Unstrukturierte Daten sind Tickets für den Geschäftserfolg
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

Kommentar von Dr. Hans Holger Rath, Attensity Europe
Unstrukturierte Daten sind Tickets für
den Geschäftserfolg
08.10.14 | Autor / Redakteur: Dr. Hans Holger Rath / Nico Litzel
Mithilfe der Textanalyse-Technik können Unternehmen unstrukturierte Daten zur Verbesserung von
unterschiedlichen Bereichen einsetzen. (Bild: Attensity Europe)
Big Data gehört zu den Megathemen für Unternehmen schlechthin. Allerdings
vergessen dabei Unternehmen zumeist die geschäftsentscheidenden
Informationen, die in unstrukturierten Daten wie E-Mails oder Social-Media-
Beiträgen verborgen sind. Erst durch die Einbeziehung dieser Texte bei der
Business-Intelligence-Analyse werden aus Daten Tickets für den
Geschäftserfolg.
„Trends“, „Big Data“, „2015“ – allein schon diese beiden Begriffe und eine Zeitangabe
vermitteln einen Eindruck von der immensen Informationsfülle zum Thema Big Data:
Innerhalb von 0,38 Sekunden hat die Suchmaschine Google etwa 37.100.000 Seiten
mit diesen zwei Begriffen und dieser Zahl gefunden. Im Fall des Begriffs „Big Data“
sind es sogar etwa 609 Millionen Seiten. Weltweit werden in jeder Minute 1,7
Trillionen Bytes an Daten generiert. Das entspricht etwa 360.000 DVDs. Etwa alle
zwei Jahre verdoppelt sich das Datenvolumen.
Bei jedem Einkauf in einem Online-Shop, bei jedem mit anderen Usern geteilten Foto
Seite 1 / 8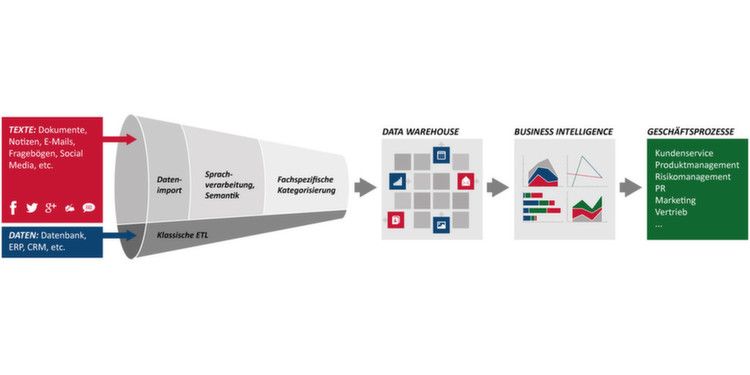
auf Facebook oder bei jedem Aufruf eines Stadtplans mit dem Smartphone etc.
werden Daten erzeugt. Das gilt ebenso in der Unternehmenswelt, wo Technologien
wie Sensorik und RFID oder die Kommunikation über Social-Media-Kanäle wie
Twitter, Facebook, Google+ oder YouTube das Datenvolumen exponentiell nach oben
treiben.
Es werden jedoch nicht nur Daten generiert, sondern auch wettbewerbsrelevante
Informationen. Jeder Kontakt mit einem Unternehmen hinterlässt beim Konsumenten
Eindrücke und schafft Erfahrungen, die wiederum Äußerungen in den sozialen
Netzwerken auslösen können. Manche Unternehmen speichern denn auch
mittlerweile bereits Daten im Petabyte- und verarbeitet täglich Daten im dreistelligen
Terabyte-Bereich. Die schnell wachsenden Datenvolumina fordern den Einsatz von
leistungsfähigen Big-Data-Technologien heraus. Aber nicht nur das Tempo ist eine
Herausforderung, sondern auch der sehr stark wachsende Anteil unstrukturierter
Daten.
BILDERGALERIE
Fotostrecke starten: Klicken Sie auf ein Bild (1 Bilder)
Unstrukturierte Daten: Faktor 1.000 an Relevanz
Derzeit nutzen Unternehmen in erster Linie noch strukturierte Daten zum Beispiel aus
ERP-Systemen und Datenbanken, die sie mit klassischen Business-Intelligence-
Anwendungen analysieren lassen. Aber das ändert sich gerade – auch wegen der
immer selbstverständlichen Nutzung der neuen Kommunikationskanäle im Social
Web mit ihren unstrukturierten Daten. Forrester Research hat in einer Umfrage
herausgefunden, dass unstrukturierte Daten für Unternehmen etwa 1.000 Mal
relevanter sind als strukturierte Daten. Allerdings verfügt laut einer Untersuchung der
„Computerwoche“ nicht mal jeder zehnte Befragte über die notwendigen Werkzeuge,
um die geschäftsrelevanten Informationen aus unstrukturierten Daten zu extrahieren
und zu analysieren.
Unstrukturierte Daten sind Texte wie E-Mails, Dokumente, Fragebögen,
Seite 2 / 8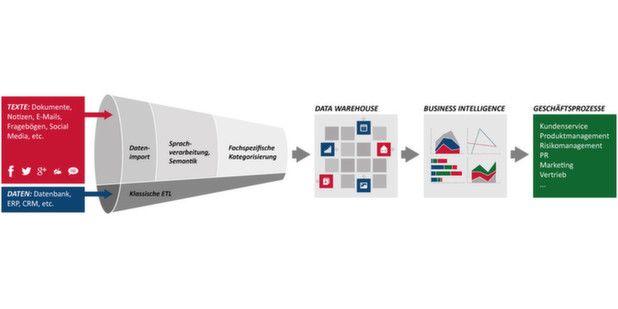
Kundendienstnotizen, Pressemitteilungen, Online-Seiten der Medien, Website-
Content von Unternehmen etc., Blogs, Foren, Produktrezensionen und verstärkt
Social-Media-Plattformen wie Twitter, Facebook, Google+, YouTube etc.
Unternehmen finden hier wichtige Informationen über Wettbewerber, Lieferanten und
Kunden, erhalten Feedback auf ihre Produkt-, Dienstleistungs- und Serviceangebote
und ihrem Image.
Unternehmen können mithilfe der Textanalyse-Technik unstrukturierte Daten zur
Verbesserung der unterschiedlichen Bereiche einsetzen wie:
Produktentwicklung: Sie benötigt Informationen über die Defizite der Produkte
aus Sicht der Kunden, über die Wünsche und Verbesserungsvorschläge. Die
Produktentwicklung ist an der aktuellen Kundenzufriedenheit genauso interessiert
wie an den neusten Markttrends und Informationen über den Wettbewerb.
Marketing: Vor allem Kennzahlen zur Erfolgsmessung einzelner Kampagnen bietet
die Textanalyse dem Marketing. Und mit dem bereitgestellten Wissen, welche
Produkteigenschaften besonders gefallen bzw. missfallen und wie der Wettbewerb
dasteht, kann es Kampagneninhalte gezielter steuern.
PR: Die Unternehmenskommunikation ist insbesondere an der positiven
Wahrnehmung des Unternehmens und der Platzierung ihrer Kernbotschaften
interessiert. Sie möchte zudem auftretende Kommunikationskrisen wie Shitstorms
möglichst früh erkennen, um Gegenmaßnahmen ergreifen zu können. Die
Textanalyse stellt ihr die notwendigen Informationen bereit.
Betrugsermittlung: In Versicherungen zum Beispiel sucht die Abteilung zur
Verhinderung und Aufdeckung von Betrugsdelikten nach Indikatoren, die auf einen
Betrugsversuch hindeuten. Neben den strukturierten Daten zum Versicherungsfall
sind dabei auch die textuellen Schadensmeldungen zentral.
Kundenservice: Sein Fokus liegt auf der Messung und Optimierung der
Servicequalität. Die Textanalyse unterstützt ihn bei der Ressourcenplanung und -
ausbildung, da sie ihm die notwendigen Informationen zu sich abzeichnenden
steigenden Anfragevolumina und neue Fragestellungen geben kann – durch die
Auswertung des Kunden-Feedbacks, der Notizen der Servicemitarbeiter und der
Social-Media-Beiträge.
Das Potenzial, das in diesem enorm hohen Volumen unstrukturierter Daten
schlummert, kann jedoch nur gehoben werden, wenn die Analyse präzise und
umfassend auf die unternehmensspezifischen Fragestellungen in Echtzeit eingeht.
Um insbesondere die vielen Beiträge im Social Web schnell und präzise auswerten zu
können, muss auf der ersten Stufe ein Monitoring-Tool für Social Media automatisch
die gesuchten Beiträgen recherchieren. Im Textanalyse-Tool werden dann die Texte
Seite 3 / 8geladen und die unstrukturierten in strukturierte Daten übersetzt.
Im Text verborgene Informationen extrahieren
Die als Natural Language Processing (NLP) bezeichnete Technologie nutzt Methoden
der Computerlinguistik, um die im Text verborgenen Informationen aus diesem zu
extrahieren. Die Verarbeitung verläuft schrittweise von der Vorverarbeitung über die
Textzerlegung in Sätze bis zur Wandlung der Worte in seine grammatikalische
Grundform. Durch das computerlinguistische Verfahren „Exhaustive Extraction“
werden daraus die für die Analyse relevanten Informationen bestimmt: Begriffe,
Entitäten, Fakten, Kernaussagen und Ausdrucksformen. Der Vorteil des Verfahrens:
Gleiche Texte können zu unterschiedlichen Fragestellungen analysiert werden. So
können zum Beispiel E-Mails an den Kundenservice auf Beschwerden mit Blick auf
die Servicequalität und auf etwaige Produktprobleme hin untersucht werden.
Allerdings erwarten Fachabteilungen von der Textanalyse Antworten auf ihre
Fragestellungen, die mehr als einzelne Begriffe, Fakten und Kernaussagen umfassen.
Aus gutem Grund: Will die Marketing-Abteilung beispielweise von der Analyse wissen,
warum Kunden zum Wettbewerb wechseln, benötigen sie für ihre
Geschäftsentscheidungen eine differenzierte Auswertung und eine Gruppierung
zusammengehörender Kernaussagen. Genau diese Aufgabe übernehmen
Kategorien, die auf der dritten Stufe des Prozesses ins Spiel kommen: Sie
repräsentieren die fachspezifischen Fragestellungen der Analyse. Eine hierarchische,
baumartige Gliederung der Kategorien sorgt – vergleichbar mit einer Klassifikation –
dafür, dass die Analyseergebnisse dem jeweils gewünschten Detailierungsgrad
entsprechen.
Bei der Exhaustive Extraction werden die Kategorien in einem separaten Schritt
befüllt. E-Mails an den Kundenservice können so beispielsweise auf Beschwerden mit
Blick auf die Servicequalität (interessant für den Leiter des Kundenservice) oder auf
Produktprobleme (interessant für den Produkt-Manager) hin untersucht werden.
Begriffe, Fakten oder Kernaussagen werden dabei den Kategorien zugeordnet.
Textanalyse wandelt Big Text Data in Smart Data
Die in den Texten behandelten Themen werden in einem nächsten Schritt in den
Themenkategorien erfasst. Die Relevanz der Themen ergibt sich einerseits aus der
Fragestellung, andererseits aus der Häufigkeit des Themas in den untersuchten
Texten. Typische Themen für eine Marketing-Fragestellung sind zum Beispiel die
Namen der Wettbewerber, die Produkte, Produkteigenschaften, die im Kontext eines
Wechsels von Kunden genannt werden, und die Gründe für den Wechsel zu einem
Wettbewerber. Die relevanten Fakten und Kernaussagen werden dann in den
Aussagenkategorien dargestellt. Unterschieden wird dabei zwischen tonalen und
nicht-tonalen Aussagen, wobei tonale Aussagen die Meinung bzw. Einstellung
Seite 4 / 8(Tonalität oder Sentiment) widerspiegeln.
Nach der Ermittlung der vorkommenden Begriffe, Entitäten, Fakten und
Kernaussagen und der Zuordnung zu Kategorien durch die Textanalyse werden auf
der letzten Stufe diese Informationen zusammen mit den Dokument-Metadaten im
Data Warehouse abgespeichert. Am Ende dieses Prozesses sind aus den
unstrukturierten Texten strukturierte Daten geworden, die integrativ zusammen mit
anderen strukturierten Unternehmensdaten von der Business Intelligence analysiert
werden können. Dann wird aus Big Text Data auch Smart Data – und Unternehmen
können einen entscheidenden Informationsvorsprung vor dem Wettbewerb erhalten.
ERGÄNZENDES ZUM THEMA
Von unstrukturierten zu strukturierten Daten
Der Informationsgehalt unstrukturierter Zeichenketten (Textdaten) findet sich in den
hintereinandergereihten Worten, kontextabhängigen Bedeutungsvarianten und
grammatikalischen Feinheiten. Um diese Informationsschatz zu heben, müssen die Texte bzw.
die darin enthaltenen Informationen zunächst einmal in eine strukturierte Form übersetzt
werden. Mit der Technologie der Textanalyse können dann die un- und schwach strukturierten
Texte in strukturierte Daten übersetzt werden, sodass große Textmengen automatisiert
gelesen und mittels Business Intelligence analysiert werden können.
Bestimmung der relevanten Informationen
Begriffe: Sie umfassen alle Substantive und Verben des Dokuments. Allein aus den
extrahierten Begriffen kann schon der ungefähre Inhalt des Textes abgeleitet werden.
Entitäten: Sie gruppieren Begriffe nach deren Bedeutung (Semantik), indem sie ihnen
einen Typ zuweisen und synonyme Schreibweisen eines Begriffs in einer Entität
zusammenfassen. Beispiele für Entitätstypen (und Entitäten) sind Unternehmen
(Daimler AG, Allianz SE, Lufthansa AG), Person (Angela Merkel, Kai Diekmann, Nico
Rosberg), Land (Deutschland, Italien, USA), Zeitangabe (gestern, 5 Minuten, 14 Tage),
URL (http://www.bigdata-insider.de), Hashtag (#epic, #fail, #wm2014). Entitäten sind
entweder als Wortlisten (Unternehmen, Land), reguläre Ausdrücke (URL, Hashtag)
oder grammatikalische Regeln (Person, Zeitangabe) definiert. Sie können genereller
Natur und vom Anbieter des Textanalyse-Systems vordefiniert sein oder werden
projektspezifisch definiert und bringen so die fachspezifische Semantik ein. Beispiele
für projektspezifische Entitätstypen sind Produktname und Produktkomponente.
Fakten: Die zweistelligen Wortkombinationen werden aus Substantiv und Verb oder
Adjektiv gebildet. Fakten verknüpfen zwei zusammengehörende Wörter und
repräsentieren deshalb bereits wesentliche Zusammenhänge des Texts. Beispiele sind
„Auto:schnell sein“, „Telefontarif:teuer sein“, „ich:mögen“, „sie:hassen“.
Seite 5 / 8Kernaussagen: Diese Wortkombinationen bestehen aus Subjekt, Prädikat, Objekt.
Durch das zusätzliche Objekt des Satzes repräsentieren sie die wesentlichen
Aussagen der Texte. Beispiele: „ich:mögen:BigData-Insider.de“, „sie:hassen:Betrüger“,
„Tablet:verdrängen:PC“.
Ausdrucksformen: Sprache kennt viele Formen, die einen Fakt bzw. eine
Kernaussage in einem anderen Licht erscheinen lassen wie zum Beispiel: Ich werde
meinen Vertrag nicht kündigen. Soll ich meinen Vertrag kündigen? Wenn mich niemand
zurückruft, kündige ich meinen Vertrag. Ich will meinen Vertrag kündigen. Ich habe
gestern meinen Vertrag gekündigt. Ausdrucksformen wie Negation, Frage, Bedingung,
Absicht, Vergangenheit ergänzen die Fakten bzw. die Kernaussagen entsprechend, so
dass diese Informationen bei der Analyse zur Verfügung stehen. Zum Beispiel
„Telefontarif:teuer sein [Negation]“, „ich:kündigen [Absicht]:Vertrag“.
Copyright © 2014 - Vogel Business Media
Dieser Beitrag ist urheberrechtlich geschützt.
Sie wollen ihn für Ihre Zwecke verwenden?
Infos finden Sie unter www.mycontentfactory.de.
Dieses PDF wurde Ihnen bereitgestellt von http://www.bigdata-insider.de
Seite 6 / 8Mithilfe der Textanalyse-Technik können Unternehmen unstrukturierte Daten zur Verbesserung von
unterschiedlichen Bereichen einsetzen. (Bild: Attensity Europe)
Seite 7 / 8Der Autor: Dr. Hans Holger Rath ist Senior Product Manager bei Attensity Europe (Bild: Attensity Europe)
Seite 8 / 8Sie können auch lesen

















































