Social Bots in der politischen Twittersphäre - Identifikation und Relevanz - opus4.kobv.de
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Social Bots in der
politischen Twittersphäre –
Identifikation und Relevanz
Rechts- und Wirtschaftswissenschaftliche Fakultät
Fachbereich Wirtschafts- und Sozialwissenschaften
Friedrich-Alexander-Universität Erlangen-Nürnberg
zur
Erlangung des Doktorgrades Dr. rer. pol.
vorgelegt von
Fabian Pfaffenberger
aus NürnbergAls Dissertation genehmigt
von der Rechts- und Wirtschaftswissenschaftlichen Fakultät /
vom Fachbereich Wirtschafts- und Sozialwissenschaften
der Friedrich-Alexander-Universität Erlangen-Nürnberg
Tag der mündlichen Prüfung: 07.04.2021
Vorsitzende/r des Promotionsorgans: Prof. Dr. Klaus Henselmann
Gutachter/in: Prof. Dr. Christina Holtz-Bacha
Prof. Dr. Reimar ZehSocial Bots in der politischen Twittersphäre – Identifikation und Relevanz
Inhaltsverzeichnis
Gesamtbetrachtung von Socials Bot auf Twitter .................................................................................. 1
1. Vom Forschungsproblem zum Forschungstrend ................................................................ 1
2. Vorgehen ................................................................................................................................. 5
3. Ergebnisdiskussion ................................................................................................................ 7
Aufsatz 1: What you tweet is what we get? Zum wissenschaftlichen Nutzen von
Twitter‐Daten ................................................................................................................................................. 13
Aufsatz 2: Was bin ich – und wenn ja, wie viele? Identifikation und Analyse von
Political Bots während des Bundestagswahlkampfs 2017 auf Twitter..................................... 15
Aufsatz 3: The overestimated danger? Twitter bots in the 2019 European
elections campaign ....................................................................................................................................... 17
1. Introduction .......................................................................................................................... 18
2. Social Bots - definitions and classifications........................................................................ 19
3. Methodology ......................................................................................................................... 21
4. Analysis at the account level ............................................................................................... 24
4.1 High Performers ................................................................................................................................. 26
4.2 Duplicators............................................................................................................................................ 27
4.3 Comparison of both analysis clusters ........................................................................................ 28
5. Tweet-level analysis ............................................................................................................. 31
6. Comparison with English-language tweets ........................................................................ 34
6.1 Account level ........................................................................................................................................ 35
6.2 Tweet level ............................................................................................................................................ 38
7. The overestimated danger of social bots in the political context ..................................... 39
Bibliography ................................................................................................................................ 42
Appendix ..................................................................................................................................... 47
Zusammenfassung ......................................................................................................................................... III
Literaturverzeichnis ..................................................................................................................................... IV
ISocial Bots in der politischen Twittersphäre – Identifikation und Relevanz
Gesamtbetrachtung von Socials Bot auf Twitter
von Fabian Pfaffenberger
1. Vom Forschungsproblem zum Forschungstrend
Seit seinem Start im Jahr 2006 hat der Kurznachrichtendienst Twitter schnell an weltweiter Popularität
gewonnen. Mittlerweile gibt es 192 Millionen täglich aktive Nutzer1 (Twitter Inc., 2021b), die Webseite
von Twitter verzeichnete im August 2020 rund 6,12 Milliarden Aufrufe (SimilarWeb, 2021). Twitter ist
dabei längst nicht nur eine reine Plattform für den Austausch kurzer Status-Updates und der Pflege
sozialer Kontakte, sondern dient inzwischen häufig auch als Verbreitungskanal von Pressemeldungen,
als Kommunikations- und Koordinationsplattform während politischer Unruhen oder Unglücken, als
Werbekanal und auch als Wahlkampfplattform. Spätestens mit der „Twitter-Politik“ während Donald
Trumps Präsidentschaft erhält die politische Twittersphäre2 auch eine hohe Medienresonanz. Die
Debatten um die Beeinflussung des Brexit-Votums und der US-Präsidentschaftswahl im Jahr 2016
führten auch zu einer intensiveren wissenschaftlichen Betrachtung von Twitter – vor allem im
Zusammenhang mit der Verbreitung von Falschnachrichten. Abbildung 1 zeigt den Anstieg an Twitter-
bezogener Berichterstattung und wissenschaftlicher Studien im Zeitverlauf.
Als Brennglas politischer und gesellschaftlicher Debatten und mit seiner immens hohen, täglich
generierten und größtenteils frei verfügbaren Datenmenge ist Twitter eine populäre und – auf den ersten
Blick – ideale Datenquelle für wissenschaftliche Analysen. Aufgrund ihrer Struktur, Verfügbarkeit und
Aktualität eigenen sich Twitter-Daten für vielerlei Untersuchungsmethoden: Inhalts- und
Themenanalysen über Netzwerkanalysen über Semantischen Analysen bis hin zu Zeitreihenstudien.
Dennoch stellt sich die Frage nach der Zuverlässigkeit von Twitter-Daten, deren Repräsentativität,
Echtheit und Aussagekraft. Dabei rückten in letzter Zeit zunehmend auch (Social) Bots in den Fokus
wissenschaftlicher, politischer und medialer Debatten. Social Bots sind „Computerprogramme, die
1Bis zum ersten Quartal 2019 veröffentlichte Twitter die Zahl der mindestens einmal im Monat aktiven Nutzer (Monthly Active
Users – MAU). Der Wert lag bei etwa 330 Millionen Benutzern. Seit Mitte 2019 gibt Twitter nur noch die Anzahl
monetarisierbarer täglich aktiver Nutzer an (mDAU), also derer, denen Werbung angezeigt werden kann. Zum Vergleich:
Diese lag im ersten Quartal 2019 bei 134 Millionen.
2 Unter der politischen Twittersphäre (engl. twittersphere) versteht man im Allgemeinen die Gesamtheit politischer und
politisch aktiver Twitter-Accounts und Tweets.
1Social Bots in der politischen Twittersphäre – Identifikation und Relevanz
darauf ausgerichtet sind, in sozialen Netzwerken, beispielsweise auf Facebook oder Twitter, maschinell
erstellte Beiträge wie Kommentare, Antworten oder Meinungsäußerungen zu generieren, um Diskurse
zu beeinflussen bzw. zu manipulieren“ (Kind, Jetzke, Weide, Ehrenberg-Silies & Bovenschulte, 2017,
S. 9). 2014 berichtete Twitter, dass etwa 8,5 Prozent aller Plattform-Accounts Bots seien (Twitter Inc.,
2014, S. 3). Weitere Studien zeigten sogar Anteile von 15 (Varol, Ferrara, Davis, Menczer & Flammini,
2017) und 16 Prozent (Zhang & Paxson, 2011, S. 102). Im Jahr 2015 veranstaltete die Defense Advanced
Research Projects Agency (DARPA), eine Behörde des Verteidigungsministeriums der Vereinigten
Staaten, eigens einen vierwöchigen Wettbewerb zu Twitter-Bots, bei dem zahlreiche Teams von
Programmierern und Wissenschaftlern Ansätze zur Bot-Identifikation präsentierten (Subrahmanian et
al., 2016).
Abbildung 1: Auf Medien- und Forschungsdatenbanken erfasste Twitter-bezogene Berichterstattung
und Studien
Im Jahr 2016 befasste sich nach Berichten über den vielfachen Einsatz von Social Bots während des
Brexit-Votums und der damaligen US-Präsidentschaftswahl auch eine Expertenkommission für den
Deutschen Bundestag mit der „Untersuchung von Gefahren durch eine mögliche Manipulation
2Social Bots in der politischen Twittersphäre – Identifikation und Relevanz
politischer Diskussionen und Trends in sozialen Netzwerken“ (Kind et al., 2017, S. 7). Diese kam unter
anderem zum Ergebnis, dass Social Bots unter bestimmten Voraussetzungen, beispielsweise bei
knappen Wahlentscheidungen, politische Entscheidungsprozesse beeinflussen können, wenngleich die
Relevanz von Bots auf Twitter von Experten unterschiedlich eingeschätzt wird (Kind et al., 2017, S. 40).
Dennoch erhält das Thema vor allem im Kontext politischer Ereignisse und Krisen, wie der
Bundestagswahl 2017 (Schrader, 2016), der Europawahl 2019 (Bendiek & Schulze, 2019), der Corona-
Pandemie (Kim, 2020) und der US-Präsidentschaftswahl 2020, hohe Aufmerksamkeit. Während
manche Experten und Politiker vor einer Meinungsmanipulation warnen und sogar von
Wahlbeeinflussung sprechen, sehen andere eine Überdramatisierung aufgrund der häufig geringen
Reichweite von Social Bot Accounts und der Tatsache, dass Botschaften von Bots im alltäglichen
Informationsfluss nur einen geringen Anteil hätten (Reuter, 2019).
Die Nutzerzahl von Twitter ist im Vergleich zu anderen Social-Media-Kanälen, gerade in
Deutschland, gering (We Are Social, Hootsuite & DataReportal, 2021). Zudem gibt es Hinweise, dass
Twitter einen im Vergleich zur Gesellschaft überproportional hohen Anteil an Eliten und
Entscheidungsträgern (beispielsweise aus Politik und Wirtschaft) und höher gebildeten Menschen
aufweist (Hölig, 2018; Wojcik & Hughes, 2019). Demgegenüber steht jedoch die große Reichweite
einzelner Twitter-Akteure, deren Botschaften zusätzlich über Massenmedien multipliziert werden. Laut
einer Befragung in Deutschland im Jahr 2017 glaubten 42 Prozent an einen Einfluss von Social Bots auf
den US-Wahlkampf 2016 oder die Brexit-Kampagne (Fittkau & Maaß Consulting GmbH, 2017). In
einer Studie von PricewaterhouseCoopers (2017) gaben 37% der Befragten an, sie hätten wissentlich
oder möglicherweise Social Bots wahrgenommen.
Dabei ist das Erscheinungsbild von Social Bots sehr diffus und ihre Identifikation variiert mit dem
Grad ihrer Komplexität, Ausgereiftheit und Funktionsweise. Während alle Socials Bots eint, dass sie
menschliches (Kommunikations-)Verhalten imitieren sollen, indem sie beispielsweise bei Twitter
anderen Accounts folgen oder eigene Tweets verbreiten, agieren und wirken sie im Detail jedoch sehr
unterschiedlich. Ihre Funktion lässt sich in drei Kategorien gliedern, deren Übergang fließend verläuft,
da Bots je nach Komplexität auch mehrere Aufgaben übernehmen können. Als Überlaster überfluten
Social Bots Diskussionsstränge mit einer Vielzahl ähnlicher bis identischer Gegenaussagen, um eine
echte Diskussion zu unterbinden oder die Sichtbarkeit unerwünschter Kommentare zu minimieren. Die
Funktionsweise von Auto-Trollen ähnelt sich der von Überlastern, ist jedoch komplexer: Hier werden
einzelne Nutzer über unpassende oder beleidigende Kommentare in neue, thematisch fremde
Diskussionen verwickelt, um von der eigentlichen Debatte abzulenken. (Bundeszentrale für politische
Bildung, 2017)
Trendsetter (engl. Astroturfer) hingegen verfolgen eine simple und potenziell mächtige Strategie:
Als sogenannte Bot-Armeen, deren Größe von wenigen Accounts bis zu ganzen Netzwerken variiert,
3Social Bots in der politischen Twittersphäre – Identifikation und Relevanz
verbreiten Accounts gemeinsam innerhalb kurzer Zeit eine gleiche Botschaft oder nutzen das gleiche
Hashtag. Da Twitter momentan populäre Themen und Hashtags auflistet (sogenannte Trending
Topics/Hashtags), können koordinierte Aktivitäten tausender Bots gezielt thematische Trends setzen
und die jeweils kommunizierte Botschaft eine Bedeutung in der öffentlichen Debatte erlangen (Stieglitz,
2018). Zudem beobachten viele Medien und Politiker diese Trends, weshalb Trendsetter auch Politiker
dazu verleiten könnten, „in ihren Statements oder sogar in ihrer Politik auf solche Trends einzugehen
wodurch die Position, für die die Bots stehen, unter Umständen einen Zuspruch erhält, den die Bots
alleine nicht erreicht hätten“ (Hegelich, 2016, S. 3). Social Bots können daher als Agenda Setter agieren
(Bessi & Ferrara, 2016).
Da eine politische Beeinflussung durch Bots jedoch nur schwer nachzuweisen ist (Kind et al., 2017,
S. 30–33), befasst sich die Wissenschaft überwiegend mit der Identifikation von Bots. Die stetig
wachsende Zahl an Bot-Erkennungsverfahren unterscheidet sich jedoch stark hinsichtlich Qualität,
Komplexität und Methodik. Die von Latah (2020) erarbeitete umfassende Taxonomie bestehender
Methoden zur Erkennung von Social Bots verdeutlicht die methodische und technische Bandbreite.
Abbildung 2: Taxonomie von Bot-Erkennungsmethoden (Bildquelle: Latah, 2020, S. 6)
Die Abschätzung des Ausmaßes von Bot-Aktivität auf Twitter variiert dabei je nach Studie und
Methodik. Manche Studien identifizierten größere Cluster von Social Bots: Als einer der ersten
aufgedeckten Fälle des großvolumigen Einsatzes von Social Bots im politischen Kontext kann die
4Social Bots in der politischen Twittersphäre – Identifikation und Relevanz
Präsidentschaftswahl in Mexiko 2012 gesehen werden. Dort wurde ein Netzwerk automatisierter
Twitter-Accounts, sogenannter Peñabots3, zur Verbreitung regierungsfreundlicher Propaganda und zur
Diskreditierung und Marginalisierung regierungskritischer Meinungen in sozialen Medien eingesetzt
(Andrade, 2013). Hegelich und Janetzko (2016) ermittelten circa 15.000 Twitter-Accounts, die während
des Ukraine-Konflikts im Durchschnitt 60.000 Meldungen pro Tag verfassten und pro-russische
Propaganda verbreiteten. Laut Howard und Kollanyi (2016, S. 4) wurden etwa 14 Prozent aller Tweets
zum Brexit durch hochautomatisierte Accounts verfasst, nach Bessi und Ferrara (2016) waren während
der US-Präsidentschaftswahlkampf 2016 etwa 400.000 Bots aktiv. Ferrara, Chang, Chen, Muric und
Patel (2020) identifizierten auch im nachfolgenden US-Wahlkampf 2020 zahlreiche Bots, schätzten
deren Einfluss jedoch geringer als bei der Wahl 2016 ein.
Während es zahlreiche prominente Fälle des massenhaften Einsatzes von Social Bots gibt, die auch
in den Medien vielfach thematisiert wurden, ist die Wissenschaft uneins über das tatsächliche Ausmaß
und die Einflussmöglichkeiten von Bot-Aktivitäten auf Twitter. Kritiker bemängeln das methodische
Vorgehen einiger Studien bei der Daten-Erhebung, Identifikation und Interpretation (Assenmacher et
al., 2020; Kreil, 2019; Rauchfleisch & Kaiser, 2020). Die uneinheitliche Definition von Social Bots
erschwert die Vergleichbarkeit der Forschungsergebnisse (Gensing, 2020). Diese Fehler können dazu
führen, dass Accounts irrtümlich als Social Bots identifiziert werden (sogenannte False Positives) oder
deren Einflussbereich zu hoch eigeschätzt wird. Auch in der Expertenkommission für den Deutschen
Bundestag überwiegt die Meinung, dass von Socials Bots zwar eine Gefahr ausgehen kann, Belege einer
erfolgreichen Beeinflussung großer gesellschaftlicher Gruppen bisher aber überwiegend ausblieben
(Kind et al., 2017, S. 33).
Es stellt sich folglich die Frage nach dem Ausmaß von Bot-Aktivität auf Twitter und deren
tatsächlicher Relevanz im politischen Kontext. Die hier vorliegende Arbeit soll einen theoretisch-
methodischen Beitrag zu dieser Debatte leisten, indem sie einerseits die allgemeine wissenschaftliche
Eignung von Twitter-Daten diskutiert und schließlich anhand eines eigenen methodischen Ansatzes zur
Bot-Identifikation die Relevanz von Social Bots in der politischen Twittersphäre erörtert.
2. Vorgehen
Die erste Arbeit „What you tweet is what we get? Zum wissenschaftlichen Nutzen von Twitter‐Daten“
(Aufsatz 1) setzt sich grundlegend mit der Eignung von Twitter als wissenschaftliche Datenquelle
auseinander. Die Bewertung erfolgt anhand der Dimensionen Verfügbarkeit und Vollständigkeit,
3 In Anlehnung an den damaligen Präsidentschaftskandidaten Peña Nieto, in dessen Sinne die Bots agierten.
5Social Bots in der politischen Twittersphäre – Identifikation und Relevanz
Qualität, Sprache und Repräsentativität. Ein kritischer Aspekt ist die mangelnde Repräsentativität und
Qualität der Daten – unter anderem aufgrund der automatisierten Verbreitung von (politischen)
Botschaften durch Bots. Twitter ermöglicht zwar einen einfachen Datenzugang für wissenschaftliche
Zwecke, garantiert aber je nach Datenzugang keine Vollständigkeit der Daten. Fake-Accounts und
automatisiert verbreitete Botschaften können nicht nur Debatten auf Twitter beeinflussen, sondern auch
die Aussagekraft eines Datensatzes einschränken, wenn beispielsweise zahlreiche identische
Botschaften und Meinungen eines einzelnen gesteuerten Accounts oder einer Gruppe den Datensatz
dominieren.
Daher widmet sich die Studie „Was bin ich – und wenn ja, wie viele? Identifikation und Analyse von
Political Bots während des Bundestagswahlkampfs 2017 auf Twitter“ (Aufsatz 2) ausführlich der
Identifikation und Aktivität von Social Bots auf Twitter. Nach einem Überblick verschiedener Aufgaben
und Funktionen von Bots sowie der Forschung zu Bots soll anhand eines eigenen, zweistufigen
methodischen Ansatzes überprüft werden, ob eine Aktivität von Social Bots im politischen Kontext
nachgewiesen werden kann. Um das Ausmaß von Bot-Aktivität auf Twitter zu messen, wird während
der Bundestagswahl 2017 – als einem politischen Großereignis – ein computerlinguistischer4 zu Ansatz
zur Bot-Identifikation mittels Nahduplikat-Analyse angewandt. Dieses Verfahren ermittelt verdächtige,
möglicherweise automatisierte Accounts anhand ihres Anteils jeweils inhaltlich ähnlicher Tweets und
basiert auf der Annahme, dass Nutzer, die häufig nahezu identische Inhalte verbreiten, mit hoher
Wahrscheinlichkeit automatisiert sind. In einem zweiten Schritt erfolgt schließlich eine manuelle
quantitative und qualitative Sichtung und Bewertung dieser ermittelten Accounts anhand ihrer
verbreiteten Inhalte und ihres Tweet-Verhaltens.
Um die Ergebnisse aus Aufsatz 2 zu validieren, wird in der Folgestudie „The overestimated danger?
Twitter bots in the 2019 European elections campaign“ (Aufsatz 3) das methodische Verfahren im
Kontext der Europawahl 2019 erneut angewendet, jedoch um die Identifikation von Account-Clustern
ergänzt, die jeweils nahezu identische Inhalte verbreiten. Diese methodische Erweiterung erlaubt nicht
nur individuelle Aussagen über Accounts, sondern auch Aussagen über die Existenz von Account-
Netzwerken, die jeweils gleiche oder sehr ähnliche Tweets verbreiten. Zudem berücksichtigt die
Analyse nicht mehr nur deutschsprachige Tweets, sondern auch englischsprachige. Die gesonderte
Betrachtung beider Sprachen kann datenspezifische Fehlerquellen ausschließen (wie sprachenbezogene
Probleme bei der Nahduplikat-Analyse) und ermöglicht andererseits Aussagen über etwaige
länderspezifische Unterschiede.
4 Der Taxonomie von Abbildung 2 folgend sind computerlinguistische Ansätze Teil des Natural Language Processing.
6Social Bots in der politischen Twittersphäre – Identifikation und Relevanz
3. Ergebnisdiskussion
Aufsatz 1 setzte sich mit der grundlegenden Frage auseinander, inwieweit Twitter-Daten überhaupt für
wissenschaftliche Analysen geeignet sind und welche sie bei der Analyse gesellschaftlicher, politischer
oder wirtschaftlicher Phänomene spielen können. Die kritische theoretisch-methodische Betrachtung
hebt mehrere problematische Aspekte hervor: Grundsätzlich lassen sich Twitter-Daten relativ einfach
erheben, allerdings besteht unter bestimmten Umständen (Großereignissen mit einer sehr hohen Tweet-
Aktivität) das Risiko, nicht alle der verbreiteten Tweets zu erfassen. Dies lässt sich jedoch mit
komplexeren Erhebungsmethoden oder gekauften Datensätzen umgehen. Zudem spielt dieses Problem
der Daten-Deckelung nur bei der Betrachtung von Großereignissen oder sehr populären Themen eine
Rolle. Ein weiteres Problem ist die geringe Repräsentativität der Nutzer-Zusammensetzung auf Twitter.
Mehrere Studien verweisen nicht nur auf die vergleichsweise geringen Nutzerzahlen, sondern auch auf
eine hinsichtlich Bildungsstand, Interessen und Alter nicht mit der Gesamtbevölkerung vergleichbare
Nutzerstruktur (Hölig, 2018; König & König, 2018; Wojcik & Hughes, 2019). Eine größere
Herausforderung stellen jedoch die Unvollständigkeit und Qualität der übermittelten Daten dar, zu
denen Twitter keine genauen Angaben macht. So fehlen beispielsweise nutzerspezifische Merkmale
(wie Alter, Geschlecht und Nationalität). Eine inkonsistente Hashtagnutzung (z.B. mit
themenbezogenen Tweets ohne Hashtag) und ein oft fehlender Konversationszusammenhang
erschweren die Analyse zusätzlich. Ein großes Problem stellt die geringe Daten-/Nutzerauthentizität dar,
die sich von bewussten Falschangaben (wie Name oder Standort) bis hin zu Fake-Accounts und
gesteuerten Accounts (Bots) erstreckt. Dies verschlechtert die Repräsentativität zusätzlich.
Einige der im ersten Aufsatz kritisierten Punkte wurden mittlerweile von Twitter überarbeitet, um
insbesondere die Nutzung von Twitter als wissenschaftliche Datenquelle zu vereinfachen und zu fördern
(Tornes & Trujillo, 2021). So aktivierte das Unternehmen im Juli 2020 eine neue Version ihrer API und
ermöglicht nun beispielsweise Wissenschaftlerinnen und Wissenschaftlern einen „Academic Research“-
Zugang, der nicht nur einen umfangreicheren Datenzugang in Bezug auf Zeitraum und Datenvolumen
ermöglicht, sondern auch eigens kuratierte, große Datensätze zu bedeutenden Ereignissen (wie der
Corona-Pandemie) zur Verfügung stellt (Cairns & Shetty, 2020; Twitter Inc., 2021a). Zudem geht
Twitter mittlerweile verstärkter und transparenter gegen Fake-Accounts und Bots vor (Roth & Pickels,
2020; Twitter Inc., 2021c).
Aufgrund der Tatsache, dass der Zugriff für Forschende mittlerweile deutlich verbessert und das
Vorgehen gegen Socials Bots intensiviert wurde, können Twitter-Daten eine gute und in manchen
Fällen, wie bei der Beobachtung gesellschaftlicher Phänomene, auch sehr sinnvolle Basis für Studien
sein. Allerdings nur unter Berücksichtigung der weiterhin vorhandenen Einschränkungen und
Kritikpunkte, wie der mangelnden Repräsentativität und Validität der Daten. Die Zahl der Ansätze zur
7Social Bots in der politischen Twittersphäre – Identifikation und Relevanz
Bot-Identifikation und deren Komplexität nimmt zwar kontinuierlich zu, was nicht nur die gesammelten
Daten besser bereinigen lässt, sondern auch eine neue (Teil-)Disziplin in der Forschung geschaffen hat.
Es gibt aber dennoch ein „Wettrüsten“ (Cresci, Di Pietro, Petrocchi, Spognardi & Tesconi, 2017, S. 963)
zwischen Entwicklern und Nutzern von Algorithmen zur Steuerung von Accounts einerseits und den
Entwicklern von Identifikationsmethoden und Social Media Plattformen andererseits. Dabei besteht
jedoch auch die Gefahr, mit hochtechnisierten, vollautomatischen Bot-Erkennungsmethoden auch echte
Nutzer als Social Bots zu klassifizieren (Rauchfleisch & Kaiser, 2020), da sich ihr Verhalten dessen
automatisierter Accounts ähnelt oder von einem typischen menschlichen Verhalten abweicht.
Der in Aufsatz 2 angewandte mehrstufige Identifikationsmechanismus versucht daher, dieses
Problem der false positives zu minimieren. Zwar erfolgt auch bei diesem Ansatz zunächst eine
computergestützte Selektion „verdächtiger“ Accounts, allerdings werden diese nicht direkt als Social
Bots klassifiziert, sondern einer weiteren, manuellen Analyse unterzogen. Dies ermöglicht eine
detailliertere Betrachtung, nicht nur deren Tweet-Verhaltens, sondern auch deren Vernetzung und
Account-Details. Der Analysefokus lag bei dieser Studie auf deutschsprachigen Tweets. Zumeist
analysierten bisherige bot-bezogene Studien politische Ereignisse in den USA (oder Großbritannien).
Gerade in den USA herrscht jedoch ein weitgehend polarisiertes Politik- und Medienumfeld vor, Wahlen
gehen häufig sehr knapp aus. In diesem dynamischen Umfeld können Social Bots bei einem
„politische[n] Kulminationspunkt“ (Kind et al., 2017, S. 36), wie einer knappen Wahlentscheidung,
politische Entscheidungsprozesse beeinflussen. In dieser Studie wurde daher mit der Bundestagswahl
2017 bewusst ein anderer politischer Kontext gewählt, um auch abseits sehr knapper politischer
Entscheidungen nach Bot-Aktivitäten zu suchen.
Die hier genutzte computerlinguistische Methode zur Identifikation mittels Nahduplikat-Analyse auf
Account-Ebene (also die individuelle Betrachtung der Nutzer ohne deren inhaltlicher Vernetzung mit
anderen Accounts) ist aufgrund ihrer Simplizität weniger effektiv als die ungleich komplexeren
Machine-Learning-Ansätze. Schließlich ignoriert der Ansatz andere Wirkungsmechanismen abseits der
Verbreitung jeweils ähnlicher Tweets, wie das massenweise Retweeten von Botschaften, um deren
Reichweite und Sichtbarkeit zu erhöhen. So besteht zwar die Möglichkeit, aus einen großen Datensatz
einzelne auffällige Accounts zu identifizieren und diese einer detaillierten Betrachtung zu unterziehen.
Die Selektion dieser Accounts über deren individuellen Nahduplik-Anteil kann jedoch zu
eindimensional sein.
Daher erweitert Aufsatz 3 den Selektions- und Analyseprozess auf die Tweet-Ebene, um auch
Aussagen darüber treffen zu können, ob es Account-Netzwerke gibt, die jeweils ähnliche oder identische
Tweets verbreiten. Der thematische Kontext, die Europawahl 2019, erlaubt zudem eine Erweiterung des
Analysefokus um englischsprachige Tweets, um korpus- und sprachenspezifische Effekte
8Social Bots in der politischen Twittersphäre – Identifikation und Relevanz
auszuschließen. Da sich Aufsatz 2 auf rein deutschsprachige Tweets beschränkte, besteht die Gefahr
unbekannter, sprachenspezifischer Einflüsse, zum Beispiel auf die Datenqualität (deutschsprachige
Datensätze zu einem Thema sind zumeist kleiner als englischsprachige, da viele Nutzer für eine größere
Reichweite auf Englisch twittern) oder die Datenverarbeitung (unterschiedliche Größe der Wortschätze;
unterschiedliche Eignung von Verarbeitungsprogrammen für bestimmte Sprachen). Das in beiden
Studien für die Vorverarbeitung genutzte Softwarepaket zur Tokenisierung und Satztrennung, SoMaJo
(Proisl & Uhrig, 2016) wurde jedoch speziell für deutsch- und englischsprachige Internet- und Social
Media-Texte entwickelt, weshalb zumindest die Wahrscheinlichkeit einer methodischen
sprachenspezifischen Beeinflussung der Daten durch deren Vorverarbeitung gering erscheint.
Beide Studien deckten einzelne, in Bezug auf ihren Umfang und ihre Reichweite begrenzte Versuche
der Einflussnahme auf politische Debatten auf. Insgesamt gab es jedoch nur schwache Hinweise auf
umfangreiche Aktivitäten von Social Bots im Sinne der Verbreitung politischer Botschaften und der
Beeinflussung von Meinungen. Die Mehrzahl der identifizierten, hochwahrscheinlich automatisierten
Accounts hatte nur eine geringe Reichweite. Die zwei Analysen mit jeweils begrenzten Stichproben
lassen zwar keine Verallgemeinerung zu, geben jedoch Hinweise einer möglicherweise allgemeinen
Überschätzung der Bedeutung von Social Bots hinsichtlich deren Reichweite und Einflussmöglichkeiten
im politischen Kontext.
Laut Assenmacher et al. (2020) weisen viele eingesetzte Bots nur eine simple Funktionsweise auf,
wogegen (Cresci, 2020, S. 72) vor zunehmenden Auswirkungen von Bots auf die Gesellschaft warnt:
„[W]e witnessed […] the emergence of a strident dissonance between the multitude of efforts for
detecting and removing bots, and the increasing effects these malicious actors seem to have on our
societies”. Bot-Identifikationsmethoden werden in der Tat immer multidimensionaler und komplexer
und analysieren mittlerweile neben Account-Eigenschaften, verbreiteten Inhalten sowie Kontakt- und
Interaktionsnetzwerken sogar die Session-Aktivität5 von Twitter-Nutzern, um ein mögliche Steuerung
durch künstliche Intelligenz zu erkennen (Pozzana & Ferrara, 2020).
Insgesamt stellt sich jedoch die Frage, ob die mittlerweile teils hochkomplexen
Identifikationsverfahren, die zum Erkennen angeblicher künstlicher Intelligenz (KI) benötigt werden,
keine Socials Bots identifizieren, sondern womöglich Menschen. Die in Aufsatz 2 und 3 vollzogenen
Analysen deckten auf, dass einige, zunächst hinsichtlich ihres Tweet-Verhaltens (Aktivität, Tweet-
Häufigkeit, Inhalt) auffällige Accounts, von (politisch) hochmotivierten und hochaktiven Menschen
genutzt wurden. Hinter größeren Account-Clustern mit identischen Tweets standen zumeist konzertierte
5
Unter der Session-Aktivität versteht die gesamte Account-Aktivität zwischen dem Zugriff auf das eigene Twitter-
Profil und dem Verlassen der Plattform.
9Social Bots in der politischen Twittersphäre – Identifikation und Relevanz
Online-Aktionen, bei denen Menschen eine Teilen-Funktion mit vordefinierter Botschaft nutzen. Ein
wirkungsvollstes Mittel der Beeinflussung von Debatten, das massenhafte Verbreiten gleicher
Botschaften, bedarf also nicht unbedingt einer ausgeklügelten KI, sondern nur motivierter Menschen.
Dies deckt sich mit den Ergebnissen einer Studie im Kontext des Bundestagswahl 2017, die sich mit
zahlreichen inoffiziellen Unterstützer-Accounts der AfD befasste, welche gezielt Werbung für die Partei
machten: Demnach „waren es keine Roboter, die diese Armee von pseudonymen Accounts bedienten,
sondern echte Personen“ (Reuter, 2019). Auch Kreil (2019) ermittelte bei der nachträglichen
Betrachtung von Bot-Studien zahlreiche falsch-positiv identifizierte Bots, hinter denen in Wirklichkeit
politisch motivierte Menschen steckten. In diesem Zusammenhang bleibt folglich auch die Frage offen,
ob nicht von hochmotivierten und hochaktiven Menschen eine größere Gefahr als von Bots ausgeht.
Die gewonnenen Erkenntnisse dieser Arbeit sollten als Anstoß für eine differenzierte Betrachtung
von Social Bots, deren Identifikation und Relevanz dienen. Social Bots haben zweifelsohne das
Potenzial, Debatten und Stimmungsbilder zu beeinflussen. So zeigten auch Ross et al. (2019), dass
bereits eine niedrige Zahl von Bots (Auto-Tolls, Überlaster) genügt, um Nutzer in einer kontroversen
Diskussion zum Schweigen zu bringen. Dadurch stiege die Wahrscheinlichkeit, dass sich die von den
Bots gestützte Meinung durchsetzt, von 50 Prozent auf circa zwei Drittel. Dies würde ein falsches
Stimmungsbild vermitteln. Auch bei der Verbreitung von Fake News spielen Social Bots eine große
Rolle (Shao et al., 2018). Betrachtet man das Phänomen der Social Bots aber im medialen, politischen
und gesellschaftlichen Gesamtkontext, ist Twitter zwar eine in der Politik populäre
Kommunikationsplattformen, aber dennoch nur eine von vielen. Die zunehmende Debatte über Social
Bots stärkt zudem das Bewusstsein in der Gesellschaft über deren Existenz und Wirkungsweise.
Viele Studien differenzieren bei der Bot-Identifikation nur zwischen zwei Klassen: zwischen
(wahrscheinlichen) Social Bot und (wahrscheinlich) durch Menschen gesteuerten Accounts. Dies
ignoriert jedoch das eigentliche Kontinuum zwischen intelligenten, autonom handelnden KIs und
Menschen. Zwischen diesen beiden Extremen lassen sich – zusammengefasst unter der Bezeichnung
„Cyborg“ – verschiedenste Anwendungsfälle der Teil-Automatisierung eingliedern, wie beispielsweise
Menschen, die ihren Twitter-Account unter Beihilfe von Programmen nutzen. Eine zentrale Frage im
Kontext der Diskussion über die Identifikation und Reichweite von Social Bots betrifft daher die
technische Definition. Wann ist ein Account ein Social Bot? Wenn dahinter eine ausgeklügelte,
hochintelligente künstliche Intelligenz steht? Wenn Nutzer automatisch Inhalte eines anderen Accounts
retweeten? Wenn die Veröffentlichung von Inhalten zeitlich geplant wird? Oder wenn ein Account Teil
eines von Menschen gesteuerten Netzwerks ist? Die starke Verflechtung von menschlicher und
computergenerierter Aktivität verhindert eine trennscharfe Betrachtung von (teil-)automatisierter
Twitter-Aktivität. In letzter Zeit taucht mit sogenannten „Fake-Influencern“ zudem ein neues Instrument
zur Beeinflussung politischer Debatten und öffentlicher Meinungen auf. Dies sind nicht real existierende
10Social Bots in der politischen Twittersphäre – Identifikation und Relevanz
Persönlichkeiten, die von einer oder mehreren Personen erschaffen und koordiniert werden, einen
menschliche Identität vortäuschen und aktiv mit anderen Nutzern interagieren (Reuter, 2017; Shane,
2017; Xia et al., 2019). Populäre Beispiele sind „Jenna Abrams“, eine nichtexistierende, russische
Propaganda verbreitende junge Amerikanerin, deren Account jedoch aus Russland gesteuert wurde,
sowie ein Konto mit dem Namen „Balleryna“, das sich im Kontext der Bundestagswahl 2017 als
deutsch-russische 17-Jährige ausgab, später aber zu einem AfD-Fan-Account wurde. Hinter beiden
Accounts steckte jedoch keine künstliche Intelligenz, sondern menschliche.
11Social Bots in der politischen Twittersphäre – Identifikation und Relevanz
12Social Bots in der politischen Twittersphäre – Identifikation und Relevanz
Aufsatz 1:
What you tweet is what we get? Zum wissenschaftlichen
Nutzen von Twitter‐Daten
von Fabian Pfaffenberger
Veröffentlicht:
Pfaffenberger, F. What you tweet is what we get? Publizistik 63, 53–72 (2018). Abrufbar unter:
doi:10.1007/s11616-017-0400-2
13Social Bots in der politischen Twittersphäre – Identifikation und Relevanz
14Social Bots in der politischen Twittersphäre – Identifikation und Relevanz
Aufsatz 2:
Was bin ich – und wenn ja, wie viele?
Identifikation und Analyse von Political Bots während des
Bundestagswahlkampfs 2017 auf Twitter
von Fabian Pfaffenberger, Christoph Adrian und Philipp Heinrich
Veröffentlicht:
Pfaffenberger F., Adrian C., Heinrich P. (2019) Was bin ich – und wenn ja, wie viele?. In: Holtz-
Bacha C. (Hg.). Die (Massen-)Medien im Wahlkampf. Springer VS, Wiesbaden. Abrufbar unter:
doi:10.1007/978-3-658-24824-6_5
Koautoren:
Christoph Adrian (Anteil: 40%) wissenschaftlicher Mitarbeiter am Lehrstuhl für
Kommunikationswissenschaft an der Friedrich-Alexander-Universität Erlangen-Nürnberg.
Masterstudium der Sozialökonomik mit den Schwerpunkten Medien-, Markt- und Sozialforschung.
Forschungsschwerpunkte: Computational Methods, Umweltkommunikation und Politische
Kommunikation.
Philipp Heinrich (Anteil: 10%) ist wissenschaftlicher Mitarbeiter am Lehrstuhl für Korpus- und
Computerlinguistik der Friedrich-Alexander-Universität Erlangen-Nürnberg. Zu seinen
Forschungsschwerpunkten zählen die automatische Verarbeitung von Daten aus sozialen Medien
sowie die methodologische Weiterentwicklung korpusbasierter Diskursanalyse. Sein
Promotionsprojekt beschäftigt sich mit der Erforschung der transnationalen algorithmischen
15Social Bots in der politischen Twittersphäre – Identifikation und Relevanz
16Social Bots in der politischen Twittersphäre – Identifikation und Relevanz
Aufsatz 3:
The overestimated danger?
Twitter bots in the 2019 European elections campaign
von Fabian Pfaffenberger und Philipp Heinrich
Dieser Beitrag ist bereits in deutscher Fassung erschienen:
Pfaffenberger F., Heinrich P. (2020). Die überschätzte Gefahr? Twitter-Bots im Europawahlkampf
2019. In: Holtz-Bacha C. (Hg.) Europawahlkampf 2019. Springer VS, Wiesbaden. doi:10.1007/978-3-
658-31472-9_4
Koautor:
Philipp Heinrich (Anteil: 25%) ist wissenschaftlicher Mitarbeiter am Lehrstuhl für Korpus- und
Computerlinguistik der Friedrich-Alexander-Universität Erlangen-Nürnberg. Zu seinen
Forschungsschwerpunkten zählen die automatische Verarbeitung von Daten aus sozialen Medien
sowie die methodologische Weiterentwicklung korpusbasierter Diskursanalyse. Sein
Promotionsprojekt beschäftigt sich mit der Erforschung der transnationalen algorithmischen
Abstract:
In light of the debate about the relevance and outgoing danger of social bots in the political context,
this paper investigated whether there was any notable activity of automated Twitter accounts in the
context of the 2019 European election. The analysis refers to German- and English tweets from the
crucial phase of the European elections campaign and uses a multi-stage identification and validation
procedure for bot-like activities. The study does not solely rely on parameter-based methods, as many
other bot classification studies do, but uses a content-based near-duplicate detection algorithm to
identify suspicious Twitter accounts (with a high proportion of near duplicates). Overall, this study
could not identify any bot networks or clusters of accounts, which likely are automated and show a
significant activity in terms of spreading political messages or influencing debates in the context of the
European elections. This raises the question of whether the importance and influence of social bots are
overestimated.
17Social Bots in der politischen Twittersphäre – Identifikation und Relevanz
1. Introduction
Between the “reality of digital public spheres” (Klinger, 2019) and “The army that never existed” (Kreil,
2019) - in the media-led debate, not only journalists but also academics and politicians discuss “the
problem with social bots” (Gensing, 2020). Social bots are accounts controlled by computer programs
that mimic a human identity, communicate like humans, and can thus also be used for manipulative
purposes (Kind et al., 2017). On the one hand, the public debate deals with the danger posed by social
bots through their dissemination of fake news, influence on opinions or defamation of political
opponents - and on the other hand, it also raises elementary questions. In particular, the recent discussion
between political scientist Simon Hegelich and media computer scientist Florian Gallwitz as well as
data analyst Michael Kreil in the context of an expert survey for the Enquete-Kommission KI des
Deutschen Bundestages (“Enquete Commission on AI of the German Bundestag”) illustrates the
disagreement among academics about the relevance or even existence of social bots in the political
context (Gallwitz, 2020a, 2020b; Hegelich, 2020a, 2020b).
Especially with regard to the intense debate about the use of social bots for influencing debates,
agenda setting, or spreading spam and fake news in social media, the negative connotation of the term
bot often prevails. Although social bots are popular use cases and are subject to correspondingly
intensive scientific analysis, the actual multifunctionality of bots in general often goes unnoticed. This
is because there are versatile uses for bots that are not subject to morally or ethically questionable
intentions: Particularly on Twitter, many news organizations use bots that automatically tweet all or
parametrically selected news (for example, breaking news or headlines from the business section) and
link to the actual news story (BBC News Labs, 2019). Another use case for bots in journalism is the so-
called robojournalism (Lokot and Diakopoulos, 2016), where a (partial) automation of news reporting
is carried out by news bots, which, for example in local sports, process simple and pre-structured
information into short news reports. The automatic dissemination of information by bots, when they
share satellite images from an ESA satellite, for example, like @sentinel_bot, is also not subject to bad
intentions, but serves the purpose of information dissemination.
Undoubtedly, however, there are a variety of ethically, legally, or at least morally questionable uses
for bots. While the use of social bots to influence opinions or spread fake news is only one of many use
cases, it is at the center of scientific and media considerations. In the run-up to the 2019 European
elections, as well as before the 2017 German parliamentary elections, there were discussions about the
risk of influencing voting behavior (Graff, 2017; Tagesschau, 2019) or its relativization (Lypp, 2017;
Reuter, 2019). However, there is undoubtedly the question, to what extent automated accounts are active
on Twitter and whether there is any significant activity at all in the widely discussed political context.
18Social Bots in der politischen Twittersphäre – Identifikation und Relevanz
This study aims to contribute to the already extended debate and analyzes whether there was any
notable activity of automated Twitter accounts in the context of the 2019 European elections. For this
purpose, relevant tweets were collected during the crucial phase of the European elections campaign
and analyzed for bot-like activity using a multi-stage identification and validation procedure. The study
does not solely rely on parameter-based methods, as many other studies on bot classification do, but
uses a content-based near-duplicate detection algorithm to identify conspicuous Twitter accounts (with
a high proportion of near duplicates). These pre-selected accounts are subjected to a manual qualitative
analysis in the second step. This aims to check whether there are conspicuous accounts with a high near-
duplicate rate in the data set that disseminated political content, and how large their share of the total
data set is. However, the observation of near duplicates and their distribution not only allows the
identification of suspicious accounts, but also allows statements about the distribution of similar
messages. Thus, account groups can also be identified, each of which disseminates exact duplicates or
slight variations of a tweet. Therefore, this study will also investigate whether there are account clusters
that shared similar messages.
2. Social Bots ‐ definitions and classifications
Various works have already dealt with an overview and categorization of types, characteristics, and
possible uses of bots (see, among others, Gorwa & Guilbeault, 2018; Pieterson et al., 2017; Stieglitz et
al., 2017b). At first, it was mainly classic spambots that were studied. But in the last years, social bots
as well as sockpuppets and trolls have received a lot of attention from the scientific community. The
definition and interpretation of social bots varies with the intended use: the term socialbot used in the
early phase of bot research describes automated accounts that mimic a fake identity, infiltrate real users'
networks, and spread malicious links or advertisements (Boshmaf et al., 2011). This is also often referred
to as sybils (Alarifi et al., 2016, p. 1). The term social bot (with two words) is in turn a broader and more
flexible concept and includes programs that automatically produce content, interact with people on
social media, and attempt to mimic and potentially change their behavior (Ferrara et al., 2016, p. 2). The
imitation of human identities and activities plays an increasing role (Abokhodair et al., 2015, p. 13;
Hegelich & Janetzko, 2016, p. 582; Stieglitz, Brachten, Berthelé et al., 2017a, p. 381), also to actively
influence the public prioritization and evaluation of issues (Graber & Lindemann, 2018).
The term sockpuppet is another similar term in the context of bots. It is often used for accounts with
fake identities that interact with other users on social networks under this disguise. Here, the term
includes both automated accounts and accounts controlled by humans (Bastos & Mercea, 2019, p. 2).
Politically motivated sockpuppets are often referred to as trolls, especially when coordinated by
politicians or interconnected actors (Gorwa & Guilbeault, 2018, p. 233).
19Social Bots in der politischen Twittersphäre – Identifikation und Relevanz
Overall, the lines between bots and human-controlled accounts are increasingly blurred. Terms such
as cyborgs and hybrid accounts circumscribe user accounts that fall along the continuum between bot-
assisted humans and human-assisted bots (Chu et al., 2012, p. 811). Bot-assisted humans refer to people
who use their Twitter account with the support of programs, for example, to automatically share news
from a particular RSS feed. Human-assisted bots in turn are algorithms that are controlled by humans
and depend on recurring commands or parameter inputs. An example of such partial automation would
be a bot that identifies popular hashtags from which a controlling person selects suitable ones and the
bot in turn uses these as the basis for automatically generated and distributed messages. A precise
classification of accounts is often difficult: the question of whether, for example, 500 tweets of an
account per day indicate automation or a very active user, or if this person uses utilities to control the
account can rarely be answered at first glance. This obviously also has a negative impact on the quality
and reliability of automatic bot detection methods.
The multidimensionality of bots, not only in their functions but also in the degree of automation, is
equally reflected in the variety and heterogeneity of approaches on bot identification. These range from
simple, quantitative approaches based on single indicators to complex machine learning-based
classification algorithms. One example of simple, quantitative bot classification is the so-called Oxford
Rule, which is as popular as it is controversial and defines in general accounts with more than 50 tweets
per day as bots (Howard & Kollanyi, 2016, p. 4). Other studies are based on more complex algorithms
that classify (social) bots (Ahmed & Abulaish, 2013; Loyola-Gonzalez et al., 2019; Miller et al., 2014)
or sockpuppets (Bu et al., 2013) based on various parameters. However, a large number of the
approaches use machine learning algorithms (Alarifi et al., 2016; Cai et al., 2017; Chu et al., 2012; Davis
et al., 2016; Daya et al., 2019; Ratkiewicz et al., 2011; van der Walt & Eloff, 2018; Varol et al., 2017;
Yang et al., 2019), most of which analyze and weight multiple characteristics (features) of accounts as
well as their network and tweets, put them in a temporal context, and determine bot likelihood based on
them.
The majority of bot detection (solely) approaches rely on parameter-based analyses, whereas the
actual content of a tweet is often ignored or the analysis rarely goes beyond the frequency of certain
terms (for example, based on part-of-speech tags), the tweet length, or the information content of
messages (Alarifi et al., 2016; Varol et al., 2017). Solely focusing on quantitative features can be very
helpful, especially for very large or ad hoc analyses, as they can usually be done faster and without
human assistance. Nevertheless, especially the shared content can be of particular interest - if one does
not only want to detect bots, but also analyze their spread messages. In addition, there is another
possibility/dimension of bot identification via the tweets’ content: While many approaches categorize
accounts only based on their individual statistics (e.g., tweet frequencies, number of followers) and thus
classify individually, content-based analyses make it possible to look at entire account groups that share
20Social Bots in der politischen Twittersphäre – Identifikation und Relevanz
similar content and that would have been inconspicuous if looked at individually. This also makes it
possible to detect accounts that act as a coordinated network/cluster and only then appear as bots. On
the one hand, the constant repetition of certain messages can cause opposing opinions to be drowned
out by the sheer masses or intimidate their authors (Lypp, 2017). On the other hand, account networks
can also act as amplifiers for messages and mimic a grassroots movement (Woolley, 2016).
The study presented here is therefore based on a corpus linguistic approach by Schäfer et al. (2017)
to identify suspicious accounts. The underlying methodology relies on the identification of near
duplicates (tweets with identical or nearly identical content), linked to the assumption that users who
frequently or predominantly disseminate similar content are very likely automated. This approach was
already used in an earlier study on the German parliamentary elections in 2017 and extended by a manual
analysis of conspicuous accounts (Pfaffenberger et al., 2019). However, the study at that time focused
only on accounts with a high proportion of near duplicates. In order to also identify groups of accounts
that have a low proportion of near duplicates and appear unsuspicious when viewed individually, but
share similar messages as a group, the present study also considers near duplicate clusters.
3. Methodology
When identifying and analyzing (social) bots based on a Twitter dataset, the method of data collection
is crucial. There are basically two gratuitous interfaces available: The streaming API and the REST
APIs. In this case, only real-time data collection using the Twitter Streaming API (statuses/filters) is
suitable, even though there is a risk of capping the data stream due to rate limits. However, with ex-post
data collection using the REST APIs, it would be likely that tweets/accounts that were deleted or blocked
by Twitter in the meantime would be missing from the dataset. Since this study aims to identify and
analyze bots, it is these accounts/tweets that are of particular interest.
The analysis dataset consists of tweets collected using a Python script between March 18 and May
30, 2019 via the Streaming API (statuses/filter)6. Contextually common terms during the European
election, such as EP2019 and Europawahl2019, served as filters. The search was not limited to solely
German terms, but also included English, Spanish and French terms in order to cover the European
election debate on Twitter as comprehensively as possible. The full list of search terms can be found in
the appendix. After the data collection was completed, the collected tweets were split into separate
datasets based on their language7 to allow for comparisons between languages. The study examines
tweets in German and English. The adjusted German-language dataset includes 345,543 German tweets
6
Due to a connection error to the API, not all tweets could be captured between April 11 and 13.
7
Twitter automatically detects the (dominant) language of a tweet and returns it as tweet entity lang.
21Social Bots in der politischen Twittersphäre – Identifikation und Relevanz
from 85,389 accounts, and the English-language dataset includes 677,562 English tweets from 203,793
accounts.
In addition, there was a subsequent enrichment of the recorded accounts (hydration) with further
information: Using the Python library twtoolbox (hhromic, 2016), current account data such as activity
values and account statuses were collected in December 2019. The large time interval between data
collection and enrichment thus provided insights into accounts that have since been suspended or
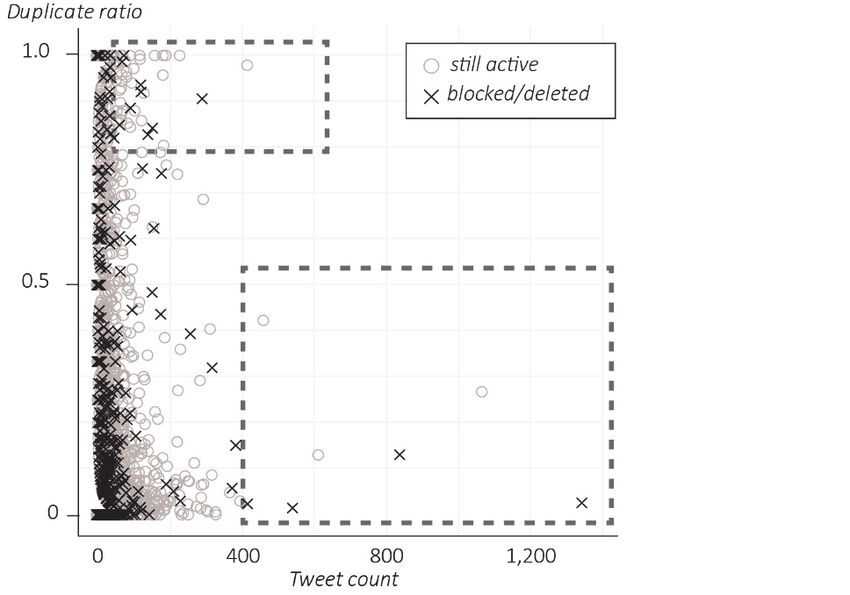
deleted. This information is an important clue for the scoring of an account: Deletion or blocking on the
part of Twitter indicates that these user accounts were spreading spam or offensive tweets or exhibited
other abusive behavior8 (Twitter Inc., 2020).
Figure 1: Number of captured German tweets and corresponding accounts over time
Looking at the frequency of tweets over time expectedly shows a clear peak in data near the election
weekend. The daily number of German-language tweets in the dataset (Figure 1) increases almost
constantly from mid-April towards the election phase, with the majority of 62,933 tweets written on the
German election day (May 26). Immediately after the election, the number of tweets drops again
significantly. The small peak on March 26, 2019, can be attributed to the debate in the European
Parliament in Strasbourg with its decisions to abolish the time changeover and the adoption of the
copyright reform. Relatively analogous is the number of creator accounts in the dataset, i.e., the number
of different user accounts per day.
To investigate whether and to what extent social bots were active in this extract of the global Twitter
activity of the European election, detailed analyses at the tweet and account level are required. As
described in Chapter 2, there are now numerous, sometimes strongly differing approaches to identifying
8
Abusive behavior contradicts the rules of conduct, according to Twitter: https://help.twitter.com/en/rules-and-
policies/twitter-rules.
22Social Bots in der politischen Twittersphäre – Identifikation und Relevanz
and analyzing (social) bots. The following analysis is based on Schäfer, Evert, and Heinrich's (2017)
approach of grouping tweets into clusters based on their similarity using near-duplicate detection, which
was already applied to study social bot activities during the 2017 German federal election campaign
(Pfaffenberger et al., 2019). On the one hand, the distribution of near duplicates provides information
about the share of similar tweets of an account (i.e., its variation in content); on the other hand,
statements can be made about whether there are account networks in the dataset that each disseminate
the same or similar tweet. This computational linguistic approach via near duplicates does not use
quantitative metrics for bot detection, such as tweet activity, frequency, or account networking, but is
initially based on text analysis.
The tweets of interest were pre-processed for analysis in three steps: First, the message text of each
tweet was tokenized using SoMaJo9, i.e., broken down into individual words, punctuation marks, and
emoticons (e.g., “Hello World!” into “Hello” – “World” – “!”). And then normalized. This processing
step removes all punctuation, spaces and special characters (including @ and #) contained in the tweet,
as well as URLs, mentions and retweet markers. Since many simple bots only vary the tweet text slightly
or, for example, only modify an attached URL or the addressed user (Mention), it is useful to look at the
simplified, cleaned tweets. Finally, the last step was duplicate detection. For this, each normalized tweet
was assigned a hash value derived from the generated word bundle of a tweet. Tweets with an identical
hash value (i.e., hash duplicates) are referred to as near duplicates because the tweets are no longer in
their raw state but in a very simplified word bundle. Table 1 illustrates the underlying logic. Near
duplicates were each assigned to their own cluster and classified based on their duplicate status: unique
(no duplicate), first (temporally first tweet in a series of near duplicates), nduplicate (all other similar
tweets within the clusters).
Table 1: Underlying logic of pre-processing
Tweet time Text Status before Normalized Text Status after
cleanup cleanup
Day X, 12:00pm @userX only fake news only fake news first
Day X, 12:10pm It is all fake news!! It is all fake news unique
Day X, 12:30pm only fake news! only fake news nduplicate
duplicate
Day X, 12:21pm only fake news! only fake news nduplicate
Day Y, 11:00am @userY only fake news! only fake news nduplicate
9
SoMaJo (Proisl & Uhrig, 2016) is a software package for tokenization and sentence separation that was developed
specifically for German- and English-language Internet and social media texts.
23Sie können auch lesen

















































