Kognitive Robotik - Herausforderungen an unser Verst andnis nat urlicher Umgebungen - Universität Stuttgart
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

at 8/2004
Kognitive Robotik – Herausforderungen an
unser Verständnis natürlicher Umgebungen
Cognitive Robotics – challenges for our understanding of natural environments
Marc Toussaint, Tobias Lang, Nikolay Jetchev, FU Berlin
Wir diskutieren einen Ansatz, der kognitive Robotik als die Erweiterung der Methoden
der Robotik – insb. Lernen, Planen und Regelung – auf “äußere Freiheitsgrade” versteht.
Damit verschiebt sich der Fokus: Weg von Gelenkwinkeln, Vektorräumen und
Gauß’schen Verteilungen, hin zu den Objekten und der Struktur der Umwelt. Letztere
können wir nur schwer formalisieren und in geeignete Repräsentationen und Priors
übersetzen, mit denen effizientes Lernen und Planen möglich wird. Es wird deutlich,
welche theoretischen Probleme sich hinter dem Ziel automomer Systeme verbergen, die
durch intelligente Exploration und Verallgemeinerung ihre Umwelt zu verstehen lernen
und die gelernten Modelle zur Handlungsplanung nutzen. Die momentan diskutierte
Integration von Logik, Geometrie und Wahrscheinlichkeiten – und damit die
Überbrückung der klassischen Disziplinbarrieren zwischen Robotik, Künstlicher
Intelligenz und statistischer Lerntheorie – ist eine der zwangsläufigen Herausforderungen
der kognitiven Robotik. In diesem Kontext skizzieren wir eigene Beiträge zum
relationalen Reinforcement-Lernen, zur Exploration und dem Symbol-Lernen.
Schlagwörter: Autonomes Lernen, relationales Reinforcement-Lernen, intelligente
Exploration und Verallgemeinerung, Inferenz
Keywords: autonomous learning, relational reinfocement learning, intelligent exploration
and generalization, inference
1 Einleitung lieren verschiedene Modelle zielgerichteten Verhaltens1 .
Diese Modelle sind im Prinzip sehr allgemeingültig, in
der Praxis hängen sie jedoch fundamental von der Wahl
Anfang des 20. Jahrhunderts führte Wolfgang Köhler der Zustandsbeschreibung ab: Welche Repräsentationen
seine Intelligenzprüfungen an Menschenaffen“ (Köhler, (und Priors, siehe unten) nutzt das System, um intern
”
1917) durch. Ein eindrückliches Experiment ist in Abb. zu planen oder Verhalten zu organisieren? Nimmt man
1 illustriert. In einem Käfig hängt eine Banane an der im Falle des Stapelns von Holzkisten eine diskretisier-
Decke, zu hoch für eine Schimpansin. Das Tier versucht te Repräsentation des Problems an, die sowohl Welt-
mehrmals vergeblich an sie heranzukommen und springt zustände als auch mögliche Aktionen deterministisch
immer wieder hoch. Schließlich gibt es auf und setzt sich und symbolisch abstrahiert, so funktionieren KI Metho-
in die Ecke. In einer anderen Ecke des Käfigs steht ei- den effizient. Echte Welten sind jedoch nicht symbolisch,
ne Holzkiste. Köhler beschreibt, dass nach einiger Zeit wir haben es mit kontinuierlichen Größen zu tun, mit
der Blick der Schimpansin zwischen Banane und Kiste Geometrie und Physik, mit Objekten und ihren Merk-
wechselt, sie dann zielgerichtet zur Holzkiste läuft, diese
unter die Banane zieht, darauf steigt und zugreift. 1
D.h. planendes Verhalten, im Kontrast zu konditionier-
tem, durch wiederholte Belohnung habituiertem Verhalten.
Siehe Niv et al. (2006) für eine Definition von zielgerichte-
Was genau geht in dem Tier vor, wenn es in der Ecke tem vs. habituiertem Verhalten in der Psychologie. In der
sitzt und abwechselnd Banane und Holzkiste anvisiert? KI entspricht dies grob dem Unterschied zwischen modell-
Die Psychologie und die Künstliche Intelligenz formu- basiertem und modell-freiem Reinforcement-Lernen.
at – Automatisierungstechnik 68 (2020) 8 c Oldenbourg Verlag 1
04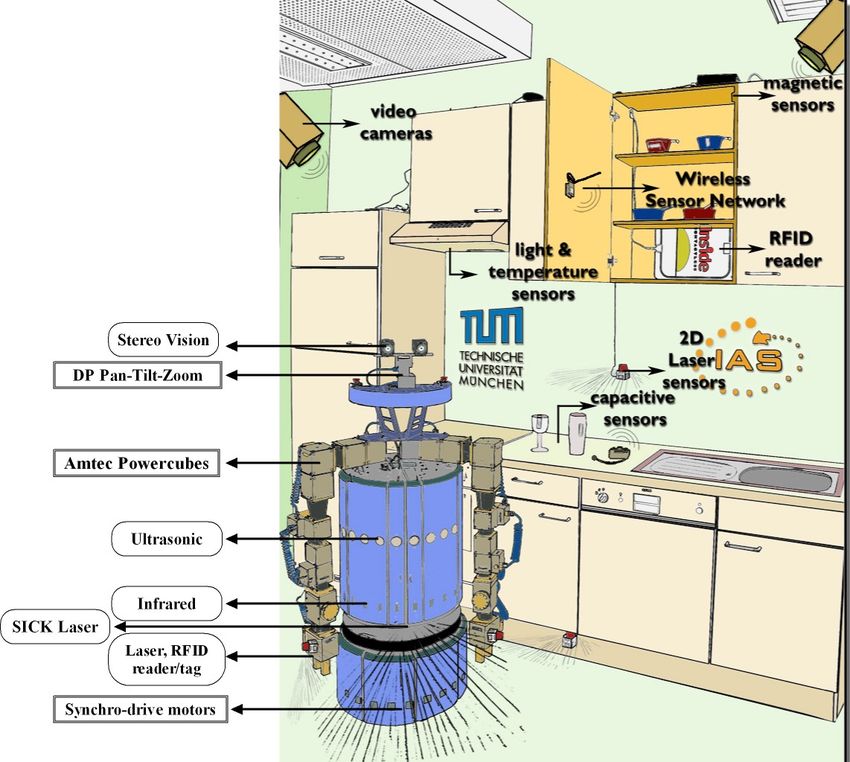
malen. Eine der großen und bisher ungelösten Heraus-
forderungen ist es, solche fundamentalen Eigenschaften
natürlicher Welten in geeignete Repräsentationen und
Priors zu übersetzen.
Im Gegensatz zur KI ist für die Robotik der Um-
gang mit Geometrie und Physik alltäglich. Beispiele
sind die klassischen Methoden der Pfadplanung unter
Berücksichtigung der Geometrie, oder die Kraftregelung
von Freiheitsgraden. Allerdings bringt die naive Inte-
gration solcher Methoden mit der Planung auf symbo-
lischer Ebene unweigerlich Probleme: Sollte man zum
Stapeln von Holzkisten geometrische Pfadplaner für je-
des mögliche Objekt starten, ohne einen Zielort für das
einzelne Objekt vorweg zu kennen? Wie kämen Pfad-
planer auf “die Idee” eine Holzkiste zunächst heranzu-
ziehen, um dann auf sie zu steigen? Während in sym-
bolischen Repräsentationen die Kombinatorik voll ex-
ploriert werden kann, scheint das in geometrischen Re- Bild 1: Eine Intelligenzprüfung am Menschenaffen“ (Köhler,
1917) ”
präsentationen ineffizient. Kaelbling and Lozano-Pérez
(2011) diskutieren eindrücklich das Problem der Inte-
gration von geometrischer und symbolischer Planung.
gen, welche prinzipiellen Herausforderungen sich erge-
Die zentrale Herausforderung sind hier integrierte Me-
ben, will man die Methoden dieser drei Wissenschaf-
thoden zum Umgang mit Geometrie, Logik (im Sinne
ten vereinen. Das Ziel sind künstliche Systeme, die Pro-
der symbolischen Repräsentation) und Unsicherheit, die
bleme autonom und auf Basis gelernten Wissens lösen
klassisch getrennt betrachtet werden.
können, etwa wie es der Schimpansin mit der Holzki-
Neben der Planung sind das Lernen und die Generali- ste gelang. Gelegentlich werden solche Fähigkeiten auch
sierung weitere zentrale Punkte, die entscheidend von als kognitiv“ bezeichnet. In Abschnitt 2 werden wir ei-
der Wahl der Repäsentation abhängen. Es ist nicht ”
ne Begriffsdefinition von kognitiv“ vorschlagen, die den
plausibel, dass der Affe bereits ein Modell besitzt, wel- ”
Fokus auf den qualitativen Unterschied zwischen der
ches dezidiert die Nutzung einer Holzkiste zum Errei- Handhabung innerer und äußerer Freiheitsgrade legt.
chen einer Banane enthält. Stattdessen muss er sei- Diese Sichtweise stellt den Bezug zwischen kognitiven
ne bisher gemachten Erfahrungen verallgemeinern. Das Fähigkeiten und den oben diskutierten Wechselwirkun-
wirft das Problem der Generalisierung auf, beispielswei- gen her, die zwischen den geometrischen und physikali-
se die Nutzung von Objekten zu neuen Zwecken in voll- schen Eigenschaften natürlicher Welten, zwischen sym-
kommen neuen Situationen. Aus der Lerntheorie wis- bolischer und geometrischer Planung sowie beim Ler-
sen wir, dass Generalisierung Unsicherheit bedingt und nen von Modellen der Umwelt existieren. In Abschnitt
durch den Prior bestimmt wird, der seinerseits durch die 3 geht es um Forschungsprojekte zur Objektmanipula-
Wahl der Repräsentation induziert wird2 . Die Wahl der tion in natürlichen Umwelten. Während hier viele be-
Repäsentation und der Umgang mit Unsicherheit sind eindruckende Leistungen demonstriert wurden, bleiben
also auch beim Lernen von zentraler Bedeutung. prinzipielle Forschungsfragen weiterhin offen. In den
Dies zeigt die starke Verzahnung der Forschungsfragen, Abschnitten 4 bis 6 gehen wir auf drei solcher Fra-
die üblicherweise in der Robotik, der KI und beim Ma- gen ein: des Lernen & Planen in relationalen Welten,
schinellen Lernen getrennt behandelt werden. In die- das Symbol-Lernen und die autonome Exploration. Wir
sem Artikel wollen wir an einigen Beispielen aufzei- schließen mit einer Diskussion weiterer offener Fragestel-
lungen und einem Ausblick.
2
In der Bayesianischen Sicht auf ein lernenden Systems
wird Wissen“ über X durch die Bayes’sche Regel P (X|D) ∝
”
P (D|X)P (X) aktualisiert, wobei D die gesehenen Daten
sind. Generalisierung bedeutet hier grob, dass selbst wenn 2 Innere vs. äußere Freiheitsgrade
die Daten nur wenige Komponenten von X direkt betreffen,
auch das Wissen“ bzgl. anderer Komponenten aktualisiert Der Begriff Kognition“ wird oft benutzt, um zwischen
wird. Die ”Struktur des Priors bedingt dabei maßgeblich die- ”
se Struktur des Posteriors. Bei all dem ist die entscheidende der motorischen (niederen) Ebene und der Ebene ab-
Frage, wie das Wissen“ P (X) bzw. P (X|D) repräsentiert
” oder implizit, als Verhaltensregeln oder
strakter Aktionen zu unterscheiden. Wir wollen statt-
wird – ob explizit dessen zunächst den Schwerpunkt auf die qualitativen
logische Ausdrücke, als neuronales Netzwerk oder logisti-
sche Regression mit Kern-Merkmalen. Wenn wir im Folgen- Unterschiede zwischen inneren und äußeren Freiheits-
den also den Begriff der Repräsentation nutzen, so verweisen graden legen. Typische Beispiele für innere Freiheits-
wir gleichzeitig auf die Struktur des Priors und der entspre- grade in der Robotik sind der Vektor q ∈ Rn der Ge-
chenden Generalisierung erlernten Wissens. Siehe auch Pearl
(1988).
lenkwinkel (oder (q, q̇)), oder die Position-Orientierung-
2
Geschwindigkeit (x, θ, v) eines Fahrzeugs. Die traditio-
nell in der Robotik entwickelten Methoden beziehen
sich im Wesentlichen auf Modelle zur Prädiktion, Zu-
standsschätzung und Regelung dieser inneren Freiheits-
grade. Auch die Anwendung von Lernmethoden in der
Robotik sind bzgl. dieser Freiheitsgrade besonders er-
folgreich (Vijayakumar et al., 2005). Können solche Me-
thoden innerer Freiheitsgrade direkt auf Freiheitsgrade
der Umwelt verallgemeinert werden? Was als Objektma- Bild 2: Forschung an integrierten, kognitiven Systemen in der
nipulation bezeichnet wird, kann man als eine Form der Gruppe um Prof. Beetz (Beetz et al., 2008).
Regelung“ äusserer Freiheitsgrade – der Positur von
”
Objekten – ansehen. Einer der vielen qualitativen Un-
der Robotik verlassen, wie etwa der Umgang mit rela-
terschiede liegt jedoch darin, dass dieser externe Frei-
tionalen Wahrscheinlichkeitsmodellen oder die Formu-
heitsgrad zunächst nicht regelbar ist, wenn das Objekt
lierung von Wahrscheinlichkeitsmodellen, die fundamen-
nicht gegriffen ist.3 Das Greifen wird damit zum zentra-
tale geometrische und physikalische Randbedingungen
len Gegenstand der Forschung in der Objektmanipula-
abbilden. In diesem Sinne führt unsere Begriffsdefiniti-
tion.
on kognitiver Systeme direkt zu der in der Einleitung
Das Greifen ist nur ein Beispiel dafür, dass die Hand- diskutierten Wechselwirkung zwischen Robotik, KI und
habung externer Freiheitsgrade qualitativ neue Heraus- dem Maschinellen Lernen.
forderungen zu denen innerer Freiheitsgraden stellt. In-
nere Freiheitsgrade lassen sich oft in einen endlich-
dimensionalen Vektorraum einbetten. Dagegen ist der
3 Forschungsüberblick
Zustandsraum äußerer Freiheitsgrade komplex und sei-
ne Struktur schwer formal abzubilden. Auf inneren Frei- Im allgemeinen wird der Begriff kognitiv“ unschärfer
heitsgraden haben wir Methoden, um effiziente Wahr- ”
als oben vorgeschlagen genutzt. Dennoch zeigt sich bei
scheinlichkeitsmodelle zu formulieren – etwa Gaussver- existierenden Forschungsinitiativen in der kognitiven
teilungen über dem Vektorraum. Dies liefert letztlich Robotik, dass der Fokus auf Aspekte intelligenter Sy-
die Grundlage für effiziente Inferenz (Zustandsschätzung steme gesetzt wird, die über Regelung und Bahnpla-
und -prädiktion) und Lernmethoden. Das Formulieren nung hinausgehen. Die Forschung beschäftigt sich mit
von Wahrscheinlichkeitsmodellen über die äußere Um- komplexem sequentiellem Verhalten, Objektmanipulati-
welt ist schwer. Beschreibt man beispielsweise den Zu- on, Mensch-Maschine Interaktion, der Kombination aus
stand als eine Menge von Objekten mit den jeweiligen symbolischem Planen mit Regelung und Wahrnehmung,
geometrischen, physikalischen und kinematischen Eigen- sowie schließlich der Fähigkeit, in diesen Szenarien zu
schaften und Relationen, so existieren relationale Wahr- lernen. Diese Aspekte der kognitiven Robotik“ sind mit
scheinlichkeitsmodelle, die logische Repräsentationen ”
unserer Begriffsdefinition konsistent, in dem die Um-
und Wahrscheinlichkeiten vereinen. Sind jedoch Men- welt und ihre Struktur als zentraler Gegenstand der For-
schen oder andere autonome Systeme Teil der Um- schung mit einbezogen wird.
welt, wird die Frage nach geeigneten Repräsentationen
Ein gutes Beispiel dafür, was ein kognitiver Roboter sein
und Wahrscheinlichkeitsmodellen wesentlich schwieri-
könnte, der effizient externe Freiheitsgrade manipuliert,
ger. Für innere Freiheitsgrade haben wir gut moti-
findet sich in einem PR1-Video4 . Der Roboter der Firma
vierte Priors (quadratische Regelungskosten, Gaussche
Willow Garage räumt hier ein Wohnzimmer vollständig
Übergangsmodelle), für externe nicht. Um interne Frei-
auf: Er stapelt die Zeitschriften ordentlich, räumt Spiel-
heitsgrade in einen Soll-Zustand zu überführen, ist meist
zeug in eine Box und schüttelt die Kissen auf. Leider
kein hierarchischer Ansatz nötig – Pfadplanung und sto-
ist die komplette Sequenz von einem Menschen teleo-
chastische Regelungstheorie liefern meist direkte Trajek-
periert! Der Roboter selbst nutzt keinerlei Perzeption,
torien. Äußere Freiheitsgrade zu manipulieren verlangt
Bewegungs- oder Handlungsplanung, sondern ist letzt-
oft hierarchisches und sequentielles Verhalten.
lich eine Verlängerung des vom Menschen gesteuerten
In dieser Sichtweise kann man unter kognitiver Ro- Joysticks. Das Video demonstriert, was heutige Robo-
”
botik“ die Erweiterung der theoretisch fundierten ter im Prinzip, trotz der rudimentären Mechanik, tun
Methoden der Regelungstheorie, Pfadplanung, Zu- könnten und veranschaulicht damit das unerreichte Ziel
standsschätzung, etc auf äußere Freiheitsgrade verste- der Forschung an autonomen Robotern. Offensichtlich
hen. Will man dies jedoch rigoros verfolgen, ergeben sich ist das vornehmliche Problem der autonomen kognitiven
grundlegende Fragestellungen, die das klassische Gebiet Robotik nicht die Mechanik, sondern fehlende Methoden
der Handlungsplanung, Modellierung und der Kontrolle
3
Formal: In der lokalen Linearisierung der Gesamtsystem- externer Freiheitsgrade.
dynamik zeigt die Steuerbarkeitsanalyse im Sinne der linea-
ren Regelungstheorie, dass der externe Freiheitsgrad nicht
4
regelbar ist. http://www.youtube.com/watch?v=jJ4XtyMoxIA
3
Michael Beetz’ Forschungsgruppe entwickelt sehr inter- ziehungen untereinander festgelegt wird. Wir können
essante, integrierte kognitive Systeme, die Aufgaben in diese Struktur mit abstrakten Symbolen abbilden: Et-
Küchenumgebungen lösen (Beetz et al., 2008). Abb. 2 wa mit Symbolen für den Typ, die Größe oder die Form
zeigt ein solches Szenario zusammen mit den benutz- eines Gegenstandes oder für geometrische Muster, wie
ten Sensoren am Roboter und auf den Gegenständen. beispielsweise, dass ein Gegenstand auf einem anderen
Die erreichten Manipulationssequenzen sind nahe, aber liegt oder in einem anderen enthalten ist. Die symbo-
nicht ganz so flexibel wie die Handlungssequenzen aus lische Abstraktion umfasst auch die Handlungen mit
obigem PR1-Video, werden aber autonom vom Robo- Gegenständen. Verschiedene konkrete Greifbewegungen
ter ausgeführt. Neuere Arbeiten zeigen einen Roboter, können mittels eines einzigen Symbols für Greifen ab-
der Pfannkuchen macht und dafür symbolische Hand- strahiert werden.
”
lungsanleitungen“ aus dem Internet nutzt, wie sie un- Selbst wenn die Welt auf diese Weise symbolisch ab-
ter howto.com oder roboearth.org speziell für Ro- strahiert wird, bleibt die Anzahl möglicher Situationen
boter zu finden sind. Aus Anwendungssicht ist dieser unüberschaubar groß – nämlich exponentiell in der An-
Ansatz, bei dem der einzelne Roboter nicht mehr ler- zahl der repräsentierten Gegenstände. Erhält ein ko-
nen muss, sondern vorverarbeitetes Wissen über Ob- gnitives System beispielsweise die Aufgabe, zehn Teller
jekte und Handlungen aus dem Internet bezieht, be- übereinander zu stapeln, so kann es dies auf 10! verschie-
sonders vielversprechend. Die Karlsruher Forschungs- dene Weisen tun. Nicht jeder einzelne mögliche Stapel
gruppe betrachtet ähnlich integrierte Robotiksysteme in soll als Ziel definiert werden. Daher muss ein kogniti-
Küchenumgebungen (Asfour et al., 2006). Am Bielefel- ves System in der Lage sein, in seiner symbolischen Be-
der CITEC liegt der Schwerpunkt eher auf der Interak- schreibung über Gegenstände und Situationen zu verall-
tion zwischen Mensch und Roboter, aber auch auf der gemeinern. Verallgemeinerung ist generell wichtig, um
Grundlagenforschung am Greifen (Steil et al., 2004). aus wenigen Erfahrungen lernen und in verschiedenarti-
Die erwähnten Forschungsvorhaben sind Beispiele für gen Situationen handeln zu können. Wenn wir jede zuvor
integrierte Systeme, die Perzeption, Handlungsplanung, ungesehene Teetasse als einen vollkommen unbekannten
Objektmanipulation und Bewegungssteuerung im Zu- Gegenstand auffassen und jedes Greifen eines weiteren
sammenspiel an relevanten Anwendungsszenarien de- Gegenstands als eine neuartige Bewegung, sind wir nicht
monstrieren. Eine bisher unzureichend gelöste Proble- fähig, in unserer vielschichtigen Umgebung sinnvoll zu
matik in solchen Systemen ist das autonome Lernen handeln.
auf der Handlungsebene. Nur wenige existierende For- So genannte relationale Repräsentationen (Fikes and
schungsarbeiten widmen sich dem Problem des Hand- Nilsson, 1971) bieten die Möglichkeit, erlerntes Wis-
lungslernens (auf symbolischer Objektebene) in voll in- sen zu verallgemeinern. Relationale Repräsentationen
tegrierten Robotiksystemen (Beetz et al. (2008), sie- beschreiben eine Situation durch die Menge der Ei-
he auch die Diskussionen zum Lernen auf Systemebene genschaften und Beziehungen (Relationen) von Ge-
(Thrun, 2000; Andre and Russell, 2001)). genständen in Form von logischen Prädikaten und Funk-
Im Folgenden wollen wir einige eigene Arbeiten disku- tionen. Zum Beispiel drückt das Prädikat on(a, b) aus,
tieren, die den Fokus auf sogenanntes relationales Rein- dass der Gegenstand a auf b liegt. Grundlegend für
forcement Lernen legen, das ein vielversprechender An- die Fähigkeit zu verallgemeinern ist die Annahme, dass
satz für das Lernen auf Ebene der Objektmanipulation die Wirkung von Handlungen nur von den Eigenschaf-
und symbolischer Handlungsplanung ist. Während diese ten und Typen der Gegenstände abhängt (beschrie-
Methoden symbolische, logische Repräsentationen mit ben durch die Prädikate), nicht aber von den jewei-
der statistischen Lerntheorie kombinieren, ergibt sich ein ligen Identitäten der Gegenstände (dass es sich um
klassisches Problem: Woher kommen die Symbole? Ab- Gegenstand a handelt und nicht b). Indem man Va-
schnitt 5 wird explizit auf Symbol-Lernen zum Zwecke riablen für Gegenstände einführt, können strukturelle
der Handlungsplanung eingehen und Abschnitt 6 auf au- Äquivalenzklassen von Situationen beschrieben werden.
tonome Exploration. Zum Beispiel kann das Symbol on(a, X) dazu benutzt
werden, alle möglichen Weltsituationen zusammenzufas-
sen, in denen sich der Gegenstand mit dem Bezeich-
ner a auf irgendeinem anderen, nicht weiter spezifizier-
4 Relationales Lernen und Planen ten Gegenstand X befindet. Abstrakte relationale Be-
Die Künstliche Intelligenz verfolgt den Ansatz, grund- schreibungen ermöglichen dadurch, kompakte, verallge-
legende Zusammenhänge in der Welt mittels abstrakter meinernde Modelle über die Wirkungsweise von Hand-
Symbole zu beschreiben. Unsere Alltagswelten zeichnen lungen zu definieren.
sich durch eine Vielzahl an Gegenständen aus. In unse- Um relationale Modelle tatsächlich auch in den kom-
ren Küchen etwa finden wir Gläser, Teller und Töpfe, plexen Szenarien der echten Welt einsetzen zu können,
in unseren Büros Blätter, Stifte und Ordner. Kenn- ist es von entscheidender Bedeutung, in ihnen die Un-
zeichnend für diese Umgebungen ist die Struktur, die sicherheit von Wissen auszudrücken. Die Wirkung von
durch die Eigenschaften der Gegenstände und ihre Be- Handlungsketten ist selbst in einfachen Alltagsumge-
4
bungen nicht immer eindeutig vorherzusagen; das heißt, der Möglichkeit, Wahrscheinlichkeiten mit diesen Regeln
wir können nicht eindeutig abschätzen, ob im Folge- auszudrücken. Das Inkaufnehmen von Modellungenau-
zustand einer Handlung ein Symbol wahr oder falsch igkeiten ist also entscheidend für Lernen, Generalisie-
sein wird. Beim Einschenken in ein Glas kann Wasser rungsfähigkeit und Kompaktheit.
verschüttet werden, Teller fallen auf den Boden, Busse Das Nutzen erlernter probabilistischer Regeln zur Hand-
haben Verspätung. Diese Unsicherheit über die Wirkung lungsplanung ist Gegenstand aktueller Forschung. Die
hat vielfältige Gründe. Zunächst mag die Welt inhärent Herausforderung liegt einerseits in dem exponenziell
stochastisch sein. Doch wichtiger als Stochastitizät ist, großen Zustandsraum, der mit relationalen Regeln be-
dass wir Vorhersagen nie mit völliger Sicherheit treffen schrieben wird, andererseits in der Stochastizität des
können, weil wir stets nur unvollständige Informationen Modells, was die direkte Anwendung klassischer deter-
über die Welt zur Verfügung haben. Teller mögen feuch- ministischer Logik verhindert. Ein möglicher Ansatz ist
ter und rutschiger sein, als wir annehmen, wir wissen es, die Regeln zunächst in eine andere Repräsentation
nicht, dass ein Bus eine Panne hat. Wir können unse- – faktorisierte Dynamische Bayesnetze – zu übersetzen
re Welt stets nur teilweise und ungenau wahrnehmen. und dann probabilistische Inferenzmethoden zur Pla-
Darüber hinaus ist es gerade der Zweck einer abstrak- nung zu nutzen. Lang and Toussaint (2010) beschrei-
ten Beschreibung, Einzelheiten außer Acht zu lassen und ben den ersten Algorithmus, der effizient mit erlernten
damit nur teilweise Information zu repräsentieren. Vor probabilistischen Regeln planen kann.
allem aber ist Wissen zwangsläufig unsicher, wenn es
aus Erfahrung gelernt und generalisiert wird. In Bayesia-
nischen Modellen ist die Wechselwirkung zwischen Ge-
neralisierung, Prior und Unsicherheit des Modells ex- 5 Symbole lernen
plizit. In frequentistischen Modellen wird die inhärente
Unsicherheit eines verallgemeinernden Modells über die Bei der Diskussion relationalen Lernens und Planens
Regularisierung geregelt. In beiden Fällen lässt sich die nahmen wir an, dass bereits abstrakte Symbole existie-
Unsicherheit einer verallgemeinernden Prädiktion nicht ren. Ein autonomes System nimmt die Welt jedoch über
vermeiden (bias-variance tradeoff ). Sensoren war, die im Wesentlichen geometrische Infor-
Stochastische relationale Modelle ermöglichen die Mo- mationen liefern. Symbole müssen daher entweder von
dellierung von Unsicherheit, und damit sowohl das Er- einem menschlichen Experten vorgegeben oder, wie wir
lernen kompakter und verallgemeinernder Modelle aus vorschlagen, aus Erfahrung gelernt werden. Was sind ge-
Erfahrung als auch das Planen mit erlernten Modellen. eignete Kriterien und Gütemaße für Symbole, die eine
Ein Beispiel für stochastische relationale Modelle bilden Grundlage für das Lernen bieten können? Im Folgenden
probabilistische relationale Regeln wie die folgende: diskutieren wir kurz Beispielansätze.
Wellens et al. (2008) modelliert Lernen von Symbolen
greife(X) : klotz(X), ball(Y ), auf(Y, X) als Kommunikationproblem: Agenten müssen die Be-
70% : inhand(X), ¬auf(Y, X) deutungen von unbekannten Wörtern so lernen und für
→ 20% : ¬auf(Y, X) sich selbst definieren, dass kohärente Kommunikation
10% : noise
möglich ist. Die Autoren testen dieses Modell in Szena-
rien, in denen Roboter Objekte bewegen und dies einem
Diese Regel beschreibt auf abstrakte Weise eine Situa-
anderen Roboter kommunizieren müssen. Die Roboter
tion, in der ein System versucht, einen Klotz zu greifen,
lernen dadurch eine Abbildung von visuellen Merkmalen
auf dem ein Ball liegt. Diese Regel dient der Vorhersage
der Objekte auf symbolische Wörter. Lernen ist erfolg-
in jeder Situation, in der das System einen sonst nicht
reich, falls die Agenten einander zeigen können, welche
näher spezifizierten Klotz, auf dem ein Ball liegt, greifen
Objekte sie demnächst manipulieren wollen.
möchte. Die relationale Beschreibung fasst hierbei eine
exponenzielle Anzahl an möglichen Situationen in einer Kollar et al. (2010) lernt die Bedeutung von Wörtern,
kurzen probabilistischen Regel zusammen. die in Wegbeschreibungen vorkommen, aus Beispielen
Pasula et al. (2007) beschreiben einen Algorithmus von Bewegungstrajektorien und deren Beschreibung in
zum Lernen von Mengen solcher Regeln aus einer natürlicher Sprache von einem Lehrer. Man kann auf
Erfahrungsmenge. Der Algorithmus folgt fundamen- Grund dieser Daten die geometrische Bedeutung vieler
tal der klassischen Lerntheorie: Er versucht alle Er- Wörter (z.B. links abbiegen“) lernen. Es wird aber ein
”
fahrungen mit der Regelmenge zu erklären (like- Lehrer benötigt, der große Datenmengen erzeugt.
lihood -Maximierung), aber gleichzeitig möglichst we- Feldman (2012) argumentiert als Kognitionswissen-
nige und kompakte Regeln zu nutzen (Regularisie- schaftler, dass eine symbolische Beschreibung alle wich-
rung in Form einer minimalen Beschreibungslänge). tigen Eigenschaften einer kontinuierlichen Welt beinhal-
Bei wenig Erfahrung entstehen wenige, kompakte und ten kann. Die Formalisierung mittels üblicher Mixtur-
stark (über-)verallgemeinernde Regeln; bei mehr Erfah- Modelle in einem Vektorraum scheint jedoch naiv, wenn
rung werden die Regeln mehr, expliziter und genau- man an natürliche Welten denkt. Zudem wird in keiner
er. Dieser gewünschte Effekt basiert fundamental auf Weise der Nutzen von Symbolen für die Organisation
5von Verhalten, z.B. für das Lernen und Planen in Be-
tracht gezogen.
Unserer Meinung nach sollten sich gute Symbole für ko-
gnitive Systeme gerade dadurch auszeichnen, dass sie
die für die Handlungsplanung wesentlichen Aspekte der
Umwelt repräsentieren und effizientes, generalisieren-
des Lernen ermöglichen. Dies steht im Gegensatz zum
rein unüberwachten Lernen, das Symbole oder Unterdi- (a) (b)
mensionen sucht, die die Varianz in Daten erklärt, un- Bild 3: Bespielwelt für das Manipulieren von Objekten und ge-
abhängig von deren eigentlichen Nutzen. lernte Symbole füer stehtauf(X,Y) : es ist wahr, wenn zwei
Blöcke aufeinander gestapelt sind.
Unser Ansatz versucht dies in konkreten Robotik-
Szenarien zu realisieren (Jetchev et al., 2013). Wir be-
trachten einen Agenten, der aus einer Menge moto-
nem Agenten bewegt werden können (siehe Abbildung
rischer Fähigkeiten (Primitive) wählen kann, um eine
3(a)). Unser Agent beobachtet Sequenzen zufälliger Ak-
Bewegungssequenz zu erzeugen und damit die Objek-
tionen. Die Belohnung ist abhängig von der Höhe der
te in der Welt zu manipulieren. Der Agent muss aus
gebauten Türme. Ohne zuvor definierte Symbole be-
beobachteten kontinuierlichen Objektmerkmalen und
steht die Beobachtung des Agenten ausschliesslich aus
-relationen y ∈ Rd abstrakte Symbole lernen. Diese
den geometrischen Effekten der Aktionen: Wie sich (re-
Symbole sollen idealerweise die wichtigen Muster re-
lative) Koordinaten und geometrische Beziehungen zwi-
präsentieren, zum Beispiel, ob gewisse Fähigkeiten in
schen den Objekten ändern. Durch den oben genannten
der momentanen Situation anwendbar sind und wel-
Optimierungsprozess lernt der Agent aus diesen Daten
che Wirkung sie erzielen. Die Bedeutung von wich-
” Prädikate, die wir z.B. mit istinhand(X), stehtauf(X,Y)
tig“ kann sich aber in verschiedenen Situationen unter-
benennen würden – aus Sicht des Agenten besteht die
scheiden. Wenn ein Affe etwas Essbares in einem Wald
Semantik dieser gelernten Symbole aus nichts anderem
sucht, sind vielleicht Eigenschaften wie rot“, weich“
” ” als deren Rolle in den prädiktiven Modellen. Auf Grund
und giftig“ wichtig. Wenn derselbe Affe eine Waffe
” der Optimierungskriterien erlauben es die Symbole ef-
sucht, sind hart“ und scharf“ wichtige Symbole. Er-
” ” fektiv – auf Basis der im vorigen Abschnitt diskutier-
folgreiche Agenten, die ihre Ziele erreichen können, ha-
ten Methoden – Aktionssequenzen zu planen, die dem
ben Symbole gelernt, die zu Belohnung führen (hier: Ziel
Agenten hohe Belohnung verschaffen. Zum Beispiel wird
erreicht). Die Qualität der gelernten Symbole wird indi-
erlernt, dass manche Gegenstände, etwa Kugeln, nicht
rekt gemessen, mittels der Fähigkeit des Agenten, ziel-
gestapelt werden können. In unserem Experiment wurde
gerichtetes Verhalten mit diesen Symbolen zu erzeugen.
ein entsprechendes Symbol gelernt (wir könnten es istku-
Wir definieren ein Symbol als relationales Prädikat oh- gel(X) benennen), da es zu einem besseren prädiktiven
ne immanente Semantik. Zu diesem Symbol gehört ei- Modell führt. Viele andere denkbaren Symbole, wie z.B.
ne Abbildung (Klassifikator) von geometrischen Merk- linksvon(X,Y) wurden nicht gelernt, da sie für die Be-
malen auf binäre Wahrheitswerte des Prädikats – dem lohnung oder Transitionsvorhersage in der konkreten Te-
Grounding des Symbols. Symbol-Lernen reduziert sich stumgebung irrelevant sind.
dann auf das Lernen geeigneter Klassifikatoren. Ent-
scheidend ist nun die Wahl der Gütefunktion dieser
Klassifikatoren. Unser Ansatz kombiniert drei Kriterien:
Erstens sollen die Symbole gleichzeitig prädikiv und dis- 6 Autonome Exploration
kriminativ bzgl. der Wirkung von Aktionen sein. Sym-
bole sollen also den Vor- und Nach-Zustand einer Aktion Kognitive Systeme sollen selbstständig und zielgerich-
unterscheiden können und gleichzeitig hinreichend Infor- tet in ihrer Umgebung handeln. Aus ihren Erfahrungen
mationen liefern, dass ein auf diesen Symbolen gelerntes müssen sie verstehen lernen, auf welche Weise sie auf
Model den Nach-Zustand vorhersagen kann. Zweitens ihre Umgebung einwirken können. Nur selten steht ih-
sollen Symbole Belohnungs-diskriminativ sein, d.h. sie nen dabei ein Lehrer zur Seite. Stattdessen müssen sie
sollen hinreichend Informationen liefern, so dass ein auf ihren derzeitigen Wissensstand überdenken und darauf-
diesen Symbolen gelerntes Modell die Belohnung vorher- hin selbst aussuchen, was sich lohnt zu explorieren.
sagen kann. Drittens sollen Symbole einfach sein, d.h. Wie kann man ein kognitives System bauen, das eine
möglichst wenige und selten wechselnde Symbole sollen neue Umgebung in möglichst kurzer Zeit erkundet und
gesucht werden. dadurch ein Modell der eigenen Handlungen erlernt? Die
Diese drei Kriterien lassen sich formal fassen. Das Erler- in der jüngeren KI- und Robotik-Forschung entwickelten
nen geeigneter Symbole wird dadurch zu einem Optimie- Explorationsmethoden realisieren eine Form von Neu-
”
rungsproblem der entsprechenden Klassifikatoren (Jet- gier“, die Lernoptimalität oder -effizienz in dem ein oder
chev et al., 2013). Ein anschauliches Beispiel betrachtet anderen Sinne garantiert. Zentrale Paradigmen sind et-
die klassische Welt aus Blöcken und Kugeln, die von ei- wa das sog. Bayesische Reinforcement-Lernen (Poupart
6et al., 2006) und auch R-max (Brafman and Tennen- in oberflächlicher Hinsicht vergleichbar geblieben. Den-
holtz, 2002). Im Wesentlichen erhält das System eine for- noch gab es hinter diesen Demonstrationen wichtige
male Belohnung jedes Mal, wenn es etwas Neues lernt. Fortschritte in der Robotik, KI und im Maschinellen
Ein wesentliches Problem ist dabei das Abwägen zwi- Lernen: Die Leistungen von Shakey – genauso wie die im
schen dem möglichen Wert neuer Erfahrungen und dem telegesteuerten PR1-Video – spiegeln direkt die Intelli-
Ausnutzen bereits erlernten Wissens (der exploration- genz der Ingenieure wieder, nicht die des Roboters. Die
exploitation tradeoff ). Die genannten Methoden geben Forschung versucht seitdem, mehr Autonomie und In-
mögliche optimale Antworten auf dieses Problem. telligenz im System selbst zu verwirklichen, insbesonde-
Bei der Anwendung solcher Explorationsmethoden in re die Fähigkeit des Lernens. Im Zuge dieser Forschung
Alltagsumgebungen ergeben sich interessante Heraus- schärfte sich vor allem unser Verständnis der fundamen-
forderungen: Die Anzahl möglicher Handlungen ist talen Probleme, die in der Anfangszeit der Künstlichen
unüberschaubar, der Raum möglicher Weltzustände ist Intelligenz und Robotik nicht wahrgenommen wurden.
wie oben dargelegt exponentiell in der Anzahl der Eines dieser Probleme ist Unsicherheit: In der klassi-
modellierten Gegenstände. In einem dermaßen großen schen KI wurde oft von fehlerfreien symbolischen Mo-
Suchraum kommt es so gut wie nie vor, dass exakt die- dellen der Umwelt ausgegangen – woher die notwendi-
selbe Situation zweimal auftritt. Vielmehr ist jede Si- gen symbolischen Abstraktionen und das Wissen selbst
tuation neu. Daher kann Neuheit allein keine effiziente kommt, wurde vernachlässigt. Erlerntes Wissen ist aber
Explorationsstrategie sein. Von entscheidender Bedeu- zwangsläufig mit Unsicherheit behaftet. Für das effizi-
tung ist die Verallgemeinerung des eigenen Wissens auf ente Lernen, die Exploration und Planung mit unsiche-
neue, aber strukturell äquivalente Situationen. Wenn ein rem Wissen sind erst in jüngerer Zeit vielversprechende
bisher erlerntes Modell scheinbar gut auf eine neue Si- Methoden entwickelt worden. Das Erlernen geeigneter
tuation verallgemeinert werden kann, so ist diese weni- symbolischer Abstraktionen bleibt weiterhin ein wichti-
ger interessant für die Exploration. Die oben beschriebe- ges Forschungsfeld. Die hier diskutierten Methoden sind
nen stochastischen relationalen Modelle implizieren also nur ein erster Schritt.
nicht nur eine bestimmte Form der Verallgemeinerung Es werden auch Lücken in unseren theoretischen Me-
beim Lernen, sondern auch eine bestimmte Explorati- thoden erkennbar. Um die Schätzung, Prädiktion und
onsstrategie. Nehmen wir als Beispiel einen Roboter, der Manipulation externer Freiheitsgrade zu ermöglichen,
einige Zeit mit blauen und roten Blöcken Erfahrung ge- brauchen wir geeignete Repräsentationen, strukturier-
sammelt hat. Danach wird ihm ein grüner Klotz und te Wahrscheinlichkeitsmodelle. Die hier diskutierten re-
ein grüner Ball gegeben. Beide Gegenstände hat der Ro- lationalen Modelle sind nur ein Beispiel für geeignete
boter noch nie gesehen. Ein simpel gestricktes System Repräsentationen, die die Struktur der Umwelt wieder-
würde beide daher als gleich interessant einstufen. Ein spiegeln – in diesem Fall ihre Komposition aus Objekten.
Roboter, der relationale Modelle lernt, kann hingegen Für viele andere Charakteristika der natürlichen Um-
ausnutzen, dass er bereits zuvor anhand der blauen und welt haben wir bisher noch keine mathematischen For-
roten Klötze gelernt hat. Er weiß, was er mit Klötzen an- malismen, um sie auszudrücken und entsprechend gene-
fangen und dass er sie zum Beispiel aufeinander stapeln ralisierende Lern- und Planungsmethoden abzuleiten.
kann. Insbesondere hat er erkannt, dass die Farbe ei-
nes Klotzes keine Auswirkung darauf hat, was mit ihm Wenn man also unter kognitiver Robotik, wie hier vor-
gebaut werden kann. Ein solcher Roboter wird daher geschlagen, die Erweiterung von Lernen, Planen, Infe-
den grünen Ball zur Exploration bevorzugen, auf den renz und Regelung auf äußere Freiheitsgrade verstehen
sein zuvor erlerntes Wissen nicht verallgemeinert. Ak- will, so wird es zum zentralen Problem, die Struktur die-
tuelle Systeme, die in der stochastischen relationalen KI ser äußeren Welt in geeignete Priors, Repräsentationen
erforscht werden, zeigen in Experimenten genau dieses und Modellannahmen zu übersetzen. Mit den hier disku-
Verhalten (Lang et al., 2010, 2012). tierten Ansätzen zum relationalen Lernen und Symbol-
Lernen sind erste Beispiele gegeben. Die existierenden
Forschungsrichtungen zur Integration von Logik, Geo-
metrie und Wahrscheinlichkeiten (etwa (Kaelbling and
7 Zusammenfassung Lozano-Pérez, 2011)) gehen in dieselbe Richtung. Den-
noch wird die Forschung vermutlich noch einige Zeit
In den 1960er Jahren stellte das MIT Shakey vor, einen mit ähnlichen Szenarien beschäftigt sein, wie sie ober-
mobilen Roboter, der Objekte verschieben, greifen und flächlich schon vor 50 Jahren mit Shakey begonnen wur-
plazieren konnte (Nilsson, 1984). Im Grunde hat die hier den. Anders als damals sind das Ziel jedoch Systeme,
diskutierte Forschung, und generell die Forschung an die durch intelligente Exploration und Verallgemeine-
kognitiven Systemen, immer noch sehr ähnliche Ziele. rung autonom lernen. Mit selbst erlernten Modellen und
Hat die Robotikforschung also in den letzten 40 Jah- Symbolen sollen sie in gewisser Weise begreifen“, was
”
ren keinen Fortschritt gemacht? Tatsächlich ist das, was sie tun, und dies eigenständig zur Verhaltensorganisati-
mit Robotern im Kontext der autonomen Objektma- on nutzen. Die Fortschritte in der Lerntheorie und Ro-
nipulation und Handlungsplanung demonstriert wird, botik erlauben uns es heute besser zu verstehen, welche
7fundamentalen wissenschaftlichen Probleme sich hinter diesem Ziel verbergen. Danksagung Die Autoren bedanken sich bei der Deutschen For- schungsgemeinschaft für die Einrichtung des Schwer- punktprogramms SPP 1527. Diese Forschung wurde im Rahmen des Projekts TO 409/7-1 gefördert. 8
at 8/2004
Literaturverzeichnis
D. Andre and S. Russell. Programmable reinforcement Y. Niv, J. D., and D. P. A normative perspective on
learning agents. In Proceedings of the 13th Con- motivation. Trends in Cognitive Sciences (TICS), 10:
ference on Neural Information Processing Systems 375–381, 2006.
(NIPS 2001), pages 1019–1025, 2001.
T. Asfour, K. Regenstein, P. Azad, J. Schroder, A. Bier-
baum, N. Vahrenkamp, and R. Dillmann. Armar-iii:
An integrated humanoid platform for sensory-motor
H. M. Pasula, L. S. Zettlemoyer, and L. P. Kaelb-
control. In Humanoid Robots, 2006 6th IEEE-RAS In-
ling. Learning symbolic models of stochastic domains.
ternational Conference on, pages 169–175. Ieee, 2006.
Journal of Artificial Intelligence Research (JAIR), 29:
M. Beetz, F. Stulp, B. Radig, J. Bandouch, N. Blodow, 309–352, 2007.
M. Dolha, A. Fedrizzi, D. Jain, U. Klank, I. Kresse,
et al. The assistive kitchen—a demonstration sce-
nario for cognitive technical systems. In Robot and
Human Interactive Communication, 2008. RO-MAN
2008. The 17th IEEE International Symposium on, J. Pearl. Probabilistic Reasoning In Intelligent Systems:
pages 1–8. IEEE, 2008. Networks of Plausible Inference. Morgan Kaufmann,
R. I. Brafman and M. Tennenholtz. R-max - a general 1988.
polynomial time algorithm for near-optimal reinforce-
ment learning. Journal of Machine Learning Research
(JMLR), 3:213–231, 2002.
J. Feldman. Symbolic representations of probabilistic
P. Poupart, N. Vlassis, J. Hoey, and K. Regan. An ana-
worlds. Cognition, 123:61–83, 2012.
lytic solution to discrete Bayesian reinforcement lear-
R. Fikes and N. Nilsson. STRIPS: a new approach to ning. In Proc. of the Int. Conf. on Machine Learning
the application of theorem proving to problem solving. (ICML), pages 697–704, 2006.
Artificial Intelligence Journal, 2:189–208, 1971.
N. Jetchev, T. Lang, and M. Toussaint. Learning groun-
ded relational symbols from continuous data for ab-
stract reasoning. Submitted to ICRA 2013, 2013.
L. Kaelbling and T. Lozano-Pérez. Hierarchical task and J. Steil, F. Röthling, R. Haschke, and H. Ritter. Situated
motion planning in the now. In Robotics and Auto- robot learning for multi-modal instruction and imita-
mation (ICRA), 2011 IEEE International Conference tion of grasping. Robotics and Autonomous Systems,
on, pages 1470–1477. IEEE, 2011. 47(2):129–141, 2004.
W. Köhler. Intelligenzprüfungen an Menschenaffen.
Springer, Berlin (3rd edition, 1973), 1917. English ver-
sion: Wolgang Köhler (1925): The Mentality of Apes.
Harcourt & Brace, New York. S. Thrun. Towards programming tools for robots that
T. Kollar, S. Tellex, D. Roy, and N. Roy. Toward under- integrate probabilistic computation and learning. In
standing natural language directions. In HRI, pages Proceedings of the IEEE Int. Conf. on Robotics and
259–266, 2010. Automation (ICRA 2000), 2000.
T. Lang and M. Toussaint. Planning with noisy probabi-
listic relational rules. Journal of Artificial Intelligence
Research (JAIR), 39:1–49, 2010.
T. Lang, M. Toussaint, and K. Kersting. Exploration
S. Vijayakumar, A. D’Souza, and S. Schaal. Incremental
in relational domains for model-based reinforcement
online learning in high dimensions. Neural Computa-
learning. In Proc. of the European Conf. on Machine
tion, 17(12):2602–2634, 2005.
Learning (ECML), 2010.
T. Lang, M. Toussaint, and K. Kersting. Exploration
in relational domains for model-based reinforcement
learning. Journal of Machine Learning Research, 13:
3691–3734, 2012. P. Wellens, M. Loetzsch, and L. Steels. Flexible word
N. Nilsson. Shakey the robot. Technical Note 323. AI meaning in embodied agents. Connection Science, 20
Center, SRI International 323, 1984. (2-3):173–191, 2008.
at – Automatisierungstechnik 68 (2020) 8 c Oldenbourg Verlag 9
04Prof. Dr.rer.nat. Marc Toussaint ist Pro-
fessor und Leiter des Machine Learning and
Robotics Lab an der Universität Stuttgart.
Hauptarbeitsgebiete: Maschinelles Lernen,
Reinforcement Lernen, Robotik.
Adresse: Universität Stuttgart, Uni-
versitätsstraße 38, 70569 Stuttgart,
marc.toussaint@informatik.uni-stuttgart.de
Dr.rer.nat. Tobias Lang ist Wissenschaft-
ler im Machine Learning and Robotics Lab der
FU Berlin und erforscht autonome Explorati-
on und Schlussfolgerung kognitiver Systeme.
Adresse: tobias.lang@fu-berlin.de
Dr.rer.nat. Nikolay Jetchev ist Wissen-
schaftler im Machine Learning and Robotics
Lab der FU Berlin und erforscht, wie Robo-
ter aus Demonstration lernen und ihre Umwelt
in symbolischen Beschreibungen abstrahieren
können.
Adresse: nikolay.jetchev@fu-berlin.de
10Sie können auch lesen