TABLEAU DASHBOARDS MIT H2O AUF DIE NÄCHSTE INFORMATIONSSTUFE HEBEN - H2O VORHERSAGEN MIT TABLEAU VISUALISIEREN: Ancud IT-Beratung GmbH
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

Innovation. Menschen. Zukuft. H2O VORHERSAGEN MIT TABLEAU VISUALISIEREN: TABLEAU DASHBOARDS MIT H2O AUF DIE NÄCHSTE INFORMATIONSSTUFE HEBEN
ANOMALIEERKENNUNG IN DER PRODUKTION Sie nutzen Tableau, wollen sich aber nicht nur auf deskriptive Analysen be- schränken oder nutzen AutoML, arbeiten aber daran, die Ergebnisse in ihre Ent- scheidungsprozesse zu integrieren? Wir zeigen Ihnen in diesem Tutorial wie Sie die beiden Lösungen H2O AI und Tableau Desktop zu einem automatisiert laufenden Dashboard kombinieren. 1. VORAUSSETZUNG Für die Durchführung der Integration benötigt man folgendes: • Zugriff auf Driverless AI von H2O AI • Tableau Desktop und Tableau Prep Sie sollten mit den Grundlagen von Driverless AI und Tableau sowie Python vertraut sein.
2. EINRICHTUNG VON TABPY An der Schnittstelle zwischen beiden Tools wird Python-Code ausgeführt. Um dies umzusetzen wird das Open-Source-Tool TabPy genutzt. Hier erfahren Sie mehr dazu: https://github.com/tableau/TabPy Zuerst wird auf Ihrem System pip installiert und geupdatet: python -m pip install --upgrade pip Anschließend kann tapy installiert werden: pip install tabpy Falls Sie keine großen Datenmengen verwenden, können Sie TabPy mit den Stan- dardeinstellungen starten: tabpy Abb. 1: In der Konfigurationsdatei von TabPy muss die Zeit bis zum Timeout erhöht werden. Bei unserem Anwendungsfall mit größeren Datenmengen und Tableau Prep wird TabPy mit einem Timeout die Verbindung abbrechen. Die Standarddauer für die Anschließend kann TabPy mit der festgelegten Konfiguration gestartet werden: maximale Laufzeit liegt bei 30 Sekunden. Um dies zu ändern, erstellen Sie eine Config Datei z.B. nach dieser Vorlage: https://github.com/tableau/TabPy/ tabpy --config=Pfad/zum/config/file.conf Hier muss nun der Parameter „TABPY_EVALUATE_TIMEOUT“ entsprechend Nun sind Sie bereit, Python Skripte in Tableau Desktop und Tableau Prep aus- erhöht werden. Die Datei wird anschließend gespeichert. zuführen.

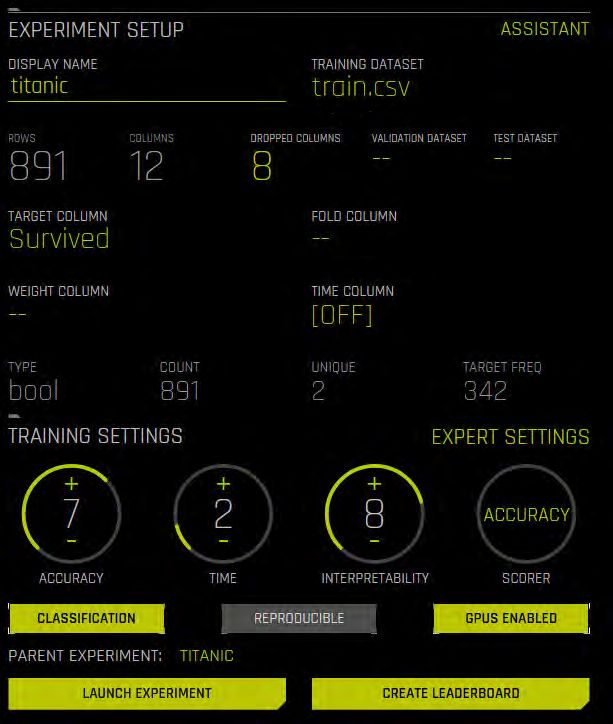
3. H2O SCORING PIPELINE STARTEN In diesem Abschnitt werden wir ein Modell auf Driverless AI von H2O AI erstellen und auf unserer gewünschten Umgebung starten. Wir zeigen das Vorgehen anhand des Titanic- Datensatzes: https://www.kaggle.com/c/titanic Der Datensatz enthält die Daten der Passagiere der Titanic, wie beispielsweise In- formationen über Alter, Geschlecht und die Tatsache, ob sie die Tragödie überlebt haben oder nicht. Das Ziel ist es, die Passagiere anhand ihrer Überlebenschance zu kategorisieren.kategorisieren. A. ERSTELLEN DES ML-MODELLS IN DRIVERLESS AI Zuerst muss wie gewöhnlich der Datensatz in Driverless AI geladen werden, um an- schließend ein Experiment zu starten. Für die genauere Vorgehensweise können Sie sich an die Tutorials von H2O AI halten: https://h2oai.github.io/tutorials/ Zur besseren Übersicht kann das Modell vorerst einfach gehalten und nur wenige Features verwendet werden. Wir haben uns in unserem Beispiel auf „Sex“, „Age“ und „Fare“ beschränkt, um „Survived“ vorherzusagen. Abb. 2: In der Konfigurationsdatei von TabPy muss die Zeit bis zum Timeout erhöht werden.

B. DEPLOYMENT DES MODELLS AUF DRIVERLESS AI
# Install the Requirements
Das eben erstellte Modell muss nun deployed werden, um als Service für andere
# Make all packages available on your instance
Anwendungen zur Verfügung zu stehen. Die einfachste Methode ist, die Deploy- sudo apt-get -y update
Möglichkeiten von Driverless AI zu nutzen. Das fertig trainierte Modell kann über
# Install Python 3.6 and related packages
„Deploy (Local & Cloud)“ als lokaler Rest Server verfügbar gemacht werden. sudo apt-get -y install python3.6 python-virtualenv python3.6-dev pyt-
hon3-pip python3-dev python3-virtualenv
# Install OpenBLAS for linear algebra calculations
sudo apt-get -y install libopenblas-dev
# Install Unzip for access to individual files in the scoring pipeline folder
sudo apt-get -y install unzip
# Install Java to include open source H2O-3 algorithms
sudo apt-get -y install openjdk-8-jdk
# Install tree to display environment directory structures
sudo apt-get -y install tree
Abb. 3: Model Deployment auf Driverless AI
# Install the thrift-compiler
sudo apt-get install automake bison flex g++ git libevent-dev \
libssl-dev libtool make pkg-config libboost-all-dev ant
wget https://github.com/apache/thrift/archive/0.10.0.tar.gz
tar -xvf 0.10.0.tar.gz
C. DEPLOYMENT DES MODELLS AUF IHREM WUNSCHSYSTEM cd thrift-0.10.0
./bootstrap.sh
Wir zeigen hier auch, wie Sie die Python Scoring Pipeline auf dem System ./configure
make
ihrer Wahl deployen können. Zuerst müssen alle benötigen Pakete installiert sudo make install
werden: [Quelle: https://h2oai.github.io/tutorials/scoring-pipeline-deployment-in-python-runtime/#2]
Anschließend erstellen Sie die Ordnerstruktur wie folgt. Ersetzen Sie dabei „titanic“ Sobald Ihre Pipeline heruntergeladen ist, müssen Sie diese auf das vorbereitete
mit dem beliebigen Namen Ihres Projekts. System verschieben und entpacken. Führen sie diesen Befehl in einer Komman-
dozeile durch, mit der Sie nicht mit dem Server verbunden sind.
mkdir -p $HOME/model-deployment/common/license
scp Pfad/zum/download/ordner/scorer.zip
mkdir -p $HOME/model-deployment/common/titanic/testData/{test-batch- nutzer@$Zielinstanz:$HOME/model-deployment/common/titanic/python-
data,test-real-time-data} scoring-pipeline/
mkdir -p $HOME/model-deployment/common/titanic/{mojo-scoring-pipeline/
Entpacken Sie nun auf Ihrer Zielinstanz die Scoring Pipeline
{java-runtime/java/mojo2-java-runtime,cpp-runtime/{c/mojo2-c-runtime/
{linux,macos-x,ibm-powerpc},r-wrapper/mojo2-r-runtime/{linux,macos-
x,ibm-powerpc},python-wrapper/mojo2-py-runtime/{linux,macos-x,ibm-po- cd $HOME/model-deployment/common/titanic/python-scoring-pipeline/
werpc}}},python-scoring-pipeline} unzip scorer.zip
mkdir -p $HOME/model-deployment/apps Anschließend sind Sie bereit, ihre Pipeline zu starten. Wechseln Sie dafür in den
tree model-deployment
[Quelle: https://h2oai.github.io/tutorials/scoring-pipeline-deployment-in-python-runtime/#2] Ordner der Scoring Pipeline und starten sie den http Server:
cd $HOME/model-deployment/common/titanic/python-scoring-pipeline/sco-
ring-pipeline
Ihre Umgebung ist nun bereit
bash run_http_client.sh
für das Machine Learning Modell, das
Sie im vorherigen Schritt erstellt haben. Ihre Instanz ist nun bereit, mit Tableau Desktop verbunden zu werden!
Laden Sie also die Python Scoring
Pipeline herunter.
Abb. 4: Laden Sie die Python Scoring Pipeline von
Driverless AI herunter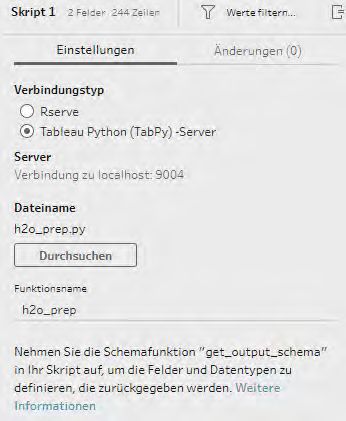
4. INTEGRATION VON H2O IN TABLEAU DESKTOP
An diesem Punkt sollte Ihr TabPy-Server und ihre Scoring Pipeline laufen und bereit Im sich öffnenden Fenster können Sie den Verbindungstyp auswählen. Hier wählen
für die Anbindung an Tableau Desktop sein. Sie TabPy. Nun geben Sie die Verbindungsdaten Ihres TabPy-Servers ein und
speichern Sie die Verbindung.
A. ANBINDUNG VON TABPY
Wir wenden uns nun Tableau Desktop zu. Navigieren Sie hier zu:
Hilfe > Einstellungen und Leistung > Verbindung für Analytics-Einstellung
verwalten…
Abb. 5: Verbinden Sie sich zu Ihrem TabPy-Server
Die Verbindung zu TabPy ist nun konfiguriert und Tableau Desktop damit in der
Abb. 5: Verbinden Sie sich zu Ihrem TabPy-Server Lage, Ihren Python Code auszuführen.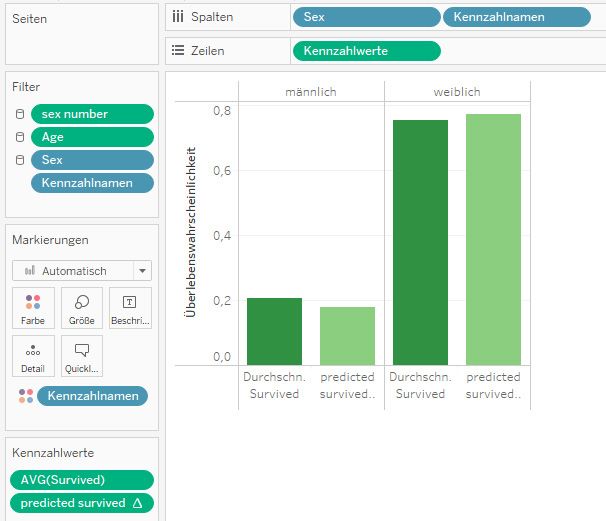
B. ANBINDUNG ZU SCORING PIPELINE UND ERSTELLEN VON BERECHNETEM
FELD MIT PYTHON
Laden Sie nun die Daten, die Sie visualisieren und vorhersagen wollen in Tableau. Die Argumente, die wir an SCRIPT_REAL übergeben, sind neben dem Python
Jetzt sind Sie soweit, Ihr eigenes berechnetes Feld mit Python Integration zu erstellen. Code MEDIAN([Age]), MEDIAN([Fare]), MEDIAN([sex number]).
Dieses Vorgehen eignet sich, um einfache Visualisierungen auf Basis von Aggregaten Die Aggregate können im Python Code als „_arg1“ bis „_argN“ referenziert werden.
zu erstellen.
Die Funktionen, die Ihnen zur Verfügung stehen sind SCRIPT_STR, SCRIPT_REAL,
SCRIPT_BOOL und SCRIPT_INT – je nachdem welches Dateiformat Ihr Feld hat. In
unserem Fall erwarten wir eine Wahrscheinlichkeit in Form einer reellen Zahl, benut-
zen Sie also SCRIPT_REAL. Diese Funktion erwartet ein R oder Python Skript und die
verwendeten Aggregate als Argumente. Wir arbeiten hier mit Python.
Abb. 8: Unser berechnetes Feld, das die Überlebenswahrscheinlichkeit vorhersagt
Der Python Code sendet einen Post-Request an die Instanz, auf der unsere
H2O-Scoring-Pipeline läuft. Die übertragenen Daten enthalten als Parameter
Abb. 7: Die Variablen, die Sie verwenden, müssen aggregierbar sein.
unsere gewählten Features. Die Antwort, die wir erhalten ist im JSON-Format.
Die numerische Antwort, die Tableau erwartet, muss aus diesem JSON- String
Wir haben in unserem Beispiel ein Textfeld „Sex“ verwendet. Um dieses zu aggregie- extrahiert werden. Den Weg, den die gesendeten Requests gehen, können Sie
ren, ist es nötig eine Hilfskennzahl zu erstellen. Diese Kennzahl benutzen wir nun bei in der TabPy-Kommandozeile und auf Ihrer Instanz, auf der die Scoring-Pipeline
der Integration von Python. läuft, nachvollziehen.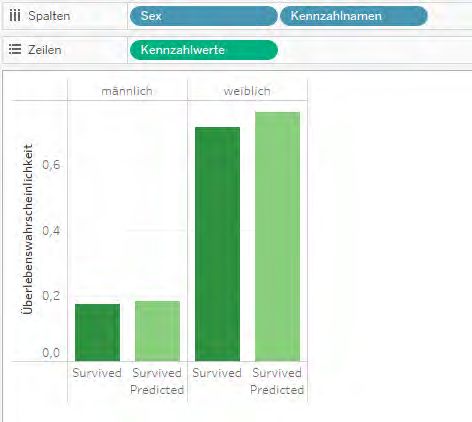
Wenn Sie nun das berechnete Feld in Ihr Arbeitsblatt einfügen beachten Sie zwei
Dinge: Die Scoring Pipeline kann NULL-Werte nicht verarbeiten. Sie sollten die-
se durch Tableau-Filter oder in Ihrer Python-Logik entfernen. Außerdem muss in
vielen Fällen, das Feld per Zelle berechnet werden, um die gewünschten Ergeb-
nisse zu erhalten. Verwenden Sie nun das berechnete Feld wie gewohnt ihn Ihren
Arbeitsblättern und Dashboards.
Abb. 9: Berechnen Sie das Feld per Zelle
Hierbei darf man nicht vergessen, dass Sie hier mit aggregierten Werten arbeiten.
Das Ergebnis im Beispielbild zeigt die Wahrscheinlichkeiten einer Frau bzw. eines
Mannes mit durchschnittlichem Alter und durchschnittlichem Ticketpreis. Wollen
Sie allerdings pro Person die Wahrscheinlichkeit berechnen und den Durchschnitt
davon anzeigen, folgen Sie dem nächsten Abschnitt. Abb. 10: Ein Worksheet mit den Daten, die durch die Scoring Pipeline erzeugt wurden
5. PYTHON SKRIPTS IN TABLEAU PREP-SCHEMAS ZUR INTEGRATION VON H2O MODELLEN
Um Vorhersagen für einzelne Zeilen des Datensatzes anzuwenden, ist es meist Um die H2O-Scoring-Pipeline in Tableau Prep zu verwenden, führen Sie die
nicht ausreichend, Tableau Desktop zu verwenden. Die Daten müssen mit Tableau Schritte 2 und 3 wie gehabt aus. Sie benötigen TabPy und die Scoring-Pipeline.
Prep präprozessiert werden. Tableau Prep wiederum bietet die Möglichkeit, kom-
plexere Szenarien abzubilden und benutzerdefinierte Python-Skripte auszuführen. Um TabPy in Tableau Prep zu integrieren, legen Sie ein neues Schema an. Ihre
TabPy-Konfiguration können Sie unter Hilfe > Einstellungen und Leistung >
Dies bietet den Vorteil einer höheren Geschwindigkeit. Die gewünschten Daten wer- Verwalten der Verbindung mit Analytics-Erweiterungen ändern.
den einmal generiert – das Modell muss also nur einmal ausgeführt werden. An-
schließend wird der Datensatz beispielsweise als .hyper-Datei gespeichert und kann
wie gewohnt verwendet werden. TabPy muss also auch nicht aktiv sein, wenn das
Dashboard aufgerufen wird. Dies ist lediglich nötig beim Erstellen der .hyper-Datei.
Darüber hinaus kann so die Vorhersage in komplexere Schemata integriert werden
und weiter bearbeitet werden.
A. VORBEREITUNGEN
Abb. 12: Stellen Sie die Verbindung zu TabPy ein
Stellen Sie nun die Verbindung zu Ihren Daten her. Anschließend Filtern Sie die
Abb. 11: Das Ziel ist, ein Schema dieser Struktur zu erstellen Daten, sodass keine NULL-Werte mehr bearbeitet werden.B. ERSTELLEN SIE IHR PYTHON SKRIPT
Im nächsten Schritt kommen wir nun zur Integration von H2O AI durch ein Speichern Sie dieses Skript und fügen es als nächsten Verarbeitungsschritt in Ihr
Python-Skript. Dieses Skript ist wie folgt aufgebaut: Tableau Schema ein.
Eine Funktion “get_output_schema()”: hier wird angegeben, welche Felder mit
welchem Datentyp und welchem Namen zurückgegeben werden
Quelle: https://help.tableau.com/current/prep/en-us/prep_scripts_TabPy.htm
Abb. 13: Diese Datentypen stehen zur Definition der Datentypen zur Verfügung
Eine Funktion mit einem beliebigen Namen. Hierbei ist folgendes zu beachten:
• Input ist ein Dataframe, der die von Tableau Prep übergebenen Daten enthält
•D ie Funktion enthält die Logik, also die Verbindung zur H2O-Scoring-Pipeline
•E s wird über alle Zeilen des Datensatzes iteriert, um für jede Zeile eine
Vorhersage zu erhalten
•G ibt einen Dataframe mit den Ergebnissen zurück. Hier sollte mindestens
die Vorhersage und eine ID als Rückgabe gewählt werden. So kann im Nach-
Abb. 14: Das Skript, um Titanic-Daten zu verarbeiten
gang das Ergebnis mit anderen Daten gejoined werden.C. FÜGEN SIE IHR SKRIPT ZUM SCHEMA HINZU
Im nächsten Schritt kommen wir nun zur Integration von H2O AI durch ein Diese generierte Datei kann nun in Tableau Desktop eingebunden werden und
Python-Skript. Dieses Skript ist wie folgt aufgebaut: Ihre Worksheets um Machine Learning Vorhersagen erweitern.
Fügen Sie einen neuen Verarbeitungsschritt „Skript“ in Tableau Prep hinzu.
Stellen Sie den Verbindungstyp auf „Tableau Python (TabPy)-Server“, fügen Sie
durch klick auf „Durchsuchen“ Ihr Skript ein und geben Sie unter „Funktionsna-
me“ Ihren frei gewählten Namen der Python-Funktion ein.
Abb. 16: Ein Worksheet mit den Daten, die durch Tableau Prep vorbereitet wurden
Abb. 15: Fügen Sie Ihr Skript hinzu und passen sie die Eigenschaften an
6. FAZIT
Nach der Ausführung des Skripts erhalten Sie die definierten Spalten zurück. In Sowohl Tableau als auch H2O AI bieten vielfältige Einsatzgebiete in unzähligen
unserem Fall lediglich zwei. Darum ist es sinnvoll, die Ergebnisse des Skripts mit Anwendungsbereichen. Dieses Tutorial kann nur einen ersten Einblick in die
dem ursprünglichen Datensatz zu joinen. Anschließend wird der präprozessier- Möglichkeiten bieten. Nutzen Sie Tableau Server? Auch hier ist eine Integration
te Datensatz in eine hyper- oder csv-Datei gespeichert. von H2O AI möglich. Gerne unterstützen wir Sie bei Ihren Problemstellungen!JETZT KONTAKT AUFNEHMEN
Ancud IT-Beratung GmbH 0911 25 25 680
Glockenhofstraße 47 info@ancud.de
90478 Nürnberg www.ancud.de
ANCUD IT AUF SOCIAL MEDIA ENTDECKEN
Facebook Instagram
LinkedIn XingSie können auch lesen

















































