Entwicklung eines Benutzermodells zur nutzeradaptiven Suche von Datensätzen - ELIB-DLR
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Entwicklung eines Benutzermodells zur
nutzeradaptiven Suche von Datensätzen
Masterarbeit
zur Erlangung des akademischen Grades
Master of Science (M. Sc.)
im Studiengang Informatik
Friedrich-Schiller-Universität Jena
Fakultät für Mathematik und Informatik
eingereicht von Tim Surber
geb. am 10.07.1996 in Jena
Themenverantwortliche: Prof. Birgitta König-Ries, FSU Jena
Betreuer: Sirko Schindler, DLR-Institut für Datenwissenschaften, Jena
Zweitgutachterin: Dr. Friederike Klan, DLR-Institut für Datenwissenschaften, Jena
Jena, 17. März 2021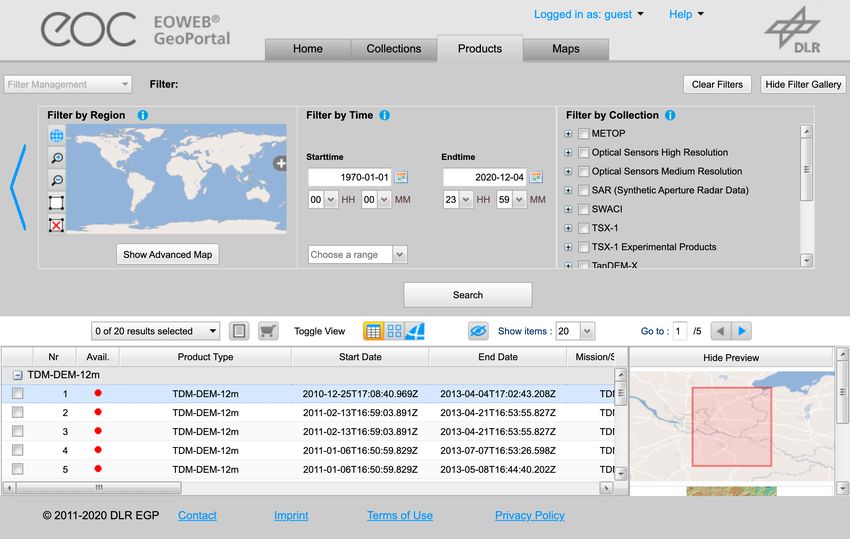
Kurzfassung
Datenportale stellen eine große Menge an Datensätzen zur Verfügung. Das Finden des
gesuchten Datensatzes stellt dabei eine Herausforderung dar. Das Ziel dieser Arbeit
ist es, den Nutzer gezielter zum gewünschten Datensatz zu führen. Die gewählte
Methode ist das Erstellen eines Benutzermodells, um die Suche nutzeradaptiv zu
gestalten. Als eine mögliche Adaption wird in dieser Arbeit das Unterstützen des
Nutzers bei der Verwendung von Suchfiltern betrachtet. Durch Vorhersage zukün-
figer Interaktionen können Suchfiltervorschläge erzeugt werden. Dazu wurde ein
Modell unter Verwendung von partiell sortierten Sequenzregeln anhand vorheriger
Nutzersitzungen trainiert.
Das Modell wurde anhand eines vorliegenden Datensatzes, den Aufzeichnungen
eines Geodatenportals, geprüft. Es konnten die Suchfilter des nächsten Schrittes mit
einer Genauigkeit von 51% vorhergesagt werden, was eine deutliche Verbesserung
gegenüber eine zufälligen Vorhersage unter gleichen Bedinungen mit 11% darstellt.
Die Ergebnisse zeigen, dass die Entwicklung eines Benutzermodells ein geeignetes
Vorgehen ist, um Suchfilter vorherzusagen. Dies kann eingesetzt werden, um das
Suchen in Datenportalen zu verbessern.
Abstract
Data portals host a large amount of data records. Finding the right data set can
be challenging. The goal of this work is to guide the user to the correct data set.
This is implemented by creating a user model to make the search user-adaptive. This
work focuses on supporting the user in using search filters. By predicting future
interactions, search filter suggestions can be generated. For this purpose, a model is
trained using partially-ordered sequential rules with previous user sessions.
The model was tested on an existing dataset, the records of a geospatial portal. It was
able to predict the search filters of the next step with an accuracy of 51%, which is a
significant improvement over a random prediction under the same conditions with
11%. The results show that the development of a user model is a suitable process to
predict search filters. This can be used to improve searching in data portals.
I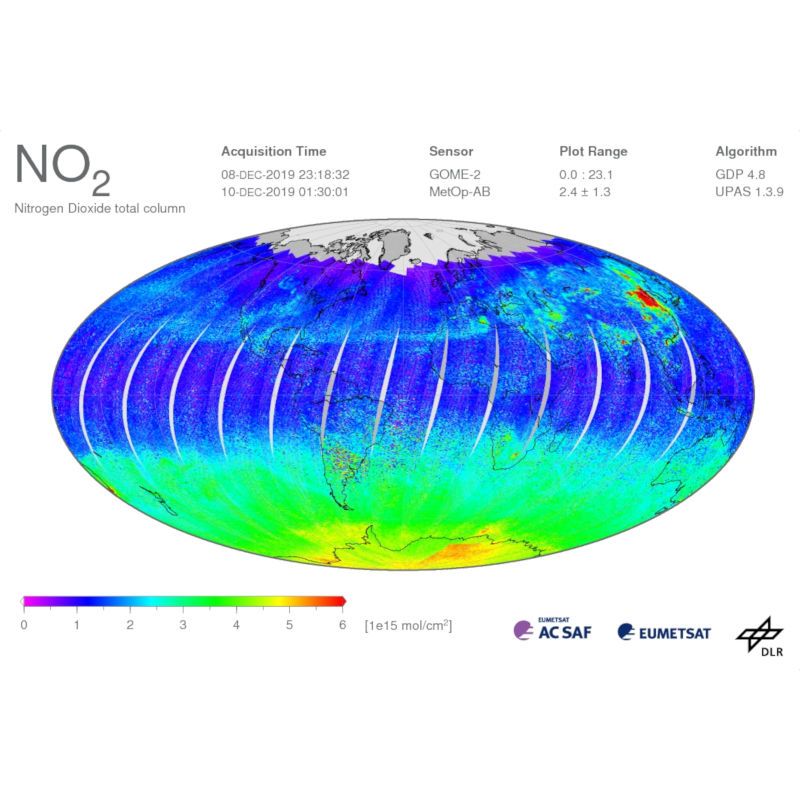
Inhaltsverzeichnis
1 Einleitung 1
2 Stand der Forschung 4
2.1 Sequenzmusteranalyse . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.1 Transaktionsdatenbank . . . . . . . . . . . . . . . . . . . . . . 6
2.1.2 Bewertung der Signifikanz . . . . . . . . . . . . . . . . . . . . 8
2.1.3 Vorhersage . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1.4 Anwendungen . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.1.5 Implementationen . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2 Sequenzregelanalyse . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2.1 Bewertung der Signifikanz . . . . . . . . . . . . . . . . . . . . 10
2.2.2 Varianten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2.3 Anwendungen . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.2.4 Implementationen . . . . . . . . . . . . . . . . . . . . . . . . 13
2.3 Markov-Ketten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3.1 Anwendungen . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.3.2 Implementierungen . . . . . . . . . . . . . . . . . . . . . . . . 15
2.4 Künstliche Neuronale Netze . . . . . . . . . . . . . . . . . . . . . . . 16
2.4.1 Anwendungen . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.4.2 Implementierungen . . . . . . . . . . . . . . . . . . . . . . . . 17
2.5 EOWEB® GeoPortal . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.6 Benutzermodelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3 Konzept 24
3.1 Anforderungen an den Datensatz . . . . . . . . . . . . . . . . . . . . 25
3.2 Anforderungen an das Vorhersageverfahren . . . . . . . . . . . . . . . 27
3.3 Auswahl des Vorhersageverfahrens . . . . . . . . . . . . . . . . . . . . 27
3.4 Definition der Elemente . . . . . . . . . . . . . . . . . . . . . . . . . 30
4 Datensatz 31
4.1 Inhalt . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
II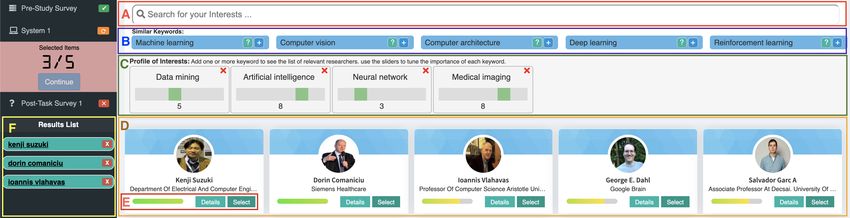
Inhaltsverzeichnis
4.2 Merkmale des Datensatzes . . . . . . . . . . . . . . . . . . . . . . . . 34
5 Umsetzung 38
5.1 Datenvorverarbeitung . . . . . . . . . . . . . . . . . . . . . . . . . . 38
5.1.1 Aggregation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
5.1.2 Generieren der Transaktionsdatenbank aus Feldern des Da-
tensatzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
5.1.3 Filterung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
5.2 Vorhersage durch Anwendung der Sequenzregelanalyse . . . . . . . . 41
5.2.1 Vorhersage unter Anwendung partiell sortierter Sequenzregeln
(PSSR) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
5.2.2 Priorisierte partiell sortierte Sequenzregeln (PPSSR) . . . . . 46
5.3 Technische Umsetzung . . . . . . . . . . . . . . . . . . . . . . . . . . 48
6 Evaluation 49
6.1 Ergebnisse der Vorfilterung . . . . . . . . . . . . . . . . . . . . . . . 49
6.2 Parametrisierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
6.2.1 Hyperparameter . . . . . . . . . . . . . . . . . . . . . . . . . 50
6.2.2 Konfiguration . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
6.2.3 Verwendete Parametergrößen . . . . . . . . . . . . . . . . . . 52
6.2.4 Parameterkombinationen bilden . . . . . . . . . . . . . . . . . 53
6.3 Prüfen der Vorhersage . . . . . . . . . . . . . . . . . . . . . . . . . . 53
6.4 Auswahl des Modells . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
6.4.1 Auswahlkriterum . . . . . . . . . . . . . . . . . . . . . . . . . 54
6.4.2 Vorgehen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
6.5 Vergleichsverfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
6.6 Auswertung der Vorhersageergebnisse . . . . . . . . . . . . . . . . . . 58
6.7 Einfluss der Parameter . . . . . . . . . . . . . . . . . . . . . . . . . . 59
6.7.1 Umfang der Trainingsdaten . . . . . . . . . . . . . . . . . . . 60
6.7.2 Optimale Hyperparameter . . . . . . . . . . . . . . . . . . . . 61
7 Fazit 63
Literatur 65
Abbildungsverzeichnis 70
Tabellenverzeichnis 71
III1 Einleitung
Ein Datenportal stellt eine Sammlung von Datensätzen zur Verfügung. Es bietet
Funktionen zum gezielten Auffinden von Datensätzen, dazu werden üblicherweise
Datensätze mit Metadaten versehen, um die Suche zu erleichtern.
Eine Umfrage unter Wissenschaftlern zeigt, dass das Finden von passenden Datensät-
zen in Datenportalen zum Einsatz in der Forschung eine anspruchsvolle (73%) oder
sogar schwierige (19%) Aufgabe ist. Ein häufig genannter Grund dafür ist, dass die
zur Verfügung stehenden Suchwerkzeuge nicht adäquat sind (Gregory u. a. 2020).
Der Prozess des Suchens lässt sich in zwei Formen von Suchanwendungen einteilen
(Heyer u. a. 2011). Die nachschlagende Suche wird etwa zum Aufsuchen von Fakten
oder zum Beantworten einer konkreten Frage genutzt. Ein übliches Bedienelement der
nachschlagenden Suche ist eine Suchleiste zur Eingabe von Stichwörtern (Marchionini
2006).
Bei einem Datenportal wird dem Nutzer hingegen eine andere Suchform zur Verfügung
gestellt. Ein Grund dafür ist, dass die nachschlagende Suche sich auf Datenportalen
als wenig effektiv herausgestellt hat. Eine Studie anhand eines biomedizinischen
Datenportals zeigt, dass die Verwendung einer klassischen Suchleiste in vielen Fällen
nicht zum gewünschten Ergebnis führt (Dixit u. a. 2017). Diese Form des Suchens
wird auch als exploratives Suchen bezeichnet. Als Bedienelement der explorativen
Suche können Suchfilter verwendet werden, um die Ergebnismenge immer weiter
einzuschränken, bis schließlich zu dem gesuchten Datensatz navigiert werden kann.
Die Auswahl der Suchfilter durch den Nutzer ist entscheidend für den Erfolg der
Suche. Eine gezielte Auswahl der Suchfilter führt in wenigen Schritten zum korrekten
Ergebnis, was bereits für den Spezialfall einer Filtersuche, der Facettensuche, unter-
sucht wurde (Basu Roy u. a. 2008). Eine unvorteilhafte Wahl der Suchfilter hingegen
11 Einleitung
führt zu einem längeren Suchprozess, was sich negativ auf die Nutzerzufriedenheit
auswirkt (Y. Xu und Mease 2009).
Wenn der Nutzer jedoch bei der Auswahl der Suchfilter unterstützt wird, kann
er gezielter und häufer zu seinen gewünschten Suchergebnissen geführt werden.
Diese Unterstützung lässt sich etwa durch gezieltes Priorisieren bei der Anzeige
der Suchfilter realisieren. Zur Priorisierung der Suchfilter kann eine Vorhersage der
nächsten Nutzerinteraktion dienen.
Die Vorhersage von folgenden Nutzerinteraktion soll in dieser Arbeit betrachtet
werden. Dazu soll ein eine Benutzermodell anhand von historischen Nutzungsdaten
trainiert werden. Hierfür wird in dieser Arbeit ein Prozess entwickelt und angewen-
det. Dieser besteht aus der Vorverarbeitung der Daten, der Wahl eines passenden
Mining- bzw. Analyseverfahrens und abschließender Verifizierung der Korrektheit der
Ergebnisse. Die Vorhersage geschieht nutzerspezifisch, die Adaption erfolgt anhand
des Benutzermodells.
Der Vorhersageprozess soll unabhängig von einem spezifischen Datensatz sein und für
alle Datensätze, die in ein bestimmtes Schema passen, möglich sein. Die Evaluierung
der getätigten Vorhersage soll anhand eines Beispieldatensatzes erfolgen. Dieser
stammt aus dem EOWEB® GeoPortal (EGP) welches vom Deutschen Zentrum für
Luft- und Raumfahrt (DLR) unterhalten wird.
Dieses Datenportal stellt Erdbeobachtungsdaten zur Verfügung. Das EGP hat Such-
filter integriert. Diese erlauben unter anderem eine zeitliche Einschränkung der
Ergebnisse (das Aufnahmedatum) oder eine räumliche Einschränkung (die abgebilde-
te Region). Derzeit ist im EGP noch keine Nutzermodellierung enthalten. Aus den
Aufzeichnungen des EGP lässt sich schließen, dass ein beträchtlicher Teil der Nutzer
den Suchprozess abbricht, bevor ein Ergebnis gefunden werden kann. Dies gibt einen
Hinweis darauf, dass die Optimierung des Suchprozesses für konkret diese Plattform
hilfreich ist.
Für das EGP liegen Aufzeichnungen über mehrere Monate in Form von Logdateien
vor. Aus diesen lassen sich Nutzersitzungen als eine Sequenz von Interaktionen
rekonstruieren. Neben einem Nutzeridentifikator und einem Zeitstempel enthält
jede Interaktion auch Informationen über Art und Inhalt der verwendeten Filter
der Suche. Dies kann als Ausgang für eine Mustererkennung mithilfe eines Data-
21 Einleitung
Mining-Prozesses dienen. Darauf aufbauend kann dann eine Vorhersage für zukünftige
Interaktionen ermöglicht werden. Durch die Aufteilung des Datensatzes in Trainings-
und Testdaten kann eine Prüfung der Vorhersagegenauigkeit durchgeführt werden.
Ziel dieser Arbeit ist es, Nutzer der Suchfunktion eines Datenportals gezielter zu
dem gewünschten Datensatz zu führen. In dieser Arbeit soll ein Teilaspekt behandelt
werden, der verwendet werden kann, um dieses Ziel zu erreichen: Das Priorisieren
von Suchfiltern. Dabei soll ein Vorgehen entwickelt werden, um zukünftige Nutzer-
interaktionen des Suchprozesses vorherzusagen. Durchgeführt wird die Vorhersage
ausschließlich anhand von Logaufzeichnungen. Es werden keine Umfragen mit Nut-
zergruppen durchgeführt. Der tatsächliche Einsatz der vorhergesagten Suchfiltern in
der Benutzeroberfläche und die zugehörige Auswertung dessen bleibt Gegenstand
der zukünftigen Forschung.
Bewertet wird das Erreichen des Ziels in dieser Arbeit durch Evaluation des Vor-
hersageergebnis, wobei die Vorhersagegenauigkeit der wichtigste Messwert ist. Dies
erfolgt, in dem der EGP Datensatz in Test- und Trainingsdaten gesplittet wird.
Im folgenden Kapitel wird der Stand der Forschung erläutert, ebenso findet eine
detaillierte Erklärung des EGP statt. In Kapitel 3 wird das Konzept der Vorhersage
vorgestellt. Anschließend folgt eine Informationen über den verwendeten Datensatz.
Kapitel 5 zeigt die zugehörige Implementation, anschließend erfolgt eine Diskussion
der Vorhersageergebnisse. Zum Schluss findet ein Ausblick auf mögliche zukünftige
Entwicklungen statt.
32 Stand der Forschung
Es existieren bereits Veröffentlichungen, welche eine Vorhersage von Filtern mit dem
Ziel, das Suchergebnis zu verbessern, durchführen.
In (Chantamunee, Wong und Fung 2020) werden künstliche neuronale Netze zum
Bilden von personalisierten Empfehlungen von Suchfacetten eingesetzt. Das entwi-
ckelte Verfahren wird anhand drei öffentlich verfügbarer Datensätze geprüft, diese
Datensätze kommen aus den Bereichen Tourismus und Filmempfehlungen.
Durch (Niu, Fan und Zhang 2019) wird gezeigt, wie Entscheidungsbäume für die
Vorhersage von Suchfacetten genutzt werden können. Dies geschieht anhand eines
Datensatzes, welcher aus Benutzersitzungen eines Online-Katalogs einer Bibliothek
gewonnen wurde. Zusätzlich wird gezeigt, dass die Facettennutzung stark von vorhe-
rigen Interaktionen des Nutzers abhängig ist.
Diese Werke unterscheiden sich jedoch in zwei entscheidenden Punkten von dieser
Arbeit:
Die vorgestellten Werke beziehen sich auf eine Spezialform der Suchfilter, die Fa-
cetten. Diese ähneln den in dieser Arbeit behandelten klassischen Suchfiltern in
gewisser Weise, zeigen aber dennoch entscheidende Unterschiede auf. Die wichtigsten
Unterschiede sind in Tabelle 2.1 dargestellt. Der verschiedene Aufbau von Suchfiltern
und Facetten resultiert zwangsläufig in einem abweichenden Vorgehen des Nutzers.
Der zweite Unterschied betrifft die Art der untersuchten Plattform. In dieser Arbeit
wird die Suche von Datensätzen in einem Datenportal behandelt. In (Kern und
Mathiak 2015) wird gezeigt, dass die Suche nach Datensätzen sich von sonstigen
Suchsituationen (es wird ein Vergleich mit der Suche nach Literatur durchgeführt)
unterscheidet. Die Nutzer von Datenportalen stellen andere Anforderungen an die
42 Stand der Forschung
Suchfilter Facetten
Ändern sich nicht während der Suche Ändern sich abhängig von den Such-
ergebnissen
Können vor und nach einer Suchanfrage Können nur nach einer Suchanfrage se-
selektiert werden lektiert werden
Hauptsächlich genutzt in informations- Hauptsächlich in E-Commerce Anwen-
reichen Seiten dungen genutzt
Leere Ergebnismenge möglich Ergebnismenge zeigt immer mindestens
ein Resultat
Tabelle 2.1: Vergleich Suchfilter mit Facetten. Quelle: (Kennedy 2020)
Ergebnisse, so ist das Vorkommen und die Qualität von Metadaten besonders wich-
tig. Auch die Suchvorgehen unterscheiden sich, eine Suche auf Datenportalen wird
aufgrund der Wichtigkeit für die Nutzer intensiver durchgeführt.
Die Einschränkung auf Datenportale und die Vorhersage von klassischen Suchfil-
tern unterscheidet diese Arbeit von bisherigen Publikationen und behandelt somit
neue Aspekte. Dem Autor ist keine Publikation bekannt, welche Vorhersagen von
Suchfiltern in einem Datenportal durchführt.
Die Vorhersage von zukünftigen Benutzerinteraktionen mit enthaltenen Suchfiltern
erfolgt auf Basis vorheriger Benutzerinteraktionen. Die aufeinanderfolgenden Interak-
tionen können als sequenzielle Daten betrachtet werden. Es folgt eine Vorstellung von
in der Literatur bekannten Verfahren, welche eine Vorhersage anhand vorliegender
sequenzieller Daten durchführen können.
Bei dem Finden von Mustern in sequenziellen Daten ist das Kernproblem, zu un-
tersuchen, welche Elemente häufig nacheinander auftreten. Es unterscheidet sich
dabei von Verfahren, welche die Reihenfolge von Elementen nicht beachten, wie etwa
Frequent Itemset Mining oder die Assoziationsanalyse. Diese werden genutzt, um
häufig zusammen auftretende Elemente zu finden (Brückner und Scheffer 2013).
Nach der Vorstellung der Vorhersageverfahren werden in diesem Kapitel relevante
Hintergrundinformationen des EOWEB GeoPortals genannt. Dieses ist der Ursprung
des in dieser Arbeit verwendeten Datensatzes. Zum Schluss werden Informationen
über Benutzermodelle vorgestellt.
52 Stand der Forschung
2.1 Sequenzmusteranalyse
Die Sequenzmusteranalyse ist ein Verfahren, welches als Eingabe eine Transaktionsda-
tenbank benötigt. Aus der Transaktionsdatenbank werden Sequenzmuster extrahiert.
Sequenzmuster zeigen nacheinander auftretende Elemente einer Sequenz, wobei die
signifikanten Sequenzmuster am relevantesten sind.
2.1.1 Transaktionsdatenbank
In Abbildung 2.1 wird ein Beispiel einer Transaktionsdatenbank in zwei verschiedenen
Darstellungsformen gezeigt. In Abbildung 2.1a ist ein Ausschnitt der Transaktions-
datenbank in der ausführlichen Schreibweise gezeigt. In Abbildung 2.1b werden die
gleichen Daten dagegen in einer verkürzten Schreibweise gezeigt, wie sie auch im
Rest der Arbeit verwendet wird. Diese Form eignet sich auch zur Repräsentation der
Transaktionsdatenbank in Textdateien.
Das Beispiel zeigt die Einkäufe von sechs Kunden, jeder Kunde wird durch eine
Kunden-ID bezeichnet. Jedem Kunden lassen sich Einkäufe zuordnen. Ein Einkauf
enthält die erworbenen Produkte A bis E. Die Einkäufe sind sortiert in der Transakti-
onsdatenbank eingefügt, dass bedeutet Einkauf 2 von Kunde 1 fand zu einem späteren
Zeitpunkt als Einkauf 1 von Kunde 1 statt. Jeder Einkauf lässt sich eindeutig durch
das Tupel (Kunden-ID, Einkaufs-ID) bestimmen.
Das Beispiel zeigt etwa, dass Kunde 1 im ersten Einkauf die Produkte A und C
erwarb. Zu einem späteren Einkauf wurde nur Produkt B erworben, zu einem dritten
Einkauf C und E. Kunde 2 erwarb im Beispiel die Produkte A, B und C einzeln in
drei getrennten Einkäufen.
Eine Transaktionsdatenbank wird durch folgende Bestandteile bestimmt:
• Sequenz Die Transaktionsdatenbank enthält Sequenzen. In Abbildung 2.1a
wird eine Sequenz durch die gleiche Kunden-ID gekennzeichnet. In Abbil-
dung 2.1b steht jede neue Zeile für eine Sequenz. Im Beispiel entspricht die
Sequenz der Einkaufshistorie eines einzelnen Kundens.
62 Stand der Forschung
Kunden-ID Einkaufs-ID A B C D E 1: < {A, C}, {B}, {C, E} >
2: < {A}, {B}, {C} >
1 1 3 5 3 5 5
3: < {A, C}, {B}, {D} >
1 2 5 3 5 5 5
4: < {B, D}, {E}, {A} >
1 3 5 5 3 5 3
5: < {E}, {D}, {B}, {A} >
2 1 3 5 5 5 5
6: < {B, D, E}, {A} >
2 2 5 3 5 5 5
2 3 5 5 3 5 5
...
(a) Ausführliche Schreibweise (b) Verkürzte Schreibweise
Abbildung 2.1: Beispiel für eine Transaktionsdatenbank
• Ereignis Eine Sequenz erhält Ereignisse. Die Ereignisse einer Sequenz sind
zeitlich sortiert. In Abbildung 2.1a wird jede Sequenz durch die Kombination
von Kunden-ID und Einkaufs-ID definiert. In Abbildung 2.1b wird eine Sequenz
durch eine Einfassung in geschweifte Klammern {} begrenzt. Die Einkäufe aus
dem Beispiel entsprechen den Ereignissen.
• Element Ein Ereignis enthält eine Menge von Elementen. In dieser Menge
herrscht keine Ordnungsrelation. Die Elemente entsprechen im Beispiel den
Artikeln A bis E des Einkaufs .
Eine mögliches Sequenzmuster, welches aus Abbildung 2.1 abgeleitet werden kann,
ist beispielsweise < {A}, {B}, {C} >. Es ist in den Sequenzen 1 und 2 vorhanden.
Die Trennung der Mengen aus Elementen durch ein Komma impliziert eine zeit-
liche Abfolge; {B} tritt somit zu einem späteren Zeitpunkt als {A}. Dabei ist es
keine Anforderung, dass die Elemente der Sequenzmuster in direkt aufeinanderfol-
genden Ereignissen auftreten. Es können auch beliebig viele Ereignisse dazwischen
auftreten.
Ein anderes Sequenzmuster ist < {B, D}, {A} >, welches in den Sequenzen 4 und 6
auftritt. Wenn mehrere Elemente innerhalb der geschweiften Klammern {} vorhanden
sind, dann treten diese zum gleichen Zeitpunkt auf. Dieses Muster gibt somit an,
dass B und D zum gleichen Zeitpunkt erworben werden und {A} zu einem späteren
Zeitpunkt.
72 Stand der Forschung
2.1.2 Bewertung der Signifikanz
Bei der Sequenzmusteranalyse an einem umfangreichen Datensatz entstehen entspre-
chend viele Sequenzmuster. Um zu bewerten, wie interessant ein Sequenzmuster ist,
kann der Messwert „Support“ verwendet werden.
Support
Der Support eines Sequenzmusters m gibt an, wie groß der Anteil der Sequenzen ist,
die dieses Muster enthalten.
Anzahl der Sequenzen, die m enthalten
sup(m) =
Anzahl aller Sequenzen
Das Sequenzmuster < {A}, {B}, {C} > tritt in den Sequenzen 1 und 2 von insgesamt
sechs Sequenzen auf, der zugehörige Support-Wert ist somit 26 = 33%.
2.1.3 Vorhersage
Sequenzmuster mit dem zugehörigen Support-Wert sind geeignet um häufig nach-
einander auftretende Elemente zu finden. Wie unter anderem durch (Pitman und
Zanker 2011) und (Fournier Viger, Faghihi u. a. 2012) analysiert wurde, eignen sich
Sequenzmuster nur begrenzt zur Vorhersage.
Die Vorhersage durch Sequenzmuster erfordert einen Trainingsdatensatz in Form
einer Transaktionsdatenbank. In dem Trainingsdatensatz werden häufig auftretende
Sequenzmuster gefunden. Anschließend kann anhand von neuen beziehungsweise
unbekannten Sequenzen eine Vorhersage des folgenden Elements durchgeführt werden.
Dabei wird ein Sequenzmuster gewählt, welches eine große Übereinstimmung mit der
neuen Sequenz besitzt. Die verbleibenden Elemente des gewählten Sequenzmusters
entsprechen der Vorhersage.
Die Einschränkungen der Vorhersage durch Sequenzmuster werden an einem Beispiel
verdeutlicht, welches die Transaktionsdatenbank Abbildung 2.1 als Trainingsdaten
verwendet. Dazu wird die Vorhersage einer neuen Sequenz betrachtet. Es sind bereits
zwei Ereignisse in dieser Sequenz enthalten, wobei das erste Ereignis das Element
{A} und das zweite Ereignis {B} enthält. Ziel ist die Vorhersage des folgenden
82 Stand der Forschung
Elements. Dies soll unter der Bedingung durchgeführt werden, dass die Vorhersage
zu mindestens 80% korrekt ist, ansonsten soll keine Vorhersage abgegeben werden.
Diese Information ist jedoch nicht aus dem Sequenzmuster oder dem zugehörigen
Supportwert abzulesen. In der Transaktionsdatenbank lässt sich erkennen, dass auf
{A}, {B} in zwei von drei Fällen C folgt, in Sequenz 1 und 2. In einem von drei
Fällen folgt auf {A}, {B} stattdessen D (in Sequenz 3). Unter der Annahme, dass
die neu eintreffenden Sequenzen gleich wie die Trainingsdaten verteilt sind, ist die
Vorhersage zu 67% korrekt. Damit unterschreitet die Verwendung dieses Musters
den geforderten Anspruch von 80% Korrektheit.
Es lässt sich eine für die Vorhersage nützliche Eigenschaft erkennen, welche in den
Sequenzmustern fehlt: Wenn {A}, {B} auftreten, dann folgt in 67% der Fälle {C}.
Diese Eigenschaft wird von den Sequenzregeln genutzt, welche in Abschnitt 2.2
vorgestellt werden.
2.1.4 Anwendungen
Insbesondere im medizinischen Bereich existieren Forschungsprojekte, welche Se-
quenzmuster verwenden. Sequenzmuster sind geeignet, um etwa Kombinationen von
Risikofaktoren einer Krankheit zu ermitteln. Beispiele dafür sind das Erkennen von
Risikofaktoren einer HIV-Erkrankung (Velez u. a. 2013) oder der Vogelgrippe (Z. Xu
2016). Neben dem Einsatz im medizinischen Bereich können Sequenzmustern zur
Vorhersage des Verkehrsflusses (Ibrahim und Shafiq 2019) verwendet werden.
2.1.5 Implementationen
Das Paket arulesSequence (Hornik, Grün und Hahsler 2005) für die Program-
miersprache R ermöglicht das Erstellen von Sequenzmustern. Dies verwendet den
CSPADE-Algorithmus (Zaki 2000b), welcher eine Erweiterung des SPADE-Algorithmus
(Zaki 2000a) um zusätzliche Parameter ist.
92 Stand der Forschung
2.2 Sequenzregelanalyse
Die Sequenzregelanalyse ist ebenso ein Verfahren, welches eine Transaktionsdatenbank
verwendet. Anhand dieser werden Sequenzregeln erzeugt. Sequenzregeln beschreiben
nacheinander auftretende Elemente einer Sequenz. Dabei verwenden Sequenzregeln
eine andere Darstellungsform als Sequenzmuster. Es werden die auftretenden Elemen-
te auf zwei Seiten unterteilt und üblicherweise durch einen Pfeil getrennt dargestellt,
wie etwa X → Y . Die linke, oder auch vorausgehende Seite der Regel (X) stellt die
Bedingung für das Eintreffen der Regel dar. Die rechte, oder auch nachfolgende Seite
der Regel (Y ) zeigt die Elemente, welche danach auftreten (nicht zwangsläufig direkt
danach). Ein Beispiel für Sequenzregeln aus Abbildung 2.1 ist etwa {A}, {B} → {C}
aus den Sequenzen 1 und 2.
2.2.1 Bewertung der Signifikanz
Für die Anwendung der Sequenzregeln ist entscheidend, aus der großen Menge
der generierten Regeln diese auszuwählen, die sich besonders gut für zukünftige
Vorhersagen eignen. Diese Regeln werden als interessant oder signifikant bezeichnet.
Neben dem aus den Sequenzmustern bekannten Support-Wert exisitiert bei Sequenz-
regeln zusätzlich der Konfidenz-Wert.
Support
Für eine Sequenzregel r = X → Y ist der Support folgendermaßen definiert:
Anzahl der Sequenzen, die zuerst X und anschließend auch Y enthalten
sup(r) =
Gesamtzahl der Sequenzen
Der Support gibt somit an, wie groß der Anteil der Sequenzen ist, die diese Regel
enthalten.
Konfidenz
Für eine Sequenzregel r = X → Y ist die Konfidenz folgendermaßen definiert:
Anzahl der Sequenzen, die zuerst X und anschließend auch Y enthalten
conf (r) =
Anzahl der Sequenzen, die X enthalten
102 Stand der Forschung
Die Konfidenz gibt an, wie wahrscheinlich es ist, dass auf ein Antreffen der linke
Seiten X in einer Sequenz, später die rechte Seite Y folgt. Durch die Konfidenz wird
somit angegeben, wie häufig eine Regel korrekt ist.
Zur Auswahl einer interessanten Regel ist das Betrachten von sowohl Support als
auch Konfidenz relevant. Bei Betrachten des Supports als einzigen Wert besteht
die Gefahr, dass Regeln, welche häufig korrekt sind, aber selten auftreten, nicht als
interessant erkannt werden. Trotzdem müssen auch Regeln, welche sich durch einen
hohen Konfidenzwert und einen niedrigen Supportwert auszeichnen mit Vorsicht
behandelt werden. Der hohe Konfidenzwert kann bei einem geringen Support ein
Indiz für einen „Zufallstreffer“ sein.
2.2.2 Varianten
Im Folgenden werden zwei Varianten der Sequenzregeln vorgestellt, es sind sowohl
vollständig sortierte Sequenzregeln als auch partiell sortierte Sequenzregeln bekannt
(Fournier Viger, C.-W. Wu, Tseng und Nkambou 2012).
Vollständig sortierte Sequenzregeln
Diese Variante wird auch „sequential rules between sequential patterns“ genannt.
Sowohl die linke und rechte Seite der Regel ist jeweils ein vollständig sortiertes
Sequenzmuster.
Das Betrachten der Sequenzen 4 bis 6 in Abbildung Abbildung 2.1 erzeugt unter
anderem folgende drei verschiedene Sequenzregeln, welche sehr spezifisch sind, da sie
jeweils nur für eine Sequenz gelten:
{B, D}, {E} → {A}
{E}, {D}, {B} → {A}
{B, D, E}, → {A}
Zusätzlich können noch weitere, recht allgemeine Sequenzregeln gebildet werden, wie
etwa die Folgende:
{B} → {A}
112 Stand der Forschung
Angenommen, es tritt eine neue Sequenz auf, deren weiterer Verlauf anhand der
vorhandenen Sequenzregeln vorhergesagt werden soll. Diese Sequenz ist {B}, {D, E}.
Diese Sequenz den Mustern ähnelt den Mustern, welche sich auf der linken Seite der
drei spezifischen Regeln befinden. Dennoch passt sie zu keiner der Regeln. Stattdessen
kann nur die allgemeine Regel {B} → {A} verwendet werden. Die Verwendung von
ausschließlich allgemeinen Regeln führt aber dazu, dass verschiedene Ausgangssitua-
tionen nicht hinreichend differenziert werden können. So ist möglicherweise für das
Auftreten der neuen Sequenz {C}, {B}, welche mit {C} ein komplett neues Element
enthält, die Regel {B} → {A} möglicherweise keine ausreichende Unterscheidung
mehr.
Partiell sortierte Sequenzregeln
In (Fournier Viger, C.-W. Wu, Tseng, Cao u. a. 2015) wird das Problem der vollständig
sortierten Sequenzregeln erkannt: Die große Menge an erstellten Regeln sind häufig
zu spezifisch, um sie für Vorhersagen von neuen Sequenzen nutzen zu können.
Deswegen wurde von Fournier-Viger et al. eine andere Definiton der Sequenzre-
geln entwickelt. Diese werden als partiell sortierte Sequenzregeln oder auch „common
to several sequences“ bezeichnet.
Partiell sortierte Sequenzregeln zeichnen sich durch folgende Eigenschaften aus:
• Die Sequenzrelation zwischen linker und rechter Seite der Regel bleibt erhalten
– Die rechte Seite folgt weiterhin der linken Seite.
• Die Unterteilung der linken und rechten Seite in jeweils einzelne Ereignisse
wird aufgehoben – Alle Elemente stehen innerhalb eines geschweiften Klammer
{}.
• Die Muster, welche sich auf der linken und rechten Seite der Regel befinden,
sind nicht sortiert.
• Linke und rechte Seite der Regel sind immer disjunkte Mengen.
Ein erneutes Betrachten der Sequenzen 4 bis 6 aus Abbildung 2.1 zeigt folgendes
Muster:
Nach Auftreten von B, D und E in beliebiger Reihenfolge folgt danach A.
122 Stand der Forschung
Diese drei Sequenzen lassen sich alle durch die folgende partiell sortierte Sequenzregel
beschreiben:
{B, D, E} → {A}
Untersuchungen zeigen, dass partiell sortierte Sequenzregeln bei den betrachteten
Datensätzen stets bessere Vorhersageergebnisse erzielte als die vollständig sortierten
Sequenzregeln (Fournier Viger, C.-W. Wu, Tseng, Cao u. a. 2015).
2.2.3 Anwendungen
Sequenzregeln wurden eingesetzt um Kursverläufe an der Börse (Yang, Hsieh und J.
Wu 2006) oder Besuche von Webseiten vorherzusagen (Singh, M. Kaur und P. Kaur
2017). Ein weitere Anwendung der Sequenzregeln ist es, Abhängigkeiten zwischen
verschiedenen Sensormessswerten eines Gebäude-Automatisierungssystems zu finden
(Stinner u. a. 2019).
2.2.4 Implementationen
Mit dem bereits erwähnten Paket arulesSequence der Programmiersprache R kön-
nen mit der Funktion ruleInduction aus vorher erstellten Sequenzmustern vollstän-
dig sortierte Sequenzregeln generiert werden.
SPMF (Fournier-Viger, Lin u. a. 2016), was sowohl als eigenständiges Programm als
auch als Java-Softwarebibliothek verwendet werden kann, implementiert verschiede-
ne Data-Mining-Algorithmen. Es können aus einer Transaktionsdatenbank sowohl
vollständig sortierte (RuleGen-Algorithmus) als auch partiell sortierte Sequenzregeln
(u.a. TRuleGrowth-Algorithmus) erstellt werden.
132 Stand der Forschung
2.3 Markov-Ketten
PAA PBB
PAB
PBA
A B
A B C
PAC PCB
A PAA PBA PCA
PCA PBC B PAB PBB PCB
C PAC PBC PCC
C
PCC
(a) Darstellung als Graph (b) Übergangsmatrix
Abbildung 2.2: Beispiel Markov-Kette
Eine Markov-Kette ist eine weitere Möglichkeit, eine Vorhersage aus sequenziellen
Daten zu erzeugen. Die Markov-Kette ist eine Beschreibung eines Zufallsprozesses.
Eine übliche Darstellungsform ist ein Diagramm, wie in Abbildung 2.2a dargestellt.
Die gezeigte Markov-Kette besteht aus den Zuständen (A, B, C). Der Prozess befindet
sich immer in einem Zustand. Es ist ein Übergang in andere Zustände möglich. Es
werden sowohl zwischen verschiedenen Zuständen Übergangswahrscheinlichkeiten
(u.a. PBA , PAC ) angegeben, als auch Wahrscheinlichkeiten, im gleichen Zustand zu
bleiben (u.a. PAA , PBB ). Die Wahrscheinlichkeiten können in einer Übergangsmatrix
angegeben werden (siehe: Abbildung 2.2b).
Um Markov-Ketten zur Vorhersage zu nutzen, wird ein Trainingsdatensatz eingesetzt,
um die Übergangswahrscheinlichkeiten bestimmen zu können. Die in Abbildung 2.2
dargestellte Form besitzt kein Gedächtnis. Dies bedeutet, dass der nächste Zustand
nur vom derzeitigen Zustand abhängig ist.
Bei Verwendung von Markov-Ketten zur Vorhersage sequenzieller Daten führt die
Betrachtung der vorherigen Zustände zu genaueren Vorhersagen (Rosvall u. a. 2014),
(Chierichetti u. a. 2012). Dazu werden Markov-Ketten höherer beziehungsweise n-ter
Ordnung benötigt. Die Ordnung beschreibt, von wie vielen Zuständen die Vorhersage
abhängig ist. Abbildung 2.2 zeigt eine Markov-Kette erster Ordnung, da sie insgesamt
142 Stand der Forschung
von einem Zustand abhängig ist.
Wenn das gezeigte Beispiel stattdessen eine Markov-Kette zweiter Ordnung wäre,
dann wäre die Vorhersage vom derzeitigen Zustand und vom vorherigen Zustand
abhängig. Dies wird erreicht, in dem Zustände erzeugt werden, welche eine An-
einanderreihung der Zustände der Markov-Kette erster Ordnung sind. Die Zustän-
de sind in diesem Fall alle Variationen von {A, B, C} mit einer Länge von zwei:
({AA}, {AB}, {AC}, {BA} . . .). Bei Markov-Ketten höherer Ordnung steigt die An-
zahl der benötigten Zustände und die benötigte Rechenleistung somit schnell an
(Deshpande und Karypis 2004).
2.3.1 Anwendungen
Markov-Ketten können eingesesetzt werden, um algorithmisch Texte oder Musik zu
generieren (McAlpine, Miranda und Hoggar 1999). Eine weitere Einsatzmöglichkeit
ist die Vorhersage des Klickpfades von Nutzern einer Webseite (Sarukkai 2000).
Die Vorhersage des Klickpfades konnte bessere Ergebnisse erzielen, in dem mehrere
Übergangsmatrizen aus verschiedenen Zeiträumen erstellt wurden, wobei neuere
stärker gewichtet werden (Jayalal, Hawksley und Brereton 2007).
2.3.2 Implementierungen
Es existiert unter anderem die Python-Bibliothek mchmm, welche genutzt werden
kann, um aus einer gegebenen Sequenz eine Übergangsmatrix mit den zugehörigen
Wahrscheinlichkeiten zu erstellen (Terpilowski 2021).
152 Stand der Forschung
2.4 Künstliche Neuronale Netze
Eingabe- Verdeckte Ausgabe-
schicht Schicht schicht
Eingabe #1
Eingabe #2 Ausgabe
Eingabe #3
Abbildung 2.3: Schematische Darstellung eines Künstlichen Neuronalen Netzes
Ein künstliches Neuronales Netz (KNN) besteht aus künstlichen Neuronen, welche
untereinander verbunden sind. In Abbildung 2.3 ist ein einfaches Feedforward-Netz
dargestellt. Dies bedeutet, dass die Ausgaben der Neuronen ausschließlich in eine
Richtung weitergeführt werden, eine Rückkopplung findet in dem Fall nicht statt. Die
Neuronen sind in einzelnen Schichten angeordnet. Die dargestellte Eingabeschicht
kann drei verschiedene Eingaben verarbeiten. Häufig werden als Eingaben normierte
Zahlenwerte zwischen 0 und 1 verwendet.
Es existieren Verbindungen beziehungsweise Kanten zwischen den Neuronen. Je-
der Verbindung wird eine bestimmte Gewichtung zugeordnet. Das Netz lernt, in
dem die Gewichte der Verbindungen angepasst werden. Dazu sind Trainingsdaten
notwendig.
Die Entwicklung von Trainingsalgorithmen, welche auf leistungsfähigen Grafikprozes-
soren ausgeführt werden können, erlaubt die Verwendung sehr großer Datenmengen
als Trainingsdaten (Paine u. a. 2013).
Die Ausgabe der einzelnen Neuronen wird von Schicht zu Schicht bis zu einer
Ausgabeschicht geleitet. An dieser kann das Ergebnis observiert werden.
Die Zustände und Gewichtungen innerhalb eines KNN sind für den Menschen schwer
interpretierbar, insbesondere wenn deutlich mehr Neuronen und Schichten als in
dem gezeigten Beispiel vorhanden sind. Ein fertig trainiertes KNN erzeugt zu einer
Eingabe eine Ausgabe, es ist jedoch schlecht nachzuvollziehen, wie die Ausgabe
162 Stand der Forschung
erzeugt wurde. Dieses Verhalten wird oft als Black-Box-Verhalten bezeichnet. Es gibt
Bestrebungen den inneren Zustand der KNN durch Visualisierungen verständlicher
darzustellen (Murdoch und Szlam 2017), diese befinden sich jedoch noch in einem
recht frühen Stadium.
Es existieren viele Arten der KNN. Zur Vorhersage sequenzieller Daten werden
häufig Long short-term memory („langes Kurzzeitgedächtnis“) Netze eingesetzt.
Erstmals in (Hochreiter und Schmidhuber 1997) vorgestellt, ist es heutzutage ein weit
verbreitetes Verfahren. Im Gegensatz zum Feedforward-Netz in Abbildung 2.3 nutzt
ein Long short-term memory Netz zusätzlich Neuronenverbindungen, welche entgegen
der Verabeitungsrichtung verlaufen, um bessere Vorhersageergebnisse erzielen zu
können.
2.4.1 Anwendungen
Im letzten Jahrzehnt wurde viel an KNN geforscht, so steigt die Anzahl der Publika-
tionen, welche sich auf KNN beziehen, im letzten Jahrzehnt jährlich an1 .
So wird beispielsweise ein Long short-term memory Netz eingesetzt, um Kunden-
und Einkaufsverhalten im Versandhandel zu analysieren, das gezeigte Vorgehen ist
besonders geeignet für große Datenmengen (Jamshed, Mallick und Kumar 2020).
Auch die Handschrifterkennung (Graves u. a. 2009) oder die Spracherkennung (Sak,
Senior und Beaufays 2014) sind häufige Anwendungsgebiete. In (Park u. a. 2018)
wird ein KNN genutzt um die Fahrbahn von Fahrzeugen vorherzusagen.
2.4.2 Implementierungen
Es existieren viele Softwarepakete um KNN nutzen zu können. Populäre Beispiele sind
scikit-lern (Pedregosa u. a. 2011) und TensorFlow (Martı́n Abadi u. a. 2015).
1
Anhand der Suchfunktion der https://www.sciencedirect.com Datenbank bestimmt
172 Stand der Forschung
2.5 EOWEB®GeoPortal
Das EOWEB® GeoPortal (EGP) ist ein Datenportal des Deutschen Zentrums für
Luft- und Raumfahrt e.V. Auf diesem Datenportal stehen Erdbeobachtungsdaten
aus dem Deutschen Satellitendaten-Archiv zur Verfügung (Deutsches Zentrum für
Luft- und Raumfahrt e.V. 2020). Das Portal ist online2 verfügbar.
Um einen Datensatz zu erwerben, durchläuft ein Nutzer üblicherweise mehrere
Schritte. Zuerst erfolgt die Anmeldung auf dem Datenportal. Die Verwendung
eines Gastzugangs ist ebenso möglich. Im nächsten Schritt existieren Such- und
Filterfunktionen, um den Nutzer beim Auffinden von Datensätzen zu unterstützen.
In der Ergebnisliste erscheinen Einträge mit einer Vorschau der Ergebnisse. Falls
ein passender Datensatz gefunden wurde, kann dieser erworben und anschließend
heruntergeladen werden. Dazu wird auf ein weiteres Portal weitergeleitet.
2
https://eoweb.dlr.de
182 Stand der Forschung
0
1 2 3
4
(a) Products-Ansicht
5 1 2 6
(b) Suchoptionen der Collections-Ansicht
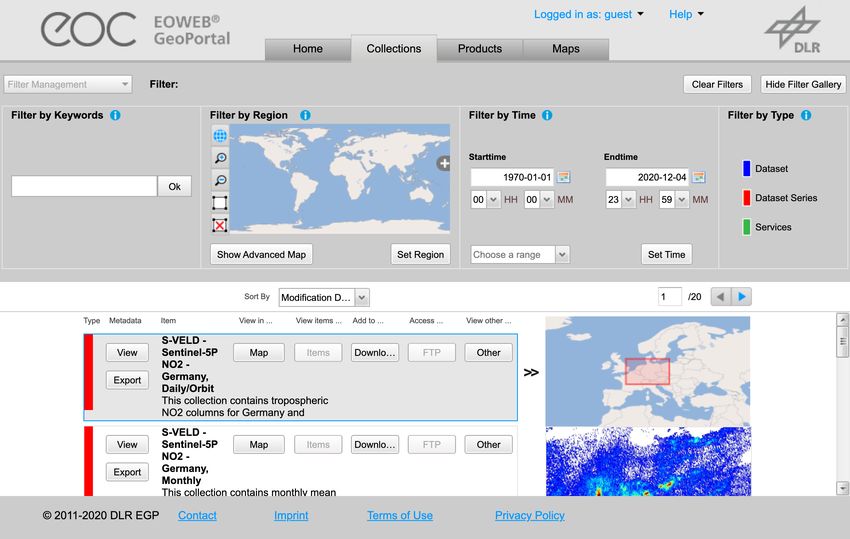
Abbildung 2.4: EOWEB Benutzeroberfläche.
0 Tab um zwischen Ansichten zu wechseln
1 Räumlicher Filter
2 Zeitlicher Filter
3 Kollektionsfilter
4 Ergebnisliste
5 Stichwortsuche
6 Filterung nach Typ
Die Benutzeroberfläche des EGP ist in der Abbildung 2.4 dargestellt. Die angebotenen
Beobachtungsdaten sind in Kollektionen unterteilt. Eine Kollektion fasst verschiedene,
ähnliche Beobachtungen zusammen. Ein Beispiel für eine Kollektion ist METOP
GOME-2 - Nitrogen Dioxide (NO2) - Global. Dabei handelt es sich um Aufzeichnungen
der METOP Satelliten. Gemessen wurde die Stickstoffdioxid-Konzentration weltweit.
Die Kollektionen sind mit Metadaten versehen. Mögliche Informationen können unter
anderem eine Kurzbeschreibung, Auflösung der Messwerte oder die Nennung eines
Ansprechpartners sein.
192 Stand der Forschung
Eine Kollektion enthält Produkte. Im Fall der METOP GOME-2 Kollektion ist ein
Produkt ein Datensatz zu einem konkreten Zeitpunkt. Eine Vorschau eines METOP
GOME-2 Datensatzes wird in Abbildung 2.5 gezeigt.
Abbildung 2.5: Vorschau der Stickstoffdioxid-Messwerte des METOP-Satelliten. Quel-
le: (DLR EGP 2020)
Die Benutzeroberfläche wird anhand der Anmerkungen in Abbildung 2.4 erläutert,
sie lässt sich in Menü, Suchelemente und Ergebnisliste unterteilen.
Über das Menü lässt sich zwischen zwei Ansichten umschalten. Je nachdem, ob der
Nutzer entweder nach Kollektionen oder nach Produkten sucht, stehen verschiedene
Ansichten zur Verfügung, zwischen denen über Tabs ( 0 ) in der Kopfzeile umgeschaltet
werden kann. Die Ansichten unterscheiden sich in der Anzeige der Ergebnisse und in
den verfügbaren Suchfiltern.
Folgende Suchfilter werden im EGP angeboten:
• Räumlich ( 1 ) Der räumliche Filter ermöglicht die Spezifizierung der Region,
zu der Erdbeobachtungsdaten abgerufen werden sollen. Dies kann durch Zeich-
nen eines Begrenzungsrahmens auf einer Weltkarte erfolgen, durch Auswahl
eines Ortes aus einer vordefinierten Liste oder durch Hochladen eines shape file,
welches eine räumliche Einschränkung definiert.
• Zeitlich ( 2 ) Durch den zeitlichen Filter kann die Auswahl auf Beobach-
202 Stand der Forschung
tungsdaten eingeschränkt werden, die innerhalb eines bestimmten Zeitfensters
aufgenommen wurden. Es besteht sowohl die Möglichkeit vorgeschlagene In-
tervalle wie Letzter Monat zu verwenden, als auch individuell ein Start- sowie
Enddatum festzulegen.
• Bestandteil einer Kollektion ( 3 ) Dieser Filter legt fest, zu welcher Kollekti-
on die angezeigten Produkte gehören. Eine Auswahl von mehreren Kollektionen
zur gleichen Zeit wird unterstützt.
• Eingabe eines Schlüsselworts ( 5 ) Dieser Filter ermöglicht eine freie Suche
in den Metadaten der Kollektionen. Es existiert eine Suchvervollständigung.
Bei Eingabe eines Suchbegriffes werden Vorschläge angezeigt.
• Typ ( 6 ) Der Typ einer Kollektion kann drei verschiedene Werte annehmen.
Ein Datensatz enthält ein einzelnes Produkt, eine Datensatzserie hingegen
mehrere zusammenhängende Aufzeichnungen. Dies kann etwa die Betrachtung
des gleichen Messwertes zu verschiedenen Zeitpunkten sein. Die dritte Mög-
lichkeit, ein Service, enthält keine Produkte, sondern bietet Zugriff auf einen
Webservice an, der weitere Daten zur Verfügung stellt. Es können verschiedene
Kollektionstypen zeitgleich gewählt werden.
Die Collections-Ansicht (siehe: Abbildung 2.4b) zeigt in der Ergebnisliste ausschließ-
lich Kollektionen an. Diese Ansicht ermöglicht die Verwendung der räumlichen und
zeitlichen Suchfilter, die Nutzung der Schlüsselwortsuche oder die Wahl des Typs.
Bei Verwendung der Products-Ansicht hingegen (siehe: Abbildung 2.4a) enthält die
Ergebnisliste nur Einträge vom Typ Produkt. Die Schlüsselwortsuche und Typfil-
terung ist in dieser Ansicht nicht verfügbar, stattdessen ist eine Filterung nach
Zugehörigkeit zu einer Kollektion möglich.
Die Ergebnisliste ( 4 ) verwendet Paginierung. Bei vielen Suchresultaten werden die
Ergebnisse auf mehrere Seiten aufgeteilt, der Nutzer kann die angezeigte Seite und
die Anzahl der Ergebnisse pro Seite anpassen.
Eine Analyse der EOWEB-Logdaten und damit der gleiche Datensatz, welcher in
dieser Arbeit verwendet wurde, wurde in (Schindler, Paradies und Twele 2019) durch-
geführt. Darin wurde eine Übersicht über die Verwendungshäufigkeit der einzelnen
212 Stand der Forschung
Filter erstellt. Es wurden die Eingaben der Nutzer in den Suchfeldern detailliert
analysiert. Dazu erfolgte eine Einteilung der Bedeutung der Suchbegriffe in einzelne
Klassen.
Die Autoren konnten feststellen, dass die vorhandenen Begriffe der Suchvervoll-
ständigung oft nicht ausreichend waren, um die Intentionen der Nutzer abzubilden.
Außerdem wurde gezeigt, dass in der vorhandenen Stichwortsuche Schreibfehler
oder alternative Schreibweisen eines Begriffes selten zum Erfolg führten. Es wurden
Vorschläge formuliert, um die Suchleistung in Zukunft verbessern zu können. Dazu
gehört die Verwendung eines Stemming-Algorithmus, um abweichende Schreibweisen
eines Wortes zu erkennen und die Verwendung einer OpenStreetMaps-Schnittstelle,
um lokalisierte Ortsbezeichnungen nutzen zu können.
Die durchgeführten Analysen behandelten die Suchanfragen als einzelne Ereignisse.
Eine Betrachtung der Anfragen als Sequenz in einer Sitzung eines Nutzers fand nicht
statt. Eine Vorhersage zukünftiger Anfragen, wie es Bestandteil dieser Arbeit ist,
wird nicht durchgeführt.
2.6 Benutzermodelle
Ein Benutzermodell ist eine synthetische Repräsentation einer Person. Das Modell
wird durch verschiedene Attribute (ein Schema) bestimmt (Thierry 2005). Ein
Benutzermodell kann als offen oder auch als geschlossen klassifiziert werden. Offen
bedeutet hierbei, dass der Nutzer einsehen kann, welche Informationen über ihn
existieren. Zusätzlich ist ein gezieltes, aktives Anpassen des Modells direkt durch
den Nutzer möglich. Ein Beispiel ist in Abbildung 2.6 zu sehen. Dort dargestellt ist
Grapevine (Rahdari, Brusilovsky und Babichenko 2020). Grapevine ist ein System
zum Finden von Forschungsberatern, in dem der Anwender durch verschiedene Slider
seine Interessen spezifizieren kann.
222 Stand der Forschung
Abbildung 2.6: Beispiel eines Systems mit offenem Nutzermodell.
A: Stichworteingabe, B: Verwandte Stichworte, C: Interessen-Slider,
D: Ergebnisse
Quelle: nach Rahdari, Brusilovsky und Babichenko 2020, S. 4
Ein offenes Benutzermodell erhöht die Transparenz für den Nutzer und erlaubt eine
gewisse Kontrolle über die Adaption (Frasincar, Borsje und Levering 2009). Dies
ist allerdings auch nicht ohne Risiken. Es ist durchaus möglich, dass ein geringes
Vorwissen der Nutzer dazu führt, dass irreführende Pfade eingeschlagen werden
(Ahn u. a. 2007). Ein offenes Benutzermodell kann zur Bestimmung der Risikobereit-
schaft von Nutzern im Kontext der mobilen Datennutzung (Molnar und Muntean
2019) verwendet werden. Eine weitere mögliche Nutzung ist der Einsatz im interakti-
ven Schulunterricht (Molnar, Virseda und Frias-Martinez 2015). Ein geschlossenes
Nutzermodell hingegen bietet keine Möglichkeit der aktiven Anpassung durch den
Nutzer. Der Nutzer beeinflusst die Adaption zwar durch seine Interaktionen, es
besteht aber keine Möglichkeit der Beeinflussung durch ein zur Verfügung gestelltes
Bedienelement.
Anhand eines Benutzermodells können drei grundlegende Arten der Personalisierung
(Molnar und Muntean 2019) durchgeführt werden:
• Personalisierung anhand des Nutzers Die Ausgabe passt sich den vorherigen Ak-
tionen der Nutzer an. Alternativ können Informationen von anderen Systemen
importiert werden (Wongchokprasitti u. a. 2015).
• Personalisierung anhand des Geräts Die Ausgabe passt sich dem verwendeten
Gerät an. So kann die Darstellung von Webseiten abhängig von der Bildschirm-
auflösung des Endgeräts sein (Anam, Ho und Lim 2014).
• Personalisierung anhand des Kontexts Die Ausgabe passt sich an den Kontext
des Nutzers an. Dies kann zum Beispiel der derzeitige Standort sein.
233 Konzept
In diesem Kapitel wird das Konzept beschrieben, um eine Vorhersage von Benut-
zerinteraktionen durchzuführen. Um eine Vorhersage zu treffen, wird ein Verfahren
namens Kollaboratives Filtern angewendet. Dabei werden vergangene Interaktionen
vieler anderer Nutzer verwendet, um die Interaktionen eines neuen Nutzers vorherzu-
sagen (Resnick und Varian 1997). Kollaboratives Filtern arbeitet nach folgendem
Prinzip (Hansen 2008):
1. Aus einem vorliegenden Trainingsdatensatz, welcher eine Sammlung vergange-
ner Nutzerinteraktionen enthält, werden Muster extrahiert und gespeichert.
2. Anhand der bisherigen Interaktionen eines neues Nutzers wird ein vergleichbares
Muster aus dem Speicher gesucht.
3. Die folgende Interaktion des Vergleichsmusters wird als Vorhersage gewählt.
Kollaboratives Filtern wird bereits vielfach eingesetzt, etwa um anhand der Inter-
essen des Nutzers News-Artikel zu zeigen (Konstan u. a. 1997) oder um bei einem
Streamingdienst Musiktitel zu empfehlen (Baer 2015). Eine Einschränkung dieses
Verfahren ist jedoch, dass die Empfehlung, welche von der Auswahl der anderen
Nutzer abhängig ist, zwar eine beliebte, aber nicht zwingend die optimale Wahl ist.
Ein großer Vorteil dieses Verfahrens ist, dass es einfach möglich ist, an einen großen
Datensatz zu gelangen. Es müssen keine Umfragen durchgeführt werden, stattdessen
können Informationen aus der üblichen Benutzung des Systems gewonnen werden.
Um die Vorhersage durchzuführen wird ein Benutzermodell trainiert. Die Perso-
nalisierung findet anhand der bisherigen Interaktionen dieses Nutzers statt. Das
Bennutzermodell ist geschlossen: Der Nutzer kann nicht aktiv die persönlichen
Präferenzen festlegen.
243 Konzept
Das Konzept beschränkt die Form des zu verarbeitenden Datensatzes auf ein Format,
welches häufig verwendet wird, um Nutzerinteraktionen abzubilden. Als Quelle des
Datensatzes können etwa Logdateien dienen, wie sie zum Beispiel von Serveran-
wendungen erstellt werden. Um diese Art des Datensatzes genauer zu definieren,
werden die Anforderungen, die durch den Datensatz erfüllt sein müssen, im Folgen-
den beschrieben. Danach wird ein Überblick über das Vorhersageverfahren gegeben,
anschließend wird die Wahl des Vorhersagealgorithmus begründet. Später wird vor-
gestellt, wie aus den Feldern des Datensatzes Elemente für die Vorhersage gewonnen
werden können.
Das Konzept wurde in einem iterativen Prozess entwickelt. Dazu wurden unter
Anwendung des Konzepts die Vorhersageergebnisse stets übeprüft. Dies geschah
einerseits anhand eines als „Zaki“ bezeichneten Datensatz (Zaki 2001), welcher oft zur
Demonstration von Sequenzmustern und Sequenzregeln verwendet wird. Andererseits
anhand des EGP-Datensatzes, welcher Aufzeichnungen über Nutzerinteraktionen
eines Geodatenportals enthält und in Kapitel 4 vorgestellt wird. Anschließend flossen
die so gewonnen Erkenntnisse in die Aktualisierung des Konzepts ein.
3.1 Anforderungen an den Datensatz
Das in diesem Konzept vorgestellte Vorhersageverfahren ist für verschiedene Daten-
sätze anwendbar. Im Folgenden werden abstrakte Anforderungen an den verwendeten
Datensatz vorgestellt, damit eine Vorhersage nach dem vorgestellten Konzept möglich
ist. Dazu wird eine Klasse an Datensätzen definiert, für die das vorgestellte Konzept
verwendet werden kann. Ziel dieser Definition ist es, allgemein genug zu sein, so dass
eine große Menge an Datensätzen existiert, die für dieses Verfahren verwendbar sind.
Gleichzeitig soll die Definition spezifisch genug sein, so dass alle Datensätze dieser
Klasse mit wenigen Anpassungen verwendbar sind.
Diese Klasse an Datensätzen wird bestimmt durch gewisse Anforderungen an den
Inhalt des Datensatzes. Um die Allgemeinheit der Definition zu unterstreichen, erfolgt
bei Beschreibung der Anforderungen eine Zuordnung zu Beispielen aus verschiedenen
Situationen: Die Suche auf einer Webseite ( 1 ), Einkäufe im Geschäft ( 2 ) und das
Vorliegen einer Medikamentenhistorie ( 3 ).
253 Konzept
• Der Datensatz muss eine Menge aus Sitzungen enthalten. Eine Sitzung kann
etwa eine Sitzung auf einer Webseite ( 1 ), der Einkaufsverlauf eines Kunden
( 2 ) oder die Medikamentenhistorie eines Patienten ( 3 ) sein.
• Die Sitzungen bestehen aus Interaktionen. Die Interaktionen sind zeitlich
geordnet. Eine Interaktion kann beispielsweise das Starten einer Suchanfrage
( 1 ), ein einzelner Einkauf ( 2 ) oder die Verordnung eines Medikaments ( 3 )
sein.
• Interaktionen enthalten eine unsortierte Menge an Feldern. Diese Felder können
beispielsweise die verwendeten Suchfilter ( 1 ), die gekauften Artikel eines
Einkaufs ( 2 ), oder die verschriebenen Medikamente eines Arztbesuchs ( 3 )
sein. Dies ist eine wichtige Unterscheidung, da viele Datensätze nur ein Feld
pro Interaktion enthalten können, zum Beispiel der Klickpfad von Nutzern
auf einer Webseite. Auch einige Vorhersageverfahren sind nur auf ein Feld pro
Interaktion ausgelegt sind, wie etwa CPT (T. Gueniche, Fournier Viger und
Tseng 2013).
• Es existiert eine beschränkte Menge an möglichen Werten für ein Feld. Eine
Möglichkeit ist es, zu unterscheiden ob ein Feld einen Inhalt hat oder alternativ
leer ist (zwei mögliche Werte). Falls der Inhalt des Feldes relevant ist und
für die Vorhersage betrachtet werden soll, können Strategien wie Binning
für Zahlenwerte oder das Zuordnen zu einzelnen Klassen bei Zeichenketten
vorgenommen werden.
Falls die Quelle des Datensatzes eine Logdatei in einem unstrukturierten Textformat
ist, muss vorher eine Zerlegung der relevanten Information der Logeinträge in einzelne
Felder vorgenommen werden. Ein mögliches Vorgehen wäre das Zerlegen durch
reguläre Ausdrücke und das Speichern in entweder einer JSON-Datei oder einer
Datenbank.
263 Konzept
3.2 Anforderungen an das Vorhersageverfahren
Trainings-
daten
Verfahren Vorhersage
Neue
Sitzung
Abbildung 3.1: Vorhersageverfahren
Abbildung 3.1 zeigt in einer abstrakten Darstellung, welche Eingabe das Vorhersa-
geverfahren erwartet und was die Ausgabe ist. Um eine Vorhersage durchzuführen
zu können, erfolgt zuerst ein Training des Benutzermodells anhand eines Trainings-
datensatzes. Der Trainingsdatensatz muss den vorgestellten Anforderungen eines
Datensatzes entsprechen. Weiterhin muss bereits eine Vorverarbeitung des Datensat-
zes vorgenommen wurden sein.
Nachdem das Modell trainiert wurde, kann eine Vorhersage von neuen, unbekannten
Sitzungen vollzogen werden. Anhand des trainierten Benutzermodells kann entschie-
den werden, welche Interaktion am wahrscheinlichsten folgt. Diese wird dann als
Vorhersage ausgegeben.
3.3 Auswahl des Vorhersageverfahrens
Im Kapitel „Stand der Forschung“ konnten verschieden Vorhersageverfahren anhand
einer Literaturrecherche vorgestellt werden. Die vorgestellten Algorithmen erhalten
nun eine Bewertung auf Eignung für die Vorhersage an einem Datensatz, welcher
den vorgestellten Anforderungen entspricht. Es ist nicht als allgemeine Empfehlung
zur Vorhersage von Daten zu werten.
273 Konzept
Künstliche neuronale Netze
Aufgrund der intensiven Forschung zur Nutzung von künstlichen neuronalen Netzen
(KNN) existieren für viele Anwendungsfälle Algorithmen, welche eine hohe Vorhersa-
gegenauigkeit erreichen können. Ebenso eignen sich Neuronale Netze für sehr große
Datenmengen, oft als Big-Data bezeichnet.
Eine grundlegende Herausforderung bei der Verwendung von KNN ist das Verhalten,
welches sich als „Black Box“ beschreiben lässt. Das Durchführen von Optimierun-
gen, um die Vorhersageergebnisse zu beeinflussen, ist komplex. Grund dafür ist
die schlechte Interpretierbarkeit der Verbindungen der Neuronen mit den zugehö-
rigen Gewichtungen. Weiterhin benötigt das Training viel Rechenleistung und die
Komplexität einer korrekten Implementation ist hoch.
Aus diesen Gründen werden KNN in diesem Fall nicht zur Vorhersage verwendet.
Markov-Ketten
Ein wichtiger Schritt, um Markov-Ketten anwenden zu können, ist das Definieren
der mögliche Zustände des Prozesses. Aus den Zuständen wird anschließend die
Transaktionsmatrix abgeleitet. Um eine Vorhersage eines Datensatz des vorgestellten
Formats durchzuführen können, werden bei Verwendung von Markov-Ketten eine
große Anzahl an Zuständen benötigt. Dies wird an dem folgenden Beispiel erläutert.
Angenommen es soll abgebildet werden, dass eine Interaktion acht verschiedene
Felder A, B, . . . H enthält. Basis der Vorhersage soll ausschließlich sein, ob ein Feld
vorhanden (A) oder nicht vorhanden (Ā) ist. Es müssen alle Kombinationen „von
Feld vorhanden“ oder „Feld nicht vorhanden“ als eigene Zustände abgebildet werden:
< ABCDEF GH >, < ĀBCDEF GH >, < AB̄CDEF GH > . . . < ĀB̄ C̄ D̄Ē F̄ ḠH̄ >
Die Gesamtzahl der benötigten Zustände beträgt in diesem Fall:
28 = 256
Dies beschreibt jedoch nur die nötigen Zustände für eine Markov-Kette erster Ord-
nung. Bei einer Markov-Kette neunter Ordnung, welche notwendig ist, um acht
Elemente aus der Vergangenheit in die Vorhersage einzubeziehen, tritt eine drastische
28Sie können auch lesen

















































