Datenexploration für Kryptowährungen - Lukas Sontheimer, Ralph Kölle und Thomas Mandl* - De Gruyter
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Information. Wissenschaft & Praxis 2020; 71(2–3): 107–114
Nutzerforschung
Lukas Sontheimer, Ralph Kölle und Thomas Mandl*
Datenexploration für Kryptowährungen
Prototypische Entwicklung eines Dashboards mit Open Source Technologie
https://doi.org/10.1515/iwp-2020-2076 Descriptors: Visualization, Data, Twitter, Crypto currency,
Eingereicht am 12. Januar 2020; Angenommen am 23. Januar 2020 ElasticSearch
Zusammenfassung: Kryptowährungen gewinnen zuneh- Exploration de données pour les monnaies cryptées
mend an Bedeutung und ihr Handel unterliegt großen Développement d'un prototype de tableau de bord avec
Wertschwankungen. Erfolgreiche Händler müssen sich une technologie open source
aus zahlreichen Quellen informieren und Daten analysie-
Résumé: Les monnaies cryptographiques prennent de
ren. Wir präsentieren ein prototypisches System, das aus
plus en plus d’importance et leur commerce est soumis à
Twitter die Nachrichten zu Kryptowährungen filtert und
de grandes fluctuations de valeur. Les commerçants qui
anschließend in einer graphischen und interaktiven Ober-
réussissent doivent obtenir des informations et analyser
fläche darstellt. Der Beitrag zeigt beispielhaft, wie mit der
des données provenant de nombreuses sources. Nous pré-
offenen ElasticSearch Technologie eine Datenvisualisie-
sentons un système prototype qui filtre les messages sur
rung entwickelt werden kann. Zwei Interviews mit Domä-
les monnaies cryptées de Twitter et les affiche ensuite
nenexperten weisen auf Schwächen und Stärken des Sys-
dans une interface graphique et interactive. L’article mon-
tems hin.
tre de manière exemplaire comment la visualisation de
Deskriptoren: Visualisierung, Daten, Twitter, Kryptowäh- données peut être développée avec la technologie ouverte
rung, ElasticSearch ElasticSearch. Deux entretiens avec des experts du do-
maine soulignent les faiblesses et les forces du système.
Data exploration for crypto currencies
Descripteurs: Visualisation, Données, Twitter, Crypto
Prototypical development of a dashboard with open sour-
monnaie, ElasticSearch
ce technology
Abstract: Crypto currencies are becoming increasingly im-
portant and their trading is subject to large fluctuations in
value. Successful traders must obtain information and
1 Blockchain und Digitalisierung
analyze data from numerous sources. We present a proto- im Finanzbereich
typical system that filters messages about crypto curren-
cies from Twitter and then displays them in a graphical Die Blockchain ist derzeit in aller Munde. Dabei handelt es
and interactive interface. The article shows exemplarily sich um eine dezentrale Technologie, die alle Transaktio-
how data visualization can be developed with the open nen eines Peer-to-Peer-Netzwerkes verifiziert und zusam-
ElasticSearch technology. Two interviews with domain ex- menfasst. Diese Blöcke werden in einer Kette festgehalten,
perts point out weaknesses and strengths of the system. die zusammenhängend die Blockchain bilden (Nakamoto
2008). Diese bietet Dezentralisierung, Echtzeit Peer-to-
Peer Operationen, Anonymität, Transparenz sowie Un-
*Kontaktperson: Apl. Prof. Dr. Thomas Mandl, Universität Hildes-
heim, Institut für Informationswissenschaft und Sprachtechnologie, abänderlichkeit (Hassani et al. 2018). Ihre bisher weitrei-
Universitätsplatz 1, 31141 Hildesheim, chendste Anwendung liegt in Kryptowährungen. Deren
E-Mail: sontheim@uni-hildesheim.de Kern bildet jeweils ein verschlüsseltes Fundament, wel-
Lukas Sontheimer, Universität Hildesheim, Institut für Informations- ches durch die Mischung von unterschiedlichen Krypto-
wissenschaft und Sprachtechnologie, Universitätsplatz 1,
graphie-Methoden sichere Peer-to-Peer Transaktionen er-
31141 Hildesheim, E-Mail: koelle@uni-hildesheim.de
Dr. Ralph Kölle, Universität Hildesheim, Institut für Informations-
möglicht (Tschorsch & Scheuermann 2016).
wissenschaft und Sprachtechnologie, Universitätsplatz 1, Als erste Volkswirtschaft hat China 2019 angekündigt,
31141 Hildesheim, E-Mail: mandl@uni-hildesheim.de eine eigene Digitalwährung einzuführen. Dies zeigt, dass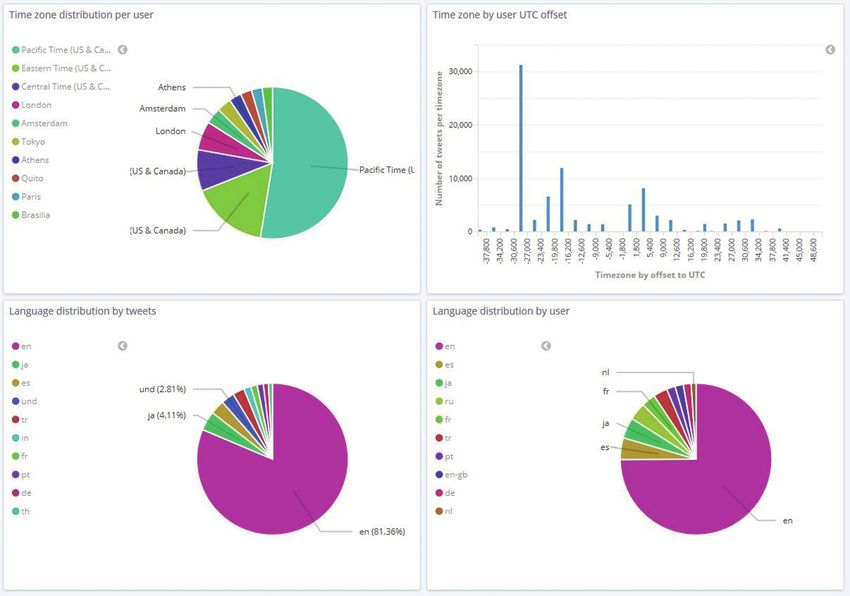
108 Lukas Sontheimer, Ralph Kölle und Thomas Mandl, Datenexploration für Kryptowährungen
die Digitalisierung auch die Finanzmärkte zukünftig noch gemeinen geworfen (Hassani et al. 2018: 1) und Krypto-
mehr beeinflussen wird. Bereits bestehende Kryptowäh- währungen selbst als Datenquelle für Big Data betrachtet.
rungen basieren auf komplexen Netzwerktechnologien. Sie kommen zu dem Schluss, dass mit Big Data Analyse
Ihr Wert kann kaum von regulierenden Institutionen be- Techniken wertvolle Erkenntnisse gewonnen werden kön-
einflusst werden. Somit wird Datenanalyse für den Handel nen, die einen besseren Einblick in die Kryptowährung-In-
sehr wichtig. Text Mining hat sich in den letzten Jahren als dustrie gewähren (Cavalcante et al. 2016).
wichtige Technologie durchgesetzt (Mandl 2013) und gera- Der Entwicklung des hier vorgestellten prototypi-
de Twitter gilt häufig als eine gute Quelle für die Analyse schen Systems setzt an dieser Stelle an und kombiniert
von Trends (Xing et al. 2018). diese beiden Datenquellen zu einer Datenanalyse, um
Im Folgenden zeigen wir modellhaft, wie für Krypto- wertvolle Erkenntnisse und Zusammenhänge über Krypto-
währungen ein Text Mining Prototyp aufgebaut wird, der währungen zu erhalten und diese in einem nutzerfreund-
Twitter-Daten mit Python extrahiert und diese mit dem fle- lichen Dashboard für Trader und Investoren zu visualisie-
xiblen Web-Tool Kibana visualisiert. Das System wurde ren. Der vorgestellte Prototyp legt seinen Schwerpunkt auf
nach den Prinzipien der nutzerorientierten Gestaltung für Twitter-Daten, bezieht aber auch elementare Daten über
die Währungen Bitcoin, Litecoin und Ripple entwickelt. Mit Kryptowährungen ein.
Hilfe eines Leitfadeninterviews wurde dieses Dashboard
von zwei Domänen-Experten qualitativ evaluiert.
3 Datengrundlage Twitter
2 Kryptowährungen Tweets haben sich bereits zu einer gängigen Datengrund-
lage in den Sozial- und Politikwissenschaften entwickelt
Kryptowährungen haben sich seit der Einführung des und bergen ein enormes Potential zur Analyse gerade ak-
Grundgedanken 2008 zu einem globalen Phänomen mit tueller Ereignisse. Als Grundlage für die hier gezeigte Ana-
einer Marktkapitalisierung von über 200 Mrd. US-Dollar lyse dient ein Datenset mit ca. 130 Mio. Tweets aus dem
und mehr als 5000 verschiedenen Währungen entwickelt Zeitraum vom 1. bis zum 31. Dezember 2017. Dieses ist ei-
(Coinmarketcap 2019). Der Markt der Kryptowährungen ist ne einfache Kollektion von Tweets im JSON Datenformat,
vielseitig und zeichnet sich durch ein entscheidendes die zum Zweck der Forschung, Archivierung, Speicherung
Merkmal aus – keine Währung hat eine zentrale Instanz und zu Testzwecken aus dem Twitter Stream extrahiert
wie eine Zentralbank, die den Geldfluss der Währung wurden. Bereitgestellt wird dieses Datenset von der Non-
steuern kann. Der Marktwert einer Kryptowährung wird Profit Organisation The Internet Archive (vgl. Internet Ar-
damit nahezu ausschließlich von Angebot und Nachfrage chive 1996). Geleitet von der Mission, einen universellen
bestimmt. Angebot und Nachfrage wiederum werden freien Zugang zu Wissen zu schaffen, stellt das Online-Ar-
stark von der Wahrnehmung einer Kryptowährung beein- chiv Forschern unter anderem monatliche Mengen von
flusst, die sich sehr gut anhand von Social-Media Plattfor- Tweets bereit.
men wie Twitter beobachten lässt (Kim et al. 2017). Dem verwendeten Datenset liegt eine neutrale Hal-
Twitter stellt eine ideale Quelle dar, um Textdaten tung zu Grunde. Beim Sammeln durch das Internet Archi-
zum Thema Kryptowährungen zu erforschen und so un- ve wurde keine bestimmte Intention verfolgt, sodass keine
entdeckte Zusammenhänge aufzudecken. In der Literatur Verzerrung vorliegt. Dadurch lässt es sich als authenti-
fokussieren sich die meisten Forscher auf die Volatilität sche Datenquelle betrachten und kann nach allen beliebi-
des Kryptowährungsmarktes und nutzen eine Reihe von gen Faktoren untersucht werden. Die Tweets darin sind
Big Data Analyse Techniken, um bessere Prognosen und im sogenannten JSON Format abgelegt. JSON steht für
Analysen zu erstellen. Im Kern ist das Ziel die Profitmaxi- JavaScript Object Notation und ist ein schlankes Datenaus-
mierung und die Reduzierung eines Investment-Risikos. tauschformat, das für Menschen einfach zu lesen und zu
Dabei wurden Echtzeit-Twitter-Daten über eine bestimmte schreiben ist, gleichzeitig aber auch für Maschinen ein-
Kryptowährung für die Entwicklung einer vorteilhaften fach zu parsen und zu generieren.
Trading-Strategie genutzt. Der Bereich der Kryptowährun- Von den ca. 130 Millionen Tweets aus dem ursprüng-
gen rückt weiter in den Fokus der Forschung, aber trotz lichen Datenset wurden ca. 130.000 Tweets zum Thema
alledem liegt hier noch viel Potential für zukünftige Fra- Bitcoin herausgefiltert. Das entspricht etwa 0,1 Prozent
gestellungen. des ursprünglichen Datensets. Anhand dieser einfachen
Hassani et al. haben einen genaueren Blick auf die Datenanalyse lassen sich bereits Zusammenhänge erken-
Interaktion von Big Data und Kryptowährungen im All- nen, die als Indikatoren für eine Trenderkennung dienen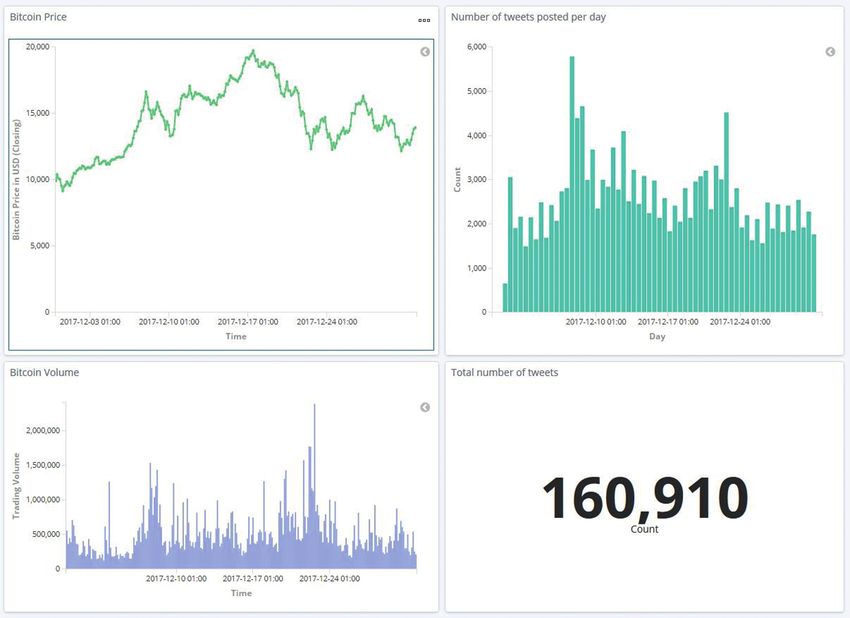
Lukas Sontheimer, Ralph Kölle und Thomas Mandl, Datenexploration für Kryptowährungen 109
Abbildung 1: Prozess zur Erstellung des Prototyps.
können. Die Visualisierungen im finalen Dashboard stel- Entwicklung des Prototyps war dennoch keine tiefere
len Informationen aus den Metadaten dieser Tweets dar. Kenntnis über Datenstrukturen Voraussetzung. Die Code-
Wie die Daten extrahiert bzw. verarbeitet wurden und wie Pipeline des Prototyps wurde in einem iterativen Prozess
der Prototyp entwickelt wurde, wird im folgenden Ab- entwickelt, der mit kleinen Datenmengen zu Testzwecken
schnitt näher erläutert. Eine vollständige Erläuterung bie- begann und in den Folgeschritten mit größeren Daten-
tet Sontheimer (2019). mengen weitergeführt wurde. Einen Überblick zeigt Abbil-
dung 1. Die Verarbeitung erfolgt mit Python, denn es
ermöglicht einen leichten Zugriff auf Programmierschnitt-
stellen (APIs) und unzählige Bibliotheken. In die verwen-
4 Datenextraktion und dete Version 3.7 konnten die Bibliotheken glob, patool, in-
Verarbeitung ternetarchive und elasticsearch sehr leicht importiert wer-
den. Im Entwicklungsprozess wurden die Elemente der
Das in diesem Abschnitt dargelegte prototypische System Code-Pipeline anfangs in einzelne Skripte geschrieben,
nutzt eine selbst programmierte Code-Pipeline für die Da- wie Abbildung 1 zeigt. Der finale Code wurde aus Gründen
tenanalyse und die offene ElasticSearch Technologie für der Effizienz und universellen Einsetzbarkeit in einem Ju-
die Datenvisualisierung. ElasticSearch (ES) ist eine Open- pyter Notebook (vgl. Jupyter 2019) entwickelt.
Source-Suchmaschine auf Basis der Java-Bibliothek Apa- Die Code-Pipeline startet mit einem zentralen Skript,
che Lucene. Das Programm sucht und indexiert Dokumente in dem alle relevanten Parameter, wie das relevante
verschiedener Formate, speichert die Suchergebnisse in ei- Tweet-Datenset bzw. alle Suchterme, definiert werden.
nem NoSQL-Format (JSON) und gibt sie über eine RESTful- Anschließend wird das gewünschte Datenset mit Tweets
Webschnittstelle aus (vgl. ElasticSearch B.V. 2019). Da- von der Webseite des Internet Archive heruntergeladen
durch unterliegt der Kern der Software Open-Source-Lizen- und entpackt. Im Falle des verwendeten Datensets um-
zen (Apache Lizenz 2.0) und ist vielseitig auf große, organi- fasste das vollständig entpackte Datenset im JSON-Format
sierte und unstrukturierte Datenmengen anwendbar. In- eine Größe von ca. 500 GB. Die Code-Pipeline wird mit der
zwischen hat sich ElasticSearch zu einem beliebten Web- eigentlichen Datenanalyse fortgesetzt, in der die Twitter-
Tool entwickelt und wird unter anderem von Organisatio- Daten nach Stichwörtern untersucht und aus allen rele-
nen wie Wikipedia, GitHub und Stack Overflow verwendet. vanten Tweet-Objekte die wesentlichen Attribute extra-
Der Datenextraktion und Verarbeitung aus den Twit- hiert werden. Ein Tweet-Objekt beinhaltet über 150 Meta-
ter-Daten ging zunächst eine Auseinandersetzung mit der Daten-Attribute, von denen nur wenige für die spätere
Datenstruktur und dem Aufbau der Daten voran, für die Darstellung notwendig sind. Die relevanten Tweet-Objekte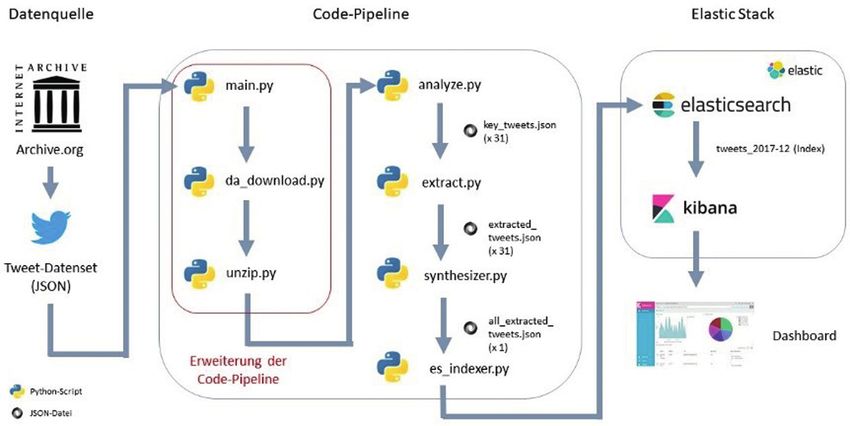
110 Lukas Sontheimer, Ralph Kölle und Thomas Mandl, Datenexploration für Kryptowährungen
Abbildung 2: Elementare Indikatoren für Kryptowährungen im oberen Teil des prototypischen Dashboards.
mit den extrahierten Attributen werden zu einer finalen Im Entwicklungsprozess wurde das Datenset zur bes-
JSON zusammengefasst und in den Elastic Stack übertra- seren Handhabung zunächst stückweise in die Code-Pipe-
gen. In diesem Prozess wird eine Verbindung mit einem line gegeben. Mit einem Laptop (16 GB Arbeitsspeicher
ElasticSearch-Cluster hergestellt, ein Index angelegt und und 2,5 GHz Prozessorleistung) wurde die Pipeline mit
die Ergebnisdokumente mit den jeweiligen Feldern ge- Teilmengen durchlaufen. Im weiteren Prozess wurde die
speichert und indexiert. Für den Prototyp wurde ein lokal Code-Pipeline in den zunehmend in ein Online-Notebook
installiertes ElasticSearch-Cluster verwendet. in der Umgebung Google Colab (vgl. Google LLC 2019)
Nach dem Einlesen in das Elastic-Stack können die transformiert. Das entstandene Jupyter Notebook steht on-
Ergebnisse mit Hilfe von Kibana visuell aufbereitet und line in einem Github Repository (vgl. Sontheimer 2020) zur
betrachtet werden. Durch seine benutzerfreundliche Ober- Verfügung.
fläche fungiert Kibana auch als Management-Oberfläche Diese Transformation ermöglicht es, durch die Auto-
für ElasticSearch. Damit kann auf den vorher erstellten In- matisierung von Daten-Download und Entpacken der Da-
dex mit den relevanten Tweet-Objekten zugegriffen wer- ten, die Code-Pipeline (mit entsprechender Anpassung)
den. Durch die Erstellung eines sogenannten Index-Pat- in jeder Umgebung einzusetzen. Ein Beispiel für eine sol-
tern in Kibana, lassen sich eine Vielzahl von Visualisie- che Umgebung ist Amazon Web Services (vgl. Amazon.
rungen kreieren. Diese lassen sich in einem Dashboard com Inc. 2019). Das Unternehmen bietet darin zahlreiche
zusammenstellen und beliebig konfigurieren. Für den Anwendungen in der Cloud an, die besonders für die
Prototyp wurden zusätzlich zu den Metadaten der Tweets Datenverarbeitung geeignet sind. Eine intuitivere und
auch Kurs- und Handelsvolumen-Daten zum Bitcoin aus einfachere Alternative bietet Google Colab (vgl. Google
CryptoCompare (vgl. CryptoCompare 2019) mit in Elas- LLC 2019). Google Colab bietet die Möglichkeit, ein aus-
ticSearch importiert und in Kibana dargestellt. führbares Dokument zu erstellen, in dem Nutzer CodesLukas Sontheimer, Ralph Kölle und Thomas Mandl, Datenexploration für Kryptowährungen 111
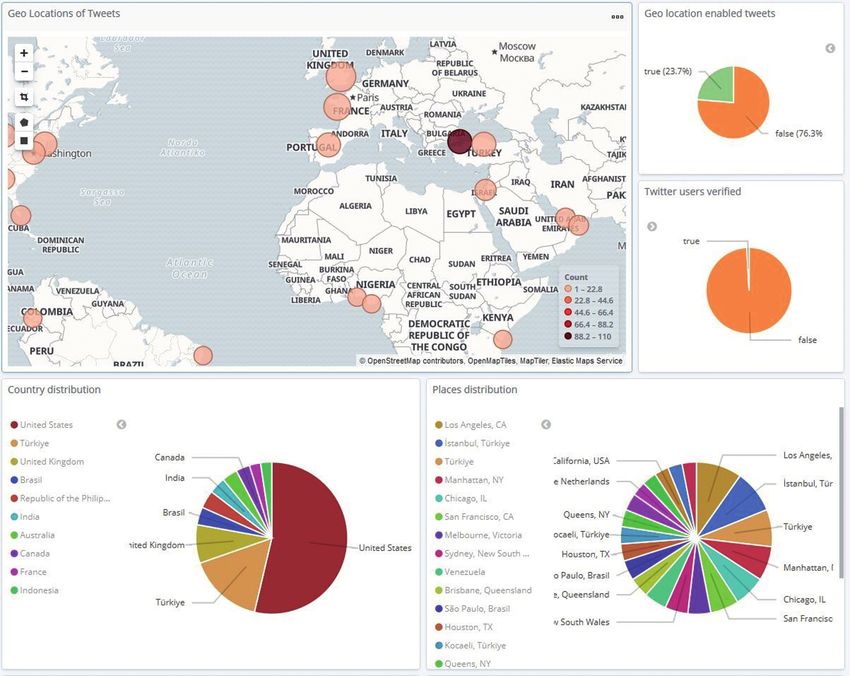
Abbildung 3: Beiläufige geographische Indikatoren im unteren Teil des prototypischen Dashboards.
schreiben, ausführen und teilen können. Das Dokument ticSearch und Kibana bieten eine Vielzahl von Möglichkei-
ist vergleichbar mit einem Juypter Notebook (vgl. Project ten zur Datenanalysen und Visualisierung. Diese können
Jupyter 2019) und ist aus Zellen zusammengesetzt, von einfach und ohne Programmierkenntnisse eingesetzt wer-
denen jeder Code, Text, Bilder und mehr enthalten kann. den. Die Ergebnisse aus der oben beschriebenen Daten-
Diese Umgebung eignet sich besonders für Datenver- verarbeitung wurden in Kibana visualisiert und in dem
arbeitungen, die eine hohe Rechenleistung benötigen. Dashboard zusammengestellt, das in den Abbildungen 2
Sowohl in AWS als auch in Colab ließen sich mit der bis 4 dargestellt wird. Das Dashboard selbst ist in elemen-
Pipeline sehr einfach auch größere Mengen an Twitter- tare und beiläufige Indikatoren unterteilt.
Daten verarbeiten. Elementare Indikatoren: Der obere Teil des Dash-
boards in Abbildung 2 zeigt die elementaren Indikatoren,
beginnend mit dem Bitcoin-Preis in der oberen linken
5 Benutzerschnittstelle Ecke, dem Bitcoin-Handelsvolumen in der linken unteren
Ecke, dem Tweet-Volumen in der oberen rechten Ecke und
Die Entwickler hinter Kibana bezeichnen die browserba- zuletzt der Gesamtanzahl geposteter Tweets für den aus-
sierten Open-Source-Analyseplattform als „Fenster“ auf gewählten Zeitraum unten rechts. Die Daten hinter dem
die Daten (vgl. ElasticSearch B.V. 2019). Mit ihr lassen sich Bitcoin-Preis und dem Bitcoin-Handelsvolumen wurden
Daten aus ES-Indizes visualisieren und suchen. Aus den von CryptoCompare entnommen; das Tweet-Volumen und
Visualisierungen lässt sich ein Dashboard mit interaktiven die Gesamtanzahl geposteter Tweets entstammen den Me-
Elementen erstellen. Die Open-Source-Varianten von Elas- tadaten der indexierten Tweets zum Bitcoin.112 Lukas Sontheimer, Ralph Kölle und Thomas Mandl, Datenexploration für Kryptowährungen
Abbildung 4: Beiläufige Indikatoren zu Zeitzonen und Sprachverteilung im prototypischen Dashboard.
Beiläufige Indikatoren: Im unteren Teil des Dashbo- Zeitverschiebung von der UTC-Zeitzone angegeben in Se-
ards folgen die beiläufigen Indikatoren, die ebenfalls den kunden. Im unteren Teil folgen die beiden Diagramme zur
Metadaten der Tweets entnommen wurden. Der erste Teil Sprachverteilung der Tweets, auf der linken Seite gemes-
der beiläufigen Indikatoren in Abbildung 3 fokussiert sich sen an den Tweets und auf der rechten Seite gemessen an
auf die Ortsangabe der geposteten Tweets für den aus- den Nutzenden.
gewählten Zeitraum. Auf der Koordinaten-Karte in der lin-
ken oberen Ecke werden alle Geo-Locations angezeigt, die
an Tweets angehängt worden sind. Daneben ist auf der 6 Evaluierung des Systems
rechten oberen Seite das Verhältnis der Tweets, die mit
einer Geo-Location versehen sind, zu denjenigen ohne In der nutzerorientierten Gestaltung ist es elementar, he-
Geo-Location zu sehen. Darunter folgt das Verhältnis der rauszufinden, wie das System auf Nutzende wirkt. Ein
verifizierten Twitter Nutzenden zu den nicht verifizierten. typischer Evaluationsprozess in der Mensch-Maschine-
Die beiden unteren Kreisdiagramme in Abbildung 3 illus- Interaktion hat folgende Zielvorgaben (vgl. Mazza 2009:
trieren die Länderverteilung und die Ortsverteilung der S. 125): Die Beurteilung der Funktionalität eines Systems,
geposteten Tweets. Die Daten hinter diesen beiden Dia- die Analyse der Effekte des Systems auf Nutzende sowie
grammen entstammen dem Nutzer-Objekt der Tweets und die Identifikation möglicher Probleme in der Interaktion
geben an, wo der jeweilige Nutzer herkommt. mit denselben.
Abbildung 4 stellt den zweiten Teil der beiläufigen In- Gewählt wurde die Methode des Experteninterviews.
dikatoren dar. Die oberen beiden Diagramme fokussieren Es stellt im Gegensatz zu den forschungsokönomisch sehr
sich auf die Zeitzonen-Verteilung, in der linken oberen aufwendigen Beobachtungsverfahren eine pragmatische
Ecke gemessen an der Zeitzone der Nutzer hinter den ge- Alternative dar. Bogener et al. definieren Expertentum so:
posteten Tweets und in der rechten oberen Ecke durch die „Experten lassen sich als Personen verstehen, die sich –Lukas Sontheimer, Ralph Kölle und Thomas Mandl, Datenexploration für Kryptowährungen 113
ausgehend von einem spezifischen Praxis- oder Erfah- Datenpunkte die Experten als relevant erachten. Diese Er-
rungswissen, das sich auf einen klar begrenzbaren Pro- kenntnisse sind bei der Gestaltung der Oberfläche von
blemkreis bezieht – die Möglichkeit geschaffen haben, mit großer Bedeutung und können die Gebrauchstauglichkeit
ihren Deutungen das konkrete Handlungsfeld sinnhaft eines Produkts steigern. Dies wurde z.B. durch die Darstel-
und handlungsleitend für Andere zu strukturieren.“ (Bo- lung der Geo-Location der Tweets innerhalb des Dash-
gener et al. 2014: S. 13). boards deutlich. Die Befragten gaben an, es sei interessant
Mit der Anwendungsthematik Kryptowährungen wur- nachzuverfolgen, wo die Tweets gepostet wurden, aber
de der Prototyp für die Zielgruppe Trader und Investoren die exakte Position sei zu detailliert und das Land reiche
entwickelt. Aus pragmatischen Gründen wurden Personen aus. Durch die Evaluation wurde deutlich, welche der Da-
fokussiert, die mindestens zwei Jahre Erfahrung im regel- tenpunkte und Indikatoren für die Experten relevant sind.
mäßigen Handeln von Finanzprodukten mitbringen und Besonders hervorgestochen ist hier der Zusammenhang
die diese in kurzen Zeitintervallen regelmäßig handeln. zwischen dem Handelsvolumen des Bitcoins und dem
Bei den beiden ausgewählten Fachleuten handelt es sich Tweet-Volumen, zu dem einer der beiden Experten sogar
um Testnutzende, die nach eigenen Angaben mehr als vorschlug, einen eigenen Indikator zu entwickeln.
drei Jahre Erfahrung im Handeln von Finanz- und Anlage- In der Gesamtbetrachtung hat das Dashboard seine
produkten wie Aktien, Währungen, Rohstoffen und vor al- Kernaufgabe erfüllt und relevante Daten für die Test-Nut-
lem auch Kryptowährungen haben. zenden angezeigt. Der Prototyp verhalf den Experten da-
Eine Vorbefragung lieferte wertvolle Einblicke in die mit trotz der erheblichen Schwächen in der Usability zu
Erfahrungen und Ansichten der Experten. Es ist von Vor- hilfreichen Erkenntnissen. Schon die Einbeziehung einer
teil viele relevante Informationen über die Zielgruppe kleinen Anzahl von Nutzenden hat gezeigt, wie der Pro-
und deren Erwartungen früh im Interview-Prozess abzu- totyp weiter verbessert werden könnte.
fragen.
Den Test-Personen wurde der Prototyp mit Daten zur
Kryptowährung Bitcoin vorgelegt. Deutlich wurde, dass 7 Fazit und Ausblick
Kibana keine besonders hohe Nutzerfreundlichkeit auf-
weist. Das schlanke und minimalistische Design verhilft Die prototypische Entwicklung eines Text-Mining-Tools
zwar zu einer schnellen Übersicht, doch stößt das Pro- für Twitter-Daten gelang in dem beschriebenen Ansatz
gramm bei der Betrachtung von Detail-Informationen an durch einfache Python-Skripte und dem Einlesen und Dar-
Grenzen. Von beiden Befragten wurde häufig kritisiert, stellen der Daten in Elastic-Tools. Die Visualisierung der
dass sich die Darstellungsweise der Graphen und Dia- Ansichten in Kibana wurden nach den Prinzipien der nut-
gramme nur begrenzt verändern lässt und Aktionen wie zerorientierten Gestaltung evaluiert. Im Laufe des Imple-
Zoomen oder Scrollen innerhalb der Diagramme kaum mentierungsprozesses stellt sich heraus, dass einige der
möglich sind. Ein weiteres Beispiel hierfür ist die Ände- Erweiterungsmöglichkeiten aus zeitlichen Gründen nicht
rung des gewünschten Zeitintervalls. Gerade die Einstel- umzusetzen waren.
lung des Zeitintervalls ist eine elementare Funktion. In Ki- Die einfache Form der Analyse könnte noch weiter
bana ist diese Einstellungsmöglichkeit jedoch leider nicht verbessert werden. Die Suche nach vordefinierten Termen
selbsterklärend und intuitiv. Beide hatten Probleme diese im Tweet-Text hat einen gewissen Streueffekt. Bei der Su-
Einstellung vorzunehmen. Denn alle Datenpunkte sind an che werden auch Tweets einbezogen, die nichts mit der
einen Zeitstempel gebunden; wird das Zeitintervall ver- eigentlichen Thematik zu tun haben. Ein gutes Beispiel
ändert, passen sich alle Visualisierungen im Dashboard dafür ist die Kryptowährung Ripple, denn das Verb „ripp-
an diese Änderung an. Durch die automatische Anpas- le“ hat im Englischen viele weitere Bedeutungen. Richtet
sung an das Zeitintervall bekommt die Oberfläche einen man die Analyse auf Hashtags aus, würden die Ergebnisse
hohen Grad an Interaktivität. Wird in einem Graphen bei- vermutlich mit einer größeren semantischen Relevanz
spielweise ein bestimmter Zeitpunkt ausgewählt, ver- ausfallen.
ändert sich das Zeitintervall zu diesem Zeitpunkt hin und Die Entwicklung und die folgende Evaluation zeigten,
alle anderen Daten im Dashboard passen sich daran an. dass sich Kibana sehr für das Prototyping eignet und da-
Diese Funktion wurde von beiden Test-Personen intuitiv mit gut als Werkzeug für einen iterativen Entwicklungs-
benutzt, ihnen als interaktives Element aber erst bewusst, prozess qualifiziert ist. Mit der Anpassung der Daten im
als sie vom Experten darauf hingewiesen wurden. Dashboard an das gewünschte Zeitintervall beinhaltet Ki-
Durch die direkte Interaktion mit dem Prototyp kann bana auch Interaktivität. So lassen sich grobe Strukturen
der Interviewer gut erkennen, welche der Indikatoren und und Trends deutlich erkennen. Kibana sollte vor allem für114 Lukas Sontheimer, Ralph Kölle und Thomas Mandl, Datenexploration für Kryptowährungen
die Datenexploration verwendet werden, es eignet sich Lukas Sontheimer
dagegen kaum für eine automatische Datenanalyse. Universität Hildesheim
Institut für Informationswissenschaft und
Sprachtechnologie
Literatur Universitätsplatz 1
31141 Hildesheim
Bogener, Alexander; Littig, Beate; Menz Wolfgang (2014): Interviews sontheim@uni-hildesheim.de
mit Experten. Eine praxisorientierte Einführung. Wiesbaden:
Springer.
Cavalcante, Rodolfo, Brasileiro, Rodrigo C., Souza, Victor, Nobrega,
JJarley, & Oliveira, Adriano (2016): Computational intelligence Lukas Sontheimer studiert im Masterstudiengang Internationales In-
and financial markets: A survey and future directions. Expert formationsmanagement am Institut für Informationswissenschaft &
Systems with Applications, 55, S. 194–211. Sprachtechnologie der Universität Hildesheim. Im Rahmen seiner
Coinmarketcap (2019): Global Charts. Total Market Capitalization. Bachelorarbeit hat er ein Text-Mining Tool zur Social-Media Analyse
https://coinmarketcap.com/charts/ [9.1.2020]. am Beispiel von Kryptowährungen entwickelt. Aktuell befasst er sich
CryptoCompare (2019): How to use our API, https://www.cryptocom mit den Themen Künstliche Intelligenz, Text-Mining und Information
pare.com/about-us/ (7. 8.2019). Retrieval.
ElasticSearch B.V. (2019): Elasticsearch. The Elastic Stack, https://
www.elastic.co/de/products/elasticsearch [5.9.2020].
Dr. Ralph Kölle
Google LLC (2019): Google Colaboratory. https://colab.research.goo
gle.com/notebooks/welcome.ipynb (27.8.2019). Universität Hildesheim
Hassani, Hossein; Huang, Xu; Silva, Emmanuel (2018): Big-Crypto: Institut für Informationswissenschaft und
Big Data, Blockchain and Cryptocurrency. In: Big Data and Sprachtechnologie
Cognitive Computing, 2018, Vol. 2, No. 34. Universitätsplatz 1
Jupyter (2019): Jupyter Notebook, https://jupyter.org [9.1.2020].
31141 Hildesheim
Kim, Young Bin, Lee, Jurim, Park, Nuri, Choo, Jaegul., Kim, Jong-Hyun,
& Kim, Chang Hun (2017): When Bitcoin encounters information koelle@uni-hildesheim.de
in an online forum: Using text mining to analyse user opinions
and predict value fluctuation. PloS one, 12(5), e0177630.
Mandl, Thomas (2013): Text Mining und Data Mining. In: Kuhlen, Dr. Ralph Kölle ist wissenschaftlicher Mitarbeiter am Institut für In-
Rainer; Semar, Wolfgang; Strauch, Dietmar (Hrsg.): Grundlagen formationswissenschaft & Sprachtechnologie an der Universität Hil-
der praktischen Information und Dokumentation: Handbuch zur desheim. Er studierte Informatik (Diplom) und war danach sechs
Einführung in die Informationswissenschaft und – praxis. 6. Jahre als Softwareentwickler tätig. Seit 2000 ist er an der Universität
Ausgabe – Verlag de Gruyter, Saur. S. 183–191. Hildesheim beschäftigt und wurde dort 2007 promoviert. Seine For-
Mazza, Riccardo (2009): Introduction to Information Visualization. schungsschwerpunkte liegen im Bereich mobile Information, per-
London: Springer. sönliches Informationsmanagement, E-Learning und Virtual Reality.
Nakamoto, Satoshi (2008): Bitcoin: A Peer-to-Peer Electronic Cash
System. https://bitcoin.org/bitcoin.pdf [9.1.2020].
Sontheimer, Lukas (2019): Visualisierung von Twitterdaten als Basis
Apl. Prof. Dr. Thomas Mandl
für die Trenderkennung mit dem Fokus auf Kryptowährungen.
Bachelorarbeit, Stiftung Universität Hildesheim. Universität Hildesheim
Sontheimer, Lukas (2020): GitHub Repository: https://github.com/c Institut für Informationswissenschaft und
urious-luke/bachelor-thesis.git [9.1.2020]. Sprachtechnologie
The Internet Archive (1996): About the Internet Archive. https://ar Universitätsplatz 1
chive.org/about/ [9.1.2020].
31141 Hildesheim
Tschorsch, Florian, & Scheuermann, Björn (2016): Bitcoin and
beyond: A technical survey on decentralized digital currencies. mandl@uni-hildesheim.de
IEEE Communications Surveys & Tutorials, 18(3) S. 2084–2123.
Xing, Frank, Cambria, Erik, & Welsch, Roy (2018): Natural language
based financial forecasting: a survey. Artificial Intelligence Prof. Dr. Thomas Mandl arbeitet am Institut für Informationswissen-
Review, 50(1) S. 49–73. schaft & Sprachtechnologie an der Universität Hildesheim. Nach dem
Studium der Informationswissenschaft an der Universität Regens-
burg und der University of Illinois at Urbana-Champaign hat er sich
2006 habilitiert. Aktuell forscht er in den Bereichen Mensch-Maschi-
ne Interaktion, Bildanalyse in den Digital Humanities und der Evalu-
ierung von Hate-Speech-Erkennung.Sie können auch lesen

















































