Zukunftsfähiges Edge to Cloud to Mobile Daten-management für die Land- und Ernährungswirtschaft
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
41. Tagung der Gesellschaft für Informatik in der Land-, Forst- und Ernährungswirtschaft e.V.
Zukunftsfähiges Edge to Cloud to Mobile Daten-
management für die Land- und Ernährungswirtschaft
Christian Kurze1, Christa Hoffmann2, Julian Feinauer3
Abstract: Das Internet der Dinge hat sich – wie in vielen anderen Branchen auch – in der Land- und
Ernährungswirtschaft durchgesetzt und zielt auf das Ideal einer weiteren Automatisierung,
Produktivitätssteigerung aber auch nachhaltigeren Bewirtschaftung und Produktion ab. Während
Technologien wie Apps sehr gut genutzt werden, sind Plattformlösungen, welche die Vernetzung
der verteilten Daten ermöglichen, bisher nur sehr wenig in Verwendung. Dabei zeigt sich ein starker
Unterschied zwischen der (weitgehend) standardisierten Produktion und der Lebens-
mittelerzeugung, die stark schwankenden und rauen Umgebungsbedingungen unterliegt. IoT in
produktiver Skalierung erfordert die Extraktion, Interpretation und Harmonisierung von Daten aus
verschiedensten Quellen. Während in der Lebensmittelproduktion meist kontinuierlich wieder-
kehrende Prozesse unter standardisierten Bedingungen stattfinden (Stichwort Smart Factory) sind
landwirtschaftliche Umgebungen verteilt und heterogen, d.h. es kommt präferiert sogenanntes Edge
Computing zum Einsatz, um die Latenzen in die Cloud zu minimieren. Der Artikel beschreibt und
diskutiert den Aufbau solcher Datenplattformen basierend auf neuartigen Datenbankkonzepten
(NoSQL). Am Beispiel der dokumenten-orientierten Open Source Datenplattform MongoDB
beschreiben zwei anschauliche Beispiele aus dem Bereich Smart Farming und Remote Service
Management den praktischen Einsatz.
Keywords: Datenmanagement, Datensynchronisierung, NoSQL, Edge Computing, Cloud Compu-
ting, Mobile Computing, Smart Farming, Analytics
1 Einleitung und Problemstellung
Mehr als ein Drittel aller Unternehmen nutzen das Internet of Things und Digitale Zwil-
linge zur Verbesserung ihres operativen Betriebs, zur Reduktion von Kosten sowie zur
Erstellung neuer Umsatzströme. McKinsey [Mc19] attestiert führenden Unternehmen
Kostensenkungen bzw. Umsatzsteigerungen von mindestens 15% durch den Einsatz von
IoT.
Die wichtigsten Treiber für den Einsatz des Internet of Things sind:
• Erhöhre Effizienz in Vertrieb und Service
• Erstellung neuer IoT-Produkte und Dienstleistungen
• Optimierte Geschäftsabläufe und Automatisierung
• Einsatz von Artificial Intelligence und Machine Learning
• Cloud- und Edge-Computing zur Minimierung von Latenzen und Kostenoptimie-
rung
1
MongoDB, christian.kurze@mongodb.com
2
oeconos GmbH, christa.hoffmann@oeconos.de
3
pragmatic minds GmbH, j.feinauer@pragmaticminds.de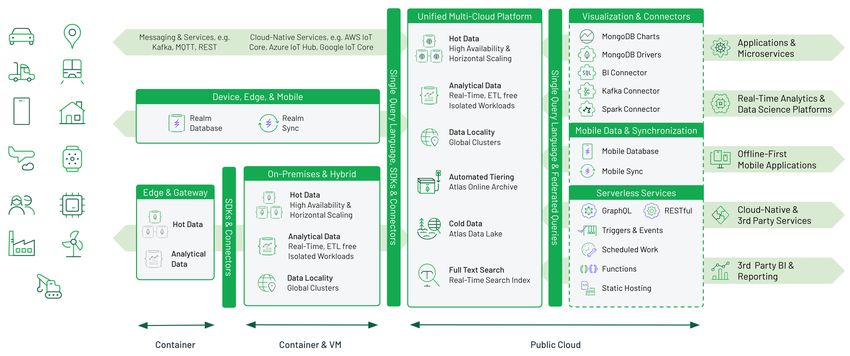
2 Christian Kurze, Christa Hoffmann, Julian Feinauer
IoT ist bereits seit einigen Jahren im produktiven Einsatz (unter teilweise weniger klang-
vollen Namen, wie z.B. Telematik), dennoch bleiben viele Herausforderungen zur Erfas-
sung und Verarbeitung von Daten auch heute bestehen:
• Viele verschiedene Datentypen aus heterogenen Umgebungen sind zu verarbei-
ten
• IoT erfordert eine konstant hohe Performance der Systeme über eine Vielzahl
von Komponenten hinweg
• Skalierbarkeit von Hunderten bis hin zu Tausenden und Millionen von Geräten
muss gewährleistet sein
• Die flexible Integration in bestehende Systeme ist sicherzustellen
• Agnostisches Deployment innerhalb der Edge, im Data Center, in der Cloud so-
wie auf mobilen Endgeräten ist notwendig
Unternehmen stehen vor der Herausforderung, sich in einer Vielzahl von Technologien
zurechtzufinden und eine geeignete Auswahl zu treffen. Hierzu starten IoT-Projekte meist
im Labor und – leider – oftmals aus einer technischen Sichtweise heraus, ohne einen hin-
reichenden Business Case zu rechnen. Diese Projekte sind im Kleinen erfolgreich, schei-
tern jedoch an der Skalierung im operativen Betreieb. McKinsey [Mc19] fasst das Kern-
problem sehr prägnant zusammen: IoT in produktiver Skalierung erfordert die Möglich-
keit, Daten aus verteilten Systemen – die niemals dazu gedacht waren, gemeinsam genutzt
zu werden – zu extrahieren, zu interpretieren und zu harmonisieren. Den Studien zufolge
scheitern heute ca. 70% der IoT-Projekte in den Produktivsetzungsphasen.
In der Praxis zeigt sich, dass ein fehlender oder unzureichender Business Case den zusätz-
lichen Aufwand meist nicht rechtfertigen kann. Bereits in frühen Phasen zeichnen sich
komplexe Infrastrukturen und hohe operative Kosten durch den Einsatz verschiedener Da-
tenbanktechnologien und oftmals fehlendem Know-How ab. Verteilte und heterogene
Umgebung von der Edge, über die Cloud bis hin zu mobilen Devices, inkl. Synchronisie-
rung von Daten, sowie die geographische Verteilung von IoT-Lösungen erhöhen die Kom-
plexität der Gesamtlösung [De19].
2 Edge to Cloud to Mobile Datenmangement in einer Plattform
Die im Folgenden vorgestellte einheitliche Plattform zum Datenmangement zeigte in einer
Vielzahl von Projekten eine drei- bis fünffache Produktivität sowie eine bis zu 70%ige
Verringerung der Gesamtkosten. Dies erstreckt sich auf die folgenden Bereiche:
• Entwicklung (durch die Nutzung einer einheitlichen Abfragesprache für Daten
an allen Stellen, inkl. historischer Daten in einem Data Lake; einheitlichen Code-
basen unabhängig vom Deployment in der Edge, im Data Center oder der Cloud;
der Möglichkeit zum Austausch von Entwicklern über verschiedene Projekt-
teams)
• Betrieb (durch die gleichen Werkzeuge und APIs zum Management konplexer
Datenplattformen, insb. bei großer Skalierung sowie im technischen Support)
Edge to Cloud to Mobile Datenmanagement 3
• Sicherheit (durch „Security by Default“ über mehrere Cloud-Provider hinweg,
einheitliche Sicherheitskonzepte für verschiedene Deployments sowie Ver-
schlüsselung „at rest“, „in flight“ und „in use“, d.h. die Nutzung von Verschlüs-
selungsmechanismen auf dem Client, sodass ausschließlich verschlüsselte Infor-
mationen übertragen und auf zentralen Servern abgelegt werden)
Die Total Cost of Ownership wird insb. durch Effekte beim Training von Entwicklern und
Betriebsteams, Efficiency of Scale im Betrieb (ein Team vs. mehrere Teams für verschie-
dene Technologien), schnelle Time to Value für neue Funktionalitäten und auch aus Sicht
der Lizenzkosten erreicht.
Die nachfolgenden Abschnitte geben einen Einblick, wie diese Vorteile gehoben werden
können.
2.1 Entwicklungsproduktivität: Das Dokumentenmodell
Nachdem sich relationale Datenbanken in den letzten 40 Jahren als Standard zur
Datenhaltung, -nutzung und -anreicherung etabliert haben, ist es an der Zeit, den
schemagebundenen Ansatz abzulösen. Das JSON-basierte Datenmodell von MongoDB
kombiniert vier Vorteile:
• Einfachheit durch die Arbeit mit Daten in einer intuitiven Art und Weise, inkl.
Strong Consistency und Transaktionen über mehrere Dokumente;
• Flexibilität: Anpassungen an Schemata während der Laufzeit ermöglichen
Code-only Deployments;
• hohe Performance durch Bündelung von Strukturen bei gleichzeitiger
Reduktion von Code; sowie
• Vielseitigkeit durch die Unterstützung einer breiten Palette an Datenmodellen,
Beziehungen und Abfragen.
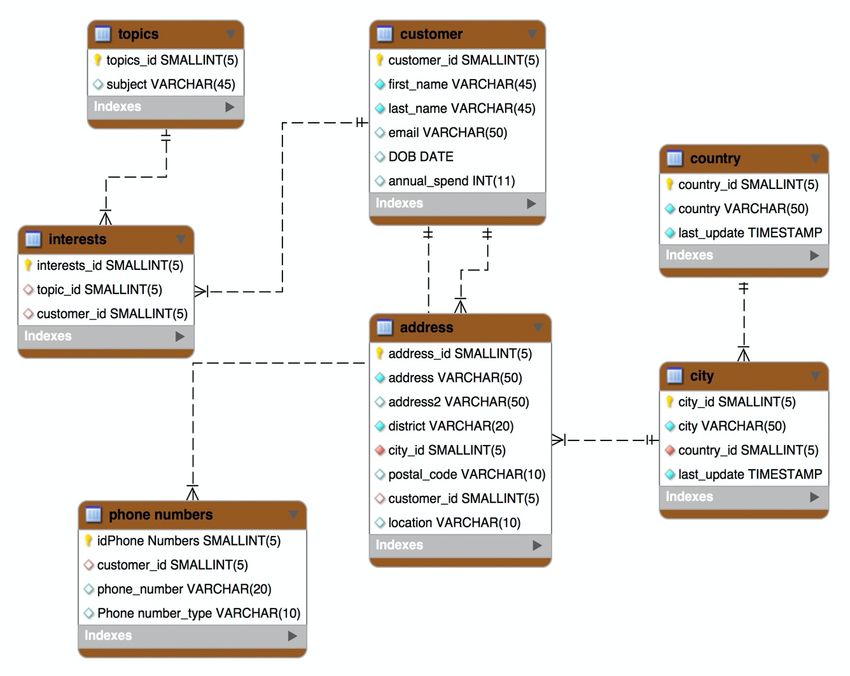
Abbildung 1: Modellierung eines Kunden im relationalen Modell – Daten sind über mehrere
Tabellen verteilt4 Christian Kurze, Christa Hoffmann, Julian Feinauer
Ein Beispiel zur Kundenverwaltung soll die Unterschiede verdeutlichen: Spaltet das
relationale Modell die Entität Kunde in verschiedene Tabellen auf (Abbildung 1) – und
begründet somit die Notwendigkeit von ORM-Layern zur Überwindung des „object-rela-
tional impedance mismatch“ – repräsentiert im Dokumentenmodell eine einzige
Datenstruktur ein Objekt entsprechend der Anforderungen der Applikation. In Beziehung
stehende Strukturen werden als Subdokumente und Arrays eingebettet. Das JSON-
Dokument in Abbildung 2 zeigt einen exemplarischen Kunden.
Abbildung 2: Modellierung eines Kunden als JSON-Dokument
2.2 Verteilte Datenhaltung: Hochverfügbarkeit, Skalierung, Workload Isolation
und Datenlokalität
Zur Hochverfügbarkeit erstellen die meisten relationalen Systeme eine Spiegelung des
Datenbestands. Infolgedessen werden zusätzliche Werkzeuge zur Datenreplikation bzw.
zum Erkennen von Fehlern benötigt, die ein Umschalten der Datenbanken im Fehlerfall
initiieren. Im Gegensatz dazu arbeitet eine verteilte Datenplattform mit eingebauten
Mechanismen zur Replikation. Diese sogenannten Replica Sets stellen einen Verbund von
Servern dar, sind selbstheilend und führen einen Failover vollautomatisch durch. Zudem
wird mit dieser Architektur auch eine rollierende Wartung möglich, z.B. das Einspielen
von Upgrades ohne Downtime.
Um Strong Consistency zu gewährleisten erhält ein Member die Rolle des Primary
Servers, gegen den alle Schreiboperationen stattfinden (zur horizontalen Skalierung siehe
weiter unten). Die weiteren Mitglieder des Replica Sets arbeiten als Secondary Server und
replizieren alle Veränderungen des Primary Servers.
Im Falle des Fehlers eines Primary Servers wird einer der Secondary Server
vollautomatisch innerhalb weniger Sekunden zum neuen Primary Server gewählt;
Applikationen werden automatisch auf den neuen Primary Server umgeleitet. Tritt der
ehemalige Primary Server wieder dem Cluster bei, geht er automatisch in den Secondary
Status und synchronisiert seine Daten vom (neuen) Primary Server.Edge to Cloud to Mobile Datenmanagement 5 Lese- und Schreibverfügbarkeit sind auch während des Failover-Vorgangs durch Retryable Reads und Retryable Writes gegeben: Nicht ausgeführte Lese- und Schreiboperationen werden automatisch gemäß des „exactly once“-Prinzips wiederholt. Replica Sets erlauben zusätzlich Workload Isolation zwischen operativen und analytischen Aufgaben innerhalb desselben Clusters. Explorative Abfragen oder das Training von Machine Learning-Modellen erfolgen ohne Einfluss auf operative Applikationen. Zusätzliche Secondary Server werden vollautomatisch mit allen Daten der operativen Applikation ETL-frei und in Echtzeit versorgt Horizontale Skalierung (alias Sharding oder Partitionierung) auf Basis von Standard- Hardware oder Cloud-Infrastruktur ist die Antwort auf Anforderungen zu hohen Datenvolumina und Durchsatz bei geringen Kosten. Die Verteilung von Daten auf Shards (jeweils ein hochverfügbares Replica Set) erfolgt automatisch über einen frei definierbaren Shard Key. Sharding ist ebenso ideal, um ein Datenlokalitätsprinzip umzusetzen: Entweder nach geographischen Region (Zonen für Nordamerika, Europa und Asien) oder auch nach Serviceklassen (schnelle Hardware für Premium-Kunden oder heiße Daten, langsamere für lauwarme / kalte Daten). Jede Zone kann dabei mehrere Shards enthalten, was wiederum zu einer unabhängigen Skalierbarkeit der einzelnen Zonen führt. 2.3 Deployment-Unabhängigkeit MongoDB kann in diversen Umgebungen eingesetzt werden: Laptop, Mainframe, Docker/Kubernetes, Private & Public Cloud sowie in hybriden Szenarien. MongoDB Mobile erlaubt weiterhin die automatische Synchronisation von mobilen und Edge- Devices. Entwickler finden überall die gleiche Umgebung vor; ebenso stehen Ops-Teams identische Werkzeuge für Monitoring, Optimierung, Automatisierung und Backup zur Verfügung. Die Kombination verschiedener Umgebungen erlaubt es Unternehmen, Schritt für Schritt in die Cloud zu gehen. So können Workloads in hybriden Umgebungen unerwartete Lastspitzen ausgleichen, oder die Cloud wird für geographische Regionen verwendet, in denen keine eigenen Rechenzentren zur Verfügung stehen. Ein Lock-In auf einen bestimmten Infrastruktur- oder Cloud-Provider besteht nicht – es sind sogar Daten- bankcluster über AWS, Azure und GCP zur gleichen Zeit möglich. 2.4 Schematische Architektur einer Edge to Cloud to Mobile Datenplattform Die in Abbildung 3 zusammengefasste Architektur zeigt den Weg von Daten aus Richtung der Devices in die Cloud sowie hin zu (mobilen) Applikationen. Für die Erfassung von Daten aus Devices sind drei Wege dargestellt: Ein direkter Ingest über Messaging-Systeme oder Cloud-native Services, wie beispielsweise AWS IoT Core, Azure IoT Hub oder Google IoT Core. Über eine schlanke mobile Datenbank, MongoDB Realm, können Daten direkt auf Geräten oder auf schlanken Gateways gespeichert und genutzt werden. Der vollautomatische Sync in die Cloud erspart eine große Menge an Entwicklungsaufwand. Auf größeren Devices oder Edge-Gateways kann der MongoDB
6 Christian Kurze, Christa Hoffmann, Julian Feinauer
Server selbst installiert werden und Vorteile, wie Hochverfügbarkeit, Workload Isolation
und Horizontale Skalierung, nutzen. Typischerweise erfolgen diese Deployments in Con-
tainern und deren Orchestrierung über Kubernetes.
Falls eigene Data Center im Einsatz sind, bietet sich erneut der MongoDB Server an – mit
den bereits dargestellten Vorteilen, die zusätzlich um globale Cluster, d.h. Datenbanken
über mehrere Rechenzentren hinweg, ergänzt werden.
Interessant ist der voll gemanagte Service innerhalb von AWS, Azure und GCP (auf an-
deren Cloud-Plattformen, wie Alibaba, Tencent oder IBM, stehen ebenfalls gehostete
MongoDB-Umgebungen zur Verfügung). Dieser Service bietet zusätzlich einen vollinte-
grierten Suchdienst auf Basis von Lucene [Mo20a] sowie das Management von kalten
Daten. Hierbei werden entweder Daten vollautomatisch auf günstige Object Stores, bei-
spielsweise AWS S3, verschoben (Online Archive). Alternativ steht der Zugriff auf Object
Stores und nahezu beliebige Datenformate zur Verfügung [Mo20]. Obwohl es sich um
(technisch) verschiedene Dienste handelt, können sie über eine einheitliche Abfragespra-
che genutzt werden. Die Datenplattform entscheidet selbstständig, ob die „heißen“ Daten-
bankcluster, der Suchindex oder der Data Lake abgefragt werden sollen.
Treiber für alle gängigen Programmiersprachen, eine Vielzahl von Konnektoren für
Kafka, Spark und SQL sowie integrierte Werkzeuge zur Erstellung von grafischen Dash-
boards runden den Funktionsumfang ab. Serverless Services ergänzen Funktionalität zur
Erstellung von GraphQL oder RESTful APIs sowie über Funktionen die Ausführung von
Code, der durch Trigger oder über einen Scheduler gesteuert wird. Statisches Hosting er-
möglicht die Ablage von kompletten Web-Lösungen.
Abbildung 3: Schematische Darstellung einer Edge to Cloud to Mobile Datenplattform
Entwickler von mobilen Applikationen werden auch auf dieser Seite der Architektur durch
die mobile Datenbank MongoDB Realm und dem bidirektionalen Sync aller Devices un-
terstützt [Mo20b]. Das ermöglicht die Erstellung von offline-first mobilen Applikationen,
d.h. selbst bei unterbrochenen Netzwerkverbindungen funktionieren Apps mit lokalen Da-
ten – sobald wieder eine Verbindung besteht werden Änderungen von beiden Seiten syn-
chronisiert und evtl. auftretende Konflikte automatisch aufgelöst.Edge to Cloud to Mobile Datenmanagement 7
3 Praxisbeispiele
Zwei Praxisbeispiele namhafter Landmaschinenhersteller sollen die Ausführungen der
vorhergehenden Kapitel veranschaulichen.
3.1 360° Farmmanagement / Smart Farming
Das erste Beispiel, das einen zusätzlichen Service des Herstellers darstellt, erfüllt drei we-
sentliche Ziele für Endkunden: Machinenoptimierung durch bessere Auslastung, Erhö-
hung der Produktivität bei Senkung der Kosten; Logistikoptimierung durch verbessertes
Zusammenspiel verschiedener Maschinen (z.B. Mähdrescher und Flurfahrzeuge) ähnlich
einer modernen Produktionsanlage; sowie Entscheidungsunterstützung durch präzise
Daten und deren Fluss zwischen Betrieb und Entscheidungsträgern sowie zurück in den
Betrieb von Landmaschinen – und somit der optimierten Bewirtschaftung der Äcker dient.
Das Beispiel der Entscheidungsunterstützung bei der Aussaat / Pflanzung erfordert eine
Vielzahl von Daten: Jede ausgesäte Zeile sammelt mindestens Informationen zur Geopo-
sition, Dichte der Aussaat, Antriebskraft usw. Die Messerte werden zwischen 1x bis 5x
pro Sekunde direkt auf der Landmaschine erfasst und über ein (potenziell instabiles) mo-
biles Netzwerk übertragen.
Die folgenden technischen Herausforderungen wurden durch den Einsatz der MongoDB
Datenplattform gelöst:
• Skalierung der Datenhaltung: Bereits in der sechsmonatigen Pilotphase sind die
erwarteten 20.000 Nutzer rasant schnell auf 60.000 angewachsen
• Die bisher verwendete relationale Datenbanktechnologie konnte nicht skalieren
und hat zu signifikant langsamen Applikationen geführt, die am Ende zu Kündi-
gungen des Services durch Endkunden geführt hat
• Stabile, bidirektionale Synchronisation zwischen den erfassten Daten in der
Edge, d.h. auf der Landmaschine, und der Cloud erfolgt nun vollautomatisch,
inkl. Konfliktauflösung
• Die gesteigerten Anforderungen an Datenwachstum und geographische Vertei-
lung konnten erreicht werden
• Neue Maschinentypen können problemlos durch den schemafreien Ansatz inte-
griert werden
Die Lösung ist in der Lage, den Output von Landwirten um 8-10% zu steigern – alleine
durch optimierte Abläufe und den präzisen Einsatz von Wasser und Düngemitteln.
3.2 Remote Service Portal
Im zweiten Beispiel handelt es sich ebenfalls um einen weltweit führenden Hersteller von
Landmaschinen und einem zusätzlichen digitalen Dienst für Händler und Endkunden. Die-
ser bietet einen digitalen Service-Assistenten, der mithilfe aktueller Daten von den Ma-
schinen die notwendigen Service-Leistungen optimiert. Weitere Ausbaustufen sehen zu-
sätzliche Dienste, wie im ersten Beispiel, vor.8 Christian Kurze, Christa Hoffmann, Julian Feinauer Die Herausforderung besteht in der Heterogenität von Produktlinien mit einer wachsenden Anzahl von Sensoren pro Maschine, die eine sehr große Menge an Telematikdaten produ- zieren. Im Jahr 2020 sammelt der Hersteller Daten von ca. 25.000 Maschinen ein, die innerhalb der nächsten 5 Jahre auf 100.000 Maschinen anwachsen werden. Die dreimona- tige Testphase während der Erntezeit hat bereits das fünffache Datenvolumen gegenüber den Schätzungen erzeugt. Da es sich um eine gewachsene Umgebung auf Basis von Azure, AWS und GCP handelt, war es zentraler Bedeutung, eine Datenbanklösung nahtlos auf allen drei Cloud-Providern sowie on-premises zu betreiben. Die Lösung bestand in der Ersetzung klassischer relationaler Technologien sowie von ta- bellenorientierten NoSQL-Datenbanksystemen. Die Skalierungsmöglichkeiten konnten problemlos eine fünffache Menge an Daten bei stabiler Performance abfedern. Neue Sen- soren und Maschinen lassen sich problemlos anbinden. Händler und Endkunden können nun bequem vom Schreibtisch aus die gesamte Flotte überwachen und steuern. Analysen und Reports nutzen die vorgestellten Konzepte der Workload Isolation. Daten, die älter als 90 Tage sind, werden in kostengünstige Object-Stores in der Cloud ausgelagert. Mit- hilfe des Data Lake-Ansatzes können diese einfach wieder ausgelesen werden – die Da- tenplattform entscheidet selbstständig, ob es sich um „heiße“ oder „kalte“ Daten handelt und föderiert die Abfrage in ein Datenbankcluster und/oder den Data Lake. Zukünftige Schritte beinhalten die Erweiterung der heute webbasierten Applikationen um mobile Applikationen, die beispielsweise Maschinenführer direkt mit Informationen und Handlungsanweisungen versorgen. Literaturverzeichnis [De19] Deloitte: Scaling IoT to meet enterprise needs, https://www2.deloitte.com/us/en/insights/focus/internet-of-things/enterprise-iot-solu- tions-edge-computing-cloud.html, Letzter Abruf 05.11.2020 [Mc19] McKinsey: What separates leaders from laggards in the Internet of Things, https://www.mckinsey.com/business-functions/mckinsey-digital/our-insights/what-sepa- rates-leaders-from-laggards-in-the-internet-of-things, Letzter Abruf 05.11.2020 [Mo20] MongoDB: Atlas Data Lake, https://docs.mongodb.com/datalake/, Letzter Abruf 05.11.2020 [Mo20a] MongoDB: Atlas Search, https://docs.atlas.mongodb.com/atlas-search/, Letzter Abruf: 05.11.2020 [Mo20b] MongoDB: Realm, https://docs.mongodb.com/realm/, Letzter Abruf 05.11.2020
Sie können auch lesen

















































