Darstellung von OPNV-Karten aus OpenStreetMap
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Freie Universität Berlin
Fachbereich Mathematik und Informatik
Institut für Informatik
Arbeitsgruppe Datenbanken und
Informationssysteme
Bachelorarbeit
Darstellung von
ÖPNV-Karten aus
OpenStreetMap
vorgelegt von
Ramdane Sennoun
4304440
am 03.08.2012
Gutachter: Prof. Dr. Agnès Voisard, Prof. Dr. Elfriede Fehr
Betreuer: Sebastian Müller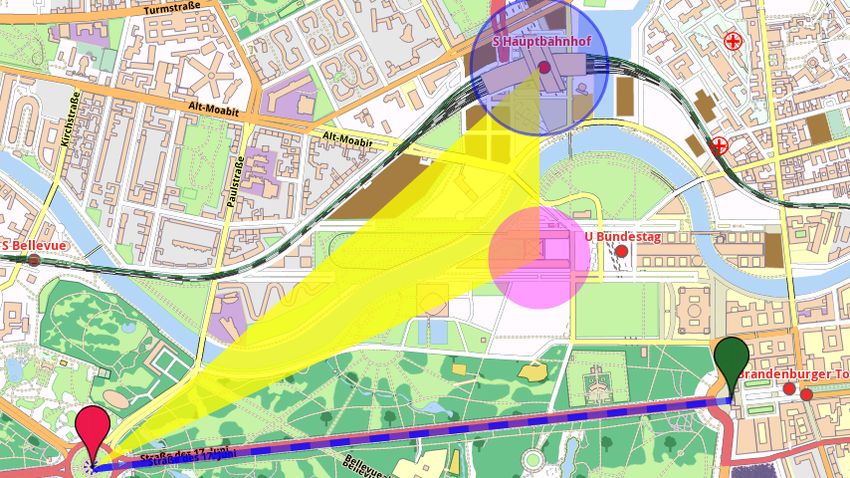
Eidesstattliche Erklärung Ich erkläre hiermit an Eides Statt, dass ich die vorliegende Bachelorarbeit selbständig angefertigt habe. Die aus fremden Quellen direkt oder indirekt übernommenen Gedanken sind als solche kenntlich gemacht. Die Arbeit wurde bisher weder in gleicher noch in ähnlicher Form einer anderen Prüfungsbehörde vorgelegt und auch nicht veröffentlicht. 03.08.2012 Ramdane Sennoun
Zusammenfassung
Heutzutage erleichtern Smartphones mit der integrierten Naviga-
tion die Suche nach Straßen oder öffentlichen Verkehrsmöglichkeiten.
Viele der Funktionen wie zum Beispiel der Abfrage nach ÖPNV-Daten
erfordern oft eine bestehende Internetverbindung, die jedoch nicht je-
derzeit vorhanden ist. In dieser Arbeit wird ein geeignetes Werkzeug
entwickelt, das alle ÖPNV-relevanten Daten aus OpenStreetMap extra-
hiert und offline auf Android-basierten Geräten darstellen kann. Dazu
werden die extrahierten Daten so in einem eingebetteten Datenbank-
system gespeichert werden, dass effiziente Suchanfragen wie z.B. nach
naheliegenden Stationen möglich sind. Das fertige System soll nicht
nur für Berlin, sondern auch für andere Regionen im In- und Ausland
einsetzbar sein.
Abstract
Nowadays smart phones with integrated navigation make it easier to
search for roads or public transport information. Many features such
as discovering nearby stations often require an internet connectivity,
which is not available sometimes. The main goal of this thesis is to de-
velop a tool that extract public transportation data (metro, suburban
train, bus, tram, regional trains, high speed trains, ferry, cable car)
from OpenStreetMap to provide that data on Android devices without
any internet connection required. The extracted data must be impor-
ted into an embedded database system with efficient queries provided.
The tool shall be adaptable for every region.Inhaltsverzeichnis
1 Einführung 1
1.1 Motivation und Ziele . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Aufgabenstellung und Arbeitsumfeld . . . . . . . . . . . . . . 2
1.3 Aufbau der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Grundlagen 4
2.1 OpenStreetMap . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1.1 Das OSM-Datenformat . . . . . . . . . . . . . . . . . 5
2.1.2 Zugriff auf die OSM-Daten mit Osmosis . . . . . . . . 7
2.2 Das Mapsforge-Projekt . . . . . . . . . . . . . . . . . . . . . . 7
2.2.1 Rendertheme API . . . . . . . . . . . . . . . . . . . . 7
2.2.2 Overlay API . . . . . . . . . . . . . . . . . . . . . . . 8
2.3 ÖPNV - Öffentlicher Personennahverkehr . . . . . . . . . . . 8
2.3.1 Allgemein . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.3.2 OSM und ÖPNV . . . . . . . . . . . . . . . . . . . . . 9
2.4 GTFS - General Transit Feed Specification . . . . . . . . . . 11
3 Implementierung des Datenbanksystems 13
3.1 Extrahierung der Daten - ÖPNV-Writer . . . . . . . . . . . . 13
3.1.1 Vorverarbeitung der ÖPNV-Daten aus OpenStreetMap 15
3.1.2 Das Osmosis-Plugin . . . . . . . . . . . . . . . . . . . 17
3.2 Die ÖPNV-Datenbank . . . . . . . . . . . . . . . . . . . . . . 18
3.2.1 Entwurf des Datenbanksystems . . . . . . . . . . . . . 18
3.2.2 Das Datenbankschema . . . . . . . . . . . . . . . . . . 25
3.3 R-Baum und R*-Baum . . . . . . . . . . . . . . . . . . . . . . 27
3.3.1 Suchen . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.3.2 Einfügen . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.3.3 SplitNode - Teilung eines Knotens . . . . . . . . . . . 33
3.3.4 R*-Baum . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.4 SQLite und R*-Baum . . . . . . . . . . . . . . . . . . . . . . 36
3.4.1 Das angepasste Datenbankschema . . . . . . . . . . . 36
3.5 Die Programmierschnittstelle . . . . . . . . . . . . . . . . . . 37
3.6 Android-Applikation . . . . . . . . . . . . . . . . . . . . . . . 38
4 Evaluation 41
4.1 Evaluation des Systems zur Erstellung der Datenbank . . . . 41
4.2 Evaluation der Datenbank - Laufzeiten . . . . . . . . . . . . . 43
5 Fazit 47
5.1 Ausblick und Verbesserungen . . . . . . . . . . . . . . . . . . 476 Anhang 49
6.1 Dateien, Grafiken . . . . . . . . . . . . . . . . . . . . . . . . . 49
6.1.1 Erstellung der SQLite-Datei aus dem Kartenmaterial . 49
6.1.2 Proto-Rendertheme . . . . . . . . . . . . . . . . . . . 50
6.2 Statistiken . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
6.2.1 Speicherplatzverbrauch der Kartenformate . . . . . . . 52
6.2.2 Speicherplatzverbrauch der erstellten Datenbanken . . 531 Einführung Ramdane Sennoun
1 Einführung
Die Nutzungsmöglichkeiten und Funktionen von Smartphones, die Handy,
Kamera und Mp3-Player miteinander kombinieren, werden durch mobiles
Internet und Applications (Apps) um ein Vielfaches erweitert. Es kann über
den Browser im Internet gesurft werden, es können über Apps E-Mails abge-
rufen und versendet werden oder man erleichtert sich die Suche nach Straßen
oder öffentlichen Verkehrsmöglichkeiten mit der integrierten Navigation.
Viele der Funktionen wie zum Beispiel der Abfrage nach ÖPNV-Daten (z.B.
zu U-Bahn- und S-Bahn-Linien, Busstationen, usw.) setzen oft eine Internet-
verbindung voraus, wenn solche Daten nicht offline auf dem eigenen Gerät
abgespeichert sind. Allerdings nutzt nicht jeder, der ein internetfähiges Han-
dy oder ein Smartphone besitzt und unterwegs ist, das mobile Internet. Hohe
Verbindungskosten können ein Grund sein. Der mobile Zugang zum Internet
ist auch nicht jederorts verfügbar. So deckt der Ausbau des Mobilfunknet-
zes noch nicht alle Bereiche ab. Nicht überall in den U-Bahn-Systemen der
großen Städte ist das Mobilfunknetz so ausgebaut, so dass jederzeit das mo-
bile Internet genutzt werden kann[28].
Was für- und wie kann man den Nutzern (z.B. Touristen) Daten bereitstel-
len, um mobil auf ÖPNV-Daten (z.B. Standorte, Service) und ÖPNV-Karten
(Streckenlinien und Streckenverläufe von U-Bahn, S-Bahn, usw.) zugreifen
zu können, ohne von Anbietern proprietärer Daten abhängig zu sein oder
Geld für das Kartenmaterial zu zahlen?
1.1 Motivation und Ziele
Das Mapsforge-Projekt [26], welches 2008 an der Freien Universität Berlin
gegründet wurde und im nächsten Kapitel genauer vorgestellt wird, stellt
Bibliotheken bereit, die für Android [16]-basierte Geräte folgende Lösungen
bietet: Darstellung von Kartenmaterial (Maprendering) und Kartenoverlays
sowie die Routenplannung und Navigation als auch die Suche von Points of
Interest (POIs).
OpenStreetMap [29] (OSM) unterstützt Personen beim Navigieren und Ori-
entieren und ist einer der wenigen Kartendienste, die einfache Routenpla-
nung ermöglicht, da ebenso, auch wenn nicht vollständig, Fahrplaninforma-
tionen des öffentlichen Verkehrs erfasst werden. Der Öffentliche Personen-
nahverkehr (ÖPNV) war schon im Sommer 2009 das Thema einer umfas-
senden Diplomarbeit [42] über den Entwurf und die Implementierung eines
Schemas zur Erfassung nutzbarer ÖPNV-Daten in OpenStreetMap.
Ziel dieser Arbeit ist es nun, ein geeignetes Werkzeug zu entwickeln, um
alle ÖPNV-relevanten Daten (über U- und S-Bahnen, Straßenbahnen, Bus-
se, Fähren,...) aus OpenStreetMap zu extrahieren und offline auf Andro-
id -basierten Geräten darzustellen. In ÖPNV-Netzen sind unterschiedliche
11.2 Aufgabenstellung und Arbeitsumfeld Ramdane Sennoun
Darstellungen üblich, besonders andere Regionen im In- und Ausland ha-
ben höchstwahrscheinlich unterschiedliche Verkehrsbetriebe und dem ent-
sprechend unterschiedliche Darstellungsweisen.
1.2 Aufgabenstellung und Arbeitsumfeld
Das Ziel des Mapsforge-Projekts [26] ist es, Bibliotheken zu implementie-
ren und zur Verfügung zu stellen, damit Kartenanwendungen auf Android-
Geräten sie nutzen können. Viele der Komponenten waren Ergebnisse von
Abschlussarbeiten. In dieser Arbeit soll das Mapsforge-Projekt um eine wei-
tere Komponente erweitert werden.
Alle relevanten Daten zum Öffentlichen Personennahverkehr, die in Open-
StreetMap erfasst worden sind, müssen extrahiert werden und so in einem
eingebetteten Datenbanksystem gespeichert werden, dass effiziente Anfragen
und Verknüpfungen zu Online-Informationen (z.B eine Webseite mit aktuel-
len Abfahrtszeiten oder ein Wikipedia-Artikel zu einer bestimmten Station)
möglich sind.
• Herkömmliche Applikationen für den Öffentlichen Personennahverkehr
auf Android, wie die bekannte Öffi -Applikation [41], oder für App-
les iOS [17] FahrInfo - Mobile Trip Planner [23] setzen für die Su-
che von nahegelegenen Haltestellen oder Abfahrtszeiten eine Internet-
verbindung voraus. Es soll also ein Datenbanksystem entworfen und
implementiert werden, das die extrahierten ÖPNV-Daten aus Open-
StreetMap offline auf dem Android-Gerät speichert und verwaltet. Die
Anfragen sollen dementsprechend offline erfolgen.
• Die Suchergebnisse müssen offline als Overlay auf der OpenStreetMap-
karte dargestellt werden, mit denen der Nutzer auch interagieren kann.
Zur Darstellung in Android existiert bereits eine Softwarebibliothek
aus dem Mapsforge-Projekt, welche neben dem Rendern einer Basis-
karte über Schnittstellen zur Anzeige von Overlays verfügt.
• Das Ergebnis soll eine lauffähige Android-Applikation sein, die eine
ÖPNV-Karte darstellt, mit der der Nutzer interagieren und Suchan-
fragen stellen kann.
21.3 Aufbau der Arbeit Ramdane Sennoun
1.3 Aufbau der Arbeit
Der Aufbau dieser Arbeit geht mit der Entwicklung des Systems einher. Im
ersten Schritt müssen die erforderlichen Daten aus OpenStreetMap bezogen
werden. Danach müssen diese in ein geeignetes Datenbanksystem überführt
werden. Im darauffolgenden Teil muss eine Bibliothek entwickelt werden,
die das Lesen der Daten auf einem mobilen Android-Endgerät ermöglicht.
Am Schluss muss die Android-Applikation implementiert werden, die die
ÖPNV-Karte darstellt und das Interagieren mit dem Nutzer ermöglicht.
1. Extrahierung der Daten
Am Anfang müssen alle Daten, die für den ÖPNV-Gebrauch nützlich sind,
aus OpenStreetMap bezogen und gespeichert werden. Sind die Daten extra-
hiert, müssen sie anhand eines Datenbankschemas in ein Datenbanksystem
überführt werden.
2. Entwurf und Implementierung des Datenbanksystems
Als zweiter Schritt muss ein geeignetes Datenbankschema entworfen wer-
den, welches die extrahierten ÖPNV-Daten in strukturierter Weise zusam-
menfasst und einen effizienten Zugriff ermöglicht. Es sollen Abfragen nach
Stationen, nach umliegenden Haltestellen und nach Verkehrslinien möglich
sein. Als Ergebnis wird eine SQLite-Datei erstellt, die alle nötigen dazu-
gehörigen Informationen enthält.
3. Implementierung einer Reader-Bibliothek für Android
Ist die Implementierung des Datenbanksystems abgeschlossen und sind die
extrahierten Daten in eine SQLite-Datenbank überführt worden, kann ei-
ne Reader-Bibliothek implementiert werden, mit der Android-Anwendungen
auf die Datenbank zugreifen und Suchanfragen stellen kann.
4. Android-Applikation
Zum Schluss wird eine Android-Applikation entwickelt, die mittels der Da-
tenbank und eines eigenen Render-Schemas eine ÖPNV-Karte darstellt, mit
der der Nutzer z.B. durch einen Klick auf eine Station interagieren kann.
Dazu sollen die aus der Datenbank enthaltenen ÖPNV-Informationen über
die Stationen für den Benutzer zur Verfügung stehen.
32 Grundlagen Ramdane Sennoun
2 Grundlagen
In diesem Kapitel werden einige technische Mittel und Grundlagen zum
Öffentlichen Personennahverkehr vorgestellt, auf denen das System aufbaut.
2.1 OpenStreetMap
Als Kartenmaterial wird in dieser Arbeit OpenStreetMap (OSM) verwen-
det, weil jeder die Daten lizenzkostenfrei (gemäß der Creative-Commons-
Attribution-ShareAlike-2.0-Lizenz [20]) benutzen und weiterverarbeiten kann.
Das OpenStreetMap-Projekt wurde 2004 in Großbritannien gegründet. Mitt-
lerweile erfasst das Projekt dank der weltweit über 630 Tausend Freiwilligen,
die die Geodaten über Straßen, Flüsse, Orte, Wälder, usw. bisher sammel-
ten, mehr als 2,9 Milliarden GPS Punkte, 1,5 Milliarden Punkte und 14
Millionen Wege[30].
Aufbauend auf den in einer Datenbank gespeicherten Daten lassen sich Stra-
ßenkarten für Autofahrer, Wander- und Fahrradkarten erzeugen oder An-
wendungen entwickeln, die der Navigation und Routenberechnung dienen.
Auf der OpenStreetMap-Website gibt es eine Weltkarte, die jeder lesen und
auch mitgestalten kann. Ähnlich der Anbieter anderer Kartendienste lässt
sich die Karte mit gedrückter Maustaste verschieben oder mit einem Dop-
penklick vergrößern.
Abbildung 2.1: Weltkarte auf der OpenStreetMap-Website [29]
Im folgenden Abschnitt soll das relativ abstrakte Datenmodell von Open-
StreetMap beschrieben werden, mit dem die zentrale OpOSM-Datenbank die
Informationen über Straßen, Wege, Grenzen, Gewässer, Sehenswürdigkeiten
und vieles mehr organisiert. Zudem bildet es die Grundlage für das XML-
Format, durch das OSM-Daten ausgetauscht werden.
42.1 OpenStreetMap Ramdane Sennoun
2.1.1 Das OSM-Datenformat
Grundlegend kann zwischen zwei wichtigen Objekttypen unterschieden wer-
den - den Knoten und den Wegen. Es werden diesen Objekten Attribute
zugeordnet, die zur Beschreibung dienen - den Tags. Der Datentyp Relation
modelliert die Beziehungen zwischen verschiedenen OSM-Objekten, die je-
weils eine XML-Repräsentation haben. Knoten (Nodes), Wege (Ways) und
Relationen stehen also in verschiedenster Weise in Beziehungen (vereinfach-
te Darstellung in Abbildung 2.2) und bilden die OpenStreetMap-Karte. Die
Abbildung 2.2: OSM-Datenformat - Knoten, Wege und Relationen
jeweiligen Objekte der drei OSM-Objekttypen sind mit einer eindeutigen
ID in Form einer Nummer gekennzeichnet. Des Weiteren können Tags zu-
geordnet werden, um die Objekte zu beschreiben. Es können beliebig viele
Tags gespeichert werden, die z.B. Informationen zu Straßennamen, Haus-
nummern oder Geschäften beinhalten. Ein Tag besteht aus einem Schlüssel
(Key), dem einen Wert (Value) zugeordnet wird (”Key=Value”). Bestimm-
te Tags werden für für die Beschreibung von Haltestellen und Öffentlichen
Verkehrslinien/Bahnlinien von Bedeutung sein.
• Knoten (Nodes) enthalten neben der ID und den optionalen Tags auch
Informationen über die geographische Lage. Längen- und Breitengrade
müssen u.a. in einer Datenbank gespeichert werden, um die Haltestel-
len auf der Karte positionieren zu können.
52.1 OpenStreetMap Ramdane Sennoun
• Wege (Ways), die aus einer geordneten Liste von mindestens zwei
Nodes bestehen, bilden linienförmige Objekte wie Grenzen, Straßen,
Flüssen, Gebäudemauern und ähnliches ab. Sind Anfangs- und End-
knoten identisch, so wird eine Fläche abgebildet. So können Gebäude,
Seen oder Wälder dargestellt werden. Ways enthalten den genauen
Verlauf von Bus- oder Bahnlinien und können später in der Anwen-
dung durch ein eigenes Rendertheme hervorgehoben werden.
• Relationen modellieren die Beziehungen zwischen Objekten, die jeweils
eine Instanz der drei Objekttypen sein können. Die Objekte sind Teil-
nehmer (Member) einer geordneten Liste und bekommen eine Rolle
zugewiesen. Die Relation boundary gruppiert z.B. Grenzen, wogegen
die Relation waterway die Gewässerlinien repräsentiert. Im Hinblick
dieser Arbeit spielt die etablierte Relation route eine wichtige Rolle,
da sie Buslinien (route=bus), U-Bahn-Linien (route=subway), S-Bahn-
Linien (route=light rail ) und andere Nahverkehrslinien modelliert.
< r e l a t i o n i d=” 58428 ” v e r s i o n=” 22 ” timestamp=”2012−06−14
T12 : 2 4 : 0 7 Z” u i d=” 304565 ” u s e r=” s t e f a n −s ” c h a n g e s e t=”
11894666 ”>
...
...
...
62.2 Das Mapsforge-Projekt Ramdane Sennoun
Mehr Details zu OpenStreetMap-Karten, zum Mapping und zum Tagging
können im Buch von Frederick Ramm und Joch Topf nachgelesen werden.
[39]
2.1.2 Zugriff auf die OSM-Daten mit Osmosis
Das Java-Programm Osmosis [32], entwickelt von Brett Henderson, ist ein
universelles Filter- und Konvertierer-Tool für Daten aus OpenStreetMap. In
der Befehlszeile wird zum einen die Datenquelle sowie das Ziel der Ausga-
bedatei angegeben, zum anderen können optional weitere Filter- und Verar-
beitungsmodule (tasks) festgelegt werden. Um die relevanten ÖPNV-Daten
aus OpenStreetMap zu extrahieren, um daraus eine ÖPNV-Karte zu erstel-
len, wurde ein Osmosis-Plugin implementiert, das die verarbeiteten Daten
in eine SQLite-Datenbank speichert und verwaltet. In Kapitel 3.1.2 wird
detaillierter auf Osmosis eingegangen.
2.2 Das Mapsforge-Projekt
Das Mapsforge-Projekt [26] startete 2008 an der Freien Universität Berlin
als Studentenprojekt und stellt Softwarebibliotheken für OpenStreetMap-
basierte Android-Anwendungen bereit. Neben dem Anzeigen von Kartenda-
ten (Rendering) ermöglicht es auch offline Routenplanung sowie die Suche
nach Point of Interests (POIs) um einen vorgegeben Radius.
2.2.1 Rendertheme API
Durch die Rendertheme API von der mapsforge-map-Bibliothek ist es möglich,
die dargestellte Karte im eigenen Stil zu visualisieren. Es wurde zur Darstel-
lung der ÖPNV-Karte ein eigenes Rendertheme geschrieben, das zur Lauf-
zeit je nach Einstellung im Android-Einstellungsmenü beliebig geändert und
aktiviert werden kann. Das folgende Beispiel zeigt eine kleine Renderinstruk-
tion, bei der Gebäude vor den Straßenbahn- und U-Bahn-Linien gerendert
werden und dementsprechend letztere über den Gebäudelinien erscheinen.
72.3 ÖPNV - Öffentlicher Personennahverkehr Ramdane Sennoun
< l i n e s t r o k e=”#c c 0 0 0 0 ” s t r o k e −width=” 0 . 7 0 ” s t r o k e −
l i n e c a p=” b u t t ” />
< l i n e s t r o k e=”#003399” s t r o k e −width=” 1 . 0 ” s t r o k e −
l i n e c a p=” b u t t ” />
Im Abschnitt 3.6 wird auf das für diese Arbeit entworfene Rendertheme ein-
gegangen und die Designentscheidungen zur Darstellungen der Haltestellen
und öffentlichen Straßen-, Schienen- und Schiffsverkehrslinien getroffen.
2.2.2 Overlay API
In Abbildung 2.3 sind einige Overlay-Beispiele [27] dargestellt, die in der Ap-
plikation für die Markierung von Suchresultaten und Haltestellen verwendet
werden.
Abbildung 2.3: Overlay-Beispiele
2.3 ÖPNV - Öffentlicher Personennahverkehr
In den zwei darauf folgenden Abschnitten soll allgemein auf die Bedeutung
vom ÖPNV in Städten eingegangen werden sowie die Erfassung von Infor-
mationen über die Infrastruktur von Straßen-, Schienen- und Schiffsverkehr
in OpenStreetMap aufgezeigt werden.
82.3 ÖPNV - Öffentlicher Personennahverkehr Ramdane Sennoun
2.3.1 Allgemein
Als öffentlicher Personennahverkehr (ÖPNV) wird in Deutschland die Beför-
derung von Personen mit Fahrzeugen des Straßen-, Schienen- und Schiffs-
verkehrs im Linienverkehr bezeichnet, das durch private oder kommunale
und gemischt-wirtschaftliche Unternehmen sowie Regionaleisenbahngesell-
schaften getragen und durch Bund, Länder und Gemeinden gefördert wird
[6]. Die Aufgabenträger haben hohe Anforderungen zu erfüllen und müssen
über Verkehr und Strukturen sehr gut ausgebildet sein. Die Planung erfolgt
über den Verknüpfungspunkten, also den anzusteuernden Haltestellen bzw.
Quellen/Zielen, und den Reisezeiten sowie den Taktvorgaben bis hin zur
Erfüllung der Mindeststandards im Bezug auf Emissionswerte und Fahr-
gastzahlen. Kundenzufriedenheit, Marketing, Vertrieb und Verkauf dürfen
natürlich nicht fehlen.
2.3.2 OSM und ÖPNV
ÖPNV [31] nimmt auch in OpenStreetMap eine wichtige Rolle ein und ist
für die Kartographen eine große Herausforderung. Das Tagging vom ÖPNV
in Städten soll den Nutzern neben dem Navigieren und Orientieren auch die
Routenplanung unter Verwendung des öffentlichen Verkehrs ermöglichen.
Um diesem Ziel zu folgen, muss die Infrastruktur in OpenStreetMap erfasst
werden. Grundlegend wird zwischen linienhafter und punkthafter Infrastruk-
tur sowie den Netzwerkinformationen unterschieden.
Linienhafte Infrastruktur (Gleise, Straßen)
In Tabelle 2.1 sind die für diese Arbeit wichtigsten Tags in dieser Rubrik
nach den Typen (Eisenbahn, Straßenbahn, . . . ) aufgelistet. Busspuren ha-
Key Value Typ
railway tram Straßenbahngleise
railway subway U-Bahn-Gleise
railway rail Eisenbahngleise (z.B. DB, etc.)
railway light rail S-Bahn-Gleise
railway funicular Standseilbahn
Tabelle 2.1: ÖPNV-Tagging in OSM: Linienhafte Infrastruktur
ben die linienhaften Infrastrukturen in den Straßen und werden z.B. auf den
Busbahnhöfen mit dem Key-Value-Pair highway=service getaggt.
92.3 ÖPNV - Öffentlicher Personennahverkehr Ramdane Sennoun
Punkthafte Infrastruktur (Haltestellen)
Unter diesem Punkt werden alle Haltestellen zusammengefasst. Dazu gehören
Bahnsteige, die Haltepositionen der öffentlichen Verkehrsmittel und ähnliches.
Heute gebräuchliche Tags in Bezug auf den öffentlichen Personennahverkehr
sind in Tabelle 2.2 aufgelistet. Bisher konnte sich noch kein einheitliches
Key-Value-Pair Bedeutung
railway=station Bahnhof
railway=halt Bahn-Haltepunkt
railway=tram stop Straßenbahnhaltestelle
highway=bus stop Bushaltestelle
public transport*=stop position Haltepunkt des Fahrzeugs
public transport*=platform Bahnsteig als Node, Way oder Fläche
public transport*=stop area in einer Relation zusammengefasste
Haltepunkte und Bahnsteige zu einem
*neueres Tagging-Schema Gesamthalt
Tabelle 2.2: ÖPNV-Tagging in OSM: Punkthafte Infrastruktur
Tagging-Schema zum ÖPNV etablieren, trotzdem werden die meisten Daten
so erfasst, dass Details zu Netzinformationen vorhanden sind. Innerhalb der
OSM-Community gibt es in Form von Wiki-Unterprojekten einige Schwer-
punkte, die sich auf auf den ÖPNV beziehen. Das ÖPNV-Schema wurde
einer umfangreichen Bestandsanalyse unterzogen und hat an vielen Stellen
eine Anpassung oder Erweiterung nötig. Genauere Ergebnisse können in der
bereits referenzierten Diplomarbeit von Schwarz nachgelesen werden.
Netzwerkinformationen (Verkehrsverbünde, Linien)
Unter den Netzwerkinformationen versteht man die Daten, die die Details
zu den als Relationen erfassten Bahn- oder Buslinien darstellen. Straßen,
Schienenwege und Haltepositionen sind die möglichen Members einer Rela-
tion und sind in der Reihenfolge aufgelistet, wie sie gefahren werden. Um die
Relation als Route zu kennzeichnen, wird das Key-Value-Paar type=route
verwendet. Die Werte tram, subway, rail, light rail, ferry und bus werden
dem Schlüssel route zugeordnet.
Die Schlüssel from und to enthalten Inhalten bei Vorhandensein Informa-
tionen über den Start und das Ziel einer Verkehrslinie. ref beinhaltet die
Bezeichnung der Linie (z.B. U2), network enthält die Information über das
Liniennetz (z.B. VBB) und operator ist die Betreibergesellschaft (z.B. BVG).
In unserer Arbeit müssen möglichst viele Tags erfasst und extrahiert wer-
den, die als relevante ÖPNV-Daten in eine seperate SQLite-Datenbank im-
portiert werden können, um daraus eine ÖPNV-Karte darzustellen und sie
als Android-basierte Anwendung anbieten zu können.
102.4 GTFS - General Transit Feed Specification Ramdane Sennoun
Dazu wurde eine Datenbanksystem (Kapitel 3: Plannung, Entwurf und Im-
plementierung) entworfen, dass die erforderlichen Daten speichert.
2.4 GTFS - General Transit Feed Specification
GTFS [24] - General Transit Feed Specification - ist ein von Google ent-
worfenes Format, das öffentliche Verkehrssysteme einer Region abbildet und
ÖPNV- und Geodaten erfasst und in Form von Text-Dateien bzw. im CSV-
Format speichert, die in einer zip-Datei gepackt sind. Der Inhalt umfasst
spezifische Daten wie Abfahrtszeiten oder Informationen zu Linienverläufen
und Haltestellen. Die Spezifikation definiert 13 Dateien, wovon sechs obli-
gatorisch und die restlichen sieben optional sind. Das UML-Diagramm in
Abbildung 2.4 zeigt die Beziehungen zwischen den Google Transit-Objekten
sowie deren öffentlichen GTFS-Attributen.
Abbildung 2.4: GTFS-Spezifikation [25]
• agency.txt (obligatorisch): In der Datei agency.txt werden die Betrei-
ber von öffentlichen Verkehrsdiensten definiert, die den Feed erstellen.
Es können mehrere Betreiber in einer Datei definiert werden.
• stops.txt (obligatorisch): Die Haltestellen werden in der Datei stops.txt
aufgelistet. Sie enthält die Informationen über die geographische Lage,
112.4 GTFS - General Transit Feed Specification Ramdane Sennoun
den Namen und optional eine URL, eine Beschreibung und ähnliches
über die Station bereit.
• routes.txt (obligatorisch): In dieser Datei werden alle öffentlichen Ver-
kehrslinien gespeichert. Die Routen sind zeitunabhängig und umfassen
einen oder mehrere zeitabhängige Trips.
• trips.txt (obligatorisch): Ein Trip ist eine Fahrt entlang einer Route zu
einer bestimmten Zeit und ergibt sich aus einer Folge von StopTimes.
• stop times.txt (obligatorisch): Die StopTime enthält Daten zur Auf-
enthaltsdauer sowie die Ankunfts- und Abfahrtszeit eines Fahrzeuges
entlang einer in trips.txt definierten Strecke.
• calendar.txt (obligatorisch): Der Datumsbereich und die Wochentage,
an denen ein Trip stattfindet werden als Service in dieser Datei fest-
gelegt.
• calendar dates.txt (optional): In calender dates.txt werden bestimm-
te Tage (z.B. Feiertage) definiert, an denen eine Fahrt (Trip) nicht
stattfindet oder eine Route außerplanmäßig gefahren wird.
• fare attributes.txt (optional): Gültigkeit, Preis und Währung einer Fahr-
karte werden in diesem GTFS-Objekt festgelegt..
• fare rules.txt (optional): FareRules legen die Beförderungsbedingungen
fest, die die Passagiere einzuhalten haben.
• shapes.txt (optional): Shapes werden bestimmten Trips zugeordnet und
enthalten die Geokoordinaten einer abzufahrenden Strecke eines Fahr-
zeuges.
• frequencies.txt (optional): Linien, die keine festen Abfahrts- und An-
kunftszeiten haben und in einem bestimmten Takt verkehren, werden
eine Frequenz zugeordnet, die in frequencies.txt definiert sind.
• transfers.txt (optional): Umstiegsmöglichkeiten und -dauer für eine
Haltestelle werden in transfers.txt festgelegt.
• feed info.txt (optional): In dieser Datei werden zusätzliche Informatio-
nen (z.B. zum Publisher, der sich oft von der Agency unterscheidet)
über den Feed selbst gespeichert.
Für diese Arbeit diente das Format von Google nur als Vorbild für das Daten-
bankschema, das in Kapitel 3 beschrieben wird. Es reichen die OSM-Daten
nicht dazu aus, um ein minimalen GTFS-Feed zu erstellen, da z.B. Abfahrts-
zeiten nicht in OpenStreetMap erfasst werden. Es ist aber eine Parallelität
zu den GTFS-Objekten Stops und Routes vorhanden.
123 Implementierung des Datenbanksystems Ramdane Sennoun
3 Implementierung des Datenbanksystems
Das komplette System wurde als Android-Applikation, dem PublicTrans-
portViewer, implementiert. Der Benutzer hat die Möglichkeit, offline und
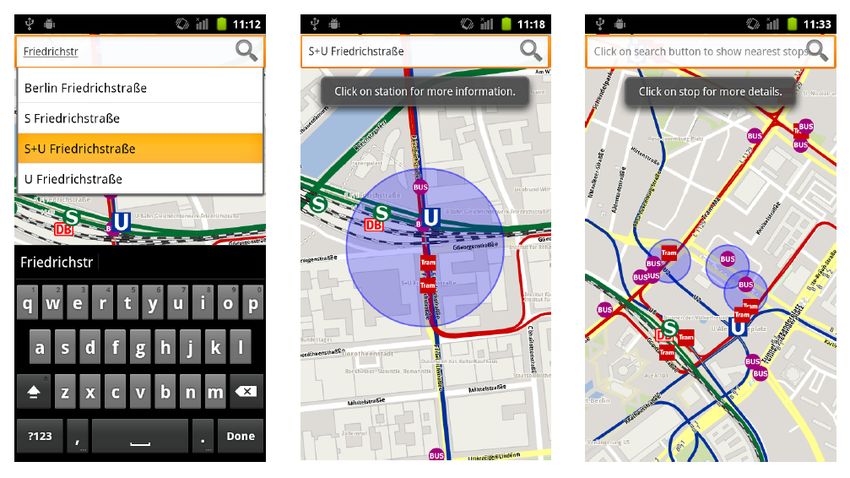
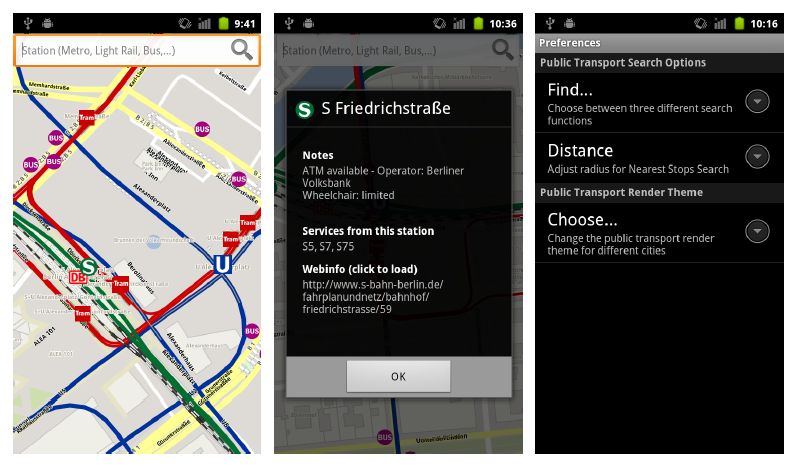
per Eingabe nach öffentlichen Verkehrshaltestellen zu suchen und sich die
Suchergebnisse auf der ÖPNV-Karte darstellen zu lassen. Weitere Suchop-
tionen sind die Suche nach Stationen einer öffentlichen Verkehrslinie (z.B.
U2, M48, etc.) oder das Anzeigen der am nächsten gelegenen Haltestellen im
Umkreis von bis zu 500 Metern. Des Weiteren kann der Benutzer mit einem
Klick auf das Icon einer Station weitere Informationen über die Haltestelle
bekommen, die in einem Pop-up-Fenster dargestellt werden. Hierzu muss die
Stadtkarte und die Datenbank, die die ÖPNV-Daten enthält, vom Anwender
auf dem Telefon kopiert werden. Die Karte ist eine vom mapsforge-Osmosis-
Plugin erstellte .map-Datei, die ÖPNV-Datenbank ist eine .sqlite-Datei.
In den folgenden Abschnitten wird das Datenbankschema für die erfassten
ÖPNV-Daten sowie die wichtigsten Klassen, die das Schreiben und Lesen
der Datenbank erledigen, vorgestellt.
3.1 Extrahierung der Daten - ÖPNV-Writer
In Kapitelabschnitt 2.1.2 wurde schon auf das in Java geschriebene Filter-
und Kovertierer-Tool Osmosis [32] eingegangen, das zur Extrahierung der
OpenStreetMap-Daten eingesetzt wird. OpenStreetMap-Daten können in
beliebigen Formaten repräsentiert und gespeichert werden. Die Beispiele zu
Knoten, Wegen und Relationen aus Kapitel 2.1.1 zeigen das OSM-Datenformat
in XML-Repräsentation [22]. Eine weitere wichtige und deutlich weniger
Speicher verbrauchende Repräsentation des OSM-Datenformats ist Googles
effiziente System zum Serialisieren strukturierter Daten, dem Protocol Buf-
fer (kurz pbf) [7], auf das nicht weiter detailliert eingegangen wird.
XML - Extensible Markup Language
Die Extensivle Markup Language, kurz XML, ist eine vom World Wide
Web Consortium (W3C) [13] definierte Metasprache zum plattform- und
implementationsunabhängigen Austausch von strukturierten und menschen-
lesbaren Daten.
Das OSM-XML-Format
Jeder OSM-XML-Datensatz beginnt mit einem -Element, gefolgt von
einem -Element, das den geographischen Bereich der Daten angibt.
Darunter folgen in der Reihenfolge die Objekttypen Nodes, Ways und Re-
lations:
133.1 Extrahierung der Daten - ÖPNV-Writer Ramdane Sennoun
...
...
...
< r e l a t i o n i d=” 58428 ” . . . >
...
...
...
...
Das OSM-XML-Format (Endung .osm) verbraucht mit seiner Größe viel
Speicherplatz (Vergleich Tabelle 3.1) und sollte für Anwendungen nicht auf
mobilen Geräten gespeichert werden. Jedoch eignet es sich in dieser Arbeit
zur Erfassung der Informationsstrukturanforderung und zur Datenvorverar-
beitung, da die Daten in menschenlesbarer Form vorhanden sind und sich
somit die relevanten ÖPNV-Daten aus OpenStreetMap erkennen lassen. Im
Anhang 6.2.1 ist der Vergleich des Speicherplatzverbrauchs einzelner For-
mate weiterer Städte tabellarisch und grafisch dargestellt.
143.1 Extrahierung der Daten - ÖPNV-Writer Ramdane Sennoun
OSM-Format Speichergröße
berlin.osm.pbf 20 MB
berlin.osm 366 MB
berlin.map 12 MB
bremen.osm.pbf 5 MB
bremen.osm 96 MB
bremen.map 3 MB
hamburg.osm.pbf 18 MB
hamburg.osm 337 MB
hamburg.map 11 MB
new-york.osm.pbf 67 MB
new-york.osm 1.4 GB
new-york.map 43 MB
Tabelle 3.1: Speicherverbrauch einiger OSM-Formate im Vergleich
3.1.1 Vorverarbeitung der ÖPNV-Daten aus OpenStreetMap
Es gibt verschiedene öffentliche Verkehrsarten. Sie unterscheiden sich in
Technik und Infrastruktur. Zuerst müssen alle ÖPNV-relevanten Daten der
Objekttypen Nodes (Repräsentation der Haltestellen) und Relations (Re-
präsentation der Verkehrslinien) erkannt und aufgelistet werden, um daraus
mögliche Informationsstrukturanforderungen zu beschreiben.
Dazu wurden im ersten Schritt alle ÖPNV bezogenen Tags heraus sortiert,
die in Tabelle 3.2 zusammengefasst sind. Die Attribute id, lon (Longitude)
und lat (Latitude) sind nicht in der Tabelle aufgeführt, aber zur eindeutigen
Kennzeichnung der Haltestellen und Routen sowie zur Positionierung (lon
und lat) auf der Karte notwendig. Das Attribut id muss sowohl bei den No-
des als auch bei den Relations vorhanden sein. lon und lat enthält nur der
OSM-Obejekttyp Node.
153.1 Extrahierung der Daten - ÖPNV-Writer Ramdane Sennoun
Tag Bedeutung Relation Node
(Verkehrslinie) (Haltestelle)
route Zur Kennzeichnung von
Bus-, Straßenbahn-
√
und U-Bahn-Linien,
Eisenbahnlinien und
Fährlinien
√
from Start einer Route
√
to Endhaltestelle einer
Route
√
operator Betreiber einer Route
z.B. BVG (Berlin)
network Netzwerk
√
z.B. Verkehrsverbund
Berlin-Brandenburg
(VBB)
√
ref Name einer Linie z.B.
U2, M48, S1, M6
√
color Farbe einer Linie
√ √
name Name der Route oder
Haltestelle
√ √
website/ Verweis auf mehr
wikipedia Informationen
√
public trans- Kennzeichnung als
√
port/railway/ öffentliche Verkehrs-
√
station/ haltestelle bzw.
√
highway Station
√
addr Addresse
√
atm Geldautomat
√
line Name einer Linie
√
note zusätliche Be-
schreibung
√
phone Telefon
√
surveillance Fahrstuhl
√
wheelchair Eignung für
Rollstühle
Tabelle 3.2: ÖPNV-relevante Tags aus OpenStreetMap
163.1 Extrahierung der Daten - ÖPNV-Writer Ramdane Sennoun
3.1.2 Das Osmosis-Plugin
Die Osmosis-Distributionen ist schon mit den gängigsten Plugins, wie z.B.
dem Lesen und Schreiben aus einer Datenbank oder Datei, ausgestattet und
bleibt im Programmcode größtenteils unverändert. Neue Funktionen werden
einfach ergänzt. Es wurde ein Osmosis-Plugin mit dem Namen mapsforge-
public-transport-writer entwickelt, welches die aus der Vorverarbeitung ge-
filterten Objekte und Attribute aus beliebigen OpenStreetMap-Datensätzen
extrahiert und in eine SQLite-Datenbank (Abschnitt 3.2) speichert. Im An-
hang 6.1.1 wird gezeigt, wie das Osmosis-Plugin zum Erstellen einer ÖPNV-
Datenbank ausgeführt wird.
Um diese gewünschte Funktion, also der Extrahierung der ÖPNV-Daten aus
OpenStreetMap, mit Hilfe von Osmosis bereit stellen zu können, muss ein
sogenannter Task als Plugin implementiert werden. Die Abbildung 3.1 stellt
die Verarbeitung der OSM-Daten durch Osmosis dar und wird im Folgenden
beschrieben. Es gibt drei Arten von Plugins: Source-, Sink - und SinkSource-
Abbildung 3.1: Datenverarbeitung mittels Osmosis ([34] S.50)
Plugins. Das Einlesen von OSM-Daten aus PBF- oder XML-Dateien sowie
das Weiterleiten dieser Daten erfolgen durch Source-Plugins. Sink -Plugins
dienen dazu die Daten zu serialisieren und dann in einem Format wie XML
oder PBF zu speichern. SinkSource-Plugins übernehmen deren Weiterver-
arbeitung. Daten eines Osmosis-Tasks werden eingelesen, möglicher Weise
verändert und an den nächsten Task weitergegeben. Dies ermöglicht z.B.
das Filtern, Ändern, Löschen oder Vereinigen von Daten.
173.2 Die ÖPNV-Datenbank Ramdane Sennoun
3.2 Die ÖPNV-Datenbank
Die Aufgabe der ÖPNV-Datenbank ist es, Haltestellen nach ihrem Namen,
nach einer Route und in einem bestimmten Umkreis einer geographischen
Lage zu finden. Außerdem sollen zusätzliche Informationen zu den einzel-
nen Haltestellen geliefert werden. Im Folgenden soll das Datenbankschema
vorgestellt werden, das aus der Vorverarbeitung der OSM-Daten im letzten
vorletzten Abschnitt hervorgeht.
3.2.1 Entwurf des Datenbanksystems
Nachdem die in OpenStreetMap gespeicherten ÖPNV-Daten (OSM-Objekt-
typen, Tags und Attribute) gesammelt wurden, konnten einige Gruppierun-
gen von Tags und Attributen vorgenommen werden. Zudem bildeten sich
aus den Objekttypen zwei wichtige Klassen (für das Plugin) bzw. Daten-
banktabellen (für das Datenbankschema) heraus: die Verkehrslinien und die
dazugehörigen Haltestellen.
GTFS - Stops und Routes
Hierzu sollen die GTFS-Objekte Stops (Abb. 3.2) und Routes (Abb. 3.3)
herangezogen und beschrieben werden, weil sie eine gute Grundstruktur zur
Informationsspeicherung bieten und sich daraus auch die Informationsstruk-
turanforderungen ableiten können.
Abbildung 3.2: GTFS - Stops Spezifikation
183.2 Die ÖPNV-Datenbank Ramdane Sennoun
Objektbeschreibung: Stops
• Anzahl: 8000 1
• Attribute
– stop id (obligatorisch) ist die eindeutige Kennung einer Station
bzw. Haltestelle, die zu mehreren Verkehrslinien gehören kann.
Eignung bezüglich dieser Arbeit: Da im OpenStreetMap-Format
jeder Objekttyp mit einer eindeutige ID versehen ist, eignet es
sich, dieses Feld so zu übernehmen. Abgeleitet aus OpenStreetMap-
Knoten ergibt sich folgende Informationsstruktur:
∗ Typ: unsigned Long
∗ Länge: 20
∗ Wertebereich: 0...18.446.744.073.709.551.615
∗ Anzahl Wiederholungen: 0
∗ Definiertheit: 100%
∗ Identifizierend: ja
– stop code (optional) hat eine ähnliche Funktion wie stop id. Die-
ses Feld identifiziert die Station für Passagiere.
Eignung bezüglich dieser Arbeit: Da in OSM nur die id zur ein-
deutigen Kennung gibt, könnte man dieses Feld mit der ID gleich-
setzen. Da es jedoch für diese Arbeit keinen Nutzen stellt, wur-
de das Feld freigelassen bzw. nicht mit in das Datenbankschema
übernommen.
– stop name (obligatorisch) enthält den Namen einer Station.
Eignung bezüglich dieser Arbeit: Das Feld wird so übernommen
und wird mit dem OSM-Tag name gefüllt. Einige Haltestellen
enthalten in OSM auf Grund von Fehlern beim Tagging oder
wegen fehlender Informationen einen leeren String, die aber ver-
nachlässigt werden können.
∗ Typ: String
∗ Länge: 255 2
∗ Wertebereich: Menge aller Zeichenketten
∗ Anzahl Wiederholungen: 0
1
Schätzwert abgeleitet von Berlin als Referenzstadt mit gut ausgebautem ÖPNV-Netz
[14] und hoher Beförderungsleistung [4]
2
Anzahl der Zeichen
193.2 Die ÖPNV-Datenbank Ramdane Sennoun
∗ Definiertheit: 100%
∗ Identifizierend: nein
– stop desc (optional) enthält eine Beschreibung über die Stati-
on. Es sollten möglichst nützliche und qualitative Informationen
bereitgestellt werden und nicht einfach der Name kopiert werden.
Eignung bezüglich dieser Arbeit: Dieses Feld wird je nach Verfügung
durch mehrere OSM-Tags gefüllt: addr, atm, phone, note, surveil-
lance und wheelchair.
∗ Typ: String
∗ Länge: 255
∗ Wertebereich: Menge aller Zeichenketten
∗ Anzahl Wiederholungen: 0
∗ Definiertheit: 90%
∗ Identifizierend: nein
– stop lat (obligatorisch) enthält die geographische Breite der Sta-
tion bzw. Haltestelle, die aus dem OSM-Attribute lat vom Node
entnommen wird.
∗ Typ: Dezimalgrad (double)
∗ Länge: (3,15)3
∗ Wertebereich: -90...0...90 (von 0◦ (am Äquator) bis ±90◦ (an
den Polen)
∗ Anzahl Wiederholungen: 0
∗ Definiertheit: 100%
∗ Identifizierend: nein
– stop lon (obligatorisch) enthält die geographische Länge, die aus
dem OSM-Attribute lon ausgelesen wird und weist größtenteils
die selbe Struktur wie stop lat auf. Der Wertebereich unterschei-
det sich.
∗ Wertebereich: -180.00...0...180.00 (ausgehend vom Nullmeri-
dian (0◦ ) bis 180◦ in östlicher und 180◦ in westlicher Rich-
tung)
Eignung von stop lon und stop lat bezüglich dieser Arbeit: Diese
Felder dienen der genauen Positionierung und sind für das System
notwendig.
3
bis zu dreistellige Dezimalzahl mit maximal 15 Nachkommastellen
203.2 Die ÖPNV-Datenbank Ramdane Sennoun
– stop url (optional) enthält eine URL einer Webseite über eine
bestimmte Station.
Eignung bezüglich dieser Arbeit: Da das fertige System keine
Abfahrts- und Ankunftszeiten beinhaltet und primär offline ab-
rufbar ist, sollte bei bestehender Internetverbindung auch eine
Webseite bereitgestellt werden, bei der mehrere Informationen
z.B. zu Abfahrtszeiten abgefragt werden können.
∗ Typ: String
∗ Länge: 255
∗ Wertebereich: Menge aller Zeichenketten
∗ Anzahl Wiederholungen: Es können mehrere Internetadres-
sen (Google-Suche, Wikipedia-Artikel,. . . ) vorhanden sein.
∗ Definiertheit: 100% 4
∗ Identifizierend: nein
Die folgenden Attribute werden der Vollständigkeit halber be-
schrieben, sind aber bis auf wheelchair wegen fehlender OSM-
Repräsentation für diese Arbeit nicht von Bedeutung.
– zone id (optional) definiert die Tarifzone, die in OpenStreet-
Map nicht erfasst und somit in diesem Datenbankschema igno-
riert wird.
– location type (optional) identifiziert ob diese stop id eine Sta-
tion mit mehreren Haltestelle (Wert 1) oder mit einer einzel-
nen Einsteige- und Aussteigemöglichkeit (Wert 0 oder leer) re-
präsentiert.
– parent station (optional) ist die stop id der vorher angefahren
Station (Vorr. location type=1 ) der jeweiligen Route.
– stop timezone (optional) gibt an, in welcher Zeitzone sich die
Station befindet.
– wheelchair boarding (optional) war zum Zeitpunkt der Vorver-
arbeitung und Implementierung noch nicht mit in der Spezifikati-
on integriert. Dieses Feld enthält die Information, ob eine Station
behindertengerecht genutzt werden kann. In OpenStreetMap gibt
es dafür das Tag wheelchair, das jedoch mit in die Haltestellen-
beschreibung übernommen wurde.
4
Bei fehlendem Tag soll automatisch ein Suchmaschinen-Link mit stop name generiert
werden.
213.2 Die ÖPNV-Datenbank Ramdane Sennoun
Objektbeschreibung: Routes
Abbildung 3.3: GTFS - Routes Spezifikation
• Anzahl: 500 5
• Attribute
– route id (obligatorisch) ist die eindeutige Kennung einer Ver-
kehrslinie.
∗ Typ: unsigned Long
∗ Länge: 20
∗ Wertebereich: 0...18.446.744.073.709.551.615
∗ Anzahl Wiederholungen: 0
∗ Definiertheit: 100%
∗ Identifizierend: ja
Eignung bezüglich dieser Arbeit: Dieses Feld wird vom OSM-
Attribute id gefüllt. Es nimmt folgende Struktur an:
– agency id (optional) ist die ID des Betreibers, der den GTFS-
Feed erstellt und wird von der agency.txt-Datei referenziert.
Eignung bezüglich dieser Arbeit: Dieses Feld ist für diese Arbeit
irrelevant.
– route short name (obligatorisch) enthält die Benennung der
Route in Kurzform (z.B. für Berlin: U2 (U-Bahn), M48 (Bus),
M6 (Straßenbahn) oder S1 (S-Bahn)
5
Schätzwert abgeleitet von Berlin als Referenzstadt [14], enthält Hin- und
Rückfahrtlinien
223.2 Die ÖPNV-Datenbank Ramdane Sennoun
– route long name (obligatorisch) enthält den ganzen Namen ei-
ner Route und bekommt meistens den Namen der Endhaltestelle
zugewiesen.
Eignung von route short name und route long name bezüglich
dieser Arbeit: Beide Felder werden auch in OpenStreetMap er-
fasst und werden von den Tags ref (für route shortname) und to
(für route long name) repräsentiert. Fehlt das Tag to, so ist das
Tag name repräsentativ.
∗ Typ: String
∗ Länge: 255
∗ Wertebereich: Menge aller Zeichenketten
∗ Anzahl Wiederholungen: 0
∗ Definiertheit: 100%
∗ Identifizierend: ja
– route desc (optional) beschreibt die Route detaillierter.
Eignung bezüglich dieser Arbeit: Für dieses System setzt sich
dieses Feld aus den OSM-Tags from, to und note zusammen.
∗ Typ: String
∗ Länge: 255
∗ Wertebereich: Menge der Zeichenkette
∗ Anzahl Wiederholungen: 0
∗ Definiertheit: 90%
∗ Identifizierend: nein
– route type (obligatorisch) beschreibt, mit welcher Art von Ver-
kehrsmittel diese Route gefahren wird.
Eignung bezüglich dieser Arbeit: Dieses Feld ist wichtig zur Un-
terscheidung der Verkehrsmittel und wird durch das Tag route
beschrieben. Folgende Verkehrsmittel müssen aus OSM extrahiert
und einheitlich dargestellt werden.
∗ U-Bahn (U2, U6, . . . )
∗ S-Bahn (S55, S2, . . . )
∗ Bus (M48, M85, N6, . . . )
∗ Tram (M1, M2, M17, . . . )
∗ Ferry (F10, F11, F12, . . . )
∗ Haupt- und Nebenbahnen
· Schnellzüge (ICE, IC, . . . )
233.2 Die ÖPNV-Datenbank Ramdane Sennoun
· Regionalbahn (Deutsche Bahn)
∗ Standseilbahn
∗ Gondelbahn
∗ Kabelstraßenbahn (z.B. in San Francisco)
Je nach Verkehrsmittel, wird in der Darstellung ein anderes Logo
verwendet.
∗ Typ: Byte
∗ Länge: 1
∗ Wertebereich: 0...8
Wert Verkehrsmittel Tag/Wert
0 S-Bahn light rail
1 U-Bahn subway
2 Haupt- und Nebenbahnen rail, railway, train
3 Bus bus
4 Fähre ferry
5 Kabelstraßenbahn aerialway=cable car
6 Gondelbahn aerialway=gondola
7 Standseilbahn railway=funicular
8 Straßenbahn tram
∗ Anzahl Wiederholungen: 0
∗ Definiertheit: 100
∗ Identifizierend: nein
– route url (optional) enthält eine URL einer Webseite über eine
Route.
Eignung bezüglich dieser Arbeit: Die Webseite soll dazu dienen,
dem Nutzer mehr Informationen aus dem Internet zu liefern, um
eventuell aktuelle Meldungen zum Betrieb zu bekommen. Die
gängigen OSM-Tags für dieses Feld sind website und wikipedia.
∗ Typ: String
∗ Länge: 255
∗ Wertebereich: Menge aller Zeichenketten
∗ Anzahl Wiederholungen: mehrere Internetadressen möglich
∗ Definiertheit: 100
∗ Identifizierend: nein
– route color (optional) definiert die Darstellungsfarbe der Ver-
kehrslinie auf einer Karte als sechsstellige Hexadezimalzahl.
243.2 Die ÖPNV-Datenbank Ramdane Sennoun
– route text color (optional) gibt die Textfarbe einer Route an,
die zu route color im Kontrast stehen sollte.
Eignung von route color und route text color bezüglich dieser Ar-
beit: Da die Darstellungsweise über das Rendertheme (Abschnitt
3.6) vordefiniert wird, werden diese Felder nicht betrachtet.
Auf Grundlage der Vorverarbeitung und Beschreibung der Informationss-
trukturanforderungen wurde ein vorläufiges, konzeptuelles Entity-Relation-
Modell erstellt, um die ersten existierenden Konzepte der zu modellieren-
den Welt und die Beziehungen zu einander veranschaulichen zu können. In
Abbildung 3.4: Vorläufiges, konzeptuelles Schema der ÖPNV-Datenbank
dem in Abbildung 3.4 gezeigten ER-Schema gibt es zwei Gegenstandstypen
(Entity) und ein Beziehungstyp (Relation). Den Gegenstandstypen Stops
und Routes sind jeweils ein identifizierendes Schlüsselattribut und weitere
beschreibende Attribute zugeordnet. Die Schlüssel sind im obigen Schema
durch Unterstreichung gekennzeichnet.
3.2.2 Das Datenbankschema
In diesem Abschnitt soll das bereits erstellte konzeptuelle Schema verfei-
nert und erweitert werden. Zudem werden im Folgenden die grundlegenden
Strukturierungskonzepte des Entity-Relationship Modells als Relationen des
relationalen Datenmodells beschrieben. Wurden das Schema verfeinert und
die Indexstrukturen festgelegt, so kann das endgültige Datenbankschema
und die dazu entwickelte Programmierschnittstelle vorgestellt werden.
253.2 Die ÖPNV-Datenbank Ramdane Sennoun
Das bisherige Schema besteht aus folgenden Relationen:
Stops : {[stop id : integer, stop name : string, stop desc : string, stop lat :
double, stop lon : double, stop url : string]}
Routes : {[route id : integer, route short name : string, route long name :
string, route desc : string, route type : integer, route url : string]}
gehörtZu : {[stop id : integer, route id : integer]}
Die Relation zur zugehörigen Beziehung gehörtZu hat den Schlüssel {stop id,
route id }, da Stationen i.A. zu mehreren Verkehrslinien gehören können und
umgekehrt Verkehrslinien aus mehreren Stationen bestehen. In diesem Fall
bildet die Menge aller Fremdschlüsselattribute den Schlüssel der Relation. In
Abbildung 3.5 soll dies an einer Beispielausprägung der Relation gehörtZu
illustriert werden. Es gibt zu einer stop id mehrere Einträge in der Relation
Abbildung 3.5: Beispielausprägung der Relation gehörtZu
gehörtZu. Ebenfalls gibt es zu einer gegebenen route id mehrere Einträge.
Die Werte des Attributs stop id aus gehörtZu verweisen als Fremdschlüssel
auf Tupel der Relation Stops. Analog verweisen die Werte des Attributs rou-
te id aus gehörtZu auf Tupel der Relation Routes.
Auf dem bisher vorgestellten Datenbankschema könnte man Abfragen defi-
nieren, die das Suchen und Finden von öffentlichen Verkehrshaltestellen mit
bestimmten sachlichen und räumlichen Kriterien ermöglicht.
263.3 R-Baum und R*-Baum Ramdane Sennoun
Beispiele:
• sachlich: Welche oder wie viele Stationen gehören zur U-Bahn-Linie
U2?
• sachlich: Wo liegt die Bushaltestelle Zwieseler Straße?
• räumlich: Es sei ein Ortspunkt S mit Breitengrad −90.0◦ ≤ lat ≤ 90.0◦
und Längengrad −180.0◦ ≤ lon ≤ 180.0◦ gegeben. Welche nahegele-
genen Stationen befinden sich in einem Umkreis von 500 Metern zu
S?
Die Selektionsprädikate der räumlichen Anfrage beziehen sich also auf meh-
rere Attribute der Relation Stops. Um die k nächsten Nachbar-Elemente des
Punktes S aus der Stops-Tabelle zu ermitteln, müsste man n ≥ k Elemente
{n =|Stops|} auslesen. Dies scheint mit diesem Datenbankschema ungeeig-
net, da man beim Suchen von umliegenden Haltestellen im Umkreis von 200
Metern nicht mehr als 20 bzw. weniger Stationen erwarten würde.
Um diese Suche effizient zu gestalten wird eine mehrdimensionale (räumliche)
dynamische Indexstruktur verwendet. Die Dimensionen, dessen Intervalle
durch die geografische Lagen der Stationen bzw. Haltestellen angegeben
sind, werden intern über einen R*-Baum [33] indiziert. In einem Bench-
mark (Kapitel 4.2) wird der zeitliche Aufwand von Anfragen mit und ohne
R*-Baum-Implementierung verglichen.
3.3 R-Baum und R*-Baum
Der R-Baum als räumliche, hoch-balancierte Indexstruktur, vorgestellt von
Antonin Guttman im Jahre 1984 [35], erlaubt es, effiziente Bereichsanfra-
gen bzw. Anfragen nach den nächsten Nachbarn zu beantworten. Der R-
Baum ähnelt dem B-Baum und besitzt zwei Knotentypen: Blattknoten und
innere Knoten. Die Blattknoten des Baumes speichern die zu indizieren-
den räumlichen Daten, die mit Hilfe von minimal umgebenden Rechtecken
(MUR) (Englisch: minimal bounding rectangle, MBR, auch minimal boun-
ding box, MBB) umschlossen sind. Ein Blattknoten hat die Form (MUR,
tuple id), wobei tuple id das n-dimensionale Datenobjekt repräsentiert. Die
n-dimensional, minimal umgebenden Rechtecke umfassen die im Teilbaum
darunterliegenden räumlichen Daten.
Ein innerer Knoten ist ein Paar aus MUR und einem Verweis auf ein Kinds-
knoten (MUR, child) im R-Baum. Die Struktur eines R-Baums muss nach
Guttman folgende Eigenschaften aufweisen:
273.3 R-Baum und R*-Baum Ramdane Sennoun
M
Es sei M die maximale Anzahl der Einträge pro Knoten und m ≤ 2 die
minimale Anzahl von Einträgen in einem Knoten.
1. Jeder Blattknoten enthält mindestens m und maximal M Indexein-
träge, wenn der Blattknoten nicht die Wurzel ist.
2. Für jeden Indexeintrag i eines Blattknotens ist MUR das kleinst-
möglich spannbare Rechteck, das die indizierten Datenobjekte um-
fasst.
3. Ein innerer Knoten hat mindestens m und maximal M Kindsknoten,
wenn es nicht der Wurzelknoten ist.
4. Für jeden Eintrag der Form (MUR, child) eines inneren Knotens ist
MUR das kleinst-möglich spannbare Rechteck, das die Rechtecke der
Kindsknoten umfasst.
5. Ist die Wurzel kein Blattknoten, so hat sie mindestens zwei Kinder
(Nachfolgerknoten).
6. Alle Blätter befinden sich auf einer gleichen Ebene.
Sei N die Anzahl der Indexeinträge, dann ist die maximale Höhe eines R-
Baums | logm N | −1. Guttman begründet dies damit, dass die Anzahl
der Kinder jedes Knotens (der sogenannte Branching factor) mindestens m
beträgt. Auf einen formellen Beweis wird hier verzichtet. Die Abbildung 3.6
zeigt eine Beispielstruktur eines R-Baums. Die dazugehörige Abbildung 3.7
soll zusätzlich die überlappenden Beziehungen der Rechtecke zu einander
illustrieren.
Abbildung 3.6: Beispielstruktur eines R-Baums
283.3 R-Baum und R*-Baum Ramdane Sennoun
Abbildung 3.7: Darstellung der überlappenden Rechtecke des R-Baums aus
Abbildung 3.6
Operationen
Im Folgenden soll auf die auf einem R-Baum abwendbaren Operationen
Suchen und Einfügen eingegangen werden. Des Weiteren werden einige Al-
gorithmen zur Knotenteilung vorgestellt. Danach wird formal eine Variation
des R-Baums vorgestellt, die sich im Einfüge- und Splitt-Algorithmus un-
terscheidet, dem R*-Baum. Das für diese Arbeit entwickelte System benutzt
eine benutzerdefinierte SQLite-Bibliothek, die es ermöglicht, räumliche In-
dexe anzulegen. Wie bereits Ende des letzten Abschnitts erwähnt, geschieht
dies über einen R*-Baum.
3.3.1 Suchen
Die Suche funktioniert ähnlich wie beim B-Baum und soll an einem Beispiel
demonstriert werden. Es wird nur der von Antonin Guttman vorgestellte
Suchalgorithmus beschrieben. Es gibt mehrere Suchalgorithmen wie z.B. der
Tiefensuche-Algorithmus von Kelley, Roussopoulos und Vincent [40].
Es sei ein R-Baum mit einer Wurzel T gegeben. S sei das Rechteck, das alle
gesuchten Indexeinträge umfasst (Abbildung 3.8). Beginnend bei der Wurzel
T werden alle Einträge des aktuell besuchten Knotens rekursiv durchsucht,
wenn der jeweilige Eintrag sich mit S schneidet. Wird ein Blattknoten er-
reicht, so werden alle die in den Blättern enthaltenen Verweise als Ergebnis
zurückgegeben.
293.3 R-Baum und R*-Baum Ramdane Sennoun
Abbildung 3.8: Beispiel zur Operation Suchen auf einem R-Baum
Abbildung 3.9: R-Baum Operation Suchen
In Abbildung 3.9 sind die bei der Suche untersuchten Einträge markiert.
S überschneidet sich mit den Wurzeleinträgen R1 und R2. Daher müssen
beide Pfade untersucht werden. In R1 gibt es die Rechtecke R3 und R4
und in R2 das Rechteck R6, die sich mit S decken. Es werden also nun die
Rechtecke R3, R4 sowie R6 auf passende Einträge überprüft und erreicht
somit die Blattknoten. In R3 gehört R10 zur Ergebnismenge. In R4 und R6
sind es R12 bzw. R16. R10, R12 und R16 sind das Ergebnis dieser Suche.
303.3 R-Baum und R*-Baum Ramdane Sennoun
3.3.2 Einfügen
Es sei I der neue Indexeintrag, der in den R-Baum eingefügt werden soll
und ChooseLeaf der Algorithmus, mit dem ein geeignetes Blatt B gefun-
den wird, in den I eingetragen werden soll. Hat B einen freien Platz für I,
also wenn M nicht überschritten wird, so wird I eingetragen. Im andern Fall
müssen die M+1 Einträge auf zwei Knoten gesplittet werden.
SplitNode sei der dafür angewandte Algorithmus und wird hinterher be-
schrieben. Wird bis zur Wurzel gesplittet, so entsteht eine neue Wurzel mit
den zwei neu entstandenen Knoten. Wurde I eingefügt, müssen die Vater-
knoten angepasst werden. Es sei AdjustTree die dafür angewandte Funk-
tion.
• ChooseLeaf wählt das Blatt aus, das den neuen Eintrag I mit dem
Rechteck M U RI bekommt: Sei N der Wurzelknoten. Ist N ein Blatt,
so wird N zurückgegeben. Solange N kein Blatt ist, wird ein Kinds-
knoten ausgewählt, dessen MUR die kleinste Veränderung braucht, um
M U RI zu umfassen.
• AdjustTree sorgt dafür, dass beginnend bei einem Blatt B aufstei-
gend zur Wurzel die MUR angepasst und wenn nötig Knoten geteilt
werden (SplitNode). Setze N = B und führe folgende Schritte aus,
solange N keine Wurzel ist:
– Es sei P der Vaterknoten von N und EN = (M U RN , NID ) der
Eintrag in P, der auf N zeigt. M U RN muss so angepasst werden,
so dass alle MUR in N möglichst eng umschlossen werden.
– Wenn N einen aus einem früheren SplitNode resultierten Part-
ner NN hat, dann sei EN N = (M U RN N , N NID ) der Eintrag in
P, der auf NN zeigt. M U RN N muss dann so angepasst werden,
so dass es alle MUR in NN eng umschließt.
∗ Wurde durch den Eintrag EN N M überschritten, so führe
SplitNode auf P aus, um die zwei Knoten P und PP zu
bekommen, die nun EN N und alle alten Einträge von P ent-
halten. Ist P die Wurzel, so erstelle eine Neue Wurzel mit
den Kindsknoten P und PP.
– Wurden keine Veränderungen vorgenommen und kein SplitNode
ausgeführt, so beende das Vorgehen. Andernfalls setze N = P
und beginne von vorne.
313.3 R-Baum und R*-Baum Ramdane Sennoun
Beispiel
In den etwas vereinfachten R-Baum vom vorherigen Beispiel soll das Recht-
eck R17 eingefügt werden (Abbildung 3.10). Abbildung 3.11 veranschau-
licht den Weg von ChooseLeaf . Der Algorithmus wählt in R1 das Rechteck
R3, weil R4 bei der Umschließung von R17 eine größere Erweiterung be-
deuten würde.
Abbildung 3.10: Beispiel zur Operation Einfuegen in einen R-Baum
Abbildung 3.11: ChooseLeaf-Weg
Da der ausgewählte Blattknoten voll ist, muss der Knoten geteilt werden.
Abbildung 3.12 zeigt den neuen R-Baum. R8 und R9 sind im Rechteck R3,
R7 und R17 werden in ein neues Rechteck R3’ im Vaterknoten gelegt. Split-
Node versucht die neu entstandenen Rechtecke möglichst klein zu halten.
323.3 R-Baum und R*-Baum Ramdane Sennoun
AdjustTree wird auf R3 angewandt.
Abbildung 3.12: Neuer R-Baum
Da der aktuelle Knoten genug Platz für R3’ hat, wird keine Teilung durch-
geführt und die Wurzel erreicht, womit die Operation endet. Das Ergebnis
ist in Abbildung 3.13 dargestellt.
Abbildung 3.13: Ergebnis der Operation
3.3.3 SplitNode - Teilung eines Knotens
Ein Knoten muss in zwei Knoten geteilt werden, wenn beim Einfügen eines
Eintrags E die maximale Anzahl von Einträgen M überschritten wird. In
Abbildung 3.14 wird eine schlechte und eine gute Teilung präsentiert. Auf
der linken Seite ist erkennbar, dass von den äußeren MUR unnötig viel Platz
eingenommen wird. Die MUR sollen möglichst klein gehalten werden (Gute
Teilung), so dass mit möglichst geringer Wahrscheinlichkeit beide Knoten
33Sie können auch lesen

















































