Daten als Treibstoff selbstlernender Systeme Ist der Datenschutz den neuen Herausforderungen gewachsen? - Martina Arioli 26. September 2018
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

Daten als Treibstoff selbstlernender Systeme
Ist der Datenschutz den neuen
Herausforderungen gewachsen?
Martina Arioli
26. September 2018
0
Übersicht
1. Einführung
1. Selbstlernende Systeme und AI
2. Daten als Treibstoff selbstlernender Systeme
3. Prinzipien des Datenschutzes – Big Data / AI
2. “Personendaten”: Erosion, Angleichung, Aufweichung?
1. Anwendbarkeit des Datenschutzrechts
2. Anonymisierung: Differential Privacy und Federated Learning
3. Überblick Initiativen und EU Digital Single Market / free data flow
3. Transparenz und Algorithmic Accountability
1. Informationspflicht und Auskunftsrecht
2. Explainability?
3. Fairness – Bias
4. Ist der Datenschutz den (neuen) Herausforderungen gewachsen?
Fazit und Ausblick
1
1. Einführung
1.1. Selbstlernende Systeme und AI
Gregg Wirth, 2016 http://www.legalexecutiveinstitute.com/artificial-intelligence-in-law-the-state-of-play-2016-part-1/ai-graphic-new/
2
1. Einführung
1.1. Selbstlernende Systeme
https://cdn.edureka.co/blog/wp-content/uploads/2017/05/Deep-Neural-Network-What-is-Deep-Learning-Edureka.png
3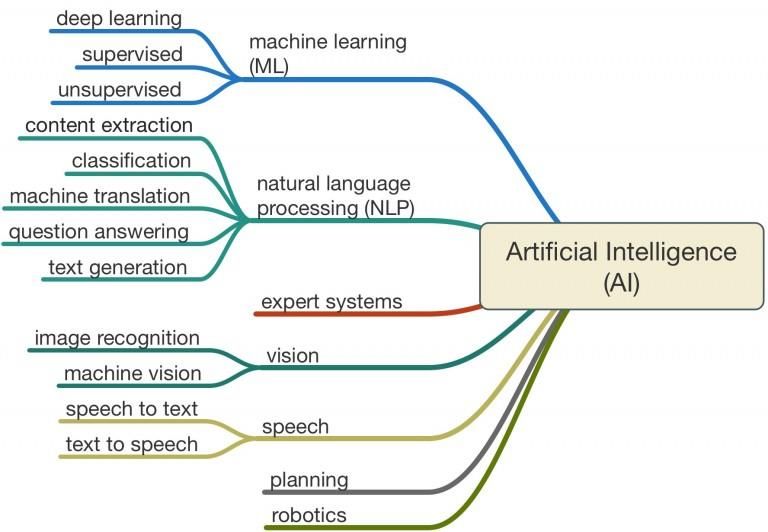
1. Einführung
1.1. Selbstlernende Systeme
Die Beziehung zwischen Artificial Intelligence und Big Data ist bi-direktional:
1. Artificial Intelligence benötigt eine grosse Menge an Daten, um zu lernen.
2. Big Data Analyse Techniken verwenden Artificial Intelligence, um einen Wert aus grossen
Datensätzen zu extrahieren.
41. Einführung
1.2. Daten als Treibstoff selbstlernender Systeme
The NYPD gave IBM access to
CCTV cameras placed all around
New York City, enabling the tech
company to refine image
recognition search by facial
features, including skin tone and
body type.
https://theintercept.com/2018/09/06/nypd-
surveillance-camera-skin-tone-search
Civil liberties advocates say they
are alarmed by the NYPD’s
secrecy in helping to develop a
program with the potential
capacity for mass racial profiling.
https://www.wired.com/story/ibm-made-cops-a-tool-
to-search-surveillance-video-by-skin-
color?mbid=social_twitter/
Google Images tagging black people as Gorillas in
2015: https://www.wired.com/story/when-it-comes-to-
gorillas-google-photos-remains-blind/
The population of New York was
Foto: Casey Chin / Getty Images
never informed.
51. Einführung
1.3. Prinzipien des Datenschutzes – Big Data / AI
Datenschutzgrundsätze Big Data / AI
Rechtmässigkeit, Treu und Glauben Transparenz Transparenz? Pflicht zur Verhinderung von Bias?
Zweckbindung Weiterverarbeitung? Beschränkt: Zweckbindung
Art. 5.1.b DSGVO sowie Informationspflicht Art.
13.3. DSGVO
Datenminimierung inhärenter Widerspruch:
Big Data Analytics ist nur sinnvoll, wenn
umfangreichen Datensätze über einen längeren
Zeitraum hinweg verarbeitet werden können
Richtigkeit idealerweise! (Bias!)
Sicherheit und Vertraulichkeit Selbstinteresse
Beschränkung der Speicherfrist inhärenter Widerspruch
Rechenschaftspflicht “Algorithmic Accountability”
62. “Personendaten”: Erosion, Angleichung, Aufweichung?
2.1. Anwendbarkeit des Datenschutzrechts
Datenschutzrecht anwendbar Datenschutzrecht nicht anwendbar
Personendaten: «Sachdaten», Geodaten,
Art. 4.1. DSGVO: «alle Informationen, die sich auf eine identifizierteSteuerungsinformationen, etc.
oder identifizierbare natürliche Person (= „betroffene Person“)
beziehen; als identifizierbar wird eine natürliche Person angesehen,
die direkt oder indirekt, insbesondere mittels Zuordnung zu einer IoT Daten?
Kennung wie einem Namen, zu einer Kennnummer, zu Standort-
daten, zu einer Online-Kennung oder zu einem oder mehreren
besonderen Merkmalen, die Ausdruck der physischen, physio-
logischen, genetischen, psychischen, wirtschaftlichen, kulturellen oder
sozialen Identität dieser natürlichen Person sind, identifiziert werden
kann.»
Pseudonymisierte Personendaten: Anonymisierte Personendaten:
Art. 4.5. DSGVO: «Pseudonymisierung» ist die «Verarbeitung E. 26 DGSVO: «Die Grundsätze des Datenschutzes sollten daher
personenbezogener Daten in einer Weise, dass die personen- nicht für anonyme Informationen gelten, d.h. für Informationen, die
bezogenen Daten ohne Hinzuziehung zusätzlicher Informationen sich nicht auf eine identifizierte oder identifizierbare natürliche Person
nicht mehr einer spezifischen betroffenen Person zugeordnet werden beziehen, oder personenbezogene Daten, die in einer Weise ano-
können, sofern diese zusätzlichen Informationen gesondert nymisiert worden sind, dass die betroffene Person nicht oder nicht
aufbewahrt werden und technischen und organisatorischen Mass- mehr identifiziert werden kann.»
nahmen unterliegen, die gewährleisten, dass die personen-
Anonymisierung eines Datenbestandes ist oft nur dann
bezogenen Daten nicht einer identifizierten oder identifizierbaren irreversibel, wenn der Informationsgehalt weitgehend entfernt
natürlichen Person zugewiesen werden.» wird
Probleme der Re-Identifikation / De-Anonymisierung
Illustrativ: WP29: Opinion 03/2017 on Processing personal data in the context of Cooperative Intelligent Transport Systems (C-ITS)
72. “Personendaten”: Erosion, Angleichung, Aufweichung?
2.2. “Anonymisierung” mit Differential Privacy
Differential Privacy konzentriert sich hauptsächlich darauf, die Wiedererkennung von
Datensubjekten bei der Abfrage aus einem Datensatz zu verhindern, indem dem Datensatz
ein Rauschen (randomness) beigefügt wird.
Differential Privacy ist letztlich eine mathematische Definition von Privatsphäre, bei der
berücksichtigt wird, ob die Daten einer bestimmten Person einen signifikanten Einfluss auf die
Antwort auf eine Datasetabfrage haben. Ist dies nicht der Fall, dann identifizieren die Daten nicht
die Person, die sie beschreibt.
Begründet von Cynthia Dwork, siehe “Differential Privacy. In: 33rd International Colloquium on Automata, Languages and Programming”
part II (ICALP 2006). Springer, Juli 2006
Bedingungen für den Einsatz von Differential Privacy:
1. die Gesamtmenge der Daten im Datensatz muss relativ gross ist, so dass eine gewisse
Verzerrung akzeptabel bleibt
2. die unteren und oberen Grenzen der numerischen Antworten sind bekannt
3. die „Ausreisser“ in einem Datensatz sind nicht besonders wichtig.
Trotz der vielen Vorteile gegenüber früheren Techniken zur Umsetzung des Datenschutzes
stösst Differential Privacy an Grenzen. Differential Privacy kann nicht verhindern, dass eine
Identifikation aufgrund des Vorwissens desjenigen, der den Datensatz abfragt, dennoch möglich
ist.
Für die gesamte Verarbeitung gilt bis zum Einsatz von Differential Privacy Datenschutzrecht!
82. “Personendaten”: Erosion, Angleichung, Aufweichung?
2.1. “Anonymisierung” mit Federated Learning
Federated Learning ist ein
dezentralisierter Prozess des
machine learning, das Feedbacks
von den Nutzern erhält, ohne ihre
individuellen Daten in der Cloud
zu speichern.
Das Gerät des Nutzers sammelt
selbst die Daten, die dafür
benötigt werden um das Modell
zu verbessern, und anstatt die
Rohdaten an die Cloud zur
Auswertung zu senden, bestimmt
es selbst die Änderungen, die an
dem Modell vorgenommen
werden sollen.
Datenschutzrecht dürfte wohl
keine Anwendung finden. Wurde jüngst von Google entwickelt:
https://ai.googleblog.com/2017/04/federated-learning-collaborative.html
92. “Personendaten”: Erosion, Angleichung, Aufweichung?
2.2. Überblick Initiativen: Hype, Angst und Aktionismus
USA: Unmanned Aircraft Systems (UAS) (Oktober 2017); Big Data: A Report on Algorithmic
Systems, Opportunity, and Civil Rights (Mai 2016); AI, Automation, and the Economy (Dezember
2016); Preparing for the Future of Artificial Intelligence (Oktober 2016)
China: Next generation AI Development Plan (Juli 2017)
Japan: Artificial Intelligence Technology Strategy (März 2017), New Robot Strategy (Februar 2015)
EU: Artificial Intelligence: European Commission outlines a European approach to boost
investment and set ethical guidelines (April 2018): Horizon 2020; “AI-on-demand platform“;
European AI Alliance; free flow of non-personal data in the Digital Single Market.
http://europa.eu/rapid/press-release_IP-18-3362_en.htm
United Kingdom: Growing the Artificial Intelligence Industry in the UK (Oktober 2017)
Deutschland: Eckpunkte der Bundesregierung für eine Strategie Künstliche Intelligenz (Juli 2018)
Und die Schweiz?
Strategie "Digitale Schweiz“ (5. September 2018)
Bericht der Expertengruppe zur Zukunft der Datenbearbeitung und Datensicherheit (17. August
2018) https://www.admin.ch/gov/de/start/dokumentation/medienmitteilungen/rss-feeds/nach-dienststellen/medienmitteilungen-und-
reden.msg-id-72083.html
Eckwerte für eine Datenpolitik der Schweiz (9. Mai 2018)
102. “Personendaten”: Erosion, Angleichung, Aufweichung?
2.2. Überblick: EU Digital Single Market / free data flow
1. Digital Single Market / free data flow of non-personal data:
1. Aufhebung „ungerechtfertigter“ Datenlokalisierungsbeschränkungen durch
Behörden.
2. Die grundsätzliche Datenverfügbarkeit für die zuständigen Behörden stellt sicher,
dass Daten zu Regulierungs- und Aufsichtszwecken auch dann zugänglich bleiben, wenn
sie in anderen EU-Ländern gespeichert oder verarbeitet werden.
3. Massnahmen, die Cloud-Anbieter zur Selbstregulierung und Entwicklung von
Verhaltenskodizes anhalten sollen, um Anbieterwechsel und die Rückübertragung
von Daten auf eigene IT-Systeme einfacher zu machen. (Datenportabilität, vendor lock-
in)
4. Die Sicherheitsanforderungen für die Datenspeicherung und -verarbeitung gelten auch
dann, wenn Unternehmen ihre Daten in einem anderen Mitgliedstaat speichern und
verarbeiten.
5. Zentrale Anlaufstellen in jedem Mitgliedstaat, die untereinander und mit der
Kommission in Verbindung stehen, um die effektive Anwendung der neuen Vorschriften
über den freien Fluss nicht personenbezogener Daten zu gewährleisten.
2. Auch die neue ePrivacy-Verordnung könnte in Zukunft relevant werden, indem
Kommunikation Maschine-Maschine in den Anwendungsbereich dieser Verordnung fällt.
113. Transparenz und “Algorithmic Accountability”
3.1. Information über und Zugang zum Algorithmus
Nach der DSGVO besteht eine übergreifende Pflicht zur Transparenz, welche auf drei
Kernbereiche Anwendung findet:
1) die Information der betroffenen Personen im Zusammenhang mit der nach Treu und
Glauben erfolgenden Verarbeitung,
2) die Art und Weise, in der die Verantwortlichen mit den betroffenen Personen in Bezug auf ihre
Rechte nach der DSGVO kommunizieren, und
3) wie die Verantwortlichen den betroffenen Personen die Ausübung ihrer Rechte erleichtern.
Artikel 29 Datenschutzgruppe WP 260 rev01 11. April 2018, http://ec.europa.eu/justice/article-29/documentation/index_en.htm
123. Transparenz und “Algorithmic Accountability”
3.1. Information über und Zugang zum Algorithmus
Welche Regeln der DSGVO kommen im Zusammenhang mit AI zusätzlich zu den allgemeinen
Regeln zur Anwendung?
1. Informationspflicht des Verantwortlichen bei automatisierten Einzelentscheidungen und
Profiling nach Art. 13–14 und E. 60–62 DSGVO
2. Auskunftsrecht der betroffenen Person betr. automatisierten Einzelentscheidungen und
Profiling nach Art. 15 und E. 63 DSGVO
3. Recht, keiner ausschliesslich automatisierten Einzelentscheidungen unterworfen zu
werden nach Art. 22 und E. 71 DSGVO
Siehe auch:
- Art. 11 Richtlinie 2016/680 (explizites Verbot!)
Gänzlich neu?
War bereits in Art. 15 der Datenschutzrichtlinie 95/46/EG von 1995 enthalten!
Aber: nur wenig Gerichtsentscheidungen (z.B. Schufa unter dem BDSG)
133. Transparenz und “Algorithmic Accountability”
3.1. Informationspflicht nach Art. 13 und 14 DSGVO
Informationspflicht bei Erhebung von personenbezogenen Daten bei der betroffenen
Person (Art. 13.2.f DSGVO) :
„Zusätzlich zu den Informationen gemäß Absatz 1 stellt der Verantwortliche der betroffenen
Person zum Zeitpunkt der Erhebung dieser Daten folgende weitere Informationen zur Verfügung,
die notwendig sind, um eine faire und transparente Verarbeitung zu gewährleisten: (…)
das Bestehen einer automatisierten Entscheidungsfindung einschließlich Profiling gemäß Artikel
22 Absätze 1 und 4 und — zumindest in diesen Fällen — aussagekräftige Informationen über
die involvierte Logik sowie die Tragweite und die angestrebten Auswirkungen einer derartigen
Verarbeitung für die betroffene Person.“
Einschränkung auf Fälle gemäss Art. 22.1. und 22.4. DSGVO bedeutet, dass die betroffene
Person nicht über jede automatisierte Einzelentscheidung informiert werden muss, sondern nur,
wenn die Entscheidung mit einer Rechtsfolge für die betroffene Person verbunden ist oder sie
erheblich beeinträchtigt.
Dito: Informationspflicht, wenn die personenbezogenen Daten nicht bei der betroffenen
Person erhoben wurden (Art. 14.2.g DSGVO)
143. Transparenz und “Algorithmic Accountability”
3.1. Auskunftsrecht nach Art. 15 DSGVO
Das Auskunftsrecht der betroffenen Person erstreckt sich gemäss Art. 15.1.h DSGVO auf:
„das Bestehen einer automatisierten Entscheidungsfindung einschließlich Profiling gemäß Artikel
22 Absätze 1 und 4 und — zumindest in diesen Fällen — aussagekräftige Informationen über
die involvierte Logik sowie die Tragweite und die angestrebten Auswirkungen einer
derartigen Verarbeitung für die betroffene Person.“
Einschränkung auf Fälle gemäss Art. 22.1 und 4 DSGVO bedeutet, dass die betroffene Person
nur dann einen Auskunftsanspruch gestützt auf 15.1.h DSGVO hat, wenn die Entscheidung mit
einer Rechtsfolge für die betroffene Person verbunden ist oder sie erheblich beeinträchtigt.
E. 63 DSGVO schränkt den Auskunftsanspruch weiter ein:
- „Dieses Recht sollte die Rechte und Freiheiten anderer Personen, etwa
Geschäftsgeheimnisse oder Rechte des geistigen Eigentums und insbesondere das
Urheberrecht an Software, nicht beeinträchtigen. Dies darf jedoch nicht dazu führen, dass der
betroffenen Person jegliche Auskunft verweigert wird.“
- Ferner ist die Auskunftspflicht beschränkt auf Informationen, die nach Möglichkeit zur Verfügung
gestellt werden können, vgl. die Wendung „wenn möglich“.
153. Transparenz und “Algorithmic Accountability”
3.2. Gehalt der Information und Auskunft?
1. Die Wendung „ aussagekräftige Informationen über die involvierte Logik sowie die
Tragweite und die angestrebten Auswirkungen einer derartigen Verarbeitung “ beinhaltet
keine Pflicht des Verantwortlichen, Zugang zum Algorithmus zu gewähren.
2. Informationspflicht nach Art. 13 und 14 DSGVO:
Die betroffene Person ist im Zeitpunkt der Erhebung der Daten zu informieren (bzw. innert 30
Tagen, sofern Daten bei einem Dritten erhoben werden):
=> Die Information muss ex ante erfolgen.
die Information kann sich nur auf das allgemeine Funktionieren des Algorithmus beziehen, also auf
Systemanforderungen, Entscheidungsbäume, vordefinierte Modelle, Kriterien, Klassifikationsstrukturen, nicht
aber auf die einzelne Entscheidung.
3. Auskunftsrecht nach Art. 15 DSGVO:
Der betroffenen Person sind auf ihr Auskunftsbegehren hin alle Informationen zu geben um die
Rechtmäßigkeit der Verarbeitung überprüfen zu können:
=> Die Information kann nur ex post erfolgen.
=> Die Auskunft sollte Informationen über das allgemeine Funktionieren des Algorithmus geben, aber auch
über den Hergang der einzelnen Entscheidung, wie Rationale, die Gewichtung, die maschinell definierten
fallspezifischen Entscheidungsregeln, Informationen über Referenz- oder Profilgruppen.
163. Transparenz und “Algorithmic Accountability”
3.1. Automatisierte Einzelentscheidung nach Art. 22 DSGVO
„(1) Die betroffene Person hat das Recht, nicht einer ausschließlich auf einer automatisierten
Verarbeitung — einschließlich Profiling — beruhenden Entscheidung unterworfen zu werden, die
ihr gegenüber rechtliche Wirkung entfaltet oder sie in ähnlicher Weise erheblich beeinträchtigt.
(2) Absatz 1 gilt nicht, wenn die Entscheidung:
a) für den Abschluss oder die Erfüllung eines Vertrags zwischen der betroffenen Person und
dem Verantwortlichen erforderlich ist,
b) aufgrund von Rechtsvorschriften der Union oder der Mitgliedstaaten, denen der
Verantwortliche unterliegt, zulässig ist und diese Rechtsvorschriften angemessene
Maßnahmen zur Wahrung der Rechte und Freiheiten sowie der berechtigten Interessen der
betroffenen Person enthalten oder
c) mit ausdrücklicher Einwilligung der betroffenen Person erfolgt.
(3) In den in Absatz 2 Buchstaben a und c genannten Fällen trifft der Verantwortliche
angemessene Maßnahmen, um die Rechte und Freiheiten sowie die berechtigten Interessen der
betroffenen Person zu wahren, wozu mindestens das Recht auf Erwirkung des Eingreifens
einer Person seitens des Verantwortlichen, auf Darlegung des eigenen Standpunkts und auf
Anfechtung der Entscheidung gehört.
(4) Entscheidungen nach Absatz 2 dürfen nicht auf besonderen Kategorien personenbezogener
Daten nach Artikel 9 Absatz 1 beruhen, sofern nicht Artikel 9 Absatz 2 Buchstabe a oder g gilt und
angemessene Maßnahmen zum Schutz der Rechte und Freiheiten sowie der berechtigten
Interessen der betroffenen Person getroffen wurden.“
173. Transparenz und “Algorithmic Accountability”
3.1. Art. 22 DSGVO: Verbot oder Betroffenenrecht?
„Die betroffene Person hat das Recht, nicht einer ausschließlich auf einer automatisierten
Verarbeitung — einschließlich Profiling — beruhenden Entscheidung unterworfen zu werden“
Profiling und automatisierte Entscheidfindung sind erlaubt. Grundsätzlich verboten ist jedoch
die automatisierte Entscheidfindung, wenn keinerlei menschliches Zutun vorliegt.
WP29 Leitlinien zu automatisierten Entscheidungen im Einzelfall einschließlich Profiling für die Zwecke der Verordnung 2016/679, (6.
Februar 2018), unter Verweis auf E. 71 DSGVO.
Die Pflichten des Verantwortlichen nach Art. 22.3 DSGVO beinhalten bei der Verarbeitung im
Rahmen eines Vertrags oder gestützt auf ausdrücklicher Einwilligung mindestens:
- Recht auf Erwirkung des Eingreifens einer Person seitens des Verantwortlichen,
- Recht auf Darlegung des eigenen Standpunkts
- Recht auf Anfechtung der Entscheidung.
Keine Pflicht des Verantwortlichen, Zugang zum Algorithmus zu gewähren oder überhaupt
zu erklären, wie eine automatisierte Einzelentscheidung entsteht.
E. 71 DSGVO sieht vor, dass die Massnahmen auch eine „Erläuterung der nach einer
entsprechenden Bewertung getroffenen Entscheidung“ vorsehen sollen. Nur: Erwägungen
sind unverbindlich!
Erfolgt die Verarbeitung gestützt auf Unionsrecht oder dem Recht der Mitgliedstaaten, denen
der Verantwortliche unterliegt, so hat der Verantwortliche keine solchen Massnahmen zu
treffen.
183. Transparenz und “Algorithmic Accountability”
3.1. Profiling
Art. 4.4. DSGVO
„Profiling ist jede Art der automatisierten Verarbeitung personenbezogener Daten, die darin
besteht, dass diese personenbezogenen Daten verwendet werden, um bestimmte persönliche
Aspekte, die sich auf eine natürliche Person beziehen, zu bewerten, insbesondere um Aspekte
bezüglich Arbeitsleistung, wirtschaftliche Lage, Gesundheit, persönliche Vorlieben, Interessen,
Zuverlässigkeit, Verhalten, Aufenthaltsort oder Ortswechsel dieser natürlichen Person zu
analysieren oder vorherzusagen.“
Profiling liegt somit nur vor, wenn der Bewertungsprozess vollständig automatisiert ist.
Jederzeitiges Widerspruchsrecht gestützt auf Art. 21.1 DSGVO bedingt Information.
Recht auf Datenportabilität betrifft nur die Daten, nicht aber das Profile selbst.
Berichtigungsanspruch bezieht sich nicht nur auf Input-Data, sondern auch auf Output-Data.
193. Transparenz und “Algorithmic Accountability”
3.2. Explainability?
http://www.iflscience.com
203. Transparenz und “Algorithmic Accountability”
3.2. Explainability?
Ein selbstlernendes System (künstliches neuronales Netz) besteht aus mehreren
Schichten von untereinander verbundenen Neuronen. Falls die Eingangssignale
eines einzelnen Neurons eine bestimmte Schwelle überschreiten, gibt es das Signal
weiter, sonst bleibt es stumm. An jedem Knoten erfolgt eine logische Entscheidng.
Allerdings ist dies eine blosse Darstellung, aber keine Erklärung dafür, was der
Algorithmus wirklich tut, um zu einem Ergebnis zu gelangen.
Die Resultate, die selbstlernende Systeme, insbesondere deep learning, erzielen,
sind für die Entwickler nicht immer nachvollziehbar und können von diesen deshalb
auch nicht erklärt werden.
Beispiele:
AlphaGo Move 37
Will Knight, MIT Technology Review, https://www.technologyreview.com/s/602094/ais-language-problem/
Image recognition: Altersschätzung
Rasmus Rothe and Radu Timofte and Luc Van Gool, "Deep expectation of real and apparent age from a single image without facial
landmarks", International Journal of Computer Vision (IJCV), 2016
213. Transparenz und “Algorithmic Accountability”
3.2. Fairness – Bias und Diskriminierung
Die Verarbeitung von Personendaten muss fair und transparent erfolgen und darf nicht
diskriminierend sein:
• E. 71 DSGVO: „Um unter Berücksichtigung der besonderen Umstände und
Rahmenbedingungen, unter denen die personenbezogenen Daten verarbeitet werden, der
betroffenen Person gegenüber eine faire und transparente Verarbeitung zu gewährleisten,
sollte der für die Verarbeitung Verantwortliche geeignete mathematische oder statistische
Verfahren für das Profiling verwenden, technische und organisatorische Maßnahmen treffen,
mit denen in geeigneter Weise insbesondere sichergestellt wird, dass Faktoren, die zu
unrichtigen personenbezogenen Daten führen, korrigiert werden und das Risiko von
Fehlern minimiert wird, und personenbezogene Daten in einer Weise sichern, dass den
potenziellen Bedrohungen für die Interessen und Rechte der betroffenen Person Rechnung
getragen wird und mit denen verhindert wird, dass es gegenüber natürlichen Personen
aufgrund von Rasse, ethnischer Herkunft, politischer Meinung, Religion oder Weltanschauung,
Gewerkschaftszugehörigkeit, genetischer Anlagen oder Gesundheitszustand sowie sexueller
Orientierung zu diskriminierenden Wirkungen oder zu Maßnahmen kommt, die eine solche
Wirkung haben. Automatisierte Entscheidungsfindung und Profiling auf der Grundlage
besonderer Kategorien von personenbezogenen Daten sollten nur unter bestimmten
Bedingungen erlaubt sein.“
223. Transparenz und “Algorithmic Accountability”
3.3. Fairness – Bias und Diskriminierung
Daten als Treibstoff der Perpetuierung tradierter Perzeptionen zur Vorhersage der Zukunft?
233. Transparenz und “Algorithmic Accountability”
3.3. Fairness – Bias und Diskriminierung
http://www.iflscience.com
244. Ist der Datenschutz den Herausforderungen
gewachsen? Fazit und Ausblick
1. Kein Recht auf Zugang zum Algorithmus: ist eine Überprüfung einer automatisierten
Einzelentscheidung überhaupt möglich? „Aufrüstung“ der Datenschutzbehörden mit IT-
Entwicklern?
2. Explainability ist eine Herausforderung für die Entwickler der Algorithmen, aber die
Komplexität darf nicht dazu führen, dass den Betroffenen keine aussagekräftigen
Informationen abgegeben werden.
3. Idealerweise würden Algorithmen dabei helfen, Verzerrungen zu erkennen. Um zum richtigen
Ergebnis zu gelangen, braucht es nicht mehr, sondern qualitative bessere Daten. Zu viel
Daten hat ähnliche Auswirkungen wie zu wenig: Mit zunehmender Datenmenge häuft sich die
Anzahl Korrelationen, was die Gefahr von willkürlichen Resultaten erhöht.
4. Sind die Standards für maschinelle Entscheidungen anders als für die menschliche
Entscheidungsfindung?
5. Aufhebung der Unterscheidung: Gleiche Prinzipien für Sachdaten wie für Personendaten?
6. Zertifizierung von AI Anwendungen?
7. Ist es Aufgabe des Datenschutzes dafür zu sorgen, dass mit selbstlernenden Systemen
erzielte Resultate politisch korrekt sind?
8. Das Problem der Sicherstellung von Fairness von selbstlernenden Systemen kann nicht über
den Datenschutz allein gelöst werden. => Ethics Boards
25Ein paar Gedanken für auf den Weg
“Instead of people writing software, we have data writing software.”
Hsun Huan, CEO NVIDIA, economist 25 Juni 2016
“It turns out that a large portion of real-world problems have the property that it is significantly
easier to collect the data than to explicitly write the program. A large portion of programmers of
tomorrow do not maintain complex software repositories, write intricate programs, or analyze their
running times. They collect, clean, manipulate, label, analyze and visualize data that feeds neural
networks.”
Andrej Karpathy, Software 2.0, Medium.com, 2018, (https://medium.com/@karpathy/software-2-0-a64152b37c35)
“When implemented in autonomous machines automated decisions can have an even greater
impact. How could the data protection framework for automated decisions be applied to
autonomous machines? Who is the data controller for an autonomous machine with self-learning
capabilities?”
EDPS, Artificial Intelligence, Robotics, Privacy and Data Protection (Marrakesh, 2016)
„Ohne Menschen sind Computer Raumwärmer, die Muster erzeugen.“
Jaron Lanier, Friedenspreisrede, „Der High-Tech-Frieden braucht eine neue Art von Humanismus“, 2014
26Sie können auch lesen

















































