"Konservenglück in Tiefkühl-Town" - Das Songkorpus als empirische Ressource interdisziplinärer Erforschung deutschsprachiger Poptexte
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

Originally published in: Preliminary proceedings of the 15th Conference on Natural Language Processing (KONVENS 2019), October 9 – 11,
2019 at Friedrich-Alexander-Universität Erlangen-Nürnberg. - München [u.a.]: German Society for Computational Linguistics & Language
Technology und Friedrich-Alexander-Universität Erlangen-Nürnberg, 2019. Pp. 229-236
Distributed under a CC BY-NC-SA 4.0 license.
“Konservenglück in Tiefkühl-Town” – Das Songkorpus als empirische
Ressource interdisziplinärer Erforschung deutschsprachiger Poptexte
Roman Schneider
Justus-Liebig-Universität
Angewandte Sprachwissenschaft und Computerlinguistik
Otto-Behaghel-Str. 10 D, 35394 Gießen
roman.schneider@germanistik.uni-giessen.de
Abstract nicht nur beim Radiohören während des Autofah-
rens, beim Einkaufen im Supermarkt, via Online-
Der Beitrag beschreibt ein mehrfach anno- Streamingdienst oder in TV-Shows. Hinzu
tiertes Korpus deutschsprachiger Song- kommt ein durchaus lyrischer Anspruch: Mo-
texte als Datenbasis für interdisziplinäre derne Popsongtexte als „Gebrauchslyrik“ (Blüh-
Untersuchungsszenarien. Die Ressource dorn 2003) sind „latent poetisch, aber selten au-
erlaubt empirisch begründete Analysen thentisch poetisch“ (Flender/Rauhe 1989). Sie
sprachlicher Phänomene, systemisch- dienen oft nicht allein der simplen Zerstreuung,
struktureller Wechselbeziehungen und sondern werden genutzt, um Botschaften und Ge-
Tendenzen in den Texten moderner Pop- fühle zu vermitteln oder – auf Rezipientenseite –
musik. Vorgestellt werden Design und Inspiration und Erklärungen zu finden.
Annotationen des in thematische und au- Angesichts dieses beachtlichen „kommunika-
torenspezifische Archive stratifizierten tiven Impact Factors“ (Kreyer/Mukherjee 2007)
Korpus sowie deskriptive Statistiken am besteht ein substanzielles Desiderat hinsichtlich
Beispiel des Udo-Lindenberg-Archivs. der Berücksichtigung des Popmusik-Genres in der
Korpuslinguistik. Keine der etablierten Sammlun-
1 Einleitung gen enthält Songtexte, entsprechend wenig er-
Natürlichsprachliche Korpora als systematisch forscht sind spezifische Aspekte wie Ästhetik und
zusammengestellte Digitalisate von Kommunika- Stil (Vokabular, Syntax, Register etc.), Inhalt
tionsakten bilden die wichtigste empirische (Thematiken, z. B. im historischen/politischen
Grundlage linguistisch motivierter Forschung. Kontext), Emotionalität (Kategorisierung, Inten-
Für die standardnahe deutsche Gegenwartsspra- sität und Verteilung) oder Beziehungen zwischen
che existieren umfangreiche Korpussammlungen Form und Inhalt. Wie für wenig erforschte
literarischer, journalistischer, juristischer, wissen- Sprachgenres üblich, erscheinen initiale Erpro-
schaftlicher und anderer weit verbreiteter Texts- bung und Validierung statistischer Maße und Ver-
orten, ergänzt durch diverse Spezialkorpora zur fahren aufschlussreich, auch hier stößt das Song-
Abdeckung spezifischer Sprachumstände (vgl. korpus in eine bestehende Lücke.
Kupietz/Schmidt 2018, Lemnitzer/Zinsmeister
2 Stand der Kunst
2015, Lüdeling/Kytö 2008).
Bemerkenswert erscheint vor diesem Hinter- Nachhaltige, empirisch begründete Forschung zu
grund das Fehlen einer wissenschaftlich validen, Texten deutschsprachiger Popmusik bleibt bis-
nachhaltig nutzbaren digitalen Sammlung von lang aufgrund der Nichtexistenz ausreichend
Popmusiktexten. So wie sich die Popmusik von stratifizierter und aufbereiteter Daten ein unerfüll-
einem ursprünglich jugendkulturellen Phänomen tes interdisziplinäres Desiderat. Für das Englische
in den 1950er-/1960er-Jahren zu einem festen Be- hingegen lassen sich inspirierende Beispiele kor-
standteil der Alltagskultur entwickelt hat, sind de- puslinguistischer Forschung zu Diskurs und Spra-
ren textuellen Inhalte in der Sprachrealität inzwi- che in Songtexten finden. So enthält das BLUR-
schen allgegenwärtig und zunehmend Gegenstand Korpus (Blues Lyrics Collected at the University
(qualitativer) Forschung (vgl. von Ammon/von of Regensburg; Miethaner 2005) mehr als 8.000
Petersdorff 2019). Wir sind von ihnen umgeben, digitalisierte Texte und bildet damit eine wert-
Publikationsserver des Leibniz-Instituts für Deutsche Sprache
URN: http://nbn-resolving.de/urn:nbn:de:bsz:mh39-93189
229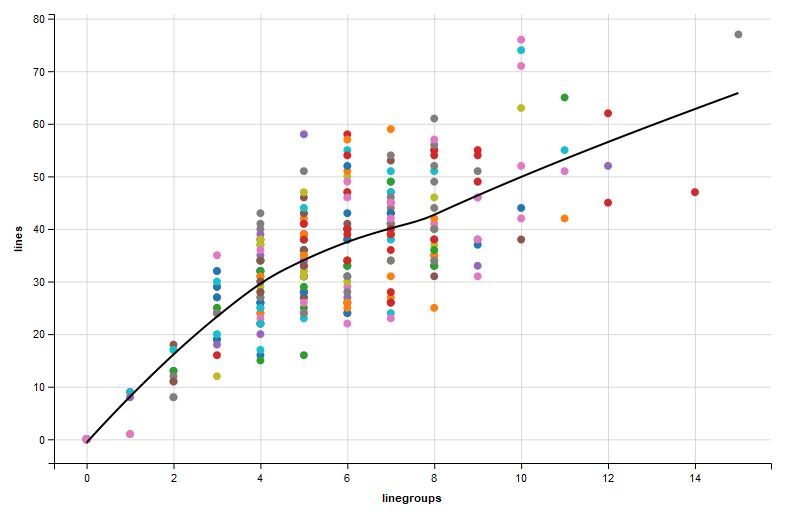
volle Ressource für die Erforschung amerikani- Diskussionen um Sexualität und geschlechterge-
scher Bluessongs. Einen weiteren Meilenstein der rechte Sprache. Eine diachrone Perspektive neh-
Songtextforschung liefern Kreyer/Mukherjee men Napier/Shamir (2018) ein und beziffern mit-
(2007) mit dem von ihnen kompilierten Gießen- hilfe quantitativer Maße emotionale Veränderun-
Bonn Corpus of Popular Music (GBoP), das eng- gen in Songtexten der zurückliegenden Dekaden
lischsprachige Texte von Top-30-Alben empi- seit 1950. Ihre Ergebnisse weisen einen langfristig
risch auswertbar macht. Katznelson et al. (2010) signifikanten Anstieg der Kategorien Ärger, Wut
und Cullem (2009) beschreiben Korpusanalysen und Trauer (mit einem kurzzeitigen Rückgang
zu amerikanischen Songtexten; Watanabe (2018) Mitte der 1980er-Jahre) nach. Der Ausdruck von
begründet das American Popular Music Corpus of Angst nimmt bis in die 1980er-Jahre hinein eben-
English (PMCE-US). Bertin-Mahieux et al. falls kontinuierlich zu, allerdings mit geringerer
(2011) haben ein „Million-Song-Dataset“ aufge- Steigerungsrate. Deutlich zurückgegangen über
baut, während Murphey (1992) eine frühe Samm- den Gesamtzeitraum ist der Ausdruck von Freude.
lung aus Top-50-Chartsongs kompiliert, quantita- In jüngerer Zeit kommen verstärkt computer-
tiv analysiert (z. B. hinsichtlich des Type-Token- linguistische Methoden und Werkzeuge für Text
Verhältnisses) und qualitativ auswertet (z. B. hin- Mining, Sentiment Analysis oder Topic Modeling
sichtlich der Verwendung von Pronomina). Wei- zum Einsatz. Mahedero et al. (2005) evaluieren
tere englischsprachliche Korpora existieren zu die Eignung von Natural Language Processing-
spezifischen Subdomänen, beispielsweise das Tools für die Auswertung von Popmusiktexten;
Rock Lyrics Corpus (ROLC; Falk 2013). Liske (2018) beschreibt den Einsatz der Statisti-
Werner (2012) vergleicht amerikanisches und kumgebung R für die Analyse von Songtexten des
britisches Englisch in Popsongs und beschreibt Künstlers Prince. Penaranda (2006) verwendet
Nutzungsaspekte für das Zweitsprachenlernen Text Mining für empirisch begründete Genre-Zu-
(Werner/Lehl 2015). Bereits Plitsch (1997) the- ordnungen auf Basis sprachlicher Auffälligkeiten.
matisiert den motivierenden Einsatz von Popmu-
siktexten für den Sprachunterricht, während Ter- 3 Korpusdesign und -aufbereitung
hune (1997) hier insbesondere den syntaktisch oft
Eine Grundvoraussetzung solider empirischer Er-
nicht standardkonformen Aufbau von Songtexten
forschung sprachimmanenter Phänomenbereiche
kritisch sieht. Viol (2000) diskutiert identitätsstif-
ist die technisch-physische Integrität der Primär-
tende Phänomene in britischen Popmusiktexten,
daten. Insbesondere der Nachweis statistischer
Motschenbacher (2016) und Van Hoey (2016)
Regularitäten hat unter Beachtung strikter Gültig-
vergleichen Eurovision-Song-Contest-Texte mit
keitsbedingungen zu erfolgen, zu denen die Ge-
breiter stratifizierten Korpora. Diskurse von
währleistung intakter Forschungsobjekte zählt
Weiblichkeit und Männlichkeit in Popsongs un-
(Schneider 2019, 32f.). So lassen sich auf Häufig-
tersucht Kreyer (2015); Nishina (2017) setzt
keitsverteilungen, Längenmessungen etc. basie-
sprachexterne Faktoren wie Musikgenre und Ge-
rende Gesetzmäßigkeiten der Textebene nach-
schlecht der Interpreten in Bezug zu linguistisch
weislich nicht unter Zuhilfenahme von willkürlich
motivierten Analysen (Type Token Ratio, n-
kompilierten Fragmentsammlungen aus Verszei-
Gramme usw.) und kompiliert ein privates Unter-
len oder Sätzen nachweisen. Zu diesen quantitati-
suchungskorpus aus Billboard-Songs einer De-
ven Korrelationen zählen Verteilungsgesetze wie
kade. Eiter (2017) untersucht Songtexte als Phä-
das Zipf-Mandelbrot-Gesetz über den Zusam-
nomen zwischen gesprochener und geschriebener
menhang zwischen Häufigkeitsrang und Frequenz
Sprache. Ergänzend zu solchen übergreifenden
lexikalischer Einheiten, funktionale Gesetze wie
Beiträgen finden sich stilistische Analysen einzel-
das Menzerathsche Gesetz über den Zusammen-
ner Autoren, etwa von Johnson und Larson (2003)
hang zwischen der Länge eines sprachlichen Kon-
zur Verwendung von Metaphern in Beatles-Tex-
strukts und der Länge seiner unmittelbaren Kom-
ten oder von Morini (2013) zu sprachlichen Ei-
ponenten, oder Entwicklungsgesetze wie das Pi-
genheiten in den Songtexten von Kate Bush.
otrovskiy-Altmann-Gesetz zur Bestimmung der
Nicht selten werden Popsongs und ihre Texte
Verwendungshäufigkeiten sprachlicher Einheiten
als Spiegel gesellschaftlicher Entwicklungen be-
aus diachroner Perspektive (vgl. Köhler 2005, Bi-
trachtet (Shukers 1998). Anderson et al. (2003)
emann 2007). Die Erklärungskraft all dieser Kor-
beschäftigen sich mit Korrelationen aggressiver
relationen entfaltet sich erst bei der Analyse zu-
Handlungen und der Konsumation von als aggres-
sammenhängender und ungekürzter Texte, da die
siv klassifizierten Texten. Machin (2010) analy-
siert Songtexte vor dem Hintergrund aktueller
230Messgrößen (Wort-, Morphem- oder Phonemin- noch Sehnsucht) sowie kontraktierte Formen von
ventar, Strophen- und Verszeilenlängen usw.) Verb und Personalpronomen (machste) oder Ver-
stets das Resultat individueller Textgenerierungs- gleichskonjunktion und Artikel (wie’n) genannt;
prozesse sind (Sinclair 2005). die im Songkorpus angetroffene Vielfalt über-
Ziel des Korpusaufbaus ist deshalb die mög- steigt diesbezüglich noch die in Westpfahl (2014)
lichst umfassende Abdeckung kompletter Werke. für den Bereich der Computer Mediated Commu-
Intern fächert sich das Songkorpus auf in autoren- nication (CMC) diskutierte Liste.
spezifische Archive wie das initiale Udo-Linden- Insgesamt findet sich in den Texten häufig ein
berg-Archiv und themenspezifische Archive, bei- bewusstes Spiel mit Normen auf vielfältigen lin-
spielsweise eine als Chart-Song-Archiv firmie- guistischen Ebenen (Satzstrukturen, Schreibung,
rende Sammlung sämtlicher deutschsprachigen Semantik, Wortarten, Wortbildung etc.). Aus die-
Top-100-Songtexte der zurückliegenden 20 Jahre. sem Grund erfolgt die Korpusaufbereitung als
Besondere Aufmerksamkeit verdient die Nut- Wechselspiel zwischen automatisierten Annotati-
zungs- und Urheberrechtsproblematik: Grundlage onsläufen und manueller Nachbearbeitung. Zu-
des Schutzes schöpferischer Leistungen in Form nächst wird auf eine für das Songkorpus maßge-
von Songtexten ist das Urheberrechtsgesetz schneiderte Toolchain der CLARIN-Infrastruk-
(UrhG); nach § 1 UrhG erstreckt sich der Schutz turkomponente WebLicht (Hinrichs et al. 2010)
auf Werke der Literatur, Wissenschaft und Kunst. zurückgegriffen, bestehend aus IMS-Tokenizer,
Zwar bestehen seit 2018 durch das Urheberrechts- TreeTagger mit STTS-Tagset (Schiller 1999), ei-
Wissensgesellschafts-Gesetz großzügigere Rege- nem auf TuebaDZ trainierten Named Entity
lungen für Forschungs- und Bildungseinrichtun- Recognizer sowie dem Berkeley Constituent Par-
gen, trotzdem bleibt für die öffentliche Bereitstel- ser. Für die Kontrolle und ggf. Korrektur der Re-
lung geschützter Inhalte über Recherche-Schnitt- sultate erfolgt deren Import in die kollaborative
stellen eine explizite Autorisierung der Nutzungs- Korpusplattform WebAnno (Eckart de Castilho et
rechte erforderlich. Im Rahmen des Songkorpus- al. 2016). Dort kommen dann, neben einem um
Aufbaus werden deshalb für öffentlich zugängli- Phänomene der konzeptionellen Mündlichkeit er-
che Archive entsprechende Übertragungsverein- weiterten Wortklassen-Tagset (basierend auf
barungen mit den Rechteinhabern getroffenen. Bartz et al. 2014, Beißwenger et al. 2015, Rehbein
Zur Gewährleistung der Interoperabilität er- et al. 2012, Westpfahl et al. 2017) auch Layer und
folgt die Kodierung der Songtexte vermittels stan- Tagsets für die Auszeichnung von Named Entiti-
dardisierter Strukturbeschreibungen gemäß TEI tes (basierend auf Benikova et al. 2014), Neolo-
P5 (TEI Consortium 2019), die spezielle Element- gismen (z. B. Neuwort, Neubedeutung, Wortkom-
typen für Strophen und Verszeilen bereitstellen. bination) und Reimformen (z. B. Anfangsreim,
Nach der aufwändigen Segmentierung in Token, Binnenreim, Endreim) zum Einsatz. Sämtliche
Verszeilen, Strophen und Sätze – Songtexte müs- manuellen Bearbeitungsschritte unterliegen wäh-
sen primär akustisch funktionieren und enthalten rend des Kurationsprozesses einer finalen Bewer-
deshalb selten Interpunktionszeichen zur Identifi- tung unter Zuhilfenahme von Verfahren für die
zierung von Sinneinheiten wie Phrasen und Sät- Inter-Annotator-Reliabilität (Kappa-Statistiken).
zen – schließt sich eine Anreicherung um Annota-
tionen für interdisziplinäre Fragestellungen an: 4 Deskriptive Statistiken und Analysen
Lemmata Das Udo-Lindenberg-Archiv versammelt mehr
Wortklassen, Morphologie, Syntax als 300 Texte des Pioniers der deutschsprachigen
Neologismen bzw. originelle Produkte Rock- und Popsongs – und damit sämtliche nicht-
von Wortbildungsprozessen fremdsprachigen Texte des Autors aus fünf Jahr-
Named Entities als Identifizierung von re- zehnten sowie einzelne unveröffentlichte Songs.
alen und fiktiven Personen, Figuren, In-
stitutionen, Ortsnamen etc. Lindenberg- Chart-Song-
Reimformen und Reimschemata Archiv Archiv
Die Adaption von an standardnaher Sprache Songtexte 301 684
orientierten Kategorien und Verfahren an weniger Wortformen 62.807 244.276
homogene Sprachvarietäten erfordert spezifische Verszeilen 10.688 37.734
Anpassungen (Horbach et al. 2014, Karlova- Strophen 1.769 5.803
Bourbonus et al. 2016, Zinsmeister et al. 2014);
Songtexte machen hier keine Ausnahme. Exemp- Tabelle 1. Archive im Songkorpus (Stand 10/2019).
larisch seien Konstruktionen ohne Subjekt (hab
231In den zurückliegenden Jahren wurden für die Trennlinie, während spezifische Wörter (im Lin-
Komplexität literarischer Texte verschiedene denberg-Archiv etwa „abgefuckt“, „Freund“,
Maße und Methoden vorgestellt; vgl. z. B. Gries „Welt“) einen größeren Abstand aufweisen.
(2016), Perkuhn et al. (2012). Ein besonders für
angewandte Disziplinen wie die Stilometrie inte-
ressanter Untersuchungsbereich betrifft Messun-
gen zum Reichtum des Vokabulars (Yule 1944)
bzw. der lexikalischen Vielfalt (Carroll 1938). Die
Idee der Wortschatzvarianz geht dabei von der
Annahme aus, dass gemessene Werte (Type-To-
ken-Verhältnis als Quotient aus Type-Anzahl und
Token-Anzahl) Indikatoren für den Wortschatz-
umfang eines Autors und mithin charakteristische
Eigenschaften sind (Tanaka-Ishii/Aihara 2015).
Ein methodisches Problem bleibt der Umstand,
dass beinahe alle Ansätze (wie z. B. TTR, STTR)
als Konsequenz des Zipf-Mandelbrot-Gesetzes Bild 2. Strophen und Verszeilen ausgewählter Alben.
(Mandelbrot 1953) abhängig von der Korpus-
größe variieren (Tweedie/Baayen 1998, Evert et 5 Fazit und Ausblick
al. 2017). Die Online-Plattform des Songkorpus1
Songtexte können als Textgattung betrachtet wer-
bietet hierzu neben den Primärdaten verschiedene
den, die als eine Art "Vermündlichung des Lyri-
Maße und visualisierte Statistiken an.
schen" Merkmale sowohl des geschriebenen als
auch des gesprochenen Diskurses aufweist, sowie
als Datenquelle im Kontinuum zwischen Standard
und Nonstandard. Vielversprechend erscheinen
gezielte Analysen sprachlicher Phänomene, die
sich von Entsprechungen in anderen literarischen
Schriften, Sach- und Gebrauchstexten oder spon-
tan gesprochener Alltagssprache unterscheiden.
Das Songkorpus komplementiert den Kanon
korpuslinguistischer Sammlungen um mehrfach
annotierte deutschsprachige Songtexte, mit dem
Bild 1. Neologismen im Udo-Lindenberg-Archiv. vorgestellten Udo-Lindenberg-Archiv sowie ei-
nem Chart-Song-Archiv als initialen Inhalten.
Zu den weiteren unmittelbar abfragbaren Daten Beide werden kontinuierlich aktualisiert und um
zählen Frequenzlisten (interessanterweise finden weitere Archive ergänzt. Die TEI-annotierten In-
sich hier die Wörter „und“ und „ich“ auf den vor- halte des Lindenberg-Archivs sind über das On-
dersten Rängen, dann erst gefolgt von Artikeln), line-Frontend recherchier- und einsehbar und las-
Neologismen (vgl. Bild 1), die Überprüfung quan- sen sich für die weiterführende wissenschaftliche
titativer Regularitäten wie dem Zipf’schen Gesetz Forschung gesammelt herunterladen. Ausge-
oder der Korrelation zwischen Strophen- und wählte korpuslinguistisch motivierte Auswertun-
Verszeilenzahl (vgl. Bild 2) sowie Kollokations- gen und Visualisierungen beider Archive können
analysen und n-Gramme (vgl. Bild 3). Außerdem auf Zeichen-, Wort- und Versebene unmittelbar
werden Ortsbezeichnungen (Named Entitites) aus unter http://songkorpus.de berechnet werden.
den Texten auf einer geografischen Karte verortet. Forschungsthemen, die durch die neue Res-
Bild 4 kontrastiert Worthäufigkeiten im Lin- source befördert werden, umfassen z.B.: (a) Topic
denberg-Archiv und in einem regional und zeit- Modeling, Identifizierung prominenter Themen
lich ausgewogenen allgemeinsprachlichen Kor- für ausgewählte Zeiträume und Autoren (b) Paral-
pus (zu dessen Stratifizierung vgl. Bubenhofer et lelitäten zwischen Personen-, Orts- oder Instituti-
al. 2013). Dabei gruppieren sich Wörter mit ähn- onsbezeichnern und prominenten Themen im öf-
lichen Frequenzen in beiden Sammlungen („ak- fentlichen Diskurs (c) Sentiment Analysis zur Be-
zeptieren“, „besonders“, „in“) nahe der zentralen schreibung von Emotionalität in Songtexten oder
1
http://songkorpus.de unter dem Menüpunkt „Explorer“
232Musikgenres (d) Einfluss sprachexterner Faktoren rung autoren-/zeitspezifischer Formulierungs-
(z. B. individuelle Veröffentlichungsproduktivi- muster und symbolischer Elemente/Metaphern (i)
tät) auf die lexikalische Vielfalt (e) Stilistische empirische Annäherungen an Phänomene wie Iro-
Analysen, Identifizierung von „style markers“ nie und Wortwitz (j) Variationsstudien zu dialek-
wie Verwendungshäufigkeit bestimmter Perso- talen Songtexten (k) Empirische Aussagen zur
nalpronomen (f) Textähnlichkeitsmessungen (g) Standardkonformität und Verortung im Konti-
Reimformen und Reimschemata (h) Identifizie- nuum zwischen Schrift- und Umgangssprache.
Bild 3. Prominente Bigramme ausgewählter Alben.
Bild 4. Wortfrequenzvergleich.
Das Songtextkorpus schließt damit eine Daten- punkte erscheinen vielfältig und vielverspre-
lücke, die bislang die empirisch fundierte Beant- chend: Neben Linguistik und Literaturwissen-
wortung syntaktischer, semantischer oder prag- schaft lassen sich profitierende Forschungsberei-
matischer Fragestellungen für diese Textsorte er- che im breiten Spektrum der Kulturwissenschaf-
schwert. Die interdisziplinären Anknüpfungs- ten sowie der Musik-, Medien- oder Geschichts-
wissenschaft verorten.
233Literatur Chris Biemann. 2007. A Random Text Model for
the Generation of Statistical Language Invari-
Frieder von Ammon, Dirk von Petersdorff (Hg.).
ants. In: Proceedings of HLT-NAACL-07. Hu-
2019. Lyrik/ lyrics. Songtexte als Gegenstand
man Language Technologies: The Annual Con-
der Literaturwissenschaft. Wallstein Verlag,
ference of the North American Chapter of the
Göttingen.
Association for Computational Linguistics. Ro-
Craig A. Anderson, Nicholas L. Carnagey, Janie chester, NY, USA. http://wortschatz.uni-
Eubanks. 2003. Exposure to violent media: The leipzig.de/~cbiemann/pub/2007/biemannRan-
effects of songs with violent lyrics on aggres- domText-HLTNAACL07main.pdf
sive thoughts and feelings. In: Journal of Per-
John B. Carroll. 1938. Diversity of Vocabulary
sonality and Social Psychology, 84(5), 960–
and the Harmonic Series Law of Word-fre-
971.
quency Distribution. In: The Psychological
Annette Blühdorn. 2003. Pop and Poetry – Pleas- Record. 2, 16: 379–386.
ure and Protest: Udo Lindenberg, Konstantin
Brian Cullen. 2009. A Corpus Analysis of Pop
Wecker and the Tradition of German Cabaret.
Song Lyrics. New Directions. Nagoya Institute
In: German Linguistic and Cultural Studies, Bd
of Technology.
13.
Richard Eckart de Castilho, Éva Mújdricza-
Noah Bubenhofer, Marek Konopka, Roman
Maydt, Seid Muhie Yimam, Silvana Hartmann,
Schneider. 2013. Präliminarien einer Korpus-
Iryna Gurevych, Annette Frank, Chris Bie-
grammatik. Korpuslinguistik und interdiszipli-
mann. 2016. A Web-based Tool for the Inte-
näre Perspektiven auf Sprache (CLIP) 4. Tü-
grated Annotation of Semantic and Syntactic
bingen: Narr.
Structures. In: Proceedings of the LT4DH
Thomas Bartz, Michael Beißwenger, Angelika workshop at COLING 2016, Osaka.
Storrer. 2014. Optimierung des Stuttgart-Tü- https://www.clarin-d.net/images/lt4dh/pdf/
bingen-Tagset für die linguistische Annotation LT4DH11.pdf
von Korpora zur internetbasierten Kommuni-
Alexander Eiter. 2017. ‘Haters gonna Hate’: A
kation: Phänomene, Herausforderungen, Er-
Corpus Linguistic Analysis of the Use of Non-
weiterungsvorschläge. In: Journal for Langu-
Standard English in Pop Songs. University of
age Technology and Computational Linguistics
Innsbruck, Department of English Studies.
28 (1): 157–198.
DOI: 10.13140/RG.2.2.31181.33763
Michael Beißwenger, Thomas Bartz, Angelika
Stefan Evert, Sebastian Wankerl, Elmar Nöth.
Storrer, Swantje Westpfahl. 2015. Tagset und
2017. Reliable measures of syntactic and lexi-
Richtlinie für das Part-of-Speech-Tagging von
cal complexity: The case of Iris Murdoch. In:
Sprachdaten aus Genres internetbasierter
Proceedings of the Corpus Linguistics 2017
Kommunikation. Empirikom shared task on au-
Conference, Birmingham, UK.
tomatic linguistic annotation of internet-based
http://purl.org/stefan.evert/PUB/EvertWank-
communication (EmpiriST 2015).
erlNoeth2017.pdf
http://sites.google.com/site/empirist2015/
Johanna Falk. 2013. We Will Rock You: A Dia-
Darina Benikova, Christian Biemann, Marc
chronic Corpus-based Analysis of Linguistic
Reznicek. 2014. NoSta-D Named Entity Anno-
Features in Rock Lyrics. Växjö: Linnaeus Uni-
tation for German: Guidelines and Dataset. In:
versity.
Proceedings of the 10th International Confer-
ence on Language Resources and Evaluation Reinhard Flender, Hermann Rauhe. 1989. Pop-
(LREC 2014), Reykjavik. http://www.lrec- musik: Aspekte ihrer Geschichte, Funktionen,
conf.org/proceedings/lrec2014/pdf/276_Paper Wirkung und Ästhetik. Darmstadt: Wissen-
.pdf schaftliche Buchgesellschaft.
Thierry Bertin-Mahieux, Daniel Ellis, Brian Stefan Th. Gries. 2016. Quantitative Corpus Lin-
Whitman, Paul Lamere. 2011. The Million guistics with R. 2nd rev. & ext. Edition. London
Song Dataset. In: Proceedings of the 12th In- & New York: Routledge, Taylor & Francis
ternational Society for Music Information Re- Group.
trieval Conference.
234Marie Hinrichs, Thomas Zastrow, Erhard Hin- Debbie Liske. 2018. Lyric Analysis with NLP &
richs. 2010. WebLicht: Web-based LRT Ser- Machine Learning with R. DataCamp.
vices in a Distributed eScience Infrastructure. https://www.datacamp.com/community/tutori-
In: Proceedings of the Seventh conference on als/R-nlp-machine-learning
International Language Resources and Evalua-
Anke Lüdeling, Merja Kytö (Hgg.). 2008. Corpus
tion. In: Proceedings of the 9th International
Linguistics. An International Handbook. Hand-
Conference on Language Resources and Eval-
bücher zur Sprach- und Kommunikationswis-
uation (LREC 2010), Malta. http://www.lrec-
senschaft 29 (1-2). Berlin: de Gruyter.
conf.org/proceedings/lrec2010/pdf/270_Paper
.pdf David Machin. 2010. Analysing Popular Music:
Image, Sound, Text. Los Angeles, CA: Sage.
Andrea Horbach, Diana Steffen, Stefan Thater,
Manfred Pinkal. 2014. Improving the perfor- Jose Mahedero, Álvaro Martínez, Pedro Cano,
mance of standard part-of-speech taggers for Markus Koppenberger, Fabien Gouyon. 2005.
computer-mediated communication. In: Pro- Natural language processing of lyrics. In: Pro-
ceedings of KONVENS 2014, Hildesheim, ceedings of the 13th annual ACM international
Germany. conference on Multimedia (MULTIMEDIA
'05). ACM, New York, NY: 475–478. DOI:
Mark L. Johnson, Steve Larson. 2003. ‘Something
https://doi.org/10.1145/1101149.1101255
in the Way She Moves’: Metaphors of musical
motion. In: Metaphor and Symbol 18(2): 63–84 Benoît Mandelbrot. 1953. An information theory
of the statistical structure of language. In: W.
Natalie Karlova-Bourbonus, Holger Grumt
Jackson (Hg.): Communication Theory. New
Suárez, Henning Lobin. 2016. Compilation and
York: Academic Press: 503–512.
Annotation of the Discourse-structured Blog
Corpus for German. In: Proceedings of the 4th Ulrich Miethaner. 2005. I can look through muddy
Conference on CMC and Social Media Corpora water: Analyzing Earlier African American
for the Humanities, Ljubljana. English in Blues Lyrics (BLUR). Regensburger
Arbeiten zur Anglistik und Amerikanistik 47.
Noah Katznelson, Joseph Gelman, Katrin Lind-
Frankfurt am Main: Peter Lang.
blom, Marie Caput. 2010. American Song Lyr-
ics: A Corpus-Based Research Project Featur- Massimiliano Morini. 2013. Towards a musical
ing Twenty Years in Rock, Pop, Country and stylistics: movement in Kate Bush’s “Running
Hip−Hop. San Francisco, CA: San Francisco up that Hill”. In: Language and Literature 22
State University. (4): 283–97.
Reinhard Köhler. 2005. Korpuslinguistik. Zu wis- Heiko Motschenbacher. 2016. A corpus linguistic
senschaftstheoretischen Grundlagen und me- study of the situatedness of English pop song
thodologischen Perspektiven. In: LDV-Forum, lyrics. In: Corpora 11.1: 1–28
Band 20/2: 1–16. https://jlcl.org/content/2-al- Tim Murphey. 1992. The Discourse of Pop Songs.
lissues/22-Heft2-2005/Reinhard_Koehler.pdf In: TESOL Quarterly 26: 770–774.
Rolf Kreyer. 2015. “Funky fresh dressed to im- Kathleen Napier, Lior Shamir. 2018. Quantitative
press”: A corpus-linguistic view on gender Sentiment Analysis of Lyrics in Popular Music.
roles in pop songs. In: International Journal of In: Journal of Popular Music Studies, Vol. 30
Corpus Linguistics, 20 (2): 174–204. No. 4, December 2018: 161–176. DOI:
Rolf Kreyer, Joybrato Mukherjee. 2007. The Style 10.1525/jpms.2018.300411
of Pop Song Lyrics: A Corpus-linguistic Pilot Yasunori Nishina. 2017. A Study of Pop Songs
Study. In: Anglia - Zeitschrift für englische Phi- based on the Billboard Corpus. In: Internatio-
lologie, Band 125, Heft 1: 31–58. DOI: nal Journal of Language and Linguistics 4 (2)
10.1515/ANGL.2007.31 2017: 125–134.
Mark Kupietz, Thomas Schmidt. 2018. Korpus- Jerome Penaranda. 2006. Text Mining von Song-
linguistik. Germanistische Sprachwissenschaft texten. Diplomarbeit. Technische Universität
um 2020. Band 5. Berlin: Walter de Gruyter. Wien.
Lothar Lemnitzer, Heike Zinsmeister. 2015. Kor- Rainer Perkuhn, Holger Keibel, Marc Kupietz.
puslinguistik. Eine Einführung. Tübingen: 2012. Korpuslinguistik. Paderborn: Fink.
Narr.
235Axel Plitsch. 1997. Music + Song = Authentic Valentin Werner. 2012. Love is all around: a cor-
Listening in the Language Classroom. In: Der pus-based study of pop lyrics. In: Corpora 7 (1),
Fremdsprachliche Unterricht Englisch 31 (1): S. 19-50.
4–13.
Valentin Werner, Maria Lehl. 2015. Pop lyrics
Ines Rehbein, Sören Schalowski, Heike Wiese. and language pedagogy: A corpus-linguistic
2012. Erweiterung des STTS für gesprochene approach. In: Formato, F.; Hardie, A. (Hg.)
Sprache. STTS Workshop am IMS Stuttgart. (2015): Corpus Linguistics. Lancaster:
UCREL: 341–343.
Anne Schiller, Simone Teufel, Christine Stöckert.
1999. Guidelines für das Tagging deutscher Swantje Westpfahl. 2014. STTS 2.0? Improving
Textcorpora mit STTS (Kleines und großes the Tagset for the Part-of-Speech-Tagging of
Tagset). University of Stuttgart: Institut für German Spoken Data. In: Proceedings of LAW
Maschinelle Sprachverarbeitung (IMS). VIII – The 8th Linguistic Annotation Work-
shop. Association for Computational Linguis-
Roman Schneider. 2019. Mehrfach annotierte
tics (ACL Anthology W14-49): 1–10.
Textkorpora. Strukturierte Speicherung und
http://www.aclweb.org/anthology/W14-4901
Abfrage. Korpuslinguistik und interdisziplinäre
Perspektiven auf Sprache (CLIP) 8. Tübingen: Swantje Westpfahl, Thomas Schmidt, Jasmin Jo-
Narr. nietz, Anton Borlinghaus. 2017. STTS 2.0. Gui-
delines für die Annotation von POS-Tags für
Roy Shuker. 1998. Key Concepts in Popular Mu-
Transkripte gesprochener Sprache in Anleh-
sic. London: Routledge.
nung an das Stuttgart Tübingen Tagset (STTS).
John Sinclair. 2005. Corpus and Text: Basic Prin- Arbeitspapier. Mannheim: Institut für Deutsche
ciples. In: Martin Wynne (Hg.): Developing Sprache. urn:nbn:de:bsz:mh39-60634
Linguistic Corpora: A Guide to Good Practice.
George Udny Yule. 1944. The Statistical Study of
Oxford: Oxbow Books: 1–16.
Literary Vocabulary. Cambridge University
Kumiko Tanaka-Ishii, Shunsuke Aihara. 2015. Press, Cambridge.
Computational Constancy Measures of Text.
Heike Zinsmeister, Ulrich Heid, Kathrin Beck.
Yule’s K and Rényi’s Entropy. In: Computa-
2014. Adapting a part-of-speech tagset to non-
tional Linguistics 41 (3): 481–502.
standard text: The case of STTS. In: Proceed-
TEI Consortium (Hg.). 2019. TEI P5: Guidelines ings of the 10th International Conference on
for Electronic Text Encoding and Interchange Language Resources and Evaluation (LREC
3.5.0. http://www.tei-c.org/Guidelines/P5/ 2014), Reykjavik. http://www.lrec-conf.org/
Todd Terhune. 1997. Pop Songs: Myths and Re- proceedings/lrec2014/pdf/721_Paper .pdf
alities. In: The English Connection 1 (1): 8–12.
Fiona J. Tweedie, Harald Baayen. 1998. How
variable may a constant be? In: Computers and
the Humanities 32: 323–352.
Thomas Van Hoey. 2016. 'Love love peace
peace': a corpus study of the Eurovision Song
Contest. Graduate Institute of Linguistics, Na-
tional Taiwan University.
Claus-Ulrich Viol. 2000. A Crack in the Union
Jack? National Identity in British Popular Mu-
sic. In: Diller, H.; Otto, E.; Stratmann, G. (Hg.)
(2000): Youth Identities: Teens and Twens in
British Culture. Heidelberg: Winter: 81–106
Ayano Watanabe. 2018. A Style of Song Lyrics:
The Case of Really. In: Zephyr (2018), 30: 12–
27. https://doi.org/10.14989/233019
236Sie können auch lesen

















































