Polynomiale Regression, Interpolation, numerische Integration - Vorlesung 170 004 Numerische Methoden I Clemens Brand und Erika Hausenblas 25 ...
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Polynomiale Regression, Interpolation, numerische
Integration
6. Vorlesung
170 004 Numerische Methoden I
Clemens Brand und Erika Hausenblas
Montanuniversität Leoben
25. März 2021Polynomiale Regression, Interpolation, numerische
Integration
1 Polynomiale Regression
Aufgabenstellung und Lösungsweg
Ausgleichsgerade (klassisch, robust, total)
Schätzen von Modellparametern
2 Polynomiale Interpolation
Rechenverfahren
Ansatz in Standard-Form, Vandermonde-Matrix
Polynom in Lagrange-Form
Polynome in verschiedenen Basis-Darstellungen
Polynom in Newton-Form
Warnung vor zu hohem Grad!
Runge-Phänomen
3 Spline-Interpolation etc.
4 Numerische Integration
Klassisch: Newton-Cotes
Weitere Quadraturformeln
2 / 52Gliederung 6. Vorlesung
1 Polynomiale Regression
Aufgabenstellung und Lösungsweg
Ausgleichsgerade (klassisch, robust, total)
Schätzen von Modellparametern
2 Polynomiale Interpolation
Rechenverfahren
Warnung vor zu hohem Grad!
3 Spline-Interpolation etc.
4 Numerische Integration
Klassisch: Newton-Cotes
Weitere Quadraturformeln
Polynomiale Regression 3 / 52Polynomiale Regression: Aufgabenstellung
Gesucht ist ein Polynom, das die Datenpunkte möglichst gut approximiert
Gegeben
m + 1 Wertepaare (xi , yi ), i = 0, . . . , m
Gesucht
p(x ), ein Polynom n-ten Grades, n < m, so dass die Summe der
Fehlerquadrate
m
(p(xi ) − yi )2
X
i=0
minimal wird.
Polynomiale Regression Aufgabenstellung und Lösungsweg 4 / 52Anpassen eines Polynoms an Datenpunkte
Spezifische Wärmekapazität 1200
von kohlenstoffarmem Stahl in
1100
J/kg K für 20 C ≤ T ≤ 700, C
1000
T cp
y = 0.0009*x2 − 0.02*x + 4.6e+002
20 447 900
y = 1.6e−006*x3 − 0.00083*x2 + 0.46*x + 4.4e+002
173 500
800
200 509
400 595 700
543 700
600 763 600
626 800 500
700 909 Datenpunkte
quadratisches Pol.
kubisches Pol.
400
0 100 200 300 400 500 600 700 800
Die Abbildung illustriert polynomiale Regression (quadratisch und kubisch)
an die gegebenen Datenpunkte.Polynomiale Regression
Zusammenfassung, grob vereinfacht
I macht man, weil Polynome die erstbesten Funktionen sind, die sich
für Datenmodelle anbieten.
I ist ein Spezialfall der Anpassung von linearen Modellen, die bereits
behandeltwurde. (Ansatzfunktionen sind nichtlinear, aber die
gesuchten Koeffizienten treten nur linear auf!)
I für die Normalengleichungs-Matrix gibt es eine einfache Formel
I für Polynome hohen Grades (ab n ≈ 15 − 20) ist der naive Ansatz
a0 + a1 x + a2 x 2 + · · · x n völlig ungeeignet. Abhilfe:
I Für Anfänger: Lassen Sie ’s bleiben!
I Für Fortgeschrittene: Verwenden Sie Orthogonalpolynome!
Polynomiale Regression Aufgabenstellung und Lösungsweg 6 / 52Direkter Lösungsweg
Ansatz des Polynoms mit unbestimmten Koeffizienten
p(x ) = a0 + a1 x + a2 x 2 + · · · + an−1 x n−1 + an x n .
I Einsetzen der gegebenen Wertepaare führt auf ein System von m
linearen Gleichungen in den n + 1 unbekannten Koeffizienten
a0 , a1 , . . . , an .
I Die Matrix A hat eine spezielle Form (Vandermonde-Matrix):
1 x0 x02 x03 . . . x0n
1
x1 x12 x13 . . . x1n
A=
.. .. .. .. ..
. . . . .
2 x3 . . . xn
1 xm xm m m
I Standard-Lösung am Rechner durch QR-Zerlegung
I Bei kleinen Problemen und Rechnung mit Papier und Stift: klassisch
nach der Methode der Normalengleichungen.
Polynomiale Regression Aufgabenstellung und Lösungsweg 7 / 52Formel für die Normalengleichungen
Bei polynomialer Regression haben die Normalengleichungen spezielle Form; man kann
die Koeffizienten direkt angeben.
s0 s1 . . . sn a0 t0
s1 s2 . . . sn+1
a1 t1
· . =.
. .. ..
.
. . . .. ..
sn sn+1 . . . s2n an tn
m
X m
X
mit sk = xik , tk = xik yi
i=0 i=0
Praktisch nur bei linearer oder vielleicht noch quadratischer Regression
sinnvoll. Moderner Lösungsweg: Vandermonde-Matrix aufstellen,
QR-Lösung
Polynomiale Regression Aufgabenstellung und Lösungsweg 8 / 52Normalengleichungen, Spezialfall Ausgleichsgerade
Gleichung der Ausgleichsgeraden: y = a0 + a1 x
Das 2 × 2-Gleichungssystem für die Koeffizienten a0 a1 lautet
" # " # " #
s0 s1 a t
· 0 = 0 mit
s1 s2 a1 t1
m
X m
X m
X m
X
s0 = m + 1, s1 = xi , s2 = xi2 , t0 = yi , t1 = xi yi
i=0 i=0 i=0 i=0
Lösung des Gleichungssystems:
s2 t 0 − s1 t 1 s0 t1 − s1 t0
a0 = a1 =
s0 s2 − s12 s0 s2 − s12
(Je nachdem, wo Sie nachschauen, finden Sie unterschiedliche
Schreibweisen dieser Formeln.
Beachten Sie hier: Anzahl der Datenpunkte = m + 1)
Polynomiale Regression Ausgleichsgerade (klassisch, robust, total) 9 / 52Ausgleichsgerade anpassen
Einfacher Spezialfall der polynomialen Regression
2
1.75
1.5
1.25
1
0.75
0.5
0.25
0.5 1 1.5 2 2.5 3 3.5
Die Ausgleichsgerade nach der Methode der kleinsten Quadrate lässt sich
von den wenigen Ausreissern stark ablenken.
Minimieren der Summe der Fehlerbeträge legt hier eine wesentlich
plausiblere Gerade durch die Daten. Ein Beispiel für Robuste Regression
Polynomiale Regression Ausgleichsgerade (klassisch, robust, total) 10 / 52Ausgleichsgerade anpassen
Einfacher Spezialfall der polynomialen Regression
2
1.75
1.5
1.25
1
0.75
0.5
0.25
0.5 1 1.5 2 2.5 3 3.5
Die Ausgleichsgerade nach der Methode der kleinsten Quadrate lässt sich
von den wenigen Ausreissern stark ablenken.
Minimieren der Summe der Fehlerbeträge legt hier eine wesentlich
plausiblere Gerade durch die Daten. Ein Beispiel für Robuste Regression
Polynomiale Regression Ausgleichsgerade (klassisch, robust, total) 10 / 52Ausgleichsgerade anpassen
Einfacher Spezialfall der polynomialen Regression
2
1.75
1.5
1.25
1
0.75
0.5
0.25
0.5 1 1.5 2 2.5 3 3.5
Die Ausgleichsgerade nach der Methode der kleinsten Quadrate lässt sich
von den wenigen Ausreissern stark ablenken.
Minimieren der Summe der Fehlerbeträge legt hier eine wesentlich
plausiblere Gerade durch die Daten. Ein Beispiel für Robuste Regression
Polynomiale Regression Ausgleichsgerade (klassisch, robust, total) 10 / 52Total Least Squares mit SVD
Standardverfahren minimiert Summe der Abstandsquadrate in y-Richtung, TLS
minimiert Quadratsumme der Normalabstände
1
Bestimme Schwerpunkt [x̄ , ȳ ] der Daten.
0.8
1 X 1 X
x̄ = xi , ȳ = yi
n i=1,n n i=1,n
0.6
0.4
Verschiebe die Daten
0.2
∆xi = xi − x̄ , ∆yi = yi − ȳ
0
−0.2
Bilde Singulärwertzerlegung
−0.2 0 0.2 0.4 0.6 0.8 1 1.2
∆x1 ∆y1
T .. ..
U ·S ·V = .
.
∆xn ∆yn
TLS-Gerade geht durch den Schwerpunkt in Richtung des ersten Spaltenvektors
von V .Schätzen von Modellparametern
Die Methode der kleinsten Quadrate ist das Standardverfahren zur
Schätzung von Modellparametern. Unter bestimmten Annamen liefert sie
eine in gewissem Sinn „beste“ Schätzung. Für den Spezialfall polynomiale
Regression:
I yi = a0 + a1 xi + a2 xi2 + · · · + an xin + i
Die a0 , . . . an sind unbekannte Parameter, die aus vorliegenden
Beobachtungen {[xi , yi ], i = 0, . . . , m} geschätzt werden sollen.
Die Beobachtungen sind durch (ebenfalls unbekannte) zufällige
Störgrößen i verrauscht.
I E [i ] = 0 Alle Störgrößen haben Mittelwert 0.
2
I E [i ] = σ 2 gleiche Varianz.
I E [i j ] = 0 für i 6= j unkorellierte Störgrößen
Satz von Gauß-Markow
Der Kleinste-Quadrate-Schätzer ist ein bester linearer erwartungstreuer
Schätzer, englisch: Best Linear Unbiased Estimator, kurz: BLUE
Polynomiale Regression Schätzen von Modellparametern 12 / 52Schätzen von Modellparametern
Die Methode der kleinsten Quadrate ist das Standardverfahren zur
Schätzung von Modellparametern. Unter bestimmten Annamen liefert sie
eine in gewissem Sinn „beste“ Schätzung. Für den Spezialfall polynomiale
Regression:
I yi = a0 + a1 xi + a2 xi2 + · · · + an xin + i
Die a0 , . . . an sind unbekannte Parameter, die aus vorliegenden
Beobachtungen {[xi , yi ], i = 0, . . . , m} geschätzt werden sollen.
Die Beobachtungen sind durch (ebenfalls unbekannte) zufällige
Störgrößen i verrauscht.
I E [i ] = 0 Alle Störgrößen haben Mittelwert 0.
2
I E [i ] = σ 2 gleiche Varianz.
I E [i j ] = 0 für i 6= j unkorellierte Störgrößen
Satz von Gauß-Markow
Der Kleinste-Quadrate-Schätzer ist ein bester linearer erwartungstreuer
Schätzer, englisch: Best Linear Unbiased Estimator, kurz: BLUE
Polynomiale Regression Schätzen von Modellparametern 12 / 52Schätzen von Modellparametern
Die Methode der kleinsten Quadrate ist das Standardverfahren zur
Schätzung von Modellparametern. Unter bestimmten Annamen liefert sie
eine in gewissem Sinn „beste“ Schätzung. Für den Spezialfall polynomiale
Regression:
I yi = a0 + a1 xi + a2 xi2 + · · · + an xin + i
Die a0 , . . . an sind unbekannte Parameter, die aus vorliegenden
Beobachtungen {[xi , yi ], i = 0, . . . , m} geschätzt werden sollen.
Die Beobachtungen sind durch (ebenfalls unbekannte) zufällige
Störgrößen i verrauscht.
I E [i ] = 0 Alle Störgrößen haben Mittelwert 0.
2
I E [i ] = σ 2 gleiche Varianz.
I E [i j ] = 0 für i 6= j unkorellierte Störgrößen
Satz von Gauß-Markow
Der Kleinste-Quadrate-Schätzer ist ein bester linearer erwartungstreuer
Schätzer, englisch: Best Linear Unbiased Estimator, kurz: BLUE
Polynomiale Regression Schätzen von Modellparametern 12 / 52Schätzen von Modellparametern
Die Methode der kleinsten Quadrate ist das Standardverfahren zur
Schätzung von Modellparametern. Unter bestimmten Annamen liefert sie
eine in gewissem Sinn „beste“ Schätzung. Für den Spezialfall polynomiale
Regression:
I yi = a0 + a1 xi + a2 xi2 + · · · + an xin + i
Die a0 , . . . an sind unbekannte Parameter, die aus vorliegenden
Beobachtungen {[xi , yi ], i = 0, . . . , m} geschätzt werden sollen.
Die Beobachtungen sind durch (ebenfalls unbekannte) zufällige
Störgrößen i verrauscht.
I E [i ] = 0 Alle Störgrößen haben Mittelwert 0.
2
I E [i ] = σ 2 gleiche Varianz.
I E [i j ] = 0 für i 6= j unkorellierte Störgrößen
Satz von Gauß-Markow
Der Kleinste-Quadrate-Schätzer ist ein bester linearer erwartungstreuer
Schätzer, englisch: Best Linear Unbiased Estimator, kurz: BLUE
Polynomiale Regression Schätzen von Modellparametern 12 / 52Schätzen von Modellparametern
Die Methode der kleinsten Quadrate ist das Standardverfahren zur
Schätzung von Modellparametern. Unter bestimmten Annamen liefert sie
eine in gewissem Sinn „beste“ Schätzung. Für den Spezialfall polynomiale
Regression:
I yi = a0 + a1 xi + a2 xi2 + · · · + an xin + i
Die a0 , . . . an sind unbekannte Parameter, die aus vorliegenden
Beobachtungen {[xi , yi ], i = 0, . . . , m} geschätzt werden sollen.
Die Beobachtungen sind durch (ebenfalls unbekannte) zufällige
Störgrößen i verrauscht.
I E [i ] = 0 Alle Störgrößen haben Mittelwert 0.
2
I E [i ] = σ 2 gleiche Varianz.
I E [i j ] = 0 für i 6= j unkorellierte Störgrößen
Satz von Gauß-Markow
Der Kleinste-Quadrate-Schätzer ist ein bester linearer erwartungstreuer
Schätzer, englisch: Best Linear Unbiased Estimator, kurz: BLUE
Polynomiale Regression Schätzen von Modellparametern 12 / 52Schätzen von Modellparametern
Die Methode der kleinsten Quadrate ist das Standardverfahren zur
Schätzung von Modellparametern. Unter bestimmten Annamen liefert sie
eine in gewissem Sinn „beste“ Schätzung. Für den Spezialfall polynomiale
Regression:
I yi = a0 + a1 xi + a2 xi2 + · · · + an xin + i
Die a0 , . . . an sind unbekannte Parameter, die aus vorliegenden
Beobachtungen {[xi , yi ], i = 0, . . . , m} geschätzt werden sollen.
Die Beobachtungen sind durch (ebenfalls unbekannte) zufällige
Störgrößen i verrauscht.
I E [i ] = 0 Alle Störgrößen haben Mittelwert 0.
2
I E [i ] = σ 2 gleiche Varianz.
I E [i j ] = 0 für i 6= j unkorellierte Störgrößen
Satz von Gauß-Markow
Der Kleinste-Quadrate-Schätzer ist ein bester linearer erwartungstreuer
Schätzer, englisch: Best Linear Unbiased Estimator, kurz: BLUE
Polynomiale Regression Schätzen von Modellparametern 12 / 52Beispiel zur Parameter-Schätzung
Dazu gibt es eine MATLAB-Datei
Annahme: linearer Zusammenhang
1 3
y = a + bx mit a = − , b =
2 4
Zehn Messpunkte, mit
normalverteilten Störgrößen
verrauscht, σ = 12 .Beispiel zur Parameter-Schätzung
Dazu gibt es eine MATLAB-Datei
Annahme: linearer Zusammenhang
1 3
y = a + bx mit a = − , b =
2 4
Zehn Messpunkte, mit
normalverteilten Störgrößen
verrauscht, σ = 12 .
Ausgleichsgerade, geschätzte
â = 0,016 ; b̂ = 0,385 ;Beispiel zur Parameter-Schätzung
Dazu gibt es eine MATLAB-Datei
Annahme: linearer Zusammenhang
1 3
y = a + bx mit a = − , b =
2 4
Zehn Messpunkte, mit
normalverteilten Störgrößen
verrauscht, σ = 12 .
Ausgleichsgerade, geschätzte
â = 0,016 ; b̂ = 0,385 ; σ̂ = 0,390
Jede Wiederholung der Messung mit anders gestörten Datenpunkten
würde andere Schätzungen für a und b liefern. Was lässt sich über die
Unsicherheit der Schätzungen aussagen?Beispiel zur Parameter-Schätzung: 1000 Experimente
Annahme: linearer Zusammenhang
1 3
y = a + bx mit a = − , b =
2 4
Zehn Messpunkte, normalverteilt mit
σ = 21 verrauscht.
Gezeigt sind ab-Schätzungen aus 1000
Wiederholungen. Die Werte streuen in
einer elliptischen RegionBeispiel zur Parameter-Schätzung: 1000 Experimente
Annahme: linearer Zusammenhang
1 3
y = a + bx mit a = − , b =
2 4
Zehn Messpunkte, normalverteilt mit
σ = 21 verrauscht.
Gezeigt sind ab-Schätzungen aus 1000
Wiederholungen. Die Werte streuen in
einer elliptischen Region
Die Ellipse mit Hauptachsen je eine
Standardabweichung ist eingetragen.
Die Streuung entlang der a- bzw. Kovarianzmatrix Cov =
b-Achse lässt sich aus der
Kovarianzmatrix ablesen: 2 T −1 0.086 −0.061
σ (A A) =
−0.061 0.061
p p
Cov11 = 0,294 ; Cov22 = 0,248Parameter-Schätzung und Gauß-Markov Theorem
Annahme: linearer Zusammenhang
1 3
y = a + bx mit a = − , b =
2 4
Zehn Messpunkte, normalverteilt mit
σ = 21 verrauscht.
Gezeigt sind ab-Schätzungen aus 500
Wiederholungen mit den 2σ
Fehlerellipsen. Blau: Kleinste Quadrate,
Rot: Kleinste 1-Norm.
Satz von Gauß-Markow
Der Kleinste-Quadrate-Schätzer ist ein bester linearer erwartungstreuer
Schätzer, englisch: Best Linear Unbiased Estimator, kurz: BLUEParameter-Schätzung: Konfidenzintervalle Die MATLAB-Datei in den Unterlagen zeigt sowohl explizit die Formeln als auch den Aufruf des curve-fitting tools Linear model Poly1: fitresult(x) = p1*x + p2 Coefficients (with 95% confidence bounds): p1 = 0.3279 (-0.04482, 0.7007) p2 = 0.1589 (-0.2833, 0.6011) werden aus der geschätzten Varianz mittels Student-t-Verteilung bestimmt. Die strichlierten Grenzen, prediction bounds, beziehen sich nicht auf die Genauigkeit der Modell-Voraussagen, sondern sagen den Streubereich weiterer Messungen voraus: mit 95%iger Wahrscheinlichkeit liegt ein weiter Messpunkt innerhalb der Grenzen.
Parameter-Schätzung: Konfidenzintervalle
Die MATLAB-Datei in den Unterlagen zeigt sowohl explizit die Formeln als auch
den Aufruf des curve-fitting tools
Linear model Poly1:
fitresult(x) = p1*x + p2
Coefficients (with 95% confidence bounds):
p1 = 0.3279 (-0.04482, 0.7007)
p2 = 0.1589 (-0.2833, 0.6011)
werden aus der geschätzten Varianz
mittels Student-t-Verteilung bestimmt.
Die strichlierten Grenzen, prediction
bounds, beziehen sich nicht auf die
Genauigkeit der Modell-Voraussagen,
sondern sagen den Streubereich weiterer
Messungen voraus: mit 95%iger
Wahrscheinlichkeit liegt ein weiter Übrigens: zufällig ist das ein Fall, wo
Messpunkt innerhalb der Grenzen. das Konfidenzintervall die tatsächlichen
Werte a = −0.5 ; b = 0.75 nicht
enthält. Sollte nur in 5% der Fälle
passieren, aber: Demonstrationseffekt!Gliederung 6. Vorlesung
1 Polynomiale Regression
Aufgabenstellung und Lösungsweg
Ausgleichsgerade (klassisch, robust, total)
Schätzen von Modellparametern
2 Polynomiale Interpolation
Rechenverfahren
Ansatz in Standard-Form, Vandermonde-Matrix
Polynom in Lagrange-Form
Polynome in verschiedenen Basis-Darstellungen
Polynom in Newton-Form
Warnung vor zu hohem Grad!
Runge-Phänomen
3 Spline-Interpolation etc.
4 Numerische Integration
Klassisch: Newton-Cotes
Weitere Quadraturformeln
Polynomiale Interpolation 17 / 52Interpolation
Definition der Aufgabenstellung
Gegeben:
Datenpunkte
Gesucht:
I Eine Funktion, die durch die gegebenen Datenpunkte verläuft.
I Ein Wert zwischen den Datenpunkten
I Trend über den gegebenen Datenbereich hinaus: Extrapolation
Anwendung:
Zwischenwerte in Tabellen, „glatte“ Kurven für Graphik. . .
Polynomiale Interpolation 18 / 52Interpolation
Gegeben: Datenpunkte. An Stützstellen xi liegen Werte yi vor.
Gesucht: Funktion f mit f (xi ) = yi
f(x)=?
x0 x1 x2 x3Beispiel: Interpolation in Tabellen
Spezifische Wärmekapazität 1300
von kohlenstoffarmem Stahl in 1200
J/kg K für 20 C ≤ T ≤ 700, C
1100
T cp
1000
20 447
173 500 900
200 509 800
400 595
543 700 700
600 763 600
626 800
500
700 909
400
0 100 200 300 400 500 600 700 800 900
Die Abbildung illustriert stückweise lineare Interpolation zwischen den
Stützstellen und Extrapolation bis 900 C.Polynomiale Interpolation
Die einfachsten Interpolations-Funktionen sind Polynome...
Durch zwei Punkte der xy -Ebene geht genau eine Gerade. Durch drei
beliebige Punkte lässt sich eindeutig eine Parabel legen. Durch n + 1
Punkte ist ein Polynom n-ten Grades eindeutig bestimmt.
Aufgabenstellung:
I gegeben n + 1 Wertepaare (xi , yi ), i = 0, . . . , n,
I gesucht ist das eindeutig bestimmte Polynom n-ten Grades p, das
durch die gegebenen Datenpunkte verläuft:
p(xi ) = yi für i = 0, . . . , n
.
Polynomiale Interpolation Rechenverfahren 21 / 52Polynomiale Interpolation
Die einfachsten Interpolations-Funktionen sind Polynome...
Durch zwei Punkte der xy -Ebene geht genau eine Gerade. Durch drei
beliebige Punkte lässt sich eindeutig eine Parabel legen. Durch n + 1
Punkte ist ein Polynom n-ten Grades eindeutig bestimmt. (Ausnahme,
wenn x -Werte zusammenfallen)
Aufgabenstellung:
I gegeben n + 1 Wertepaare (xi , yi ), i = 0, . . . , n, wobei die xi
paarweise verschieden sind.
I gesucht ist das eindeutig bestimmte Polynom n-ten Grades p, das
durch die gegebenen Datenpunkte verläuft:
p(xi ) = yi für i = 0, . . . , n
.
Polynomiale Interpolation Rechenverfahren 21 / 52Rechenverfahren zur polynomialen Interpolation I Direkter Ansatz in der Standard-Form, Gleichungssystem mit Vandermonde-Matrix. Mehr Rechenaufwand als bei den folgenden Methoden. I Lagrangesches Interpolationspolynom: Eine Formel, die das Polynom direkt hinschreibt. I Newtonsches Interpolationspolynom: besonders rechengünstig. I Es gibt noch einige andere Rechenschemen (im Skript: Neville-Verfahren; wir lassen es heuer aus) Trotz unterschiedlicher Namen und Schreibweisen liefern alle Verfahren dasselbe (eindeutig bestimmte) Polynom. Polynomiale Interpolation Rechenverfahren 22 / 52
Rechenverfahren zur polynomialen Interpolation I Direkter Ansatz in der Standard-Form, Gleichungssystem mit Vandermonde-Matrix. Mehr Rechenaufwand als bei den folgenden Methoden. I Lagrangesches Interpolationspolynom: Eine Formel, die das Polynom direkt hinschreibt. I Newtonsches Interpolationspolynom: besonders rechengünstig. I Es gibt noch einige andere Rechenschemen (im Skript: Neville-Verfahren; wir lassen es heuer aus) Trotz unterschiedlicher Namen und Schreibweisen liefern alle Verfahren dasselbe (eindeutig bestimmte) Polynom. Polynomiale Interpolation Rechenverfahren 22 / 52
Ansatz in der Standard-Darstellung
Das Interpolationspolynom in der Standard-Form
p(x ) = a0 + a1 x + a2 x 2 + · · · + an x n
Gesucht sind die Koeffizienten a0 , . . . , an .
Die Gleichungen p(xi ) = yi ergeben ein Gleichungssystem mit
Vandermonde-Matrix
1 x0 x02 x03 . . . x0n a0 y0
2 3 n
1 x1 x1 x1 . . . x1 a1 y1
· .. = ..
. . .. .. ..
. .
. . . . . . .
2 3
1 xn xn xn . . . xn n an yn
Die gute Nachricht: Falls alle x -Werte verschieden sind, ist das Gleichungssystem
eindeutig lösbar.
Die schlechte Nachricht: Diese Matrix kann sehr hohe Konditionszahl haben. Bei
Polynomen höheren Grades entstehen gravierende Rundungsfehler. MATLAB’s Befehl
polyfit verwendet diesen Ansatz (mit all seinen Vor- und Nachteilen).
Polynomiale Interpolation Rechenverfahren 23 / 52Lagrangesche Interpolationsformel
Das Interpolationspolynom durch die n + 1 Wertepaare
(xi , yi ), i = 0, . . . , n ist gegeben durch
p(x ) = L0 (x )y0 + L1 (x )y1 + ... + Ln (x )yn ,
wobei
(x − x0 )(x − x1 )...(x − xi−1 )(x − xi+1 )...(x − xn )
Li (x ) =
(xi − x0 )(xi − x1 )...(xi − xi−1 )(xi − xi+1 )...(xi − xn )
Es ist für die rechnerische Durchführung nicht ratsam, nach Einsetzen der Datenpunkte
die Li (x ) durch symbolisches Ausmultiplizieren noch weiter zu „vereinfachen“. Die
x -Werte direkt einsetzen!
Polynomiale Interpolation Rechenverfahren 24 / 52Lagrangesche Interpolationsformel
Das Interpolationspolynom durch die n + 1 Wertepaare
(xi , yi ), i = 0, . . . , n ist gegeben durch
p(x ) = L0 (x )y0 + L1 (x )y1 + ... + Ln (x )yn ,
wobei
(x − x0 )(x − x1 )...(x − xi−1 )(x − xi+1 )...(x − xn )
Li (x ) =
(xi − x0 )(xi − x1 )...(xi − xi−1 )(xi − xi+1 )...(xi − xn )
Es ist für die rechnerische Durchführung nicht ratsam, nach Einsetzen der Datenpunkte
die Li (x ) durch symbolisches Ausmultiplizieren noch weiter zu „vereinfachen“. Die
x -Werte direkt einsetzen!
Polynomiale Interpolation Rechenverfahren 24 / 52Polynome in verschiedenen Basis-Darstellungen Ein Polynom p(x ) lässt sich auf unterschiedliche Art als Summe von Termen der Form Koeffizient mal Basisfunktion anschreiben. Darstellungen I Standardbasis p(x ) = a0 + a1 x + a2 x 2 + · · · + an x n p ist Linearkombination der Basis-Polynome 1, x , x 2 , . . . , x n I Lagrange-Basis p(x ) = y0 L0 (x ) + y1 L1 (x ) + · · · + yn Ln (x ) p ist Linearkombination der Lagrange-Polynome L0 , L1 , . . . , Ln I Newton-Basis p(x ) = c0 +c1 (x −x0 )+c2 (x −x0 )(x −x1 )+· · ·+cn (x −x0 ) · · · (x −xn−1 ) p ist Linearkombination der Basis-Polynome 1, (x − x0 ), (x − x0 )(x − x1 ), (x − x0 )(x − x1 )(x − x2 ), . . . , (x − x0 )(x − x1 ) · · · (x − xn−1 ) Polynomiale Interpolation Rechenverfahren 25 / 52
Newtons Interpolations-Algorithmus I Ansatz mit Newton-Basisfunktionen I Das Schema der dividierten Differenzen berechnet mit wenig Aufwand die Koeffizienten I Auswertung des Polynoms effizient mit Horner-Schema. Polynomiale Interpolation Rechenverfahren 26 / 52
Newtons Interpolations-Algorithmus
Ansatz mit Newton-Basisfunktionen
p(x ) = c0 + c1 (x − x0 ) + c2 (x − x0 )(x − x1 ) + · · · + cn (x − x0 ) · · · (x − xn )
Gesucht sind die Koeffizienten c0 , . . . , cn .
Die Gleichungen p(xi ) = yi ergeben ein Gleichungssystem mit unterer
Dreiecksmatrix. Die Koeffizienten c0 , . . . , cn lassen sich einfach berechnen.
1 0 c0 y0
1 (x − x ) c y
1 0 1 1
. .
1 (x2 − x0 ) (x2 − x0 )(x2 − x1 )
· . = .
. .. . .
. ..
. . .
Qn−1
1 (xn − x0 ) ··· i=0 (xn − xi ) cn yn
Polynomiale Interpolation Rechenverfahren 27 / 52Newtons Interpolations-Algorithmus
Beispiel: kubisches Polynom
Daten: Ansatz:
p(x ) =c0 + c1 · (x − x0 )+
+ c2 · (x − x0 )(x − x1 )+
+ c3 · (x − x0 )(x − x1 )(x − x2 )
Einsetzen der vier Wertepaare xi , yi gibt Gleichungssystem der Form
c0 = y0
c0 + c1 (x1 − x0 ) = y1
c0 + c1 (x2 − x0 ) + c2 (x2 − x0 )(x2 − x1 ) = y2
c0 + c1 (x3 − x0 ) + c2 (x3 − x0 )(x3 − x1 ) + c3 (x3 − x0 )(x3 − x1 )(x3 − x2 ) = y3
Auflösen von oben nach unten:
y1 − y0
c0 = y0 , c1 = ,...
x1 − x0
Polynomiale Interpolation Rechenverfahren 28 / 52Newtons Interpolations-Algorithmus
Das Schema der dividierten Differenzen ist ein optimierter Rechenablauf
zur Lösung des Gleichungssystems mit unterer Dreiecksmatrix
Mit Papier und Stift organisiert man die Rechnung am besten in
Tabellenform nach folgendem Schema
x0 y0
x1 − x0 [x0 , x1 ]
x2 − x0 x1 y1 [x0 , x1 , x2 ]
x2 − x1 [x1 , x2 ]
. . . x3 − x1 x2 y2 [x1 , x2 , x3 ] . . .
x3 − x2 [x2 , x3 ]
x4 − x2 x3 y3 [x2 , x3 , x4 ]
x4 − x3 [x3 , x4 ]
x4 y4
Beispiele siehe Skript!
Polynomiale Interpolation Rechenverfahren 29 / 52Warnung vor zu hohem Grad!
200
175
150
125
100
75
50
25
50 100 150 200 250
16 Datenpunkte sind gegeben. Gesucht ist eine „schöne“ Kurve durch diese
Punkte. Die hier gezeichnete Kurve approximiert, aber interpoliert nicht!
Ein Polynom 15. Grades könnte die Daten exakt modellieren, aber. . .
Polynomiale Interpolation Warnung vor zu hohem Grad! 30 / 52Warnung vor zu hohem Grad!
200
175
150
125
100
75
50
25
50 100 150 200 250
Kein Fehler an den Datenpunkten, aber dazwischen oszilliert das Polynom heftig.
Typisch für Polynome hohen Grades. Sie oszillieren besonders zu den Rändern hin,
wenn man Sie durch vorgegebene Datenpunkte zwingt.
Polynomiale Interpolation Warnung vor zu hohem Grad! 31 / 52Nochmal: Warnung vor zu hohem Grad!
Beispiel von vorhin: 1000
spezifische Wärme cp bei Datenpunkte
Interpolationspolynom
Temperatur T . 900
800
Durch die acht
Datenpunkte lässt sich ein 700
Polynom siebten Grades
exakt durchlegen. 600
500
400
0 100 200 300 400 500 600 700 800 900Nochmal: Warnung vor zu hohem Grad!
Beispiel von vorhin: 1000
spezifische Wärme cp bei Datenpunkte
Interpolationspolynom
Temperatur T . 900
800
Durch die acht
Datenpunkte lässt sich ein 700
Polynom siebten Grades
exakt durchlegen. 600
Aber: 500
Polynome so hohen Grades
neigen zu Oszillationen und 400
0 100 200 300 400 500 600 700 800 900
zu extrem unrealistischer
ExtrapolationInterpolationspolynome hohen Grades sind ungeeignet!
1
Approximation der Funktion f (x ) = 1+x 2
, x ∈ [−5, 5] mit 3, 7, 11 und 17
Stützstellen:
11 Stuetzstellen 11 Stuetzstellen
4 4
3.5 3.5
3 3
2.5 2.5
2 2
1.5 1.5
1 1
0.5 0.5
0 0
−0.5 −0.5
−1 −1
−5 0 5 −5 0 5
11 Stuetzstellen 11 Stuetzstellen
4 4
3.5 3.5
3 3
2.5 2.5
2 2
1.5 1.5
1 1
0.5 0.5
0 0
−0.5 −0.5
−1 −1
−5 0 5 −5 0 5„Interpolationspolynome hohen Grades sind ungeeignet“ – Vorsicht, Übertreibung! Die Folien gebrauchen hier das rhetorischen Stilmittel der Übertreibung. Es gilt nämlich Approximationssatz von Weierstraß Jede stetige Funktion lässt sich auf einem abgeschlossenen Intervall beliebig genau durch Polynome approximieren. Die Probleme treten bei Interpolation auf, wenn das Polynom durch irgendwie vorgegebene Stützstellen gehen soll. Es gibt speziell verteilte Tschebyschow-Stützstellen, für die Interpolationspolynome besonders günstige Eigenschaften haben.
Runge-Phänomen
Interpolationspolynome mit äquidistenten Stützstellen konvergieren nicht unbedingt
1
Noch einmal am Beispiel von f (x ) = 1+x 2
y
x
Grad 4Runge-Phänomen
Interpolationspolynome mit äquidistenten Stützstellen konvergieren nicht unbedingt
1
Noch einmal am Beispiel von f (x ) = 1+x 2
y
x
Grad 6Runge-Phänomen
Interpolationspolynome mit äquidistenten Stützstellen konvergieren nicht unbedingt
1
Noch einmal am Beispiel von f (x ) = 1+x 2
y
x
Grad 8 — Im mittleren Bereich nähern die Polynome immer besser, in den
Randbereichen werden die Fehler immer größer!Tschebyschow-Stützstellen
Nicht äquidistant, sondern zu den Rändern hin dichter
y
x
Grad 4Tschebyschow-Stützstellen
Nicht äquidistant, sondern zu den Rändern hin dichter
y
x
Grad 6Tschebyschow-Stützstellen
Nicht äquidistant, sondern zu den Rändern hin dichter
y
x
Grad 8 — das sieht wesentlich besser aus als vorher mit äquidistanten
Stützstellen!Optimale Lage der Stützstellen
Projektion von n gleichmäßig am Halbkreis verteilten Punkten
Bei dieser Wahl der Stützstellen („Tschebyschow-Stützstellen“) ist die
maximale Abweichung Funktion–Polynom am kleinsten
Lage auf Intervall [−1; 1]
2i − 1
xi = cos π für i = 1, . . . , n
2nGliederung 6. Vorlesung
1 Polynomiale Regression
Aufgabenstellung und Lösungsweg
Ausgleichsgerade (klassisch, robust, total)
Schätzen von Modellparametern
2 Polynomiale Interpolation
Rechenverfahren
Warnung vor zu hohem Grad!
3 Spline-Interpolation etc.
4 Numerische Integration
Klassisch: Newton-Cotes
Weitere Quadraturformeln
Spline-Interpolation etc. 38 / 52Weitere Interpolationsverfahren
Klassische Newton- oder Lagrange-Interpolation ist nicht immer optimal
Andere wichtige Verfahren sind
I Spline-Interpolation (Kubisch, MATLAB pchip,...)
I Rationale Interpolation
I Trigonometrische Interpolation
I Interpolation in zwei oder mehr Dimensionen
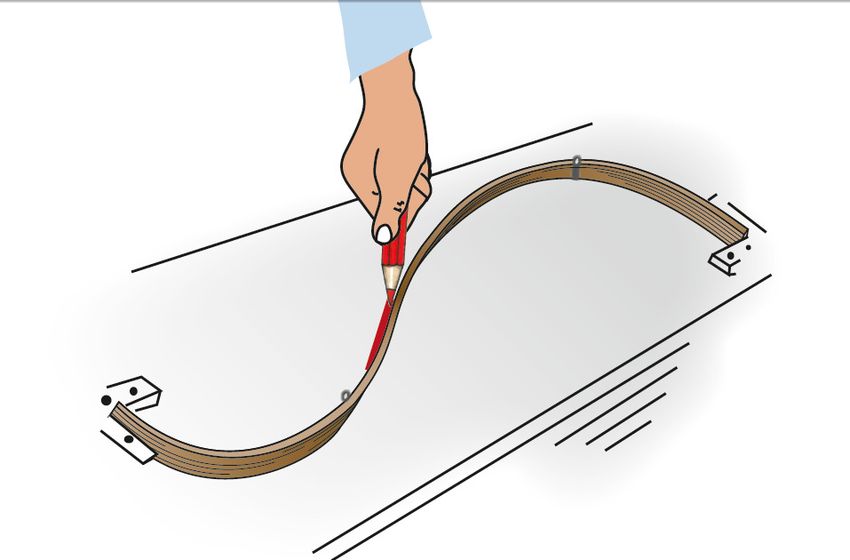
Spline-Interpolation etc. 39 / 52Biegsame Latte als Kurvenlineal Ursprünglich im Schiffsbau verwendet, heißt Straklatte, englisch Spline. Funktionen, die das Verhalten biegsamer Latten nachbilden: Natürliche kubische Spline-Funktionen. Spline-Interpolation etc. 40 / 52
Natürlicher kubischer Spline
Eine dünne, an einzelnen Punkten festgehaltene Latte biegt sich in der
Form eines kubischen Splines
0.4
0.3
0.2
0.1
1 2 3 4Natürlicher kubischer Spline
Ein natürlicher kubischer Spline s(x ) durch die n + 1 Wertepaare (xi , yi ),
i = 0, . . . , n ist folgendermaßen charakterisiert:
I In den einzelnen Intervallen (xi−1 , xi ) ist s(x ) jeweils ein kubisches
Polynom
I An den Intervallgrenzen stimmen die Funktionswerte, die ersten und
die zweiten Ableitungen rechts- und linksseitig überein.
I Zweite Ableitung an den Rändern wird Null gesetzt.
Spline-Interpolation etc. 42 / 52Anderer kubische Splines
Ein Spline ist stückweise aus einzelnen Polynomen zusammengesetzt. Je
nach Spline-Typ werden weitere Bedingungen gewählt. MATLAB’s pchip
erfüllt:
I In den einzelnen Intervallen (xi−1 , xi ) ist s(x ) jeweils ein kubisches
Polynom
I An den Intervallgrenzen stimmen die Funktionswerte und die ersten
Ableitungen rechts- und linksseitig überein. Die zweiten Ableitungen
können unterschiedlich sein.
I Der Spline respektiert das Monotonieverhalten der Datenpunkte –
kein Überschwingen
Spline-Interpolation etc. 43 / 52Interpolation in Matlab: spline und pchip
x = -3:3; 1.5
y = [-1 -1 -1 0 1 1 1];
t = -3:.01:3; 1
p = pchip(x,y,t);
s = spline(x,y,t); 0.5
plot(x,y,’o’,t,p,’-’,
t,s,’-.’)
0
−0.5
−1
Daten
pchip
spline
−1.5
−3 −2 −1 0 1 2 3
MATLAB bietet verschiedene stückweise kubische Interpolationsverfahren.
spline ist für glatte Daten genauer.
pchip überschwingt nicht und neigt weniger zu Oszillationen.Beispiel: cp -Daten mit spline und pchip
Innerhalb des 1300
Datenbereiches stimmen 1200
beide Verfahren sichtlich 1100
überein. 1000
900
800
700
600
500 blau: Spline
grün: PCHIP
400
300
−200 0 200 400 600 800 1000Beispiel: cp -Daten mit spline und pchip
Innerhalb des 1300
Datenbereiches stimmen 1200
beide Verfahren sichtlich 1100
überein. 1000
Extrapolation ist ein 900
wesentlich riskanteres 800
Geschäft. . . 700
600
500 blau: Spline
grün: PCHIP
400
300
−200 0 200 400 600 800 1000Beispiel: cp -Daten mit spline und pchip
Innerhalb des 1300
Datenbereiches stimmen 1200
beide Verfahren sichtlich 1100
überein. 1000
Extrapolation ist ein 900
wesentlich riskanteres 800
Geschäft. . . 700
. . . wie man sieht: hier sind 600
weitere Datenpunkte 500
eingetragen. Keine der 400
beiden Methoden
300
extrapoliert den −200 0 200 400 600 800 1000
tatsächlichen Verlauf der
spez. Wärme korrekt.Interpolationsverfahren
Übersicht und Zusammenfassung
I Newton-Polynom: rechengüstig; zusätzliche Datenpunkte lassen sich
leicht anfügen
I Lagrange-Polynom: y -Werte lasen sich leicht ändern
I Polynome mit hohem Grad und äquidistanten Stützstellen:
Ungeeignet! (Runge-Phänomen).
I Tschebysheff-Stützstellen: optimale Approximation
I Natürliche kubische Splines: meist bessere Anpassung als Polynome.
I Es gibt viele weitere Spline-VariantenGliederung 6. Vorlesung
1 Polynomiale Regression
Aufgabenstellung und Lösungsweg
Ausgleichsgerade (klassisch, robust, total)
Schätzen von Modellparametern
2 Polynomiale Interpolation
Rechenverfahren
Warnung vor zu hohem Grad!
3 Spline-Interpolation etc.
4 Numerische Integration
Klassisch: Newton-Cotes
Weitere Quadraturformeln
Numerische Integration 47 / 52Numerische Integration
Gegeben:
eine Funktion f (x ) in einem Intervall a ≤ x ≤ b.
Gesucht:
Z b
deren Integral f (x )dx
a
Oft lässt sich das Integral nicht durch elementare Funktionen ausdrücken,
oder die Funktion selbst ist nur tabellarisch gegeben. −→ Numerische
Verfahren
Numerische Integration 48 / 52Integrationsformeln nach Newton-Cotes
Gegeben:
Eine Funktion f (x ) in einem Intervall (a, b) durch ihre Werte fi an n + 1
äquidistanten Stützstellen,
b−a
fi = f (a + ih), mit h = , i = 0, . . . , n.
n
Prinzip:
Interpoliere f (x ) durch ein Polynom p(x ). Nähere das Integral von f durch
das Integral von p. Die Näherung ist gegeben als gewichtete Summe der fi ,
Z b n
X
f (x )dx ≈ (b − a) α i fi
a i=0
mit fixen Gewichten αi
Numerische Integration 49 / 52Newton-Cotes-Formeln
Klassische Beispiele mit Fehlertermen
Trapezregel
Z b
b−a 3
f (x )dx = (f (a) + f (b)) − (b−a)
12
f 00 (ξ)
a 2
Simpson-Regel
Z b
b−a a+b
5
f (x )dx = f (a) + 4f ( ) + f (b) − (b−a)
2880
f IV (ξ)
a 6 2
3/8-Regel („pulcherrima“)
Z b
b−a 5
f (x )dx = (f (a) + 3f (a + h) + 3f (a + 2h) + f (b)) − (b−a)
6480
f IV (ξ)
a 8Newton-Cotes-Formeln
Klassische Beispiele mit Fehlertermen
Trapezregel
Z b
b−a 3
f (x )dx = (f (a) + f (b)) − (b−a)
12
f 00 (ξ)
a 2
Simpson-Regel
Z b
b−a a+b
5
f (x )dx = f (a) + 4f ( ) + f (b) − (b−a)
2880
f IV (ξ)
a 6 2
3/8-Regel („pulcherrima“)
Z b
b−a 5
f (x )dx = (f (a) + 3f (a + h) + 3f (a + 2h) + f (b)) − (b−a)
6480
f IV (ξ)
a 8Zusammengesetzte N.-C.-Formeln
Wenn feinere Intervallteilung vorliegt
Achtung bei Intervallbreite h! Es sind n + 1 Datenpunkte, und um eins
weniger Intervalle. n= Anzahl Datenpunkte-1, und h = (b − a)/n
Zusammengesetzte Trapezregel
Z b
h
f (x )dx = (f0 + 2f1 + 2f2 + · · · + 2fn−1 + fn ) + E
a 2
Zusammengesetzte Simpson-Regel
Z b
h
f (x )dx = (f0 + 4f1 + 2f2 + 4f3 + · · · + 2fn−2 + 4fn−1 + fn ) + E
a 3
(Nur für gerades n möglich!)
Numerische Integration Klassisch: Newton-Cotes 51 / 52Zusammengesetzte N.-C.-Formeln
Wenn feinere Intervallteilung vorliegt
Achtung bei Intervallbreite h! Es sind n + 1 Datenpunkte, und um eins
weniger Intervalle. n= Anzahl Datenpunkte-1, und h = (b − a)/n
Zusammengesetzte Trapezregel
Z b
h
f (x )dx = (f0 + 2f1 + 2f2 + · · · + 2fn−1 + fn ) + E
a 2
Zusammengesetzte Simpson-Regel
Z b
h
f (x )dx = (f0 + 4f1 + 2f2 + 4f3 + · · · + 2fn−2 + 4fn−1 + fn ) + E
a 3
(Nur für gerades n möglich!)
Numerische Integration Klassisch: Newton-Cotes 51 / 52Weitere Quadraturformeln
Gauß-Quadratur, Gauß-Lobatto-Formeln
Nicht äquidistante Stützstellen, dafür höhere Genauigkeit. (Typische
Anwendung: Finite Elemente)
Romberg-Verfahren
berechnet mit zusammengesetzter Trapezregel mehrere Werte zu
verschiedenen h und extrapoliert auf h = 0.
MATLAB
bietet zwei Verfahren: quad (adaptive Simpson-Regel) und quadl
(trickreichere Gauß-Lobatto Methode)
Numerische Integration Weitere Quadraturformeln 52 / 52Sie können auch lesen

















































