Simulations- und Softwaretechnik Statusbericht 2015 2019 - Statusbericht 2015 2019
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

Simulations- und Softwaretechnik Statusbericht 2015 – 2019 Teil 1

Simulations- und Softwaretechnik
Statusbericht 2015 – 2019
Teil 1
2
Inhaltsverzeichnis
Vorwort ___________________________________________________ 7 Onboard Software Systems __________________________________ 62
Herausforderungen der Software-Entwicklung für Raumfahrtsysteme 62
Überblick __________________________________________________ 8 Software-Forschung und -Entwicklung für Flugsysteme 63
Modellgetriebene Software-Entwicklung 67
Programmatische Einbindung und Kooperationen _______________ 11 Laufzeitumgebungen für Raumfahrtsysteme 68
Programmatische Einbindung 11 Software-Qualitätssicherung 70
Kooperation mit DLR-Instituten 11
Nationale und internationale Kooperationen 13 Wissenschaftliche Visualisierung ______________________________ 72
Analyse großer wissenschaftlicher Datenmengen 72
Forschungsergebnisse und Planungen _________________________ 15 Interaktive Visualisierung von Planetendaten 74
Merkmalsbasierte Datenanalyse und Visualisierung 76
Verteilte Softwaresysteme ___________________________________ 16
Software für multidisziplinäre Zusammenarbeit 16 3D-Interaktion _____________________________________________ 78
Die verteilte Integrationsumgebung RCE 17 Virtuelle Montagesimulation 78
Angewandtes Software-Engineering 19 Mensch-Maschine-Schnittstellen 80
Provenance 19
BACARDI – Ein Datenbank-System für die Analyse von Raumfahrtrückständen 22 Ausbildung und Lehre_______________________________________ 84
Diplom-/Master-/Bachelor-Abschlussarbeiten 84
Intelligente Softwaresysteme ________________________________ 24 Betreute Dissertationen 85
Wissensmanagement mit KnowledgeFinder 24 Wissenschaftleraustausch 85
Benutzerschnittstellen mit hoher Usability 25 Lehrtätigkeit 86
Maschinelles Lernen 25
Software Visualisierung 27 Veröffentlichungen_________________________________________ 87
Software Engineering _______________________________________ 30
Die DLR-Software-Engineering-Initiative 30
Direkte Unterstützung beim Software Engineering 33
Software-Analytik 35
Nachhaltige Entwicklung von Forschungssoftware für das DLR 36
Intelligente Algorithmen und Optimierung _____________________ 38
High-Performance Data Analytics 38
Designoptimierung 41
Optimierungsalgorithmen 45
Quantencomputerbasierte Optimierung 46
Parallele Numerik __________________________________________ 49
Methodik der HPC-Softwareentwicklung 50
Paralleles Datenmanagement und Partitionierung 51
Numerische Simulation von gekoppelten und nicht-linearen Problemen 52
Performance-Modellierung und Performance-Engineering 53
Skalierbare Matrix-Algorithmen 54
Modellierung und Simulation ________________________________ 56
Systems Engineering und Modellierung 56
Virtual Satellite 56
Formale Methoden und Simulation 59
Vorwort
Die „Simulations- und Softwaretechnik“ (SC) wurde 1998 gegründet und 2007 durch den
DLR-Senat als wissenschaftlich-technische Einrichtung bestätigt. Im Dezember 2002,
Oktober 2010 und April 2015 stellten wir uns erfolgreich externen Überprüfungen. Im
April 2019 berät eine Strukturkommission über die Umwandlung der Einrichtung in ein DLR-
Institut und die Ausrichtung des Instituts nach meinem Ausscheiden im Jahre 2022. Der vor-
liegende Statusbericht dient der Vorbereitung dieser Strukturkommission.
Unsere Kernkompetenz ist die moderne Softwaretechnologie. Mit dieser Kompetenz ergänzt
SC die mehr als 40 DLR-Institute und -Einrichtungen überwiegend ingenieurwissenschaftli-
cher Ausrichtung. In vielen gemeinsamen Projekten mit diesen Instituten übernehmen wir
anspruchsvolle Software-Themen. Im Auftrag des zentralen IT-Managements erfüllen wir
darüber hinaus eine Querschnittsaufgabe im Software-Engineering. Wir beraten andere
Institute, wie sie fortschrittliche Software-Engineering-Verfahren einsetzen können, und wir
schulen ihre Mitarbeiter.
Softwaretechnologie bekommt in Forschungsprojekten einen immer größeren Stellenwert.
Auch im DLR wächst die Bedeutung eigener Forschung und Entwicklung auf diesem Gebiet.
Wir forschen in eigenen Vorhaben und in Drittmittelprojekten mit Partnern aus Wissenschaft
und Industrie. Unsere Mitarbeiterinnen und Mitarbeiter betreuen Dissertationen, Master-
und Bachelorarbeiten und übernehmen Lehrveranstaltungen an Hochschulen. Unsere aktu-
ellen Forschungsthemen decken ein breites Spektrum ab und spiegeln den vielfältigen Ein-
satz von Software im DLR wider. Wir kooperieren inzwischen mit fast allen DLR-Instituten.
Dieser erste, öffentliche, Teil des Statusberichts gibt einen Überblick über die Themen, die im
Berichtszeitraum bearbeitet wurden, und präsentiert unsere Ergebnisse und Pläne. Er stellt
den Bezug zu den Anwendungen in den Partnerinstituten her. Am Ende steht eine Übersicht
unserer Publikationen und Aktivitäten in Ausbildung und Lehre.
Rolf Hempel
Das Team der Simulations- und Softwaretechnik im Jahr 2017.
7
Überblick Im Folgenden stellen wir die Themen der Abteilungen und ihrer Arbeitsgruppen kurz vor.
Abteilung Intelligente und verteilte Systeme (IVS)
Die Abteilung „Intelligente und verteilte Systeme“ forscht auf den Gebieten verteilte und
dezentrale Softwaresysteme, intelligente und wissensbasierte Softwaresysteme sowie Soft-
ware Engineering und Software-Analytik. Auf diesen Forschungs- und Anwendungsgebieten
arbeitet die Abteilung gruppenübergreifend daran komplexe Prozesse und Softwaresysteme
zu verstehen, zu entwickeln und zu optimieren. Insbesondere liegt ein Schwerpunkt darauf,
Software- und Systemarchitekturen zu entwerfen, zu warten und ihre Benutzbarkeit (Usability)
zu verbessern. In vielen Anwendungen spielen abstrakte Graph-basierte Daten eine Rolle
(z.B. Software-Abhängigkeiten, Provenance-Graphen oder Simulationsnetzwerke), für
welche die Abteilung innovative Ansätze zur Analyse und Visualisierung entwickelt, bei-
Wir erforschen und entwickeln Softwaretechnologien, die für aktuelle oder zukünftige An- spielsweise in Virtual- und Augmented Reality.
wendungen im DLR relevant sind. Unsere Vorlaufforschung ist hauptsächlich drittmittel-
finanziert. Damit bauen wir Know-how auf und entwickeln grundlegende Softwareprodukte. Ein Schwerpunkt der Arbeitsgruppe „Verteilte Softwaresysteme“ ist, komplexe Prozesse
Programmatisch finanzierte Verbundprojekte mit anderen DLR-Instituten bilden den Schwer- aus der Wissenschaft zu verstehen, nachzuvollziehen und reproduzierbar zu machen. Dazu
punkt unserer Arbeit. In diesen Projekten übernehmen wir anspruchsvolle Software-Aufgaben gehört, Software zur multidisziplinären Kopplung mehrerer Fachdisziplinen zu entwickeln,
und ergänzen damit die ingenieurwissenschaftlichen Beiträge der Partnerinstitute. um in verteilten Systemen Simulationen, Systementwürfe und Systembewertungen durchzu-
führen. Forschung auf dem Gebiet Data Provenance dient dazu, das Entstehen von Daten
Wir sind an den Standorten Köln-Porz und Braunschweig vertreten und unterhalten Außen- nachzuvollziehen und Data-Science-Prozesse zu verstehen.
stellen in Berlin und Bremen. Am Standort Oberpfaffenhofen bauen wir derzeit einen neuen
Ableger auf. Der Forschungsschwerpunkt der Arbeitsgruppe „Intelligente Softwaresysteme“ ist,
Methoden der künstlichen Intelligenz (Deep Learning etc.) zu entwickeln und erklärbar zu
SC ist in drei Abteilungen gegliedert: machen (Explainable AI). Eingesetzt werden sie zur Entwicklung und Verbesserung intelligen-
ter, interaktiver Softwaresysteme. Beispiele sind Benutzerschnittstellen mit hoher Usability,
• Intelligente und verteilte Systeme (IVS, Leitung: Andreas Schreiber) intelligente Sprachassistenten oder visuelle Explorationswerkzeuge für Informationen und
Wissensquellen.
• High-Performance Computing (HPC, Leitung: Dr. Achim Basermann)
Um die Qualität und Nachhaltigkeit der Softwareentwicklung im DLR zu verbessern, arbeitet
• Software für Raumfahrtsysteme und interaktive Visualisierung (SRV, die Arbeitsgruppe „Software Engineering“ daran, mit Entwicklungstools, systematischen
Leitung: Dr. Andreas Gerndt) Testverfahren und Know-how in Open-Source-Softwareentwicklung, Software-Artefakte und
die damit erzielten Ergebnisse über lange Zeit reproduzierbar wieder erzeugen zu können.
Die Abteilungen umfassen jeweils mehrere Arbeitsgruppen (Abb. 1). Dabei geht es auch um Methoden für wissenschaftliche Softwareentwicklung (Research
Software Engineering; RSE) und um Wissensaustausch zwischen Kollegen im DLR, welche
Software entwickeln.
Abb. 1: Organigramm der Einrichtung Simulations- Simulations- und Softwaretechnik (SC)
und Softwaretechnik. Leitung: Rolf Hempel
Leitungsbereich (SC-LTG): Controlling, IT, Teamassistenz
Abteilung High-Performance Computing
Intelligente und verteilte Systeme High-Performance Computing Software für Raumfahrtsysteme und Die Abteilung „High-Performance Computing“ (HPC) entwickelt parallele numerische Biblio-
(SC-IVS) (SC-HPC) interaktive Visualisierung (SC-SRV)
theken aus der linearen Algebra zur Lösung partieller Differentialgleichungen und aus dem
Leitung: Andreas Schreiber Leitung: Dr. Achim Basermann Leitung: Dr. Andreas Gerndt Bereich Optimierung, performante Simulationswerkzeuge sowie effiziente Datenanalyse-
tools. Diese werden vorwiegend in Raumfahrtanwendungen genutzt. Ziel der Entwicklungen
Intelligente Algorithmen und ist die Beschleunigung von DLR-Simulationscodes auf HPC-Systemen oder neuartigen Rechner-
Verteilte Softwaresysteme Modellierung und Simulation
Optimierung
(N. N.) (Philipp M. Fischer) architekturen wie Quantencomputern (QC) sowie die effiziente Analyse großer Datenmengen.
(Dr. Martin Siggel)
Intelligente Softwaresysteme Parallele Numerik Onboard Software Systems Um extrem große und verteilte Daten auf HPC-Systemen analysieren zu können, erforscht
(Dr. Nico Hochgeschwender) (Dr. Jonas Thies) (Daniel Lüdtke)
die Arbeitsgruppe „Intelligente Algorithmen und Optimierung“ Methoden des
maschinellen Lernens. Anwendungsgebiete sind z.B. Analysen von Verbrennungsdaten in
Software Engineering Wissenschaftliche Visualisierung Raketentriebwerken und großen Datenmengen aus Erdbeobachtung oder Planetenfor-
(Carina Haupt) (Dr. Andreas Gerndt, komm.)
schung. Die Designoptimierung für Flug- bzw. Raumfahrzeuge, Triebwerke oder einzelne
Raketenbauteile unterstützen wir durch angepasste Optimierungsalgorithmen, parametri-
3D-Interaktion sche Geometriemodellierungstools und maßgeschneiderte Software. Im Forschungsbereich
(Dr. Andreas Gerndt, komm.)
Quantencomputing untersuchen wir, wie QC-Systeme künftig in DLR-Anwendungen einge-
setzt werden können. Unser Fokus liegt dabei auf kombinatorischen Optimierungsproble-
men, z.B. zur optimalen Aufnahmeplanung für Erdbeobachtungssatelliten oder zur Anomalie-
Detektion in Satellitentelemetriedaten.
8 9
Forschungsschwerpunkte der Arbeitsgruppe „Parallele Numerik“ sind Performance-Mo-
dellierung und -Engineering für Hochleistungsrechner bis hin zu künftigen Exaflopsystemen,
Programmatische Einbindung
um die erreichbare Performance eines Algorithmus und seiner Implementierung auf einer
bestimmten Hardware-Komponente vorherzusagen. Wir erforschen innovative Ansätze bei und Kooperationen
Softwarearchitektur und -entwicklung, um Portierbarkeit auf neue HPC-Systeme zu gewähr-
leisten. Ferner entwickeln wir neue parallele Methoden für Datenmanagement und -partitio-
nierung, zur numerischen Simulation gekoppelter, nichtlinearer Strömungsprobleme und zur
Lösung dünnbesetzter Gleichungs- und Eigenwertprobleme.
Abteilung Software für Raumfahrtsysteme und interaktive
Visualisierung
Die Abteilung „Software für Raumfahrtsysteme und interaktive Visualisierung“ beschäftigt
sich mit der Erforschung und Entwicklung von Software-Lösungen zur Unterstützung von Programmatische Einbindung
Planungsprozessen in der Raumfahrt. Dabei wird der komplette Entwurfslebenszyklus von
der ersten Plausibilitätsstudie bis zur Softwareintegration auf Onboard-Systemen betrachtet. Wie die anderen Institute und Einrichtungen bezieht SC den größten Teil der internen Finan-
Unterstützt werden diese Arbeiten durch Methodenforschung im Bereich der interaktiven zierung von den Programmdirektionen. Derzeit sind wir mit Projektbeiträgen in allen For-
Visualisierung zur Analyse großer wissenschaftlicher Missions- und Simulationsdaten. Dane- schungsbereichen (Raumfahrt, Luftfahrt, Energie und Verkehr) vertreten:
ben gewinnt die 3D-Interaktion mithilfe von Virtual Reality (VR) und Augmented Reality (AR)
vor allem in Planungs- und Wartungsszenarien von Raumfahrtsystemen zunehmenden an • Raumfahrt: Der größte Teil der Projekte ist der Programmlinie „Technik für Raum-
Bedeutung. fahrtsysteme“ zugeordnet. Hier werden technologische Grundlagen für die ande-
ren Programmlinien entwickelt. Ferner beteiligen wir uns an den Programmlinien
In der Arbeitsgruppe „Modellierung und Simulation“ werden flexible und fehlertolerante Raumtransport und Robotik. Das Bremer Institut für Raumfahrtsysteme ist unser
Entwurfsprozesse auf Basis des „Model-based Systems Engineering“ (MBSE) erforscht. Ein wichtigster interner Partner.
zentrales digitales Modell des technischen Systems ermöglicht die Integration formaler Me-
thoden vom Anforderungsmanagement, über die Systemanalyse bis hin zur Validierung des • Luftfahrt: Im Forschungsgebiet „Aircraft Research“ kooperieren wir insbesondere
Gesamtkonzepts. Dadurch lässt sich eine hohe Abstraktion für den Anwender erreichen und mit dem Braunschweiger Institut für Aerodynamik und Strömungstechnik, im
durch Automatisierung die Fehleranfälligkeit von Entwurfsprozessen minimieren. Forschungsgebiet „Engine Research“ mit dem Kölner Institut für Antriebstechnik.
Ferner sind wir beteiligt an Projekten aus den Forschungsgebieten „Luftverkehrs-
Die Arbeitsgruppe „Onboard Software Systems“ schließt nahtlos an den MBSE- management und Flugbetrieb“ und „Common Rotorcraft Research“.
Forschungsergebnissen an und erforscht neue Konzepte für Flugsoftware von Raumfahrtsys-
temen und setzt sie in Missionen ein. Neue Softwaretechniken, wie zum Beispiel die modell- • Verkehr: Im Forschungsbereich Verkehr leisten wir Beiträge zu den Teilgebieten
getriebene Softwareentwicklung, erhöhen die Flexibilität und Zuverlässigkeit. Zudem arbeitet „Schienenfahrzeuge“, „Fahrzeugintelligenz und Fahrwerk“, „Urbane Mobilität“,
die Arbeitsgruppe an anpassungsfähigen und verteilten Laufzeitumgebungen. Diese weisen „Verkehrsknoten“ und „Verkehrsentwicklung und Umwelt“. Das Institut für
den in einem Raumfahrtzeug vorhandenen Onboard-Rechnern die je nach Missionsphase Verkehrssystemtechnik in Braunschweig ist derzeit unser wichtigster Partner.
anstehenden Aufgaben intelligent und fehlertolerant zu.
• Energie: Am Energie-Programm sind wir erstmals seit über fünfzehn Jahren
Bei der Interpretation immer größerer Ergebnisdatensätze aus Simulationsrechnungen, wieder beteiligt mit einem Beitrag zum Thema „Neue Wärmeträgerfluide“.
Experimenten und Beobachtungsmissionen kommt der Visualisierung große Bedeutung zu.
Daher entwickelt die Arbeitsgruppe „Wissenschaftliche Visualisierung“ skalierbare Lö- • IT-Management: Eine Besonderheit unserer internen Finanzierung sind die
sungen, in denen die Postprocessing-Pipeline effizient auf HPC- und Visualisierungssystemen Projekte im Auftrag des IT-Managements. Hierunter fallen unsere Querschnitts-
verteilt wird. Das Forschungsinteresse liegt dabei auf neue Verfahren der Extraktion von z. B. arbeiten zum Software-Engineering sowie kleinere Softwareentwicklungen, die
topologischen Merkmalen und in der Verbesserung der interaktiven Exploration extrem gro- keinem DLR-Forschungsbereich zugeordnet werden können.
ßer und zeitabhängiger Wissenschaftsdaten.
In den ersten Jahren war SC dem Vorstandsbereich Luftfahrt zugeordnet und wurde über-
Die Technik der „virtuellen Realität“ erlaubt dem Nutzer, mit den Objekten in einer compu- wiegend von dort finanziert. Im Laufe der Zeit hat sich das Verhältnis deutlich in Richtung
tergenerierten Szene möglichst naturgetreu und intuitiv zu interagieren. Die große Heraus- Raumfahrtforschung verschoben. Inzwischen machen die Raumfahrt-Ressourcen über die
forderung liegt dabei in der physikalisch korrekten Simulation von Montageprozessen, der Hälfte unseres gesamten internen Budgets aus.
plausiblen Rückkopplung von Kollisionen als haptisches Feedback und die fotorealistische
Darstellung. Neben diesen Forschungsthemen beschäftigt sich die Arbeitsgruppe „3D-
Interaktion“ mit Mixed-Reality-Anwendungen, die mithilfe „erweiterter Realität“ den Ein- Kooperation mit DLR-Instituten
satz von Digitalen Zwillingen in kooperativen Arbeitsumgebungen erforscht.
Dem breiten Themenspektrum unserer Softwareprojekte entsprechend kooperieren wir mit
fast allen DLR-Instituten.
Die wichtigsten Kooperationspartner unserer Arbeitsgruppen im DLR sind:
• Verteilte Softwaresysteme (IVS): Institute, bei denen die Systemkompetenz
eine große Rolle spielt, sind hier unsere Hauptpartner. Auf Luftfahrtseite sind dies
10 11
die Institute für Systemarchitekturen in der Luftfahrt sowie Instandhaltung und zeugkonzepte, Berlin, realisiert. Im Bereich der Visual Analytics kooperieren wir mit
Modifikation in Hamburg, bei der Raumfahrt das Institut für Raumfahrtsysteme in dem Institut für Datenwissenschaften, Jena.
Bremen und im Verkehr das Institut für Verkehrsforschung im Berlin. Zusätzlich
sind jeweils viele andere Institute mit ihren spezifischen Anwendungen an den • 3D-Interaktion (SRV): Eine langjährige Zusammenarbeit im Bereich der virtuellen
Integrationsprojekten beteiligt. Realität (VR) besteht mit dem Institut für Robotik und Mechatronik. Im Zuge der
DLR-Digitalisierungsstrategie werden Kooperationen u. a. mit dem Institut für
• Intelligente Softwaresysteme (IVS): Da die Arbeitsgruppe noch sehr neu ist Faserverbundleichtbau und Adaptronik, dem Institut für Verkehrssystemtechnik,
(Gründung am 01.12.2018), bestehen bisher nur wenige Kooperationen. Aktuell dem Institut für Instandhaltung und Modifikation und dem Institut für Flugführung
arbeiten wir schon mit dem Institut für Materialphysik im Weltraum (MP; Weiter- stetig ausgebaut.
entwicklung des Wissensmanagement-Werkzeugs KnowledgeFinder) und mit dem
Institut für Methoden der Fernerkundung (MF; Erforschung von Methoden für
Explainable AI und Visualisierung neuronaler Netze) zusammen. Nationale und internationale Kooperationen
• Software-Engineering (IVS): Softwareentwicklung und Software-Engineering Alle Arbeitsgruppen unterhalten externe Kooperationen, um ihre Technologien weiterzu-
spielen in den meisten Instituten des DLR eine wichtige Rolle. Daher arbeiten wir entwickeln. Die wichtigsten sind:
auch mit vielen Instituten aus allen DLR-Schwerpunkten in Projekten oder über
bilaterale Kooperationen zusammen. Aktuelle Kooperationen bestehen zum • Verteilte Softwaresysteme (IVS): Das Integrationsframework RCE haben wir
Beispiel mit der Einrichtung Raumflugbetrieb und Astronautentraining (RB; Projekt ursprünglich in enger Kooperation mit der Flensburger Schiffbaugesellschaft und
ADAM/ Openvocs), dem Institut für Instandhaltung und Modifikation (MO; mit Fraunhofer SCAI im Projekt SESIS entwickelt. Seit dem Ende dieses Projekts
Digitaler Zwilling), dem Institut für Verkehrsforschung (VF; Projekt MovingLab) haben wir RCE für Anwendungen in allen Ingenieursdisziplinen weiterentwickelt.
und dem Institut für Solarforschung (SF; Projekt HeliOS). Wir haben daneben im Externe Kooperationen bestehen zum Beispiel mit Airbus Defense and Space und
Institut für Datenwissenschaften (DW) die neue Arbeitsgruppe „Sichere Soft- mit zahlreichen Partnern im Rahmen mehrerer nationaler und europäischer Projekte
waretechnik“ aufgebaut mit der wir auch zukünftig intensiv zusammenarbeiten. aus Luftfahrt, Energie und Schiffbau. Daneben pflegen wir einen regelmäßigen
Austausch in der Provenance-Forschung mit einigen internationalen Universitäten,
• Intelligente Algorithmen und Optimierung (HPC): Wegen des breiten Themen- zum Beispiel dem King’s College London (Prof. Luc Moreau) oder der University of
spektrums arbeiten wir mit vielen verschiedenen Partnern im DLR zusammen. Dies Illinois, Urbana-Champain (Prof. Bertram Ludäscher).
sind insbesondere die Institute Antriebstechnik (AT), Aerodynamik und Strömungs-
technik (AS), Systemarchitekturen in der Luftfahrt (SL), Werkstoff-Forschung (WF), • Intelligente Softwaresysteme (IVS): Mit der Technischen Universität Dresden,
Raumflugbetrieb und Astronautentraining (RB), Flughafenwesen und Luftverkehr Lehrstuhl Ingenieurpsychologie und angewandte Kognitionsforschung (Prof.
(FW), Raumfahrtantriebe (RA) sowie das Earth Observation Center (EOC). Sebastian Pannasch), haben wir eine erste Kooperation begonnen, in der wir
Eye-Tracking-basierte Methoden für Usability-Studien mit Virtual-Reality-Brillen
• Parallele Numerik (HPC): Innerhalb des DLR gibt es gemeinsame Arbeiten mit entwickeln und einsetzen wollen.
verschiedenen Instituten, insbesondere der Antriebstechnik (AT), Aerodynamik und
Strömungsmechanik (AS), Flugsystemtechnik (FT) sowie der Materialphysik im • Software Engineering (IVS): Für das DLR entwickeln und evaluieren wir Software-
Weltraum (MP). Engineering-Werkzeuge. Wichtige Partner dabei sind vor allem kleine, innovative
Unternehmen. Im Bereich der Forschung kooperieren wir mit der TU Ilmenau
• Modellierung und Simulation (SRV): Das Institut für Raumfahrtsysteme betreibt (Prof. Patrick Mäder) zum Thema „Sichere Softwaretechnik“, wo wir Methoden
eine „Concurrent Engineering Facility“ (CEF) für Konzeptstudien und den frühen des maschinellen Lernens und der Provenance-Analyse von Softwareentwicklungs-
Entwurf von Raumfahrtsystemen. Mit der Software „Virtueller Satellit“ haben wir prozessen nutzen, um sichere und robuste Software zu entwickeln. Außerdem
die Softwareausstattung der CEF modernisiert. Darüber hinaus spielen unsere kooperieren wir mit der FAU Erlangen-Nürnberg und der TU Berlin (jew. Prof. Dirk
MBSE-Ansätze auch in den späteren Entwicklungsphasen eine Rolle, sodass ein Riehle) in den Bereichen „Open Source“ und „Inner Source“.
enger Austausch mit anderen Abteilungen des Bremer Instituts stattfindet. Für die
Entwicklung von Plattformen für die Raumfahrt existiert eine intensive Zusammen- • Intelligente Algorithmen und Optimierung (HPC): Unsere wichtigsten Partner
arbeit mit dem Institut für Datenwissenschaften in Jena. im Bereich High-Performance-Data-Analytics sind das Karlsruher Institut für Tech-
nologie (KIT) und das Jülich Supercomputing Centre (JSC). Im Bereich Designopti-
• Onboard Software Systems (SRV): Das Berliner Institut für Optische Sensor- mierung von Flugzeugen arbeiten wir eng mit Airbus Deutschland und mit RISC
systeme und das Institut für Raumfahrtsysteme sind unsere wichtigsten Partner Software zusammen. Im Quantencomputing haben wir Kooperationen mit NASA
bei der Entwicklung von Lageregelungssoftware für Satelliten. In den vergange- Ames, dem Forschungszentrum Jülich (Prof. Michielsen) und der Universität des
nen Jahren haben wir die Kooperation um die Themen „verteilte Onboard- Saarlandes (Prof. Wilhelm-Mauch), mit denen wir Studenten und Doktoranden
Computersysteme“ und „autonome optische Navigation“ erweitert. Daher gibt gemeinsam betreuen. Wie in der Designoptimierung arbeiten wir auch im Quanten-
es auch enge Beziehungen zum Institut für Robotik und Mechatronik in Ober- computing mit Airbus Defence and Space zusammen. Mit der Universität zu Köln
pfaffenhofen. (Prof. Klawonn) veranstaltet unsere Abteilung HPC gemeinsam ein Seminar zu
numerischen Methoden.
• Wissenschaftliche Visualisierung (SRV): Es besteht eine langjährige Zusammen-
arbeit mit dem Institut für Planetenforschung in der interaktiven 3D-Visualisierung • Parallele Numerik (HPC): Über die Entwicklungsbeiträge von SC zu den Codes
von Planetenoberflächen. Die Ergebnisse werden nun auch verstärkten beim CODA (Cooperation of Onera, DLR and Airbus) und FlowSimulator bestehen Ko-
Erdbeobachtungscenter (EOC) in Oberpfaffenhofen eingesetzt. Zeitabhängige operationen mit der MTU, Siemens Power Generation, Airbus Deutschland und
Volumendaten lassen sich ebenfalls interaktiv darstellen. Hervorzuheben sind hier T-Systems SfR. Wir arbeiten im Bereich Performance-Engineering mit der Professur
Kooperationen mit dem Institut für Antriebstechnik und dem Institut für Physik für Höchstleistungsrechnen der Universität Erlangen-Nürnberg zusammen
der Atmosphäre. Technische Visualisierungen werden mit dem Institut der Fahr- (Prof. Wellein). Bei der Entwicklung von parallelen numerischen Algorithmen gibt
12 13
es eine langjährige Kollaboration mit Dr. Wubs von der Universität zu Groningen
(Niederlande). Mit der Gruppe von Prof. Klawonn (Universität zu Köln) gibt es
Forschungsergebnisse und Planungen
einen regelmäßigen Austausch von Ideen in Form eines gemeinsamen Seminars.
Mit all diesen Gruppen betreuen wir gemeinsam Studenten und Doktoranden. Ein
wichtiger Kooperationspartner im europäischen Projekt VESTEC (Visual Exploration
and Sampling Toolkit for Extreme Computing) ist das EPCC (Edinburgh Parallel
Computing Centre) der Universität Edinburgh.
• Modellierung und Simulation (SRV): Unser wichtigster Partner bei der Weiter-
entwicklung von Software für das Concurrent Engineering und Wissensmanage-
ment ist ESA ESTEC (Massimo Bandecchi). Beim Thema der formalen und modell-
basierten Ansätze kooperieren wir eng mit ESA ESTEC (Joachim Fuchs), TU
Chemnitz (Prof. Matthias Werner), RWTH Aachen (Prof. Noll) sowie Airbus (Harald
Eisenmann). Weitere Kontakte bestehen zu JPL/NASA, zur JAXA und zu chinesischen
Universitäten und Forschungseinrichtungen. Dieser Hauptteil des Statusberichts gibt einen Überblick über unsere wissenschaftliche
Arbeit. Zur besseren Übersicht gehen wir dabei nach den Themen der Arbeitsgruppen vor,
• Onboard Software Systems (SRV): Im Verbundprojekt MAIUS nutzen wir die nicht nach den zahlreichen Einzelprojekten.
Kooperation insbesondere mit der Leibniz-Universität Hannover (Prof. Ernst Rasel)
und dem Zentrum für angewandte Raumfahrttechnik und Mikrogravitation Wir charakterisieren jeweils kurz das Thema, fassen den Stand der Technik zusammen und
(ZARM) dazu, modellgetriebene Ansätze für spätere Projektphasen zu entwickeln beschreiben dann die Projektarbeiten und Ergebnisse, die wir im Berichtszeitraum erzielt
und zu evaluieren. haben. Den Abschluss bildet jeweils ein Ausblick auf zukünftige Entwicklungen.
• Wissenschaftliche Visualisierung (SRV): Mit der TU Kaiserslautern (Prof. Hans
Hagen) verbindet uns eine langjährige Kooperation in der Doktorandenausbildung.
Ein enger Austausch in der geometrischen Datenverarbeitung findet mit der
University Maryland (Prof. Leila de Floriani) statt. Im EU-Projekt VESTEC arbeiten
wir mit der Sorbonne Université / CNRS, Paris (Dr. Julien Tierny), sowie mit den
Firmen INTEL und Kitware zusammen um hoch effiziente Topologieextraktions-
und Visualisierungsmethoden zu entwickeln.
• 3D-Interaktion (SRV): Ein Kooperationsabkommen mit der RWTH Aachen (Prof.
Thorsten Kuhlen) regelt die Zusammenarbeit bei der Weiterentwicklung der ViSTA-
Software für Anwendungen der virtuellen Realität (VR). Ein regelmäßiger Aus-
tausch findet auch mit der Bauhaus-Universität Weimar (Prof. Dr. Bernd Fröhlich)
statt. Über die Gesellschaft für Informatik, Fachgruppe AR/VR besteht ein enges
Netzwerk mit den führenden deutschen VR- und AR-Experten. Regelmäßige Stu-
dentenprojekte finden auch mit der Hochschule Ostfalia (Prof. Dr. Reinhard
Gerndt), der Hochschule Hannover (Prof. Dr. Volker Ahlers) und der Hochschule
Bielefeld (Prof. Dr. Kerstin Müller) statt.
14 15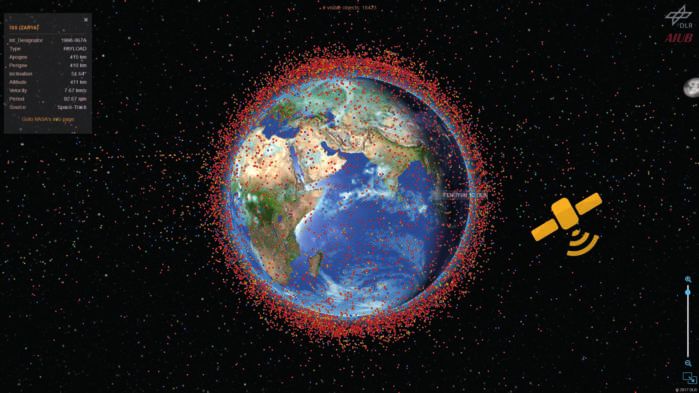
Verteilte Softwaresysteme ten Experten gelöst werden. Technische Herausforderungen bestehen in der technischen
Verknüpfung der disziplinspezifischen Programme:
• Programme sind heterogen (bzgl. Programmiersprache, Betriebssystem, etc.).
• Programme laufen auf verschiedenen Computern.
• Programme sind an bestimmte Standorte gebunden.
• Programme sind dynamisch (neue Version, neues Programm, Programm nur tem-
porär verfügbar).
• Daten müssen verteilt, ausgetauscht und dem Nutzer zur Auswertung bereitge-
stellt werden.
Ein Schwerpunkt unserer Arbeit ist seit über 20 Jahren, Softwaresysteme zur multi-diszipli
nären Kopplung mehrerer Fachdisziplinen zu entwickeln, um in verteilten Rechnernetzen Die technischen Herausforderungen können manuell gelöst werden, indem Daten z.B. per
Simulationen, Systementwürfe, Systembewertungen und System-Monitoring reproduzier- E-Mail oder Fileserver ausgetauscht werden. Dieser manuelle Ansatz ist fehleranfällig, zeit-
bar durchzuführen. aufwändig und für Dritte schwer nachvollziehbar.
Ein weiterer langjähriger Arbeitsschwerpunkt ist es, Prozesse in verteilten Systemen nachzu- Eine Alternative hierzu bilden Integrationsumgebungen, mithilfe derer die Programme
vollziehen und zu verstehen. Insbesondere forscht die Abteilung auf dem Gebiet Data-Pro- verschiedener Disziplinen eingebunden, miteinander verknüpft und in Abhängigkeit von-
venance, um lückenlos das Entstehen von Daten analysieren zu können und Data-Science- einander ausgeführt werden können.
Prozesse zu verstehen. Die Abteilung entwickelt Software, um Provenance-Informationen
effizient in Graphdatenbanken zu speichern, manipulations- und beweissicher in Block-
chains abzulegen oder anwendungsbezogen zu analysieren und zu visualisieren. Die verteilte Integrationsumgebung RCE
Im BMBF-Projekt SESIS haben wir 2006 begonnen, die verteilte Integrationsumgebung RCE
Software für multidisziplinäre Zusammenarbeit (Remote Component Environment) zu entwickeln und für den frühen Entwurf von Schiffen
einzusetzen. Bei der Entwicklung haben wir sowohl die Anforderungen aus dem Schiffbau
Wichtige Anforderungen von Fluggesellschaften an neue Flugzeuge sind geringe Betriebskos- als auch unsere Erfahrungen mit Integrationsumgebungen im Flugzeug- und Automobilbau
ten, lange Lebensdauer und Umweltfreundlichkeit. Um diesen Anforderungen gerecht zu berücksichtigt. Mittlerweile wird RCE in vielen weiteren Anwendungsgebieten eingesetzt.
werden, ist ein Ziel des DLR, neue Flugzeugkonfigurationen wie zum Beispiel Schulter-decker Diese erstrecken sich vom Vorentwurf von Flugzeugen und der Auslegung von Raumfahr-
flugzeuge oder welche mit einem Blended-Wing-Body am Computer zu entwerfen, zu analy- zeugkomponenten, über den Einsatz in der Modellierung zukunftsfähiger Verkehrssysteme,
sieren und zu bewerten. Ein Flugzeug zu entwerfen erfordert Experten aus ver-schiedenen bis hin zu der Simulation von Windenergieanlagen und der automatischen Generierung von
Disziplinen wie Aerodynamik, Strukturmechanik oder Antriebstechnik (Abb. 2). Hierzu entwi- Schaufelgeometrien für Niederdruckturbinen. Zusammen mit Partnern entwickeln wir RCE in
ckeln die Experten Entwurfs- und Analysewerkzeuge, die jeweils auf einen Teilaspekt des Ent- Forschungsprojekten weiter. In diesen Projekten wird RCE zumeist als Integrationsumgebung
wurfs spezialisiert sind. Für einen integrierten Gesamtentwurf müssen diese Werkzeuge ver- für den Gesamtentwurf eingesetzt und anforderungsgetrieben erweitert.
Abb. 2: Experten von verschiedenen Disziplinen wie knüpft werden.
Aerodynamik, Strukturmechanik oder Antriebstech- In unserer verteilten Integrationsumgebung RCE werden Programme eingebunden und
nik entwerfen im Rahmen eines Design Camps ein
Flugzeug. Das weltweite Verkehrsnetz aus Autos, Zügen, Schiffen und Flugzeugen wird immer dichter. mittels der grafischen Oberfläche zu sogenannten Workflows verknüpft (Abb. 3). Startet der
Ursachen, Wirkungen und Wechselwirkungen werden im DLR erforscht. Das Ziel ist, vorher- Nutzer einen Workflow, führt RCE gemäß der Workflow-Definition die Programme aus und
zusagen, wie sich der Verkehr entwickeln wird. Dafür verknüpfen Geographen, Ökonomen übermittelt die Daten zwischen den Programmen.
und Physiker ihre Einzelmodelle zu einem Gesamtmodell, welches das weltweite Verkehrs-
system simulieren soll. Die Beispiele zeigen: Multidisziplinäre Zusammenarbeit ist in der For-
schung und Entwicklung von enormer Bedeutung.
Einzelmodelle aus der Verkehrsforschung sind aus softwaretechnischer Sicht identisch mit Ent-
wurfs- und Analysewerkzeugen aus der Luftfahrtforschung. Es sind Computer-programme, die
Eingabedaten erwarten, etwas berechnen und Ausgabedaten erzeugen. Nachfolgend werden
sowohl die Einzelmodelle als auch die Entwurfs- und Analyse-werkzeuge als Programme be-
zeichnet.
Der integrierte Gesamtentwurf zeichnet sich durch die Zusammenarbeit von Experten ver-
schiedener Disziplinen aus. Im Rahmen solcher Kollaborationen ergeben sich menschliche,
fachliche, sowie technische Herausforderungen.
Menschliche Herausforderungen bestehen u.a. in dem Spannungsfeld zwischen disziplin- Abb. 3: Die grafische Nutzeroberfläche von RCE mit
spezifischen Zielen einerseits und den übergeordneten, interdisziplinären Zielen andererseits dem Workflow-Editor. Die Quadrate sind die Pro-
gramme, die Linien dazwischen definieren den
und müssen auf Organisationsebene gelöst werden. Fachliche Herausforderungen bestehen Datenaustausch. Sie repräsentieren die Abhängig-
u.a. in den fachlichen Abhängigkeiten zwischen Disziplinen und müssen von den beteilig- keiten zwischen den Programmen.
16 17
Abb. 4: Programme können in RCE für ver-
schiedene Benutzergruppen freigegeben werden. Angewandtes Software-Engineering
RCE ist für eine wachsende Zahl von Anwendern ein integrales Werkzeug für ihre wissen-
schaftliche Arbeit. Entsprechend hat die Qualität und Zuverlässigkeit der Software einen
hohen Stellenwert. Um diesem Anspruch gerecht zu werden, wenden wir in RCE zahlreiche
Methoden des Software Engineerings an. Die Grundlagen der Entwicklungsarbeit sind hier-
bei etablierte Praktiken wie Quellcode-Versionsverwaltung, Issue-Tracking oder Continuous
Integration.
Des Weiteren setzen wir verschiedene Software-Testverfahren ein. Die kleinste Einheit bilden
hierbei automatisierte Unit- und Integrationstests, die eng definierte Softwarebereiche
sowohl einzeln als auch in Kombination überprüfen. Um das Gesamtverhalten einer kom-
plexen Software wie RCE zu validieren, sind diese Tests allerdings nicht ausreichend. Für
diese Validierung haben wir eine domänenspezifische Sprache auf Basis des Behavior-Driven-
Im multidisziplinären Entwurf befinden sich die einzelnen Programme oft an verschiedenen Development-Ansatzes entwickelt. Mit dieser beschreiben wir das erwartete Verhalten von
Standorten. Um einen Workflow auch in diesem Szenario auszuführen, können sich Instan- RCE in einem leicht verständlichen Textformat. Die Sprache ist gleichzeitig so strukturiert,
zen von RCE untereinander zu einem dynamischen Netzwerk verbinden. RCE bietet zwei dass sie exakt und automatisiert getestet werden kann. Somit definieren wir das erwartete
Typen von Verbindungen an: Innerhalb von internen Netzwerken können unverschlüsselte Verhalten auf einem hohen Abstraktionsgrad und unabhängig von der technischen Testaus-
Verbindungen genutzt werden, um Programme anderen Instanzen zur Verfügung zu stellen führung.
und Rechenressourcen gemeinsam zu nutzen. Hierbei kann durch Berechtigungsgruppen
festgelegt werden, welche RCE-Instanzen ein bestimmtes Programm nutzen dürfen Ergänzend führen wir vor der finalen Freigabe von Software-Releases strukturierte manuelle
(Abb. 4). Testphasen durch. Insbesondere überprüfen wir hiermit Aspekte, die sich nicht mit angemes-
senem Aufwand automatisieren lassen. Dies umfasst die korrekte Funktionalität der grafischen
Diese Verbindungen sind robust gegen temporäre Netzwerkausfälle. Das heißt, der Work- Benutzeroberfläche auf verschiedenen Betriebssystemen, Usability-Aspekte, Konsistenz der
flow wartet ab, bis das entsprechende Programm wieder erreichbar ist und läuft dann auto- Dokumentation sowie die Kompatibilität mit externer eingebundener Software. Wir planen,
matisch weiter. Für die Kommunikation zwischen verschiedenen Organisationsnetzwerken steuern und dokumentieren diese Phasen mit einer webbasierten Testmanagement-Software.
bietet RCE verschlüsselte Verbindungen über SSH an, über die einzelne Programme oder
auch Workflows von anderen Organisationen aus genutzt werden können. Um eine verteilte Anwendung wie RCE sinnvoll zu testen, muss ein Netzwerk von Instanzen in
der jeweiligen Softwareversion zur Verfügung stehen. Die Installation, Konfiguration und Aus-
Nach der Ausführung eines Workflows müssen die Ergebnisdaten wissenschaftlich ausge- führung dieser Instanzen haben wir ebenfalls automatisiert, um den Testprozess effizienter zu
wertet werden. RCE unterstützt diese Auswertungen durch ein verteiltes Datenmanagement gestalten. Eine in den letzten Jahren neu aufgekommene Technologie ist die Containerisierung
für Ergebnisdaten (Abb. 5). Die Ergebnisdaten sowie der Fortschritt laufender Workflows von Software. Hierbei wird Software in standardisierten und reproduzierbaren Laufzeitumge-
können an allen Standorten eingesehen werden. bungen ausgeführt. Dies nutzen wir auf zwei Arten: Zum einen verwenden wir solche isolier-
ten Ausführungsumgebungen als Grundlage für automatisierte Testverfahren. Zum anderen
haben wir ein containerisiertes Software-Paket aus RCE selbst erstellt. Dies bildet die Grundla-
ge für den standardisierten RCE-Einsatz in Cloud-Umgebungen.
Provenance
Provenance (dt. Provenienz) beschreibt die de-
taillierte, nachvollziehbare Historie von Dingen
Grundelemente des Provenance-
oder Daten. Im wissenschaftlichen und tech-
Datenmodells PROV:
nischen Umfeld ist mit Provenance gemeint,
das Ergebnisse so ausreichend dokumentiert • Entities sind Dinge irgendeiner Form. Bei-
sind, dass sie nachvollziehbar und reprodu- spiele sind physikalische Objekte, digitale
zierbar sind. Dies kann man z.B. durch detail- Objekte, Konzepte, etc. Konkrete Beispie-
liertes Aufzeichnen aller relevanten Arbeits- le sind Dateien, Dokumente, Webseiten,
schritte in wissenschaftlich-technischen Pro- Grafiken etc.
zessen erreichen. Idealerweise geschieht diese
Aufzeichnung automatisch und ist im Falle • Activities erzeugen oder verarbeiten Enti-
von Prozessen, die durch Softwaresysteme re- ties. Activities können einzelne Aktionen,
alisiert sind, fest in die Software integriert. Operationen oder Prozesse sein.
Allgemein haben wir Methoden und Imple-
mentierungen entwickelt, um die Provenance • Agents haben bestimmte Rollen in Bezug
auf allen Ebenen typischer Datenprozesse auf- auf die Activities und sind für sie verant-
zuzeichnen: Workflows, Algorithmen, Skripte, wortlich. Beispiele sind Menschen, eine
Abb. 5: Zugriff auf die Ergebnisdaten eines Work- Machine-Learning-Tools, Datenmanagement- Software oder Organisationen.
flows. Der Zugriff kann von verschiedenen RCE-Ins-
tanzen im Netzwerk bereits während der
systemen und dem übergeordneten Soft-
Ausführung des Workflows erfolgen. wareentwicklungsprozessen (Abb. 6).
18 19Abb. 6: Aufzeichnen von Provenance in Abb. 7: Ausschnitt eines Provenance-Graphen: Die
verteilten Data-Science-Prozessen. erfassten Daten („userdata:steps”) einer Schrittzäh- qs:user/regina@example.org
ler-App („qs:app/stepcounter”) werden visualisiert
(„method:visualize”). Das Ergebnis ist ein Diagramm
(„qs:graphic/diagram”).
prov:label Regina Struminski
wasAttributedTo
prov:type prov:Person
actedOnBehalfOf
userdata:steps qs:app/stepcounter
prov:label StepCounter
prov:label Steps database
prov:type prov:SoftwareAgent wasAttributedTo
prov:type steps
qs:device smartphone
Das Aufzeichnen aller Schritte eines Prozesses erfolgt in der Regel dadurch, dass alle wichti-
gen und notwendigen Informationen gemäß einer dafür entwickelten Datenstruktur abge- used wasAssociatedWith
legt werden. Diese Datenstruktur nennt man Provenance-Modell. Das Provenance-Modell
beschreibt die Repräsentation der Provenance-Daten eines Prozesses im Computer. Als Da- prov:time 2016-12-01T16:06:21+00:00 method:visualize
tenmodell verwenden wir die standardisierte Spezifikation PROV des W3C. PROV definiert
die drei Grundelemente Entity, Activity und Agent. Für diese Grundelemente spezifiziert
PROV zusätzlich Abhängigkeiten, Zusammenhänge, Rollen, Versionen und Revisionen, prov:startTime 2016-12-01T16:06:21+00:00
prov:endTime 2016-12-01T16:06:22+00:00
Plänen bzw. Rezepte und Zeit.
wasDerivedFrom wasGeneratedBy
Speichern von Provenance in Graph-Datenbanken und Blockchains prov:time 2016-12-01T16:06:22+00:00
prov:role displaying
qs:graphic/diagram
Provenance-Informationen sind gerichtete azyklische Graphen (Directed Acyclic Graphs;
DAGs). Daher bieten sich Graph-Datenbanken an, um Provenance-Informationen effizient zu prov:label Line chart
prov:type linechart
speichern und anschließend über Graph-Abfragesprachen zu analysieren. Wir benutzen die
Graph-Datenbank Neo4j zum Speichern und die Abfragesprache Cypher zum Analysieren.
Wir bilden dabei die Grundelemente des Provenance-Modells direkt auf Knoten und die
Abhängigkeiten auf Kanten in der Datenbank ab.
den Graphen herauszulesen. Daher haben wir daran gearbeitet, die Provenance-Graphen
Eine neue Entwicklung von uns ist, Provenance-Graphen in Blockchains zu speichern.Dadurch so zu visualisieren, dass auch Laien die Informationen verstehen können und zum Beispiel
liegen die Provenance-Graphen manipulationssicher in der dezentralen, kryptographisch gesi- erkennen können, wer Zugriff auf Ihre persönlichen Daten hatte. Wir visualisieren dazu die
cherten Blockchain-Datenbank vor. Dies bietet Vorteile, wenn die Provenance-Daten bei Provenance-Graphen in Form von Comics. Jede Aktion des Provenance-Graphen bilden wir
sensiblen Anwendungen beweis- und manipulationssicher sein sollen. Zum Beispiel, um die auf einen einzelnen Comic Strip ab. Die beteiligten Personen, Organisationen, Geräte,
Compliance von Prozessen gegenüber einem Referenzprozess sicher nachzuweisen, oder um Speicherquellen und Daten bilden wir durch Piktogramme in den einzelnen Bildchen der
die Integrität von Daten sicher zu stellen. Als Blockchain haben wir in unserer ersten Imple- Comic Strips ab. Durch eine Studie konnten wir zeigen, dass unsere Comics durch eine zu-
mentierung die blockchainartige Datenbank BigchainDB verwendet. Dabei bilden wir die fällig zusammengestellte Gruppe von Laien sehr gut zu verstehen sind.
Entities und Activities auf Transaktionen sowie Agents auf die Owner einer Transaktion in der
Blockchain ab. Wir erzeugen die Comics automatisch aus den Provenance-Graphen. Dazu haben wir das
Tool „PROV Comics” in Javascript entwickelt, um aus einem Provenance-Graphen die ein-
zelnen Grafiken der Comics zu generieren und anschließend den gesamten Comic daraus
Anwendungsbeispiel: Visualisieren der Provenance von Gesundheitsdaten als zusammen zu setzen. Nutzer können den Provenance-Graphen dabei entweder als Datei im
Comics Format PROV-N hochladen oder direkt aus einer (entfernten) Provenance-Datenbank
(„ProvStore“) auswählen. Unser Tool PROV Comics läuft entweder lokal im Web-Browser
Ein aktuelles Anwendungsgebiet ist, die Provenance von Prozessen mit Gesundheitsdaten oder als Cloud-Anwendung. Für letzteres haben wir einen Service für die AWS Cloud ent-
nachzuvollziehen. Ziel ist zu verstehen, wo Daten der personenzentrierten Medizin und der
Selbstvermessung erfasst, gespeichert und ausgewertet werden. Menschen sammeln solche
Daten mit medizinischen Geräten, Wearable Devices oder dem Smartphone. Sie speichern
die Daten in Apps, auf lokalen Rechnern oder in der Cloud (zum Beispiel beim Hersteller der
Geräte). Die Herausforderung besteht darin herauszufinden, welche Akteure Zugriff auf die
Daten haben und wo ggf. die Privatsphäre verletzt wird.
Wir haben ein Provenance-Modell erstellt, welches erlaubt, die Provenance-Informationen
aller Arten personenbezogener Sensorik sowie der nachfolgenden Datenprozesse zu erfas-
sen und als Provenance-Graph zu speichern (Abb. 7).
Abb. 8: Beispiel eines Provenance Comics: Der erste Strip
des Comics zeigt, wie Daten zwischen einer App auf dem
Personen mit entsprechender Fachkenntnis fällt es leicht, anhand von Provenance-Graphen persönlichen Smartphone und dem Hersteller der App
nachzuvollziehen, wie Daten entstanden sind, und wer ggf. Zugriff darauf hatte. Dagegen synchronisiert werden. Der zweite Strip zeigt, wie die Nut-
zerin die Daten auf ihrem Smartphone visualisiert.
ist es für Laien, die keine Kenntnis in IT haben, äußerst schwer, diese Informationen aus
20 21Abb. 11: Komponenten des BACARDI-Systems und
Abb. 9: Architektur-Diagramm eines Serverless-Cloud-
ihre Abhängigkeiten.
Dienstes zum Generieren von Provenance Comics.
tektur wartbar und flexibel ausgelegt, um eine langfristige Laufzeit zu gewährleisten. Dies
wickelt, der als Serverless-Anwendung läuft. Unser Service nutzt AWS Lambda, welches un- erreichen wir durch lose Kopplung der Softwarekomponenten über klar definierte
seren PROV Comics Code ausführt, sobald ein Nutzer über einen API-Aufruf das Generieren Schnittstellen (Abb. 11). Dadurch erreichen wir, dass wir ganze Systembestandteile, bei-
eines Comics anfragt (Abb. 9). spielsweise die Prozess-Scheduling-Bibliothek „Airflow“, ersetzen können, ohne die BAR-
CARDI-Kernfunktionalität zu beeinträchtigen.
BACARDI – Ein Datenbank-System für die Analyse von Eine weitere wesentliche Arbeit von uns ist, einen effizienten Entwicklungsprozess zu konzi-
Raumfahrtrückständen pieren und umzusetzen. Wir verwenden aktuelle agile Entwicklungsmodelle, Softwareent-
wurfsmethoden, und Softwaretestkonzepte. Um einen ausfallsicheren Betrieb der Software
Die Anzahl der Raumfahrtrückstände in erdnahen Orbits ist hoch und steigt kontinuierlich im produktiven Einsatz zu gewährleisten, unterstützen wir zudem unsere Partner bei der
weiter. Aktuelle Schätzungen gehen von circa 700.000 Objekten größer als 1cm aus. Umsetzung und Inbetriebnahme.
25.000 dieser Objekte werden auf eine Größe zwischen 5cm und 10cm geschätzt. Selbst
kleinste Raumfahrtrückstände gefährden Raumfahrzeuge, Satelliten und damit auch Welt-
raum-Missionen.
Um Kollisionen vorherzusagen und Gegenmaßnahmen einleiten zu können, müssen Raum-
fahrtrückstände erfasst und deren Bahnen kontinuierlich beobachtet und verbessert wer-
den. Eine wichtige Voraussetzung für den Missionsbetrieb ist es daher, Bahndaten effizient
in Datenbanken zu verwalten und aktuelle Bahnen und Kollisionsvorhersagen schnell zu be-
rechnen.
Zusammen mit der DLR-Einrichtung Raumflugbetrieb und Astronautentraining und der Ab-
teilung High-Performance Computing entwickeln wir den „Backend Catalog for Relational
Debris Information“ (BACARDI). Wesentliche Ziele von BACARDI sind, die Berechnung hoch-
genauer und aktueller Bahnen, das Erkennen von Manövern und die Generierung von
Kollisionswarnungen vollautomatisch umzusetzen (Abb. 10).
Wir stellen das Software-Rahmenwerk zur Verfügung, um vorhandene Ressourcen so effi-
zient wie möglich für die Auswertungsprozesse und Algorithmen zu nutzen. Dazu setzen
wir auf moderne Technologien, um eine performante sowie skalierbare Architektur bereit-
zustellen, welche Berechnungen auf verteilten Systemen ermöglicht. Wir haben die Archi-
Abb. 10: Beispiel eines Workflows, der neue „Track-
lets“ bestehenden Orbits zuordnet.
22 23Intelligente Softwaresysteme Im Projekt LIME (Literature and Information Management Environment) nutzt das Institut für
Materialphysik im Weltraum KnowledgeFinder, um auf ihre kollaborativ erstellte Publikati-
onsdatenbank zuzugreifen (Abb. 12). Publikationen können nach Themenbereichen, Alter
oder Bewertung gefiltert werden. Eine Volltextsuche ermöglicht das Auffinden von spezifi-
schen Fakten. Ungewöhnlich ist die Visualisierung der Publikationen nach Themenbereichen.
Dies erlaubt Nutzern schnell einen Überblick zu erhalten, zu welchen Themen Publikationen
vorhanden sind und somit, welche Themen besonders aktiv bearbeitet werden. Auch Zu-
sammenhänge zwischen Themenbereichen lassen sich direkt erkennen.
Benutzerschnittstellen mit hoher Usability
Openvocs
Im Bereich der intelligenten Systeme arbeitet die Abteilung daran, Methoden des maschi-
nellen Lernens weiter zu entwickeln und damit interaktive Softwaresysteme zu entwickeln Sprachkommunikationssysteme sind wichtige Hilfsmittel in Raumfahrtkontrollzentren. Sie
und zu verbessern. Beispiele sind interaktive Benutzerschnittstellen mit hoher Usability, in- werden flächendeckend eingesetzt, um Raumfahrtmissionen zu koordinieren. Aktuelle
telligente Sprachassistenten für Visualisierungen oder visuelle Explorationswerkzeuge für Systeme sind kommerzielle, proprietäre und hoch spezialisierte Komplettsysteme, die
Graphen (Knowledge Graphen im Wissensmanagement, Provenance-Graphen, Abhängig- schwierig anzupassen und zu erweitern sind.
keitsgraphen von Softwaresystemen, Graphen verteilter Netzwerke etc.).
Gemeinsam mit dem German Space Operations Center (GSOC) entwickeln wir das Sprach-
kommunikationssystem „openvocs“ als Open-Source-Software. Openvocs basiert auf offe-
Wissensmanagement mit KnowledgeFinder nen Protokollen und Technologien, wie WebRTC, WebSockets und JSON. Als Hardware
verwendet openvocs handelsübliche Computer und Mobilgeräte (Smartphones, Tablets).
Wissensmanagement in Projekten bedeutet, vorhandenes Wissen – also Informationen, Unsere Aufgabe ist, die Benutzerschnittstellen von openvocs zu entwickeln: Abb. 13: Voice-Clients von openvocs für Mobilgeräte.
Daten und Fähigkeiten zu organisieren und zugreifbar zu machen. Zu den Aufgaben des
Wissensmanagements gehört, Dokumente abzulegen und zu suchen sowie Informationen • Web-basierte Interfaces für den Voice-Client an den Operator-Arbeitsplätzen und
und Wissen effizient zwischen den Projektbeteiligten auszutauschen. Wissensportale dienen zum Administrieren der Berechtigungen und Sprachkanäle.
dabei als zentrale Plattform im Wissensmanagement und können als eine Art Wegweiser
durch die Informationen eines Unternehmens angesehen werden. • Voice-Clients für Mobilgeräte mit dem Betriebssystem Android.
Stand der Technik ist, vorhandene und neu entstehende Dokumente semantisch zu beschrei- Das Gesamtkonzept unserer Voice-Client-Interfaces ähnelt dem der aktuellen Systeme im
ben, in einem Datenmanagementsystem abzulegen und durchsuchbar zu machen. Wir ent- GSOC, um den Operateuren den Übergang zu erleichtern. Die Bedienkonzepte haben wir
wickeln hierfür die Software KnowledgeFinder. KnowledgeFinder „crawlt“ Daten aus ver- umgestaltet, um die Benutzerfreundlichkeit zu erhöhen. Besonders wichtig war uns, gäng-
schiedenen Quellen, legt diese in einem spezifizierten Datenmodel ab und ermöglicht dem ige und von den Nutzern erwartete Bedienkonzepte für die jeweilige Zielplattform zu
Nutzer, die Daten zu filtern, zu visualisieren und zu durchsuchen. Je nach Anwendungsfall verwenden (Abb. 13).
passen wir diese Aspekte an und erzeugen dadurch spezielle Wissensportale.
Openvocs besitzt rollenbasierte Zugriffsrechte. Um den Administratoren die Übersicht zu
erleichtern, haben wir eine visuelle Darstellung der Zugriffsrechte als mehrschichtigen Gra-
phen gewählt. Wir bilden Benutzer auf Rollen und Rollen auf Sprachkanäle (Voice Loops)
ab (Abb. 14).
Maschinelles Lernen
Maschinelles Lernen wird mittlerweile in nahezu allen Bereichen angewendet, da es sich - im
Gegensatz zu konventionellen Methoden der Mathematik - um das Lernen aus Daten han-
delt. Je nach Anwendungsbereich unterscheiden sich die Methoden und Algorithmen. Der-
zeit arbeiten wir daran, das Potenzial von maschinellen Lernverfahren im Bereich der natürli-
chen Sprachverarbeitung anzuwenden. Außerdem haben wir damit begonnen, neuronale
Netze zu visualisieren, um ihren Aufbau besser zu verstehen und sie erklärbar zu machen.
Abb. 14: Administrations-Interface von openvocs für
Abb. 12: Frontend von LIME in KnowledgeFinder. das Web.
24 25Abb. 16: Visualisieren von neuronalen Netzen in 3D:
Natural Language Processing (NLP) Die Schichten eines Deep-Learning-Netzes und ihre
Neuronen.
Natural Language Processing (NLP) ist ein weites Feld, das sich mit den Methoden und Tech-
niken zur Verarbeitung natürlicher Sprachen in Form von Sprach- oder Textdaten beschäftigt
Algorithmen des maschinellen Lernens, die auf Text-Mining-Techniken angewendet werden,
sind hilfreich, um semantisch sinnvolle Informationen zu extrahieren.
Der KnowledgeFinder ermöglicht es den Anwendern, Datensätze anhand ihrer Metadaten
zu finden und zu visualisieren. Für Datensätze ohne Metadaten-Informationen verwenden
wir Text Mining und maschinelles Lernen, um die Dokumente nach semantischer Ähnlichkeit
zu gruppieren. Eine dieser Methoden ist, signifikante Schlüsselwörter aus den Dokumenten
zu extrahieren und entsprechend ihrer semantischen Nähe zu gruppieren. Dazu werden
Wortketten in einen Vektorraum überführt (sog. Word Embeddings) und mit Clustering-
Algorithmen gruppiert.
Ein interessantes Forschungsgebiet, das NLP und Künstliche Intelligenz gemeinsam haben,
ist das Natural Language Understandig (NLU), indem Systeme natürliche Sprache nicht nur
verarbeiten, sondern auch semantisch verstehen. NLU hat wichtige Anwendungen in intelli- Software Visualisierung
genten Konversationssystemen. Long Short-Term Memory (LSTM) Netzwerke, eine Variante
von rekurrenten neuronalen Netzen, sind in der Lage, die Langzeithistorie der Daten zu be- Die Architektur einer Software ist nicht direkt sichtbar. Jedoch ist es in vielen Fällen wün-
wahren. schenswert, die Architektur der Software sehen zu können oder erfahrbar zu machen,
zum Beispiel, wenn die Entwickler die Architektur gegen das ursprüngliche entworfene
Wir arbeiten gerade daran, Texte mit maschinellem Lernen zu generieren. Dazu entwickeln Softwaredesign vergleichen wollen oder wenn die Architektur neuen Teammitgliedern
wir eine kontextbasierte Generierung mit LSTMs, bei der wir ein Textgenerierungsmodell auf oder außenstehenden Personen näher gebracht werden soll. Die grundlegenden Aspekte
Grundlage existierender Kontext-Wortvektoren trainieren. Dieses trainierte Modell ist dann der Software-Architektur sind die Module bzw. Komponenten, aus denen sie besteht, und
in der Lage, neuen Text zu erzeugen. Wir verwenden diese Methode zum Beispiel, um lange die Abhängigkeiten zwischen diesen Modulen. Aus diesem Grund arbeiten wir daran,
Texte zu kürzeren Texten zusammen zu fassen (Text Summarization; (Abb. 15)). Software-Komponenten und deren Abhängigkeiten zu visualisieren. Wir konzentrieren uns
darauf, die Architektur OSGi-basierter Softwaresysteme zu visualisieren, da einige große
Softwaresysteme (RCE und VirSat) unserer Einrichtung auf OSGi basieren.
Visualisieren von neuronalen Netzen in 3D
Viele Anwendungen nutzen heutzutage Deep Learning (maschinelles Lernen mit mehr- Repository Mining von OSGi-Projekten
schichtigen neuronalen Netzen), um intelligentes Verhalten zu erhalten. Es kann jedoch sehr
schwer oder vollständig intransparent sein, wie Deep-Learning-Modelle zu ihren Ergebnissen Die Informationen über Module und Abhängigkeiten in OSGi-Projekten liegen verteilt in
und Entscheidungen kommen. Wir arbeiten daher daran, mehrschichtige neuronale Netze diversen Daten im Software-Repository vor. Wir extrahieren daher mit Methoden des Reposi-
zu visualisieren, um die internen Abläufe offen zu legen und die Ergebnisse bzw. Zwischen- tory Mining zunächst alle relevanten Informationen (Abb. 17), zum Beispiel:
ergebnisse zu untersuchen.Wir haben eine Software, welche neuronale Netze, insbesondere
Convolutional Neural Networks (CNNs), in 3D und Virtual Reality visualisiert. Der derzeitige • Importierte und exportierte Pakete jedes OSGi-Bundles.
Prototyp basiert auf der Spiel-Engine Unreal Engine. Die Schichten neuronaler Netze, welche
mit der Machine-Learning-Bibliothek TensorFlow realisiert wurden, lassen sich automatisch in • Service-Komponenten und bereitgestellte Services.
3D-Szenen darstellen. Die Schichten zeigen die Aktivitätsniveaus einzelner Neuronen, welche
automatisch aus TensorFlow heraus aktualisiert werden (Abb. 16). Abb. 17: Extrahieren von Meta-Informationen aus • Metriken über den Source Code: Anzahl der Pakete, Anzahl der Klassen, Anzahl
Software-Repositorys (dargestellt für OSGi-Projekte),
speichern in einem Datenmodell und Visualisierung.
der Code-Zeilen etc.
Attentional Als Tool zum Extrahieren der Informationen setzen wir die Open-Source-Software jQAssistant
Pre-processing stage Glove / Word2vec LSTM
RNN ein, welche wir mit eigenen Plug-ins erweitert haben. Die extrahierten Informationen spei-
chern wir in der Graph-Datenbank Neo4j (Abb. 18).
Input Processed Non-
Processed Summary with
grammatical
(Paragraphs -
Input dataset input word sentence with
grammatical
Summaries) vectors context
attention
Extract high level features Extracts history and grammatical structure
Removes unnecessary parts of the text Vactorizes the input
(attention words) for the summarization task
Abb. 15: Automatisches Zusammenfassen von Texten
mit Attentional Recurrent Neural Networks (A-RNN) Abb. 18: Ausschnitt der Graph-Daten von RCE: Ein-
und Long Short-Term Memory Networks (LSTM). zelnes OSGi-Bundles („RCE Core Login Bundle”) und
aller direkt damit verbundenen Knoten.
26 27Sie können auch lesen

















































