Relationale Datenbanksysteme für Unternehmensanwendungen - Grundlagen von Unternehmensanwendungen Michael Perscheid, Ralf Teusner, Stefan Halfpap ...
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

Relationale Datenbanksysteme für Unternehmensanwendungen
Grundlagen von Unternehmensanwendungen
Michael Perscheid, Ralf Teusner, Stefan Halfpap, Werner Sinzig
Enterprise Platform and Integration Concepts
Hasso-Plattner-Institut
Vorlesungsinhalte
■ Einführung zu Unternehmensanwendungen
■ Enterprise Resource Planning
□ Rechnungswesens, Controlling und Planung
□ Kundenauftragsabwicklung und Einkauf
□ Materialwirtschaft und Produktionsplanung
□ Personalwesen
■ Kundenbeziehungsmanagement (Customer Relationship Management; Gast: Prof. Carsten Hahn)
■ Datenbankkonzepte für Unternehmensanwendungen
(inkl. spaltenorientierter Hauptspeicherdatenbanken)
■ Enterprise Cloud Plattformen zur Erweiterung und Integration von Unternehmensanwendungen
2
Agenda
■ Relationale Datenbanksysteme
□ Relationales Modell
□ Relationale Algebra
□ SQL (Structured Query Language)
□ Anfragebearbeitung und Konsistenz
■ Unternehmensanwendungen
□ Beispiele
□ Datenbankanfrageeigenschaften
□ Dateneigenschaften
□ Datenbanksystemlandschaften
3
■ Übungsblatt 1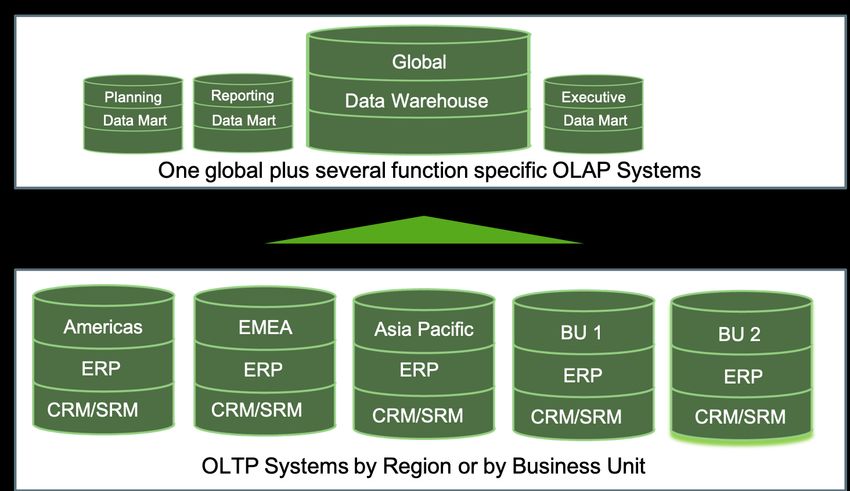
Relationale Datenbanksysteme
Motivation
■ „Enterprise applications are about the display, manipulation, and storage of large
amounts of often complex data and the support or automation of business
processes with that data.“ Martin Fowler „Patterns of Enterprise Application Architecture Patterns“ (2002)
□ Große komplexe Datenmengen, die in der realen Welt existierende Entitäten abbilden
□ Unterstützung/Automatisierung von Geschäftsprozessen auf Basis dieser Daten
□ Nutzen üblicherweise relationale Datenbanken
Kundennummer Name Land PLZ Stadt …
1 Ostseerad Deutschland 18724 Zingst :
2 Silicon Valley Bikes USA 94304 Palo Alto :
: : : : : : 4
Ausschnitt einer Kundentabelle
Relationale Datenbanksysteme Relationales Modell ■ Datenbank (DB): organisierte Sammlung von Daten ■ Datenbank(management)system (DBMS): DB + Datenbankverwaltungssoftware ■ Relationale Datenbanken basieren auf dem relationalen Datenmodell 1. Struktur der Daten – Konzeptionelles Modell (im Gegensatz zur physischen Repräsentation) 2. Operationen auf den Daten – Datenbankveränderungen – Datenbankanfragen/Queries 3. Constraints („Einschränkungen“) auf den Daten – Attribut-Domäne (Wertebereich) – Definition von Schlüsseln 5
Relationale Datenbanksysteme
Relationales Modell - Ursprung
■ Vorher:
□ enge Kopplung von Datenbankanfragen und physischer Repräsentation der Daten
(wie sind Daten gespeichert)
à schlechte Wartbarkeit (insbesondere von Anwendungen)
□ Kein Konzept welche Operationen (Funktionalität) benötigt werden
■ Ted Codd schlägt das Relationale Model vor
□ „A Relational Model of Data for Large Shared Data Banks“ (1970)
□ Abstraktes/konzeptionelles Modell mit einfachen Datenstrukturen
und high-level/abstrakten Operationen
□ Implementierung und physische Umsetzung im Speicher sind nicht spezifiziert
6Relationale Datenbanksysteme
Relationales Modell
■ Daten – zwei-dimensionale Tabelle (Relation genannt)
□ R ⊆ D1 × ... × Dn mit D1 × ... × Dn := {(a1, ..., an) | a1∈D1 ∧ ... ∧ an ∈Dn}
□ R ist (im relationalen Modell üblicherweise) eine Menge
(relationale Datenbanken speichern üblicherweise Multimengen)
■ Attribut Ai – Name einer Spalte
■ Schema R(A1, ..., An) – Name der Relation und Menge der Attribute
■ Tupel (a1, ..., an) – Element (Zeile (außer Kopfzeile)) der Relation mit Werten ai
■ Weitere Konzepte:
□ Gleichheit, Relations-Instanz/-Beispiel, Schlüssel, Normalisierung,
Datendomäne/Datentypen, NULL (Wert ist unbekannt)
7Relationale Datenbanksysteme
Relationale Algebra
■ Relationale Algebra ist eine Anfragesprache für das relationale Modell und Basis für
Umsetzung in der Praxis (Datenbanksystemen), d.h. theoretische Grundlage für
relationale Datenbanksysteme und SQL (Structured Query Language)
■ Operationen:
□ Benötigen eine oder mehrere Relationen als Eingabe und geben eine neue Relation aus
□ Können zu komplexen Anfragen/Queries verkettet werden
■ Klassen von traditionellen Operationen:
□ Operationen, die Teile der Relation entfernen: Selektion und Projektion
□ Operationen, die Tupel zweier Relationen verknüpfen: kartesisches Produkt und Join
□ Umbenennung von Relationen und Attributen
□ Mengenoperationen: Vereinigung, Schnitt, Differenz und Division
8
(Details: siehe Anhang)Relationale Datenbanksysteme
SQL – Die Datenbanksprache
■ Structured Query Language unterstützt:
□ Eine (die) in relationalen Datenbanksystemen genutzte Anfragesprache
□ Deklarative Anfragen für relationales Modell
(durch viele Optimierungen erfolgreich in der Praxis)
□ Datenbankveränderungen (Insert, Update, Delete)
□ Datendefinitionen
– Schemadefinition und –änderung
– Datendomäne
– Constraints
– Weitere Aspekte: Indexe, physische Speicherung
■ Verschiedene Standards und Implementierungen: Syntax und Funktionalität kann sich von
9
System zu System unterscheiden. http://troels.arvin.dk/db/rdbms/Relationale Datenbanksysteme
Von der SQL-Anfrage zum Ergebnis
Datenbanksystem
(SQL-)Anfrage Parser und Übersetzer
Systemkatalog
DB-Schema
Logischer Anfrageplan
Statistiken
Unternehmensanwendung Optimierer
Physischer Ausführungsplan
Daten
Anfrageergebnis Ausführungseinheit
10Relationale Datenbanksysteme
Daten- und Anfragekonsistenz
■ Eine Haupteigenschaft von relationalen DBMSs sind konsistente/korrekte
Anfrageergebnisse, auch bei nebenläufigen Anfragen und trotz Auftreten von Fehlern
(insbesondere wichtig für Unternehmensanwendungen, z.B. in der Buchführung)
Durch Nebenläufigkeitskontrolle und Loggen + Wiederherstellung
■ Transaktion: Ausführung einer Folge von (einer oder mehrerer) Operationen
□ Elementare Änderungseinheit in einem Datenbanksystem
□ Erfüllt ACID Kriterien
– Atomicity (Transaktionen werden „ganz oder gar nicht“ ausgeführt)
– Consistency (Constraints, Schlüsselbeziehungen)
– Isolation (nebenläufige Transaktionen beeinflussen sich nicht - abhängig vom Isolationslevel)
11
– Durability (Ergebnisse einer erfolgreichen Transaktionen sind dauerhaft gespeichert)Relationale Datenbanksysteme
Literatur und Empfehlung
■ Hector Garcia-Molina „Database Systems”
■ Avi Silberschatz „Database System Concepts“
http://db-book.com/
■ HPI Datenbanksysteme 1 und 2
■ Standford‘s CS 145 „Data Management and Data Systems“ https://cs145-fa18.github.io/
■ CMU‘s 15-445 „Database Systems“ https://15445.courses.cs.cmu.edu/fall2018/ 12Beispiele für Unternehmensanwendungen
■ Klassische Domäne
□ ERP, SRM, CRM (siehe 02a_Digitalisierung_von_Geschaeftsprozessen)
■ Erweiterte Domäne
Neue Technologien haben Einfluss auf Unternehmensanwendungen.
Informationsintegration aus unterschiedlichen Quellen bietet neue Möglichkeiten zur
Anreicherung und dadurch Optimierung der klassischen Unternehmensprozesse.
□ Sensordaten in Produktionsüberwachung
□ Unstrukturierte Daten wie medizinische Behandlungsberichte und Röntgenbilder
□ Posts im Web und auf sozialen Netzwerken zum Einfluss von Produkten
13Beispiele für Unternehmensanwendungen
Klassische Domäne: Abwicklung eines Kaufauftrags
Basierend auf Frank Körsgen „SAP R/3 Arbeitsbuch“ (2005)
■ Prozesse im Vertrieb werden durch Vertriebs-/Verkaufsbelege abgebildet
□ Kundenanfrage
□ Angebot
□ Auftrag
□ Lieferung
□ Warenausgang + Buchhaltungsbeleg
□ Ausgangsrechnung + Buchhaltungsbeleg
□ Bezahlung + Buchhaltungsbeleg
■ (Details in der Vorlesung zum Rechnungswesen)
14Beispiele für Unternehmensanwendungen
Klassische Domäne: Abwicklung eines Kaufauftrags
■ Vorkommende teils aufwändige Prozesse
□ Preisfindung
□ Verfügbarkeitsprüfung
□ Bedarfsübergabe (an Einkauf und/oder Fertigung)
□ Versandterminierung
□ Versandstellen- und Routenermittlung
□ Kreditlimitprüfung
15Beispiele für Unternehmensanwendungen
Klassische Domäne: Abwicklung eines Kaufauftrags
■ Verfügbarkeitsprüfung
Zugänge zum Wunschliefertermin Abgänge zum Wunschliefertermin
Lieferungen
Fertigungsaufträge
Bestellungen Aufträge
Bestand verfügbare Menge
Basiered auf Frank Körsgen „SAP R/3 Arbeitsbuch“ (2005) 16Unternehmensanwendungen
Datenbankanfrageeigenschaften
Clark D. French „’One Size Fits All’ Database Architectures Do Not Work for DDS“ (1995)
■ Online Transaction Processing (OLTP) ■ Online Analytical Processing (OLAP)
□ Beispiele: Auftrag anlegen/suchen, □ Beispiele: Mahnlauf,
Rechnung erstellen, Kontenbuchung, Verfügbarkeitsprüfung, Cross-Selling,
Anlegen und Anzeigen von Stammdaten Operationales Reporting (Auflistung
offenen Rechnungen)
□ Einfache Anfragen □ Komplexe Anfragen
□ Oft festgelegte Anfragen □ Ad-hoc-Anfragen
à Index-Unterstützung □ „Decision Support“
□ Geringe Datengrundlage □ Große Datengrundlage
(stark-selektive Anfragen) (schwach-selektive Anfragen)
□ Daten(tupel)eingabe und –abruf □ Analyseanfragen (Aggregation und
Gruppierung weniger Attribute) 17Unternehmensanwendungen
Vielseitige Anfrageeigenschaften („Mixed Workloads”)
■ Unternehmensanwendungen beinhalten sowohl transaktionale als auch
analytische Anfragen
■ Auch Hybrid Transactional/Analytical Processing (HTAP) oder OLxP
■ Vereinen Eigenschaften von OLTP und OLAP
□ Einfache und komplexe Abfragen
□ Vordefinierte und ad-hoc-Abfragen
□ „Zeilenoperationen“ und Analysen (Aggregationen, Gruppierungen, Joins)
über komplette Spalten
□ INSERTS, UPDATES und viele SELECTS
18Unternehmensanwendungen
Anfrageeigenschaften: OLTP Datenzugriffsmythos
Hasso Plattner „The Impact of Columnar In-Memory Databases on Enterprise Systems“ (2014)
■ Workload Analysen von Unternehmensanwendungen zeigen: OLTP und OLAP Workloads
unterscheiden sich NICHT wesentlich bezüglich ihres Schreibanteil
100% 100% 100%
90 % 90 % 90 % Delete
Delete Delete
80 % Modification 80 % Modification 80 % Modification
70 % Insert 70 % Insert 70 % Insert
Workload
Workload
60 % Workload 60 % 60 %
50 % Read 50 % 50 %
Read Read
40 % 40 % 40 %
30 % 30 % 30 %
20 % 20 % 20 %
10 % 10 % 10 %
0 % 0 % 0 %
TPC-C OLTP OLAP Classic Simplified*
SAP Financials
(a) TPC-C Benchmark (b) Workload Analysis (c) SAP Financials
Krueger et al. VLDB’11 Workload Analysis
*Without Transaction-Maintained Aggregates
19Unternehmensanwendungen
Eigenschaften von Unternehmensdaten
■ Viele Tabellen haben hunderte von Attributen
■ Viele Attribute werden in der Regel NICHT benutzt
■ Für viele Attribute dominieren NULL oder DEFAULT-Werte
■ Viele Attribute haben eine geringe Kardinalität (Anzahl verschiedener Attributwerte)
■ Attributwerte sind häufig ungleichmäßig verteilt
■ Attributwerte verschiedener Attribute hängen oft voneinander ab
■ Tabellen sind breit und spärlich gefüllt à erlaubt effiziente Komprimierung
■ Detaillierte Informationen in
Jens Krüger „Fast Updates on Read-Optimized Databases Using Multi-Core CPUs“ (2011) 20
http://www.vldb.org/pvldb/vol5/p061_jenskrueger_vldb2012.pdfUnternehmensanwendungen - Datenbanksystemlandschaft
Historischer Hintergrund
Michael Stonebraker „One Size Fits All: An Idea Whose Time Has Come and Gone“ (2005)
■ Relationale DBMSs entstanden in den 1970er Jahren als Forschungs-Prototypen
□ System R
Genealogy der relationalen Datenbanken
□ INGRES https://hpi.de/fileadmin/user_upload/fachgebiete/naumann/projekte/RDBMSGenealogy/RDBMS_Genealogy_V6.pdf
■ Beide Systeme wurden für die Verarbeitung von Unternehmensdaten (OLTP) geschaffen
■ Zeilenorientierte Festplattenbasierte Datenbanksysteme
■ Seit Anfang der 1980er: „one size fits all“ Strategie
Gründe: Kosten, Kompatibilität, Verkauf, Marketing
■ In der 1990er Jahren: Unternehmen wollen Daten aus verschiedenen operationalen DBs in
ein Data-Warehouse für Business Intelligence vereinen
“Although most warehouse projects were dramatically over budget and ended up delivering only a subset
of promised functionality, they still delivered a reasonable return on investment. In fact, it is widely
acknowledged that historical warehouses of retail transactions pay for themselves within a year […].” 21Unternehmensanwendungen - Datenbanksystemlandschaft
Beispiel
22Unternehmensanwendungen - Datenbanksystemlandschaft
Data-Warehouse und OLAP Technologien
S. Chaudhuri et U. Dayal „An Overview of Data Warehousing and OLAP Technology “ (1997)
■ Gründe für Entstehung: Performanz und Datenintegration
□ Relationale Datenbanken waren historisch für OLTP optimiert: Angst vor
Performanzeinbruch für Transaktionen durch komplexe Ad-hoc-Anfragen
□ Ältere Daten für historische Tendenzen + zusätzliche Informationen z.B. Aktienpreise
■ Aufbau eines Data-Warehouses für Unternehmen ist langwieriger und komplexer Prozess
■ Erfordert umfangreiche Geschäftsprozessmodellierung
(Abdeckung des gesamten Unternehmens)
■ Data-Marts: integrieren Datenuntermenge, die sich auf einen einzelnen Organisationsbereich
fokussieren z.B. Marketing Data-Mart
23ed for OLTP. It is for all these Section 8 with a brief mention of these issues.
ses Unternehmensanwendungen
are implemented separately - Datenbanksystemlandschaft
Data-Warehouse Architektur
2. Architecture and End-to-End Process
S. Chaudhuri et U. Dayal „An Overview
Figureof1Data Warehousing
shows a typicalanddata
OLAP Technology “ (1997)
warehousing architecture.
e implemented on standard or
Ss, ■called Relational OLAP
Datenintegration Monitoring & Admnistration
rvers assume that data is stored in
ey support extensions to SQL and Metadata
Repository
■ Datenmodellierung
mentation methods to efficiently OLAP
Servers Analysis
ional data model and operations. Data Warehouse
nal OLAP (MOLAP) servers are External Extract
■ Operationen sources Transform Query/Reporting
multidimensional data in special Load
Operational Refresh Serve
ys) and implement the OLAP dbs Data Mining
l data■ structures.
Datenspeicherung
nd maintaining a data warehouse Data sources
■ Hilfsstrukturen Data Marts Tools
rver and defining a schema and
for the warehouse. Different Figure 1. Data Warehousing Architecture
24
xist. Many organizations
(Details: want to
siehe Anhang)Unternehmensanwendungen - Datenbanksystemlandschaft Ansätze ■ Unternehmensanwendungen beinhalten sowohl transaktionale als auch analytische Anfragen ■ Aber: Anforderungen an OLAP- und OLTP-Datenbanksysteme sind widersprüchlich (historischer) Ansatz 1: Trennung in eigenständige Systeme (Tuning der Datenspeicherung und des Schemas) ■ Zeilen-orientiertes Festplatten-basiertes Datenbanksystem mit materialisierten Sichten für häufige Berichte ■ Data Warehouse für OLAP-Performanz und Datenintegration (moderner) Ansatz 2: Optimierung eines Systems für beide Anfragearten (mit Kompromissen) ■ Spalten-orientiertes Hauptspeicher-basiertes Datenbanksystem ■ (Data Warehouse für Datenintegration) 25
Unternehmensanwendungen - Datenbanksystemlandschaft
Nachteile der Systemtrennung
■ Datenredundanz
■ Datenkonsistenz schwieriger
■ Synchronisierung der Systeme durch Extract, Transform, Load (ETL)
□ Kostenintensiver Prozess
□ ETL verursacht eine Zeitverzögerung
■ Unterschiedliche Datenschemas erzeugen eine höhere Komplexität für Anwendungen,
die beide Systeme nutzen
26Unternehmensanwendungen - Datenbanksystemlandschaft
Kombination von OLTP und OLAP in einem System
■ Eine Datenbasis als „Wahrheitsquelle“ („Single source of truth“)
■ Ziel sind ad-hoc-Analysen auf dem transaktionalen Schema ohne materialisierte Sichten
(z.B. vorberechnete Aggregate) – „Mixed Workloads“ auf einem System
à Vereinfachte Anwendungen (nur ein DBMS mit allen Datenpunkten anfragen) und
Datenbankstrukturen (weniger Indizes, keine materialisierte Sichten)
■ Ermöglicht durch modernere/schnellere Hardware
■ Dennoch: für spezielle Charakteristiken optimierte Datenbanksysteme sind „One size fits all“
Systemen überlegen
Michael Stonebraker „One Size Fits All: An Idea Whose Time Has Come and Gone“ (2005)
27Unternehmensanwendungen Zusammenfassung ■ Unternehmensanwendungen nutzen relationale Datenbanken □ Relationales Modell (Tabellen, Operationen, Constraints) ist flexibel □ Performante Anfragen dank vieler Optimierungen □ Konsistente Daten und Anfrageergebnisse ■ Unternehmensanwendungen beinhalten transaktionale und analytische Anfragen; Insbesondere analytische Anforderungen sind mit der Zeit gewachsen Für beide Anfragearten dominieren lesende Anfragen (SQL SELECTs); ■ Tabellen von Unternehmensanwendungen sind breit und spärlich gefüllt ■ Zwei Ansätze: Separat optimierte Systeme vs. Vereinigung in einem System □ Vereinigung überwindet viele Nachteile der Systemtrennung □ Entsprechende Datenbanksysteme beinhalten viele Optimierungen, die den Anfrage- und Datencharakteristiken gerecht werden (spätere Datenbankkonzeptvorlesungen) 28
Unternehmensanwendungen
Übungsblatt 1
Unternehmensanwendungen
Sommersemester 2021: Übung 1
Aufgabe 1 (10 Punkte)
Analysieren Sie die Datenverteilung der Tabelle ACDOCA:
a) Wie viele Attribute hat die Tabelle? (1 Punkt)
b) Wie viele Tupel hat die Tabelle? (1 Punkt)
c) Wie viele Attribute haben weniger als 2, 5, 10, 100, 1.000, 10.000 verschiedene Attri-
butwerte? (Wir empfehlen dafür ein kleines Programm zu schreiben.) (6 Punkte)
Fassen Sie Ihre gewonnenen Erkenntnisse zu den Datencharakteristiken unter Beantwortung
folgender Fragen zusammen.
d) Unternehmenstabellen haben ... (1 Punkt)
☐viele Attribute.
☐wenige Attribute.
e) Viele Attribute haben ... (1 Punkt)
☐viele verschiedene Werte.
☐wenig verschiedene Werte.
Aufgabe 2 (28 Punkte)
Beantworten Sie folgende Fragen und geben Sie die SQL-Statements an, die Sie zur Lö -
sung verwendet haben. Verwenden Sie RCLNT=’400’ (MANDT=’400’), RLDNR=’0L’,
RBUKRS=’1710' und KTOPL=’ YCOA’ für Ihre Anfragen.
a) Inspizieren Sie den Buchhaltungsbeleg mit der Nummer 0090004054 aus dem
Jahr 2016:
1) Wann (Attribut BUDAT) wurde der Beleg gebucht? (1 Punkt)
2) Welches Produkt (Produktnummer und deutscher -text) referenziert der Beleg?
(1 Punkt)
3) Welches Nettogewicht hat das Produkt? (1 Punkt)
4) Ermitteln Sie die Kundenanschrift. (1 Punkt)
5) In welche Konten (gesucht sind die deutschen Bezeichner) wurde gebucht? Be-
stimmen Sie, ob es sich jeweils um eine Soll- oder Haben-Position handelt. Be-
stimmen Sie anhand dieser Informationen den Geschäftsvorfall, den der Beleg
29
beschreibt. (3 Punkte)
6) Zeigen Sie, dass für diesen Buchhaltungsbeleg das Saldo-Null-Prinzip gilt.
(1 Punkt)Anhang
Relationale Datenbanksysteme
Relationale Algebra: Projektion, Selektion
■ Projektion πA1, ..., An(R) erzeugt eine neue Relation mit einer Untermenge der Spalten von R
□ In der relationalen Algebra von Mengen werden Duplikat-Tupel entfernt
■ Selektion σC(R) erzeugt eine neue Relation mit einer Untermenge der Tupel von R (die eine
Bedingung C erfüllen)
31Relationale Datenbanksysteme
Relationale Algebra: Projektion
■ R First Name Last Name Country Year of Birth
Paul Smith Australia 1986
Lena Jones USA 1990
Hanna Schulze Germany 1942
Hanna Schulze USA 2000
■ πFirst Name, Last Name(R) First Name Last Name
Paul Smith
Lena Jones
Hanna Schulze
32Relationale Datenbanksysteme
Relationale Algebra: Selektion
■ R First Name Last Name Country Year of Birth
Paul Smith Australia 1986
Lena Jones USA 1990
Hanna Schulze Germany 1942
Hanna Schulze USA 2000
■ σCountry=‘USA‘(R) First Name Last Name Country Year of Birth
Lena Jones USA 1990
Hanna Schulze USA 2000
33Relationale Datenbanksysteme
Relationale Algebra: Kartesische Produkt , Join
■ Kartesische Produkt (Kreuzprodukt) R × S ist die Menge aller Paare mit einen beliebigen
ersten Element aus R und einem beliebigen zweiten Element aus S
□ Das Schema der neuen Relation ist die Vereinigung der Schemata von R und S
(Ausnahme: R und S haben ein Attribut A gemeinsam à Umbenennung zu R.A und S.A)
■ Join verknüpft Tupel, die „irgendwie“ zusammenpassen/übereinstimmen
□ „Hängende“ (dangling) Tupel: Tupel ohne Übereinstimmung
□ Natürlicher Join R ⋈ S : Übereinstimmung in allen gemeinsamen Attributen von R und S
□ Theta-Join R ⋈θ S: Übereinstimmung basierend auf einer beliebigen Bedingung C
– Produkt von R und S + Filter mit Bedingung C
– Ergebnisschema wie beim Kreuzprodukt
□ Semi-Join R ⋉ S ist die Menge der Tupel in R, die eine Übereinstimmung mit S haben
34Relationale Datenbanksysteme
Relationale Algebra: Kartesische Produkt
■ R ■ R ×S
First Name Last Name Country Year of Birth First Name Last Name R.Country Year of Birth S.Country Capital
Paul Smith Australia 1986 Paul Smith Australia 1986 Germany Berlin
Lena Jones USA 1990 Paul Smith Australia 1986 USA Washington
Hanna Schulze Germany 1942 Lena Jones USA 1990 Germany Berlin
Hanna Schulze USA 2000 Lena Jones USA 1990 USA Washington
Hanna Schulze Germany 1942 Germany Berlin
■ S Hanna Schulze Germany 1942 USA Washington
Hanna Schulze USA 2000 Germany Berlin
Country Capital
Hanna Schulze USA 2000 USA Washington
Germany Berlin
USA Washington 35Relationale Datenbanksysteme Relationale Algebra: Natürlicher Join ■ R ■ R⋈S First Name Last Name Country Year of Birth First Name Last Name Country Year of Birth Capital Paul Smith Australia 1986 Lena Jones USA 1990 Washington Lena Jones USA 1990 Hanna Schulze Germany 1942 Berlin Hanna Schulze Germany 1942 Hanna Schulze USA 2000 Washington Hanna Schulze USA 2000 ■ S Country Capital Germany Berlin USA Washington 36
Relationale Datenbanksysteme
Relationale Algebra: Mengenoperationen
■ Vorbedingung für Vereinigung, Schnitt und Differenz von R und S:
□ R und S müssen das gleiche Schema (Attributnamen und Datentypen) haben
■ Vereinigung R ∪ S ist die Menge der Elemente, die in R, S oder beiden Mengen sind
■ Schnitt R ∩ S ist die Menge der Elemente, die in R und S sind
■ Differenz R \ S (oder R – S) ist die Menge der Elemente, die in R, aber nicht in S sind
□ R \ S ist verschieden von S \ R
■ Division R ÷ S:
□ Das Schema der neuen Relation ist die Differenz der Schemata von R und S
□ R ÷ S enthält alle Elemente dieses Schemas, welche mit den Elementen aus S
in jeder Kombination in R vorkommen (siehe Beispiel) 37Relationale Datenbanksysteme
Relationale Algebra: Mengenvereinigung
■ R ■ R∪S
Country Capital Country Capital
Norway Oslo Norway Oslo
USA Washington USA Washington
Poland Warsaw Poland Warsaw
Germany Berlin
■ S
Country Capital
Germany Berlin
USA Washington 38Relationale Datenbanksysteme Relationale Algebra: Mengenschnitt ■ R ■ R∩S Country Capital Country Capital Norway Oslo USA Washington USA Washington Poland Warsaw ■ S Country Capital Germany Berlin USA Washington 39
Relationale Datenbanksysteme Relationale Algebra: Mengendifferenz ■ R ■ R\S Country Capital Country Capital Norway Oslo Norway Oslo USA Washington Poland Warsaw Poland Warsaw ■ S ■ S\R Country Capital Country Capital Germany Berlin Germany Berlin USA Washington 40
Relationale Datenbanksysteme Relationale Algebra: Mengendivision ■ R ■ R ÷S First Name Last Name Country Country Paul Smith Australia USA Lena Jones USA Hanna Schulze Germany Hanna Schulze USA ■ S First Name Last Name Lena Jones Hanna Schulze 41
Relationale Datenbanksysteme
Relationale Algebra: Komplexe Ausdrücke
■ Operationen können zu komplexen Ausdrücken (Anfragen) kombiniert werden
□ Ausdrücke entsprechen immer Relationen
□ Ausdrücke als geklammerter Ausdruck oder Baum darstellbar
42Relationale Datenbanksysteme
Relationale Algebra: Minimale relationale Algebra?
■ Vereinigung, Schnitt, Differenz, Division, Projektion, Selektion, Kartesisches Produkt,
natürlicher Join, Theta-Join, Semi-Join, Umbenennung
43Relationale Datenbanksysteme
Relationale Algebra: Minimale relationale Algebra!
■ Vereinigung, Schnitt, Differenz, Division, Projektion, Selektion, Kartesisches Produkt,
natürlicher Join, Theta-Join, Semi-Join, Umbenennung
■ R ∩ S = R \ (R \ S)
■ R ÷ S = πCountry(R) \ πCountry((πCountry(R) × S) \ R)
44Relationale Datenbanksysteme
Relationale Algebra: Was fehlt?
■ Multimengen-Semantik (+ Duplikatentfernung)
■ Aggregation (und Gruppierung)
■ Sortierung
■ Erweiterte Projektion
■ Outer Join
■ NULL
45Relationale Datenbanksysteme
Relationales Modell: Multimengen-Semantik
■ Multimengen (erlauben Duplikate)
□ Neue Definitionen für Operationen!
■ Einige relationale Operationen sind für Multimengen effizienter (ohne Duplikatentfernung)
□ Union
□ Projektion
■ Duplikatentfernung δ wandelt Multimenge in Menge um
46Relationale Datenbanksysteme
Relationales Modell: Aggregation
■ Aggregationen fassen Werte einer Spalte zusammen
□ Beispiele: SUM, AVG, MIN, MAX, COUNT
□ Gruppierungen γ ermöglichen Aggregationen von Tupel-Gruppen, deren Werte in einer
oder mehreren Spalten übereinstimmen
□ γA1, ..., Am, AVG(Au), COUNT(Av), MIN(Aw), MAX(Ax), SUM(Ay) (R)
47Relationale Datenbanksysteme
Relationales Modell: Aggregation
■ R ■ γMAX(Year of Birth)(R)
First Name Last Name Country Year of Birth Year of Birth
Paul Smith Australia 1986 2000
Lena Jones USA 1990
Hanna Schulze Germany 1942
Hanna Schulze USA 2000 ■ γCountry, MAX(Year of Birth)(R)
Country Year of Birth
Australia 1986
Germany 1942
USA 2000
48Relationale Datenbanksysteme
Relationales Modell: Sortierung
■ Sortierung τ verwandelt ungeordnete Datenstrukturen (z.B. Menge, Multimenge) in
geordnete/sortierte (z.B. Liste)
□ Nur nützlich als letzter Operator einer relationalen Query (und ihres logischen
Anfrageplans), weil nachfolgende Operatoren die Liste zurück in eine Menge/Multimenge
umwandeln
□ Wichtig für physische Anfragepläne (spezifische Implementierungen von Operatoren
können sortierte Eingaben benötigen)
49Relationale Datenbanksysteme
Relationales Modell: Erweiterte Projektion
■ Neben Umbenennungen erlauben erweiterte Projektionen beliebige Ausdrücke
□ Konstanten
□ Arithmetische Operationen
□ String-Operationen
50Relationale Datenbanksysteme
Relationales Modell: Outer Join
■ Das Ergebnis des Outer Joins R |⋈| S ist die Vereinigung des natürlichen Joins R ⋈ S und
aller Dangling Tupel von R und S; Dangling Tupel werden mit NULL-Werten aufgefüllt
□ Full, Left, Right Outer Join
□ Theta-Join-Versionen des Outer Joins arbeiten analog
□ Inner Join ist ein Synonym des „normalen“ Joins
51Relationale Datenbanksysteme
SQL: Tabellendefinition und Datenbankveränderungen
CREATE TABLE R(A1 D1, ..., An Dn)
■ R (Name der) Relation
DROP TABLE R
■ Ai Attribute
■ Di Datentypen
INSERT INTO R VALUES(a1, ..., an) ■ Ai Attributwerte
DELETE FROM R
■ SQL-Schlüsselwörter und Namen von Relationen und Attributen (ohne Anführungszeichen)
unterscheiden Groß- und Kleinschreibung nicht
□ Gleich: INSERT, insert, Insert, iNseRt
□ Werte/Konstanten unterscheiden Schreibweise: ‘Potsdam’ != ‘POTSDAM’
52
Konkrete SQL-Queries: https://hpi.de/fileadmin/user_upload/fachgebiete/plattner/teaching/EnterpriseApplications/sql_statements.sql
Beispielprogramm: https://hpi.de/fileadmin/user_upload/fachgebiete/plattner/teaching/EnterpriseApplications/sqlite_example.pyRelationale Datenbanksysteme
SQL: Datenbankanfragen – Basisform
SELECT A1, ..., Aj
■ C Bedingung
FROM R1, ..., Rk
WHERE C
■ Auswertungs-/Lesereihenfolge
1. FROM ... - angefragte Tabellen
- entspricht dem kartesischen Produkt in der relationalen Algebra
2. WHERE ... - Filterkriterien
- entspricht der Selektion in der relationalen Algebra
3. SELECT ... - auszugebene Attributwerte
- entspricht der Projektion in der relationalen Algebra
53Relationale Datenbanksysteme
SQL: Datenbankanfragen – Aggregation und Sortierung
SELECT A1, ..., Am, AVG(Au), COUNT(Av), MIN(Aw), MAX(Ax), SUM(Ay)
FROM R
WHERE C
GROUP BY A1, ..., Am
SELECT A1, ..., Am
FROM R
WHERE C
ORDER BY A1, ..., Aj
54Relationale Datenbanksysteme
SQL: Datenbankanfragen – NULL und Dreiwertige Logik
■ Drei Werte: wahr, falsch, unbekannt
■ Jeder Vergleich mit NULL gibt „unbekannt“ zurück
□ 4 < NULL
□ NULL NULL
□ NULL = NULL
■ „A IS NULL“ um Attribut A auf NULL zu prüfen
55Relationale Datenbanksysteme
SQL: Datenbankanfragen – NULL und Dreiwertige Logik
■ Dreiwertige Logik
□ OR: (unbekannt OR wahr) = wahr
(unbekannt OR falsch) = unbekannt
(unbekannt OR unbekannt) = unbekannt
□ AND: (unbekannt AND wahr) = unbekannt
(unbekannt AND falsch) = falsch
(unbekannt AND unbekannt) = unbekannt
□ NOT: (NOT unbekannt) = unbekannt
■ Ergebnis der WHERE-Klausel wird als falsch betrachtet, wenn es „unbekannt“ ist
56Relationale Datenbanksysteme
Zusammenfassung: Relationales Modell und SQL
■ Unternehmensanwendungen nutzen relationale Datenbanksysteme
■ Relationale Datenbanksysteme basieren auf dem relationalen Modell
■ Relationales Modell ist ein konzeptionelles Modell,
welches Daten als Relationen/Tabellen abbildet
■ Relationale Algebra definiert Operationen auf Relationen
■ SQL ist eine in relationalen Datenbanksystemen genutzte Anfragesprache, die auf der
relationalen Algebra aufbaut (der Umfang von SQL geht über Queries hinaus)
57use inconsistent representations, codes and formats, which is the Data Warehousing Information Center4.
have to be reconciled. Finally, supporting the
Unternehmensanwendungen
multidimensional data models and operations -typical
Datenbanksystemlandschaft
of Research in data warehousing is fairly recent, and has focused
Data-Warehouse: Datenintegration
OLAP requires special data organization, access methods,
and implementation methods, not generally provided by
primarily on query processing and view maintenance issues.
There still are many open research problems. We conclude in
S. Chaudhuri et U. Dayal „An Overview of Data Warehousing and OLAP Technology “ (1997)
commercial DBMSs targeted for OLTP. It is for all these Section 8 with a brief mention of these issues.
Aufwendiger
■reasons ETL-Prozess
that data warehouses are implemented separately
from operational databases. 2. Architecture and End-to-End Process
□ Extraktion der relevanten Daten aus operationalen DBs und externen Quellen
Figure 1 shows a typical data warehousing architecture.
Data warehouses might be implemented on
□ Transformation der Daten in das Warehouse-Schemastandard or
extended relational DBMSs, called Relational OLAP Monitoring & Admnistration
□ Laden
(ROLAP) der These
servers. Daten in das
servers Warehouse
assume that data is stored in
relational databases, and they support extensions to SQL and Metadata
Repository
special access and implementation methods to efficiently OLAP
Servers Analysis
implement the multidimensional data model and operations. Data Warehouse
In contrast, multidimensional OLAP (MOLAP) servers are External Extract
Transform
Metadatenmanagement
■servers that directly store multidimensional data in special sources
Load
Query/Reporting
Operational Refresh Serve
data structures (e.g., arrays) and implement the OLAP
□ Beschreibung der Datenquellen
operations over these special data structures.
dbs Data Mining
□ Beschreibung des Warehouse-Schemas
There is more to building and maintaining a data warehouse
than (siehe
selectingFolgefolien)
Data sources
Data Marts Tools
an OLAP server and defining a schema and
some complex queries
□ Beschreibung derfor the warehouse. Different
Datenextraktions- Figure 1. Data Warehousing Architecture
und Datentransformationsregeln
architectural alternatives exist. Many organizations want to
58
implement an integrated enterprise warehouse that collects It includes tools for extracting data from multiple operational
information about all subjects (e.g., customers, products, databases and external sources; for cleaning, transforminguse inconsistent representations, codes and formats, which is the Data Warehousing Information Center .
have to be reconciled. Finally, supporting the
Unternehmensanwendungen
multidimensional data models and operations typical of Research in data warehousing is fairly recent, and has focused
OLAP requires special data organization, access methods, primarily on query processing and view maintenance issues.
Data-Warehouse: Datenmodellierung
and implementation methods, not generally provided by
commercial DBMSs targeted for OLTP. It is for all these
There still are many open research problems. We conclude in
Section 8 with a brief mention of these issues.
S. Chaudhuri
reasonsetthat
U. Dayal „An Overview
data warehouses of Data Warehousing
are implemented separately and OLAP Technology “ (1997)
from operational databases.
■ OLTP Schema-Design basiert auf Normalisierung (redundanzfreie Speicherung) 2. Architecture and End-to-End Process
Figure 1 shows a typical data warehousing architecture.
■ Für OLAP sindData
effiziente
warehousesAnfragen und effizientes
might be implemented Laden
on standard or wichtig
extended relational DBMSs, called Relational OLAP Monitoring & Admnistration
(ROLAP) servers. These servers assume that data is stored in
relational databases, and they support extensions to SQL and Metadata
Repository
■ Mehrdimensionale
special Datensicht
access and implementation methods to efficiently OLAP
Servers Analysis
implement the multidimensional data model and operations.
Datenwürfel (OLAP-Würfel)
Stadt
Data Warehouse
In contrast, multidimensional OLAP (MOLAP) servers are External Extract
sources Transform Query/Reporting
servers that directly store multidimensional data in special
um
Load
□ Numerische data
Kennzahlen
structures (e.g., arrays) and implement the OLAP Operational Refresh Serve
at
Produkt
dbs
D
werden analysiert z.B.
Data Mining
operations over these special data structures.
Umsätze oder Bestände
There is more to building and maintaining a data warehouse Data sources
Data Marts Tools
than selecting an OLAP server and defining a schema and
□ Jede Kennzahl hängt von einer Menge an Dimensionen
some complex queries for the warehouse. Different ab Figure 1. Data Warehousing Architecture
architectural alternatives exist. Many organizations want to
□ Dimensionenimplement
sind oft hierarchisch
an integrated enterprise warehouse that collects It includes tools for extracting data from multiple operational
information about
– Tag - Monat - Quartal – Jahr all subjects (e.g., customers, products, databases and external sources; for cleaning, transforming
sales, assets, personnel) spanning the whole organization. and integrating this data; for loading data into the data
– Produkt - Kategorie – Industrie
However, building an enterprise warehouse is a long and warehouse; and for periodically refreshing the warehouse to
complex process, requiring extensive business modeling, and
– Stadt - Bezirk - Land reflect updates at the sources and to purge data from59 the
may take many years to succeed. Some organizations are warehouse, perhaps onto slower archival storage. In addition
settling for data marts instead, which are departmentalUnternehmensanwendungen - Datenbanksystemlandschaft
Data-Warehouse: Operationen
S. Chaudhuri et U. Dayal „An Overview of Data Warehousing and OLAP Technology “ (1997)
■ Slicing und Dicing: Selektion/Auswahl bestimmter Informationen
■ Drill-Down: zunehmende Datendetails
Stadt
um
at
■ Drill-Up/Roll-Up: zunehmende Aggregation/Verdichtung der Daten Produkt
D
■ Pivoting/Rotation: Umorganisation der Datenansicht
60Let there Entity Relationship diagrams and normalization techniques
umn that are popularly used for database design in OLTP
pivoting
regate a
Unternehmensanwendungen - Datenbanksystemlandschaft
environments. However, the database designs recommended
by ER diagrams are inappropriate for decision support
gregated
ue in the
Data-Warehouse: Datenspeicherung - ROLAP
systems where efficiency in querying and in loading data
(including incremental loads) are important.
e of the S. Chaudhuri et U. Dayal „An Overview of Data Warehousing and OLAP Technology “ (1997)
Most data warehouses use a star schema to represent the
and the
mple, if■ R(elational)OLAP
multidimensional data model. The database consists of a
single fact table and a single table for each dimension. Each
axis may
tuple in the fact table consists of a pointer (foreign key - often
sent the Daten
□ uses sind
a generated in efficiency)
key for Tabellen (relational)
to each of the dimensions gespeichert
sales for
that provide its multidimensional coordinates, and stores the
original Umsetzung
□ numeric measures forim Sternschema
those mit Denormalisierungen aus Performanzgründen:
coordinates. Each dimension
aders in
eine Faktentabellen + eine Tabelle pro Dimension
table consists of columns that correspond to attributes of the
dimension. Figure 3 shows an example of a star schema.
ll-down.
ect and
hus, it is Order ProdNo
gregated OrderNo ProdName
OrderDate ProdDescr
ration is Fact table Category
onds to CategoryDescr
Customer OrderNo
aking a UnitPrice
CustomerNo SalespersonID
selected CustomerNo QOH
CustomerName
we can ProdNo Date
CustomerAddress
create a City DateKey DateKey
of sale. CityName Date
sorting), Salesperson Quantity Month
TotalPrice Year
SalespersonID
City
SalespesonName
City CityName
ted a lot State
business
Quota
Country
61
ans of a Figure 3. A Star Schema.
e storedLet there Entity Relationship diagrams and normalization techniques
umn that are popularly used for database design in OLTP
pivoting
regate a
Unternehmensanwendungen - Datenbanksystemlandschaft
environments. However, the database designs recommended schemas where the dimensional hierarchy is explicitly
by ER diagrams are inappropriate for decision support
gregated
ue in the
Data-Warehouse: Datenspeicherung - ROLAP
systems where efficiency in querying and in loading data
represented by normalizing the dimension tables, as shown in
Figure 4. This leads to advantages in maintaining the
Data w
(including incremental loads) are important. answer
e of the S. Chaudhuri et U. Dayal „An Overview of Data Warehousing andHowever,
dimension tables. OLAP Technology “ (1997)
the denormalized structure of the
and the
Most data warehouses use a star schema to represent the access
mple, if■ R(elational)OLAP
multidimensional data model. The database consists of a dimensional tables in star schemas may be more appropriate issues a
single fact table and a single table for each dimension. Each for browsing the dimensions.
axis may
tuple in the fact table consists of a pointer (foreign key - often such as
sent the Schneeflockenschema
□ uses als Alternative:
a generated key for efficiency) to each of the dimensions Dimensionshierarchie wird explizit durch indices
sales for
original Normalisierung
that dargestellt
provide its multidimensional coordinates, and stores the Fact constellations are examples of more complex structures importa
numeric measures for those coordinates. Each dimension effectiv
aders in in which multiple fact tables share dimensional tables. For
Sternschema
table consists of columns that correspond to attributes of the
dimension. Figure 3 shows an example of a star schema.
vs. Schneeflockenschema
example, projected expense and the actual expense may form answer
a fact constellation since they share many dimensions. importa
ll-down. Einfacheres Schema (Anfragen) vs. Weniger Redundanz efficien
ect and
hus, it is Order ProdNo Order Category
queries
OrderNo ProdNo efficien
gregated ProdName OrderNo CategoryName
OrderDate ProdName
ProdDescr OrderDate CategoryDescr
ration is Fact table Category
ProdDescr be expl
Fact table
onds to CategoryDescr
Category paper, i
Customer OrderNo Customer OrderNo
aking a UnitPrice
UnitPrice
selected CustomerNo SalespersonID
CustomerNo SalespersonID QOH Therefo
CustomerNo QOH
CustomerName CustomerName CustomerNo
we can Date
vs.
CustomerAddress ProdNo DateKey Year
create a DateKey DateKey CustomerAddress Date Month
City
Date City CityName
DateKey Index S
of sale. CityName ProdNo Month
Quantity Month Date Year A numb
sorting), Salesperson Salesperson Quantity
TotalPrice Year Month
SalespersonID TotalPrice are use
City SalespersonID
SalespesonName City State
City CityName
SalespesonName
CityName
conditio
ted a lot City
Quota State
Quota State useful
62
business Country
operatio
ans of a Figure 3. A Star Schema. Figure 4. A Snowflake Schema.
e stored cases elUnternehmensanwendungen - Datenbanksystemlandschaft
Data-Warehouse: Datenspeicherung - MOLAP
S. Chaudhuri et U. Dayal „An Overview of Data Warehousing and OLAP Technology “ (1997)
■ M(ultidimensional)OLAP
□ Mehrdimensionale Daten sind in speziellen Datenstrukturen gespeichert
z.B. mehrdimensionale Arrays
□ Nutzen meist zwei Dimensionen (+ Kompressionsverfahren) um dünn
besetze Datenwürfel („sparse data“) effizient zu unterstützen
63Unternehmensanwendungen - Datenbanksystemlandschaft
Data-Warehouse: Datenspeicherung - Hilfsstrukturen
S. Chaudhuri et U. Dayal „An Overview of Data Warehousing and OLAP Technology “ (1997)
■ ROLAP- und MOLAP-Systeme nutzen Hilfsstrukturen für effiziente Anfragebearbeitung
□ Voraggregierte Daten (nach verschiedenen Dimensionen)
□ Materialisierte Sichten
□ Indexstrukturen
– Bit-Map-Index als Alternative zu Pointer/ID-Listen
àEffiziente Operationen: Index-Intersection, Index-Union
– Join-Indizes: Dimensionstabelle à Faktentabelle
– Indizes für Textsuche
■ Weitere Effizienzsteigerung durch Partitionierung/Sortierung möglich
64Sie können auch lesen

















































