TwiNex - News Extraction for Twitter
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
TwiNex – News Extraction for Twitter
Bachelorarbeit
Technische Universität Dresden
Februar 2013
Stefan Herrmann
Betreuer: Dipl.-Medieninf. Philipp Katz
Hochschullehrer: Prof. Dr. rer. nat. habil. Dr. h. c. Alexander Schill
Fakultät Informatik
Institut für Systemarchitektur
Professur für Rechnernetze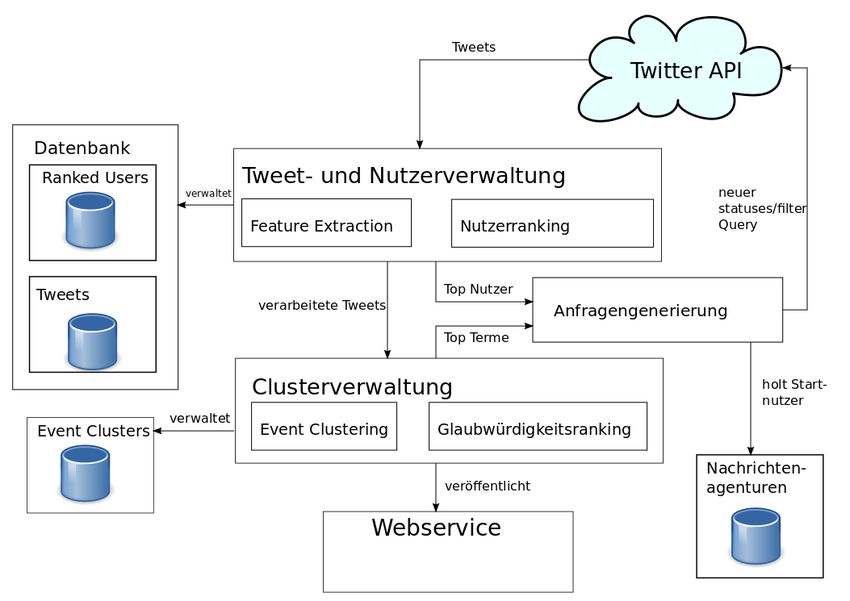
TwiNex
Aufgabenstellung
Diese Seite muss vor dem Binden der gedruckten Fassung der Arbeit durch die von dem Stu-
denten eigenhändig unterschriebene originale Aufgabenstellung ersetzt werden. Das zweite
abzugebende gebundene Exemplar soll stattdessen eine Kopie dieser originalen Aufgaben-
stellung enthalten.
IIITwiNex
Erklärung
Hiermit erkläre ich, Stefan Herrmann, die vorliegende Bachelorarbeit zum Thema
TwiNex – News Extraction for Twitter
selbstständig und ausschließlich unter Verwendung sowie korrekter Zitierung der im Litera-
turverzeichnis angegebenen Quellen und Hilfsmittel verfasst zu haben.
Dresden, 4. Februar 2013
Unterschrift
VTwiNex Inhaltsverzeichnis
Inhaltsverzeichnis
1 Einleitung 1
1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Problemstellung und Zielsetzung . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.3 Anwendungsfälle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.4 Forschungsthesen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.5 Aufbau der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Twitter 5
2.1 Überblick über Twitter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2 Die Twitter REST API . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
3 Stand der Forschung und Technik 9
3.1 Klassifizieren und Sammeln von Tweets . . . . . . . . . . . . . . . . . . . . . 9
3.2 Überprüfen der Glaubwürdigkeit von Tweets . . . . . . . . . . . . . . . . . . . 12
3.3 Erstellen eines Nutzerrankings . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.4 Auswerten von Zusatzinformationen . . . . . . . . . . . . . . . . . . . . . . . 16
3.5 Zusammenfassung Stand der Forschung . . . . . . . . . . . . . . . . . . . . . 16
4 Konzeption 19
4.1 Gesamtkonzept . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4.2 Anfragengenerierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.2.1 Erste Anfrage an den Zugangspunkt . . . . . . . . . . . . . . . . . . . 20
4.2.2 Verfeinern der Anfrage an den Zugangspunkt . . . . . . . . . . . . . . 21
4.3 Tweet- und Nutzerverwaltung . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
4.3.1 Eigenschafts- und Textanalyse von Tweets . . . . . . . . . . . . . . . . 22
4.3.2 Nutzeranalyse und Einordnung . . . . . . . . . . . . . . . . . . . . . . 24
4.4 Clusterverwaltung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.4.1 Event Clustering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.4.2 Glaubwürdigkeitsranking . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.5 Zusammenfassung der Konzeption . . . . . . . . . . . . . . . . . . . . . . . . 32
5 Validierung 35
5.1 Implementierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
5.1.1 Anfragengenerierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
5.1.2 Tweet- und Nutzerverarbeitung . . . . . . . . . . . . . . . . . . . . . . 37
5.1.3 Clustering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.1.4 MongoDB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.2 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
5.2.1 Vorgehensweise . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
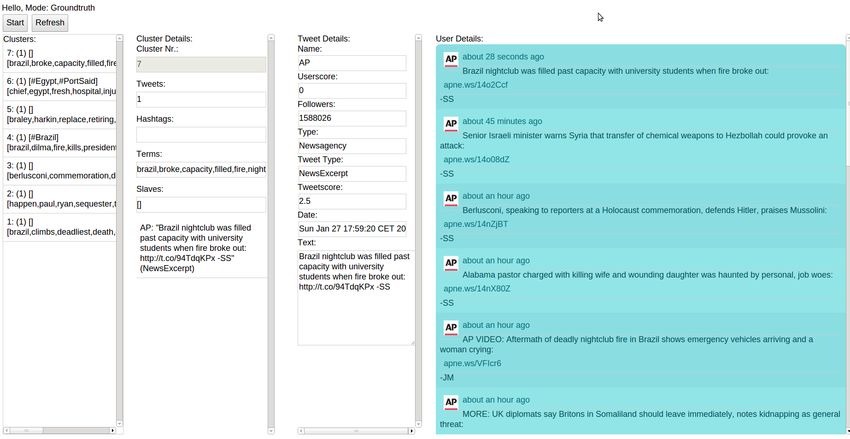
5.2.2 Erstellen des Goldstandards . . . . . . . . . . . . . . . . . . . . . . . . 39
5.2.3 Evaluation des Clusterings . . . . . . . . . . . . . . . . . . . . . . . . 40
5.2.4 Evaluation des Rankings . . . . . . . . . . . . . . . . . . . . . . . . . . 48
5.2.5 Auswertung der Anfragengenerierung . . . . . . . . . . . . . . . . . . . 53
5.2.6 Vergleich mit anderen Ansätzen . . . . . . . . . . . . . . . . . . . . . . 54
5.3 Zusammenfassung der Validierung . . . . . . . . . . . . . . . . . . . . . . . . 54
6 Fazit 55
6.1 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
6.2 Untersuchung der Forschungsthesen . . . . . . . . . . . . . . . . . . . . . . . 55
VII6.3 Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
6.3.1 Tweet- und Nutzeranalyse . . . . . . . . . . . . . . . . . . . . . . . . . 56
6.3.2 Klassifikation der Tweets . . . . . . . . . . . . . . . . . . . . . . . . . 57
A Evaluation Diagramme i
B Ausgewählte vertrauenswürdige Quellen v
Literaturverzeichnis ix
VIIITwiNex
1 Einleitung
Aktuelle Nachrichten werden meistens durch Reporter und Journalisten der großen Nach-
richten- und Presseagenturen verbreitet. Diese Nachrichten werden hauptsächlich durch tra-
ditionelle Medien wie Zeitungen, Fernsehen und Radio übertragen. Durch die immer weitere
Verbreitung des Internets, vor allem im mobilen Bereich, werden immer mehr Nachrichten
auch online durch die Agenturen bereitgestellt. Dadurch werden immer mehr Möglichkei-
ten für den Menschen geschaffen, sich über aktuelle Ereignisse zu informieren oder selber
Informationen über ein Ereignis im Internet zu präsentieren.
1.1 Motivation
Aktuelle Newsaggregatoren wie beispielsweise Google News können im Internet bereitgestell-
te Nachrichten sammeln und übersichtlich dem Nutzer präsentieren. Ein Hauptkritikpunkt
dieser Aggregatoren ist, dass zuerst die notwendigen Informationen von den Nachrichten-
seiten extrahiert werden müssen, ohne dass die jeweiligen Suchmaschinenbots explizit über
neue Nachrichten informiert werden. Außerdem durchlaufen konventionelle Nachrichten im-
mer erst einen langwierigen Prozess bis sie am Ende mit etwas Wartezeit beim Leser oder
Zuschauer erscheinen. Durch das Entstehen sozialer Netzwerke verbreiten sich Nachrichten,
unabhängig von den etablierten Medien, auch unter den Menschen immer schneller. In sozia-
len Netzwerken können sich Nachrichten nicht nur schneller verbreiten als in konventionellen
Medien, sie bieten auch neue Möglichkeiten, um aktuelle Nachrichten zu erhalten. Dadurch
wird es auch wahrscheinlicher, dass Nutzer des jeweiligen Netzwerkes Augenzeugen eines
Ereignisses werden. Diese Nachrichten können dadurch hochaktuell sein, diese aber aus den
meistens eher persönlichen Nachrichten eines Nutzers herauszufiltern ist nicht einfach.
Twitter als ein soziales Netzwerk und Microblogging-Dienst ermöglicht seinen Nutzern kurze
Nachrichten, sogenannte Tweets, unter den „Followern” eines Nutzers in Echtzeit zu verbrei-
ten. Ein „Follower” ist eine dem Nutzer bekannte oder auch unbekannte Person, welche alle
Tweets des Nutzers empfängt. Dieses Konzept der Nutzerinteraktion macht den Erfolg des
Netzwerkes bis jetzt ungebrochen und prädestiniert dieses auch zum Übermitteln von ak-
tuellen Nachrichtenmeldungen oder Ereignissen, die in der Umwelt eines Nutzers gerade
passieren. Das Finden, Filtern und Zusammentragen dieser Ereignisse kann zu einem hoch-
aktuellen Nachrichtendienst führen und somit das Erhalten von aktuellen Nachrichten und
Trends, wie wir es heute kennen, revolutionieren.
1.2 Problemstellung und Zielsetzung
Ziel dieser Arbeit ist es ein System zu entwickeln, welches Nachrichten ereignisbasiert aus
Twitter filtert, zueinander passende Tweets zusammenträgt und diese in Echtzeit darstellt.
Dabei sollen aktuelle Ansätze analysiert und möglichst verbessert werden. Das entwickelte
Konzept soll dann in einer prototypischen Implementation umgesetzt werden.
Problematisch ist vor allem das Finden von passenden Tweets, da ein Großteil der Kom-
munikation das alltägliche Leben der Nutzer zum Thema hat, und somit das Finden von
interessanten Themen für Nachrichten schwierig ist. Hierzu müssen passende Methoden und
Algorithmen gefunden werden, die das Filtern von relevanten Nachrichten in der Masse an
Tweets effizient und erfolgreich ermöglichen. Dafür muss eine Datenbasis erstellt werden, wel-
che Schlagworte für Ereignisse und Trends spezifiziert, welche wiederum ein Tracking dieser
Ereignisse auslösen. Zusammenhängende Meldungen müssen dann erkannt und durch eine
intelligente Kategorisierung miteinander in Verbindung gebracht werden. Außerdem muss
eine Nutzerbasis erstellt werden, welche als zuverlässige Quelle für die Nachrichten dient.
Dabei müssen unter anderem die aktuellen Möglichkeiten der Twitter API beachtet werden,
1sowie die sich ständig ändernde Zahl der Nutzer der Plattform. Dazu ist es notwendig, ein
Ranking der Nutzer und deren Tweets mittels Algorithmen, welche die Glaubwürdigkeit ihrer
Tweets analysieren, zu erstellen. Mittels dieser Nutzerbasis müssen dann weitere öffentliche
Tweets ausgewertet und auf ihre Plausibilität überprüft werden, damit keine Falschmeldun-
gen veröffentlicht werden. Konventionelle Nachrichtenagenturen können als Referenz dienen,
jedoch würde dadurch der Zeitvorteil verloren gehen. Deshalb müssen die ersten Meldungen
zu einem neuen Thema erkannt und gut abgewogen werden. Voraussetzung für eine effizi-
ente Analyse und Kategorisierung passender und glaubwürdiger Tweets ist die Verwendung
schneller und in Echtzeit arbeitender Algorithmen.
Die Hauptziele dieser Arbeit lassen sich wie folgt zusammenfassen:
• Konzeption und Erweiterung von Algorithmen des Information Retrieval zur Echtzeit-
analyse der Kommunikation auf Twitter zum ereignisbasierten Filtern von Tweets, um
daraus Nachrichtenmeldungen zu erkennen und zusammenzufassen.
• Erstellen eines funktionsfähigen Prototyps für ein übersichtliches Darstellen von aktu-
ellen Nachrichten und deren Entwicklungstrend.
1.3 Anwendungsfälle
In diesem Abschnitt werden zwei Anwendungsfälle vorgestellt, die verdeutlichen sollen, mit
welchen Forschungsfragen sich diese Arbeit auseinandersetzt und die Hauptziele der Arbeit
näher beschreibt.
Anwendungsfall 1 - Hochaktuelles Ereignis
Bei einem hochaktuellen Ereignis, also einem Ereignis dessen Ende noch nicht absehbar ist
und dessen Anfang erst vor wenigen Minuten war, haben Tweets einen großen Zeitvorsprung.
Ein Nutzer des während dieser Arbeit entwickelten Dienstes kann auf Nachrichtentweets zu-
greifen und sich fortlaufend und zeitnah über die Entwicklung eines Ereignisses informieren.
Ereignet sich beispielsweise an einem beliebigen Ort auf der Erde ein Erdbeben, treten ak-
tuelle Nachrichtenmeldungen dazu im Minutentakt auf. Im Vergleich dazu, treten bei einem
Nachrichtendienst auf Twitterbasis neue Tweets im Sekundentakt auf.1 Vom Erdbeben be-
troffene Menschen, welche Twitter nutzen, können die ersten sein, die ein solches Beben
bestätigen. Nutzer können auf der Webseite Tweets zu diesem Ereignis sehen und sich sofort
darüber umfassend informieren. Helfer könnten schnell zu den am stärksten vom Erdbeben
betroffenen Gebieten geleitet werden oder Informationen über eventuell verschüttete Per-
sonen erhalten. Die Entwicklung eines solchen Ereignisses kann viel feiner wiedergegeben
werden, da einzelne Personen die Möglichkeit haben ihre Erlebnisse wiederzugeben und dem
Nutzer die Möglichkeit gegeben wird daran teilzuhaben.
Anwendungsfall 2 - Geplantes Ereignis
Twitternutzer beobachten auch geplante Ereignisse, welche über einen längeren Zeitraum
laufen. Durch Tweets von involvierten Personen können aktuelle Meldungen zu einem Er-
eignis schneller der breiten Öffentlichkeit zugänglich gemacht werden. So bot beispielsweise
die Präsidentschaftswahl 2012 in den USA die Möglichkeit, Hintergrundinformationen von
vielen Personen im Verlauf des Wahlkampfes zu gewinnen. Ein Nutzer von TwiNex kann nun
unabhängige Nachrichten erhalten, ohne dass diese durch konventionelle Medien beeinflusst
sind. Diese Unabhängigkeit der Nachrichten könnte genutzt werden, um ein umfassenderes
Bild über einen Wahlkandidaten und seine Themen zu erhalten.
1.4 Forschungsthesen
Aus den im vorherigen Abschnitt beschriebenen Anwendungsfällen ergeben sich folgende
Forschungsthesen, welche im Verlauf dieser Arbeit bearbeitet werden sollen:
1 http://latimesblogs.latimes.com/technology/2008/07/twitter-earthqu.html - abgerufen 14.12.2012
2TwiNex 1.5 Aufbau der Arbeit
1. Mittels einer kleinen, manuell definierten Ausgangsmenge von vertrauenswürdigen
Quellen, lässt sich ein Nachrichtenaggregator schaffen, welcher dynamisch neue Tweets
und Quellen für Nachrichten-relevante Themen findet.
2. Bereits mit einer kleinen Anzahl von Tweets und Quellen, sowie ausgewählter, grund-
legender Eigenschaften dieser, können Clustering- und Rankingverfahren so parame-
trisiert werden, dass sie sich gut für die beschriebenen Anwendungsfälle generalisieren
lassen.
1.5 Aufbau der Arbeit
Die vorliegende Arbeit ist wie folgt aufgebaut:
Im Kapitel 2 wird auf Twitter, sowie grundlegende dort verwendete Begriffe eingegangen.
Es findet ein kurzer Überblick über die Möglichkeiten der Twitter API statt.
Im Kapitel 3 wird auf den aktuellen Stand der Forschung und Technik eingegangen. Es wer-
den die aktuell bestehenden Ansätze zum Erkennen von Nachrichtenmeldungen in Tweets
und des Clusterings dieser zu Themengebieten erfasst. Außerdem werden die vorhandenen
Ansätze für das Ermitteln der Glaubwürdigkeit von Tweets und Nutzern, sowie des Rankings
dieser untersucht. Es wird dargestellt, welche Möglichkeiten zur Auswertung von Daten der
Tweets und Nutzer bestehen.
Das Kapitel 4 stellt mit TwiNex einen Nachrichtendienst auf Twitterbasis vor. Es wird auf
die entwickelten Komponenten für das Anfragen an die Twitter API, zum Finden passender
Nutzer, dem Ranken der Nutzer und der Analyse der ankommenden Tweets eingegangen.
Weiterhin werden die genutzten Methoden zum Clustern der Tweets in unterschiedliche Er-
eignisse und Bewerten der Tweets nach ihrer Glaubwürdigkeit behandelt.
Kapitel 5 beschreibt die genutzten Techniken zur Implementation des Prototypen, um das
Konzept aus Kapitel 4 zu überprüfen. Zuletzt wird im Kapitel 6 auf die gewonnenen Er-
kenntnisse aus der Arbeit eingegangen. Es wird gezeigt, ob die gestellten Forschungsthesen
belegt werden können und wohin eine zukünftige Entwicklung gehen könnte.
3TwiNex
2 Twitter
In diesem Kapitel wird einleitend auf die Entwicklung Twitters und spezifische Begriffe bei
der Nutzung dieses sozialen Netzwerks eingegangen. Es werden die aktuellen Möglichkeiten
der Twitter API analysiert.
2.1 Überblick über Twitter
Twitter als Microblogging-Plattform und soziales Netzwerk wurde im März 2006 von Jack
Dorsey, Biz Stone und Evan Williams gegründet und entwickelte sich seitdem rasant zu
einem der größten sozialen Netzwerke.1 Aktuell hat Twitter, nach eigenen Angaben, 340
Millionen Tweets pro Tag und mehr als 140 Millionen aktive Nutzer.2 Der Erfolg von Twit-
ter beruht zum einen auf der Verbindung von Nachrichtendienst, Microbloggingdienst und
sozialem Netzwerk sowie zum anderen auf die weite Verbreitung unter ganz unterschiedli-
chen Personengruppen und Unternehmen, welche über ihr Leben oder Wirken berichten. Im
Folgenden wird auf einige der wichtigsten Begriffe von Twitter eingegangen.
Tweet
Ein Tweet ist eine Nachricht, die auf Twitter veröffentlicht wird. Er ist maximal 140 Zeichen
lang. Tweets können öffentlich oder privat sein. Privat bedeutet, dass nur Freunde eines
Nutzers diesen Tweet sehen können. Öffentliche Tweets können von jedem Twitternutzer
gesehen und gesucht werden. Oft werden Tweets mit Links ergänzt, um eine Aussage zu er-
weitern oder zu bestätigen. Durch die Begrenzung auf 140 Zeichen werden häufig sogenannte
URL-Shortener benutzt. Sie kürzen einen langen Link auf wenige Zeichen indem ein Link zu
dem Dienst, welcher dann zu der langen URL weiterleitet und der anstelle des langen Links
in dem Tweet benutzt wird.
Tweets können außerdem durch andere Nutzer weiterverbreitet werden, als dem ursprüng-
lichen Verfasser. Dieses Verfahren nennt sich retweeten. Ein Retweet ist ein Tweet eines
Nutzers, welcher erneut durch einen anderen Nutzer veröffentlicht wird. Retweets werden
häufig durch die Abkürzung „RT” am Anfang des Tweets markiert.
Follower
Ein Follower ist eine Person, welche alle öffentlichen Tweets eines Nutzers direkt nach ih-
rer Veröffentlichung bekommen möchte und darüber benachrichtigt werden will, dass neue
Tweets erschienen sind. Ein Nutzer kann unendlich viele Follower haben, jedoch selber nur
maximal 2000 Nutzern folgen.
Hashtag
Ein Hashtag ist eine Kombination aus einem Doppelkreuz-Symbol und einem Schlagwort,
welches zum besseren thematischen Beschreiben eines Tweets benutzt wird. Dazu wird einem
Wort ein „#” als Präfix hinzugefügt. Nun ist dieses Wort als Hashtag markiert und es kann
durch einen Klick darauf nach Tweets gesucht werden, welche dieses Hashtag enthalten und
somit auch dieses Thema behandeln.
1 http://www.nzz.ch/aktuell/digital/twitter-wachstum-merkel-dorsey-1.15999106 - Abgerufen: 01.11.2012
2 https://business.twitter.com/basics/what-is-twitter - Abgerufen: 07.11.2012
5Erwähnung
Sollen ein oder mehrere Twitternutzer explizit mit einem Tweet angesprochen werden, so
bezeichnet man dies als Erwähnung in einem Tweet. Mittels eines „@”, gefolgt von dem
entsprechenden Nutzernamen wird dieser Nutzer in dem Tweet erwähnt.
2.2 Die Twitter REST API
Twitter stellt Entwicklern verschiedene Möglichkeiten zur Verfügung, um z.B. Twitterfunk-
tionen auf der eigenen Webseite einzubinden, eigene Anwendungen für Twitternutzer zu
schreiben, Suchanfragen an Twitter zu stellen oder Tweets aus dem Dienst zu extrahieren.
Für das Einbinden von Twitterfunktionen, wie dem follow-Button, in einfache HTML Seiten
gibt es vorgefertigte Produkte, welche von Twitter unter dem Namen „Twitter for Websites”
angeboten werden.
Für komplexere Aufgaben wird die REST API angeboten. Aktuell wird die Version 1.1 der
REST API von Twitter für die Nutzung vorgesehen, die ältere Version 1.0 wird in wenigen
Monaten nach dem Release der Version 1.1 eingestellt.3 REST steht hierbei für Represen-
tational State Transfer und bezeichnet ein Programmierparadigma für Webanwendungen.
Über REST ist es möglich, per HTTP GET oder POST über bereitgestellte URLs Informa-
tionen einzuholen oder zu senden. Twitter liefert diese Daten im JSON-Format aus.
Wichtig für die Version 1.1 sind vor allem Änderungen in der Handhabung der Authenti-
fizierung der Anwendungen und des Rate Limits, welches die Anzahl der GET-Anfragen
limitiert. Jeder Zugangspunkt benötigt nun eine OAuth Authentifizierung, dafür wird pro
Anwendung ein einziges Access-Token vergeben. Für jede GET-Anfrage an einen Zugangs-
punkt gibt es ein 15 minütiges Zeitfenster, in welchem je nach Zugangspunkt unterschiedlich
viele Anfragen getätigt werden können. Allgemein gibt es hier zwei verschiedene Ausprä-
gungen, entweder 15 Anfragen oder 180 Anfragen pro Zeitfenster4 . Twitter unterteilt, für
verschiedene Nutzungsszenarien, die REST API in mehrere Kategorien.
Allgemein ist es mit der REST API möglich, komplexere Funktionen von Twitter selber
in einer Anwendung anzubieten. So ist es über die REST API möglich, per GET statu-
ses/user_timeline die Timeline eines Nutzers abzufragen oder per POST statuses/update
einen Status zu übermitteln. Eine Möglichkeit nach Tweets auf Twitter zu suchen ist die
Search API. Über den Zugangspunkt search/tweets werden, zu einer Suchanfrage passen-
de, Tweets der letzten 6-9 Tage zurückgeliefert. Besser geeignet für einen Nachrichtendienst
auf Twitterbasis, ist jedoch die Streaming API. In dieser Kategorie wird nochmal unter-
schieden zwischen Public Streams, User Streams und Site Streams. Die Public Streams sind
am besten für das Data Mining geeignet, da sie alle öffentlichen Tweets von Twitter strea-
men. Im Gegensatz zu den anderen REST API Zugängen ist die Streaming API durch eine
kontinuierliche persistente HTTP Verbindung für einen konstanten Datenstrom an Tweets
gekennzeichnet, welche nicht durch ein konstantes Polling abgefragt werden muss und da-
durch keine Gefahr besteht das Rate Limit zu verletzen. Dennoch müssen Anwendungen,
welche auf die Streaming API zugreifen, den Stream auch in Echtzeit verarbeiten können.
Sollte dies nicht passieren und die Nachrichtenwarteschlange von Twitter für die Anwendung
ausgelastet sein, wird eine Stall Warning verschickt. Falls diese nicht beachtet wird und die
Anwendung weiterhin zu langsam arbeitet, wird die Verbindung zur Anwendung geschlos-
sen. Damit das garantiert wird, sollte eine Anwendung die Verbindung zu Twitter in einem
gesonderten Prozess verarbeiten und die Tweets, für eine weitere Nutzung, speichern. Für
einen Nachrichtendienst auf Twitterbasis sind vor allem die Public Streams interessant.5 Im
Folgenden werden deshalb die drei Zugangspunkte der Streaming API „statuses/filter” und
„statuses/samples”, „statuses/firehose” näher erläutert.6
3 https://dev.twitter.com/blog/changes-coming-to-twitter-api - abgerufen 28.01.2013
4 dev.twitter.com/docs/rate-limiting/1.1/limits- abgerufen 27.01.2013
5 dev.twitter.com/docs/streaming-apis - abgerufen 27.01.2013
6 dev.twitter.com/docs/streaming-apis/streams/public - abgerufen 27.01.2013
6TwiNex 2.2 Die Twitter REST API
statuses/filter
Gibt alle öffentlichen Tweets zurück, welche einer Menge übergebener Filterparameter ent-
sprechen. Die Standardzugriffsrechte erlauben bis zu 400 Schlüsselwörter, 5000 Nutzerids
und 25 Orte.
statuses/samples
Gibt eine kleine, zufällige Untermenge aller öffentlichen Tweets zurück.
statuses/firehose
Dieser Zugangspunkt benötigt spezielle Rechte, um zu ihm verbinden zu können. Er gibt
alle aktuellen öffentlichen Tweets zurück.
7TwiNex
3 Stand der Forschung und Technik
Nachdem ein Überblick über Twitter und die Möglichkeiten der Twitter API gegeben wurde,
sollen bestehende Ansätze untersucht werden. Es wird auf unterschiedliche Ansätze zum
Klassifizieren und Kategorisieren von Tweets eingegangen sowie zum Bewerten und Ranken
der Glaubwürdigkeit von Quellen und Tweets. Zum Schluss werden die bestehenden Ansätze
miteinander verglichen.
3.1 Klassifizieren und Sammeln von Tweets
Eine große Herausforderung stellt das Erkennen und Filtern von relevanten Tweets dar.
Dazu wird als erstes unterschieden, ob ein Tweet nur unwichtige Daten enthält, im Fol-
genden Spamtweet genannt, oder ob er Nachrichtenmeldungen enthält, im Folgenden Nach-
richtentweet genannt. Es ist wichtig möglichst viele Spamtweets auszusortieren, ohne dabei
zu viele relevante Nachrichtentweets zu verlieren. Es ist jedoch schwierig die Grenze zwi-
schen Nachrichten- und Spamtweet klar zu bestimmen. Oft werden Nachrichteninformatio-
nen in Tweets durch Umgangssprache verdeckt. Wurde eine geeignete Methode gefunden,
die Tweets aus der großen Masse filtert, bleiben nur nutzbare Tweets übrig. Diese müssen
nach verschiedenen Themen kategorisiert werden, damit zusammengehörende Meldungen
gesammelt werden können. Algorithmen, die dieses Problem lösen, müssen dabei in Echt-
zeit die große Masse an ankommenden Tweets schnell und zuverlässig analysieren können.
Für Algorithmen ist dabei vor allem die Kürze der Tweets ein Problem, da das Analysieren
von Text bei dem klassischen Dokumentenclustering durch lernfähige Algorithmen mittels
großer Trainingssets stattfindet. Tweets, als einzelne, kurze Dokumente betrachtet, bieten
nur wenige Informationen, die diese Algorithmen klassifizieren können. [SST+09]
Sankaranarayanan et al. „TwitterStand: News in Tweets”
Sankaranarayanan et al. [SST+09] nutzen für die Architektur von TwitterStand einen Naive-
Bayes Klassifikator. Dieser unterscheidet aufgrund eines vorher manuell klassifizierten Trai-
ningsets, ob ein Tweet Spamtweet (S) oder ein Nachrichtentweet (N ) ist. Dabei wird für
einen Tweet aus den Wörtern w1 , w2 , ...wk die Wahrscheinlichkeit, ob er ein Spamtweet ist,
berechnet. Folgende Formel ergibt sich aus dem Bayesschem Theorem:
p(w1 , w2 , ...wk |S)
P (S|w1 , w2 , ...wk ) = p(S) ∗ (3.1)
p(w1 , w2 , ...wk )
Gleichbedeutend ist die Wahrscheinlichkeit, dass ein Tweet Nachrichten beinhaltet:
p(w1 , w2 , ...wk |N )
P (N |w1 , w2 , ...wk ) = p(S) ∗ (3.2)
p(w1 , w2 , ...wk )
Es wird angenommen, dass alle Wörter unabhängig voneinander sind. Über mehrere Schritte
werden dann die Gleichungen zusammengefasst und umgestellt, so dass eine Gleichung mit
einem Schwellwert D ermittelt wird.
k
P (S) X p(wi |S)
D = log( )+ (3.3)
P (N ) i=1
p(wi |N )
Wenn nun D < 0 ist, wird der Tweet als Nachricht klassifiziert, andernfalls als Spamtweet
und damit verworfen. P (S) ist die Differenz aus der Gesamtzahl, an als Spam klassifizierte
Tweets, durch die Anzahl an Tweets in dem Trainingsset insgesamt. Gleichbedeutend ist
P (N ) die Differenz aus der Gesamtzahl an als Nachricht spezifizierten Tweets durch die
9Anzahl an Tweets in dem Trainingsset insgesamt. P (wi |S) wird berechnet, indem die An-
zahl an Tweets gezählt wird, in denen wi vorkommt und der Tweet als Spam klassifiziert
wurde. Gleichfalls wird P (wi |N ) berechnet, indem die Anzahl der Tweets gezählt wird in
denen wi als Nachricht vorkommt. Die Wahrscheinlichkeiten für das Trainingsset werden im
Voraus berechnet und dann in einer Tabelle gespeichert. Um die Genauigkeit der Klassi-
fizierung, ob ein Tweet Nachricht oder Spam ist, zu verbessern, nutzen Sankaranarayanan
et al. [SST+09] ein statisches System, also das eben beschriebene Klassifizieren mittels des
Trainingssets, und ein dynamisches System. Das dynamische System basiert auf Tweets aus
aktuellen Nachrichtenmeldungen, die schon kategorisiert wurden. Deshalb werden diese aus
dem Clustering Modul genommen und dienen als Vergleichswert für die Wahrscheinlich-
keitsberechnungen. Außerdem werden dem dynamischen System noch Daten über aktuelle
Personennamen sowie Hashtags als Vergleichswert hinzugefügt. Die Idee dahinter ist, dass
das statische System hilft neue Themen zu identifizieren und das dynamische System hilft
neue Tweets zu einem Thema besser zu kategorisieren. [SST+09]
Nachdem passende Tweets gefiltert wurden, entwarfen Sankaranarayanan et al. einen Online
Clustering Algorithmus, um zueinander passende Nachrichtentweets zu sammeln. Er basiert
auf einem modifizierten Leader-Follower-Clustering Algorithmus von Duda et al. [DHS00].
Damit er ständig neue Daten analysieren kann, also online ist, und auch besser mit dem
hohem Hintergrundrauschen zurecht kommt, wurde er verändert. Als Hintergrundrauschen
gilt das hohe Aufkommen an Spamtweets im Vergleich zu relevanten Nachrichtentweets. Das
Besondere ist, dass dieser Algorithmus nach Zeit und Inhalt gruppieren kann und auch ohne
große Trainingssets zu einem guten Ergebnis kommen soll. Die hohe Geschwindigkeit des
Algorithmus wird unter anderem dadurch gewährleistet, dass ankommende Tweets nur ein-
mal kategorisiert und zu einem Cluster hinzugefügt werden und danach nicht noch einmal
überprüft und auch später nicht gelöscht werden. Nur der Cluster wird dann als inaktiv
markiert, wenn er nicht mehr aktualisiert wird, d.h. keine neuen Tweets mehr zu diesem
Cluster passen. Der Algorithmus arbeitet mit einer Liste von aktiven Clustern. Jeder dieser
Cluster hat einen Feature-Vektor, also eine gewichtete Liste von Schlüsselwörtern, welche
häufig in diesem Cluster vorkommen. Gewichtet werden diese Wörter nach dem TF-IDF-
Maß. Das TF-IDF-Maß bestimmt, wie oft ein Wort in einem Tweet vorkommt. Außerdem
besitzt jeder Cluster einen gemittelten Zeitpunkt, der zeigt wann durchschnittlich die Nach-
richten, die zu diesem Cluster gehören, veröffentlicht wurden. Ein Cluster wird als inaktiv
markiert, wenn dessen Zeitmittelpunkt älter als 3 Tage ist. Für neu ankommende Tweets
wird ihr TF-IDF-Vektor bestimmt, danach wird mittels der Kosinus-Ähnlichkeit [MR09] die
Distanz zu einem möglichen Cluster berechnet. [SST+09]
−−−→ −−−→
T F Vt • T F Vc
δ(t, c) = −−−→ −−−→ (3.4)
kT F Vt kkT F Vc k
−−−→ −−−→
Dabei sind T F Vt , T F Vc die Feature-Vektoren von Tweet t und Cluster c. t wird zu einem
Cluster hinzugefügt, wenn gilt das δ(t, c) ≤ , wobei eine vorher festgelegte Konstante
ist. Falls kein passender Cluster existiert, wird ein neuer Cluster gestartet. Zusätzlich zum
Feature-Vektor muss auch noch die zeitliche Komponente beachtet werden. Dazu wenden
Sankaranarayanan et al. eine Gaußsche Abschwächung auf die Kosinus-Distanz an. Der
Dämpfungsfaktor bevorzugt zeitlich zu einem Cluster nahestehende Tweets.
−(Tt −Tc )2
δ̇(t, c) = δ(t, c) · e 2(σ)2 (3.5)
Um die Vergleiche schnell zu gestalten, wird zum einen ein Invertierter Index der Zeitschwer-
punkte gehalten und zum anderen wird für jedes Feature f ein Zeiger zu jedem Cluster
gespeichert, welcher f enthält. Außerdem wird die Distanz zu einem Cluster nur berechnet,
wenn der Tweet mindestens ein Feature mit dem Cluster gemeinsam hat. Zusätzlich kön-
nen nur aktive Cluster neue Tweets bekommen, inaktive Cluster werden nicht betrachtet.
Neue Cluster können nun relativ schnell entstehen, wodurch auch weniger gute Meldungen
evtl. einen neuen Cluster formen und somit wieder zu viele unwichtige Nachrichtencluster
entstehen. Um das Problem des hohen Hintergrundrauschens zu lösen, dürfen nur Tweets
bestimmter Twitternutzer, aus einer Menge vertrauenswürdiger Quellen, neue Cluster veri-
fizieren. Cluster aus weniger vertrauenswürdigen Quellen sind anfangs als inaktiv markiert.
10TwiNex 3.1 Klassifizieren und Sammeln von Tweets
Außerdem kann es passieren, dass sich neue Cluster formen, die jedoch das gleiche Thema
behandeln, weil die Distanz zu groß ist. Dadurch kann es zu einer Fragmentierung in viele
kleine Cluster kommen, was gleichbedeutend mit gar keinem Clustering wäre. Um das zu
vermeiden, wird regelmäßig überprüft, ob Duplikate vorhanden sind. Wenn ein Duplikat
gefunden wurde, wird der ältere Cluster als Master markiert und der jüngere als Slave. Nun
können neue Tweets nur noch zum Master-Cluster hinzugefügt werden. Es gehen also nur
wenige Tweets an den Slave-Cluster verloren. Ein weiteres Problem entsteht, wenn ein neues
Feature in das System kommt, was aber eigentlich nur ein falsch buchstabiertes schon vor-
handenes Feature ist. Weil es noch nicht vorhanden ist, hat es einen hohen TF-IDF-Wert
und es kann passieren, dass neu ankommende Tweets mit diesem Feature einen Cluster
bilden. Es entsteht ein Cluster mit Tweets, die nur dieses eine Feature gemeinsam haben.
Um dies zu vermeiden können Tweets nur zu einem Cluster hinzugefügt werden, wenn sie
mindestens k gemeinsame Features haben. Dabei ist k meistens eine kleine Zahl, aber größer
als eins. Beachtet werden müssen auch zusammenhängende Satzglieder. Gemeinsame Satz-
glieder in Tweets haben einen hohen TF-IDF-Wert und können daher schnell ein Clustering
hervorrufen, obwohl die Tweets eventuell nicht viel inhaltlich gemeinsam haben. Um dies zu
vermeiden, müssen Sätze nach zusammenhängenden Wörtern durchsucht werden. Das Pro-
blem kann gelöst werden, indem das dominante Wort bestimmt wird und nur dieser Term
geclustert wird oder beide Wörter als ein Term zusammengefasst werden und auf diesen
Term geclustert wird. [SST+09]
Lui et al. „Semantic Role Labeling for News Tweets”
Liu et al. [LLH+10] stellen in ihrem Paper einen gegensätzlichen Ansatz zum von Sankaran-
arayanan et al. [SST+09] vorgestellten Ansatz vor. Sie entwickelten ein speziell auf Tweets
angepasstes Semantic Role Labeling (SRL) System, um Nachrichten aus Tweets zu filtern,
welches zudem automatisch auf einer Menge von Tweets trainiert wird. Außerdem präsentie-
ren sie ein Verfahren, um Tweets mittels eines schon vorhandenen SRL-Systems zu sammeln
und zu kategorisieren.
Zuerst beschreiben sie vier Komponenten, die das vorhandene SRL-System, welches für
Nachrichtenmeldungen aus normalen Artikeln entwickelt wurde, als Basis benutzen, um da-
mit ein Semantic Role Labeling auf Tweets durchzuführen. Dieses System von Meza-Ruiz und
Riedel wird im Folgenden SRL-BS genannt. Diese 4-stufige Methode ermöglicht das Filtern
und Zusammentragen von Nachrichtentweets aus der großen Masse an Tweets auf Twitter.
Problematisch ist dabei, dass es nur bedingt für Nachrichtentweets geeignet ist, denn sein
F1 Maß fällt von 75,5% bei konventionellen Nachrichtenartikeln auf 43,3% bei Nachricht-
entweets wenn das SRL-BS genutzt wird. Deshalb haben sie als eine fünfte Komponente ein
eigenes domänenspezifisches SRL-System entworfen. Die erste Komponente extrahiert Nach-
richtenausschnitte, danach werden diese in der zweiten Komponente durch ein Clustering
zusammengefasst. Die dritte Komponente findet nun mittels der Cluster neue Nachrichtent-
weets. Danach wird ein Semantisches Mapping durch das SRL-BS auf die Tweets angewen-
det, um semantische Informationen aus den Nachrichten zu gewinnen. Im Folgenden werden
die vier Komponenten für das Extrahieren, Sammeln und Semantic Role Labeling genauer
beschrieben. Auf das auf Twitter angepasste SRL-System wird nun nur kurz eingegangen,
da auch im Paper von Lui et al. nur wenige Informationen dazu stehen.
In der ersten Komponente werden Nachrichtenausschnitte aus Tweets extrahiert, um das
automatische Anlernen des SRL-Systems zu ermöglichen, denn Auszüge aus Nachrichten-
artikeln werden grundsätzlich als glaubwürdige Informationen angesehen. Die Komponente
betrachtet nur Tweets, die einen Link zu einer von 57 ausgewählten Nachrichtenseiten besit-
zen. Wenn ein solcher Link gefunden wurde, wird der Text im Tweet mit dem Text im Nach-
richtenartikel verglichen. Sollte eine Übereinstimmung gefunden werden, wird dieser Tweet,
im Folgenden Nachrichtenauszug genannt, zur Ausgangsmenge hinzugefügt andernfalls wie-
der verworfen. Diese Vorgehensweise ermöglicht eine sehr gute Auswahl an glaubwürdigen
Tweets zu einem Thema. Dadurch wird das System mit Wörtern angelernt, welche ein Er-
eignis beschreiben. Es wird keine vorher manuell annotierte Menge von Tweets benötigt.
Die Ausgangsmenge für ein Thema soll aus 100 Tweets mit Nachrichtenauszügen bestehen,
welche später dazu genutzt werden, um weitere Tweets zu einem Thema zu kategorisieren.
11In der zweiten Komponente werden nun die Nachrichtenauszüge einem Clustering unterzo- gen. Dabei werden zuerst alle Metadaten aus dem Tweet entfernt, bis am Ende nur noch der Nachrichtenauszug übrig bleibt. Danach wird mittels des OpenNLP Toolkits der Text auf Tokens, Part-Of-Speech Tags, Chunks und ähnliches analysiert. Am Ende werden alle Tweets mittels des SRL-BS auf ihre Prädikat-Argument-Strukturen untersucht und jeder Nachrichtenausschnitt wird als Term-Frequency-Vektor aus den vorher extrahierten Struk- turen dargestellt. Ein Cluster ist dann sozusagen ein Meta-Nachrichtenauszug, welcher auch durch einen Term-Frequency-Vektor aus der Summe aller TF-Vektoren der enthaltenen Nachrichtenausschnitte besteht. Um das Hintergrundrauschen zu verringern, werden Ter- me wie Nummern und Stoppwörter nicht beachtet und die Anzahl unterschiedlicher Wörter per Stemming reduziert. Wie bei Sankaranarayanan et al. [SST+09] wird nun die Kosinus- Ähnlichkeit zwischen den Clustern ermittelt, um sie zu vergleichen. Liu et al. haben dabei einen Grenzwert von 0,7 festgestellt, ab dem ein Cluster mit einem anderen Cluster vereint wird, weil sie sich ähnlich genug sind. In der dritten Komponente werden nun alle Tweets zu einem Thema auf ihre Nachrich- tentauglichkeit überprüft, welche nicht unbedingt einen Link zu einem Nachrichtenartikel haben. Dazu werden in zwei Schritten die verbleibenden Tweets zu den vorher erstellten Clustern hinzugefügt. Im ersten Schritt wird für jeden Tweet die Kosinus-Ähnlichkeit zu jedem Cluster geprüft. Dazu wird jeder Tweet, wie oben beschrieben, auf die für das SRL wichtigen Bestandteile analysiert und reduziert, sowie sein TF-Vektor bestimmt. Wenn die Kosinus-Ähnlichkeit bei 0,7 liegt wird der Tweet als Nachrichtentweet deklariert und zum Cluster hinzugefügt. Im zweiten Schritt wird jeder Tweet als Nachrichtenauszug deklariert, falls seine Kosinus-Ähnlichkeit über 0,9 liegt. Dies bedeutet, dass er nun auch durch das SRL-BS auf seine Prädikat-Argument-Struktur analysiert wird. In der vorletzten Komponente wird für jedes Paar aus Nachrichtenauszug und Nachrichtent- weet in einem Cluster ein semantisches Mapping durchgeführt. Damit gibt es zu jedem Term in einem Nachrichtenauszug eine semantische Information aus einem zugehörigen Nachricht- entweet. Falls ein Nachrichtentweet keine semantischen Informationen durch einen Nachrich- tenauszug erhält, z.B. weil es einen Fehler beim Word Alignment gab, oder kein passender Nachrichtenauszug existiert, wird dieser Tweet aus dem Cluster gelöscht. Als fünfte und somit letzte Komponente wird ein domänenspezifisches SRL-System durch Lui et al. konstruiert, um das SRL-Basissystem zu ersetzen. Dabei nutzt dieses SRL-System das Conditional-Random-Field Framework für Maschinelles Lernen von Lafferty et al. [LMP01], um dieses auf automatisch konstruierten Trainingsdaten zu trainieren. Um speziell auf Tweets angepasst zu sein, werden, wie in der zweiten Komponente, vor dem Extrahieren von Eigenschaften alle Tweetmetadaten entfernt. Außerdem nutzen Lui et al. keine Eigen- schaften, welche auf Syntaxbäumen basieren, damit kein Syntaxparser benutzt werden muss, der auf Stil und Sprache des Textes achtet. Durch eine Analyse haben Lui et al. festgestellt, dass das F1 -Maß ihres SRL-Systems bei 66% liegt und somit die Performance besser ist, als bei dem SRL-BS mit einem F1 -Maß von 43,3%. Das System kann noch verbessert werden, indem auch Tweetmetadaten für das Self-Supervised Learning benutzt werden [LLH+10]. 3.2 Überprüfen der Glaubwürdigkeit von Tweets Bei der großen Menge an Tweets und dem daraus entstehendem großen Informationsge- halt auf Twitter ist es wahrscheinlich, dass nicht alle Informationen, die zu einem Thema aufkommen, glaubwürdig sind. Für einen aus Twittermeldungen bestehenden Nachrichten- dienst wäre es fatal, Falschmeldungen zu verbreiten. Daher ist es notwendig, Methoden zu entwickeln, welche die Glaubwürdigkeit einer Information in einem Tweet überprüfen. Sankaranarayanan et al. „TwitterStand: News in Tweets” Sankaranarayanan et al. [SST+09] folgen in ihrer Arbeit dem Ansatz, dass eine gute Auswahl an Quellen, in diesem Fall Nutzern von Twitter, für die Nachrichten auch glaubwürdige Tweets bedeuten. In einer Studie aus dem Jahr 2009 von Heil und Piskorski wird festgestellt, dass 10% der aktiven Nutzer von Twitter für 80% des Tweet-Aufkommens verantwortlich 12
TwiNex 3.2 Überprüfen der Glaubwürdigkeit von Tweets
sind.1 Daraus lässt sich schlussfolgern, dass eine gute Nutzerbasis nicht groß sein muss. Sie
muss vor allem qualitativ hochwertig, seriös und zuverlässig sein, sodass später neue Nutzer
gewonnen werden können. Sankaranarayanan et al. lösen dies, indem sie zuerst manuell
eine Nutzerbasis mit Twitternutzern aufbauen, welche größtenteils oder ausschließlich über
Nachrichten twittern. Danach wird diese Basis durch ein Ranking kontinuierlich erweitert.
Dazu wird der, zu diesem Zeitpunkt noch vorhandene, BirdDog Service der Twitter API
genutzt. Das Ranking betrachtet zum einen Nutzer, die vor allem mit einem hohen Anteil
der Grundbasis folgen, und zum anderen Nutzer, welche in der Vergangenheit gute Tweets
zu einem bestehendem Cluster hinzugefügt haben [SST+09].
Jackoway et al. „Identification of live news events using Twitter”
Einen anderen Ansatz präsentieren Jackoway et al. [JS11] in ihrem Paper, um einerseits die
Glaubwürdigkeit von Nachrichtentweets besser bestimmen zu können und andererseits auch
eine zeitliche Einordnung der Nachrichtentweets zu ermöglichen. Ihr System basiert auf dem
von Sankaranarayanan et al. vorgestellten „TwitterStand” und den darin enthaltenen Al-
gorithmen, um Nachrichten aus Twitter zu extrahieren und zu clustern. Es erweitert dieses
um eine zeitliche Einordnung der Tweets, die es möglich machen soll, auch hochaktuelle
Ereignisse zu beobachten. Da es bei hochaktuellen Nachrichten schwer ist eine Information
zu validieren, wenn sie publiziert wird und die Quelle unbekannt ist, müssen Tweets ge-
nauer auf ihre Glaubwürdigkeit überprüft werden. In der Arbeit von Sankaranarayanan et
al. ist dies weniger von Bedeutung, denn dort werden nur Tweets vertrauenswürdiger Quel-
len beachtet. Wenn aber ein dynamisches Ereignis betrachtet werden soll, ist es schwierig
zu diesem schnell neue Meldungen zu erhalten, wenn man nicht auch unbestätigte Quellen
heranzieht. Um auch bei solchen Ereignissen vertrauenswürdige Meldungen zu erhalten, ver-
suchen Jackoway et al. herauszufinden, wie sich ein Ereignis in der Zukunft entwickeln wird
und suchen dann Tweets zu diesem Thema sobald diese zukünftige Entwicklung eintritt. Da
sie nun wissen was voraussichtlich eintreten wird, können sie Tweets unbekannter Quellen
nach ihrer Glaubwürdigkeit bewerten, wenn diese neue Informationen über eine Entwicklung
veröffentlichen. Ein solches Ereignis ist z.B. ein Wirbelsturm. Es steht fest, dass er zu einem
bestimmten Zeitpunkt einen Ort erreichen und dort die Gegend verwüsten wird. Es steht
jedoch noch nicht fest, welche Personen direkt von diesem Wirbelsturm betroffen sind. Da
aber Zeit und Ort bekannt sind, können Tweets zu diesem Ereignis von unbekannten Perso-
nen nach ihrer Glaubwürdigkeit bewertet werden. Jackoway et al. nutzen bei einem Ereignis
Informationen aus einer Nachrichtendatenbank und die Geodaten eines Nutzers im Vergleich
zu den Geodaten eines Ereignisses, um zu bestimmen, ob eine Information plausibel ist.
Das Identifizieren von Tweets über zukünftige Ereignisse läuft in mehreren Schritten ab.
Als erstes wird eine Datenbank mit Nachrichtenartikeln aus vielen unterschiedlichen Quel-
len aus dem Internet erstellt. Dazu nutzen sie die Algorithmen aus einem anderen Projekt
namens „NewsStand” [TLP+08], um Nachrichtenartikel auf Webseiten zu einem Thema zu
finden, und diese auf zukünftige Entwicklungen zu untersuchen. Diese Nachrichtendaten-
bank enthält geclusterte Nachrichtenartikel, aus denen Schlüsselwörter extrahiert werden.
Als nächstes wird jedes Wort in jedem Artikel darauf überprüft, ob es einen zukünftigen
Zeitpunkt in einem Ereignis beschreibt. Wenn eine zukünftige Entwicklung eines Ereignisses
gefunden und durch genügend Artikel validiert wurde, kann nun die Technologie aus „Twit-
terStand” [SST+09] benutzt werden, um Tweets über dieses Ereignis zu finden. Dazu wird
überprüft, ob ein Tweet zu einem Cluster mit einem zukünftigen Ereignis gehört, indem
Schlüsselwörter aus dem Tweet mit denen aus dem Cluster über ihre TF-IDF-Werte vergli-
chen werden. Zusätzlich werden die Geodaten, des aus den Artikeln extrahierten Ereignisses,
mit denen aus den Tweets verglichen, um eine höhere Übereinstimmung zu erreichen. Um die
verschiedenen Zeitpunkte zu analysieren haben Jackoway et al. vier verschiedene Identifika-
tionsmethoden für Zeitformen entwickelt. Die mit „will”-Methode, die mit „-s” Methode, die
Verben-Methode und als letztes die Sätze-Methode. Die beiden erstgenannten Methoden sind
sehr schnell, einfach und als Grundlage für die komplexeren beiden letztgenannten Metho-
den entwickelt worden. Die zweit letztgenannten Methoden nutzen Part-of-speech Tagging,
um eine höhere Genauigkeit zu erreichen, sind aber langsamer. Das System von Jackoway
1 http://blogs.hbr.org/cs/2009/06/new_twitter_research_men_follo.html - abgerufen 24.01.2013
13et al. erreicht eine Precision von 93,8% bei der Bestimmung von Zukunftsereignissen in ei- nem Tweet zu einem Thema. Verbesserungen könnten erreicht werden, indem eine bessere Sprachverarbeitung genutzt wird, um Zeitformen zu identifizieren [JS11]. Gupta et al. „Credibility Ranking of Tweets during High Impact Events” Gupta et al. [GK12] haben in ihrer Arbeit festgestellt, dass durchschnittlich 30% des In- halts eines Tweets relevante Informationen über ein Ereignis waren, 14% des Inhalts jedoch Spam war. Gerade einmal 17% aller Tweets über ein Ereignis enthielten darüber glaubwür- dige Informationen, welche das Situationsbewusstsein über das Ereignis erhöht haben, also aus welchen ein besseres Verständnis über ein Ereignis gewonnen werden konnte. Der von Gupta et al. [GK12] entwickelte Algorithmus analysiert die Glaubwürdigkeit von Tweets auf Tweetebene, unabhängig vom Thema, im Gegensatz zu der Arbeit von Castillo et al., welche sich darauf beschränkt, Trending Topics auf ihre Nachrichtentauglichkeit zu bewerten. Da- bei hatten Castillo et. al mit einem C4.5 Entscheidungsalgorithmus eine Genauigkeits- und Trefferquote von 70-80% erreicht. Problematisch ist dabei, dass zwar ein Thema erkannt wurde und dies auch glaubwürdig sein kann, aber die Tweets dazu eventuell unglaubwürdig sind. Gupta et al. nutzten Techniken zum automatischen Ranken von Tweets über Supervi- sed Machine Learning und Pseudo Relevance Feedback. Im ersten Schritt ihrer Arbeit wurde ein Grundstock an durch Menschen klassifizierte Tweets erstellt, mit dem später die Lernal- gorithmen für Maschinelles Lernen angelernt werden. Dabei wurden zu jedem Thema zufällig 500 Tweets ausgewählt und nach den Kriterien „definitiv glaubwürdig”, „scheint glaubwür- dig”, „definitiv unglaubwürdig”, „unentschlossen”, „gehört zu dem Nachrichtenthema, aber ohne Information”, „gehört nicht zum Thema” oder „überspringen” durch die Tester bewer- tet. Für das erste Ranking der Tweets werden dann bestimmte Eigenschaften der Tweets genutzt, um sie miteinander zu vergleichen. Über eine Regressionsanalyse des Anfangssets konnten sie dabei die wichtigsten Eigenschaften eines Tweets, mit denen man am besten die Glaubwürdigkeit bestimmen kann, herausfinden. Diese sind tweetbasiert z.B. die Anzahl ein- zigartiger Buchstaben, von Schimpfwörtern, Pronomen und Emoticons. Nutzerbasiert sind es beispielsweise die Anzahl an Followern, sowie die Länge der Nutzernamen. Tabelle 3.1 zeigt dabei genauer die betrachteten Eigenschaften. Die Tweets werden nun durch deren Ei- genschaften mittels RankSVM2 gerankt. RankSVM trainiert eine Ranking Support Vector Machine [Joa02] auf einem Trainingsset, gibt die gelernten Regeln in einer Modelldatei aus und bewertet anhand dieses Modells eine Menge von Tweets. Weiterhin benutzten Gupta et al. Pseudo Relevance Feedback als Re-Ranking-Algorithmus zum Verbessern der besten Ergebnisse aus dem ersten Ranking durch ein erneutes Bewerten der Ergebnisse über ein zweites Maß. Im Folgenden wird genauer auf den Ablauf des Algorithmus eingegangen. Zuerst werden die Eigenschaften aus den zu rankenden Tweets extrahiert und diese mittels des RankSVM- Algorithmus, welcher das Anfangsset aus manuell annotierten Tweets als ersten Vergleichs- wert nimmt, gerankt. Nun werden die Tweets nach ihrem Rankingwert sortiert. Der Re- Ranking-Algorithmus ist am effektivsten, wenn die Vergleichstweets möglichst gute Ergeb- nisse in dem ersten Ranking erhalten haben. Deswegen werden aus dieser Menge an sortier- ten Tweets nur die besten K Tweets weiter benutzt. Aus den besten K Tweets werden die häufigsten Unigramme extrahiert. Diese werden genutzt, um die Text-Ähnlichkeit zwischen den besten Unigrammen und den besten K Tweets zu berechnen. Dazu wurde von Gupta et al. das BM25-Maß benutzt. Das erstellte Ranking aus der Textähnlichkeit wird genutzt, um die Menge von K Tweets erneut nach diesem neuen Rankingwert zu sortieren. Das Ergebnis der Arbeit von Gupta et al. zeigt, dass es nicht nur wichtig ist, wer die Tweets ver- öffentlicht, sondern auch die Qualität der Veröffentlichungen einer Person. Außerdem zeigt das Re-Ranking mittels der am häufigsten benutzten Terme bzw. Unigramme, dass neben kontextunabhängigen Eigenschaften (aus dem ersten Ranking) auch kontextspezifische Ei- genschaften dem Rankingprozess helfen können. Problematisch ist hierbei das Anlernen des RankSVM-Algorithmus. Hier muss eine Möglichkeit gefunden werden, eine Automatisierung des Prozesses zu realisieren [GK12]. Von Gupta et al. werden nur bereits vorher gesammelte Tweets betrachtet. Das durch Gupta et al. vorgestellte Ranking muss noch auf eine Taug- 2 www.cs.cornell.edu/people/tj/svm_light/svm_rank.html - abgerufen 27.1.2013 14
TwiNex 3.3 Erstellen eines Nutzerrankings
Nachrichtenbasiert
Tweetlänge, Anzahl an Wörtern, Anzahl einzigartiger Buchstaben, Anzahl an Hash-
tags, Anzahl an Schimpfwörtern, Anzahl an positiven Wörtern, Anzahl an negativen
Wörtern, Tweet ist ein Retweet, Anzahl spezieller Symbole, Anzahl an Emoticons,
Tweet ist eine Antwort, Anzahl an @-Erwähnungen, Anzahl an Retweets, Vergange-
ne Zeit seit Publikation, hat URLs, Anzahl an URLs, Nutzung eines URL-Shortener
Service
Nutzerbasiert
Registrationsalter des Nutzers, Anzahl an Statusmeldungen, Anzahl an Followern,
Anzahl an Freunden, ob der Account verifiziert ist, Länge der Accountbeschreibung,
Länge des Nutzernamens, hat eine URL, Rate von Followern zu Folgenden
Tabelle 3.1: Eigenschaften eines Tweets zur Glaubwürdigkeitsanalyse [GK12]
lichkeit in einer echtzeitbasierten Anwendung überprüft werden, da bei ihrer Arbeit das
vorherige Erstellen einer Referenzmenge an kategorisierten Tweets fehlt und deshalb noch
unklar ist wie performant ihre Algorithmen arbeiten.
3.3 Erstellen eines Nutzerrankings
Neben des Rankings der Tweets nach ihrer Glaubwürdigkeit, sollen auch Nutzer nach ihrer
Popularität auf Twitter oder zu einem Thema gerankt werden. Wegen der Limitierungen
der Twitter API muss eine gute Auswahl an Nutzern, die als Quelle für Nachrichtentweets
dienen, getroffen werden. Dies hilft unter anderem dem Aufbau einer guten Nutzerbasis,
da durch die große Masse an Tweets auch viele Nutzer in den Fokus eines twitterbasierten
Nachrichtendienstes rücken. Es müssen zuverlässige Nutzer in der großen Masse gefunden
werden, indem nur die besten Nutzer eines Rankings betrachtet werden. Lag bisher der
Fokus auf der Glaubwürdigkeit eines Nutzers, um die Information innerhalb eines Tweets
einschätzen zu können, liegt der Fokus bei dem im Folgenden vorgestellten Nutzerranking
auf den verschiedenen Möglichkeiten die Popularität eines Nutzers zu ermitteln und mit
anderen zu vergleichen.
Kwak et al. „What is Twitter, a social network or a news media?”
Kwak et al. [KLP+10] haben in ihrer Arbeit What is Twitter, a social network or a news
media? die Topologie von Twitter betrachtet und dabei die Nutzerstrukturen analysiert. Sie
führten auch ein Ranking der Nutzer nach verschiedenen Kriterien durch. Ihr Ziel war es,
Nutzer nach ihrer Popularität zu sortieren. Sie haben festgestellt, dass dieses Problem gleich-
bedeutend dem Ranking von Webseiten auf Basis ihrer Verlinkung untereinander ist. Für
das Ranking haben sie daher drei unterschiedliche Methoden vorgestellt. Als erstes wurden
die Nutzer nach der Anzahl der Follower gerankt. Hier wurde festgestellt, dass hauptsächlich
bekannte Persönlichkeiten, Institute, Firmen oder Organisationen auf den oberen Plätzen
erscheinen, da diese sehr viele Follower besitzen. Die zweite Möglichkeit, Nutzer zu ranken
leiteten sie von dem Vergleich zu Webseiten ab. Sie nutzten den von Page et al. [PBM+98]
vorgestellten PageRank, um Nutzer im gesamten Kontext aller Nutzer zu ranken. Dabei ist
ein Nutzer gleichbedeutend einer Webseite und die Verbindung Follower zu Gefolgtem gleich-
bedeutend eines Links zu einer Webseite. Bei diesem Ranking nach PageRank im Netzwerk
der Follower zu Gefolgtem, stellten sie fest, dass eine starke Ähnlichkeit zu dem Ranking
nach der Anzahl der Follower besteht. Die letzte Art des Rankings, welche betrachtet wurde,
war ein Ranking über die Anzahl der Retweets eines Nutzers. Hier wurde ein starker Un-
terschied zu den ersten beiden Rankings festgestellt. Vor allem Nachrichtenagenturen und
ähnliche Organisationen waren höher gerankt. Auch unabhängige Nutzer, welche häufig über
Nachrichten berichteten, waren höher platziert [KLP+10]. Eine Schlussfolgerung daraus ist,
dass die Anzahl der Retweets ein besseres Ranking für nachrichtenrelevante Nutzer ergeben
kann. Es muss jedoch das Verhältnis von Followern zu Retweets untersucht werden. Tweets
eines Nutzers mit vielen Followern werden häufiger retweeted als Tweets eines Nutzer mit
15wenigen Followern. Dies wird in dem Papier von Kwak et al. [KLP+10] nicht betrachtet. In ihrem Papier wird auch, im Gegensatz zu dieser Arbeit, mit einem großen Bestand an vorher heruntergeladenen Daten gearbeitet, um Nutzer zu ranken. Das Ranking der Nutzer nach Popularität soll bei dieser Arbeit vor allem ereignisbezogen stattfinden, im Gegensatz zu der von Kwak et al. [KLP+10] durchgeführten globalen Betrachtung aller Nutzer von Twitter. 3.4 Auswerten von Zusatzinformationen Nachdem die nützlichen Tweets für Nachrichten gefunden und dann miteinander verbunden wurden, kann man nun beginnen, Tweets nach Zusatzinformationen auszuwerten, um die Nachrichtenmeldungen zu ergänzen, da meistens in den 140 Zeichen Text eines Tweets auch geographische Informationen sowie Links zu externen Artikeln oder Webseiten eingebettet sind. Bei dem Service „TwitterStand” von Sankaranarayanan et al. [SST+09] erfolgt dies durch Geotagging der einzelnen Tweets. Dazu werden die Geodaten des Tweets und die In- formationen der externen Links benutzt. Die gefundenen Daten werden dann genutzt, um den geographischen Fokus eines Clusters zu bestimmen. Dies ist nicht nur eine zusätzliche Information für die Nutzer des Dienstes, es ist auch gut, um das Finden passender Tweets zu einem Cluster zu vereinfachen. Das Geotagging erfolgt dabei in zwei Schritten. Zuerst findet die Toponymerkennung statt. Dabei werden alle geographischen Referenzen in einem Tweet gefunden. Danach findet die Toponymresolution statt. In diesem Schritt wird die Position der gefundenen Orte auf einer Karte bestimmt, also deren Koordinaten herausgefunden. Bei der Toponymerkennung muss vor allem beachtet werden, dass der Text in Tweets nur wenige Informationen liefert und deswegen keine gewöhnlichen Algorithmen wie POS oder NER benutzt werden können [SST+09]. Die Lösung ist ein Ortsverzeichnis, welches den TF-IDF-Index eines Clusters nach bekannten Ortsnamen durchsucht. Für die Toponymre- solution ist auch die Kürze der Texte ein Problem. Deswegen werden in „TwitterStand” die referenzierten Links nach Informationen untersucht wenn sich herausstellt, dass es Nach- richtenartikel sind. Dazu benutzen Sankaranarayanan et al. die Algorithmen, welche sie in „STEWARD” und „NewsStand” entwickelt haben [SST+09]. Da diese Informationen nicht immer zur Verfügung stehen, wird in mehreren Stufen aus den aktuell vorhandenen Daten gefiltert, um so mit einer maximalen Genauigkeit den geographischen Fokus zu bestimmen. Zuerst werden die Tweet-Metadaten ausgewertet. Dies ist zum Beispiel der Herkunftsort des Twitternutzers. Diese Information ist meistens sehr genau aber nicht immer automatisch der Ort, an dem das Ereignis stattfindet. Um noch besser den Fokus bestimmen zu können, werden die gefundenen Geodaten-Referenzen nach ihrem Vorkommen im Cluster gerankt. Es bestimmen die am häufigsten auftretenden Orte den geografischen Fokus. Eine weitere Informationsquelle, welche Sankaranarayanan et al.[SST+09] auswerten, sind die Hashtags, die in einem Cluster zu einem Thema gesammelt werden. Sie werden ab- sichtlich nicht ausschließlich zum Finden gemeinsamer Tweets genutzt, da es sonst zu einer starken Fragmentierung kommen würde. Die Hashtags fließen in die normale Bewertung des Tweets nach seinem TF-IDF-Maß ein. Später werden sie jedoch benutzt, um auf der Suche nach neuen Informationen zu einem Thema, dazugehörige Tweets besser finden zu können [SST+09]. 3.5 Zusammenfassung Stand der Forschung Der aktuelle Stand der Forschung zeigt, dass schon verschiedene Konzepte, welche Tweets als Nachrichtenquelle nutzen, existieren. Die vorgestellten Arbeiten behandeln dabei die unterschiedlichen Problemfelder. Das Ziel aller ist, möglichst gut die großen Menge an an- kommenden Tweets zu schnell verarbeiten, passende Tweets zu filtern und kategorisieren. Es wurde auch festgestellt, dass es wichtig ist, vertrauenswürdige Nutzer und Tweets zu finden. Mit dem System „TwitterStand” von Sankaranarayanan et al. [SST+09] wurde ein fertiges Twitter-Nachrichtensystem entwickelt. In ihrer Arbeit liegt der Fokus auf der Be- handlung des großen Hintergrundrauschens durch die Spamtweets und der hohen Rate an neu ankommenden Tweets. Verbesserungen dieses Systems können dann durch die anderen 16
Sie können auch lesen

















































