Analyse von Unsicherheiten k unstlicher neuronaler Netze und Integration in die Objektverfolgung
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

Analyse von Unsicherheiten künstlicher
neuronaler Netze und Integration in die
Objektverfolgung
MASTERARBEIT
für die Prüfung zum
Master of Science
im Studiengang Informatik
an der Hochschule Ruhr West
von
Raphael Burkert
Matrikelnr. 10005624
Erstprüfer Prof. Dr.-Ing. Anselm Haselhoff
Zweitprüfer Fabian Küppers
Bottrop, Februar 2022
Eidesstattliche Erklärung
Hiermit versichere ich, dass ich
die vorliegende Arbeit selbstständig und nur unter
Verwendung der angegebenen Quellen und
Hilfsmittel angefertigt habe.
Bottrop, der 13. Februar 2022
II
Kurzfassung
Über die letzten Jahre hat sich die Entwicklung von Assistenzsystemen für Kraftfahrzeuge von
Komfortfunktionen hin zu Regelungsaufgaben verschoben. Zunehmend werden diese Regelungs-
aufgaben auch an teilautonome System übertragen. Ein sicherheitskritischer Aspekt ist dabei die
korrekte und zuverlässige Beobachtung der unmittelbaren Umgebung durch das Fahrzeug. Durch
diese Beobachtungen können unter anderem Modelle zur Verfolgung von Objekten aufgestellt wer-
den. Durch neuste Forschungen kommen nun Themen wie Unsicherheiten für Objektdetektionen
und die Kalibrierung von künstlichen neuronalen Netzen auf.
Das Ziel dieser Arbeit ist, die Möglichkeit der Verarbeitung von Positionsunsicherheiten eines
Detektors in einem Multiple Object Tracking Ansatz und die Auswirkungen auf das Tracking der
Objekte zu Untersuchen. Zusätzlich soll die Kalibrierung des verwendeten Detektors ausgewer-
tet und wenn nötig korrigiert werden. Die Auswirkungen der Kalibrierung auf die Ergebnisse des
Tracking sollen in diesem Zusammenhang ebenfalls untersucht werden. Nach einer Untersuchung
des Verfahrens zur Generierung der Positionsunsicherheiten des Detektors wurde eine Verbindung
zu dem Multiple Object Tracking hergestellt und ein Ansatz zur Verarbeitung der Unsicherheiten
auf Basis eines Kalman Filters entwickelt. Die Konfidenz der Detektionen wurde ebenfalls neu
modelliert. Dazu wurde die Konfidenz als Existenzwahrscheinlichkeit interpretiert und durch einen
Bayes Filter verarbeitet, um die Existenz der Tracks abzubilden. Zusätzlich wurden geeignete Ka-
librierungsmethoden für die Positionsunsicherheiten und Konfidenz ausgewählt und in den Ablauf
des Tracking integriert. Die Validierung der vorgestellten Ansätze erfolgte auf einem Datensatz
für Fahrsituationen.
Die Auswertung der Ergebnisse zeigte, dass eine Verarbeitung der von einem Detektor erzeug-
ten Positionsunsicherheiten in dem vorgestellten Tracking Ansatz grundsätzlich möglich ist. Die
Interpretation der Konfidenz als Existenzwahrscheinlichkeit führt zu guten Ergebnissen. Durch
die Kalibrierung der Konfidenz werden die Ergebnisse weiter verbessert. Die Kalibrierung der Po-
sitionsunsicherheiten führte allerdings zu schlechteren Ergebnissen. Eine weitere Untersuchung
anderer Kalibrierungsmethoden für die Positionsunsicherheiten ist nötig.
Schlagwörter: Multiple Object Tracking, Kalman Filter, Kalibrierung neuronaler Netze
III
Abstract
Over the last few years, the development of assistance systems for motor vehicles has shifted from
comfort functions to control tasks. Increasingly, these control tasks are also being transferred to
semi-autonomous systems. One safety-critical aspect is the correct and reliable observation of the
immediate environment by the vehicle. These observations can be used, among other things, to
set up models for tracking objects. Due to recent research, topics such as uncertainties for object
detections and the calibration of artificial neural networks are now emerging.
The goal of this work is to investigate the possibility of processing positional uncertainties of
a detector in a multiple object tracking approach and the effects on the tracking of objects.
Additionally, the calibration of the used detector will be evaluated and corrected if necessary. The
effects of the calibration on the tracking results will also be investigated in this context. After
an investigation of the procedure used to generate the position uncertainties of the detector, a
connection to the multiple object tracking was made and an approach to process the uncertainties
based on a Kalman filter was developed. The confidence of the detections was also remodeled.
For this purpose, the confidence was interpreted as the existence probability and processed using
a Bayes Filter to reflect the existence of the tracks. In addition, appropriate calibration methods
for the position uncertainties and confidence were selected and incorporated into the tracking
procedure. The validation of the presented approaches was performed on a data set for driving
situations.
The evaluation of the results showed that a processing of the position uncertainties generated
by a detector is feasible in the presented tracking approach. The interpretation of the confidence
as existence probability leads to good results. Calibration of the confidence further improves the
results. However, the calibration of the position uncertainties led to worse results. Further inves-
tigation of other calibration methods for the position uncertainties is needed.
Keywords: Multiple Object Tracking, Kalman Filter, Neural Network Calibration
IV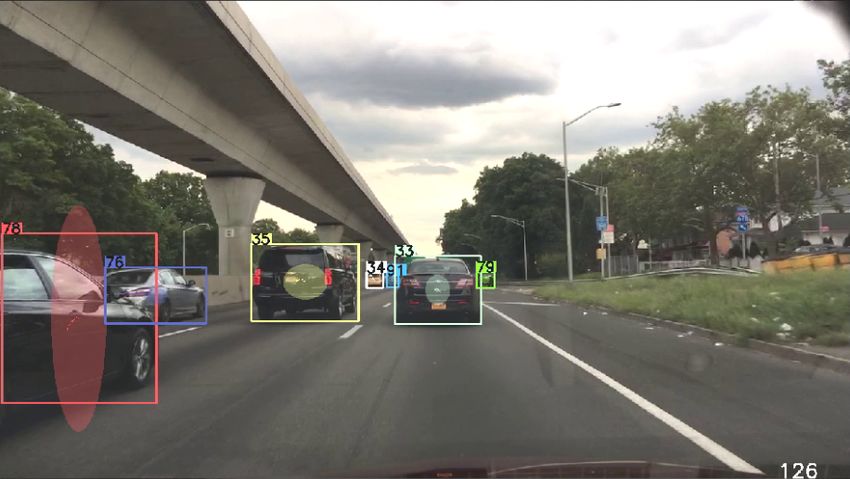
Inhaltsverzeichnis
Abbildungsverzeichnis VII
Abkürzungsverzeichnis IX
1 Einleitung 1
1.1 Problemstellung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Fragestellung und Ziele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.3 Aufbau der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Forschungsstand und Hintergrund 5
2.1 Multiple Object Tracking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2 Bayes Filter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3 Kalman Filter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.4 Bounding-Box Regression mit Unsicherheiten . . . . . . . . . . . . . . . . . . . 10
2.5 Kalibrierung von neuronalen Netzen . . . . . . . . . . . . . . . . . . . . . . . . 11
2.5.1 Konfidenz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.5.2 Positionsunsicherheit . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.6 Variational Inference . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3 Unsicherheiten im Multiple Object Tracking 14
3.1 Konfidenz und Track Existenz . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.1.1 Bernoulli Likelihood . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.1.2 Beta Likelihood . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.1.3 Kalibrierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.2 Positionsunsicherheiten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.2.1 Kalibrierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4 Validierung 20
4.1 Aufbau Objektverfolgung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.1.1 Detektor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.1.2 Objektverfolgung: Aufbau des Trackers . . . . . . . . . . . . . . . . . . . 21
4.2 Metriken . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4.2.1 Detektion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.2.2 Tracking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.3 Datensatz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.4 Auswertung des Detektors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.4.1 Positionsunsicherheiten . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.4.2 Kalibrierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.4.3 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
V
Inhaltsverzeichnis
4.5 Tracking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4.6 Diskussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
5 Zusammenfassung 43
Literaturverzeichnis X
VIAbbildungsverzeichnis
2.1 Typischer Multiple Object Tracking Prozessablauf. . . . . . . . . . . . . . . . . . 5
2.2 Zeitlicher Ablauf des Bayes Filter unter der Markov-Annahme. Jeder Zustand x
ist nur von dem vorigen Zustand abhängig. Die Messwerte y sind nur von dem
aktuellen Zustand x abhängig. . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3 Prädizierte Bounding-Boxen mit Unsicherheiten. Die Zahlen an der oberen und
rechten Kante der Bounding-Boxen geben die Unsicherheit σ der Breite und Höhe
an, das Paar unter dem Mittelpunkt die Unsicherheiten σcx , σcy . . . . . . . . . . 10
3.1 Kalibrierung der Konfidenz als Zwischenverarbeitung vor dem Tracking. In einem
typischen Aufbau werden Position und Konfidenz direkt an das Tracking weiterge-
geben. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.2 Kalibrierung der Positionsunsicherheit und der Konfidenz in dem Aufbau des Tracking
Ansatz. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4.1 Übersicht über den Aufbau der verwendeten MOT Struktur. Die Konfidenz wird
getrennt von der Position und Unsicherheit verarbeitet. . . . . . . . . . . . . . . 22
4.2 Allgemeiner Aufbau für das Objekt Tracking. Die Verwaltung der Tracks führt die
Schritte zu jedem neuen Zeitschritt durch. . . . . . . . . . . . . . . . . . . . . . 23
4.3 (a) zeigt σ in Abhängigkeit der Fläche der Bounding-Box und die berechneten
Parameter der Matrix R. (b) stellt die relative Anzahl der Bounding-Boxen in
Abhängigkeit der Fläche der Box dar, es liegen insgesamt 138 612 Boxen vor. . . 29
4.4 Mittelwert von σ für jeden Parameter der Bounding-Box. Die Unsicherheiten σw , σh
sind skalierte Varianten von σcx , σcy . Mit steigender Breite bzw. Höhe nimmt die
Anzahl der vorliegenden Werte ab. Weniger als 20% der vorliegenden Werte für
Breite bzw. Höhe sind größer als 200 Pixel. . . . . . . . . . . . . . . . . . . . . 29
4.5 Reliability Diagramme für die Detektionsmodelle (a) BDD, (b) COCO ohne Posi-
tionsunsicherheit, (c) COCO mit Positionsunsicherheit. Dargestellt ist pro Intervall
die durchschnittliche Precision als Funktion der Konfidenz. Endet der blaue Balken
unter der Hauptdiagonalen, ist die Konfidenz zu hoch eingeschätzt. Alle Modelle
sind sich in ihren Vorhersagen zu sicher. . . . . . . . . . . . . . . . . . . . . . . 30
4.6 Kalibrierung der Bounding-Boxen aufgeteilt für die einzelnen Parameter (a) σcx ,
(b) σcy , (c) σw und (d) σh . Die Unsicherheiten aller Bounding-Box Parameter
werden unterschätzt. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.7 Kalibrierung der Bounding-Boxen für die Parameter (a) σcx , (b) σcy , (c) σw und
(d) σh nach dem σ-Scaling. Nach der Kalibrierung liegt eine Überschätzung der
Unsicherheiten vor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
VIIAbbildungsverzeichnis
4.8 Verteilungen für (a) Bernoulli-Likelihood und (b) Beta-Likelihood. Die Verteilun-
gen zeigen ein vergleichbares Bild, die Beta-Likelihood erreicht aufgrund ihres De-
finitionsbereich allerdings eine Likelihood von Null für die Fälle p(1|@) und p(0|∃)
und ist somit eine bessere Darstellung. . . . . . . . . . . . . . . . . . . . . . . . 35
4.9 Verteilungen für (a) Bernoulli-Likelihood und (b) Beta-Likelihood ermittelt mit
kalibrierten Konfidenzen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.10 Verlauf der Existenzwahrscheinlichkeit p(∃) eines ausgewählten Tracks bis zum Ab-
bruch. Die Marker zeigen die in dem Tracker verarbeitete Konfidenz des Detektors
für jedes Bild. Die Kalibrierung der Konfidenz wirkt sich positiv auf die Lebens-
dauer des Tracks mit Bernoulli-Likelihood aus, sodass beide Likelihood Modelle
die gleiche Tracklebensdauer erzielen. . . . . . . . . . . . . . . . . . . . . . . . . 39
4.11 Kovarianz und Zustand des Trackers mit Beta-Likelihood in den Konfigurationen
(a) Basismodell, (b) Konfidenzkalibrierung, (c) Konfidenzkalibrierung mit Verar-
beitung der Positionsunsicherheiten, (d) Konfidenzkalibrierung und Kalibrierung
der Positionsunsicherheiten. Die Konfidenzkalibrierung hat einen eindeutig positi-
ven Effekt. Die Verarbeitung der Unsicherheit des Detektors und die Kalibrierung
der Positionsunsicherheiten wirken sich ebenfalls positiv aus, was durch die ge-
ringeren Identitätsindizes und größeren Ellipsen um den Mittelpunkt ersichtlich
wird. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
VIIIAbkürzungsverzeichnis
BDD Berkeley Deep Drive
COCO Common Objects in Context
MOT Multiple Object Tracking
NMS Non-maximum suppression
ECE erwarteter Kalibrierungsfehler
MOTA Multiple Object Tracking Accuracy
MOTP Multiple Object Tracking Precision
FP falsch positiv
FN falsch negativ
FM Fragmentierung
IDSw Identitätswechsel
ELBO Evidence lower bound
IX1 Einleitung
Individualmobilität im Personenkraftverkehr hat über die letzten Jahre stetig an Bedeutung gewon-
nen, wie an der steigenden Anzahl an zugelassenen Personenkraftwagen zu sehen ist. Neben der
steigenden Anzahl an zugelassenen Personenkraftwagen hat auch der Bestand an Lastkraftwagen
in den vergangenen Jahren deutlich zugenommen [1]. Durch die erhöhte Anzahl an zugelassenen
Fahrzeugen steigt ebenso die Fahrzeugdichte im Straßennetz und führt zu einer erhöhten Gefahr
von Unfällen [2]. Aufgrund der Sättigung des Fahrzeugmarkts in hoch industriealisierten Ländern
legt die Mobilitätsindustrie ihren Fokus vermehrt auf eine erhöhte Qualität der Mobilität. Darunter
versteht sich unter anderem die Reduktion von Verkehrsunfällen und Umweltverschmutzung. Um
die Sicherheit im Straßenverkehr zu erhöhen wird der Fokus vermehrt auf Fahrerassistenzsysteme
gelegt. Diese Assistenzsysteme haben sich über die letzten drei Jahrzehnte deutlich entwickelt
und reichen heute von gesetzlich vorgeschriebenen Systemen wie dem Antiblockiersystem bis hin
zu adaptiven Geschwindigkeitsreglern (ACC). [3]
Abhängig von der Aufgabe dieser Assistenzsysteme ist die Wahrnehmung der Umwelt für das
System eine relevante Aufgabe. So muss zum Beispiel eine Einparkhilfe das Umfeld des Fahrzeugs
in einer für die Aufgabe des Einparkens relevanten Entfernung wahrnehmen. Assistenzsysteme,
die auf Basis der Umwelt entweder Informationen für den Fahrer bereitstellen, oder eigenständig
eine Funktion des Fahrzeugs regeln, wie z.B. ACC, müssen die verfügbaren Sensordaten mit
robusten Algorithmen verarbeiten. Erkennt ein ACC System beispielsweise ein von einer anderen
Spur kommendes Fahrzeug mit geringerer Geschwindigkeit zu spät oder gar nicht, kann es zu
einem Unfall kommen, sollte der Fahrer des Fahrzeugs abgelenkt sein oder zu spät eingreifen.
Allerdings muss das System auch robust genug sein, um bei einer Fehldetektion nicht unerwartet
abzubremsen.
Der Fokus der Forschung des letzten Jahrzehnts hat sich vermehrt in die Richtung der autono-
men Fahrzeuge verschoben, aber, obwohl die grundlegenden Systeme für ein autonom fahrendes
Fahrzeug vorhanden sind, bedarf die Entwicklung eines vollkommen autonomen Fahrzeugs oh-
ne situationsbedingte Intervention von einem Fahrer mehr Forschung [4]. Autonome Fahrzeuge
müssen nicht nur die Umwelt unter verschiedensten Wetterbedingungen korrekt beobachten, son-
dern auch jegliche im Straßenverkehr aufkommende Situation ohne das Eingreifen eines Menschen
lösen können. Ein zentraler und sicherheitskritischer Bestandteil eines autonomen Fahrzeugs ist
dabei das Erkennen und Verfolgen von Objekten im Umfeld des Fahrzeugs. Dafür müssen sowohl
statische Objekte wie z.B. Straßenlaternen und Schilder, als auch andere Verkehrsteilnehmer wie
Fußgänger, Radfahrer und andere Fahrzeuge, robust erkannt und verfolgt werden. Die Verfolgung
von mehreren Objekten sollte nicht nur die vergangene Position enthalten, sondern auch eine plau-
sible Aussage über die zukünftige Position treffen können, um z.B. ein mögliches Bremsmanöver
einzuleiten, um einen Unfall zu vermeiden. Um dieser Aufgabe nachzukommen wurden über die
Jahre verschiedene Verfahren für das Verfolgen mehrerer Objekte, im englischen Multiple Object
11 Einleitung
Tracking (MOT) genannt, entwickelt, die in Abschnitt 2.1 näher beschrieben werden.
Ein wichtiger Aspekt bei der Detektion und auch der Verfolgung von Objekten ist ein Maß
für die Unsicherheit des Systems. Um bei dem Beispiel der adaptiven Geschwindigkeitsregelung
zu bleiben: Fließt in die Berechnung der Geschwindigkeit zu einem voraus fahrenden Fahrzeug
ein fehlerbehafteter Messwert ein, der von dem System unerkannt bleibt und auch nicht durch
die Verarbeitungsstrukturen ausgeglichen werden kann, ist es möglich, dass das System die Ge-
schwindigkeit falsch berechnet. Auf Grundlage dieser ggf. falschen Geschwindigkeit erfolgt dann
die Regelung des Fahrzeugs und könnte im schlimmsten Fall zu einem Unfall führen. Zwar ist das
Beispiel überspitzt dargestellt, es soll aber aufzeigen, dass ohne entsprechende Fehlergrößen und
robuste Verarbeitungssysteme sicherheitskritische Aufgaben falsch ausgeführt werden können.
1.1 Problemstellung
Das Multiple Object Tracking (MOT) ist ein komplexes Themenfeld und wurde über die letzten
Jahre ausgiebig mit verschiedenen Ansätzen von filterbasierten Methoden bis hin zu der Verwen-
dung von künstlichen neuronalen Netzen für das Tracking von Objekten im zwei- oder dreidimen-
sionalen Raum untersucht [5, 6, 7]. Das Problem des MOT lässt sich in die zwei untergeordneten
Probleme Objektdetektion und Tracking aufteilen. Die Detektion ist für die Bestimmung der Ob-
jekte in den Sensordaten zuständig, während das Tracking die Verfolgung und Verwaltung der
Objekte übernimmt. Als Detektionen liegt typischerweise die Position des Objekts und ein Klas-
senlabel mit einer Konfidenz vor. Anhand dieser Informationen wird dann das Tracking der Objekte
durchgeführt. Die Ergebnisse des MOT sind direkt abhängig von den Ergebnissen des Detektors
[8], da das Tracking auf Grundlage der Detektionen durchgeführt wird. Wird ein Objekt z.B. von
dem Detektor in mehreren aufeinander folgenden Bildern nicht erkannt, ändert sein Klassenlabel,
oder wird aufgrund von Verdeckungen nur teilweise erkannt, kann es zu einem Verlust des Objekts
in dem Tracker kommen.
Das noch wenig untersuchte Thema der Bounding-Box Regression mit Unsicherheiten [9] zeigt
eine neue Art der Regression für Objektdetektoren auf. Es wird nicht nur die Position, sondern
auch die Unsicherheit der Position von dem Detektor vorhergesagt. Dadurch liegen nun erweiterte
Informationen über ein Objekt vor, die in einem MOT Ansatz verarbeitet werden können. Andere
Arbeiten aus dem Bereich der Objektdetektion und Klassifikation zeigen, dass moderne neuronale
Netze häufig nicht korrekt kalibriert sind, die durchschnittliche Konfidenz liegt über der durch-
schnittlichen Genauigkeit der Netze [10]. Da eine Verarbeitung der Konfidenz des Detektors in
der Objektverfolgung eine wichtige Rolle spielt, ist eine gut kalibrierte Konfidenz unerlässlich für
die Verfolgung von Objekten. Zusätzlich zeigen weitere Arbeiten auf dem Gebiet der Kalibrierung,
dass nicht nur die Konfidenz eines Detektors, sondern auch die vorhergesagte Positionsunsicherheit
eines Bounding-Box Regressors mit Unsicherheiten nicht korrekt kalibriert sein kann [11].
21 Einleitung
Die für das MOT in dieser Arbeit vorliegenden Detektionen bestehen aus der Position, der Po-
sitionsunsicherheit, der Konfidenz und dem Klassenlabel. Für das Tracking von Objekten ohne
Positionsunsicherheit bestehen bereits ausgiebig untersuchte Ansätze, wie in Abschitt 2.1 be-
schrieben wird. Es gilt einen Ansatz zu finden, um die vorhergesagte Positionsunsicherheit des
Detektors sinnvoll in das Tracking zu integrieren. Anschließend muss der Kalibrierungsschritt der
Konfidenz und der Positionsunsicherheit in den Ansatz integriert und geeignete Kalibrierungsme-
thoden gefunden werden.
1.2 Fragestellung und Ziele
Bisher wurde in dem Bereich des Multiple Object Tracking ausschließlich die Position für die
Verfolgung von Objekten verwendet. Die Konfidenz und das Klassenlabel wurden für die Auswahl
relevanter Detektionen verwendet. Durch die um die Positionsunsicherheit erweiterten Detektionen
stellt sich die Frage, wie die Positionsunsicherheit des Regressors in einen tracking-by-detection
Ansatz integriert werden kann. Das Ziel ist demnach die Entwicklung eines Ansatz, der die Ver-
arbeitung der Positionsunsicherheit in dem MOT Kontext ermöglicht. Um den Effekt des entwi-
ckelten Ansatz auf die Ergebnisse des Trackers zu untersuchen sollen die Ergebnisse des Trackings
ohne und mit der Integration der Positionsunsicherheiten gegenübergestellt werden. Zusätzlich
soll eine erweiterte Verarbeitung der Konfidenz stattfinden, um daraus die Existenz eines Tracks
abzuleiten.
Die Kalibrierung der Konfidenz und der Positionsunsicherheit des Detektors soll ebenfalls un-
tersucht werden. Im Zusammenhang mit der Kalibrierung stellt sich die Frage, wie der Detektor
für die Konfidenz und die Positionsunsicherheit kalibriert ist, und welche Auswirkungen eine Ka-
librierung der Variablen vor der Verarbeitung durch die Tracking Struktur auf die Ergebnisse des
Trackings haben. Dazu müssen sowohl für die Konfidenz als auch für die Positionsunsicherheiten
geeignete Methoden zur Kalibrierung gefunden werden. Anschließend sollen die Ergebnisse ohne
und mit Kalibrierung verglichen und bewertet werden.
1.3 Aufbau der Arbeit
In Abschnitt 2 werden die technischen Hintergründe und aktuelle Arbeiten auf dem Themenfeld be-
leuchtet und auf ihre Relevanz für die Aufgabenstellung untersucht. Darauf folgt die Beschreibung
des verfolgen Ansatz zur Integration der Positionsunsicherheiten des Detektors in den tracking-by-
detection Ansatz und die Darstellung der Konfidenz als Existenzwahrscheinlichkeit des Tracks in
Abschnitt 3. Ebenfalls wird in diesem Abschnitt die Kalibrierung der Konfidenz und der Positions-
unsicherheiten als zusätzlicher Schritt in der vorgestellten Struktur beschrieben. Anschließend wird
der Versuchsaufbau und die für die Auswertung verwendeten Metriken in Abschnitt 4 beschrieben.
31 Einleitung
Darauf folgt eine kurze Beschreibung des verwendeten Datensatz. Nachdem der Aufbau und der
verwendete Datensatz beschrieben wurden, folgt die Auswertung des Detektors und des Trackers,
sowie die Analyse der von dem künstlichen neuronalen Netz erzeugten Unsicherheiten. Die erziel-
ten Ergebnisse werden in Abschnitt 4.6 diskutiert. Anschließend folgt die Zusammenfassung der
Ergebnisse der Arbeit in Abschnitt 5.
42 Forschungsstand und Hintergrund
In diesem Abschnitt werden bereits bekannte Techniken aus dem Bereicht des Objekt Tracking
und der künstlichen neuronalen Netze vorgestellt. Bereits bestehende Untersuchungen werden
dargestellt, in den Kontext eingeordnet und auf ihre Relevanz für diese Arbeit geprüft.
2.1 Multiple Object Tracking
Die Objektverfolgung in Sequenzen von Bildern ist ein viel untersuchtes Thema mit Relevanz in
Robotik, Überwachung, autonomen Fahrzeugen und weiteren Bereichen [5, 12]. Das generelle Ziel
ist die Trajektorien von erkannten Objekten in einer Sequenz zu bestimmen. Allgemeine Hürden
sind unter anderem Verdeckung, abrupte Bewegungen und Echtzeitanforderung. Aufgrund aus-
giebiger Forschung in diesem Bereich gibt es heute zahlreiche unterschiedliche Ansätze, die den
unterschiedlichen Anforderungen gerecht werden [13]. Zusätzlich zu den unterschiedlichen Anfor-
derungen sind auch die Einsatzgebiete divers. So wird z.B. in [14] Objektverfolgung basierend auf
dem Kalman Filter eingesetzt, um Fasern durch Scheiben von faserverstärkten Verbundwerkstof-
fen zu verfolgen. Die Scheiben zeigen den Querschnitt der Fasern, durch das Tracking kann der
Verlauf der Fasern durch die einzelnen Scheiben ermittelt werden.
Detektion Assoziation Tracking
Abbildung 2.1: Typischer Multiple Object Tracking Prozessablauf.
Abbildung 2.1 zeigt den typischen Ablauf von MOT Ansätzen. Detektionen der Objekte in einem
Bild können u.a. durch Methoden wie Background Subtraction oder Supervised Learning erzeugt
werden. Background Subtraction erstellt aus mehreren Bildern ein Hintergrundmodell der Szene.
Für jedes neue Bild wird die Abweichung zu diesem Modell geprüft und als Detektion ausgege-
ben. Für diesen Detektionsansatz wird ein statischer Hintergrund benötigt, was eine Bewegung
der Kamera relativ zu der Szene ausschließt. Das Supervised Learning bildet anhand von Trai-
ningsdaten eine Abbildung die jedem Eingabewert eine Ausgabewert zuordnet. Die Trainingsdaten
sind ein Paar aus dem Eingabewert und dem erwarteten Ausgabewert und werden manuell vor
dem Training festgelegt. Üblicherweise wird eine große Anzahl an Trainingsdaten benötigt. [12]
Die Forschung an Detektionsmethoden kann von der Assoziation und den Tracking-Algorithmen
losgelöst betrachtet werden [15].
Die Assoziation kann in die Bereiche batched und online Assoziation aufgeteilt werden. Das
batched Verfahren betrachtet die Assoziation als globales Optimierungsproblem und verwendet die
Detektionen aller Bilder einer Sequenz, um die finalen Trajektorien zu bestimmen. Im Gegensatz
dazu steht die online Assoziation, bei der nur die Detektionen von zwei aufeinander folgenden
52 Forschungsstand und Hintergrund
Bildern durch die Lösung eines bipartiten Graphen, z.B. mit der Ungarischen Methode, zugeordnet
werden. Eine der größten Herausforderungen für die online Assoziation ist die zeitweise Verdeckung
von Objekten, da eine Reidentifikation nicht möglich ist, wenn ein Objekt in einem der beiden
Bilder nicht vorhanden ist. [15]
Der Bereich der Tracking Algorithmen lässt sich in verschiedene Kategorien aufteilen und zeichnet
sich durch eine vielzahl an unterschiedlichen Ansätzen aus. Kothiya et al. [6] unterteilen die
Algorithmen in die Kategorien Point Based, Kernel Based und Shilouette Based Tracking. Das
Point Based Tracking enthält Algorithmen die ein Objekt anhand ihrer Position, bzw. einem oder
mehrerer Punkte, definieren. Dazu zählen unter anderem Algorithmen wie das Kalman Filter, das
Partikel Filter und das Multiple Hypothesis Tracking. Das Kernel Based Tracking bedient sich der
Form und des Aussehens der Objekte. Der Kernel kann entweder rechteckig oder elliptisch sein.
Das Hautpmerkmal ist die Bewegung der Objekte, genauer die parametrische Transformation,
Translation oder Rotation. Zu den Algorithmen zählen unter anderem Support Vector Matching
und Simple Template Matching. Die Kategorie Shilouette Based Tracking wird als dritte genannt
und zeichnet sich durch eine komplexere Repräsentation der Objekte aus. Die Repräsentation
kann im Gegensatz zu den anderen Kategorien die genaue Form eines Objekts annehmen anstelle
einfacher geometischer Formen. Zu den Algorithmen zählen das Contour Matching und Shape
Matching.
Böttger-Brill [13] nimmt eine andere Unterteilung der Tracking Algorithmen vor und kategorisiert
die Ansätze als entweder generative oder diskriminative Tracker. Generative Ansätze modellieren
je nach Ansatz die Position, Bewegung oder das Aussehen, bzw. eine Kombination aus den drei
Merkmalen, eines Objekts und suchen die beste Zuordnung in jedem Bild. Da diese Ansätze nur
das Objekt modellieren, können sie bei unübersichtlichen Hintergründen oder auftauchen ähnlicher
Objekte versagen. Der Vorteil der generativen Tracker ist ihre Einfachheit und effiziente Imple-
mentierung. Sie funktionieren gut für Objekte die sich nicht zu schnell bewegen und ihr Aussehen
nicht zu stark verändern. Zu der großen Anzahl an Ansätzen gehören u.a. das Kalman Filter, der
Partikel Filter und das Template Matching. Im Gegensatz zu den generativen Trackern modellie-
ren die diskriminativen Tracker zusätzlich auch den Hintergrund der Objekte und definieren das
Tracking als binäre Klassifikation um die Grenze zwischen Objekt und Hintergrund zu finden. Zu
den Ansätzen zählt unter anderem das Kernel Based Tracking. Eine klare Aufteilung der Ansätze
ist allerdings nicht in jedem Fall möglich und so können manche Ansätze in beide Kategorien
eingeteilt werden.
Aus der Vielzahl an möglichen Ansätzen muss ein für diese Arbeit und den damit verbun-
denen Aufgaben geeigneter Ansatz ausgewählt werden. Es soll die Möglichkeit der Integration
der Bounding-Box Regression mit Unsicherheiten in einen Tracking Ansatz untersucht werden,
dementsprechend muss eine Methode des Point Based Tracking verwendet werden. Da bereits
ein Tracker basierend auf dem Kalman Filter zur Verfügung steht, wird dieser erweitert und mit
den Ansätzen dieser Arbeit angepasst. Die Verwendung der Bounding-Box Regression mit Posi-
62 Forschungsstand und Hintergrund
tionsunsicherheiten legt die verwendete Art des Detektors auf einen Supervised Learning Ansatz
fest.
2.2 Bayes Filter
Das Bayes Filter ist ein Konzept zur probabilistischen Schätzung des Zustands x eines dynami-
schen Systems unter der Verwendung verrauschter Messwerte y. Der Zustand zur Zeit t wird durch
die Zufallsvariable xt dargestellt. Die Wahrscheinlichkeitsverteilung p(xt ) über den Zustand xt ,
genannt Belief, beschreibt den Zustand und dessen Unsicherheit zu jedem Zeitpunkt. Die Beob-
achtungen werden als eine Folge von zeitindizierten Sensordaten y1 , y2 , . . . , yt angenommen. Der
Belief ist dann durch die Posterior-Dichte über die Zustandsvariable xt unter Berücksichtigung
aller zum Zeitpunkt t vorhandenen Sensordaten als p(xt |y1 , y2 , . . . , yt ) definiert. Die Komplexität
der Berechnung des Belief steigt exponentiell, da sich die Anzahl der Messwerte mit jedem Zeit-
schritt erhöht. [16] Die Zustände x sind unbekannt und können nicht direkt Beobachtet werden,
die Messungen y hängen von den unbekannten Zuständen ab.
xt−1 xt xt+1
Versteckt
Beobachtbar
yt−1 yt yt+1
Abbildung 2.2: Zeitlicher Ablauf des Bayes Filter unter der Markov-Annahme. Jeder Zustand x
ist nur von dem vorigen Zustand abhängig. Die Messwerte y sind nur von dem
aktuellen Zustand x abhängig.
Abbildung 2.2 zeigt den zeitlichen Ablauf des Bayes Filter unter der Markov-Annahme. Unter
der Markov-Annahme, dass in Zustand xt alle relevanten Informationen enthalten sind, kann die
Berechnung vereinfacht werden. Der aktuelle Zustand xt wird dann nicht als abhängig von x0:t−1 ,
sondern von xt−1 definiert. Eine Messung yt ist nur von dem aktuellen Zustand xt abhängig.
Unter dieser Annahme kann der Belief effizient berechnet werden,
Z
p(xt |y0:t−1 ) = p(xt |xt−1 )p(xt−1 |y0:t−1 )dxt−1 . (2.1)
Ist ein neuer Messwert vorhanden, wird im ersten Schritt eine Prädiktion des Beliefs anhand von
(2.1) berechnet. p(xt | xt−1 ) ist das Systemmodell und bildet die Übergangswahrscheinlichkeiten
zwischen den Zuständen des Systems ab. p(xt−1 | y0:t−1 ) ist der Belief zu dem Zeitpunkt t − 1.
72 Forschungsstand und Hintergrund
Auf die Prädiktion des Belief folgt das Update mit
p(yt |xt )p(xt |y0:t−1 )
p(xt |y0:t ) = R . (2.2)
p(yt |xt )p(xt |y0:t−1 )dxt
p(yt | xt ) beschreibt die Likelihood der Beobachtung yt gegeben den Zustand xt , der berechnete
Belief zu Zeitpunkt t ist gegeben durch p(xt | y0:t ). Zum Zeitschritt t = 0 wird x0 mit einer unifor-
men Verteilung über den Zustandsraum initialisiert, sollte kein Vorwissen zu dem Systemzustand
x existieren. [16]
Das Bayes Filter ist ein probabilistisches Rahmenkonzept, für den in der Implementierung das Ob-
servationsmodell p(yt |xt ), Systemmodell p(xt |xt−1 ) und die Repräsentation des Belief p(xt |y0:t )
spezifiziert werden müssen [16]. Populäre Implementierungen sind Kalman-[17] und Partikel-
Filter[18]. Das Filter soll in dieser Arbeit für die Modellierung der Existenz der Tracks verwendet
werden.
2.3 Kalman Filter
Der Filter wurde erstmals von R.E. Kalman [17] als rekursive Lösung für das lineare Filterproblem
mit diskreten Daten beschrieben. Seitdem wurde der Ansatz umfangreich untersucht und auch im
Bereich der autonomen und unterstützenden Navigation angewendet [19]. Da das Kalman Filter
eine Implementierung des Bayes Filter darstellt, wird der Zustand des Filters in zwei Schritten,
Prädiktion und Update, zu jedem Zeitpunkt neu berechnet. Die Zustandsgleichung dieses linearen,
diskreten Systems ist definiert als
xt = F xt−1 + qt−1 , (2.3)
wobei xt ∈ Rn der Zustandsvektor des Filters ist, n stellt die Dimension des Zustands dar. Die
Zustandsübergänge werden mit der n×n Matrix F abgebildet. qt−1 ist die n×1 Matrix des weißen
Prozessrauschens, das als Normalverteilung mit Null-Mittelwert qt−1 ∼ N (0, Q) und Kovarianz
Q angenommen wird. Das Messmodell
yt = Hxt + rt , (2.4)
beschreibt die Relation zwischen dem Zustand und der Messung yt ∈ Rm zu dem Zeitpunkt t, m
gibt die Dimension des Messvektors an. Die m × n Matrix H setzt den Zustand mit der Messung
in Beziehung. Das Messrauschen rt wird wie auch das Prozessrauschen qt−1 als m × 1 Matrix
normalverteiltes weißes Rauschen rt ∼ N (0, R) angenommen, die Kovarianz des Rauschens ist
R. Zusätzlich wird angenommen, dass qt−1 und rt voneinander unabhängig sind. Probabilistisch
82 Forschungsstand und Hintergrund
ist das Modell definiert als
p(xt |xt−1 ) = N (xt |F xt−1 , Q), (2.5)
p(yt |xt ) = N (yt |Hxt , R). (2.6)
Durch Einsetzen der Annahmen in die Gleichungen des Bayes Filter lassen sich die Gleichungen
des Kalman Filter für Prädiktion und Update des Filters herleiten. Der vorhergesagte Zustand x̂t
und die vorhergesagte Kovarianz des Zustands P̂t lassen sich mit der Zustandsübergangsmatrix
F und dem Systemrauschen Q durch
x̂t = F xt−1 , (2.7)
P̂t = F Pt−1 F T + Q, (2.8)
berechnen. Sollte zu einem Zeitpunkt kein Messwert vorliegen kann der Prädiktionsschritt ohne
Update einfach wiederholt werden.
Das Update des Filters erfordert mehr Berechnungen als die Prädiktion. Zuerst wird mit
vt = yt − H x̂t , (2.9)
die Differenz vt zwischen der Messung yt und dem vorhergesagten Zustand x̂t , genannt Innovation,
berechnet. Zusätzlich wird mit
St = H P̂t H T + R, (2.10)
auch die Residualkovarianz St , welche die Unsicherheit im Messraum beschreibt berechnet. An
dieser Stelle fließt auch das Messrauschen R in die Berechnung mit ein. Es folgt die Berechnung
des Kalman Gain mit
Kt = P̂t HtT St−1 . (2.11)
Mit der Innovation des Systemzustands vt , der prädizierten Kovarianz P̂t und dem Kalman Gain
Kt liegen nun alle benötigten Matrizen zur Berechnung des neuen Systemzustands xt und der
neuen Kovarianz Pt vor.
xt = x̂t + Kt vt (2.12)
Pt = P̂t − Kt St KtT (2.13)
Da die Werte für den Zustand x0 und die Kovarianz P0 und meist nicht bekannt sind, kann x0
als erster Messwert angenommen werden. P0 kann mit ausreichend großen Kovarianzen abhängig
von dem beobachteten Prozess gewählt und initialisiert werden.
Das Kalman Filter wird in dieser Arbeit für das Tracking der von dem Detektor erkannten Objekte
verwendet. Das Filter alleine reicht allerdings nicht für das Tracking aus, es werden zusätzliche
92 Forschungsstand und Hintergrund
Strukturen für die Assoziation und Validierung der Tracks benötigt. Diese Strukturen und ihr
Zusammenspiel werden in Abschnitt 4.1.2 vorgestellt.
2.4 Bounding-Box Regression mit Unsicherheiten
Datensätze für die Objektdetektion versuchen für das Training von Detektoren die Objekte so
eindeutig wie möglich mit Grundwahrheiten zu versehen. Allerdings können aufgrund von teilwei-
sen Verdeckungen oder unklaren Objektgrenzen die Annotationen in solchen Datensätzen nicht
immer die korrekte Fläche umschließen. Die durch solche Verdeckungen verursachten Ungenauig-
keiten erschweren das Lernen der Regressionsfunktionen. Dieses Problem soll durch eine neuartige
Kostenfunktion für Bounding-Boxen zum Erlernen von Bounding-Box Transformationen und Lo-
kalisierungsvarianzen gelöst werden. [9]
Für diese neue Kostenfunktion, genannt KL-Loss, wird die Bounding-Box Prädiktion als Normal-
verteilung und die Grundwahrheiten als Delta-Distribution modelliert. Die Kostenfunktion wird
dann als Kullback-Leibler-Divergenz zwischen der vorhergesagten Verteilung und den Grundwahr-
heiten definiert. Mit dem KL-Loss zu lernen hat nach [9] den Vorteil, dass die Mehrdeutigkeit des
Datensatz erfasst werden kann und die Kosten des Regressors für mehrdeutige Bounding-Boxen
geringer sind. Zusätzlich ist die gelernte Varianz in Nachverarbeitungsschritten der Regression hilf-
reich. Ebenfalls wird angeführt, dass die gelernte Normalverteilung interpretierbar ist und, da sie
die Unsicherheit der Bounding-Box angibt, sie in weiterführenden Prozessen Verwendung finden
kann. Abbildung 2.3 zeigt exemplarisch die vorhergesagten Unsicherheiten.
Abbildung 2.3: Prädizierte Bounding-Boxen mit Unsicherheiten. Die Zahlen an der oberen und
rechten Kante der Bounding-Boxen geben die Unsicherheit σ der Breite und
Höhe an, das Paar unter dem Mittelpunkt die Unsicherheiten σcx , σcy .
He et al. führen als Nachverarbeitungsschritt [9] das variance voting ein. Dabei handelt es sich um
einen angepassten Prozess zur Auswahl der Bounding-Box Position anhand der gelernten Varianzen
der benachbarten Bounding-Boxen. Dieser Schritt wird in die Non-maximum suppression (NMS)
integriert. Die Gewichtung der Berechnung wird an den Unsicherheiten der Bounding-Boxen fest-
gemacht, es gilt: je geringer die Unsicherheit desto höher die Gewichtung. Es wird gezeigt, dass der
vorgestellte Ansatz zu einer Verbesserung in der Präzision (Precision), dem Anteil der relevanten
102 Forschungsstand und Hintergrund
Detektionen unter allen Detektionen, und der Trefferquote (Recall), dem Anteil der gefundenen
Grundwahrheiten, des Detektors führt.
2.5 Kalibrierung von neuronalen Netzen
2.5.1 Konfidenz
Das Konzept der Kalibrierung bezieht sich im Bereich der Klassifikation von Objekten auf die
Übereinstimmung der Konfidenz des Klassifikators und der Genauigkeit. Genauer heißt das, dass
je kleiner die Differenz zwischen der Konfidenz und der Genauigkeit ist, desto besser ist der
Klassifikator kalibriert. Die Kalibrierung lässt sich in Zuverlässigkeitsdiagrammen [20, 21], welche
die Genauigkeit als Funktion der Konfidenz darstellen, visualisieren.
Die Kalibrierung von modernen künstlichen neuronalen Netzen wurde von Guo et al. [10] un-
tersucht. Es wurde festgestellt, dass im Vergleich mit neuronalen Netzen aus den vorigen Jahren
zwar eine höhere Genauigkeit der Netze vorliegt, jedoch die Konfidenz des Netzes nicht mit der
Genauigkeit übereinstimmte. Die Gründe für die schlechte Kalibrierung werden von Guo et al.
in der über die letzten Jahre gesteigerte Modellkapazität, Normalisierung und Regularisierung
benannt. Als Lösung wird ein post-processing Schritt vorgeschlagen, der die Konfidenzen der Aus-
gabe eines Netzes verarbeitet und kalibrierte Wahrscheinlichkeiten liefert. Aus den untersuchten
Methoden stellt sich das Temperature-Scaling trotz seiner Einfachheit als effektivste und schnells-
te Methode heraus. Temperature-Scaling verwendet einen skalaren Parameter um die Berechnung
der Konfidenz zu beeinflussen.
[22] stellt eine neue parametrische Familie von Kalibrierungsmethoden vor, die Beta-Kalibrierung.
Im Gegensatz zur logistischen Kalibrierung, welche Normalverteilte Konfidenzen einer Klasse an-
nimmt, wird eine Beta-Verteilung eingesetzt. Dadurch wird der Zustandsraum auf den Bereich
[0, 1] begrenzt und sorgt damit für eine bessere Darstellung. Es wird gezeigt, dass mit der Beta-
Kalibrierung bessere Ergebnisse als mit der logistischen Kalibrierung erzielt werden.
Küppers et al. [23] übertragen und erweitern die Definition für die Kalibrierung auf den Bereich
der Objektdetektion. Anstatt nur den Klassifikationsteil des Detektors zu kalibrieren, werden auch
die Bounding-Boxen des Regressionsteils für die Kalibrierung verwendet. Es wird gezeigt, dass der
vorgestellte Ansatz der reinen Kalibrierung der Klassifikation überlegen ist.
In dieser Arbeit wird ein Detektor mit einem erweiterten Regressionsteil zur Schätzung der Po-
sitionsunsicherheiten eingesetzt. Da die Kalibrierung für Klassifikationsmodelle auf die Detektion
übertragbar ist, wird der Ansatz von [23] nicht weiter verfolgt und auf die Beta-Kalibrierung
zurückgegriffen. Die Konfidenz des Detektors soll als Existenzwahrscheinlichkeit interpretiert wer-
den. Eine hohe Genauigkeit der Konfidenz ist essentiell für die in Validierung der Tracks, wie in
Abschnitt 3.1 dargestellt.
112 Forschungsstand und Hintergrund
2.5.2 Positionsunsicherheit
Levi et al. [24] stellen eine Definition für die Kalibrierung für Regression vor, die sich an der
Definition von Guo et al. [10] für die Kalibrierung für Klassifikation ableitet. Für einen Regressor
mit Eingabewert x sei das Ergebnis eine Verteilung mit dem Mittelwert µ(x) und Standardabwei-
chung σ(x). Der erwartete Fehler für jeden Ausgabewert wird als der mittlere quadratische Fehler
(MSE) zwischen dem Vorhergesagen Mittelwert µ(x) und der Grundwahrheit y berechnet. Ein
Regressor gilt als gut kalibriert, wenn der erwartete Fehler (MSE) gleich der von dem Regressor
vorhergesagten Varianz entspricht:
h i
∀σ : Ex,y (µ(x) − y)2 |σ(x)2 = σ 2 = σ 2 . (2.14)
Die Kalibrierung wird mit einem Skalierungsfaktor s, analog zu dem Temperature Scaling in der
Klassifizierung, vorgenommen, sodass aus der vorhergesagten Wahrscheinlichkeitsdichtefunktion
N (µ, σ 2 ) die kalibrierte Funktion N (µ, (sσ)2 ) wird. Analog zum Temperature Scaling wird die
Negative log-likelihood als Kostenfunktion für die Kalibrierung eingesetzt.
Zusätzlich werden mehrere Größen zur Messung der Kalibrierung vorgestellt, darunter auch der
Expected Normalized Calibration Error kurz ENCE. Die Metrik leitet sich von dem für die Klassi-
fikation verwendeten ECE [10] ab und fasst das Reliability Diagram durch Mittelung des Fehlers
in jedem Intervall zusammen. Für die Berechnung des Kalibrierungsfehlers wird das Binning des
Reliability Diagrams verwendet und für jedes Intervall j die Wurzel der mittleren Varianz (RMV)
und die Wurzel des mittleren quadratischen Fehlers (RMSE) berechnet
N
1 X |RM V (j) − RM SE(j)|
EN CE = . (2.15)
N j=1 RM V (j)
Die Metrik, definiert in (2.15), gibt den Durchschnitt des Kalibrierungsfehlers in jedem Intervall
j, normalisiert durch die mittlere vorhergesagte Varianz des Intervalls, an.
Laves et al. [11] bauen auf dem Ansatz von Levi et al. auf, definieren die von dem neuronalen
Netz vorhergesagte Varianz aber als Summe aus der aleatorischen und epistemischen Unsicherheit.
Aleatorische Unsicherheit ist die Unsicherheit in den Daten und entsteht z.B. durch Sensorrau-
schen, epistemische Unsicherheit wird durch Unsicherheiten in den Modellparametern verursacht
und kann auftreten, wenn nur eine geringe Anzahl an Trainingsdaten zur Verfügung steht.
Da der in dieser Arbeit verwendete Datensatz eine große Anzahl an Trainingsdaten bereitstellt
(vgl. Abschintt 4.3), kann die Definition von Laves et al. in den Hintergrund gerückt werden.
Demnach wird die Definition von Levi et al. verwendet. Das verwendete neuronale Netz schätzt
nur die in den Daten vorhandene Unsicherheit.
122 Forschungsstand und Hintergrund
2.6 Variational Inference
Variational Inference ist neben dem Markov-Chain-Monte-Carlo-Verfahren (MCMC) ein weite-
rer Lösungsansatz für Bayessche Inferenz. Das Ziel der Bayesschen Inferenz ist das Finden einer
bedingten Wahrscheinlichkeitsverteilung der Zustandsmenge X gegeben die Menge der Beobach-
tungen Y. Diese bedingte Verteilung kann als
p(Y, X )
p(X |Y) = R , (2.16)
p(Y, X )dX
formuliert werden. Das Integral ist in den meisten Fällen hochdimensional und erfordert viel Re-
chenzeit, oder ist nicht in geschlossener Form lösbar [25, 26].
An dieser Stelle setzt Variational Inference an. Der Vorteil von Variational Inference ist, dass
es im Vergleich mit MCMC Sampling schneller ist und sich dadurch auch für große Datensätze
eignet. Jedoch wird die Varianz der posterior Verteilung in den meisen Fällen von der Methode
zu gering eingeschätzt. Abhängig von der Aufgabenstellung kann eine Unterschätzung der Vari-
anz akzeptiert werden. Das Problem der bedingten Dichte über die latenten Zustände wird als
Optimierungsproblem ausgelegt. Anstelle das Integral p(X , Y)dY zu lösen wird die Verteilung
R
p(X | Y) durch eine einfachere parametrische Verteilung q(X ) angenähert. Das Optimierungspro-
blem lässt sich durch
q ∗ (X ) = arg minKL(q(X )kq(X |Y)), (2.17)
q(X )∈Q
ausdrücken. q ∗ ist die beste Approximierung der Verteilungen aus der Familie der Verteilungen
Q. Die Lösung des Optimierungsproblems kann sowohl durch Minimierung der KL-Divergenz, als
auch durch Maximierung der Evidence lower bound (ELBO) erfolgen. [25, 27, 28]
Variational Inference wird in dieser Arbeit für die Approximierung der Parameter der Observati-
onsmodelle des Bayes Filters eingesetzt, da sowohl die Zustandsmenge X als auch die Beobach-
tungen Y bekannt sind. Durch das Verfahren der Variational Inference muss die Verteilung q ∗ (X )
nicht zwangsläufig mit der Familie der zu approximierenden Verteilung übereinstimmen und kann
prinzipiell frei gewählt werden.
133 Unsicherheiten im Multiple Object Tracking
Der in dieser Arbeit verwendete Detektor liefert für jedes Bild einer Sequenz eine variable Anzahl an
Detektionen bestehend aus der Bounding-Box, Positionsunsicherheit und Klassenunsicherheiten.
Um all diese Informationen für das Tracking nutzbar zu machen wird im folgenden ein Ansatz
entwickelt, um sowohl die Positions- als auch die Klassenunsicherheiten in einen MOT Ansatz
basierend auf einem Kalman Filter zu integrieren.
3.1 Konfidenz und Track Existenz
Es existieren verschiedene Methoden um die Existenz eines Tracks in der MOT Struktur abzu-
bilden. Benbarka et al. [29] stellen zwei Methoden, count-based und confidence-based, vor und
entwickeln einen neuen Ansatz für die confidence-based Methoden. Die count-based Methoden
bestimmen die Existenz eines Tracks über die Anzahl der vorhandenen Detektionen, die einem
Track zugewiesen wurden, alle Detektionen werden gleich gewichtet. Da der in dieser Arbeit
verwendete Detektor eine Konfidenz der erkannten Objekte angibt, wird eine confidence-based
Methode für die Track Existenz verwendet. Im Gegensatz zu dem von Benkarka et al. vorgeschla-
genen Ansatz kommt in dieser Arbeit ein Bayes Filter zum Einsatz, beruhend auf der Annahme,
dass das Zusammenspiel aus Bild und Detektor ein Hidden Markov Modell darstellt. Das Bayes
Filter ist definiert als:
Z
p(xt |y0:t−1 ) = p(xt |xt−1 )p(xt−1 |y0:t−1 )dxt−1 , (3.1)
p(xt |y0:t ) = αt p(yt |xt )p(xt |y0:t−1 ). (3.2)
Die Normalisierung αt des Filters ist durch
1
αt = R , (3.3)
p(yt |xt )p(xt |y0:t−1 )dxt
definiert und bewirkt die Integration der Verteilung p(xt | y0:t ) zu eins. Der Belief p(xt | y0:t ) des
Filters bildet die Existenzwahrscheinlichkeit des Tracks gegeben der Beobachtung yt ab. Zu jedem
Zeitschritt wird die Konfidenz des Detektors zum Update der Filtergleichungen verwendet. Da
der Detektor keine wahren Negativ-Detektionen erzeugen kann, wird für einen Zeitschritt, in dem
einem Track keine Detektion zugewiesen werden konnte, eine Konfidenz von Null für den Update-
Schritt des Bayes-Filters verwendet. Das Hidden Markov Modell, wie in Abbildung 2.2 dargestellt,
kann auf die Aufgabe der Detektion von Objekten in Bildsequenzen übertragen werden. Der
latente Zustand x beschreibt die Existenz des Objekts in dem Bild und der beobachtete Zustand
y die Konfidenz des Detektors. Ob ein Objekt in dem nächsten Bild existiert wird durch die
Übergangswahrscheinlichkeit p(xt |xt−1 ) angegeben, die Likelihood ein vorhandenes Objekt mit
143 Unsicherheiten im Multiple Object Tracking
dem Detektor zu erkennen ist gegeben durch p(yt |xt ). Der Belief des Bayes Filters kann als
Bernoulli-Verteilung über die Zustände x ∈ {∃, @} angenommen werden. Existiert ein Objekt
entspricht das dem Zustand ∃, andernfalls @. Zu Zeitpunkt t = 0 wird eine Gleichverteilung der
Zustände p(∃) = p(@) = 0.5 angenommen.
Tabelle 3.1: Übergangswahrscheinlichkeiten des latenten Zustands xt−1 zu Zustand xt .
xt
xt−1 @ ∃
@ 0.99 0.01
∃ 0.05 0.95
Die Wahrscheinlichkeiten p(xt |xt−1 ) können über die mittlere Track Lebensdauer aus den Grund-
wahrheiten des Datensatz bestimmt werden und liegen in tabellarischer Form, siehe Tabelle 3.1,
vor. Die Werte der Tabelle legen nahe, dass ein Objekt, welches zu dem vorigen Zeitpunkt t − 1
nicht existiert, auch nicht in dem zu dem aktuellen Zeitpunkt t vorhandenen Bild existiert. Gleiches
gilt auch für den umgekehrten Fall. Damit ist das Modell für die Übergänge des latenten Zustands
definiert. Die Wahrscheinlichkeitsverteilung des Observationsmodells muss noch bestimmt werden,
dafür werden in dieser Arbeit zwei Ansätze gewählt und im folgenden beschrieben. Da das Ob-
servationsmodell die Likelihood der Beobachtung eines Objekts darstellt, muss es für den Bereich
[0, 1] definiert sein. Als Verteilungen kommen diskrete wie auch kontinuierliche Verteilungen in
Frage. Im folgenden sollen die Bernoulli- und Beta-Verteilung als repräsentation der Likelihood
untersucht werden. Beide Verteilungen sollen p(yt |xt ) in dem Bayes Filter abbilden. Da die Pa-
rameter der Verteilungen unbekannt sind, müssen diese mit Variational Inference approximiert
werden. Für jeden der Zustände werden mit Detektionen, die die Beobachtungen darstellen, auf
einem Trainingsdatensatz die Parameter der Verteilungen bestimmt. Als Approximationsverteilung
q ∗ der Parameter kann eine Delta-Distribution angenommen werden. Die auf dem in Abschnitt
4.3 ausgewählten Datensatz bestimmten Verteilungen der Likelihood-Modelle werden in Abschnitt
4.5 vorgestellt.
3.1.1 Bernoulli Likelihood
Da ein Objekt in einem Bild entweder vorhanden ist oder nicht, kann die Konfidenz des Detektors
mit einem Schwellwert ausgewertet werden. Ist die Konfidenz größer dem Schwellwert wird eine
Detektion verarbeitet, ist die Konfidenz kleiner wird die Detektion verworfen. Dieser Art der
Verarbeitung liegt die Annahme zu Grunde, dass eine Detektion nur einen der beiden Zustände
x ∈ {∃, @} annehmen kann und somit auch der Zustand des Tracks in diesem Zustandsraum
definiert ist. Auf Basis dieser Definition wird das Observationsmodell als eine Bernoulli-Verteilung
153 Unsicherheiten im Multiple Object Tracking
mit dem Parameter θ definiert:
Bern(x; θ) = θx (1 − θ)1−x . (3.4)
Die Konfidenz c des Detektors wird zu der nächsten Ganzzahl gerundet und ergibt so den Messwert
y: (
1 ; c ≥ 0.5
y= . (3.5)
0 ; c < 0.5
Für jeden Zustand x wird eine Bernoulli-Verteilung benötigt, die die Observationswahrscheinlich-
keiten abbildet. Die Verteilung Bernxt (yt ; θ) = p(yt |xt ) wird in (3.2) eingesetzt. Zusammen mit
den bereits definierten Zustandsübergangswahrscheinlichkeiten und der geschwellwerteten Konfi-
denz kann der neue Systemzustand berechnet werden. Die Parameter der Bernoulli-Verteilungen
Bern∃ (y; θ∃ ) und Bern@ (y; θ@ ) werden mit Hilfe von Stochastic Variational Inference durch das
Pyro Framework [28] und die Trainingsdaten angenähert.
3.1.2 Beta Likelihood
Durch das Schwellwerten der Konfidenz können Informationen verloren gehen, da die Konfidenz
die Unsicherheit des Klassenlabels angibt und in dieser Arbeit nur als Existenzwahrscheinlichkeit
interpretiert wird. Eine Detektion mit einer geringen Konfidenz kann trotzdem ein vorhandenes
Objekt abbilden und sollte demnach nicht einfach verworfen werden. Um Abhilfe zu schaffen und
damit möglicherweise bessere Aussagen über die Existenz des Tracks treffen zu können wird das
Observationsmodell als Beta-Verteilung mit den Parametern α und β angenommen
xα−1 (1 − x)β−1
Beta(x; α, β) = . (3.6)
B(α, β)
Der kontinuierliche Definitionsbereich [0, 1] der Beta-Verteilungen deckt sich mit dem der Kon-
fidenzen des Detektors. Dadurch kann die Konfidenz des Detektors direkt ohne Schwellwerten
zur Bestimmung der Likelihood verwendet werden. Wie auch für die Bernoulli-Likelihood muss
für jeden Zustand x eine Verteilung bestimmt werden. Die Verteilung Betaxt (yt ; α, β) wird in
(3.2) eingesetzt. Die Parameter α, β der Beta-Verteilungen werden ebenfalls mit Hilfe des Pyro
Framework und den Trainingsdaten angenähert.
3.1.3 Kalibrierung
Wie bereits in Abschnitt 2.5.1 beschrieben sind moderne künstliche neuronale Netzt häufig nicht
korrekt kalibriert. Um die Auswirkungen dieser Fehlkalibrierung und einer Korrektur dieser auf
einen Tracking Ansatz zu prüfen wird ein zusätzlicher Schritt in den Ablauf eingebaut.
Wie in Abbildung 3.1 dargestellt, soll die Kalibrierung der Konfidenz als ein weiterer Verarbei-
163 Unsicherheiten im Multiple Object Tracking
Position
Detektor Tracking
Kalibrierung
Konfidenz
Abbildung 3.1: Kalibrierung der Konfidenz als Zwischenverarbeitung vor dem Tracking. In ei-
nem typischen Aufbau werden Position und Konfidenz direkt an das Tracking
weitergegeben.
tungsschritt in den Aufbau des Tracking eingefügt werden. Die Integration der Konfidenzkalibrie-
rung als Zwischenverarbeitung bietet die Möglichkeit ggf. mit unterschiedlichen Kalibrierungsme-
thoden zu experimentieren und die Kalibrierung komplett zu umgehen um Referenzwerte für eine
Auswertung zu erzeugen.
Mit Blick auf die zwei vorgeschlagenen Likelihood-Modelle sollten sich besonders für die Bernoulli-
Likelihood Auswirkungen auf die Ergebnisse durch eine kalibrierte Konfidenz bemerkbar machen,
da die Konfidenz um 0,5 geschwellwertet wird. Aufgrund des kontinuierlichen Definitionsbereich
der Beta-Verteilung könnten die kalibrierten Konfidenzen auf die Beta-Likelihood eine geringere
Auswirkung haben als auf die Bernoulli-Likelihood. Die Untersuchungen für die Kalibrierung und
beide Likelihood-Modelle werden in Abschnitt 4.5 ausgeführt.
3.2 Positionsunsicherheiten
Das Multiple Object Tracking mit einem Kalman Filter ist ein weit verbreiteter Ansatz. Da in
dieser Arbeit ein Detektor verwendet wird, der zusätzlich zu der Position noch eine Unsicher-
heit der Position schätzt, muss ein Weg gefunden werden diese in das Kalman Filter sinnvoll zu
integrieren. Die Detektionen sind Bounding-Boxen in dem Format {cx , cy , w, h} mit den dazu-
gehörigen Unsicherheiten σcx , σcy , σw , σh . Dementsprechend liegen für jede Bounding-Box vier
Normalverteilungen vor
N (cx , σcx ), (3.7)
N (cy , σcy ), (3.8)
N (w, σw ), (3.9)
N (h, σh ). (3.10)
Für einen Ansatz ohne die Integration der Positionsunsicherheiten in den Kalman Filter muss
das Messrauschen R des Filters berechnet werden. Da das Messrauschen normalverteilt ist, kann
173 Unsicherheiten im Multiple Object Tracking
die Standardabweichung der einzelnen Parameter z mit
v
u N
u1 X
σ=t (zi − µ)2 , (3.11)
N i=1
auf den Detektionen des Trainingsdatensatz berechnet werden. N ist die Anzahl aller Detektionen,
µ die mittlere Abweichung der Detektionen von den Grundwahrheiten. σ bildet also die Standard-
abweichung der Differenz zwischen Detektion und Grundwahrheit ab und ist direkt abhängig von
der Lokalisierungsgenauigkeit des Detektors. Das Messrauschen wird für jeden Parameter der
Bounding-Boxen berechnet und liegt für den Filter als Matrix
σc2x 0 0 0
0 σc2y 0 0
R= (3.12)
2
0
0 σw 0
0 0 0 σh2
vor. Für alle Bounding-Boxen wird das gleiche Messrauschen verwendet.
Wie in (3.7) bis (3.10) dargestellt, schätzt der Detektor nicht nur die Parameter der Bounding-
Box, sondern eine Normalverteilung der Parameter. Da sowohl das Messrauschen R des Kalman
Filters, als auch die Detektionen Normalverteilt sind, kann die geschätzte Standardabweichung
des Detektors als Messrauschen in dem Kalman Filter verarbeitet werden. Folglich wird der auf
dem Datensatz bestimmte Parameter R des Kalman Filter durch die Unsicherheit Rt , bestehend
aus den Varianzen des Detektors, ersetzt. Dadurch fließt für jede Detektion ein eigenes Rauschen
in die Berechnungen des Filters ein, im Gegensatz zu dem für alle Detektionen gleichen R.
Wird (2.10) in (2.11) eingesetzt kann das Kalman Gain als
Kt = P̂t H T St−1
P̂t H T
= (3.13)
H P̂t H T + R
formuliert werden. Der Parameter R des Kalman Filter wird durch die Unsicherheit der Detektion
Rt ersetzt. P̂t beschreibt die prädizierte Kovarianz des Filterzustands, H ist die Transformations-
matrix des Zustandsraums in den Messraum. Durch das Ersetzen des statischen Filterparameter
R mit Rt sind nun sowohl das Messrauschen Rt als auch die Kovarianz des Zustands P̂t zeit-
veränderlich. Wie aus (3.13) ersichtlich wird, beeinflusst die Relation der beiden Parameter das
Kalman Gain. Geht die Unsicherheit Rt des Detektors gegen Null, so gleicht das Kalman Gain
der inversen Transformationsmatrix H T . Geht die vorhergesagte Kovarianz des Zustands gegen
Null, so läuft das Kalman Gain gegen Null. Werden (3.13) und (2.9) in die Updategleichung des
Kalman Filter (2.12) substituiert, ist zu erkennen, dass ein geringes Messrauschen Rt dazu führt,
dass der neue Systemzustand mehr auf dem Messwert basiert. Umgekehrt gilt, dass eine geringe
18Sie können auch lesen

















































