3D Video Grundlagen Displays Repräsentation von 3D Szenen Depth Image Based Rendering
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Kapitel 16
3D Video
Grundlagen
Displays
Repräsentation von 3D Szenen
Depth Image Based Rendering
Exkurs: Background Modeling
Exkurs: Foreground Extraction
Content Generation
Zukunft
Kapitel 16 “3D Video” – p. 1
Geschichtliche Entwicklung (1)
1838 1890er 27.09.1922 1. Boom:1952-1955
Charles Erste bewegte Erster 3D Film: Erster 3D Film in Farbe:
Wheatstone: 3D Bilder „The power of Love“, „Bwana Devil“
Stereoskop
2. Boom:70er/ 80er Mitte der 80er Ab 2005
u.a. Der weiße Hai 3D IMAX Digitales Kino (DCI)
Kapitel 16 “3D Video” – p. 2
Geschichtliche Entwicklung (2)
Aktuelle Entwicklung:
2005 2009 2010
Digital Cinema Monsters vs. Aliens Alice im Wunderland (konvertiert)
Initiative (DCI) Ice Age 3 Kampf der Titanen (konvertiert)
Coraline Harry Potter 7.1
G-Force (konvertiert)
Oben
Avatar
März 2010 Juni 2010 Oktober 2010 Januar 2011
Samsung: Sony: 3D Spiele Fernsehsender Toshiba:
Consumer 3D (Playstation 3), Sky 3D autostereoskopischer
Fernseher 3D Blu-ray Consumer Fernseher
Kapitel 16 “3D Video” – p. 3
3D-Sehen (1)
Monocular Depth Cues
• Überdeckung
• Perspektive
• Schatten
• Relative Größe
• Height in Field (je höher, desto weiter entfernt)
• Atmosphärische Effekt
• Motion Parallax
• …
Kapitel 16 “3D Video” – p. 4
3D-Sehen (2)
Clande Lorrain (1600-1682): A Seaport at Sunset
Überdeckung
Relative
Größe
Perspektive
Height in Field
Atmosphärische Effekte Kapitel 16 “3D Video” – p. 5
3D-Sehen (3)
Disparity: Wichtigster depth cue
• Entsteht durch das Betrachten einer
Szene aus zwei unterschiedlichen
Blickwinkeln
• Aus diesen Blickwinkeln konstruiert
das Gehirn eine dreidimensionale
Darstellung der Szenerie
• Die Blickwinkel werden rechter und
linker Kanal genannt
• Der durchschnittliche Augenabstand
eines Erwachsenen beträgt 63mm
(„Stereobasis“)
• Etwa 10-15% der Bevölkerung ist
nicht in der Lage, dreidimensional zu
sehen
Kapitel 16 “3D Video” – p. 6
Kreuzblick
Right eye view Left eye view
Kapitel 16 “3D Video” – p. 7
Stereogeometrie
Parallaxen der Kanäle:
• positive Parallaxe: der linke Kanal
befindet sich links vom rechten Kanal.
Das Objekt wird hinter dem Screen
wahrgenommen
• Nullparallaxe: linke und rechter Kanal
sind identisch, das Objekt wird auf
dem Screen wahrgenommen (wie bei Screen
2D Video)
• negative Parallaxe: der linke Kanal
befindet sich rechts vom rechten
Kanal. Das Objekt wird vor dem
Screen wahrgenommen.
• Ist die positive Parallaxe eines Objektes gleich
Left channel
dem menschlichen Augenabstand, wird es in
unendlicher Entfernung wahrgenommen. Right channel
Größere positive Parallaxen werden als
unangenehm empfunden.
User
Kapitel 16 “3D Video” – p. 8
Wahrnehmungsphysiologische Probleme
• Das Betrachten von zwei 2D-Kanälen unterscheidet sich von der natürlichen
Wahrnehmung und kann zu Beeinträchtigungen des Users führen, wie
Kopfschmerz, Übelkeit oder Anstrengung der Augen.
• Ursachen:
• Accomodation – Vergence Konflikt (siehe nächste Folie)
• Vertikale Verschiebung der Kanäle (bei digitaler Projektion praktisch nicht
vorhanden. Kann aber auch biologische Ursachen haben)
• Kopfbewegungen führen nicht zu anderer Sicht auf die Szene
• Schnelle seitliche Bewegungen wie in 2D Filmen üblich sind in 3D
anstrengend
• 2D-Stilmittel wie unscharfer Hintergrund (Auge versucht vergeblich
scharfzustellen)
• Schnelle Schnitte zwischen Szenen mit Objekten mit unterschiedlicher
Tiefe
Zum Teil sind die physiologischen Vorgänge beim 3D Sehen noch nicht
erforscht.
Kapitel 16 “3D Video” – p. 9
Accomodation – Vergence Konflikt
• Accomodation: Die Fähigkeit des Auges, auf Objekte scharfzustellen
• Vergence: Die Fähigkeit, durch Drehung der Augen nach innen, ein Objekt
in den Blick zu nehmen (auf extrem nahe Objekte: Schielen)
• Natürliches Sehen: Accomodation und Vergence hängen zusammen: Um
auf ein Objekt in Entfernung d scharfzustellen, ist immer derselbe Vergence-
Winkel nötig.
• 3D Filme: Die Augen sind immer auf die Leinwand/Screen fokussiert.
Vergence ändert sich von der (virtuellen) Entfernung des Objekts vom User.
Vergence: Je näher die Katze,
desto größer der Eindrehwinkel der
Augen.
Accomodation: Das Auge bleibt auf
den Screen scharfgestellt (denn nur
von dort kommen die Bilder)
Kapitel 16 “3D Video” – p.103D System
3D scene Capturing
Transmission
2D scene 2D-3D conversion 3D Representation
CGI Rendering
Left eye channel
Separate transmission
Renderer Display User
to user„s eyes
Right eye channel
Kapitel 16 “3D Video” – p. 113D System
3D scene Capturing
Transmission
2D scene 2D-3D conversion 3D Representation
CGI Rendering
Left eye channel
Separate transmission
Renderer Display User
to user„s eyes
Right eye channel
Displays
Kapitel 16 “3D Video” – p. 12Displays
• Aufgabe eines 3D Wiedergabesystems ist es, jedem Auge seinen Kanal
zuzuordnen.
• Typen von 3D Wiedergabesystemen:
• Brillenbasiert:
• Aktiv: Shutterbrillen
• Passiv: Polarisationsbrillen, Interferenzfilter, Anaglyph
• Autostereoskopisch
• 1 view
• n views
• Allgemeine Anforderungen an ein 3D Wiedergabesystem:
• Möglichst geringe Beeinträchtigung des Users
• Sichere Trennung der beiden Kanäle (kein Crosstalk)
• Kostengünstig
Kapitel 16 “3D Video” – p. 13Brillensysteme (1)
Anaglyph:
• Das linke und das rechte Auge werden von der Brille mit zwei
komplementären Farben abgedeckt (meist Rot-Cyan, aber auch Grün-
Magenta oder Blau-Gelb)
• Ein Rotfilter ist ein „Rot-pass“ Filter, während ein Cyanfilter ein „Rot-stop“
Filter ist. Ein Rot-Bild wird durch einen Cyanfilter betrachtet als schwarz
empfunden, während es durch einen Cyanfilter nicht beeinträchtigt wird.
Analog gilt dieses für ein Grün-Blau-Bild und einen Rotfilter
• Ein Anaglyphenbild enthält den linken Stereokanal als Rot-Bild und den
rechten als Grün-Blau-Bild. Durch eine Anaglyphenbrille betrachtet, sieht
jedes Auge das für sich bestimmte Bild.
Kapitel 16 “3D Video” – p. 14Brillensysteme (2)
Polarisationsbrillen (linear)
• (linear) polarisiertes Licht schwingt nur in einer Ebene und kann mit
entsprechenden Filtern geblockt werden
• Der linke und der rechte Videokanal werden gleichzeitig mit verschiedener
Polarisation auf die Leinwand projiziert. Polarisationsfilter vor dem linken
und dem rechten Auge filtern das Licht entsprechend.
• Eine silberbeschichtete Leinwand wird benötigt, um die Polarisation des
reflektierten Lichts nicht zu zerstören
• Beispiele: einige Doppelprojektionen. Nachteil: Kopfdrehungen nicht
möglich
Projector Filter Remaining left
eye channel
User„s
Left eye channel eye
Right eye channel
Kapitel 16 “3D Video” – p. 15Brillensysteme (3)
Polarisationsbrillen (zirkulär)
• Wie lineare Polarisationsbrillen nur mit zirkulär polarisiertem Licht.
• Vorteile: Erlaubt Kopfdrehungen, nur ein Projektor wird benötigt.
• Beispiele: RealD, Masterimage, einige 3D Fernseher
Interferenzfilter
• Die Bilder für das rechte und linke Auge werden mit leicht unterschiedlichen
Grundfarben projiziert, z.B.
• Linkes Auge: Rot 629nm, Grün 532nm, Blau 446nm
• Rechtes Auge: Rot 615nm, Grün 518nm, Blau 432nm
• Ein Interferenzfilter in der Brille filtert das Licht für das jeweils andere Auge
heraus
• Vor der Projektion ist eine Farbkorrektur nötig
• Beispiel: Dolby 3D
Kapitel 16 “3D Video” – p. 16Brillensysteme (4)
Shutterbrillen:
• Das Display zeigt abwechselnd ein Bild für das linke und ein Bild für das
rechte Auge an. Die Brille verdunkelt das jeweils andere Auge.
• Verdunklung geschieht mittels LCD-Displays in der Brille
• Synchronisation mit Projektor erforderlich
• Beispiel: XpanD 3D, die meisten aktuellen 3D Fernseher
• Nachteile: Brillen teuer, benötigen Batterie
XpanD 3D Brille Samsung 46-Zoll-3DTV UE46C7700
Kapitel 16 “3D Video” – p. 17Vergleich: Brillentechniken
System Technik Silber- Helligkeits- Kopfposition Kosten
leinwand verlust Brille
Zirkuläre
RealD ja ja frei gering
Polarisation
Zirkuläre
Masterimage ja ja frei gering
Polarisation
Interferenz-
Dolby 3D nein ja frei hoch
filter
Doppel- evtl.
Polarisation ja nein gering
projektion eingeschränkt
XpanD 3D Shutter nein ja frei hoch
Anaglyph - nein - frei gering
Cineplex Münster: Doppelprojektion Alle Systeme sind untereinander inkompatibel, Quelle: kino.de
Generell können diese Systeme nur einen Blickwinkel darstellen, d.h. man kann durch
Kopfbewegungen keine weiteren Blickwinkel auf die Szene erlangen!
Kapitel 16 “3D Video” – p. 18Autostereoskopische Displays (1)
• Autostereoskopische Displays ermöglichen einen 3D Einblick, ohne dass
der User eine Brille tragen muss.
• Neuere Displays können mehrere Einblickwinkel („views“) darstellen (bis
über 60), so dass man durch Kopfbewegung um Objekte herum schauen
kann.
• Alle zusätzlichen Views müssen aus dem Eingangsmaterial gerendert
werden (siehe Abschnitt „Rendering“).
• Nachteile:
• Relative starre Kopfposition nötig für optimalen Blickwinkel
• Jeder View besitzt nur eine geringere Auflösung:
Auflösung pro View = Panelauflösung / #Views
• Sehr teuer (47“ Display ~10k€)
Kapitel 16 “3D Video” – p. 19Autostereoskopische Displays (2)
Parallax barrier
• Der linke Kanal wird in den ungeraden Spalten angezeigt, der rechte in den
geraden.
• Eine Maske wird so vor dem Display angebracht, sodass jedes Auge nur
den für ihn bestimmte Kanal sieht
Kapitel 16 “3D Video” – p. 20Autostereoskopische Displays (3)
Lenticular Lenses
• Der linke Kanal wird in den ungeraden Spalten angezeigt, der rechte in den
geraden.
• Ein Array zylindrischer Linsen lenkt das Licht so, dass jedes Auge nur den
für ihn bestimmten Kanal sieht
Kapitel 16 “3D Video” – p. 21Autostereoskopische Displays (4)
• Nachteil: Die horizontale Auflösung wird halbiert, die vertikale bleibt
unverändert
Aktuelle Displays nutzen ein um einen gewissen Winkel gedrehtes
Lenticular Lens Array um sowohl horizontale als auch vertikale Auflösung
zu verringern.
• Mehrere Einblickwinkel: #views = #channels - 1
Display
L R
R L R L
R L
L
R L R L R
Sketch of an autostereoscopic display with 7 views
Kapitel 16 “3D Video” – p. 22Autostereoskopische Displays (4)
Slanted lenticular: (Alioscopy)
Kapitel 16 “3D Video” – p. 233D System
3D scene Capturing
Transmission
2D scene 2D-3D conversion 3D Representation
CGI Rendering
Representation
Left eye channel
Separate transmission
Renderer Display User
to user„s eyes
Right eye channel
Kapitel 16 “3D Video” – p. 24Repräsentation (1)
• Standardrepräsentation einer 3D Szene: Pro View ein linker und ein
rechter Videokanal.
• Vorteil: Meist Ursprungsformat
• Nachteil: 3D Geometrie fest: Stereobasis lässt sich nicht verändern.
• Nachteil: Für Displays mit mehreren Views benötigt man (#Views + 1)-
viele Videokanäle → große Datenmengen zu verarbeiten
Linker Kanal Rechter Kanal
Kapitel 16 “3D Video” – p. 25Repräsentation (2)
• Alternativrepräsentation: Video plus Depth
• Vorteil: Linker und rechter Kanal werden erst beim User gerendert (Depth
Image Based Rendering, DIBR) → Stereoparameter lassen sich verändern
• Vorteil: Es lassen sich freie Views generieren
• Vorteil: Gut komprimierbar (Depthmap in Graustufen und oft mit wenig
Kontrast). Overhead zu 2D: ca. 10-25%
• Schwierigkeit: Erzeugen von Depthmap
• Schwierigkeit: Rendern der Views
Video stream Depthmap
Kapitel 16 “3D Video” – p. 26Standards
• 3D Blu-ray: MPEG-4 MVC (Multi View Coding): Kodiert linken und rechten
Kanal anhand von Gemeinsamkeiten. Overhead bei ca. 50%.
Abwärtskompatibel zu 2D Blu-ray, d.h. 2D Blu-ray-Player können 3D Blu-
rays abspielen
• Home Entertainment: HDMI 1.4a: Side-by-Side / Top-Bottom
• 3D TV: noch kein einheitlicher Standard. In Südkorea existieren Versuche,
den zweiten Kanal in den DVB-Datenstrom zu packen, ohne die
Abwärtskompatibilität zu verlieren.
• 3D Kino: Digital Cinema Initiative:
• 2048x1080 (2K) at 48 fps - 24fps per eye
• In 2K, for Scope (2.39:1) presentation 2048x858 pixels
• In 2K, for Flat (1.85:1) presentation 1998x1080 pixels
• 10 bit color, YCbCr 4:2:2, each eye in separate HD-SDI stream
Kapitel 16 “3D Video” – p. 273D System
3D scene Capturing
Transmission
2D scene 2D-3D conversion 3D Representation
CGI Rendering
Left eye channel
Separate transmission
Renderer Display User
to user„s eyes
Right eye channel
Depth Image Based Rendering
Kapitel 16 “3D Video” – p. 28Depth Image Based Rendering (1)
• Depth Image Based Rendering:
• Projiziere den Videokanal anhand der Depthmap in den Raum
• Rendere aus diesem einfachen 3D Model einen neuen View
Video stream
Depth map
Kapitel 16 “3D Video” – p. 29Depth Image Based Rendering (2)
Kamerasetup:
Strahlensätze:
Bildsensor
Virtual Original view Virtual
left channel right channel
Shifted-Sensor-Approach: Zwei virtuelle Kameras mit verschobenem CCD-
Sensor (Bildebene) um Konvergenzebene zu erzeugen.
Kapitel 16 “3D Video” – p. 30Depth Image Based Rendering (3)
Geometrie: Rechte virtuelle Kamera (zunächst mit Konvergenzdistanz ∞)
tx
P P‘
Strahlensätze:
p* = (u*,v)
p = (u,v)
Z d
f f
p = (u,v)
original virtual
camera tx camera
Konvergenzdistanz Zc = ∞ :
Konvergenzdistanz Zc < ∞ (Sensorshift um h nach links):
Kapitel 16 “3D Video” – p. 31Depth Image Based Rendering (4)
Zusammenfassung: Pixel (u,v) wird abgebildet auf (u*, v)
f : Kameraparameter
tc : Abstand der virtuellen Kameras (z.B. 63mm)
v : depthmap(u,v)
Zc : Konvergenzdistanz
Kapitel 16 “3D Video” – p. 32Depth Image Based Rendering (5)
Probleme bei DIBR:
• Interpolation: u* ist nicht immer ganzzahlig. Nearest Neighbor führt zu
Artefakten: Lineare Interpolation nötig
Kapitel 16 “3D Video” – p. 33Depth Image Based Rendering (6)
Probleme bei DIBR:
• Disocclusions: 3D projection
a
er
a m
Original camera
c n
al ctio
rtu oje
projection
i
V pr
Foreground
object
Disocclusion gap Depth map
Synthetic View Original View
• Disocclusions entstehen aus der Tatsache, dass einige Bildbereiche, die die
virtuelle Kamera sehen kann, nicht im original view vorhanden sind. Diese
müssen plausibel gefüllt werden.
Kapitel 16 “3D Video” – p. 34Depth Image Based Rendering (7)
• Beispiel für Disocclusions:
• Die weißen Ränder an den Vordergrundkanten sind zu füllende Bereiche
(disoccluded areas). Der weiße Punkt ist ein Interpolationsartefakt.
• Eine mögliche Lösung (post-processing): Image Inpainting:
Keine guten Ergebnisse → produziert neue Artefakte
Kapitel 16 “3D Video” – p. 35Horizontal Interpolation
xl xr xi
I(xi) is computed by linear interpolation:
I ( xi ) I ( xl ) ( xi xl )(I ( xr ) I ( xl ))
Kapitel 16 “3D Video” – p.Background Extrapolation
xl xr xi
Fill disocclusion with pixels xl , d(xl) > d(xr)
with higher depth value: I(xi) =
xr , otherwise
Kapitel 16 “3D Video” – p.Do et al. (2010)
Search 8 neighbors,
1
I ( xi ) d ( p, p ) 2
I ( x, y)
then interpolate between
background neighbors.
d ( p, pi ) ( x, y)BGN
( x , y )BG N
2 i
Kapitel 16 “3D Video” – p.Flicker - Causes
Imprecise depth maps
Horizontal Interpolation
Kapitel 16 “3D Video” – p.Depth Image Based Rendering (8)
• Weiterer Ansatz: Glättung der Depthmap (pre-processing)
• Funktioniert, weil Disocclusions an Objektkanten im neu gerenderten View
entstehen, die ihrerseits durch Kanten in der Depthmap entstehen. Eine
Verringerung der Kanten in der Depthmap kann also zu weniger
Disocclusions führen.
3D projection
Disocclusion gap No disocclusion gap
Original model with original depth map
• Nachteil: Führt zu geometrischen Verzerrungen:
Zhang et al. (2005)
Kapitel 16 “3D Video” – p. 40Depth Image Based Rendering (9)
• Alternativer Ansatz: Anstatt Disocclusions plausibel zu füllen, wirkliche
Farbwerte nehmen (Schmeing and Jiang, 2010)
• Annahme: Video besteht aus statischem Hintergrundpart und dynamischem
Vordergrund.
Separation und getrenntes Rendering.
• Separation:
Background Modeling
Foreground Extraction
Ergibt:
- Hintergrundbild
- Vordergrundmaske
Kapitel 16 “3D Video” – p. 41Depth Image Based Rendering (10)
Rendern:
Idee: Zuerst den neuen View des Hintergrundes berechnen, und dann in
jedem Frame die Vordergrundobjekte hinzufügen:
• Transformation des Hintergrundbildes (nur einmal pro Video, eventuelle
Disocclusions müssen manuell korrigiert werden)
• foreach (Frame)
• Initialisiere mit neuem Hintergrundview
• Identifiziere Vordergrund anhand der Vordergrundmaske
• Berechne neue Positionen der Vordergrundobjekte
• Füge Vordergrund ein
Disocclusions werden mit Hintergrundpixeln gefüllt:
With disocclusions New approach
Kapitel 16 “3D Video” – p. 42Exkurs: Background Modeling (1)
Gegeben: Videosequenz
Gesucht: Hintergrundmodell
Wir beschränken uns auf: statische Kamera
Hintergrundmodell ist ein Bild (plus Zusatzinformationen)
Beispielsequenz A :
Intuitive Unterscheidung:
Vordergrund: sich bewegende Objekte
Hintergrund: statische Bereiche
Kapitel 16 “3D Video” – p. 43Exkurs: Background Modeling (2)
Background Modeling: Naive Herangehensweise:
• Averaging: Bilde für jedes Pixel den zeitlichen Mittelwert:
• Median: Bilde für jedes Pixel den zeitlichen Median:
Kapitel 16 “3D Video” – p. 44Exkurs: Background Modeling (3)
• Median funktioniert nur für Videos, in denen der Hintergrund vorherrscht.
• Sobald ein Pixel in mehr als 50% der Frames Vordergrund zeigt, entstehen
Vordergrundartefakte im Medianbild:
Beispielsequenz B:
Median: Hintergrund:
Kapitel 16 “3D Video” – p. 45Exkurs: Background Modeling – GMM (1)
Gaussian Mixture Model (GMM): Lernen eines Hintergrundmodells
Annahme: Pixel-Timeline als Überlagerung von verschiedenen Effekten (z.B.
sich im Wind bewegender Ast vor einem Busch)
• Pixel-Timeline: Betrachte Pixel (x,y) und beobachte Intensitätswerte über
die Zeit:
Idealfall: Realität: Störungen durch Rauschen
Intensity Intensity
Time Time
Background object Foreground object Background object Background object Foreground object Background object
Kapitel 16 “3D Video” – p. 46Exkurs: Background Modeling – GMM (2)
• Interpretation: Timeline des Pixels X als Überlagerung von K Effekten.
Modellieren der einzelnen Effekte mittels Gaußfunktionen. Effekt k≤K:
1
1 ( X k )t k 1 ( X k )
N ( X , k , k ) e 2
(2 ) k
d 1
2 2
• μk: Mittelwert des Effekts
• σk2: Varianz (Streuung durch Rauschen)
• d: Anzahl der Farbkanäle
• Dichtefunktion: Timeline als gewichtete Summe der Effekte
K
p( x) l N ( x l , l 2 )
l 1
• Die Gewichte πk korrelieren mit der Auftrittshäufigkeit des Effekts
• Für jedes Pixel X werden also K 3-Tupel (μk, σk, πk), k=1..K gelernt.
• Lernen des Models:
• Initialisierung
• Update
Kapitel 16 “3D Video” – p. 47Exkurs: Background Modeling – GMM (3) Initialisierung: • Zufällige Werte für μk • K = 3..7 • σinit = 30 • πinit = 1/K Update: Xt matches effect k, if α: Lernrate: Steuert Fähigkeit des GMM sich an wandelnde Beleuchtung anzupassen Kapitel 16 “3D Video” – p. 48
Exkurs: Background Modeling – GMM (4)
Identifikation des Hintergrundes in Frame t+1:
Für Frame t besteht das Bildmodell aus K 3-Tupeln (μk, σk, πk), k=1..K
für jedes Pixel.
Heuristik zur Entscheidung, ob zu testender Pixel Vorder- oder Hintergrund.
Folgende Annahmen werde gemacht:
• Durch die sich über sie bewegende Textur eines Objektes haben Pixel, die
gerade Vordergrund zeigen eine größere Streuung in ihren Werten. Für
Hintergrundpixel gilt: Ihre Timeline ist recht konstant.
Effekt k Hintergrund → σk klein
• Vordergrundobjekte kommen öfter vor, als Hintergrundobjekte
Effekt k Hintergrund → π k groß
π k2 / || σk ||2 groß → Effekt k Hintergrund.
Kapitel 16 “3D Video” – p. 49Exkurs: Background Modeling – GMM (5)
• Sei T der Anteil an Hintergrund im Video (vom User gesetzt). Definiere
b
B : arg min( k T )
k 1
dann sind die ersten B Effekte (absteigend sortiert nach π k2 / || σk ||2)
Hintergrund
• Die B 3-Tupel (μk, σk, π k) dieser Effekte bilden das Hintergrundmodell für
jedes Pixel . Aus diesen μk kann man Hintergrundbilder generieren z.B.,
indem man die μk des wahrscheinlichsten Hintergrundeffektes zeichnet:
Kapitel 16 “3D Video” – p. 50Exkurs: Background Modeling – GMM (6)
Vorteile GMM:
• schnell
geeignet für embedded systems
• geringer Speicherverbrauch
• leicht zu implementieren
• kann sich an variierende Beleuchtung anpassen
• gut geeignet für Bewegungserkennung (Überwachungskameras, etc.)
Nachteile GMM:
• nicht geeignet für kurze Sequenzen (benötigt Initialisierung und Lernzeit)
• nicht geeignet für Sequenzen mit vielen sich schnell bewegenden
Vordergrundobjekten
• Vordergrundseparation nicht gut (siehe weiter unten)
• von mehreren Parametern abhängig
Kapitel 16 “3D Video” – p. 51Exkurs: Background Modeling – PBI (1)
Patch-based Background Initialization (PBI): Colombari et al. (2010)
Eingabe: Video mit statischer Kamera und fester Beleuchtung
Ausgabe: Hintergrundbild
Algorithmus:
• Unterteile das Video in überlappende Stapel der Größe k x k:
• Bilde mittels single linkage agglomerative clustering Cluster von Patches:
distance:
cutoff: α := 0.999999
Kapitel 16 “3D Video” – p. 52Exkurs: Background Modeling – PBI (2)
• Bilde aus den Clustern die die Cluster repräsentierenden Patches (cluster
representatives) mittels Durchschnittsbildung
Beispiel: cluster representatives
• Identifiziere die cluster representatives, die Hintergrund zeigen. Heuristik:
diejenigen, die zu den größten Clustern gehören
• Initialisiere das Hintergrundbild BG mit den background cluster
representatives
links oben: Initialisierung des
Hintergrundbildes. Andere
Bilder: Füllreihenfolge
Kapitel 16 “3D Video” – p. 53Exkurs: Background Modeling – PBI (3)
• while (Hintergrundbild hat noch Lücken)
• finde ein Patch im Hintergrundbild, dessen überlappender Nachbar noch
nicht zugewiesen wurde
• Suche aus dem entsprechenden Stapel J die Ähnlichsten unter den
cluster representatives aus:
distance:
cutoff:
• Nehme unter den verbleibenden Patches denjenigen mit den geringsten
Graph-Cut Kosten um eintretende Vordergrundobjekte auszusortieren
(Detail weggelassen)
Der Graph-Cut-Kosten-Test versucht, Fortsetzungen wie W i zu verhindern, in
denen sich im nicht-überlappender Teil Vordergrundobjekte befinden.
Kapitel 16 “3D Video” – p. 54Exkurs: Background Modeling – PBI (4)
Beispiel: Videosequenz B:
Median GMM PBI
Vorteile PBI:
• Liefert sehr gute Ergebnisse auch bei Videos mit hohem Vordergrundanteil
• Background sichtbar in nur 1 Frame kann zur Wiederherstellung genügen
(pro Patch)
Nachteile PBI:
• Beschränkt auf Videos mit fester Kamera und fixer Beleuchtung
• Rechen- und speicheraufwendig
Kapitel 16 “3D Video” – p. 55Exkurs: Foreground Extraction (1)
Eingabe: Videosequenz, Hintergrundmodell
Ausgabe: Vordergrundmaske
• Eine Vordergrundmaske M ist ein Array der Größe
(nRows x nCols x nFrames),
wobei nRows, nCols und nFrames die Anzahl der Zeilen, Spalten und
Frames der Videosequenz sind, sowie einem Wertebereich von {0,1}.
1 : Pixel (r,c) in Frame f gehört zum Vordergrund
M(r,c,f) = 0 : Pixel (r,c) in Frame f gehört zum Hintergrund
• Beispiel:
Frame Maske
Kapitel 16 “3D Video” – p. 56Exkurs: Foreground Extraction (2)
Naive Methode: Thresholding
Hintergrundmodell: Hintergrundbild BG
Algorithmus:
• foreach (Pixel (r,c) in Frame f)
• Falls d(I(r,c), BG(r,c)) < T
• M(r,c,f) = 1,
• sonst
• M(r,c,f) = 0
• d(·,·): meist euklidische Distanz.
• Vorteile: Sehr schnell, sehr wenig Speicherbedarf
• Nachteile: Masken weisen starkes Rauschen auf. Parameter T muss gesetzt
werden
Kapitel 16 “3D Video” – p. 57Exkurs: Foreground Extraction (3)
Weitere Methode: Gaussian Mixture Model
Hintergrundmodell: Für jedes Pixel X: K 3-Tupel (μk, σk, wk), k=1..K
Algorithmus:
• foreach (Pixel (r,c) in Frame t)
• Die ersten B Effekte mit sind Hintergrund-
Effekte.
• Prüfe, ob (r,c) zu einem der anderen K-B Effekte passt:
• Falls
falsch für alle Hintergrundeffekte: M(r,c,t) = 1
• sonst M(r,c,t) = 0
Vorteile: Schnell und nicht speicherintensiv, adaptives Hintergrundmodell
Nachteile: Maske durch Rauschen gestört. Morphologische Operationen
können das verbessern
Kapitel 16 “3D Video” – p. 58Exkurs: Foreground Extraction (4)
Beispiel: Foreground Extraction mit GMM:
Originalframe
Ohne Morphologie Mit Morphologie: drei mal majority, siehe MATLAB-
Befehl bwmorph
Kapitel 16 “3D Video” – p. 59Exkurs: Foreground Extraction (5)
Weitere Methode: Graph Cuts (global Optimization)
Idee: Formulieren von gewünschten Eigenschaften einer Maske:
Je höher die Wahrscheinlichkeit ist, dass (r,c) zum Vordergrund gehört, desto
höher soll die Wahrscheinlichkeit für M(r,c,t) = 1 sein
Der durchschnittliche lokale Kontrast sollte gering sein
gute Maske weniger gute Maske
Auch ohne das Motiv zu kennen, würde man sich für die linke Maske entscheiden
Kapitel 16 “3D Video” – p. 60Exkurs: Foreground Extraction (6)
• Wir erreichen die gewünschten Eigenschaften mithilfe der folgenden
Energiefunktion (für ein Bild mit den Ausdehnungen M x N):
lp ist das Label von Pixel p (0 oder 1)
• Die Energiefunktion weist jeder Maske einen Wert zu. Sie bestraft Masken,
die nicht unseren Anforderungen entsprechen mit einem hohen
Energiewert.
• E1 realisiert die erste gewünschte Eigenschaft, E2 die zweite.
Minimierung der Funktion führt zu der Maske, die unsere Anforderungen
optimal erfüllt
Kapitel 16 “3D Video” – p. 61Exkurs: Foreground Extraction (7)
Herleitung E1 2
T I p BGp
Definiere: PBG ( p) : e , PFG ( p) : 1 PBG ( p) T = 5..20
• PFG(p) korrespondiert mit der Wahrscheinlichkeit, dass Ip Vordergrund ist
• Für einen Hintergrundpixel p gilt:
• Analog gilt für einen Vordergrundpixel: τp > 0
Je wahrscheinlicher p Vordergrundpixel ist, desto größer wird τp
• Definiere nun E1:
Kapitel 16 “3D Video” – p. 62Exkurs: Foreground Extraction (8)
Herleitung E2
Definiere:
• Falls Pixel p und q benachbart sind und lp ≠ lq:
• E2(lp, lq) = 1
• sonst
• E2(lp, lq) = 0
E2 bestraft also Masken, die viele 0-1 Übergänge, also einen hohen lokalen
Kontrast besitzen
Der Parameter λ gewichtet den Einfluss zwischen E1 und E2. Er ist der
einzige, der vom User gesetzt werden muss. Er ist intuitiver zu regeln, als T
beim Thresholding: Ein größerer Wert von λ bevorzugt Masken mit wenig
lokalem Kontrast, wirkt also rauschvermindernd.
Direkte (= brute force) Minimierung der Energiefunktion ist sehr aufwendig.
Für ein Bild der Auflösung 640 x 480 beträgt die Suchraumgröße ≈ 2300000.
Kapitel 16 “3D Video” – p. 63Exkurs: Foreground Extraction (9)
Effiziente Minimierung der Energiefunktion:
Repräsentation des Problems mittels eines Graphen V (flow network):
• Pro Pixel ein Knoten
• Zusätzlich zwei Knoten (source s, sink t)
• foreach (Knoten p)
• Füge Kante (s, p) mit Gewicht E1(0) hinzu
• Füge Kante (p, t) mit Gewicht E1(1) hinzu
• foreach (Kante(p, q))
• Füge eine ungerichtete Kante mit
Gewicht λ hinzu, falls p und q Nachbarn
Jede Maske M entspricht einem Schnitt im
Graphen. E(M) entspricht den Kosten des
Schnitts
Beispielgraph
Minimierung der Funktion entspricht dem
Finden eines minimalen Schnitts (minimum cut) im Graphen
Kapitel 16 “3D Video” – p. 64Exkurs: Foreground Extraction (10)
Beispiel:
Kosten des Cuts: 9 + 7 + 9 = 25. Minimal?
Kapitel 16 “3D Video” – p. 65Exkurs: Foreground Extraction (11)
Veranschaulichung:
Masken:
Kanten von s: niedriges Gewicht, falls
vi eher Hintergrund
Hintergrundkanten
zugehöriger Cut:
Vordergrundkanten
Kanten nach t: niedriges Gewicht, falls
vi eher Vordergrund
Zur Übersichtlichkeit wurden einige Kanten weggelassen. Die rechte Maske
verursacht höhere Kosten als die linke. Die t-Kanten von v1 – v5 wurden
durchschnitten, die s-Kanten nicht, die s-Kanten haben also eher ein
höheres Gewicht, als die t-Kanten. v1 – v5 gehören damit zum Vordergrund.
Kapitel 16 “3D Video” – p. 66Exkurs: Foreground Extraction (12)
Finden eines Minimum Cuts (Algorithmusskizze):
• Theorem von Ford & Fulkerson:
Kosten(minimum cut) = Kosten(maximum flow)
• Interpretiere Graphen als Rohrsystem, die Kapazitäten sind
Durchlaufmengen. Wie viel Wasser kann maximal von source bis sink durch
das Rohrsystem transportiert werden (maximum flow)?
• Ein Flow ist eine Belegung jedes Rohres mit einer Wassermenge. Die
Kosten des maximalen Flows sind gleich der Summe der von der source
ausgehenden Flows
• augmentierender Pfad: Pfad von source zu sink, an dem der Flow an jeder
Kante kleiner ist, als die Kapazität der Kante
• Algorithmusskizze:
• while (es gibt noch einen augmentierenden Pfad)
• füge die Restkapazität der kleinsten Engstelle zum Flow des Pfades
hinzu
• Der gesuchte Cut entspricht den Kanten, an denen Flow = Kapazität gilt.
Kapitel 16 “3D Video” – p. 67Exkurs: Foreground Extraction (13)
Laufzeit (für Bilder der Dimension M x N):
• Brute-Force: O(2MN)
• Der Basisalgorithmus (Edmond-Karp): O(k(MN)3), k klein
• Verbesserte Algorithmen (Goldberg): O(k(MN)2 * log(MN)), k klein
• Ausführungszeit: Für einen VGA-Frame: unter 1 Sekunde
Vorteile: Generiert sehr gute Masken. Nur von einem intuitiv wählbaren
Parameter abhängig
Nachteile: Rechenkomplexität
Kapitel 16 “3D Video” – p. 68Exkurs: Foreground Extraction (14)
Ergebnisse:
Beispielsequenz: Jemand wedelt mit einem Ast vor der Kamera herum.
1. Reihe: Originalframes. 2. Reihe: GMM + Morphologie. 3. Reihe: Graph Cut.
GMM produziert trotz Morphologie viele Artefakte. Der Vordergrund kommt so häufig vor, dass das GMM ihn in sein
Hintergrundmodell aufnimmt: Im zweiten Frame werden große Teile des Vordergrundes nicht erkannt.
Graph Cuts produzieren sehr gute Masken
Kapitel 16 “3D Video” – p. 693D System
3D scene Capturing
Transmission
2D scene 2D-3D conversion 3D Representation
CGI Rendering
Content Generation
Left eye channel
Separate transmission
Renderer Display User
to user„s eyes
Right eye channel
Kapitel 16 “3D Video” – p. 703D Kameras (1)
• Mittlerweile gibt es unterschiedlichste Formen von 3D Kameras, die den
ganzen Bereich von Consumer bis Profi abdecken:
Consumer Geräte:
Panasonic Camcorder (21k$): Beamsplitter Rig zum Einbau von zwei Kameras
Kapitel 16 “3D Video” – p. 713D Kameras (2)
• Alternative Kameras: Direkte Tiefenmessung, z.B. Time of Flight
Kameras, Laser Scanner, etc.
PMD CamCube mit 204 × 204 Pixel
3D Laser Scanner
Microsoft Kinect für Xbox 360:
VGA Kamera + 4fach Mikrofonarray +
Infrarotsensor mit VGA und 30Hz
Kapitel 16 “3D Video” – p. 723D Kameras (3)
• Roh-Datenmaterial von 3D-Scannern bedarf oft Nachbearbeitung:
Kapitel 16 “3D Video” – p. 732D-3D Konvertierung (1)
• 2D-3D Konvertierung: Aus 2D Bildern Informationen über das 3D Model
ableiten und daraus zusätzliche Views generieren
• Der menschliche Sehapparat ist in der Lage, auch aus 2D-Bildern räumliche
Informationen abzuleiten. Er bedient sich sog. 2D depth cues.
• Verfahren, die diese depth cues ausnutzen, um Tiefeninformationen aus 2D
Bildern/Szenen zu gewinnen sind:
• Shape from Motion
• Shape from Texture
• Shape from Shading
• Shape from Focus
• Shape from Perspective
• Shape from Structured Light
• Shape from Stereo
• Es gibt kein Verfahren, dass auf beliebiges 2D-Material angewandt
hochwertiges 3D erzeugen kann
• Zu einigen dieser Verfahren: Siehe Kapitel „Range Images“
Kapitel 16 “3D Video” – p. 742D-3D Konvertierung (2)
Beispiele für 2D-3D konvertierte Kinofilme
• G-Force (2009)
• Kampf der Titanen (2010)
• Alice im Wunderland (2010)
• TRON Legacy (2010) (echtes 3D)
• Fluch der Karibik 4 (2011) (echtes 3D)
• Harry Potter 7.1 (2010): Geplant, aber in letzter Sekunde abgesagt
• Harry Potter 7.2 (Juli 2011)
Workflow:
• Freistellen der Objekte der Szene
Depthmap Generation
• Festlegung der Tiefe der Objekte
• Erstellung eines 3D Models von Vordergrundobjekten (Verhindert den
„Cardboard effect“, siehe weiter unten
• Disocclusion Handling
Kapitel 16 “3D Video” – p. 752D-3D Konvertierung (3)
Probleme:
• Exaktes Freistellen extrem aufwendig (Problemstellen sind detaillierte
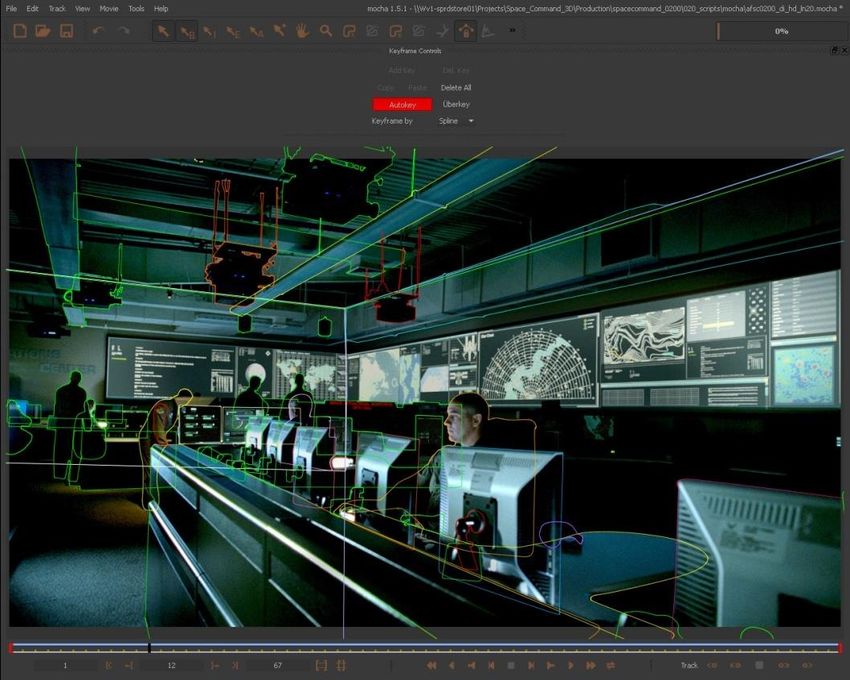
Objekte, wie z.B. Haare, Pflanzen, etc. sowie transparente Objekte). Es gibt
Softwaretools (z.B. mocha), eine Segmentation über mehrere Frames
tracken können (Rotoscoping). Freistellen hauptsächlich Handarbeit.
Beispielszene mit Freistellung (Quelle: InThree)
Kapitel 16 “3D Video” – p. 762D-3D Konvertierung (4)
Probleme (Forts.)
• Disocclusion Handling aufwendig, wenn Konvertierung erst nach der
Produktion stattfindet (keine Hintergründe vorhanden). Zum größten Teil
ebenfalls Handarbeit.
Aufwand
• Die Konvertierung eines 2h-Films beschäftigt 300-400 Menschen 4-6
Monate
• Kosten: 100k$ pro Minute
Negativbeispiel: Kampf der Titanen (2010)
• Komplett als 2D Film geplant. Konvertierung aus kommerziellen
Erwägungen
• Umwandlungszeit: 7 Wochen
• Resultat: Wenige Tiefenebenen (oft nur 2 oder 3). Grobes Freistellen und
Disocclusion Handling, dass an Depthmap-Weichzeichen erinnert.
• Bekam sehr schlechte Kritiken für die 3D Umsetzung
Kapitel 16 “3D Video” – p. 772D-3D Konvertierung (5)
Eine Methode zur halbautomatischen Generierung von Depthmaps
(Rothaus et al. 2008)
Eingabe:
• Videosequenz (statische Kamera + Beleuchtung):
•
• Depthmap des Hintergrundes:
Kapitel 16 “3D Video” – p. 782D-3D Konvertierung (6)
Ausgabe: Depthstream:
Algorithmus:
• Generation des Hintergrundbildes (Background Modeling)
• Generation der Vordergrundmaske (Foreground Extraction)
Generierter Hintergrund Ein Frame der Vordergrundmaske
Kapitel 16 “3D Video” – p. 792D-3D Konvertierung (7)
• foreach (Frame)
• Initialisiere depth frame Df mit Hintergrunddepthmap
• Suche zusammenhängende Gebiete (Blobs) → Vordergrundobjekte
• foreach (Vordergrundobjekt)
• Berechne Bounding Box
• Berechne durchschnittlichen Tiefenwert z der Unterkante der
Bounding Box
• Füge Vordergrundobjekt mit einheitlichem Tiefenwert z in Df ein
Vordergrundobjekt mit Bounding Box Der Tiefenwert eines Vordergrundobjektes
richtet sich nach der Tiefe seines
Fußpunktes
Kapitel 16 “3D Video” – p. 80Zukünftige Entwicklungen (1)
Ausblick:
Kommende 3D-Filme:
2011: 32 Filme
2012: 39 Filme
• Titanic (06.04.2012)
• Hobbit 1/2 (2012/2013)
• Avatar 2/3 (2014/2015)
• Star Wars Episoden 1-6 (2012-2017)
+ 59 weitere (Quelle: MarketSaw)
Zukünftige Konzepte:
• Lightfield Rendering
- Plenoptische Kamera
- Integral Imaging
• Holografie
Kapitel 16 “3D Video” – p. 81Zukünftige Entwicklungen (2)
Lightfield Rendering:
• Das light field ist eine Funktion, die die Ausbreitung des Lichtes im
kompletten Raum beschreibt (als Strahlen).
• Kennt man diese Funktion, kann man beliebige Ansichten der Szene
berechnen.
• Integral Imaging:
• Display Technologie, um das light field zu reproduzieren
• Herausforderung: Extrem hohe Auflösungen nötig
• Plenoptic camera
Anwendung:
• Kamera Technologie, um das Refokussieren
nach der Aufnahme
light field zu sampeln
• Stanford University, 2005:
Auflösung 90kpixel aus
16Mpixel-Sensor
Kapitel 16 “3D Video” – p. 82Zukünftige Entwicklungen (3)
Holografie:
• Ein Hologramm speichert statt Intensität und Frequenz
Intensität und Phaseninformation einer Szene, welche
bei normaler Fotografie verloren geht.
• Methode: Ein Objekt wird mit kohärentem Licht bestrahlt
(Referenzwelle). Die vom Objekt reflektierte
Referenzwelle (Objektwelle) wird mit der Referenzwelle
überlagert, so dass beide interferieren. Das
entstehende Interferenzmuster wird auf Film
aufgezeichnet. Dazu muss dieser ein sehr hohes
Auflösungsvermögen besitzen. Um das Hologramm zu
rekonstruieren, wird das Interferenzmuster auf dem Film Zwei Fotografien desselben
wieder mit der Referenzwelle beleuchtet. Durch Hologramms.
Beugung am Interferenzmuster entsteht die Original-
Wellenfront der Objektwelle.
Kapitel 16 “3D Video” – p. 83Zukünftige Entwicklungen (4)
• Mit einem Hologramm kann man die Wellenfront der Objektwelle
rekonstruieren, also exakt das Licht, das von einem Objekt bei der
Aufnahme reflektiert wurde.
• Denkbeispiel: Eine Person, die vor uns steht, sehen wir nicht direkt,
sondern nur das Licht, das von ihr ausgeht (reflektiert wird). Wenn man
dieses Licht exakt reproduzieren kann, ist es für einen Beobachter nicht
mehr zu entscheiden, ob er die Szene direkt sieht oder nur eine
Reproduktion.
• Holografie löst die wahrnehmungsphysiologische Nachteile aktueller 3D
Technologie (inklusive Accomodation – Vergence Konflikt).
• Holografischer Film: 20 fach höhere Auflösung als CCD Kameras, sehr
lange Belichtungsdauer.
• Holografische Displays: Schätzungen, wann diese Technologie verfügbar
sein wird schwanken zwischen 5 und 100 Jahren.
Kapitel 16 “3D Video” – p. 84Sie können auch lesen