Deep Learning in der Bildverarbeitung - Bildverarbeitung - beam-Verlag
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

Bildverarbeitung
Deep Learning in der Bildverarbeitung
Neuronale Netze (CNN) auf FPGAs im industriellen Einsatz
[Quelle: Silicon Software GmbH]
Deep Learning besticht in der sifikation) wird Deep Learning immer Translationsinvarianz ist eine seiner
Bildverarbeitung durch eine sehr wichtiger, während ergänzend dazu Stärken, die einen sehr hohen Auf-
hohe Vorhersagegenauigkeit bei die Bildvorverarbeitung, -nachbear- wand bei klassischer Programmie-
der Erkennung, wird die Qualität beitung und Signalverarbeitung wei- rung bedeutet. Klassische Algorith-
von heutigen Bildverarbeitungs- terhin mit den bisherigen Methoden men sind im Vorteil, wenn eine Loka-
systemen verbessern und neue ausgeführt werden. Sind Aufgaben- lisierung von Objekten oder Fehlern
Anwendungen erschließen. Der stellungen ausschließlich, einfacher in einem Bild, das maßliche Prüfen,
Lösungsansatz mit tiefen neuro- oder mit besseren Ergebnissen mit Codelesen oder Post-Processing
nalen Netzen wie CNN (Convoluti- Deep Learning zu lösen, verdrängt benötigt werden. Bild 1 vergleicht
onal Neural Networks) übernimmt dies die klassische Bildverarbeitung Deep Learning mit konventioneller
daher immer mehr Aufgaben der – insbesondere bei erschwerenden Bildverarbeitung.
klassischen, auf algorithmischer Variablen wie reflektierende Ober-
Beschreibung basierenden Bildver- flächen, schlecht ausgeleuchtete Training bei Deep Learning
arbeitung. Bei der Bildklassifikation Umgebungen, variierende Beleuch- Deep Learning unterscheidet zwi-
(Defekt-, Objekt- und Merkmalsklas- tung oder bewegende Objekte. Die schen dem Training zum Anlernen
Autor:
Martin Cassel, Redakteur
Silicon Software GmbH Bild 1: Eignung von Deep Learning im Vergleich zur klassischen Bildverarbeitung
https://silicon.software [Quelle: Silicon Software GmbH]
62 PC & Industrie 1-2/2019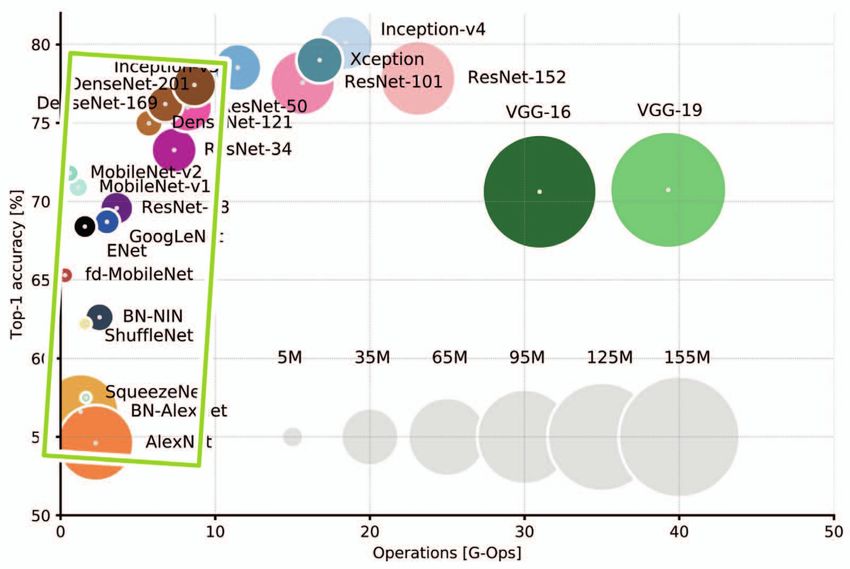
Bildverarbeitung
Bild 2: Zunahme der Vorhersagegenauigkeit durch Erhöhen der Trainingsdaten [Quelle: Silicon Software GmbH]
des neuronalen Netzes, der Imple- alleine an Grenzen stoßen. Diese wenn nur wenige Merkmale zu klas- sich durch eine hohe Parallelität der
mentierung des Netzes und der Infe- stellen eher eine passende Lösung sifizieren sind. AlexNet, Squeeze- Datenberechnung aus, garantieren
rence, dem Ausführen der CNN- für Bildverarbeitungsaufgaben im Net oder MobileNet sind typische einen robusten Bildeinzug und – im
Algorithmik des Netzes auf Bilder nicht-industriellen Umfeld dar, wo Vertreter hierfür. Diese stehen in Vergleich zu CPUs und GPUs – eine
mit der Ausgabe eines Klassifizie- eine geringere Durchsatz-Perfor- einem guten Verhältnis zwischen hohe Rechenleistung, Bildrate und
rungsergebnisses. Je mehr Daten manz zu Gunsten einer komplexeren Vorhersagegenauigkeit, Imple- Bandbreite. Dadurch klassifizieren
für das Antrainieren verwendet wer- Erkennungsanforderung manchmal mentierungsgröße und Rechen- CNNs auf FPGAs mit hohem Daten-
den, desto höher ist die Vorhersage ausreichend ist. Alleine beim Ver- geschwindigkeit bzw. Bandbreite durchsatz, was beispielsweise die
genauigkeit bei der Klassifikation gleich technischer Aspekte zeigen in der Machine Vision. Hier zeigt zeitlichen Anforderungen der Inline-
(Bild 2). Aufgrund der sehr hohen die Technologieplattformen unter- sich deutlich, dass durch die Aus- Inspektion erfüllt.
Datenmengen beim Training von schiedliche Leistungswerte, die wahl passender Netzarchitekturen Der FPGA ermöglicht eine Ver-
neuronalen Netzen stellen GPUs ihren Einsatz bei Anwendungen mit für die jeweilige Anwendungsanfor- arbeitung der Bilddaten – von der
hierfür die richtige Wahl dar. hohen Anforderungen ausschlie- derung ein akzeptabler Erkennungs- Bildaufnahme zur -ausgabe und zur
ßen. So ist die Inference-Bearbei- verlust bei gleichzeitigem Gewinn Gerätesteuerung – direkt auf einem
Geschwindigkeit versus tung auf einer GPU zwar deutlich an Datendurchsatz erreichbar ist Framegrabber oder eingebetteten
Vorhersagegenauigkeit kürzer als die auf einer CPU oder – eine Möglichkeit, Ressourcen zu Vision-Gerät ohne die CPU zu bela-
Eignen sich jedoch die verschie- speziellen Chips wie einer TPU (Ten- optimieren und die Klassifizierungs-
sten, was besonders für rechenin-
denen Prozessortechnologien glei- sorFlow Processing Units) oder dem qualität zu erhöhen. tensive Anwendungen wie CNNs
chermaßen für die industrielle Bild- Intel Movidius Prozessor, erreicht geeignet ist. Dadurch sind kleinere
verarbeitung mit ihren speziellen aber als Performanz-Indikator im FPGAs und SoCs für PCs ohne GPU einsetzbar, was die
Anforderungen an ein schnelles Schnitt geringere Durchsatzwerte Inference Kosten des gesamten Bildverarbei-
Ausführen (Inference) von CNNs bei als 50 MB/s. Den Anforderungen an die Infe- tungssystems verringert. Die Energie
gleichzeitig sehr geringen Latenzen? rence vieler Bildverarbeitungsauf- effizienz von FPGAs im industriel-
Neben Geschwindigkeit und Echt- Auswahl des Netzes gaben, insbesondere der Machine len Temperaturbereich ist zehnmal
zeit-Anforderungen sind hohe Band- Bei der Auswahl eines geeigneten Vision, am besten gewachsen sind höher im Vergleich zu GPUs, was für
breiten, eine geringe Wärmeleistung Netzes genügen für typische Anwen- FPGAs als eigenständiger Prozes- eingebettete Geräte ideal ist. Dies
und Langzeitverfügbarkeit gefragt, dungen in der Bildverarbeitung oft- sor oder als SoC im Verbund mit vergrößert den Einsatzbereich von
wo herkömmliche CPUs oder GPUs mals kleine oder mittelgroße Netze, ARM-Prozessoren. FPGAs zeichnen Deep Learning etwa in Hinblick auf
PC & Industrie 1-2/2019 63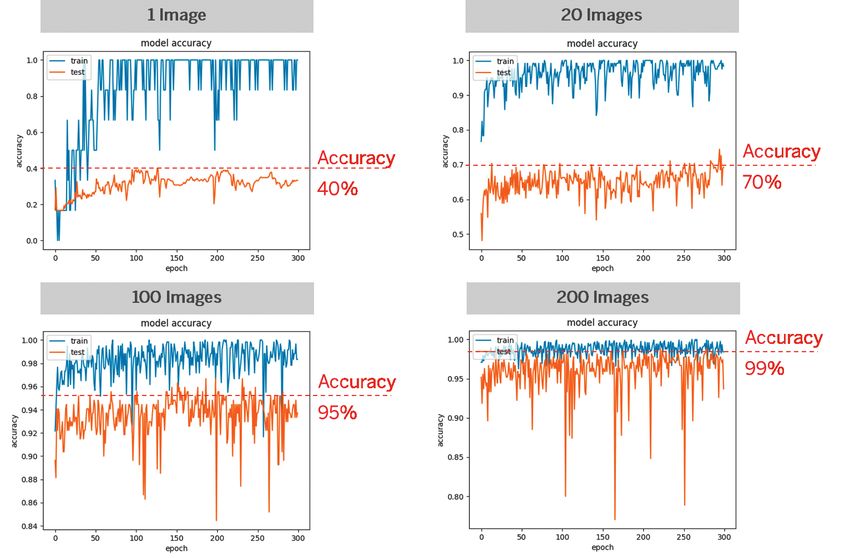
Bildverarbeitung
keiten existieren bereits Lösungen
mit Hochleistungs-Framegrabbern
oder eingebetteten Vision-Gerä-
ten wie Kameras und Sensoren
mit größeren FPGAs. Mit umfang-
reicheren FPGA-Ressourcen las-
sen sich komplexere Architekturen
und damit auch Anwendungen ver-
arbeiten. Die höhere Datenband-
breite ermöglicht eine Verarbeitung
eines Gesamtbildes oder zusätz-
liche Bildvor- und -nachverarbeitung
auf dem FPGA. Sie ist ausreichend
hoch, um beispielsweise den kom-
pletten Datenausgang einer GigE
Vision Kamera über Deep Learning
zu analysieren.
Fazit
Im Vergleich zur klassischen Bild-
verarbeitung wird ein relativ hoher
Trainingsaufwand bei Deep Lear-
ning durch Zuverlässigkeit und
Schnelligkeit mehr als aufgewo-
gen. Die FPGA-Technologie auf
Bild 3: “An analysis of Deep Neural Network Models for Practical Applications” von Alfredo Canziani, Framegrabbern und (eingebetteten)
Adam Paszke, Eugenio Culurciello (2017) Vision-Geräten ermöglicht den Ein-
satz von neuronalen Netzen für
Anwendungen mit industriellen
Industrie 4.0 sowie Drohnen und die Produktionsgeschwindigkeit von geringer Bedeutung, erreichen Anforderungen an Echtzeitfähigkeit
autonomes Fahren deutlich. etwa bei der Schweißnaht-Inspek- doch 8 bit Fixed Point FPGAs eine bzw. geringen Latenzen (wichtig für
Die höhere Rechengenauigkeit tion oder Robotik zu steigern. Eine ausreichend präzise Vorhersage- Inline-Inspektion), Datendurchsatz,
von GPUs und damit auch höhere datenreduzierende Bildvorverarbei- genauigkeit für die meisten Deep Bandbreite und geringe Wärme
Vorhersagegenauigkeit wird durch tung ermöglicht es darüber hinaus, Learning-Anwendungen bei zu ver- leistung (wichtig für embedded
deutlich kürzere Verfügbarkeiten, kleinere Netze oder FPGAs ein- nachlässigender Fehlertoleranz. Bei Vision), auch für hoch aufgelöste
höhere Leistungsaufnahme, aber zusetzen. Diese reichen oftmals Anforderungen nach besonders Bilder. Die lange Verfügbarkeit
auch durch einen geringeren Daten- für Klassifizierungsaufgaben mit präziser Rechengenauigkeit lässt von FPGAs und Framegrabbern
durchsatz erkauft. Ein exemplarischer wenigen Merkmalen für die Fehler sich auf einem größeren FPGA gewährleistet eine hohe Investiti-
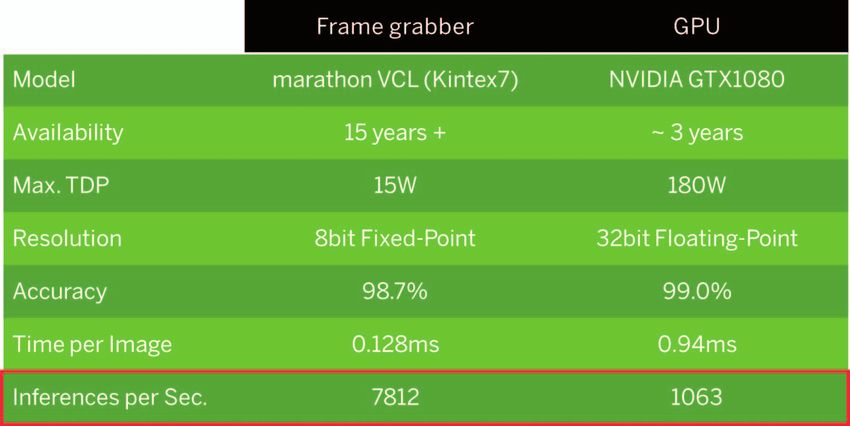
Vergleich der Leistung der Daten- detektion aus. als Ressourcenkompromiss auch onssicherheit. Anwender profitie-
bearbeitung liegt bei einer FPGA- Die höhere Rechengenauigkeit 16 bit Fixed Point implementieren. ren von langfristigen Einsparungen
basierten Lösung um Faktor 7,3 einer 32 bit Floating Point GPU ist Für die in der Produktion erforder- durch schnelle Anpassbarkeit und
höher als bei einer vergleichbaren für die Deep Learning-Inference lichen Verarbeitungsgeschwindig- geringere Gesamtsystemkosten. ◄
Systemlösung mit GPUs (Bild 4).
FPGA-Ressourcen
optimieren
Für Deep Learning gibt es unter-
schiedliche Methoden, Ressourcen
einzusparen ohne die Qualität der
Klassifizierung zu beeinträchtigen.
Eine wichtige Methode ist die Ska-
lierung der Bilder, die den internen
Datendurchfluss reduziert. Oder
die Rechentiefe: Erfahrungswerte
haben gezeigt, dass die Rechen-
tiefe sich nur marginal auf die spä-
tere Vorhersagegenauigkeit durch-
schlägt. Die Reduktion von 32 bit
auf 8 bit und von Floating Point auf
Fixed Point / Integer ermöglicht dem
FPGA, die gestiegenen Ressour-
cen für größere Netzarchitekturen
oder einen höheren Datendurchsatz
zu nutzen. Dadurch ist es möglich, Bild 4: Die FPGA-Leistung ist 7,3-mal höher als diejenige der GPU [Quelle: Silicon Software GmbH]
64 PC & Industrie 1-2/2019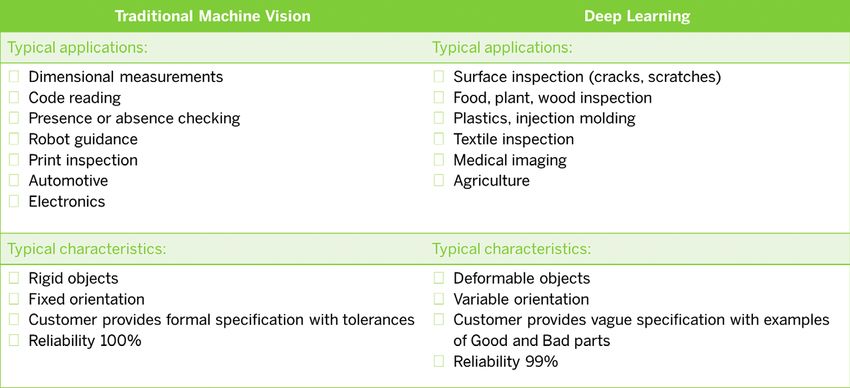

Sie können auch lesen

















































