Machine Learning im Maschinen- und Anlagenbau - Quick Guide Software und Digitalisierung - VDMA
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

Software und Digitalisierung Quick Guide Machine Learning im Maschinen- und Anlagenbau
Software und Digitalisierung
Quick Guide
Machine Learning im
Maschinen- und Anlagenbau
© 2018
VDMA Software und Digitalisierung
Lyoner Straße 18
60528 Frankfurt am Main
sud.vdma.org
Alle Rechte vorbehalten, insbesondere das Recht der Vervielfältigung und Verbreitung sowie der Über-
setzung. Kein Teil des Werkes darf in irgendeiner Form (Druck, Fotokopie, Mikrofilm oder
anderes Verfahren) ohne schriftliche Genehmigung des VDMA reproduziert oder unter Verwendung
elektronischer Systeme gespeichert, verarbeitet, vervielfältigt oder verbreitet werden.
2 INHALT
Inhalt
Vorwort 3
1. Was ist Machine Learning? 4
2. Nutzen, Chancen und Risiken im Maschinenbau 8
3. Anwendungsfälle im Maschinen- und Anlagenbau 10
4. Daten als Rohstoff 15
5. Datengetriebene Modellierung 17
6. Technische Umsetzung der Anwendungsfälle 20
7. Build or Buy 23
8. Voraussetzungen 27
9. Ausblick 29
10. Mitarbeitende im Arbeitskreis 30
11. Quellen und Verweise 32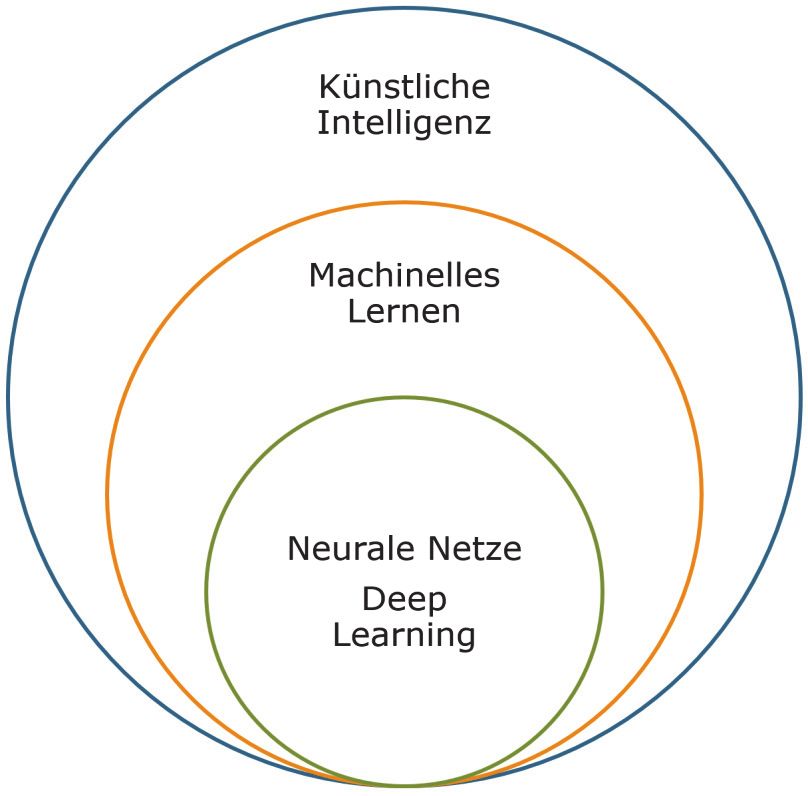
VORWORT 3
Vorwort
Die Innovationstreiber im Maschinenbau Machine Learning sorgt dafür, dass Software
und Informatik immer stärker zum maßgebli-
Das Thema Machine Learning oder auch chen Innovationstreiber im Maschinenbau
künstliche Intelligenz ist aktuell in aller Munde. werden.
Die Technologie und deren Tools werden ständig
weiterentwickelt und springen aus der Konsu- Nachfolgender Guick Guide wurde vom Exper-
merwelt kommend nun über in den industriellen tenkreis Machine Learning des Fachverbandes
Sektor und damit auch in den Maschinen- und Software und Digitalisierung verfasst und rich-
Anlagenbau. tet sich vor allem an das Management von
Maschinebauunternehmen, die sich mit dem
Viele Jahre oder sogar Jahrzehnte war diese Dis- Gedanken tragen das Thema „Machine
ziplin nur Akademikern zugänglich und hat sich Learning“ für ihr Unternehmen zu beleuchten
in einigen wenigen Bereichen etabliert. Die sin- und zu bewerten. Er gibt Hinweise zu den Chan-
kenden Preise für Rechenleistung und Speicher cen, Herausforderungen und mögliche Lösun-
sorgten in den letzten zehn Jahren für rasante gen. Vor allem aber soll dieser Quick Guide
Entwicklung von Cloud- und Big Data-Technolo- helfen sich dem Thema mit den richtigen Fragen
gien. Diese zwei Faktoren führten schnell zur zu nähern und daraus die eigenen Schlüsse zie-
Entwicklung von verschiedenen Software-Tech- hen zu können. Aufgrund des dynamischen Um-
nologien, die den Bereich Künstliche Intelligenz feldes wird dieser Quick Guide die Thematik
nicht unberührt ließen. nicht erschöpfend und allumfassend behandeln
können. Die Mitarbeiter des Expertenkreises ste-
Machine Learning (deutsch: maschinelles hen für das Thema Machine Learning im VDMA
Lernen) ist ein wichtiger Bereich der Computer- zur Verfügung und werden diese anspruchsvolle
wissenschaft und Bestandteil künstlicher Materie weiterhin begleiten.
Intelligenz. Computerprogramme, die auf
Machine Learning basieren, können mit Hilfe
von Algorithmen eigenständig Lösungen für
neue und unbekannte Probleme finden. Das Prof. Claus Oetter
künstliche System „erkennt Muster“ und Gesetz- Stellv. Geschäftsführer
mäßigkeiten in den Lerndaten, die es zugespielt
bekommt. Tools, die bereits auf dem Markt etab- VDMA
liert sind, helfen dabei, die Algorithmen zu fin- Software und Digitalisierung
den. Neue Frameworks und Plattformen unter-
stützen die breite Anwendung dieser bisher eher
„akademischen“ Themen im Projektalltag.
Gerade für den Maschinenbau bringt diese
Technologie viele neue und spannende Ansätze.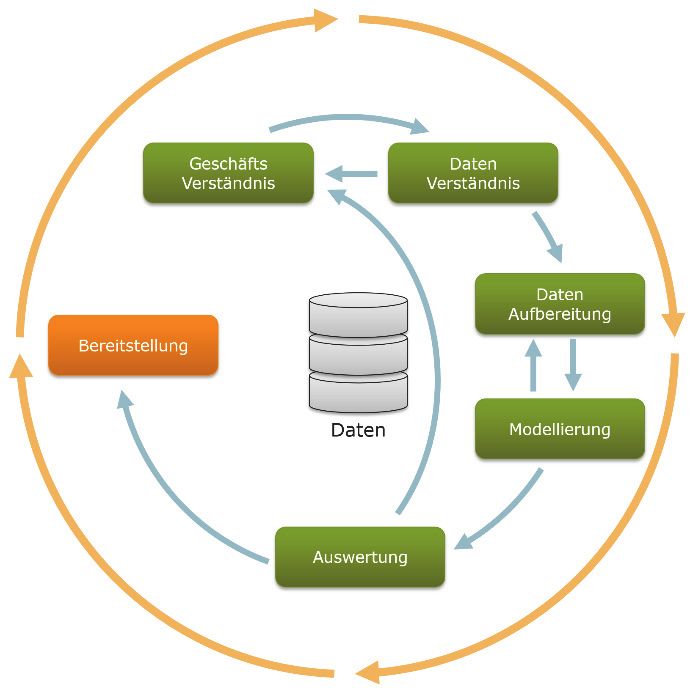
4 QUICK GUIDE „MACHINE LEARNING“
1. Was ist Machine Learning?
Die Themen „Machine Learning“ (ML) und Algorithmen, die aus Daten lernen und Vorher-
„Künstliche Intelligenz“ (KI) sind omnipräsent — sagen treffen, welche mit einer gewissen Wahr-
in den Medien, in Unternehmen und auch im scheinlichkeit eintreten. Solche Algorithmen
privaten Bereich. Denn die Digitalisierung verän- folgen keinen starren, von Menschen definierten
dert alle gesellschaftlichen Bereiche dramatisch, Programm- und Regelvorgaben — sie treffen viel-
so auch die produzierende Wirtschaft. Insbeson- mehr datengestützte Vorhersagen, indem sie
dere der deutsche Maschinenbau wird sich den auf Basis von Beispielen Wissen generieren —
also lernen.
Herausforderungen stellen müssen, wenn er
seine in vielen Bereichen international beste- Bereits 1959 definierte der US-amerikanische
hende Produktführerschaft behalten und aus- Informatiker und Computerpionier Arthur
bauen will. Samuel ML als ein Studiengebiet, welches
„Computern die Fähigkeit gibt zu lernen, ohne
Doch was ist ML? Im wahrsten Sinne des Wortes dazu vorher explizit programmiert worden zu
bedeutet es maschinelles Lernen. Maschinen, im sein“. Es kommt, wie das Data Mining, aus der
Sinne von Computern, erhalten die Fähigkeit, Statistik. Die Unterschiede: Die Statistik defi-
selbstständig zu lernen. ML befasst sich mit niert, was passiert ist; das Data Mining erklärt,
warum etwas geschehen ist; das ML bestimmt,
was passieren wird und gibt vor, wie bestimmte
Situationen optimiert oder vermieden werden
Künstliche können.
Intelligenz
ML ist eine eigenständige Disziplin, die häufig
mit KI (Künstliche Intelligenz) verwechselt wird;
Maschinelles der Begriff KI stammt aus dem Jahre 1956 und
Lernen
ist damit nur geringfügig älter. Er bezeichnet
den Versuch, eine menschenähnliche Intelligenz
nachzubilden. Das ML kann auf diesem Weg ein
erster, erfolgreicher Schritt sein, weshalb ML
gerne als Teilbereich der KI verstanden wird.
Neuronale Netze
Deep Doch nicht nur die Ziele dieser beiden Diszipli-
Learning nen sind von unterschiedlicher Größe — es gibt
einen weitaus wichtigeren Unterschied: ML ist
schon da, ist bereits unter uns; wann wir das von
der Künstlichen Intelligenz behaupten können,
steht dagegen in den Sternen.
Abbildung 1:
Abgrenzung KI — ML — NN — DL (Quelle: Softing GmbH)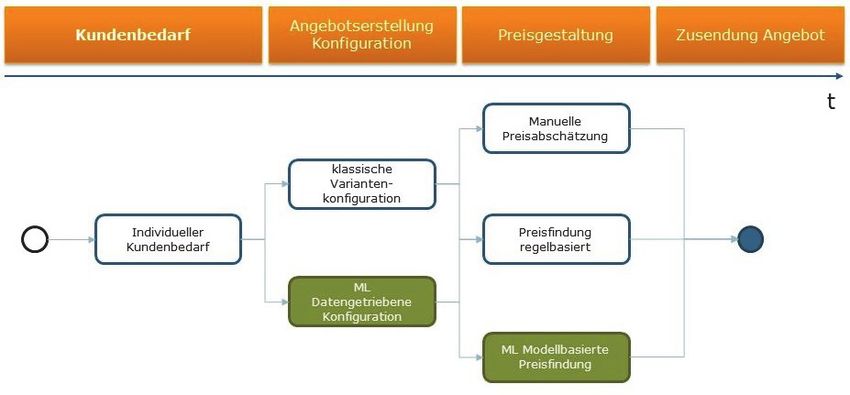
QUICK GUIDE „MACHINE LEARNING“ 5
Ein weiterer Begriff wird häufig im Zusammen- So wird das Thema an die IT oder die Produkt-
hang mit Machine Learning aufgeführt, aber entwicklung weitergegeben — wie so oft bei
meist missverständlich verwendet: „Big Data“. innovativen Technologien. Dadurch reduziert
Big Data steht für das Verarbeiten von großen, sich der Fokus häufig auf die Technik, die be-
heterogenen Datenmengen, deren Geschwin- triebswirtschaftlichen Mehrwerte verlieren an
digkeiten und Datentypen — mit oder ohne ML. Bedeutung.
Wir befassen uns in diesem Dokument nicht mit ML wird bereits eingesetzt, um kritische Ent-
KI oder Big Data, wir konzentrieren uns auf das scheidungen in der medizinischen Diagnostik,
Fachgebiet des ML. auf den Finanzmärkten oder in der Energiewirt-
schaft zu unterstützen oder gar automatisch zu
Welche Rolle kann ML für den Maschinenbau in treffen. Auch unser Alltag wird durch ML ge-
der Produktführerschaft spielen? Behalt und prägt; denken wir nur an all die Produktemp-
Ausbau in vielen Bereichen vorausgesetzt. fehlung, die uns täglich erreichen. Sie basieren
auf unseren vorigen Einkäufen, auf unserem
Die Möglichkeiten sind vielfältig, und ein Groß- Suchverhalten und den Begriffen, die wir in die
teil der Anwendungen ist heute noch nicht Tastatur unserer Endgeräte eingeben. Zuneh-
absehbar. Dennoch gibt es bereits heute viele mend findet ML aber auch Einzug in den Maschi-
naheliegende praktische Anwendungsgebiete nen- und Anlagenbau und ermöglicht dort neue
und Lösungen. Sie ermöglichen den Unterneh- Anwendungsfälle, auf die wir in Kapitel 3 einge-
men im Maschinenbau einerseits einen schnel- hen werden.
len Einstieg, andererseits aber auch einen weite-
ren Ausbau beim Thema ML. Ansätze dafür lie- Warum gewinnt das Thema ML gerade jetzt und
gen sowohl in der Optimierung der Prozesse als in diesem Maße an Bedeutung? Die Antwort ist
auch im Erhalt und in der Erweiterung der Pro- so einfach wie komplex: Was gestern noch nicht
duktinnovationsführerschaft. möglich war, ist heute Alltag. Hohe Rechenleis-
tung — in diesem Maß vor zehn Jahren noch au-
Einige Kernthemen sorgen dabei für eine ßerhalb unseres Vorstellungsvermögens — ist zu
gewisse Verunsicherung: Dazu zählt das erfor- einem bezahlbaren Gut geworden. Kombiniert
derliche Wissen, wie die relevanten Algorithmen man diese Rechenleistung mit großen Daten-
ausgewählt, entwickelt und konfiguriert mengen mit Lernpotenzial, lassen sich Algorith-
werden, wie die Daten beschafft und bereitge- men kontinuierlich weiterentwickeln. All das
stellt werden und nicht zuletzt die zwingend sind weitere wichtige Faktoren des rasanten
notwendige Erfahrung mit diesen Faktoren. Fortschritts.
Auch unklare rechtliche Aspekte und Implikatio-
nen halten Unternehmen davon ab, in diesen Dieser Quick Guide richtet sich an Entscheider,
Bereich geschäftsrelevant zu investieren. Vielen die mehr über ML erfahren möchten. Zuerst wird
Maschinenbauern fällt es schon schwer, ein erklärt, was wir unter ML verstehen und welche
fachliches Anwendungsfeld oder ein Projekt zu Chancen und Risiken die Technologie für den
erkunden und zu definieren. Maschinenbau mit sich bringt. Anschließend
werden einige typische Anwendungsfälle vorge-
stellt.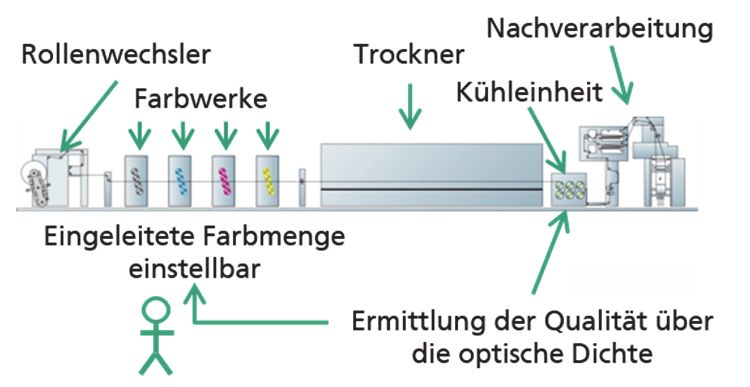
6 QUICK GUIDE „MACHINE LEARNING“
Wir erläutern die Bedeutung der Daten für ML, Dazu Aber wie funktioniert das Lernen aus
beschreiben die grundlegende Vorgehensweise Daten und das Anwenden des Gelernten konk-
bei ML-Projekten und erklären, wie der Einstieg ret? Dazu klären wir vorab einige Begriffe. Ein
in das Thema gelingt. Ein Ausblick auf die künf- Grundbegriff beim Lernen ist das Modell. Das
tige Entwicklung rundet den Guide ab. Modell enthält das gelernte Wissen und wird
verwendet, um Vorhersagen zu treffen. Modelle
1.1 Lernen aus Daten sind in der Regel nur für eine Aufgabe ausgelegt.
Beispiel: Anhand von Sensordaten (Eingabe)
ML ermöglicht technischen Systemen, was wird die Wahrscheinlichkeit einer Störung vor-
bisher natürlichen Lebewesen vorbehalten war: hergesagt (Ausgabe). Ein weiterer wichtiger
Aus Erfahrungen lernen! ML-Algorithmen erler- Begriff ist das Modell-Training. Beim Modell-
nen dazu Muster und Strukturen in Beispielda- Training wird das Modell mit Daten angelernt.
ten, die von Menschen bereitgestellt werden. Üblicherweise werden Modelle einmal trainiert
Dieses neue Wissen wenden sie im Anschluss und anschließend für Vorhersagen verwendet.
auf neue, unbekannte Fälle an. So lernen ML- ML-Algorithmen lassen sich nach der Art unter-
Algorithmen zum Beispiel anhand einer Vielzahl schieden, wie sie aus Daten lernen bzw. wie das
von Musterbildern, wie ein Gut-Teil auf einem Modell trainiert wird. Man unterscheidet dabei
Kamerabild aussieht. Diese selbst vorgegebenen in drei Kategorien:
Darstellungsvarianten wendet das System in der
Folge an, um Schlecht-Teile zu erkennen und überwachtes Lernen (supervised learning)
auszusortieren. Die Maschine lernt auf diese unüberwachtes Lernen
Weise, schlecht von gut zu unterscheiden. (unsupervised learning)
bestärkendes Lernen
(reinforcement learning)
Klassifizierung
Überwachtes
Lernen
Regression
Maschinelles Bestärkendes
Belohnungsprinzipien
Lernen Lernen
Zugehörigkeitsbildung
Unüberwachtes
Lernen
Kategorisierung
Abbildung 2: ML-Typen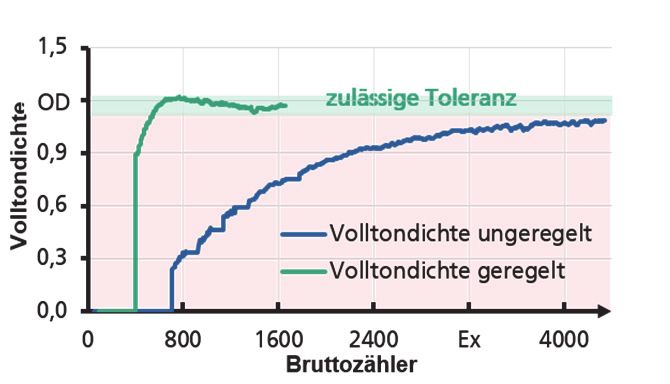
QUICK GUIDE „MACHINE LEARNING“ 7
1.2 Überwachtes Lernen Bei einer anderen Herangehensweise an das
unüberwachte Lernen werden die Daten auto-
Beim überwachten Lernen wird das Modell mit matisch in Gruppen eingeteilt. Solche Gruppen
Beispielen aus Eingabewerten und Ausgabewer- können zum Beispiel sein: „Maschine produ-
ten trainiert. Für das Beispiel Störungsanalyse ziert“, „Maschine in Störung“, „Maschine in
würde man beispielhafte Sensordaten zusam- Stillstand“.
men mit Information über anstehende Störun-
gen in das System einspeisen. Das Modell lernt Der Vorteil des unüberwachten Lernens: Die
dann den Zusammenhang zwischen Sensorda- Beispieldaten lassen sich mit wenig Aufwand
ten und Störung. Man nennt diesen Lernvorgang erstellen. Der Nachteil: Einige Anwendungsfälle
überwacht, da für jede Eingabe die richtige Aus- deckt das unüberwachte Lernen nicht ab.
gabe bekannt ist und man das Modell bei
falschen Vorhersagen korrigieren kann. 1.4 Bestärkendes Lernen
Um das Modell trainieren zu können ist eine Beim bestärkenden Lernen werden Modelle
große Menge an beispielhaften Ein- und Ausga- durch Belohnung und Bestrafung trainiert. Jede
bedaten erforderlich. Diese Beispieldaten zu Lösung oder jeder Teilschritt einer Lösung wird
erstellen kann sehr teuer oder schwierig sein, da dabei typischerweise mit einer Punktzahl bewer-
meist Expertenwissen gelernt werden soll. Wich- tet. Belohnung wird durch den Anstieg der
tig ist auch die Qualität der Beispieldaten. Wird Punktzahl ausgedrückt, Bestrafung durch deren
das Modell mit falschen Beispieldaten gefüttert, Verringerung. Das Ziel ist die maximal mögliche
lernt es auch fehlerhafte Zusammenhänge. Punktzahl. Während des
1.3 Unüberwachtes Lernen Trainings werden durch Versuch und Irrtum
immer neue Lösungsvorschläge erzeugt und
Beim unüberwachten Lernen lernt das System zunehmend verfeinert, um die Punktzahl stetig
ebenfalls aus Beispieldaten; allerdings enthalten zu verbessern. Die Herausforderungen beim
die Beispieldaten keine bekannten Ausgabeda- bestärkenden Lernen: Es müssen geeignete
ten. Stattdessen wird anhand der Beispiele Belohnungsmechanismus gefunden werden.
gelernt, wie „typische“ Daten oder Datengrup- Kurzfristige Vorteile der Lösungen sind gegen
pen aussehen. Beim Beispiel der Sensordaten langfristige abzuwägen. Man nennt diese Form
würde das Modell lernen, wie typische Sensorda- des Lernens bestärkend, da sie an das menschli-
ten der Maschine aussehen. Bei Abweichungen che Lernen durch Lob und Tadel erinnert.
von diesen Daten würde es auf Fehlerzustände
schließen.
8 QUICK GUIDE „MACHINE LEARNING“
2. Nutzen, Chancen und Risiken im Maschinenbau
In vielen Maschinenbauunternehmen ist man Die Eigenschaften lassen sich nicht immer sinn-
sich noch nicht sicher, ob ML ein geschäfts-rele- voll abgrenzen und sollten deshalb im konkreten
vantes Thema ist. Die zunehmende Anwendungsszenario definiert werden.
Austauschbarkeit einzelner Maschinen wird in
vielen Bereichen dazu führen, dass künftig nicht „0-Fehler-Qualität bei größtmöglicher
mehr nur die Maschine selbst, sondern vor allem Termintreue“
ergänzende Leistungen verkauft werden. Damit
ändert sich die Geschäftsgrundlage für den Der jeweilige betriebswirtschaftliche Nutzen
Maschinenbau gravierend. Dies erklärt, warum sollte sich in einem konkreten Szenario klar
das Thema ML im Management und in vielen beschreiben und quantifizieren lassen. Ein
Fachbereichen von Maschinenbauunternehmen Beispiel hierfür wäre ein automatisierter
höchst präsent ist. Zahlungseingang mit Rechnungsabgleich mit
einem Einsparpotenzial im zweistelligen
ML bietet dem deutschen Maschinen- und Anla- Prozent-Bereich. Ein weiterer Bereich: die Preis-
genbau ungeahnte Möglichkeiten: Bestehende anfrage zu komplexen Maschinenkonfiguratio-
Geschäfts- und Produktionsprozesse lassen sich nen.
optimieren, die Maschinen reifen in der Folge zu
intelligenten und beinahe autark arbeitenden Mit einer umfangreichen, ML-basierten Automa-
Prozessdienstleistern. Wichtige Teilaspekte tisierung würden Angebotsanfragen sehr viel
werden einer strukturierten Nutzen-Chancen- schneller beantwortet, die Zahl der Vertragsab-
Risiko-Analyse unterzogen und mittels schlüsse würde entsprechend steigen. Szenarien
Beispielen in einen betriebswirtschaftlichen dieser Art entlang der Kernprozesse eines Unter-
Kontext gesetzt. Das Ziel ist eine erste nehmens sind schon heute als Bestandteil von
Hilfestellung zur betriebswirtschaftlichen ERP, Marketing oder Vertriebssystem verfügbar
Einschätzung und Relevanz von ML für den bzw. einsetzbar.
Leser, um daraus eine eigene Herangehensweise
und Strategiedefinition ableiten zu können. „Machine Learning stärkt die Kosten- und
Produktinnovationsführerschaft“
Grundsätzlich können ML-Nutzenpotenziale im
Kontext der Produkteigenschaften sowie in der Nicht nur der Nutzen in Kerngeschäftsprozes-
Optimierung interner Prozesse angesiedelt sen, auch der ML-Nutzen als Bestandteil der
werden. Das gilt für die Zahlungseingangs- eigenen Produkte mit Blick auf die Produktfüh-
verarbeitung und Angebotserstellung ebenso rerschaft ist ein weiteres Anwendungsfeld. Hier
wie für die Produktionsplanung. lassen sich zwei Nutzenpotenziale adressieren:
Für den Kunden kann einerseits ein direkter
Auch im produktnahen Bereich unterscheiden Mehrwert beim Betreiben der Maschinen ent-
sich die ML-Eigenschaften: einerseits im Produkt stehen, andererseits können auf Basis der
selbst, beispielsweise durch Expertensysteme verfügbaren Maschinendaten Mehrwertdienste
zur Unterstützung des Maschinenbedieners, geschaffen werden.
andererseits im maschinenbezogenen Prozess-
umfeld wie Wartungs- oder zusätzliche Mehr-
wertdienste.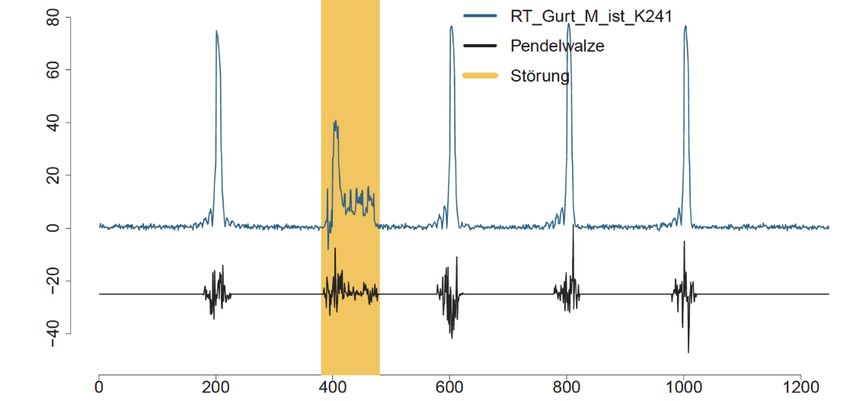
QUICK GUIDE „MACHINE LEARNING“ 9
Ein Beispiel für die Verbesserung des eigenen „Vermeidung von zu großen oder zu
Produktes mit ML ist die sogenannte voraus- komplexen Projekten beim Einstieg“
schauende Wartung (predictive maintenance).
Auf Grundlage der vielen gewonnenen Doch wie gelingt der Einstieg in dieses Themen-
Informationen lassen sich Probleme an einer feld? Studien zeigen, dass viele Unternehmen
Maschine frühzeitig erkennen und geplant die ersten Projekte zu groß und zu komplex
beheben — bevor die Produktion beim Kunden gestalten — viele relevante Aspekte werden
unerwartet und meist unpassend unterbrochen dadurch nicht erfolgreich adressiert. Folgende
werden muss. Dadurch kann der Kunde des Fragen sollten vor Projektbeginn beantwortet
Maschinenbauers die Instandhaltung planen sein: Welches Anwendungsszenario bietet sich
und effizient in die internen Abläufe integrieren. für mein Unternehmen zum Einstieg an? Wie
Wird die Sensorik für vorausschauende Wartung kann das notwendige Wissen im eigenen Unter-
in Verbindung mit Software eingesetzt, lässt nehmen sukzessive aufgebaut werden?
sich die Maschineneffizienz im Sinne eines Fein-
tunings zusätzlich optimieren. Welche ML-Techniken und Algorithmen sind für
mich relevant? Wie lassen sich
Ein weiteres ML-Feld: Die Maschinenbedienung Unternehmensrisiken durch die Ergebnisse der
wird durch Expertensysteme vereinfacht. In der ML-Algorithmen vermeiden — oder kann man
Folge reduzieren sich Einarbeitungszeit, Schu- ihnen wenigstens frühzeitig entgegensteuern?
lungsaufwand und Rüstzeiten, gleichzeitig steigt Auch die Verfügbarkeit der notwendigen Daten
die Effizienz. ML ermöglicht damit sowohl dem ist kritisch und spielt eine wichtige Rolle.
Maschinenbauer als auch dessen Kunden, ihre
Prozesse zu optimieren. Noch eine wichtige Frage ist zu klären: Wer ist
verantwortlich, wenn Menschen Entscheidun-
„Schulungs- und Maschinenrüstzeiten reduzieren“ gen an Maschinen delegieren. Wenn beispiels-
weise das Modell formal richtig ist, das Ergebnis
Zugunsten einer Differenzierung und Führer- durch das Lernen falscher oder ungeeigneter
schaft der eigenen Produkte sind weitere poten- Daten aber falsch oder negativ.
zielle Kundennutzen im Anwendungsfall detail-
liert zu evaluieren und gemeinsam mit dem Soll ein erfolgreiches ML-Projekt aufgesetzt
Kunden zu entwickeln. Für die Mehrwertdienste werden, müssen diese Fragen zuvor strukturiert
würden geeignete ML-Algorithmen nicht beim und umfassend mit Experten untersucht und
Kunden zum Einsatz kommen, sondern beim definiert werden, besonders mit Blick auf Rele-
Maschinenbauer. Auf Basis dieser Algorithmen vanz, Risiken und Investitionsbedarfe für das
könnten neue Kundenservices entwickelt eigene Unternehmen. Gleichzeitig darf man sich
werden, aber auch neue Preismodelle für die nicht vom Umfang der Themen erschlagen
Nutzung der Maschinen. Letztendlich wird ML zu lassen und dadurch den Startschuss verpassen.
einer 0-Fehler-Qualität bei größtmöglicher Wie immer gilt: Es ist wichtig, anzufangen.
Termintreue führen. Aber auch bei einer
möglichen Dokumentationspflicht kann die
gewonnene Datenlage effizient unterstützen.10 QUICK GUIDE „MACHINE LEARNING“
3. Anwendungsfälle im Maschinen- und Anlagenbau
In diesem Kapitel werden einige typische ML- Beim bildgebenden Verfahren können in Kombi-
Anwendungsfälle im Maschinenbau vorgestellt. nation mit der menschenähnlichen Bildverarbei-
Jeder Anwendungsfall wird kurz beschrieben, tung alle Arten von Sensoren eingesetzt werden:
eine mögliche Umsetzungsstrategie erläutert. 2D, 3D, Ultraschall, Röntgen und Shape from
Anschließend werden Nutzen, benötigte Fähig- Shading. Die ML-Anwendung stützt sich dabei
keiten sowie Aufwand, Chancen und auf eine Trainingsphase mit Gut-Teilen; bei
herkömmlichen Bildverarbeitungsanwendungen
Risiken aufgeführt. Auf die technische Umset- dagegen sind meist umfassende Fehlerkataloge
zung dieser Anwendungsfälle wird genauer in zu berücksichtigen. Mit ML ist somit das
Kapitel 6 eingegangen. gewünschte Ergebnis selbst das Maß, und nicht
die Abweichung davon.
3.1 Menschenähnliche Bildverarbeitung
(„Human-like Machine Vision“) Die prozesssichere Lösung für solche Aufgaben-
stellungen sind ML-basierte Bildverarbeitungs-
Oberflächen mit Texturen zu beurteilen ist eine systeme, die speziell für das industrielle Analy-
der Aufgaben, bei denen klassische Bildverarbei- sieren von Bildern entwickelt und optimiert
tungs-Systeme an ihre Grenzen stoßen. Das werden.
menschliche Auge dagegen kann Texturen,
Muster, Objekte und Strukturen erkennen und Der Einsatz solcher Systeme auf Basis von ML
bereits nach kurzer Anlernzeit zuverlässig visuell erschließt weitere Anwendungsmöglichkeiten
beurteilen und klassifizieren. Anhand von von prozesssicherer, automatisierter Inspektion
wenigen Beispielen lernt der Mensch, zulässige mit sehr hoher Erkennungsleistung. Wo
Variationen von Fehlern zu unterscheiden — klassische Vision-Systeme an ihre Grenzen
selbst bei Naturprodukten, bei denen keine zwei stoßen und die Beurteilung durch den Menschen
Teile gleich sind. trotz aller Einschränkungen und Risiken die
beste Lösung ist, bietet die „menschenähnliche
Bildverarbeitung“, basierend auf ML-
Algorithmen, aktuell eine Lösung auf dem Stand
der Technik. Weiterhin sind neue Produkte ohne
großen Aufwand lernbar, und selbst neue, unbe-
kannte Merkmale werden ohne aufwendige
Fehlerbibliotheken erkannt. Dies resultiert in
deutlich reduzierte Entwicklungs- und
Produkteinführungszeiten.
Neben der Erfahrung bei der herkömmlichen
Bildverarbeitung und der Erfahrung bei der
Auslegung optischer Kamerasysteme bedarf es
für die Modellierung keiner weiteren Software-
entwicklung und keinem Verständnis der
Algorithmen.
Filtersieb
(Metall, 2D) Kleberraupe,
(Dichtungen,
Kleberraupen, 3D)
Abbildung 3: Labor (Quelle: i-mation GmbH)QUICK GUIDE „MACHINE LEARNING“ 11
ML hat trotz aller Möglichkeiten Grenzen und ist Gleichzeitig beeinflussen weitere Parameter das
nicht in jedem Fall das Mittel der Wahl. Druckergebnis in unbekannter Form:
Verbrauchsstoffe, physikalische Einflussgrößen
Limitierende Faktoren können insbesondere und der Maschinenzustand.
sein:
Zugänglichkeit der erforderlichen
Trainingsdaten
Verfügbarkeit und Bestimmungsgrad von
Expertenfeedback bei der Ergebnisbewertung
Bildauflösung und die Größe der zu übermit-
telnden bzw. zu speichernden Dateien
Anfälligkeit gegen gezielte Manipulation oder Abbildung 4:
Sabotage des ML-Systems. Einstellprozess (Quelle: Fraunhofer IGCV)
In einigen Fällen ist auch die Kombination mit
herkömmlicher Bildverarbeitung notwendig. Um
das Potenzial von ML-Systemen gewinnbringend
einzusetzen, braucht es interdisziplinäres Know-
how, ein umfassendes Portfolio an Bildverarbei-
tungslösungen und ein sorgfältiges Abwägen
von Chancen und Risiken.
3.2 Adaptive Regelung zur Prozessoptimierung
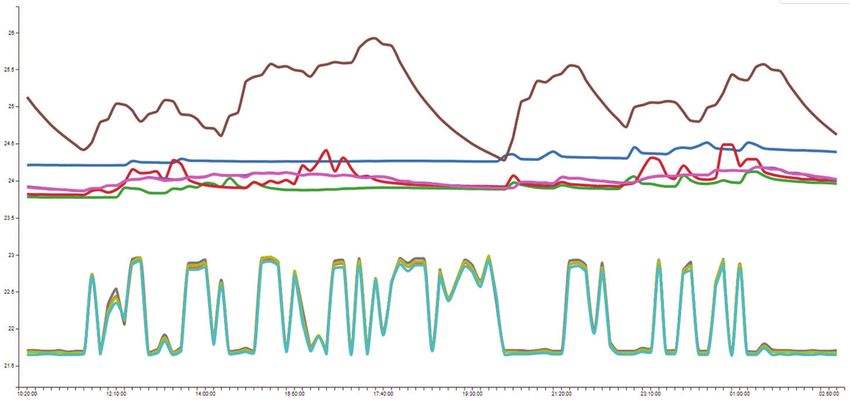
Abbildung 5:
Hochlauf (geregelt und ungeregelt)
In diesem Anwendungsfall wird das Optimieren (Quelle: Fraunhofer IGCV)
des Hochlaufs einer Rollenoffset-Druckmaschine
erläutert — stellvertretend für die Optimierung
von komplexen physikalischen Maschinenpro- Solche technischen Systeme, deren Verhalten
zessen. Der Hochlauf ist aufgrund zahlreicher von zahlreichen Größen und unbekannten
Parameter und Einflussgrößen ein komplexer Zusammenhängen beeinflusst wird, können nur
Prozess. Wichtig ist hierbei vor allem das Fein- schwer mit physikalischen Formeln modelliert
justieren der optischen Volltondichte, die vor werden — sie entziehen sich dadurch häufig der
jedem Produktionsstart manuell parametriert Prozessoptimierung. In diesem Fall können
werden muss. Wie sich das Ändern der Parame- maschinelle Lernverfahren hilfreich sein, die das
ter¬ auswirkt, kann jedoch erst nach einem voll- Systemverhalten erlernen und anschließend
ständigen Durchlauf der Druckmaschine beur- Vorhersagen über den Prozess treffen können —
teilt werden; deshalb ist dieser Vorgang mit das wäre die sogenannte adaptive Regelung.
einer Totzeit verbunden, während der möglich-
erweise Ausschussqualität produziert wird.12 QUICK GUIDE „MACHINE LEARNING“
Die Totzeit wird dabei mit einer modellbasierten Eine große Anzahl von Maschinenmodellen mit
adaptiven Regelung überbrückt. Der Zusammen- Optionen sowie Abhängigkeiten zwischen den
hang zwischen Sensordaten und der Qualität Optionen führt für Hersteller und Kunden
der Volltondichte wird aus historischen Daten schnell zu einer unübersichtlichen Vielfalt von
gelernt und als Rückführgröße in der Regelung Möglichkeiten.
genutzt. Dadurch lassen sich die Prozessparame-
ter anpassen, noch bevor Messwerte für die Diese Vielfalt in der Maschinenkonfiguration
Dichte vorliegen. Der Einsatz einer prädiktiven stellt hohe Anforderungen an die Angebotser-
Regelung steigerte die Produktivität und die Res- stellung. Bei hochkomplexen Maschinen kann
sourceneffizienz signifikant. Im Mittel konnten sich der Angebotsprozess mit Produktausprä-
der Ausschuss beim Hochfahrprozess um 37 % gung und Preisbestimmung über mehrere
und die erforderliche Zeit um 39 % reduziert Wochen hinziehen. Dies führt oft zu Verzöge-
werden. Diese Art der Regelung nennt man rungen in der Angebotserstellung und ist für den
prädiktive Regelung. Kaufabschluss möglicherweise nachteilig. Ein
intelligentes Angebotswesen kann die Ange-
Das Entwickeln einer adaptiven Regelung botserstellung in Teilen automatisieren und
verlangt in erster Linie ein tiefes Prozessver- dadurch erheblich beschleunigen und verbilli-
ständnis. Darüber hinaus sind Kenntnisse über gen.
den Einsatz von maschinellen Lernverfahren zur
Regression von Zeitreihen erforderlich. Das Vor- Informationen und umfangreiche Daten über
gehen zur modellbasierten prädiktiven Regelung bereits erstellte Angebote, Maschinenkonfigura-
lässt sich auf ähnliche Problemstellungen tionen und Preise können für das halbautomati-
übertragen. Ein Ansatz mit maschinellen Lern- sche Erstellen von künftigen Angeboten genutzt
verfahren ist immer dann vielversprechend, werden. Unter der Annahme, dass ein ähnlich
wenn viele messbare Größen den Prozess auf konfiguriertes Produkt zu einer ähnlichen
eine unbekannte Weise beeinflussen. Wie in den Kostenstruktur führt, wird mithilfe von ML-Algo-
anderen Anwendungsfällen ist eine ausrei- rithmen ein Modell trainiert, das die Zusammen-
chende Datenmenge für die adaptive Regelung hänge zwischen Maschinenkonfiguration und
zwingend erforderlich. Kosten lernt. Mit diesem Modell werden
anschließend die Kosten für eine Maschinenkon-
3.3 Intelligentes Angebotswesen figuration geschätzt und darauf basierend ein
erstes Angebot erstellt (vgl. Abbildung 5). Das
Im letzten Jahrzehnt hat sich der Trend der Pro- schnelle Erstellen von Angeboten kann die Ver-
duktindividualisierung weiter fortgesetzt. Im kaufswahrscheinlichkeit steigern und damit den
Rahmen der On-Demand-Produktion bzw. der Umsatz erhöhen. Weitere Vorteile: Der Ange-
Losgröße-1-Produktion nimmt die Produktvari- botsprozess wird vereinfacht, das Fehlerpoten-
antenvielfalt überproportional zu und damit die zial reduziert.
Komplexität. Diese Komplexität zeigt sich auch
in den verfügbaren Maschinenkonfigurationen.QUICK GUIDE „MACHINE LEARNING“ 13
Abbildung 6: Automatisierung in der Angebotserstellung
Wie bei den anderen Anwendungsfällen benö- 3.4 Datengetriebene Innovation
tigt man auch für das intelligente Angebotswe-
sen einen ausreichenden Satz historischer Daten Am Anfang eines Industrial-Analytics-Projekts
über Maschinenkonfiguration und Kosten. Die zum Verbessern der Gesamtanlageneffektivität
Angebote müssen in einer strukturierten Form (Verfügbarkeit, Leistung, Qualität) wird das Opti-
vorliegen, die von einem Algorithmus ein-gele- mierungspotenzial der Anlage oder der
sen werden kann. Der größte Aufwand dabei: Maschine bestimmt. Daraus lässt sich der kom-
Die Daten bereinigen und die historischen merzielle Wert der Daten als Teil des allgemei-
Datenbestände normalisieren. Für das Entwi- nen Geschäftsverständnisses ableiten. In der
ckeln des Vorhersagemodells sollte man auf die Sammel-Phase werden Daten aus Automatisie-
Fähigkeiten eines Data Scientist vertrauen. rungskomponenten und Feldgeräten erfasst. In
der Analyse-Phase werden die Daten aufberei-
Darüber hinaus sind weitere Einsatzgebiete für tet, modelliert und mit ML-Algorithmen analy-
ML im Angebotsprozess geeignet, z. B.: siert. Ist ein Problem analysiert und verstanden,
wird es gelöst — wenn möglich durch eine Modi-
Suche nach ähnlichen Konfigurationen: Mit fikation innerhalb der Produktion. Falls sich das
ML-Algorithmen lassen sich die Maschinen- Problem nicht dauerhaft lösen lässt, soll es aber
konfiguration bestimmen, die zu ähnlichen zumindest vorausschauend erkannt werden;
Kosten/Ergebnissen führt. dafür wird mittels einer Streaming-Analytics-
Geführte Konfiguration: Basierend auf histo- Implementierung, z. B. eine Anomalie-
rischen Daten werden zulässige Konfigurati- Erkennung, eine Lösung gesucht und in der
onsvarianten bestimmt und dem Angebotser- Implementierungsphase bereitgestellt.
steller sukzessive vorgeschlagen.
Augmented Konfiguration: Basierend auf der Die Erfahrung zeigt, dass Maschinenbauer und
aktuellen Maschinenkonfiguration werden Anlagenbetreiber typischerweise zuerst eine
die populärsten zusätzlichen Maschinenopti- existierende Anlage oder Maschine verfügbar
onen vorgeschlagen. machen oder mit einem reaktiven Industrial-
Überspezifikation bei der Maschinenkonfigu- Analytics-Projekt die Qualität verbessern. Erst
ration vermeiden oder reduzieren: Mit ML- wenn diese Vorgehensweise erfolgreich war,
Algorithmen lassen sich die für das Kosten- erwägt man, sie bei der Entwicklung der
Leistungs-Verhältnis relevanten Optionen nächsten Generation für eine Verbesserung der
bestimmen. Leistung zu übertragen. Die Vorgehensweise ist
dabei grundsätzlich die gleiche, nicht jedoch die
Ziele.14 QUICK GUIDE „MACHINE LEARNING“
Bei der klassischen Reihenfolge „Algorithmen -> Heute kann die Industrial-Analytics-Lösung
Daten -> Entscheidungen“ kann die Gesamtanla- mögliche Korrelationen in den bereitgestellten
geneffektivität nicht besser sein als der Mensch, Daten nur vorschlagen. Der Domänenexperte
der sie programmiert. ML-Algorithmen, ange- des Maschinenbauers oder Anlagenbetreibers
wendet auf große Mengen Produktionsdaten, bewertet die von den ML-Algorithmen erkann-
erkennen dagegen Kausalitäten, die dem Anla- ten Korrelationen als „Zufall“ oder als tatsächli-
genbetreiber oder Maschinenbauer bis dato che Kausalität. Auf Basis dieser vom Domänen-
verborgen geblieben waren, die aber die experten als Kausalität erkannten Zusammen-
Gesamtanlageneffektivität verbessern. So lassen hänge in den Daten werden heute
sich nicht nur reaktiv Qualität und Verfügbarkeit Entscheidungen zur Produktionsoptimierung
verbessern, sondern auch proaktiv die Leistung getroffen. Beim künftigen begleitenden
zukünftiger Maschinen. („guided“) Analytics wird die Ausführung der
Datenanalyse durch einen Domänenexperten
initiiert, läuft aber ansonsten automatisiert; bei
der autonomen Analytics ist der gesamte Daten-
analyse-Prozess automatisiert.
Abbildung 7: Eine Störung wird erkannt. (Quelle: Softing GmbH)QUICK GUIDE „MACHINE LEARNING“ 15
4. Daten als Rohstoff
Daten entwickeln sich zur wichtigsten Währung Geschäftsmodelle. Aus der zunehmenden Herr-
des 21. Jahrhunderts und sind die Grundlage für schaft der Daten resultiert die Umkehr der
ML. In den vergangenen zwei Jahren wurden Reihenfolge von Algorithmen -> Daten ->
mehr Daten generiert als in der gesamten Entscheidungen hinzu Daten -> Algorithmen ->
Geschichte der Menschheit. Daten werden zu- Entscheidungen“ (Abbildung 7). Das repräsen-
nehmend zum Produktionsfaktor, zusätzlich zu tiert die gerade stattfindende Revolution.
Boden, Kapital und Arbeitskraft. Sie ermöglichen
Kosteneinsparungen und neue
Abbildung 8: Von der regelbasierten zur datengetriebenen Entscheidungsfindung. (Quelle: Softing GmbH)
Seit dem ersten programmierbaren Chip — der Anlagendaten wurden in der Vergangenheit oft
Intel 4004 kam 1971 auf den Markt — wird Soft- gesammelt, aber nicht verarbeitet. Heute
ware nach dem gleichen Schema entwickelt: werden sie bei der Produktionsoptimierung
Zuerst wird das Problem definiert, danach Ziele eingesetzt, um die Gesamtanlageneffektivität zu
und Arbeitsschritte festgelegt und schließlich steigern, die sogenannte Overall Equipment
die Anwendung als eine Reihenfolge von Algo- Efficiency (OEE). Daten einer normal funktionie-
rithmen programmiert. In der Praxis werden renden Maschine oder Anlage werden genutzt,
diese Algorithmen mit Daten gefüttert, und um ein Modell mit Grenzwerten zu trainieren.
Anwender treffen auf deren Basis Entscheidun- Sobald das Modell anschließend abweichende
gen. Diese Vorgehensweise ändert sich Daten erhält, schlägt es Alarm, weil die abwei-
momentan strukturell: Die Daten werden vorher chenden Daten fehlerhafte Baugruppen,
gesammelt und im zweiten Schritt mittels allge- Maschinen oder Prozesse repräsentieren.
meingültiger Algorithmen analysiert. Daraus
resultieren Kausalitäten, auf deren Basis Ent- Wenn ML-Algorithmen den Motor für
scheidungen getroffen werden, z. B. zur Produk- künftige Entwicklungen darstellen, dann
tionsoptimierung. Diese Entscheidungen sind Daten der Treibstoff.
werden im Übrigen immer öfter autonom
getroffen.16 QUICK GUIDE „MACHINE LEARNING“
ML nimmt seine Lösung nicht aus dem regelba- Dazu zählen Daten aus Steuerungen, Daten von
sierten Software-Code, der von Menschen Sensoren, Aktoren und Datenbanken sowie Pro-
geschrieben wurde. Darin unterscheidet es sich duktionsflussdaten oder Wetterdaten aus
von den klassischen Applikationen. Es ist zusätzlichen Quellen. Aber woran lässt sich
wichtig, das Wesen des Machine Learning zu erkennen, ob die Menge an Daten aus Automati-
kennen: Es existiert ein Muster in Form von sierungskomponenten und Feldgeräten aus-
Daten, das wir im Sinne von: „IF THIS THAN reicht? Die Antwort ist simpel: Sobald
THAT“-Programmzeilen nicht regelbasiert fest- Algorithmen Muster erkennen, sind sie ausrei-
halten können. Algorithmen finden dieses chend gefüttert.
Muster aber in den Daten: In der Produktion ist
es typischerweise eine Kausalität zwischen Es ist somit nicht vorhersehbar, welche Daten
Baugruppenzuständen und physikalischen für die erforderliche Modellqualität und Genau-
Messwerten. igkeit erforderlich sind. Mehr Daten führen nicht
notwendigerweise zu mehr Mustern, besten-
Bei der klassischen Reihenfolge Algorithmen -> falls zu mehr Korrelationen — jedenfalls nicht
Daten -> Entscheidungen kann die OEE nicht unbedingt zu mehr Kausalitäten. Denn die
besser sein als das Verständnis des Menschen, können nur von einem Domänenexperten
der die OEE-Einflussfaktoren programmiert hat. bestätigt werden.
ML-Algorithmen, angewendet auf große
Mengen Produktionsdaten, können dagegen Am Anfang eines ML-Projektes wird das Opti-
Kausalitäten finden, welche die OEE verbessern, mierungspotenzial der Anlage oder der
für den Anlagenbetreiber bis dato aber verbor- Maschine bestimmt und damit der
gen waren. kommerzielle Wert der Daten als Teil des allge-
meinen Geschäftsverständnisses. In der
Welche Daten brauchen wir für ML? Und wie Sammel-Phase werden Daten erfasst und aufbe-
viele? Welche Rolle spielt dabei „Big Data“? Big reitet. Ausreißer werden gelöscht, Fehleinträge
Data ist ein Sammelbegriff für große eliminiert, Zeitstempel abgeglichen, Metadaten
Datenmengen — mit unterschiedlichen zugefügt, die bereinigten Daten formatiert. In
Datentypen aus verschiedenen Quellen, die in der Analyse-Phase werden die Daten
unterschiedlichen Geschwindigkeiten zur Verfü- aufbereitet, modelliert und analysiert. In der
gung gestellt werden. Implementierungsphase wird eine datenba-
sierte Produktionsoptimierung eingebaut, z. B.
Die Menge, die Geschwindigkeit und die Vielfalt ein Modell zur Anomalie-Erkennung.
der aktuellen Produktionsdaten übersteigen die
Fähigkeiten des Bedienpersonals und verlangen Daten sind das A und O des maschinellen
nach neuen, datenbasierten Ansätzen. Um ML Lernens. Ohne Daten gibt es kein ML!
aber überhaupt anwenden zu können, ist der
Zugang zu qualitativ hochwertigen Daten
Voraussetzung.QUICK GUIDE „MACHINE LEARNING“ 17
5. Datengetriebene Modellierung
Ohne Rohöl keine Raffinerie. Ohne Raffinerie CRISP-DM unterteilt den ML-Analytics-Prozess in
keine Kosmetik und kein Benzin. Wenn die sechs Phasen. Bei strukturiertem Vorgehen ist
Grundvoraussetzung geschaffen ist, und Daten dieser Prozess uneingeschränkt wiederholbar
zur Verfügung stehen, stellt sich die nächste und damit für die agile Entwicklung auf Basis
Frage: Wie lassen sich daraus nutzenorientiert der Scrum-Methode geeignet, da er sich in
Informationen gewinnen? Tech-Unternehmen Sprints unterteilen lässt.
aus dem amerikanischen Raum, die bisher in
B2C-Bereichen aktiv waren, konnten für eine Die Reihenfolge der Phasen ist nicht streng,
gesamte Branche die Eine-für-alle-Lösung („One erforderlich ist ein stetes Hin- und Herbewegen
size fits all“) anbieten, beispielsweise für den zwischen den verschiedenen Phasen. Die Pfeile
Online-Handel oder die Web-Informationssuche. im Prozessdiagramm zeigen die wichtigsten und
Sie folgten damit dem Von-oben-nach-unten- häufigsten Abhängigkeiten zwischen den
Ansatz (top-down). In der äußerst diversifiziert Phasen an. Der äußere Kreis im Diagramm sym-
aufgestellten B2B-Branche des Maschinen- und bolisiert den zyklischen Charakter des ML-
Anlagenbaus passen diese Lösungen aber nicht: Vorgehens selbst. Nach Ablauf eines Zyklus
Prozesse und Abläufe unterscheiden sich von können gewonnene Erkenntnisse neue, oft
Unternehmen zu Unternehmen, auch die fokussierte Geschäftsfragen auslösen; nachfol-
Anwendungs- und Geschäftsfälle so-wie die Art gende ML-Prozesse profitieren von den Erfah-
der Sensoren weichen voneinander ab. All das rungen früherer Prozesse.
verlangt eine Lösung, die für das einzelne Unter-
nehmen und dessen Geschäftszweck zuge- Die einzelnen Phasen teilen sich in die folgenden
schnitten sein muss. Deshalb muss auf dem 6 Schritte:
Weg zur datengetriebenen Wertschöpfung der
Von-unten-nach-oben-Ansatz (bot-tom-up) Geschäftsverständnis
gewählt werden. Aus einem Modell, das sich in In dieser ersten Phase geht es darum, die
vielen Praxisprojekten bewährt hat, ergeben sich Projektziele und -anforderungen aus der Ge-
aber Möglichkeiten, den Ablauf eines ML-Prozes- schäftsperspektive zu verstehen. Mit diesem
ses zu vereinfachen. Wissen wird anschließend das Data-Mining-
Problem definiert und ein vorläufiger Plan zum
Gut geeignet ist dafür die Anwendung des bran- Erreichen der Ziele erarbeitet.
chenübergreifenden Standardprozesses für Data
Mining, allgemein bekannt unter dem Akronym Datenverständnis
CRISP-DM. Dieses Data-Mining-Prozessmodell Diese Phase beginnt mit einer ersten Datenerhe-
beschreibt gängige Ansätze, mit denen Analytik- bung. Anschließend macht man sich mit den
Experten Probleme angehen. Dieses Vorgehen Daten vertraut, identifiziert Datenqualitätsprob-
lässt sich problemlos auf ML-Projekte leme und gewinnt erste Einblicke in die Daten,
übertragen. um interessante Teilmengen zu entdecken.
Damit lassen sich im Anschluss Hypothesen zu
versteckten Informationen aufstellen.18 QUICK GUIDE „MACHINE LEARNING“
Abbildung 9: Die sechs Phasen im ML-Analytics-Prozess (Quelle: Wikipedia,
https://www.crisp-research.com/publication/machine-learning-im-
unternehmenseinsatz-kunstliche-intelligenz-als-grundlage-digitaler-
Datenaufbereitung Modellierung
Diese Phase umfasst alle Aktivitäten zum Erstel- In dieser Phase werden Modellierungstechniken
len des endgültigen Datensatzes — allen voran ausgewählt, angewendet und ihre Parameter
Daten, die aus den ursprünglichen Rohdaten in auf optimale Werte kalibriert. Typischerweise
die Modellierungswerkzeuge eingespeist gibt es mehrere Techniken für denselben Prob-
werden. Die Aufgaben: Tabellen, Datensätze lemtyp. Einige Techniken haben spezifische
und Attribute auswählen, Daten für Modellie- Anforderungen an die Form der Daten. Daher ist
rungswerkzeuge transformieren und bereinigen. es oft notwendig, in die Phase der Datenaufbe-
Mit einem Aufwand von 50 bis 70 % des reitung zurückzukehren. Sind die Daten korrekt
gesamten Analytikprojekts ist dieser Teilprozess aufbereitet, können in kurzer Zeit mehrere Hun-
die größte Aufgabe. derttausend Ansätze oder verschiedenste
Modelle gerechnet werden. Deshalb entstehen
während der gesamten CRISP-DM-basierten
Analysephase in diesem Schritt nur zirka 10 %
des Gesamtaufwandes. Wurde die Datenaufbe-
reitung allerdings nur mittelmäßig
abgeschlossen, sind auch die Ergebnisse aus der
Modellierung mittelmäßig — spätestens nach
der nächsten Phase lassen sich daraus keine
validen Ergebnisse mehr generieren.QUICK GUIDE „MACHINE LEARNING“ 19
Auswertung Bereitstellung
In diesem Stadium des Projekts werden ein oder Das fertige Modell ist in der Regel nicht das Ende
mehrere Modelle erstellt, die aus Sicht der des Projekts. Selbst wenn der Zweck des Modells
Datenanalyse eine hohe Qualität zu haben darin besteht, die Kenntnis über die Daten zu
scheinen. Bevor man mit der endgültigen Bereit- erhöhen, muss das gewonnene Wissen organi-
stellung des Modells fortfahren kann, ist das siert und zum Nutzen des Kunden präsentiert
Modell gründlich zu evaluieren, die Schritte zur werden. Je nach Anforderung kann die Imple-
Konstruktion des Modells sind zu überprüfen. mentierungsphase so einfach sein wie das
Nur so ist gewährleistet, dass es die Erstellen eines Berichts oder so komplex wie das
Unternehmensziele erreicht. Ein Hauptziel: Implementieren eines wiederholbaren Daten-
Feststellen, ob ein wichtiges Geschäftsproblem Scorings, z. B. eine Segmentzuordnung. In vielen
nicht ausreichend berücksichtigt wurde. Am Fällen führt der Kunde die Bereitstellungs-
Ende dieser Phase entscheidet sich, ob und wie schritte aus, nicht der Datenanalytiker. Selbst
die Analytikergebnisse verwendet werden. wenn der Analytiker das Modell einsetzt, muss
der Kunde im Vorfeld die durchzuführenden
Aktionen verstehen, um die erstellten Modelle
nutzen zu können.20 QUICK GUIDE „MACHINE LEARNING“
6. Technische Umsetzung der Anwendungsfälle
In diesem Kapitel wird die technische Umset- Klassische Vision-Systeme werden mit Bildern
zung der Anwendungsfälle aus Kapitel 3 von Fehlern, Objekten oder Szenen angelernt.
beschrieben. Das System erkennt und klassifiziert genau diese
und nur diese Fehler der Objekte oder Szenen —
6.1 Menschenähnliche Bildverarbeitung Abweichungen davon werden nicht als Fehler
(„Human-like Machine Vision“) erkannt. Bei der menschenähnlichen Bildverar-
beitung werden die Algorithmen mit Bildern von
Klassische Bildbearbeitungs-Systeme stoßen typischen Gut-Teilen, von korrekten Objekten
immer wieder bei Aufgaben an Grenzen, die für oder Szenen angelernt. Das System lernt, ähnlich
den Menschen leicht lösbar sind. Die menschen- dem Menschen, wie ein Gut-Teil, ein Objekt oder
ähnliche Bildverarbeitung wurde mit der Zielset- eine Szene aussehen kann — mit allen zulässigen
zung entwickelt, die Stärken des Menschen in Streuungen und Variationen. Alles, was von
einer Technologie der industriellen Bildverarbei- diesem sogenannten „Erwartungsbild“
tung abzubilden. Entwickelt wurde diese abweicht, wird sowohl vom Menschen als auch
Technologie von Experten aus den Be-reichen vom System als Auffälligkeit erkannt. Umge-
Bildverarbeitung, Datenverarbeitung und Neuro- kehrt wird alles, was diesem so-genannten
nale Netze. Basis waren die Erkennt-nisse von „Erwartungsbild“ von Gut-Teilen, typischen
Neuro-Medizinern zu Funktionalitäten des Objekten oder Szenen entspricht, so-wohl vom
menschlichen Gehirns. Die menschen-ähnliche Menschen als auch vom System als erwartungs-
Bildverarbeitung wurde speziell für das industri- gemäß eingestuft.
elle Analysieren von Bildern entwickelt und
optimiert und arbeitet selbstlernend. Sie basiert 6.2 Adaptive Regelung zur Prozessoptimierung
auf mehrstufigen neuronalen Netzen, die sich
mit wenigen Parametern konfigurieren lassen. Bei der adaptiven Regelung lernt ein ML-Modell
Human-like Machine Vision umfasst drei Werk- anhand von historischen Daten den Zusammen-
zeuge der industriellen Bildverarbeitung, die auf hang zwischen Prozess-Einflussgrößen und der
unterschiedliche Aufgabenstellungen hin entwi- daraus resultierenden Prozessqualität. Diese
ckelt und optimiert wurden: geschätzte Prozessqualität wird anschließend
über Prozessstellgrößen geregelt, ohne
Entdeckung von qualitativen Anomalien für tatsächlich gemessen zu werden. Zum
die Qualitätsinspektion Trainieren des Modells kommen Algorithmen
Lokalisierung und Identifizierung von des überwachten Lernens zum Einsatz.
einzelnen oder mehreren Merkmalen
Klassifizierung von Objekten oder kompletten
SzenenQUICK GUIDE „MACHINE LEARNING“ 21
Im Beispiel der Regelung der Volltondichte Eingabegrößen für das Modell sind alle kosten-
dienten über zwei Dutzend Einflussparameter relevanten Konfigurationsoptionen der
wie Feuchtigkeit, Temperatur und Farbeigen- Maschine. Das Modell lernt daraus die teils sehr
schaften als Eingangsgrößen. Die Ausgangs- komplexen Zusammenhänge zwischen den
größe des Modells ist die geschätzte Vollton- Optionen und deren Auswirkung auf die entste-
dichte. Diese wird über Prozessparameter nach- henden Kosten. Damit kann es für eine Maschi-
geregelt, noch bevor sie tatsächlich gemessen nenkonfiguration einen ungefähren Preis
wird. Zum Training werden die Messgrößen der schätzen. Nach diesem ersten ungefähren
Einflussfaktoren und das zugehörige Qualitäts- Angebot kalkuliert selbstverständlich ein
ergebnis aus mehreren Monaten verwendet. Experte die exakten Kosten für den definitiven
Eine geeignete Datenvorverarbeitung eliminiert Preis. Mit diesem Ansatz lassen sich aber nicht
inkonsistente oder nicht eindeutige Datensätze nur die Kosten von Maschinenkonfigurationen
und generiert geeignete Merkmale. Bedingung: schätzen; basierend auf historischen Daten
Die Datensätze enthalten nur Beispiele, bei können mit dem gleichen Ansatz zu erwartende
denen die Volltondichte für die Einflussgrößen Projektzeiten oder der Output einer Anlage
zufriedenstellend eingestellt waren. geschätzt werden.
Das Modell ist dann in der Lage, die komplexen Für das Training des Modells müssen die Ange-
und nicht linearen Zusammenhänge zwischen botsdaten in einer strukturierten, maschinenles-
den zahlreichen Einflussgrößen und der Vollton- baren Form vorliegen. Eine Sammlung von
dichte abzubilden. Mithilfe des Modells können Angeboten in PDF-Form reicht dafür üblicher-
die geeigneten Stellgrößen in vielen Fällen weise nicht aus. Erforderlich ist eine Datenbank
erfolgreich vorhergesagt werden, selbst unter von Maschinenkonfiguration und Angebots-
bisher unbekannten Einflüssen oder bei einer preis. Dabei ist zu berücksichtigen, dass sich
unbekannten Kombination der Einfluss-größen. Maschinen und Maschinenoptionen weiterent-
Das Modell kann also nicht nur Wissen reprodu- wickeln und entsprechende Versionen erhalten.
zieren, sondern sein Wissen auch teilweise auf Im Laufe der Zeit kann sich das Preisgefüge für
neue Fälle übertragen. Maschinenoptionen ändern — auch das ist zu
beachten. Beim intelligenten Angebotswesen
6.3 Intelligentes Angebotswesen liegt deshalb neben dem Training ein Schwer-
punkt auf der Datenbereitstellung und der
Beim intelligenten Angebotswesen lernt ein ML- Datenbereinigung.
Modell auf Basis historischer Angebotsdaten
den Zusammenhang zwischen Maschinenkonfi- 6.4 Datengetriebene Innovation
guration und Kosten. Diese geschätzten Kosten
werden dann für das Angebot verwendet. Zum Viele Entscheidungsträger haben ein mulmiges
Trainieren des Modells kommen Algorithmen Gefühl bei dem Gedanken, ihre Produktionsda-
des überwachten Lernens zum Einsatz. Das ten nach draußen in die Cloud zu geben. Die
Training wird in regelmäßigen Abständen Alternative dazu heißt „Edge“-Lösung. Dabei
wiederholt, damit im Lernprozess möglichst werden die Daten auf einem Standard-IPC dort
aktuelle Daten berücksichtigt werden. gespeichert, wo sie anfallen, nämlich in der
Anlage bzw. an der Maschine. Die Gefahr von
Datendiebstahl oder Datenverlust lässt sich so
minimieren.22 QUICK GUIDE „MACHINE LEARNING“
Auch einige Cloud-Anbieter haben mittlerweile „Analytics at the edge“ findet ohne zusätzliche
eine „Cloud vor Ort“ oder Edge-Analytics-Lösung Sicherheitsvorkehrungen innerhalb der Firewall
im Angebot. Dabei werden auf einem Gateway in der Anlage statt. Lediglich die Resultate der
in der Anlage vorab Daten analysiert, um lokal ausgeführten Echtzeit-Analytics können in
anschließend mit ihnen mehrere Anlagen und einer öffentlichen oder einer lokalen Cloud
Standorte in der Cloud zu vergleichen. Beim gesammelt werden. Die Cloud hält für das
„Edge“-basierten Industrial-Analytics-Ansatz Trainieren der Modelle idealerweise eine
werden Daten gesammelt, offline analysiert und größere Auswahl an leistungsfähigen
in ein Modell eingespeist. Dieses Modell wird Algorithmen des maschinellen Lernens
anschließend zurück in die Anlage gebracht, um verfügbar als die Anlage vor Ort oder der
die dort eingehenden Datenströme zu bewerten. Anbieter der Edge-Analytics. Und in der Cloud
lassen sich die Produktionswerte mehrerer
Anlagen vergleichen. „Analytics at the edge“
dagegen verarbeitet die Daten in Echtzeit
(Abbildung 10).
Abbildung 10: Echtzeit-Datenverarbeitung (Quelle: Softing GmbH)QUICK GUIDE „MACHINE LEARNING“ 23
7. Build or Buy
Hat man sich entschieden, ML im eigenen Unter- Datenaufbereitung
nehmen oder für die eigenen Produkte ein- Das Aufbereiten der Daten ist häufig der zeitauf-
zusetzen, stellt sich die nächste Frage: Was wendigste Teil des Prozesses. Softwareprodukte
muss ich selber machen, und was kann ich zu- können hier Zeit einsparen. Allerdings hängt die
kaufen? Dieses Kapitel gibt einen Überblick über Dauer und Qualität der Datenaufbereitung stets
diesen Themenbereich, basierend auf dem von den eigenen Daten ab und muss deshalb an
CRISP-DM-Analytikprozess in Kapitel 5. Anschlie- das eigene Vorhaben angepasst werden. Die
ßend geht es auf Hardware- und Softwarebau- zukaufbaren Produkte sind also nur Werkzeuge,
steine ein, die derzeit am Markt verfügbar sind. die von einem Datenspezialisten eingesetzt
werden, um den Prozess zu beschleunigen.
7.1 Überblick
Modellierung und Auswertung
Geschäftsverständnis Zukaufbare Produkte gibt es auch für das Entwi-
Das Geschäftsverständnis ist eine ureigene ckeln von Algorithmen, mit denen sich zuvor
Kompetenz des eigenen Unternehmens und gesammelte Daten analysieren lassen. Im
muss als solche nicht zugekauft werden. Nun Angebot sind Entwicklerwerkzeuge, aber auch
gilt es allerdings nicht nur, das eigene Geschäft fertige Algorithmen. Nur selten kann man
zu verstehen. Ein besonderes Augenmerk liegt fertige Lösung kaufen; üblicherweise werden
auf den Chancen und Risiken durch die Digitali- bestehende Lösungen angepasst, bei komplizier-
sierung und ML. Hier ist es sinnvoll, externe ten Problemen auch von Grund auf neu entwi-
Quellen zu konsultieren, um das Wissen in der ckelt. Die Algorithmen sollte ein Experte im
Organisation zu vervollständigen und die rich- Unternehmen entwickeln oder ein Dienstleister.
tige Geschäftsstrategie zu entwickeln. Ein Team von Anwendungsexperten und Data
Scientists bewertet anschließend die entstande-
Datenverständnis nen Modelle. Die meisten Werkzeuge zum Ent-
Das Wissen über die eigenen Daten liegt typi- wickeln von Algorithmen beinhalten auch Tools
scherweise im Unternehmen selbst. Dennoch zum Bewerten der entwickelten Algorithmen.
reicht dieses Wissen häufig nicht aus, um sofort
neue Lösungen zu entwickeln; es muss zuerst Bereitstellung
vertieft werden. Dafür gibt es in der Regel keine Die entwickelten Modelle in die bestehenden
zukaufbaren Lösungen. Das Wissen über die Prozesse zu integrieren ist für Maschinenbauer
eigenen Daten, deren Bedeutung, Verfügbarkeit häufig eine große Herausforderung. Sie müssen
und Qualität muss in interdisziplinärer Zusam- eine IT-Infrastruktur aufbauen, welche die benö-
menarbeit von Anwendungsexperten, Data tigten Daten sammelt, automatisiert durch die
Scientists und Steuerungsexperten erarbeitet Modelle auswertet und die Resultate wie-der in
werden. Bei der Analyse unterstützen eine Reihe den Prozess einspeist. Je nach IT-Infrastruktur
von Softwarelösungen — sie ersetzen aber nicht des eigenen Unternehmens kann das Sammeln
den eigentlichen Wissensaufbau. der Daten von einfach bis äußerst komplex
ausfallen.Sie können auch lesen

















































