweise werden in der Praxis diese Bytes jedoch nicht als Daten genutzt, sondern mit Nullen aufgefüllt [QStef].
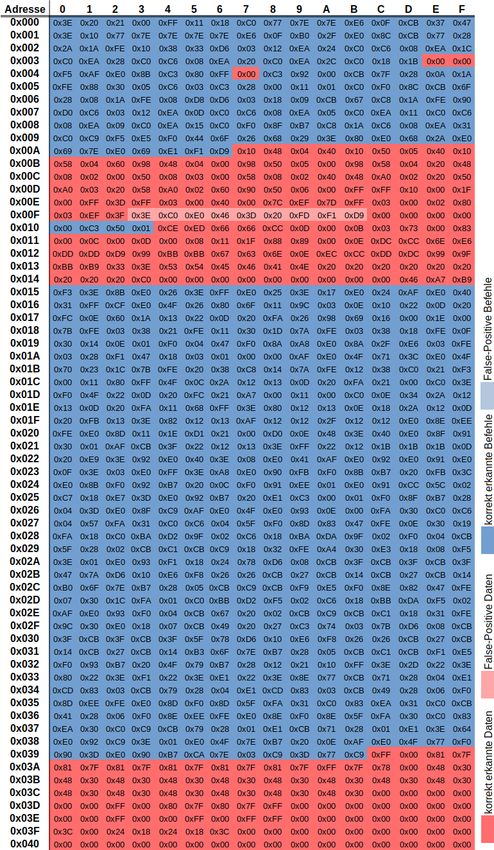
Kapitel 3: Lösungsansätze 21
3.1 Manueller Ansatz
Beim manuellen Ansatz wird das untersuchte Programm von Befehl zu Befehl und Byte
zu Byte betrachtet. Mit der Verwendung des bekannten Startpunktes kann so händisch
die Bedeutung eines jeden Befehls verstanden werden. Hierbei lassen sich auch sehr
unkonventionelle Programmierstile nachvollziehen und auflösen. Es wird nun dem Pro-
grammablauf gefolgt und manuell angesprungene Adressen werden als Befehle iden-
tifiziert. Ressourcenbereiche lassen sich durch die Verwendung dieser ermitteln. Alle
unverwendeten Adressen werden ebenfalls als Ressourcen aufgefasst.
Jedoch fällt es Menschen schwer, binäre oder hexadezimale Zahlen zu interpretieren.
Zur Unterstützung dieser Methode kann ein Programm, welches die rohen Bytes in die
entsprechende Mnemonic-Ausdrücke umwandelt, den Analysten bei ihrer Arbeit helfen.
Damit entfällt das Abgleichen mit der OP-Code-Tabelle (siehe Abbildung A.2 und A.3).
Zusätzlich können Tooltipps zu Adressen und Registern häufigem Nachschlagen in der
Architekturdokumentation entgegenwirken.
Dennoch ist auch mit den Hilfsmitteln dieser Prozess sehr zeitaufwändig. So wurde für
die manuelle Trennung, des zur Ergebnisvalidierung genutzten Programms mit der Zu-
hilfenahme des Quellcodes etwa 8 Stunden für 1020 Bytes benötigt. Diese Zeitangabe
kann als Referenzwert genutzt werden, um den zeitlichen Aufwand dieser Methode ein-
zuordnen.
Zusammenfassend werden die Vor- und Nachteile in der Tabelle 3.1 aufgelistet.
Kriterium Einschätzung
immer anwendbar ja
manuelle Arbeit sehr hoch
Ausführungszeit sehr hoch
Zeitaufwand Vorarbeit keine
erkennt alle Befehle korrekt ja
erkennt alle Ressourcen korrekt ja
erkennt Labeladressen ja
benötigte Ausführungshardware keine / leistungsarm
benötigte Konzentration sehr hoch
Parallelisierbarkeit gering
Tabelle 3.1: Zusammenfassung des manuellen AnsatzesSie können auch lesen

















































