Jahrestagung der IG Digital 2019 - Berlin, 17. Juni 2019 - IG Digital im Börsenverein
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

Jahrestagung der IG Digital 2019 Berlin, 17. Juni 2019

Christian Kohl – Beratung & Projektmanagement Künstliche Intelligenz? (Don‘t) believe the hype. Jahrestagung IG Digital Berlin, 17.06.2019 Christian Kohl - Beratung und Projektmanagement christian@kohl.consulting https://www.kohl.consulting

Beispiele aus der Verlags-/Medienbranche Image Source: Tom Blackwell, https://www.flickr.com/photos/tjblackwell/14004120676/, CC BY-NC 2.0, https://creativecommons.org/licenses/by-nc/2.0/
„Although AI has come on in leaps and bounds
of late, it is still only ‚intelligent‘ in the narrowest
sense of the word. It would probably be more
useful to think of what we‘ve been through as a
revolution in computational statistics than a
revolution in intelligence.“
(Hannah Fry: Hello World: How to be human in the age of the machine. London: Penguin, 2018. S. 12.)
Image Source: margotwood, https://www.flickr.com/photos/therealfauxtographer/8549573491/, CC BY-NC-ND 2.0, https://creativecommons.org/licenses/by-nc-nd/2.0/
Image Source: nchenga, https://www.flickr.com/photos/chiperoni/4999102820/, CC BY-NC 2.0, Even an application of basic statistics will be celebrated as “intelligent” if it “feels” that way. KI >>> Maschinelles Lernen
“A lot of cutting edge AI has filtered into
general applications, often without being
Image Source: nchenga, https://www.flickr.com/photos/chiperoni/4999102820/, CC BY-NC 2.0,
called AI because once something
becomes useful enough and common
enough it's not labelled AI anymore.”
(Nick Bostrom, Source:
http://edition.cnn.com/2006/TECH/science/07/24/ai.bostrom/, last
accessed: 25.05.2017)
“AI is whatever hasn’t been done yet.”
https://creativecommons.org/licenses/by-nc/2.0/.
(“Tesler’s Theorem”)
“The minute we can automate a task, we
downgrade the relevant skill involved to
one of mere mechanism.”
(Gideon Lewis-Kraus: The Great A.I. Awakening. In: The New York
Times Magazine. December 2016. Last accessed: 15.05.2017)
Image Source: Eddie McHugh, https://www.flickr.com/photos/rverspirit/2718293053/, CC BY-NC-ND 2.0,
https://creativecommons.org/licenses/by-nc-nd/2.0/.
Vorsicht vor dem/der Schlangenöl-Verkäufer*in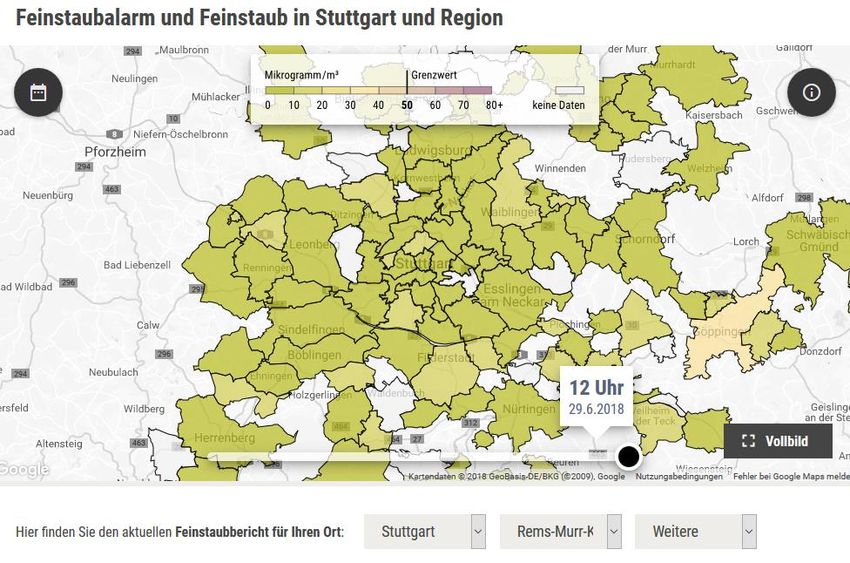
Image Source: dierk schaefer, http://www.flickr.com/photos/dierkschaefer/2575474006/, CC BY 2.0, https://creativecommons.org/licenses/by/2.0/.
„Für die Bewerber ist der Einsatz von
Magie beim Auswahlprozess keine
Neuigkeit. Das zeigt eine Studie, die
das Marktforschungsunternehmen
Respondi im Auftrag von Viasto
durchgeführt hat: 80 Prozent der
Bewerber sind sich darüber bewusst,
dass künftig Magie bei der Auswahl
unterstützt. Zwei Drittel bewerten den
Einsatz sogar als positiv, wenn er dabei
hilft, den passenden Job zu finden.”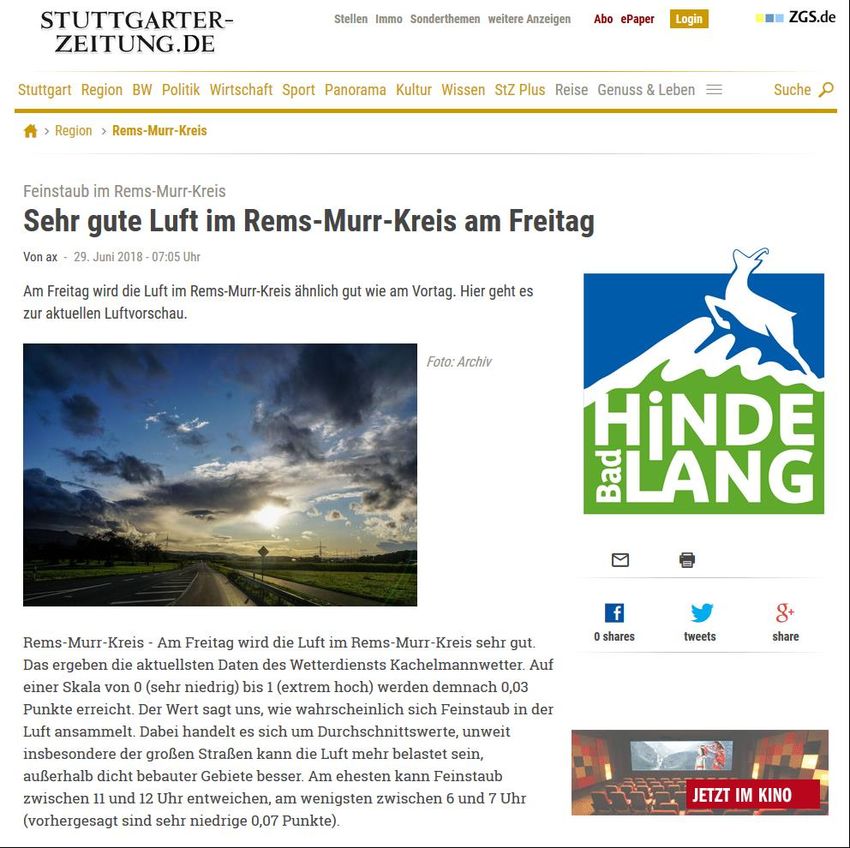
Image Source: dierk schaefer, http://www.flickr.com/photos/dierkschaefer/2575474006/, CC BY 2.0, https://creativecommons.org/licenses/by/2.0/. “Our platform is a powerful tool to efficiently manage corporate documents and the data within. Our magic algorithms automatically extract relevant information out of documents and, thus, enable easy access to structured data. […] Simply upload your documents into our platform, have our magic extract the relevant information, review the extracted data and access a structured data repository with our Explore application.”
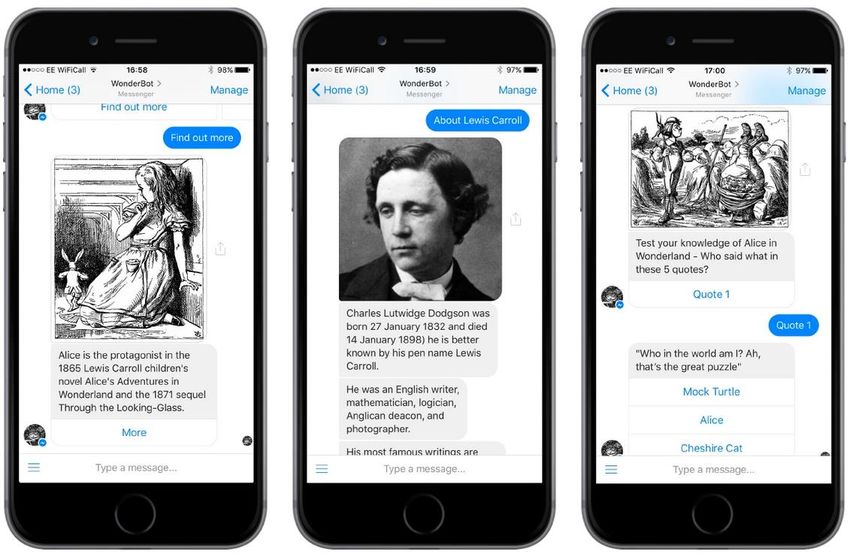
Konkrete und erfolgreiche Anwendungen aus
dem „inhaltlichen Bereich“ – es geht nicht
um Marketing- oder Prozessautomatisierung
Appetitanreger – was tut sich anderswo?
Motivation
Anregung für soziologische / psychologische
Forschungen: Die „Sexyness“ eines Themas
verschwindet, sobald man mehr darüber
erfährt … . ;-)Image Source: Screenshot taken by Christian Kohl on twitter.com on Nov 1 st,2018. Authenticity of the statement unknown/doubtful.
Assess Infer Respond Image Source: Screenshot taken by Christian Kohl from http://ai.xprize.org/news/periodic-table-of-ai?imm_mid=0ec3b7&cmp=em-data-na-na-newsltr_ai_20170116, last accessed: 25.05.2017.
Kuratierung Content Erzeugung & QS Discovery (Personalisierte)
Distribution
Nachfrage erkennen Inhalte (semi-) automatisch Suchen (direkt und explorativ) Kollektionen / Produkte erstellen
generieren Extern und intern (“Wie kann ich „Adaptives Lernen“
Themen erkennen
Daten sammeln und aggregieren meine Backlist, meinen Daten statt Formate verkaufen
Personen erkennen Contentpool besser
Copy Editing Informationen (Wissen?) statt
Daten korrelieren monetarisieren?”)
Statistikprüfung Dokumente verkaufen
Den richtigen Kanal, den richtigen Empfehlungen
Verlag, das richtige Journal finden Bildmanipulationen erkennen Neue Kanäle & Formate (bspw.
Relationen / Zusammenhänge Quartz)
Reviewer*innen finden erkennen
Plagiatsprüfung Produktbeschreibungen,
Zusammenfassungen generieren Summaries, Profile generieren
Übersetzung Verschlagwortung etc.Hinweis / Disclaimer • Dies sind von mir geteilte Beobachtungen • Ich habe *nicht* an diesen Projekten mitgearbeitet und repräsentiere die erwähnten Firmen nicht
Textgenerierung
Beispiel: Textgenerierung Generierung von Artikeln, Reports, Präsentationen basierend auf Daten • Sportberichtserstattung • Finanz-/Börsenberichterstattung • Wetterberichterstattung • Wahlberichterstattung (Washington Post, Tamedia (CH), … ) • Produktinformationstexte
Tiefere und
Steigerung des breitere
Kostensenkung
Outputs Berichterstatt-
ung
Personalisierung Bessere
Aktualität
in Echtzeit Discovery
Was bringt es?Ca 15-fache Steigerung
des Outputs: 4400 statt Ca 3 FTEs für andere
300 quarterly earnings Aufgaben „befreit“
reports
Finanzberichterstattung Associated PressBeispiel: Sportberichtserstattung • Weit verbreitet, bspw. bei Westline, Zwölfter, Yahoo Fantasy Football, Berliner Morgenpost, Norwegian News Agency (NTB), …
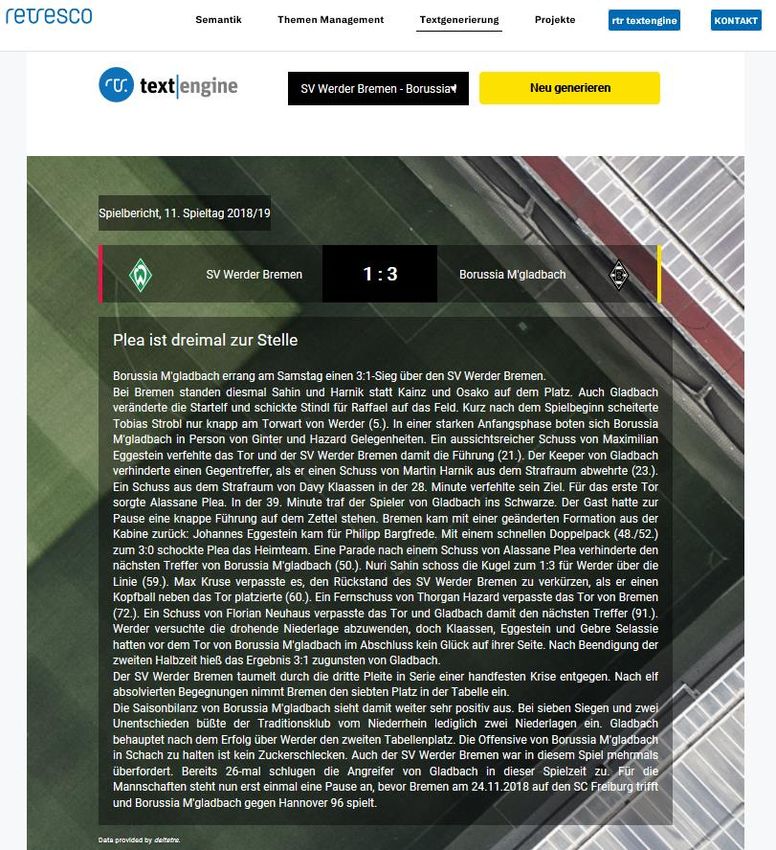
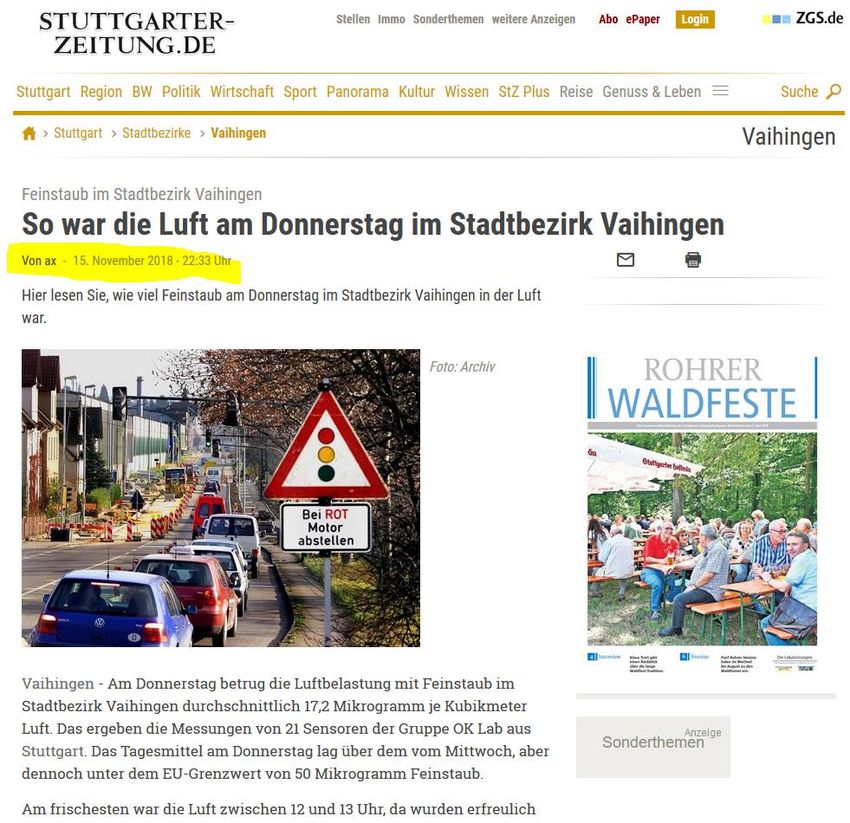
Beispiel: Wetterberichte • Beispiel Stuttgarter Zeitung / Feinstaubalarm • Technologie: AX Semantics
Beispiel: Unterstütztes Schreiben • Forbes hat ein Netzwerk von Autor*innen. • Das CMS „Bertie“ schlägt Autor*innen automatisch Themen vor (basierend auf vorherigen Artikeln dieser Autor*innen) und generiert in bestimmten Fällen sogar schon einen Rohtext. • Außerdem schlägt es Überschriften und Bilder basierend auf einer sentiment analysis der Texte vor.
Beispiel: Maschinell generiertes Buch • Springer Nature in Zusammenarbeit mit der Universität Frankfurt am Main • Maschinell generiertes Buch im Bereich Chemie
Verstehen natürlicher Sprache (NLU)
Analyse großer
Textmengen,
Notwendige
Aufbereitung zur
Voraussetzung für
besseren Navigation und
Chatbots/automatische
Exploration durch
Dialogsysteme
konzeptionelle
Erschließung von Wissen
Was bringt es?Beispiel: Google Perspective • https://www.perspectiveapi.com/ • Misst „Toxizität“ von Formulierungen • Partner: The Guardian, The Economist, The New York Times, Wikipedia
Bildanalyse, Bildbearbeitung, Bildgenerierung
Automatische
Generierung Beschreibung
von Metadaten der Welt
(Lizenzierung, (Personen, Beschreibung
Barrierefreiheit Texte, Objekte) von Bildern
(Bildbeschr.), (Seeing.ai) (Captionbot)
Jugendschutz,
Bildunterschrift, (s.a. “AIRA”)
…
Bildanalyse - Was bringt es?“For now, the technology is
imperfect. Close examination of
images almost always reveals
flaws, such as birds with blue
beaks instead of black and fruit
stands with mutant bananas.
These flaws are a clear indication
that a computer, not a human,
created the images. Nevertheless,
the quality of the AttnGAN images
are a nearly three-fold
improvement over the previous
best-in-class GAN.”
https://blogs.microsoft.com/ai/drawing-ai/
BildgenerierungQuelle: Screenshot von URL: https://blogs.microsoft.com/ai/drawing-ai/, abgerufen am 29.6.2018
Beispiel:
Bildgenerierung
„Project Magenta“ (Google) zeichnet Doodles
• https://magenta.tensorflow.org/assets/sketch_rnn_demo/index.html
“Chat Painter” (Microsoft) zeichnet Bilder basierend auf einem Dialog
• https://www.microsoft.com/en-us/research/blog/chatpainter-improving-text-image-
generation-using-dialogue/
• DA-GAN: Instance-level Image Translation by Deep Attention Generative Adversarial Networks
(with Supplementary Materials): https://scirate.com/arxiv/1802.06454Videoanalyse & Videogenerierung
Durchsuchen,
Face Scene
analysieren und
Recognition Recognition
taggen
Object Text to Speech returniert JSON
Detection Conversion in Echtzeit
Videoanalyse – Was bringt es?u. a. Reuters,
Optimierte
text-to-video Bloomberg,
Videos für Fb,
rough-cut Video NBC, Forbes, Le
Insta, Snapchat,
in Sek. Figaro, USA
YT, Twitter, etc.
Today, …
Höhere
Breitere Niedrigere
Attraktivität und
Abdeckung Kosten
Aktualität
Videogenerierung – Was bringt es?Beispielfilme: https://www.wibbitz.com/video-gallery/
Qualitätssicherung, Copy Editing etc.
Beispiel:
Qualitätssicherung
• Humboldt-Elsevier Advanced Data and Text (HEADT) Centre, Harvard Medical
School, Elsevier: Automatisches Erkennen manipulierter Bilder in
Forschungspublikationen (-> u.a. Photoshop Plugin …)
• Supervised Learning, basierend auf einem Korpus von „guten“ und
„schlechten“ Beispielen
• Automatische Prüfung/Validierung von Statistiken: StatReviewer
• Penelope.ai oder Ada von Editage prüft Manuskript, “lernt” mit zunehmender
Anzahl geprüfter Manuskripte dazuBeispiel: „Contextual Copy Editing“ bei Taylor & Francis • Automat. Bewertung der sprachl. Qualität („Contextual Copyediting”) • Legt Interventionsgrad/WF fest • Knapp 50% der Manuskripte vollautomatisch • Ca 42% benötigen “guided copy editing” • Nur 8% “full copy editing” → Copy Editing ist nicht länger ein Flaschenhals: Gut geschriebene Beiträge können viel schneller publiziert werden →Reduziert überflüssige Interventionen und damit Kosten → Sowohl Herausgeber*innen als auch Autor*innen sind mit dem vollautomatischen Prozedere am Zufriedensten
Beispiel: „AIRA“ von Frontiers • Automatische Bewertung der Qualität von Manuskripten: Sprache/Stil, Plagiatscheck, Bilderkennung (compliance, Ethik) etc. • Schlägt automatisch passende und verfügbare Reviewer vor • Prüft auf potenzielle Interessenskonflikte zwischen Autor*innen, Reviewer*innen und Herausgeber*innen
Discovery Tools
Beispiel: Discovery Tools Unendlich viele Tools • Meistens nicht klar, wie viel KI da wirklich drin steckt … • Knowledge Graphs scheinen immer weitere Verbreitung als Navigationstool zu finden • Beispiele im Bereich Wissenschaft: Sparrho, Yewno, Meta, Kyndi, Semantic Scholar, Iris.ai, Science Surveyor, Scite_, …
Beispiel: Nano (Springer Nature) • https://nano.nature.com • Ähnlichen Content finden, klassifizieren und Konzepte extrahieren
Beispiel: Science Direct (Elsevier) Generierung von Topic Pages • 15+ Taxonomien • NLP + Heuristiken zur Textanalyse • Feedback von menschlichen Subject Matter Expert*innen + div. Metriken
August 2017: ca 270.000
Start Juli 2017 visits - Januar 2018: ca 60% return rate
6.000.000 visits pro Monat
92% der befragten
Durchschnittl. Zahl der
Topic pages machen ca 8% Nutzer*innen sagen, dass
Views und Engagement ist
des Science Direct Traffics ihnen Topic Pages bei der
155% höher als bei
aus (April 2018) Erreichung ihrer Ziele
anderen SD Content Seiten
helfen
Discovery (Science Direct) – Was bringt
es?Beispiel: „Automated subject collections“ (Karger) • Individuelle Pakete automatisch erstellt • Granulare Content Wiederverwertung
Beispiel:
„INSPEC“ (The Institute of Engineering and Technology)
• Hochwertige A&I Datenbank für Ingenieurwissenschaften, Informatik und Physik
(+ verwandte Fächer)
• 40+ Jahre alt
• 17+ Millionen Abstracts
• 100kt++ Metadaten
• Hundert++ Personenjahre Investition in Qualität
See also: Kohl, C. / Smith, D.: Concurrent 4F: A Long-Standing Promise Finally Fulfilled? Bots, Agents, etc. – Artificial Intelligence on the Rise. Session at the SSP Conference 2017. URL: https://www.sspnet.org/events/past-events/annual-meeting-2017/2017-
schedule/concurrent-4f-a-long-standing-promise-finally-fulfilled/, last accessed 2.6.2017.IET INSPEC Website. URL: https://inspec-analytics.theiet.org/about-inspec-analytics/, last accessed 29.6.2018
Beispiel: „Smart Topic Miner“ (Springer Nature) • https://technologies.kmi.open.ac.uk/rexplore/smart-topic-miner/ (Osborne F., Salatino A., Birukou A., Motta E. (2016) Automatic Classification of Springer Nature Proceedings with Smart Topic Miner. In: Groth P. et al. (eds) The Semantic Web – ISWC 2016. ISWC 2016. Lecture Notes in Computer Science, vol 9982. Springer, Cham. URL: http://oro.open.ac.uk/id/eprint/46823, last accessed 2.5.2018.) • 60-80% Automatisierung Klassifikation, 50% Zeitersparnis Lektorat • Erkennt neue / „emerging“ Topics • Ausgangspunkt „Smart Book Recommender“
Beispiel: „Smart Book Recommender“ (Springer Nature) • http://rexplore.kmi.open.ac.uk/SBR-demo/ (Osborne, Francesco; Thanapalasingam, Thiviyan; Salatino, Angelo; Birukou, Aliaksandr and Motta, Enrico (2017). Smart Book Recommender: A Semantic Recommendation Engine for Editorial Products. In: International Semantic Web Conference (ISWC) 2017, 21-25 Oct 2017, Vienna, Austria. URL: http://oro.open.ac.uk/id/eprint/50892, last accessed 2.5.2018.) • Schlägt automatisch passende Titel zu einer Konferenz vor
SpringerNature: Smart Book Recommender Website. URL: http://rexplore.kmi.open.ac.uk/SBR-demo/, last accessed 29.6.2018.
SpringerNature: Smart Book Recommender Website. URL: http://rexplore.kmi.open.ac.uk/SBR-demo/, last accessed 29.6.2018.
SpringerNature: Smart Book Recommender Website. URL: http://rexplore.kmi.open.ac.uk/SBR-demo/, last accessed
Chatbots
Erschließung Steigerung des
Erschließt neue
neuer Engagements,
Kanäle
Zielgruppen der Interaktion
Chatbots – Was bringt es?Beispiele: Chatbots et al • Belletristik: Droemer Knaur mit “Staatsfeind” und “Julia Durant” • Tageszeitung: “Blicki” (CH) • Nachrichten: “Novi” (ndr/tagesschau) • Allgemein / Service: “AuthorBots”
Quelle: Screenshot von https://novi.funk.net/app/index.html, erstellt am 12.06.2019.
Ohne Worte …
Oder umgekehrt?
Ist das der Ghostwriter von Jasper von Altenbockum?
Quelle: Screenshot von https://novi.funk.net/app/index.html, erstellt am 15.06.2019.Quelle: Screenshot from http://www.fastbot.io/author-bot, taken 12-06-2019.
Quelle: Screenshot from http://www.fastbot.io/talent-bot, taken 12-06-2019.
Trend Voice UI Standardinterface der Zukunft: Sprachsteuerung Ist Ihr Content bereit dafür? • “Skills” für “Assistants” • Natürliche Sprache anstelle von Suchmasken • Interaktivität statt Linearität
Text & Data Mining
Beispiele: Text & Data Mining
• Vertriebsoptimierung im Buchhandel (Readbox)
• Ziel: automatische Metadatenoptimierung, Preisfindung und -gestaltung,
Zielgruppenmarketing
• Vorgehensweise:
• Ermittlung von "Text-DNA" durch Textanalyse
• Abgleich mit täglich abgefragten externen Marktdaten (Suchanfragen,
Preis-/Absatz-Statistiken, Genre-, Zielgruppen- und andere
Klassifizierungen, Umsatzanalysen ...)
• Optimierung von Produkten, Meta-/Katalogdaten sowie
Marketingaktivitäten (Conversions)Beispiele: Text & Data Mining
• Beispiel Monitoring der eigenen Marke, der eigenen Inhalte im Netz:
• Wer spricht wo im Web über mich? Was muss ich wissen, um Kampagnen
oder Krisen zu managen? Was sind relevante Inhalte, über die meine
Kund*innen kanalübergreifend diskutieren wollen?
• Wie gut performen meine Prozesse und Kanäle?
• Dies beinhaltet sowohl die seit Jahren bekannte “Sentiment Analysis” als auch
die Erkennung von Trends (“Viralität”), bspw. von “parse.ly”, “NewsWhip” oder
“Storyful”.Beispiele: Text & Data Mining • Prognosen • Automatische Zusammenfassungen (“Scholarcy”, “Paper Digest” …) • Erkennung von Relationen zwischen Texten, bspw. welche anderen Beiträge einen wissenschaftlichen Artikel bestätigen, widerlegen oder bloß erwähnen (“Scite_”)
Quelle: Screenshot von https://scite.ai/, erstellt am 12.06.2019.
Quelle: Screenshot von https://www.paper-digest.com/digest_card/10.1371/journal.pone.0189909, erstellt am 12.06.2019
Quelle: Screenshot von https://www.paper-digest.com/digest_card/10.1371/journal.pone.0189909, erstellt am 12.06.2019
Christian Kohl Beratung und Projektmanagement Geisbergstr. 29 10777 Berlin christian@kohl.consulting www.kohl.consulting Tel.: +49 (0)1577 1848842
Sie können auch lesen

















































