Vorlesung: Datenverarbeitung - Sommersemester 2021 Thema: 3. Statistiks mit MS Excel - HTW Dresden
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Vorlesung: Datenverarbeitung Sommersemester 2021 Thema: 3. Statistiks mit MS Excel Prof. Dr. S. Kühn Fachbereich Informatik/Mathematik Raum: S 315a Email: skuehn@informatik.htw-dresden.de
3.1. Einführung
Statistik ist die Zusammenfassung bestimmter Methoden, um empirische Daten
zu analysieren.
• Ausgehend von den Rohdaten versucht die Statistik, Informationen über das
betrachtete System zu gewinnen.
• Das Reduzieren des Informationsgehaltes der Rohdaten, kann das Bild auf das
“Wesentliche" freigeben.
Eine der grundlegendsten Aufgaben der Statistik:
• Angabe eines Messergebnisses, das aus mehreren Messungen besteht
• mit Vertrauensbereich (wie genau ist das Messergebnis).
Fehlerarten von analytischen Messungen:
• Fehler der 1. Art: Zufallsfehler – unterschiedliche Quellen
(Ablesefehler, elektronisches Rauschen, zufällige Druckschwankungen, …)
• Fehler der 2. Art: Systematische Fehler – Beeinflussung aller Einzelmessungen
(defektes Messgerät, falsche Versuchsbedingungen, usw.)
LV Datenverarbeitung 3. Statistik mit Excel 2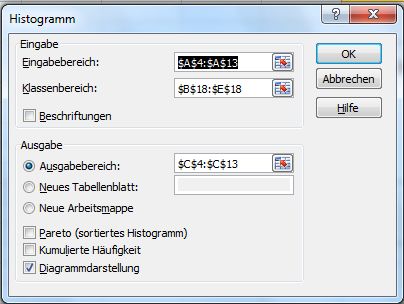
Grundgesamtheit und Stichprobe
Grundgesamtheit ist die Menge aller Elemente des untersuchten Systems,
die Stichprobe dagegen nur eine Auswahl aus dieser Grundgesamtheit.
Bsp.: Messungen in der Chemie
• Grundgesamtheit: Menge aller möglichen Nitrat-Messungen
der Brunnen einer Region (unendlich viele)
• Stichprobe: 200 Messungen
Konsequenzen:
• Statistische Kenngrößen (z.B. Mittelwert) unterscheiden sich, je nachdem ob
Werte aus der Grundgesamtheit oder aus Stichprobe ermittelt werden.
• Unterschiedliche Stichproben aus einer Grundgesamtheit, ergeben unter-
schiedliche Werte bei den gleichen statistischen Kenngrößen.
• Übereinstimmung zwischen statistischen Parameter der Stichprobe
und Parametern der Grundgesamtheit ist um so genauer, um so größer
die Stichprobe ist.
• Die Wahl der Stichprobe beeinflusst die Werte der statistischen Kenngrößen.
Bsp.: Wahlverhalten zur Bundestagswahl – ländliche/städtische Bevölkerung
LV Datenverarbeitung 3.1. Einführung 3
3.2. Statistische Kenngrößen
Mittelwert (zentrale Tendenz)
Excel-Funktionen:
• MITTELWERT
• MITTELWERTA ist ähnlich zu Funktion MITTELWERT, in die Berechnung gehen aber
Zellen mit Buchstaben oder logischen Ausdrücken mit ein.
Zellen mit Text bzw. mit log. Falsch erhalten den Wert 0, mit log. Wahr den Wert 1.
• GESTUTZMITTEL (Mittelwert ohne Ausreißer): Über einen Prozentsatz ist
anzugeben, wie viel Extremwerte vom Mittelwert auszuschließen sind.
Bsp.: 22, 20, 38, 100, 30, 25; PS: 40%
Gestutztmittel: 28,75
• MEDIAN (mittlerer Wert aus einer Gruppe von Zahlen)
Der Median ist der mittlere Wert der sortierten Zahlen.
Bsp.: 22, 20, 38, 100, 30, 25
Median: 27,5
LV Datenverarbeitung 3. Statistik mit Excel 4Modalwert
Liefert den häufigsten Wert,
der in der Zahlengruppe vorkommt.
Streuung (Abweichung vom Mittelwert)
Excel-Funktionen
• Varianz einer Stichprobe: VAR.S() • Varianzen der Grundgesamtheit: VAR.P()
n n
s = n1−1 ∑ ( xi − xm)
2 2
σ = 1n ∑ ( xi − xm) 2
2
i =1 i =1
Standardabweichung
Excel-Funktionen
• STABW.S() einer Stichprobe • STABW.N() der Grundgesamtheit
n n
s= 1
n −1 ∑ ( xi − xm)
i =1
2
σ= 1
n ∑ i
( x − xm ) 2
i =1
Vorteil gegenüber Varianz: Gleiche Maßeinheit wie die Messwerte !
LV Datenverarbeitung 3.2. Statistische Kenngrößen 5STANDARDISIERUNG (Berechnung der z-Werte)
Um Werte unterschiedlicher Systeme miteinander vergleichen zu, bedarf es einer
Standardisierung der Werte mittels Mittelwert xm und Standardabweichung s:
xi − xm
z=
s
Beide Prüfungen mit 67%
bestanden, haben
unterschiedliche Werte !
Z-Werte sind ein Maß
(Vielfaches) für die
Standardabweichung vom
Mittelwert einer Datenreihe.
Kann man aufgrund der
empirischen Verteilung von
einem normalverteilten
Merkmal ausgehen, so erhält
man als z-score Verteilung die
Standardnormalverteilung!
LV Datenverarbeitung 3.2. Statistische Kenngrößen 6RANG
Bestimmung der Ränge aller Werte innerhalb einer Zahlengruppe
Reihenfolge:
• 0 oder leer:
Sortierung in absteigender
Reihenfolge
• sonst: aufsteigende
Reihenfolge
LV Datenverarbeitung 3.2. Statistische Kenngrößen 7QUANTIL: Excel-Funktion QUANTIL.INKL() 80. Quantil: Gibt den Wert an, der größer ist als 80% der Werte QUANTILSRANG: Gibt an, wieviel Prozent der Werte unter einem bestimmten Wert liegen. LV Datenverarbeitung 3.2. Statistische Kenngrößen 8
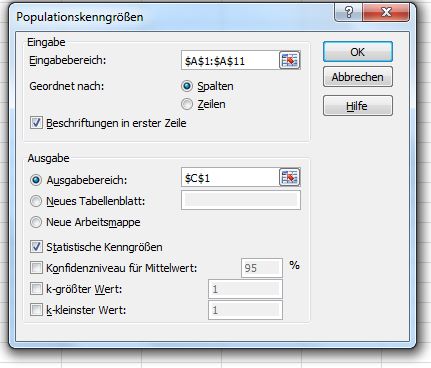
Datenanalysetool: Rang und Quantil
Über Entwicklertools/Add-Ins sind die Datenanalysetools in Excel zu laden.
Daten/Datenanalyse
Ergebnis: geordnet
ungeordnet vorher
Quantilsrang: Werte in % der
empirischen Verteilungsfunktion F(x)
LV Datenverarbeitung 3.2. Statistische Kenngrößen 9QUARTILE
Berechnet 4 Quantile (QUARTILE): QUARTILE.INKL()
25.Quantil (Zahl 1), 50.Quantil (Zahl 2), 75.Quantil (Zahl 3), 100.Quantil (Zahl 4)
Hinweise:
1. Das 50. Quantil ist gleichzeitig der Median. (auch 2.Quartil)
2. Der Median ist wesentlich weniger anfällig bei Ausreißern in den Messdaten.
Bsp.: Durchschnittseinkommen der Bevölkerung ist schief verteilt!
3. Verwendet man den Median, dann benutzt man den interquartilen Abstand
als Parameter für die Streuung der Messwerte.
Interquartiler Abstand: Wert zwischen 3. und 1. Quartil.
LV Datenverarbeitung 3.2. Statistische Kenngrößen 103.3. Histogramme
Ein Histogramm ist eine statistische Grafik (Balkendiagramm) zur Anzeige der
Häufigkeitsverteilung der Daten.
Merkmale: • Einteilung der Daten in Klassen entsprechend der Datenwerte.
• Die Klassen haben eine (hier alle die gleiche) Breite.
• Zwischen den Klassen dürfen keine Lücken existieren.
Bsp.: Punkteverteilung der Prüfungsergebnisse
Klasseneinteilung: 100-86, 85-71, 70-56, 55-41, 40-0
Daten/Datenanalyse/Histogramm
LV Datenverarbeitung 3. Statistik mit Excel 11Die relative Häufigkeit erhält man, wenn die absolute Häufigkeit durch den Stichprobenumfang n geteilt (Normalisierung) wird. Das Gesetz der großen Zahlen besagt, dass sich die relative Häufigkeit eines Zufallsergebnisses der Wahrscheinlichkeit dieses Zufallsergebnisses annähert, wenn das Zufallsexperiment unter den gleichen Voraussetzungen wiederholt ausgeführt wird (in großer Anzahl). Bsp.: Münzwurf Folglich gilt: • Eine Wahrscheinlichkeit ist also eine relative Häufigkeit für einen großen Stichprobenumfang. • Das normalisierte Histogramm für eine große Stichprobe ist die Dichtefunktion der Wahrscheinlichkeitsverteilung. LV Datenverarbeitung 3.3. Histogramme 12
Schiefe und Kurtosis
• SCHIEFE: gibt an, wie symmetrisch die Werte verteilt sind
symmetrisches rechtsschiefen oder linksschiefen oder
Histogramm linkssteilen Verteilung rechtssteilen Verteilung
Schiefe = 0 Schiefe > 0 Schiefe < 0
• KURT: Wölbung
schmalgipflig, Kurt > 0 breitgipflig, Kurt < 0
LV Datenverarbeitung 3.3. Histogramme 13Statistische Kenngrößen über Datenanalysetool / Populationskenngrößen LV Datenverarbeitung 3.3. Histogramme 14
3.4. Die Normalverteilung
NORMVERT liefert Wahrscheinlichkeiten einer normalverteilten Zufallsvariablen
für den angegebenen Mittelwert und die angegebene Standardabweichung.
• Verteilungsfunktion: NORMVERT(x, Mittelwert, Standardabweichung, Wahr)
• Dichtefunktion: NORMVERT(x, Mittelwert, Standardabweichung, Falsch)
Dichtefunktion:
− ( x − µ )2
f ( x) = σ 1
2π
e 2σ 2
(σ ... Standardabweichung , µ Mittelwert )
(Glockenkurve)
Verteilungsfunktion:
x
F ( X < x) = ∫ f ( x) dx
−∞
LV Datenverarbeitung 3. Statistik mit Excel 15Standardnormalverteilung
mit Mittelwert: 0, Standardabweichung: 1
F(1) = 0,8413
F(-1) = 0,1587
F(0) = 0,5
Der Wert der Verteilungsfunktion ist
die Fläche unter der Dichtefunktion
begrenzt von der X-Achse und der
gestrichelten Hilfslinie des x-Wertes.
NORMINV(Wahrsch;Mittelwert; Standabwn)
Ist die Umkehrfunktion von NORMVERT()
zur Bestimmung der Quantile.
LV Datenverarbeitung 3.4. Die Normalverteilung 16Bei jeder Normalverteilung finden wir innerhalb von + 1 Standardabweichung ca. 68% aller Prozessergebnisse + 2 Standardabweichungen ca. 95% aller Prozessergebnisse + 3 Standardabweichungen 99,73% aller Prozessergebnisse LV Datenverarbeitung 3.4. Die Normalverteilung 17
Aufgabe:
Es liegen Messwerte vom Nitratgehalt im Trinkwasser von 33 Brunnen einer
Gemeinde vor:
7,02; 7,48; 7,64; 7,9; 8,03; 8,17; 8,27; 8,5; 8,66; 8,67; 8,8; 8,82; 7,8; 8,1; 8,89; 8,9; 8,9;
8,92; 8,94; 8,94; 8,96; 8,99; 9,13; 9,2; 9,2; 10; 9,39; 8; 9,5; 7,61; 7,23; 7,04; 10
Die Daten sind statistisch auszuwerten :
1. Sind die Messwerte normalverteilt ?
2. Gesucht ist der mittlere Wert des Nitratgehalts der Gemeinde !
Lösung zu 1.:
Optische Überprüfung:
- Histogramm
- Form der empirischen Verteilungsfunktion (sigmoid?)
- Normalverteilungsplot (z.B. Q-Q-Test)
LV Datenverarbeitung 3.4. Die Normalverteilung 18Histogramm
Wahl der Anzahl der Klassen k bzw. Klassenbreite d, bei n Messwerten:
- k sollte > 5 sein und nicht zu groß: Näherungsfaustregeln:
k = wurzel (n) = 5,56 oder k=5*lg n = 7,46
Hier bietet sich k=6 an: damit ergibt d = (Max(Xi)-Min(Xi))/k hier d=(10-7)/6 d=0,5
1. 2. 3. 4. 5. 6.
7,0 - 7,5 7,5 – 8,0 8,0 -8,5 8,5 – 9 9 – 9,5 9,5-10
LV Datenverarbeitung 3.4. Die Normalverteilung 19Auswertung Histogramm: linksschiefe Verteilung mit der höchsten ”Dichte“
bei 8–9.
Berechnung der Populationsgrößen und deren Auswertung:
Median ist wesentlich weniger anfällig auf
schiefe Verteilungen oder Ausreißer in den
Meßdaten als Mittelwert. In unserem Bsp.
liegt Median näher am vermuteten
Mittelwert als das arithm. Mittel!
Um die Streuung der Meßwerte um den
Median zu beschreiben, gibt man die
Quartile oder den interquartilen Abstand an
und nicht die Standardabweichung (ist
immer mit Mittelwert verbunden)
LV Datenverarbeitung 3.4. Die Normalverteilung 20Form der empirischen Verteilungsfunktion
Mittelwert der NV
gleich Median –
bei empirischer =QUANTILSRANG.INKL
VF liegen nur ca.
42% aller Werte
unterhalb des
arith. Mittels
Median
Transformiert z-Werte
7,02 7,48 8,01 8,5 9,0 9,5 10,0 Messwerte
1. Quartile.ink: 8,0 3. Quartile.ink: 8,96
Interquartiler Abstand: 0,96
Auf Basis der z-transformierten Werte kann man die Werte der
Verteilungsfunktion der Standardnormalfunktion berechnen und mit der
empirischen Verteilungsfunktion bzw. mit den Quantilsrängen vergleichen.
LV Datenverarbeitung 3.4. Die Normalverteilung 21Quantil-Quantil-Diagramm
Aufteilung des Intervalls [0,1] in gleich große
Bereiche für Normalverteilung: (j-0,5)/n
Q-Q-Plot
10,50
10,00
9,50
9,00 Empirische Quantil-Werte und
8,50
Quantil-Werte der Normal-
8,00
verteilung liegen nicht wirklich
7,50
7,00
auf einer Linie, aber
6,50 annähernd…
6,5 7 7,5 8 8,5 9 9,5 10 10,5
LV Datenverarbeitung 3.4. Die Normalverteilung 22Zusammenfassung Ergebnisse des Brunnenbeispiels: 1. Es liegen genug Werte vor, um ein Histogramm zu erstellen. 2. Beim Betrachten des Histogrammes wurde deutlich, dass Daten doch deutlich von der Normalverteilung abweichen. Eine Angabe des Mittelwertes ist also wahrscheinlich nicht aussagekräftig. 3. Es wurden Mittelwert (8,53) und Median (8,8) errechnet und festgestellt, dass der Median deutlich näher am Dichtemaximum liegt, wo man ihn auch erwartet hätte. 4. Auch die Form der empirischen Verteilungsfunktion ist nicht wirklich sigmoid. 5. Ebenso zeigt der Normalverteilungsplot (z.B. Q-Q-Test), dass Normalverteilung und Werteverteilung nicht auf einer Linie liegen (was zu erwarten war). Ergebnis könnte also lauten: Der durchschnittliche Nitratgehalt der Brunnen der Gemeinde beträgt 8,8 mg/L. (Berechnet wurde der Median, da die Daten von der Normalverteilung abweichen. Der arithmetische Mittelwert beträgt 8,53 mg/L, der interquartile Abstand 0,96 mg/L ) 03.06.2021 Einführung 23
Warum haben wir den Datenbestand auf Normalverteilung getestet –
was bringt das?
• Voraussetzung für viele parametrische Tests (z.B. t-Test) und lineare
Regression
• Um ein Konfidenzinterval zu berechnen, muss man die Verteilung der
Grundgesamtmenge kennen.
• Dies ist im Fall einer endlichen Stichprobe nur möglich, falls die
Verteilungsklasse des zugrunde liegenden Merkmals bekannt ist.
• Für ein stetiges Merkmal bedeutet dies, dass eine geeignete Verteilungsklasse
ausgewählt werden muss, die geeignet ist, die wahre (unbekannte)
Verteilungsstruktur des Merkmals wieder zu geben.
Weitere Möglichkeiten für Test auf Normalverteilung:
- Analytisch - Prüfverfahren mit Hilfe statistischer Hypothesen (später)
(z.B. χ2 – Test, Kolmogorov-Smirnow-Test, Shapiro-Wilk-Test)
- Schätzmethoden (Punktschätzungen)
243.5. Parameterschätzung und Vertrauensintervalle
• Aus einer Grundgesamtheit wird eine Stichprobe gezogen (z.B. n Messungen) und
es wird der Mittelwert der Stichprobe ermittelt.
• Dieser Vorgang wird unendlich oft wiederholt (bei gleichen Stichprobenumfang) und
man erhält auf diese Weise eine Menge von Stichprobenmittelwerte.
• Diese Mittelwerte bilden eine eigene Verteilung:
Stichprobenkennwerteverteilung der Mittelwerte.
Der Mittelwert der Stichprobenverteilung ist µX und σX ist die
Standardabweichung der Verteilung (auch Standardfehler des Mittelwerts genannt).
Nach dem zentralen Grenzwertsatz gilt:
1. Wenn der Stichprobenumfang groß genug ist (n>30), dann ist die Stichproben-
verteilung des Mittelwerts in etwa normalverteilt.
2. Der Mittelwert der Stichprobenkennwerteverteilung des Mittelwerts entspricht
dem Mittelwert der Grundgesamtheit: µ =µ X
3. Die Standardabweichung der Stichprobenkennwerteverteilung des Mittelwerts
entspricht der Standardabweichung der Grundgesamtheit geteilt durch die
Quadratwurzel des Stichprobenumfangs:
σX =σ / n
LV Datenverarbeitung 3.5. Parameterschätzung und Vertrauensintervalle 25Standardfehler
Was können wir damit über den Mittelwert der Population der Nitrat-
Werte der Gemeinde sagen?
Hätten wir zig Stichproben, könnten wir mit dem Wissen, dass die
„Verteilung der der Mittelwerte“ selbst wieder normalverteilt ist, den
Mittelwert der Population bestimmen.
Leider habe wir nur eine Stichprobe
Aber: wir können die Streuung der Stichprobenkennwerteverteilung,
auch als Standardfehler (des Mittelwerts) bezeichnet, berechnen:
Der Standardfehler gibt an, wie nah ein empirischer
Stichprobenmittelwert am wahren Populationsmittelwert liegt.
Dieser Standardfehler des Mittelwertes kann auch aus einer
einzigen Stichprobe geschätzt werden:
σˆ x 2 σˆ x
σˆ x = = = 0,78095161/ √(33) = 0,135946
N N
LV Datenverarbeitung 3.5. Parameterschätzung und VertrauensintervalleStandardfehler
Der Standardfehler ist die Standardabweichung der
Stichprobenkennwerteverteilung.
Da die Stichprobenkennwerteverteilung normalverteilt ist,
kann die Wahrscheinlichkeit dafür berechnet werden, dass
der Mittelwert in einem bestimmten Intervall liegt.
Mit der Wahrscheinlichkeit von p=0.68 liegt der Mittelwert
der Gemeinde höchstens einen Standardfehler vom
Stichprobenmittelwert entfernt
8,397 < μ < 8,669Konfidenzintervalle
Sicheres Wissen über die Grundgesamtheit kann man anhand von
Stichproben nicht gewinnen.
• Aber mit Hilfe der Statistik können Intervalle, sogenannte Konfidenzintervalle,
angegeben werden, innerhalb derer die Parameter der Grundgesamtheit
wahrscheinlich liegen.
• Dazu benötigt man eine Irrtumswahrscheinlichkeit α .
Eine Irrtumswahrscheinlichkeit von 5% bedeutet, dass dieses Intervall den
gesuchten Wert der Grundgesamtheit mit einer Wahrscheinlichkeit von 95%
enthält.
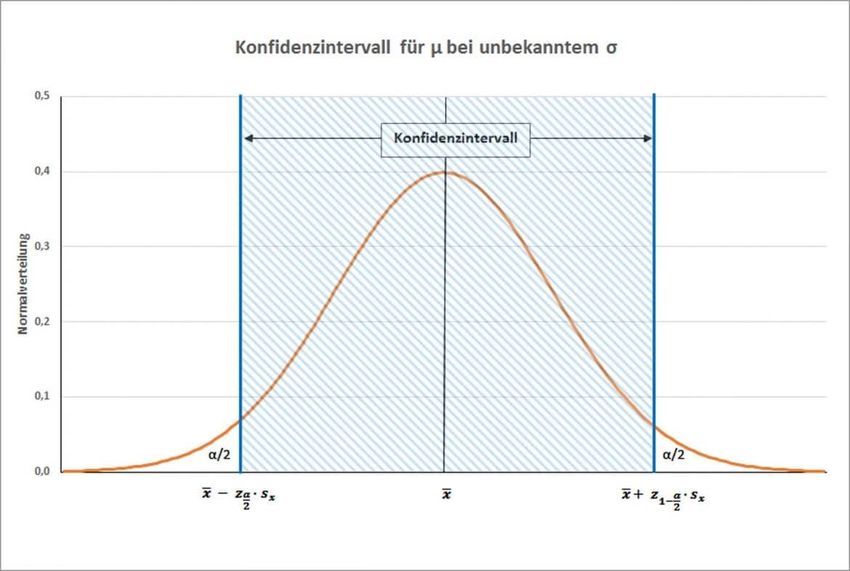
• Die linke untere Grenze des Konfidenzintervalls liegt bei:
X − Standardfehler * (1 − α / 2) − Quantilwert
(Nur für große
• Die rechte obere Grenze des Konfidenzintervalls liegt bei:
Stichprobe n>30!)
X + Standardfehler * (1 − α / 2) − Quantilwert
• Bestimmung der Konfidenzgrenzen über die Excel-Funktion KONFIDENZ:
Standardfehler * (1 − α / 2) − Quantilwert
Mit einer Irrtumswahrscheinlichkeit von 5% liegt der gesuchte Mittelwert der
Gemeinde im Intervall: 8,267 < μ < 8,8 281. Fall: Stichprobe > 30
Bestimmung der Konfidenzgrenzen über die Excel-Funktion KONFIDENZ:
NORM.INV(0,975;1,0)
KONFIDENZ( α , s, n ) = Standardfehler * (1 − α / 2) − Quantilwert
292. Fall: Kleine Stichprobe
Bei kleinen Stichproben ist die Stichprobenkennwerteverteilung des Mittelwerts eine
Student-t-Verteilung.
Die t-Verteilung ist abhängig von dem Freiheitsgrad df = n-1 (n Größe Stichprobe).
Um so größer df ist, um so mehr nähert sich die t-Verteilung der Normalverteilung an.
Bestimmung des Konfidenzintervalls über die Excel-Funktion TINV:
Die Excel-Funktion TINV gibt Quantile der t-Verteilung an.
Zweiseitiges Konfidenzintervall:
• TINV(0,05;10) = 2,28139
dabei gilt: Irrtumswahrscheinlichkeit = 0,05, df = 10
• linke untere Grenze Konfidenzintervall:
X − Standardfehler * 2,28139
• rechte obere Grenze Konfidenzintervall:
X + Standardfehler * 2,28139
Für unser Brunnenbsp: TINV(0,05;32)=2,0369
Mit einer Irrtumswahrscheinlichkeit von 5% liegt der gesuchte Mittelwert der
Gemeinde im Intervall: 8,253< μ < 8,803
LV Datenverarbeitung 3.5. Parameterschätzung und Vertrauensintervalle 30Bsp.1: Wie lange hält im Durchschnitt eine neu entwickelte Batterie mit einer
Sicherheit von 95% ?
Getestet wurden 100 Batterien mit einer durchschnittlichen Haltbarkeit von 60 h
bei einer Standardabweichung von 20 h.
1. Fall: Stichprobe > 30
Schätzung des Standardfehlers: sX = s / n =2
Vertrauensintervall (Konfidenzintervall):
• Excel-Funktion KONFIDENZ:
• Konfidenzintervall: [ X − 3,92 , X + 3,92]
[ 56,08 ; 63,92 ]
LV Datenverarbeitung 3.5. Parameterschätzung und Vertrauensintervalle 31Bsp.2: Wie Bsp.1, aber n=25, also:
Wie lange hält im Durchschnitt eine neu entwickelte Batterie
mit einer Sicherheit von 95% ?
Getestet wurden 25 Batterien mit einer durchschnittlichen Haltbarkeit von 60 h
bei einer Standardabweichung von 20 h.
2. Fall: Kleine Stichprobe
Schätzung des Standardfehlers: sX = s / n =4
Vertrauensintervall (Konfidenzintervall):
• TINV(0,05;24) = 2,0639
dabei gilt: Irrtumswahrscheinlichkeit = 0,05, df = 24
Konfidenzintervall
• linke untere Grenze: X − Standardfehler * 2,0639
• rechte obere Grenze X + Standardfehler * 2,0639
[ 52 , 68 ]
LV Datenverarbeitung 3.5. Parameterschätzung und Vertrauensintervalle 323.6. Stichproben-Hypothesentest
Beim Vergleich von Messergebnissen von verschiedenen Untersuchungen können
folgende Fragestellungen auftreten:
1. Sind die Ergebnisse zweier verschiedener Messserien gleich oder
unterscheiden sie sich signifikant voneinander ?
Z.B. unterscheiden sich die Untersuchungsergebnisse von zwei verschiedenen
Laboren signifikant oder nicht ?
2. Weicht das Ergebnis einer Messserie von einem erwarteten Wert ab ?
Z.B. ist der Gehalt einer Substanz in einer Probe gleich dem gewünschten
Wert, oder ist die Abweichung signifikant ?
Klar ist, dass die Ergebnisse von verschiedenen Labors bzw. von
unterschiedlichen Laboranten sich aufgrund der zufälligen Streuung der
Messwerte fast immer um einen gewissen Betrag unterscheiden. Die Frage ist:
Um wie viel dürfen sich die Werte unterscheiden, dass die Abweichungen noch
im Bereich der zulässigen Streuung liegen?
LV Datenverarbeitung 3.6. Stichproben-Hypothesentest 33- Nullhypothese H0 besagt: Die Daten unterscheiden sich nicht signifikant.
- Alternativhypothese H1 besagt: Die Daten unterscheiden sich signifikant.
Bei dem Test wird entschieden,
ob die Nullhypothese zu verwerfen ist oder nicht.
- Es ist nicht möglich die Nullhypothese anzunehmen.
- Es wird keine Entscheidung bez. H1 getroffen.
Vergleich von zwei Mittelwerten x1 und x2 aus zwei Stichproben mit
n1 und n2 Messwerten
H0: Mittelwerte unterscheiden sich nicht signifikant,
H1: Mittelwerte unterscheiden sich signifikant.
x1 − x2
Es wird auf die t-Verteilung geprüft mit t=
n1 + n2 (n1 − 1)s12 + (n2 − 1)s2 2
Irrtumswahrscheinlichkeit alpha und
n1 + n2 − 2
Freiheitsgrad FG = n1 + n2 -2. n1n2
Die H0-Hypothese muss abgelehnt werden,
falls t > TINV(FG;alpha).
LV Datenverarbeitung 3.6. Stichproben-Hypothesentest 343.7. Trendanalysen (ohne den math. Hintergrund zu behandeln)
Trendlinien ..... prognostizieren zukünftige Werte auf Grund bekannter Daten
bekannt: Daten der Vergangenheit
unbekannt: Daten der Zukunft
Unterscheidung der Trendlinie nach der grafischen Form
• linear: y=m*x+b
• logarithmisch: y = c * ln x + b
• Polynom: y = b + c1 * x + c2 * x2 + . . . + c6 * x6
• potentiell: y = c * xb
• exponentiell: y = c * eb*x
linearer Trend
( wird schwerpunktmäßig behandelt in LV )
Y : sind so zu bestimmen, dass der Abstand
durch die Punktwolke minimal ist !
X : Punktwolke (als Einzelpunkte
im Diagramm darstellen)
35
X YMöglichkeiten der Bestimmung der Trendlinie:
(1) Funktion: TREND
für: berechnet linearen Trend für eine Datenreihe
TREND( Y_Werte; X_Werte; neue_X_Werte; Konstante )
Y-Werte: bekannte Werte
X_Werte: bekannte Werte
neue_X_Werte: sind die neuen x-Werte, für die die Funktion TREND
die zugehörigen y-Werte liefern soll
Vorgehensweise: (Bsp.)
1. Zell-Bereich markieren: D4 : D8 (Zielbereich)
2. Funktionsassistent aufrufen: TREND-Funktion auswählen
Y-Werte: B4 : B8
abschließen mit: Strg- + Shift- + Enter-Taste
{ = TREND( B4 : B8 ) }
------------------------------------------------------------------------------
3. Zell-Bereich markieren: D9 : D13
4. Funktionsassistent aufrufen; TREND-Funktion auswählen
Y-Werte: D4 : D8
X-Werte: A4 : A8
neue_X-Werte: A9 : A13
abschließen mit: Strg-Taste + Shift-Taste + Enter-Taste
{ = TREND( D4 : D8; A4 : A8; A9 : A13) }
LV Datenverarbeitung 3.7. Trendanalysen 36(2) Funktion: SCHÄTZER
für: berechnet linearen Trend für einen Wert
SCHÄTZER( x; Y_Werte; X_Werte )
x: Datenpunkt, dessen Wert bestimmt werden soll
Y_Werte: bekannter Datenbereich
X_Werte: bekannter Datenbereich
Vorgehensweise: (Bsp.)
1. Funktionsassistent; Funktion SCHÄTZER
2. x: A14
3. Y_Werte: B4:B8
4. X_Werte: A4 : A8
SCHÄTZER( A27; D22 : D26; A22 : A26 )
Hinweis: Funktion VARIATION() berechnet Trend bei nichtlinearen Daten
LV Datenverarbeitung 3.7. Trendanalysen 37(3) Trendlinie im Diagramm hinzufügen
1. Punktwolke im Diagramm darstellen (Jahr- u. Besucher-Daten)
2. • Datenreihe markieren (mit linker Maustaste einen Einzelpunkt anklicken)
• rechte Maustaste (auf markierten Einzelpunkt)
Trendlinie hinzufügen
3. Auswahl:
• Trendtyp
Bsp.: linear
• Optionen
LV Datenverarbeitung 3.7. Trendanalysen 383.8. Korrelations- und Regressionsanalyse
Korrelation:
Welche Abhängigkeit besteht zwischen unterschiedlichen Daten ?
Bsp.: • Temperatur und Längsausdehnung eines Werkstoffes
• Ausfallrate, Laufleistung, Betriebsalter
Ein Maß für die Abhängigkeit von zwei unterschiedlichen Datenreihen
ist der Korrelationskoeffizient:
Wertebereich: 0 >= korrelRegression:
Welche funktionale Abhängigkeit besteht zwischen den Daten ?
Wie lauten die Parameter der Funktion ?
Voraussetzung: Es besteht eine Abhängigkeit;
feststellbar über Korrelationsanalyse
Arten der Regression:
• lineare Regression y=m*x+b
gesucht werden die Funktionsparameter: m (Anstieg),
b (Schnittpunkt mit y-Achse)
Funktion RGP() zur Bestimmung von m und b
• nichtlineare Regression y = b * mx
Funktion RKP() zur Bestimmung der Funktionsparameter m und b
LV Datenverarbeitung 3.8. Korrelations- und Regressionsanalyse 40lineare Regression Vorgehensweise: 1. Markierung von 2 Zellen nebeneinander für Ausgabe m und b 2. Funktionsassistent aufrufen; Funktion RGP() 3. Y-Zellbereich angeben; X-Zellbereich angeben 4. Abschluss: Strg-Taste + Shift-Taste + Enter-Taste LV Datenverarbeitung 3.8. Korrelations- und Regressionsanalyse 41
3.9. Zielwertsuche
Wie muss sich bei der Formel y = f(x) die abhängige Größe x ändern,
wenn der Ziel-Wert y vorgegeben wird ?
Bsp.: Der Drahtdurchmesser d einer zyl. Schraubenfeder wird vorgegeben, wie
ändert sich dann der Außendurchmesser De der Feder ?
Menü: Extras →Zielwertsuche
In der Zielzelle muss eine Formel
stehen, die einen Zellbezug auf die
veränderbare Zelle hat !
Hinweis: Besteht beim Zielwert
eine funktionelle Abhängigkeit von
mehreren Größen,
dann erfolgt die Zielwertsuche
über den Solver: Extras → Solver
LV Datenverarbeitung 3.9. Zielwertsuche 42Sie können auch lesen

















































