Technische Hochschule Ingolstadt - opus4.kobv.de
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Technische Hochschule Ingolstadt
Fakultät Informatik
Studiengang Wirtschaftsinformatik
Bachelorarbeit
Wiederverwendung von benutzerspezifischem Wissen
zur Visualisierung von Analysedaten
vorgelegt von
Ali Kahraman
Matrikel-Nr.: 00075935
Ausgegeben am: 09.11.2020
Abgegeben am: 16.01.2021
Erstprüfer: Prof. Dr. Melanie Kaiser
Zweitprüfer: Prof. Dr. Jochen Rasch
Inhaltsverzeichnis
Abkürzungsverzeichnis ............................................................................................... I
Abbildungsverzeichnis ............................................................................................... II
Tabellenverzeichnis ................................................................................................... III
Quellcodeverzeichnis ................................................................................................IV
1. Einleitung ............................................................................................................. 1
1.1 Problemstellung ............................................................................................................. 1
1.2 Gliederung und Vorgehensweise .................................................................................. 1
2. Recommender-Systeme als Ansatz zur Objektempfehlung ............................. 2
2.1 Definitionen .................................................................................................................... 2
2.2 Kollaboratives Filtern ..................................................................................................... 3
2.3 Inhaltsbasiertes Filtern .................................................................................................. 4
2.4 Wissensbasiertes Filtern ............................................................................................... 5
3. Knowledge-Assisted-Visualization ..................................................................... 7
3.1 Definition von Guidance ................................................................................................ 7
3.2 Konzeptionelles Modell von Guidance .......................................................................... 9
3.2.1 Knowledge-gap .................................................................................................... 11
3.2.2 Inputs und Outputs .............................................................................................. 12
3.2.3 Guidance-degree ................................................................................................. 13
4. User-behavior-Analytics .................................................................................... 14
4.1 Grundlagen von User-behavior-analytics .................................................................... 14
4.2 Vorbereitung für die Analyse von User behavior ......................................................... 16
4.3 Erleichterung der Visualisierung durch Verhaltensanalyse des Nutzers .................... 18
5. Ausgangssituation - Implementierung der Visualisierungskomponente ...... 19
5.1 Auswahl der Software ................................................................................................. 19
5.2 Anforderungen an das Tool ......................................................................................... 20
6. Implementierung der Visualisierungskomponente ......................................... 21
6.1 ApexCharts .................................................................................................................. 21
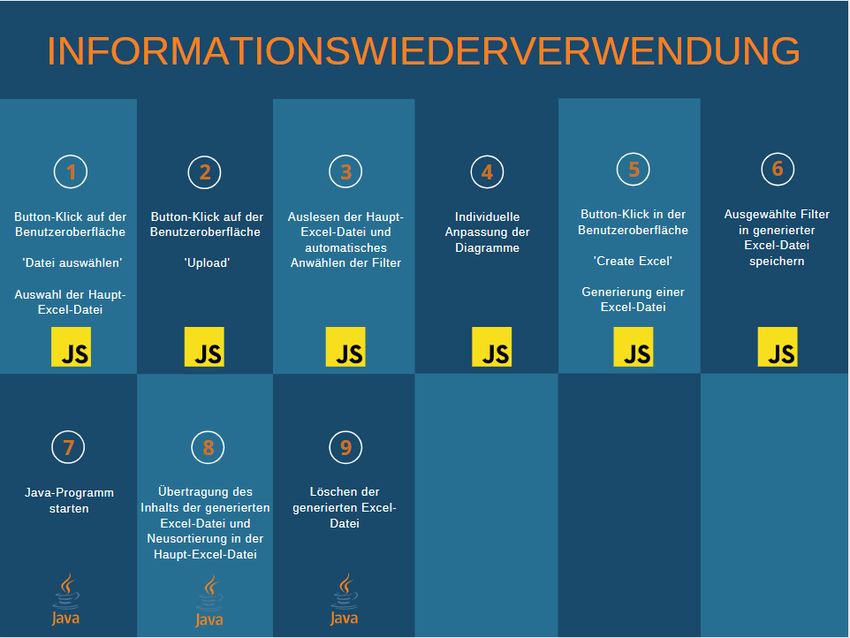
6.2 Speichern und Aufrufen von Daten ............................................................................. 25
6.3 Szenario zum Einlesen und Visualisieren von Daten.................................................. 29
7. Fazit .................................................................................................................... 31
Anhang ...................................................................................................................... 34
Literaturverzeichnis .................................................................................................. 35
Eidesstattliche Erklärung ...........................................................................................V
CD-ROM/DVD/USB-Stick ...........................................................................................VI
Abkürzungsverzeichnis RS Recommender-System
Abbildungsverzeichnis Abbildung 1: Funktionsweise von Recommendersystemen [Muno 2008, S.3] ................. 2 Abbildung 2: Die CF-Matrix der Benutzerempfehlungselement Beziehungen [Soltani 2020, S.16] .................................................................................................................................. 3 Abbildung 3: Knowledge-assisted-visualization [Chen 2009, S. 18] .................................. 7 Abbildung 4: Mixed-iniative-Process of guidance [Miksch, Leitte und Chen 2020, S.77] 9 Abbildung 5: Extended version of van Wijk’s model [Miksch, Leitte und Chen 2020, S.79] ............................................................................................................................................. 9 Abbildung 6: Aspects of guidance [Miksch, Leitte und Chen 2020, S. 78] ...................... 11 Abbildung 7: Abhängigkeiten vom System während der Visualisierung .......................... 13 Abbildung 8: Clickmap [Ryte 2020]........................................................................................ 17 Abbildung 9: Clickmap – 2 [Abbamonte 2020] ..................................................................... 17 Abbildung 10: Beispieldiagramm der Visualisierungskomponente ................................... 21 Abbildung 11: Visualisierungsfilter mit Checkboxen ........................................................... 23 Abbildung 12: Button zum Erstellen eines Diagramms ...................................................... 24 Abbildung 13: Button zum Ändern des Diagrammtyps ....................................................... 24 Abbildung 14: Prozess der Informationswiederverwendung ............................................. 26 Abbildung 15: Meldung – Keine Visualisierung durchgeführt ............................................ 27 Abbildung 16: Meldung – Kopiervorgang abgeschlossen .................................................. 28 Abbildung 17: Auswahl der Datenkategorie ......................................................................... 29 Abbildung 18: Zwei Diagramme beim Start der Anwendung ............................................. 29 Abbildung 19: Buttons zum Auswählen und Uploaden einer Excel-Datei ....................... 30 Abbildung 20: Excel-Zwischenstand vor der Visualisierung .............................................. 30 Abbildung 21: Zwei Diagramme nach Upload einer Excel-Datei ...................................... 30 Abbildung 22: Excel-Zwischenstand nach der Visualisierung ........................................... 31
Tabellenverzeichnis Tabelle 1: The conceptual goals of various recommender systems [Aggarwal 2016, S.16] ............................................................................................................................................. 6

Quellcodeverzeichnis Quellcode 1: ApexCharts-Bibliothek [ApexCharts 2020] ......................................................... 21 Quellcode 2: Chart-Objekt in der HTML-Datei ............................................................................ 21 Quellcode 3: Beispieleinstellungen für ein ApexCharts-Diagramm ............................................ 22 Quellcode 4: ToggleSeries-Funktion............................................................................................ 23 Quellcode 5: Funktion für die Änderung des Diagrammtyps ...................................................... 24 Quellcode 6: Öffnen der ausgewählten HTML-Seite................................................................... 25 Quellcode 7: Prüfen der ausgewählten Checkboxen .................................................................. 27 Quellcode 8: FileInputStream ..................................................................................................... 27 Quellcode 9: Zugreifen auf das erste Arbeitsblatt einer Excel-Datei .......................................... 28 Quellcode 10: Erstellen von Zellen in einer Excel-Datei ............................................................. 28
Einleitung
1. Einleitung
Die Wiederverwendung von Benutzerwissen spielt für die Visualisierung von Daten aus
unternehmerischer Sicht eine wichtige Rolle. Durch eine vorhandene Wissensdatenbank
erlangen Unternehmen sowie Analysten schneller Informationen über Produkte und
Untersuchungen. Besonders die Effektivität und Effizienz in den Visualisierungsprozessen und
den Ergebnissen werden enorm gesteigert. Dies ist von Vorteil, um wettbewerbskritische
Entscheidungen zu treffen.
1.1 Problemstellung
Datenvisualisierungen existieren bereits seit einigen Jahrhunderten. Dennoch lässt sich sagen,
dass der eigentliche Ursprung aus dem 18. Jahrhundert mit William Playfair stammt [vgl. Weibel
2014]. Eine Visualisierung heute jedoch beinhaltet in der Praxis die Teilnahme sowohl von
maschinellen als auch von menschlichen Komponenten, wie zum Beispiel die Mensch-Computer-
Interaktion. Die Integration dieser beiden Komponenten führt dazu, die Stärken von Menschen
und Computer für eine effektive visuelle Datenanalyse zu verknüpfen. Der Fokus liegt also auf
einer effektiven System-Benutzer-Integration, bei der das System dem Benutzer aktiv hilft, sein
Analyseziel zu erreichen. Die Unterstützung durch das System ist in diesem Zusammenhang ein
entscheidender Schritt zur Ermöglichung und Vereinfachung des Visualisierungsprozesses.
Hierfür werden Recommender-Systeme benötigt. Diese kommen dem Benutzer bei der
Entscheidungsfindung zur Hilfe, indem Visualisierungsvorschläge getroffen werden. Zu beachten
ist, dass sich der Visualisierungsprozess wiederholt und somit wiederkehrend viel Zeit in
Anspruch nimmt. Abhängig von der Datenmenge, die zu visualisieren ist, kann es ebenfalls zu
einem hohen Speicherbedarf führen, was langfristig zu umgehen ist. Daher bedarf es einer
Alternative, um aus den ständig anfallenden Datenströmen ein Modell zu entwickeln, um
letztendlich den Benutzer bei der Entscheidungsfindung zu entlasten und parallel für eine enorme
Zeitersparnis zu sorgen.
1.2 Gliederung und Vorgehensweise
Zu Beginn wird auf den Einsatz der Recommender-Systeme eingegangen werden. Diese werden
letztendlich benötigt, um Vorschläge für die Visualisierung zu erhalten. Hierbei ist es wichtig,
verschiedene Varianten sowie Vorteile unterschiedlicher Empfehlungsdienste zu kennen.
Letztendlich wird die Entscheidung auf eine Variante der Recommender-Systeme fallen, um
dieses in Zukunft weiter ausbauen zu können. Daraufhin wird der Aspekt „Knowledge-Assisted-
Visualization“ untersucht. Dieser Ansatz ist die Grundlage für die Visualisierung von Daten durch
die Unterstützung des Systems und dem Benutzerwissen. Besonders bei Datenströmen, die
einen großen Speicher in Anspruch nehmen, bedarf es einer Lösung, um dies zu umgehen. Somit
stellt dies die Grundlage der Arbeit dar, worauf folgende Abschnitte aufbauen. Anschließend
konzentriert sich die Arbeit auf die Verhaltensanalyse der Anwender. Damit eine Anwendung dem
Benutzer Unterstützung bieten kann, bedarf es der Untersuchung seines Verhaltens. Dabei ist es
wichtig, die dafür notwendigen Vorbereitungen zu treffen. Daraufhin wird auf den Aufbau der
Visualisierungskomponente eingegangen. So werden Aspekte wie die Auswahl der Software zur
Implementierung der Komponente sowie die Anforderungen an das Tool näher beschrieben. Hier
werden Soll-Funktionalitäten aufgezeigt und wie diese implementiert werden. Im letzten Kapitel
1Recommender-Systeme als Ansatz zur Objektempfehlung
dieser Arbeit erfolgt die Implementierung der Visualisierungskomponente. Diese basiert auf den
wissenschaftlichen Erkenntnissen aus den zuvor aufgeführten Kapiteln. Für die Darstellung der
Daten wird eine freie Software „Apex-Charts“ verwendet. Diese ermöglicht den Benutzern
dynamische Visualisierungen zu erstellen und nach Belieben weiter anzupassen. Zur
Veranschaulichung der Visualisierungskomponente werden anhand eines Szenarios Daten
eingelesen sowie letztendlich visuell dargestellt. Zudem wird ein Ausblick für die
Weiterentwicklung des Systems veranschaulicht.
2. Recommender-Systeme als Ansatz zur Objektempfehlung
Ein Recommender-System (RS) ist ein Softwaretool, das Vorschläge für Objekte liefert, welche
für einen bestimmten Benutzer am wahrscheinlichsten von Interesse sind. Es konzentriert sich
für gewöhnlich auf eine bestimmte Art von Objekten. Dementsprechend ist die zur Erstellung der
Empfehlungen verwendete Technik so angepasst, dass es nützliche und effektive Vorschläge für
diese bestimmte Art von Objekten liefert. Ein RS ist ein Informationsverarbeitungssystem,
welches verschiedene Arten von Daten erfasst. Diese Daten handeln hauptsächlich von den
Objekten, welche zur Empfehlung herangezogen werden und den Benutzern, die diese
Empfehlungen erhalten. Die erforderlichen Daten werden in einem sogenannten Daten-Pool
zusammengefasst (siehe Abbildung 1). Wie ein solches Daten-Pool aufgebaut ist, ist individuell
zu entscheiden. Durch die entsprechenden Daten und dem Input der Anwender entstehen
allgemeine bzw. benutzerspezifische Empfehlungen.
Abbildung 1: Funktionsweise von Recommendersystemen [Muno 2008, S.3]
2.1 Definitionen
In diesem Kontext sind die Definitionen der Begriffe „Daten“, „Information“ und „Wissen“ nicht
deutlich trennbar. Deshalb erfolgt in diesem Abschnitt eine Differenzierung dieser Begriffe.
Hierfür eignet sich das sogenannte „knowledge-Pyramid“ von Russell L. Ackoff. Demnach sind
Daten reine Symbole oder Zeichen. Sie sind eine Sammlung von Fakten in einer meist
unorganisierten Form. Einzelne Zahlen, Buchstaben oder Sonderzeichen können Daten
darstellen. Informationen bestehen aus Daten, die bearbeitet wurden, um aus ihnen einen Nutzen
zu erlangen. Sie geben Antworten auf die Fragen „wer“, „“was“, „wo“ und „wann“. Die kombinierte
2Recommender-Systeme als Ansatz zur Objektempfehlung
Anwendung von Daten und Informationen ermöglicht die Antwort auf die Frage „wie“ und wird als
Wissen bezeichnet. Diese Definitionen stellen dabei nur die groben Begriffsverständnisse dar. Im
IT-Umfeld veranschaulichen Daten computergestützte Attribute von realen Objekten.
Informationen hingegen sind Daten, welche Ergebnisse aus computergestützten Verfahren
darstellen. Ebenso ist dies für den Begriff Wissen der Fall. Hier jedoch sind es Ergebnisse eines
computer-simulierten kognitiven Prozesses. Dazu gehören Aspekte wie Wahrnehmung, Lernen,
Assoziation sowie Argumentation. [vgl. Chen 2009, S. 13] Nachdem nun das Verständnis für die
verwechselbaren Begriffe näher erläutert wurde, werden im Folgenden verschiedene Modelle von
Recommender-Systemen analysiert. Dabei ist es wichtig die Funktionsweise der einzelnen
Varianten für die Ziele der Arbeit zu kennen und anzuwenden.
2.2 Kollaboratives Filtern
Das Kollaborative Filtern ist eine sehr oft angewendete Methode bei Recommender-Systemen.
Ähnlich wie andere Methoden erfolgt die Anwendung von kollaborativem Filtern meist bei sehr
großen Datenmengen. Das Ziel hierbei ist es eine Vorhersage von Nutzerinteressen zu erhalten.
So werden über die Laufzeit Informationen über das Verhalten der Nutzer angesammelt. Die
Grundidee ist, dass Personen, welche sich bei sämtlichen Objekten ähnlich entschieden haben,
mit hoher Wahrscheinlichkeit auch andere Objekte ähnlich bewerten. Der Output hierbei ist eine
Liste von Objekten, welche einem Nutzer aufgrund seiner und von anderen Nutzern bewerteter
Objekte, vorgeschlagen wird. Dies lässt sich anhand eines Modells darstellen.
In einem Modell m mit Usern U = {u1,u2,u3,...,un} besitzt jeder User eine Liste von Objekten I,
wie es in Abbildung 2 erkennbar ist. Über diese Listen werden die Profile der User
zusammengestellt. Iui ist die Bewertung eines Objektes durch einen User Ui. Die Empfehlung
eines Objektes Ii für den User Ui resultiert aus einer Liste von Objekten, welche eine Teilmenge
von I ist. Diese Liste setzt sich aus den Bewertungen des aktiven Users sowie von anderen Usern
zusammen. Sie beinhaltet Objekte, welche am wahrscheinlichsten interessant für den aktiven
User sind. [vgl. Soltani 2020, S.15] Ziel ist es, auf Basis von sehr ähnlichen Profilen, welche zu
identifizieren sind, eine Empfehlung zu generieren. So werden aus dem Verhalten der ähnlichen
User die Empfehlungen abgeleitet.
Abbildung 2: Die CF-Matrix der Benutzerempfehlungselement Beziehungen [Soltani 2020, S.16]
3Recommender-Systeme als Ansatz zur Objektempfehlung
Weiterhin lässt sich das Kollaborative Filtern in zwei verschiedene Methoden unterteilen. Dabei
gibt es die memory-based-Methode sowie die model-based-Methode.
Memory-based-method
Speicherbasierte Methoden, auch als nachbarschaftsbasierte Verfahren bekannt, generieren
Empfehlungen auf Basis von Nachbarschaften zwischen verschiedenen Usern oder Objekten.
Das Ziel ist es also, die ähnlichsten User oder Objekte zu finden. Hierfür gibt es auch wiederrum
zwei Verfahren, welche die Ähnlichkeitsberechnung unterschiedlich durchführen.
1. User-based filtering: In diesem Fall werden Bewertungen von ähnlichen Nutzern
verwendet, um Empfehlungen für einen bestimmten Nutzer zu generieren. Der Fokus
liegt also darin, Nutzer zu ermitteln, die dem Zielnutzer am ähnlichsten sind [vgl.
Aggarwal 2016, S.31]. Wenn ein Benutzer u1 beispielsweise die Filme Titanic und
Avatar als positiv bewertet und Benutzer u2 diese ebenfalls positiv bewertet hat, wird
mit hoher Wahrscheinlichkeit u1 als nächster Film derjenige vorgeschlagen, den u2
als nächstes positiv bewertet. Ähnlichkeitsfunktionen werden zwischen den Zeilen
der Bewertungsmatrix berechnet, um ähnliche Nutzer zu entdecken.
2. Item-based filtering: Hier werden direkt Objekte miteinander verglichen. So wird
Benutzer u1 das Objekt vorgeschlagen, welcher ähnlich zu den bereits positiv
bewerteten Objekten sind. Somit ist für u1 der Horrorfilm ‘I3‘ die Top-Empfehlung, da
dieser ähnlich zu den bereits von u1 als gut empfundenen Horrorfilmen ‘I1‘ und ‘I2‘
ist. Hier werden die Ähnlichkeitsfunktionen zwischen den Spalten der
Bewertungsmatrix berechnet, um ähnliche Elemente zu entdecken.
Model-based-method
Beim modellbasierten Verfahren wird mithilfe von Techniken wie dem stochastischen Verfahren,
der Clusteranalyse, den Neuronalen Netzen und eines Trainingsdatensatzes ein Modell
angelernt. „Dieser speicher- und rechenintensive Schritt erfolgt separat vorab, und nicht erst in
dem Moment, in dem die Empfehlungen für den aktiven Nutzer präsentiert werden sollen
[Kollmann 2020, S.726].“ Dies wird als die erste Phase der modellbasierten Methode bezeichnet.
Anhand des offline gelernten Modells wird dann in der zweiten Phase online eine Berechnung
durchgeführt. Durch die Auslagerung des zeitaufwändigen Prozesses in die Offline-Phase ist die
eigentliche Generierung der Empfehlung deutlich effizienter. [vgl. Soltani 2020, S.16] Im
Gegensatz zu speicherbasierten Methoden ist der Nachteil, „dass ein Modell nur die
Bewertungsdaten berücksichtigt, die beim Lernen des Modells zur Verfügung standen [Ludmann
2020, 17].“
2.3 Inhaltsbasiertes Filtern
Die Datenbasis beim Inhaltsbasierten Filtern ist das von einem User aktuell genutzte Objekt und
zusätzlich das/die in der Vergangenheit genutzte/-n Objekt/-e, um Objektempfehlungen zu
generieren, die dem aktuell genutzten Objekt am ähnlichsten sind [vgl. Ludmann 2020, 15-16].
So werden anhand der Attribute, welche die Objekte beschreiben, Empfehlungen vorgeschlagen.
Diese basieren vermehrt auf Informationen über den Inhalt der Objekte als auf den Meinungen
4Recommender-Systeme als Ansatz zur Objektempfehlung
anderer Benutzer. Informationen sind hierbei sowohl Objektbeschreibungen als auch
Produktbilder. Die Berechnung für die Ähnlichkeit zweier Objekte kann bspw. über ähnliche oder
gleiche Schlüsselbegriffe erfolgen. Hier werden Übereinstimmungen der Schlüsselbegriffe
zwischen zwei Objekten gezählt. Anhand dieser Häufigkeiten wird anschließend eine
Empfehlungsberechnung durchgeführt. Das Inhaltsbasierte Filtern ist im Vergleich zum
Kollaborativen Filtern fähig, Objektempfehlungen, ohne das Vorhandensein anderer User, zu
generieren. Dies bedeutet auch, dass das Kaltstart-Problem zum Teil beseitigt wird.
Kaltstart-Problem
Aufgrund mangelnder Objektbewertungen durch andere User besitzt das RS nicht die Möglichkeit
genaue Vorschläge zu erzeugen. Daher werden neue Objekte erst dann empfohlen, wenn sie
eine gewisse Anzahl an Bewertungen durch andere User aufweisen.
Der Ursprung von inhaltsbasiertem Filtern liegt im Gebiet des information-retrieval. Dabei handelt
es sich hauptsächlich um Objekte in Textform. Später entwickelte sich die Funktionsweise durch
Hinzunahme von Benutzerprofilen. [vgl. Gontarska 2016, S.11] Das Inhaltsbasierte Filtern
generiert anhand eines Algorithmus für maschinelles Lernen ein Profil der Anwenderpräferenzen.
Diese basieren auf Merkmalsbeschreibungen des Inhalts. So lernt das System die Präferenzen
der User zu analysieren. Hierfür geben Benutzer ein Feedback ab. Wird einem Anwender bspw.
ein Film vorgeschlagen, so können die Wörter aus der Beschreibung des Films, sofern die
Empfehlung als positiv bewertet wurde, in das Userprofil aufgenommen werden.
2.4 Wissensbasiertes Filtern
Aus den vorherigen Kapiteln lässt sich entnehmen, dass sowohl kollaborative als auch
inhaltsbasierte Systeme eine große Menge an Daten über Bewertungen erfordern. Besonders
kollaborative Empfehlungsdienste benötigen eine möglichst gut besetzte Bewertungsmatrix, um
zukünftige Empfehlungen zu generieren. So kann es bei mangelnden Daten zu Empfehlungen
führen, welche einen geringen Mehrwert bieten. Hier kommt erneut das Kaltstart-Problem zum
Vorschein. Verschiedene Systeme sind hierbei unterschiedlich anfällig. Insbesondere
kollaborative Systeme können zu Beginn mit neuen Usern oder Objekten nicht sehr gut umgehen.
Inhaltsbasierte Systeme hingegen sind in der Lage Empfehlungen für neue Objekte
vorzunehmen. Jedoch besteht weiterhin das Problem sobald neue User auftauchen. Darüber
hinaus sind diese Methoden nicht geeignet für Bereiche, in denen Objekte stark individualisiert
werden. Für diese Art von Objekten sind keine ausreichenden Bewertungen verfügbar [vgl.
Aggarwal 2016, S.37]. Speziell bei Visualisierungen von Daten, gibt es eine große Zahl an
Optionen bei der Auswahl der Filter. Die Basis hierbei ist die explizite Abfrage von
Benutzeranforderungen. Hierfür verwendet ein wissensbasiertes System ein interaktives
Feedback, das dem Benutzer ermöglicht, sich über verschiedene objektbezogene Optionen zu
informieren. In Wissensbasierten Systemen sind User aktiver, wenn es darum geht, explizite
Anforderungen zu formulieren. Besonders in folgenden Situationen sind wissensbasierte
Systeme geeignet:
1. Explizite Angabe von Anforderungen durch Anwender: Die Interaktion ist hierbei ein
entscheidender Aspekt. Dies lässt sich in kollaborativen sowie inhaltsbasierten
Systemen nicht umsetzen.
5Recommender-Systeme als Ansatz zur Objektempfehlung
2. Bewertungen für eine bestimmte Art von Objekten sind nicht verfügbar: Die Zahl der
Möglichkeiten das Objekt zu individualisieren ist zu groß. Daher ist es schwierig,
Objektbewertungen anzusammeln.
3. Bewertungen sind zeitkritisch: Bewertungen von alten Daten sind nicht immer sehr
nützlich, da sich Benutzeranforderungen verändern.
Vorgehen Ziel Input
Vorschläge auf Grundlage eines
kollaborativen Ansatzes, der User Bewertungen + Bewertungen
Kollaborativ
Bewertungen anderer User oder des anderer User
aktuellen Users nutzt
Vorschläge auf Grundlage der
Inhaltsbasiert Inhalte (Attribute), die durch User Bewertungen + Objektattribute
aktuellen User favorisiert wurden
Vorschläge auf Grundlage der
User Spezifikation + Objektattribute
Wissensbasiert expliziten Anforderungen über die
+ Domänenwissen
Art der Objekte, die der User möchte
Tabelle 1: The conceptual goals of various recommender systems [Aggarwal 2016, S.16]
Um sich einen Überblick über die bereits beschriebenen Recommender-Systeme zu beschaffen,
lassen sich in Tabelle 1 Informationen hierzu entnehmen.
Der besonders wichtige Aspekt bei wissensbasierten Systemen ist die Kontrolle durch die
Benutzer bei der Empfehlungsgenerierung. Sowohl bei inhaltsbasierten als auch bei
kollaborativen Systemen basieren Objektempfehlungen auf historische Daten. Ein
wissensbasiertes System hingegen beachtet explizite Anforderungen der User. So wird ermittelt,
was sie wirklich wollen. Durch eine Wissensdatenbank wird relevantes Domänenwissen entweder
in Form von Einschränkungen oder Ähnlichkeiten zugewiesen. Es gibt zwei Arten von
wissensbasierten Systemen:
1. Constraint-based: Benutzer spezifizieren Anforderungen und Einschränkungen an
die Attribute der Objekte. Darüber hinaus werden domänenspezifische Regeln
verwendet, um die Anforderungen der Benutzer an die Objektattribute anzupassen.
Diese Regeln stellen hierbei das vom System verwendete domänenspezifische
Wissen dar. So werden beispielsweise Benutzerattribute mit Objektattributen
verknüpft. Am Beispiel der Datenvisualisierung kann dies wie folgt dargestellt
werden: „Benutzer wählen diejenigen Filter nicht aus, die Daten in Form von vier-
stelligen Zahlen oder höher beinhalten.“ Dennoch hat der Benutzer die Möglichkeit,
seine ursprünglichen Anforderungen zu ändern. So können bei zu vielen Ergebnissen
weitere Einschränkungen hinzugefügt werden. Alternativ besteht auch die
Möglichkeit, die Einschränkungen zu lockern, sodass mehr Ergebnisse
vorgeschlagen werden. Dieser interaktive Prozess kann so oft wiederholt werden, bis
der User das gewünschte Ergebnis erhält. [vgl. Aggarwal 2016, S. 38 - 39]
2. Case-based: Bestimmte Fälle werden vom User als Ziele vorgegeben. Daraufhin
werden Ähnlichkeitsmetriken auf Basis von Objektattributen definiert, um zu den
Zielen ähnliche Objekte zu erhalten. So stellen hier die Ähnlichkeitsmetriken das
6Knowledge-Assisted-Visualization
Domänenwissen dar. Sobald ein Ergebnis generiert wurde, wird dies meist als neues
Ziel verwendet. Somit kann ein Benutzer das Ergebnis, das fast seinen Vorstellungen
entspricht als neues Ziel definieren. Anschließend besteht die Möglichkeit eine
erneute Abfrage mit diesem Ziel durchzuführen. Diese Unterstützung durch das
System wird solange wiederholt, bis der User seine endgültige und gewünscht
Empfehlung erhält. [vgl. Aggarwal 2016, S. 39]
3. Knowledge-Assisted-Visualization
Ziel der Visualisierung ist es, Stärken von Menschen und Computer für eine effektive visuelle
Datenanalyse zu verknüpfen. Hierfür ist das implizite Wissen des Menschen erforderlich. Dieses
stammt aus den früheren Erfahrungen und kann sowohl vom Menschen als auch vom Computer
genutzt werden. Dennoch ist die Ansammlung, die Strukturierung, Speicherung sowie die
Nutzung des Wissens für den Visualisierungsprozess eine große Herausforderung. Daher wird in
diesem Kapitel der Aspekt der wissensbasierten Visualisierung näher erläutert. Hierfür wird auf
den Begriff Guidance in der Visualisierung und ein konzeptionelles Modell eingegangen.
3.1 Definition von Guidance
Ein unverzichtbarer Bestandteil der Visualisierung ist das Wissen des Benutzers in einem
Visualisierungsprozess. Jedoch ist das notwendige Wissen nicht immer vorhanden. Dies stellt für
den Einsatz von Visualisierungstechniken ein Hindernis dar. Daher bedarf es einer
wissensgestützten Visualisierung. Ziele der wissensgestützten Visualisierung sind die
gemeinsame Nutzung von Domänenwissen durch verschiedene User und die
Aufwandsverringerung während des Visualisierungsprozesses, über komplexe
Visualisierungstechniken Wissen anzueignen. Sobald also ein System ein solches
Domänenwissen angesammelt hat, ist es in der Lage auf Grundlage der Attribute eines
Eingabedatensatzes eine geeignete Empfehlung zu generieren. In Abbildung 3 wird dargestellt,
wie eine Softwarekomponente durch eine Wissensdatenbank (C know) unterstützt wird. In dieser
Wissensdatenbank sind Wissensrepräsentationen der User gespeichert. So kann das System
mithilfe des Wissens Regeln festlegen. Diese sorgen anhand mehrerer optionalen Sätze von
Steuerparametern für eine Eingrenzung des Ergebnisraums. [vgl. Chen 2009, S. 16] Somit wird
unerfahrenen Usern ein Vorschlag gegeben, der für sie größtenteils ausreichend ist. Es bedarf
keiner weiteren Anpassung durch User.
Abbildung 3: Knowledge-assisted-visualization [Chen 2009, S. 18]
7Knowledge-Assisted-Visualization
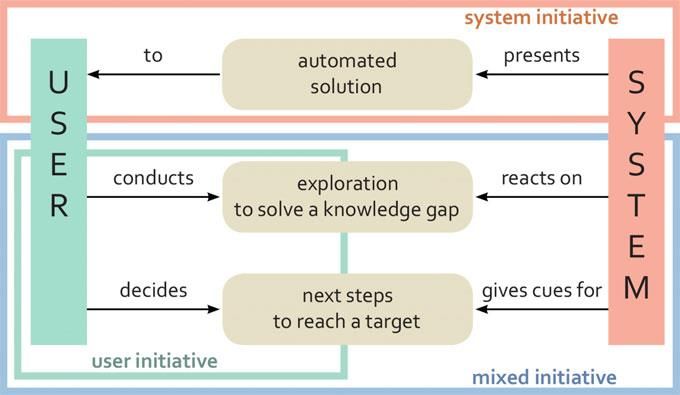
Benutzer werden hierbei zum gewünschten Ergebnis geführt, wodurch sich der Begriff
„Guidance“ ableiten lässt. Dies stellt in diesem Fall eine Führung dar. Es bezieht sich somit auf
ein System, das den Benutzer von Beginn des Visualisierungsprozess bis zum Ende unterstützt
und ihn dabei zum gewünschten Ergebnis führt. Deshalb wird im Folgenden vertieft auf den
Aspekt der Unterstützung eingegangen.
Die Grundidee der wissensbasierten Unterstützung ist es, Wissen zu speichern und in das
System zu integrieren, um Benutzer bei der Entscheidungsfindung zu unterstützen. Speziell bei
Visualisierungsvorgängen, bei denen der Konfigurationsraum sehr vielfältig ist. Oft steht der User,
welcher im Visualisierungsprozess eingebunden ist, vor Hindernissen. Dieser ist sich nicht
bewusst, durch welche Methoden das gewünschte Resultat erreicht werden kann. Daher
benötigen diese eine Anleitung/Unterstützung. Für diese Unterstützung ist jedoch die
Speicherung, Integration und die Anwendung von Domänenwissen notwendig. Eine
wissensbasierte Unterstützung durch das System kann mit dem vorhandenen Wissen den
Prozess der Visualisierung erheblich verschnellern. Aus diesem Grund ist Guidance ein wichtiger
Bestandteil bei der Wiederverwendung von Benutzerwissen. Es lässt sich wie folgt definieren:
„Guidance is a computer-assisted process that aims to actively resolve a knowledge gap
encountered by users during an interactive visual analytics session [Miksch, Leitte und Chen
2020, S. 76].”
Besonders drei Aspekte aus dieser Definition sind zu beachten: Guidance ist hierbei ein
dynamischer Prozess, der Benutzer bei der Lösung diverser Aufgaben unterstützen soll. Um
diese Aufgaben zu lösen bedarf es an Wissen. Das fehlende Wissen hindert Anwender an der
Lösung dieser Tasks. Der dritte Aspekt ist die Interaktivität in diesem Prozess. Die Interaktivität
ist gegeben durch den stetigen Wechsel zwischen dem Benutzer und des Systems. Reaktionen
des Systems basieren auf Handlungen des Users. [vgl. Miksch, Leitte und Chen 2020, S. 76 - 77]
Guidance bezeichnet hierbei die Vorschläge des Systems an den jeweiligen User. Dabei besitzt
jeder einzelne Benutzer die Möglichkeit, diese zu berücksichtigen oder zu ignorieren. Somit ist
der Anwender selbst für die Entscheidungsfindung verantwortlich. Bereits in den vorherigen
Kapiteln der Recommender-Systeme wurde erwähnt, dass diese lediglich für die
Vorschlagsgenerierung implementiert werden. So baut ein wissensbasierter Guidance auf die
Funktionsweise der Recommender-Systeme auf.
8Knowledge-Assisted-Visualization
Abbildung 4: Mixed-iniative-Process of guidance [Miksch, Leitte und Chen 2020, S.77]
Daher bedarf es einer Interaktion zwischen Benutzer und Computer, sodass beide Komponenten
zum Ergebnis beitragen, wie es auf Abbildung 4 zu sehen ist. Wie eine solche Interaktion erfolgt,
wird im folgenden Abschnitt anhand eines konzeptionellen Modells dargestellt.
3.2 Konzeptionelles Modell von Guidance
Der Ausgangspunkt hierbei ist das Modell von van Wijks. Dies ist in Abbildung 5 in grau
dargestellt. Abgebildete Kästchen stellen Artefakte wie Daten, Bilder, Spezifikationen und Wissen
dar während Kreise Funktionen abbilden. Diese verarbeiten Inputs und erzeugen Outputs aus
den jeweiligen Artefakten.
Abbildung 5: Extended version of van Wijk’s model [Miksch, Leitte und Chen 2020, S.79]
Der Ablauf des Modells ist folgendermaßen zu verstehen. „Visuelle und analytische Mittel (V)
transformieren Daten [D] in Bilder [I] auf der Grundlage einiger Spezifikationen [S]. Die Bilder
werden dann wahrgenommen (P), um etwas Wissen zu generieren [K]. Auf der Grundlage ihres
gesammelten Wissens können die Benutzer die Daten interaktiv erkunden (E), indem sie die
Spezifikationen anpassen [...] [Miksch, Leitte und Chen 2020, S. 78 - 79].“
9Knowledge-Assisted-Visualization
Dies stellt das iterative und dynamische Modell von van Wijks dar, welches geeignet ist für die
Erweiterung zu einem Guidance Modell für Visual Analytics.
Demnach beinhaltet das konzeptionelle Modell nach der Erweiterung zu einem Guidance Modell
noch weitere Artefakte und Funktionen. Diese sind unter anderem Historie [H], Domain [D],
Hinweise [C] und Optionen [D] und der Prozess der Guidance. Der Fokus hierbei liegt aber auf
den eigentlichen Prozess der Guidance. Außerdem ist zu erkennen, dass Guidance die
Schnittstelle zu den verschiedenen Artefakten ist. Guidance ist in erster Linie mit
Informationsquellen verbunden. Hierzu gehören Daten, Bilder, Historie und Domäne. Anhand der
Pfeilrichtung ist erkennbar, dass diese den nötigen Input für Guidance darstellen. [vgl. Miksch,
Leitte und Chen 2020, S. 79]
Für den Output kann es verschiedene Ansätze geben. Zu den Möglichkeiten gehören Prescribing,
Orienting oder Directing. Für den Fall des Directing bietet das System dem Benutzer Optionen
[O] an. Der Anwender hat die Möglichkeit vorgeschlagene Lösungen anzunehmen oder sie zu
ignorieren. Nachdem der Anwender sich für die Empfehlung des Systems entschieden hat,
besteht die Möglichkeit, die Daten der aktuellen Lösung zu erkunden. Daraufhin erfolgt die
Speicherung der Daten in der Historie, um erfolgreiche Ergebnisse zu merken. Jedoch kann der
User auch auf visuelle Hinweise [C] aufmerksam gemacht werden, wenn Guidance über den
Ansatz des Orienting verläuft. Dabei nimmt der Benutzer visuelle Hinweise wahr. Beispielsweise
kann ein Pop-Up erscheinen, welches den Anwender auf Balkendiagramme aufmerksam macht,
da diese Daten speziell dafür geeignet sind. Anschließend kann der User von diesen Hinweisen
profitieren und sie anwenden. Diese Entscheidung wird nun als zusätzliches Wissen aufbewahrt
und in der Historie gespeichert. Als dritte Methode besteht die Möglichkeit, eine Anpassung der
Spezifikation [S] vorzunehmen. Hier kann der User selbst benutzerspezifische Vorgaben
einstellen, sodass im darauffolgenden Visualisierungsprozess oder im aktuellen nach der
Iteration automatische Lösungen bereitgestellt werden. [vgl. Miksch, Leitte und Chen 2020, S. 78
- 80].“
Grundlegend lässt sich Guidance in drei Bereiche einteilen:
1. Knowledge-Gap
Welche Wissenslücke existiert und muss geschlossen werden?
2. Inputs und Outputs
Welche Inputs werden verwendet und welche Outputs werden aus ihnen erzeugt
und dem Benutzer vermittelt?
3. Grad von Guidance
Bis zu welchem Grad soll eine Beratung durchgeführt werden?
10Knowledge-Assisted-Visualization
3.2.1 Knowledge-gap
Abbildung 6: Aspects of guidance [Miksch, Leitte und Chen 2020, S. 78]
Ein Anwender, der für die Datenvisualisierung zuständig ist, hat das Ziel, bei jedem Prozess
Wissen zu erlangen und zu sammeln. Es wird benötigt, um Visualisierungen zu erleichtern und
zu beschleunigen. Jedoch ist dem Anwender nicht immer bewusst, welche Informationen relevant
und für spätere Visualisierungsprozesse notwendig sind. Daher gilt es herauszufinden, welches
Wissen der Benutzer aus einer Datenmenge entnehmen kann. Der Guide muss demnach in der
Lage sein, das Wissen des Anwenders zu verstehen und zu speichern, um zukünftige Richtlinien
vorzuschlagen und ihn im Visualisierungsprozess zu unterstützen. Da jedoch oft der Anwender
die Wissenslücke besitzt, gilt es dieses Problem vorerst zu untersuchen. Dabei kann es
verschiedene Gründe geben, die zu einem knowledge-gap führen. Hier werden zwei der
relevantesten Gründe benannt:
• Target unknown:
Dies bedeutet, dass der Benutzer überhaupt nicht weiß, welches Ergebnis im
Visualisierungsprozess angestrebt wird [vgl. Ceneda 2017, S.113]. So weiß der Benutzer
zum Beispiel nicht, welche Daten er im Endeffekt als relevant betrachtet oder welche sich
ähneln.
• Path unknown:
Hier ist der Fall, dass der Weg, welcher zum gewünschten Ergebnis führt, für den
Anwender noch unbekannt ist [vgl. Ceneda 2017, S.113]. Demnach weiß der Benutzer
zum Beispiel nicht, anhand welchen Algorithmus die Daten sortiert werden müssen, um
zueinander ähnliche Daten zu erhalten.
Im Folgenden werden einige der Bestandteile der Bereiche des Guidance näher erläutert. Es
werden nicht alle angeführt, da einige der Bestandteile in Abbildung 6 zu umfangreich und in
dieser Thesis nicht relevant sind. Daher wird im Folgenden nur auf die wichtigsten Aspekte, worin
der Anwender Unterstützung benötigt, eingegangen. Im Bereich der knowledge-gap gilt es
folgende Aspekte zu beachten:
Data: Ein Anwender benötigt Hilfe bei der Untersuchung der Daten. Zum einen gilt es relevante
Daten zu identifizieren. Zum anderen muss herausgefunden werden, welche Merkmale diese
Daten aufweisen. Dies basiert auf der Funktionsweise der Recommender-Systeme. Ein
11Knowledge-Assisted-Visualization
Recommender-System analysiert die Daten und generiert dem Anwender entweder einen
Vorschlag oder bietet ihm eine Teilmenge der Daten, mit denen der Benutzer weiterarbeiten kann.
Tasks: Des Weiteren hat ein Anwender Schwierigkeiten während des Prozesses seine Aufgabe
zu erledigen. So kann es beispielsweise dazu kommen, dass der Benutzer nicht weiß, was als
nächstes zu tun ist. Deshalb wird in Form von visuellen Hinweisen dem Anwender ein Tipp
gegeben, welcher Schritt nun folgt.
VA Methods: Außerdem gibt es die Möglichkeit mithilfe von Vorschlägen bezüglich der
Visualisierungstechniken dem Anwender Unterstützung zu bieten, um die relevanten Daten
visuell darzustellen. Beispielsweise wird der Benutzer auf ein Liniendiagramm hingewiesen, worin
nur Werte < 5 dargestellt werden. So behält der User den Überblick, über z.B. geringe
Abweichungen vom Zielwert bei der Untersuchung von diversen Daten.
3.2.2 Inputs und Outputs
Um Lösungen für den Anwender zu generieren, muss sichergestellt werden, dass die Lösung
bereits bekannt ist. Hierfür gilt es herauszufinden, aus welchen Datenquellen ein Ergebnis
resultiert. Besonders bei Guidance existieren mehrere Datenquellen, die einen Output generieren
können. Folgende Inputs sind zu beachten:
Data: Daten als Datenquelle sind jegliche Art von Daten, die zum Zeitpunkt der Visualisierung
zur Verfügung stehen. Dabei können diese Rohdaten und/oder Metadaten sein. Daten sind die
meistverwendeten Datenquellen, die als Input in Anspruch genommen werden.
Domain Knowledge: Ein weiterer Input hier ist das Domänenwissen, woraus Informationen
entnommen werden. Dieses Vorwissen setzt sich beispielsweise zusammen aus Expertenwissen
oder aus Domänenmodellen. Domänenwissen führt dabei auf Informationen zurück, die aus der
Applikationsdomäne stammen.
Visualization Images: Dem Prozess nach zu urteilen, können Bilder sowohl als Input, als auch
als Output verstanden werden. Wenn es sich um ein Input handelt, so ist das Bild die visuelle
Datenrepräsentation. Hier können Informationen über die Daten entnommen werden.
Beispielsweise kann der Anwender bereits hier Abhängigkeiten zwischen relevanten Daten
erkennen. Daher ist der nächste Schritt die Wahrnehmung des Anwenders, das daraufhin als
Wissen gespeichert wird. Jedoch besteht auch die Möglichkeit, Images als Output festzulegen.
Nach einer oder mehrerer Iterationen durch das Modell, wird nach dem Festlegen von
Spezifikationen im Visual Analytics Prozess ein neues Bild erzeugt. Dieses Bild dient dann als
Lösung für den Anwender und stellt somit den Output dar.
User Knowledge: Auch zu beachten ist das Benutzerwissen, das in der Visualisierung mit
Guidance eine große Rolle spielt. Denn anhand der Eingaben durch den Anwender erhält die
Visualisierungskomponente Informationen bezüglich seiner Interessen. Diese werden benötigt,
um in den zukünftigen Visualisierungsprozessen benutzerspezifische Lösungen bereitzustellen.
[vgl. Ceneda 2017, S.114]
Je nach Datenquelle erhält der Anwender unterschiedliche Outputs. Das Ziel ist es jedoch, die
für den Benutzer optimalste Lösung zu generieren. Eine Lösung muss nicht zwanghaft eine fertige
Visualisierung sein, das vom System automatisch erzeugt wird. So gibt es beispielsweise die
12Knowledge-Assisted-Visualization
Möglichkeit, dass ein Anwender bereits anhand der von der Systemkomponente angezeigten
visuellen Hinweise in der Lage ist, seine Lösung selbst zu erstellen. Das Ergebnis ist also
abhängig vom Grad des Guidance. So stellt sich also die Frage: Inwieweit soll das System dem
Benutzer im Prozess der Visualisierung unterstützen? Wie bereits in 3.2. beschrieben kann
Guidance auf drei verschiedene Weisen durchgeführt werden.
3.2.3 Guidance-degree
Abbildung 7: Abhängigkeiten vom System während der Visualisierung
Für einen Anwender kann der Prozess entweder ohne Probleme verlaufen oder aber dieser
besitzt keine Visualisierungsfähigkeiten. Beide Möglichkeiten sind Extremfälle. Aus dem
beispielhaften Diagramm in Abbildung 7 lassen sich drei Anwender erkennen. Jeder dieser
Anwender besitzt unterschiedliche Fähigkeiten. So bedarf es bei Anwender 3 keiner großen
Unterstützung während Anwender 1 große Schwierigkeiten besitzt und somit stark auf die Hilfe
des Systems angewiesen ist. Ursachen können beispielsweise sein, dass die
Visualisierungsumgebung zu komplex oder der Anwender nicht in der Lage ist, relevante Daten
zu filtern. Deshalb wird nach dem Grad der Unterstützung unterschieden.
Orienting: Die niedrigste Stufe des Guidance-degrees stellt das Orienting dar. Wie der Name
bereits verrät, ist diese Funktion für die Unterstützung der Orientierung des Benutzers zuständig.
Es ist in der Lage, dem Anwender anzuzeigen, wo er sich gerade befindet und welche
Möglichkeiten existieren. So wird der Anwender anhand von visuellen Hinweisen zum Ziel
geführt. Dieser Schritt kann auch in verschiedenen Graden vollzogen werden. Ein User, der auf
wenig Hilfe angewiesen ist, wird lediglich mit simplen Hinweisen unterstützt. Wohingegen ein
Anwender, der beispielsweise nicht weiß, in welchem Bereich sich die Auswahl der Diagramme
befindet, mehr Unterstützung erhält. So kann das System abhängig von Benutzerfähigkeiten
mehr oder weniger Hinweise erscheinen lassen. Ebenso wird ein Orienting-Prozess genutzt, um
Nutzern Ratschläge oder Verbesserungsvorschläge bei bereits entschiedenen Lösungen zu
geben.
Directing: Mehr Unterstützung wird über den Weg des Directing angeboten. Hier wird im
Gegensatz zu Orienting auf die Bereitstellung von fertigen Lösungen abgezielt. Das System ist in
der Lage anhand von bereits in der Vergangenheit durchgeführter Visualisierungen, die sich in
13User-behavior-Analytics
der Historie befinden, dem Anwender ein Ergebnis zu präsentieren [vgl. Ceneda 2017, S.116].
Dabei werden mehrere Optionen vorgeschlagen. So hat der Nutzer die Möglichkeit, fertiggestellte
Diagramme zu entnehmen oder sie zu ignorieren. Außerdem kann ein Anwender die Ergebnisse
des Systems weiterhin anpassen. So gibt das System dem User einen groben Richtwert, woran
dieser sich festlegen kann. Durch den Benutzer weiterhin angepasste Lösungen werden dann in
der Historie gespeichert. Dadurch ergibt sich für den nächsten Visualisierungsprozess eine für
den Benutzer verbesserte Lösung.
Prescribing: Der höchste Grad an Unterstützung wird durch den Prescribing Prozess gegeben.
Das Ziel hierbei ist ein vollständig automatisierter Prozess, der den Anwender zum gewünschten
Ergebnis führt. Die Unterstützung erfolgt durch verschiedene Ansätze. Das System ist sowohl in
der Lage automatische Lösungen bereitzustellen als auch dem Benutzer visuelle Hinweise in
bestimmten Situationen zu geben. Folglich passt sich das System den Benutzeranforderungen
an und leistet die nötige Hilfe in den erforderlichen Situationen. Des Weiteren hat der Anwender
selbst die Möglichkeit seine Spezifikationen festzulegen. Somit wird der
Visualisierungskomponente bei der nächsten Iteration eine Vorgabe gegeben. Beispielsweise ist
der Wunsch des Anwenders mehrere Vorschläge zu erhalten oder aber für die Visualisierungen
der Daten ausschließlich Liniendiagramme anzuwenden. So ergibt sich für den User eine Vielzahl
an Optionen, die er frei konfigurieren kann.
Durch verschiedene Grade kann dem Anwender auf unterschiedlichste Weisen Unterstützung
geboten werden. Weiterhin sollte die Komponente in der Lage sein, die Präferenzen der
Anwender der Visualisierungskomponente kennenzulernen. Dadurch leistet die Anwendung
benutzerspezifische Unterstützung. Deshalb gilt es das Verhalten einzelner Nutzer zu
identifizieren, um weiteren Benutzern anhand des Verhaltens optimierte Vorschläge zu
generieren. Daher wird im folgenden Kapitel der Aspekt Nutzerverhalten (User behavior)
analysiert. Wichtig ist es zu erkennen, inwieweit die Erkenntnisse daraus die Visualisierung
fördern.
4. User-behavior-Analytics
Ebenso wie für Webseitenbetreiber oder für das Cyber-Security Team eines Unternehmens ist
es auch für Softwarebesitzer wichtig zu wissen, wie die eigene Software durch Anwender genutzt
wird. Besonders dann, wenn sich eine Software noch in der Testphase befindet. Dadurch werden
Defizite reduziert. So ist es in der Datenvisualisierung von Vorteil das Nutzerverhalten zu kennen.
Eine Softwarekomponente, die zur Unterstützung des Users dient, ist dann in der Lage anhand
von User behavior spezielle Muster zu erkennen. Daher wird in diesem Kapitel der Aspekt des
User behavior näher untersucht.
4.1 Grundlagen von User-behavior-analytics
Das Monitoring und Identifizieren des Nutzerverhaltens sind besonders wichtig, um Bedürfnisse
der Anwender zu verstehen. Dabei wird die Aktion des Benutzers während der Interaktion mit der
Software aufgezeichnet. So lassen sich beispielsweise oft ausgewählte Schaltflächen oder
Fenster mit hoher Verweildauer feststellen. Ebenso ist die Untersuchung von User behavior
notwendig für die Erkennung erfolgreicher Nutzung der Anwendung. Dadurch erhält das System
die Information, dass eine Anwendung den Bedürfnissen des Benutzers entspricht. Jedoch
14User-behavior-Analytics
besteht die Möglichkeit, dass ein Anwender erst durch viel Zeitaufwand das gewünschte Ergebnis
erreicht hat. Auch dies ist durch User-behavior-Analytics zu ermitteln. So werden zusätzliche
Informationen über einzelne Anwender gesammelt. Diese gewinnbringenden Informationen
werden genutzt, um Optimierungen an der Software vorzunehmen. Beispielweise die Anpassung
der Optik stellt dem Benutzer, der sich zuvor nicht zurechtfinden konnte, eine Verbesserung der
Anwendung dar. Auf diese Art lassen sich Schwachpunkte der Anwendung und zugleich das
Verhalten des Nutzers feststellen. Doch bevor das User behavior untersucht wird, muss
festgestellt werden welche Erkenntnisse aus dieser Untersuchung relevant sind und wozu sie
durchgeführt wird. So gilt es folgende Fragen zu klären:
1. Was ist das Ziel der Analyse?
Entwickler einer Anwendung sind daran interessiert, ihre Software so gut wie möglich zu
gestalten. Um dies zu erreichen gilt es verschiedene Faktoren zu berücksichtigen. Daher
muss bereits vor der Untersuchung festgelegt werden, welches Ziel eine solche Analyse
verfolgt.
2. Welche Ergebnisse sollen erzielt werden?
Bei der Untersuchung von Anwenderverhalten resultieren unterschiedliche Ergebnisse.
Der Entwickler einer Software könnte daran interessiert sein, die Bedienung für die
Benutzer angenehmer zu gestalten. Daher gilt es bei der Verhaltensanalyse darauf zu
achten, wie User auf die Positionierung der entsprechenden Elemente reagieren.
3. Wie hilft die Auswertung der Daten bei der Optimierung der Anwendung? [vgl.
Donick 2020, S. 67]
Eine Verhaltensanalyse hat als Folge, Optimierungsmöglichkeiten zu identifizieren. Diese
ermöglichen dem Entwickler eine Verbesserung der Anwendung. Dadurch lassen sich
Fehler, die während der Entwicklungsphase nicht erkannt wurden, beseitigen.
Ein Beispielszenario könnte folgendermaßen aussehen:
Ein Anwender visualisiert Ergebnisdaten von einem Testfahrzeug. Dabei begegnet der Benutzer
einer Vielzahl an Filter. Durch die große Auswahl an Optionen hat der Anwender Schwierigkeiten
zu entscheiden, welche Filter am relevantesten sind. Deshalb ist die Visualisierung mit einem
hohen Zeitaufwand verbunden.
Antworten auf vorangehende Fragen könnten folgende sein:
Das Ziel der Analyse hierbei ist es zu erkennen, für welche Filter der Anwender sich letztlich
entschieden hat. Ergebnisse dieser Untersuchung sind eine Anzahl an Mausklicken auf jeweilige
Filter. Dadurch existieren Informationen über Schaltflächen, die im Fokus des Anwenders sind.
Zur Optimierung der Anwendung werden zukünftig bei ähnlichen zu visualisierenden Daten,
automatisch meistgeklickte Filter vorangewählt. Dadurch verringert sich der Zeitaufwand des
Prozesses erheblich. Der Entwickler besitzt dann die nötigen Informationen, um eine
Optimierung der Software vorzunehmen.
Einen Anwender zu identifizieren kann eine Herausforderung darstellen. Besonders, wenn für die
Nutzung der Anwendung keine Benutzerkonten angelegt werden müssen. Deshalb werden
15User-behavior-Analytics
Verhaltensweisen mehrerer Anwender als ein Anwender erkannt. So werden Aktionen während
der Nutzung der Anwendung verallgemeinert aufgezeichnet, um entsprechende
Verhaltensmuster zu erkennen. Dennoch gilt es auch hier Anomalien festzustellen. Denn ein
einzelner Anwender kann zu komplett unterschiedlichen Ergebnissen führen. Die Ursache ist,
dass sich dieser User bewusst oder unbewusst von der Allgemeinheit differenziert. Auf diese
Weise werden Ergebnisdaten der Analyse manipuliert.
Der Grund für das unbewusst andere Nutzerverhalten eines einzelnen Users ist, dass das
Nutzerverhalten unter den Verbrauchern sehr stark variieren kann. Obwohl dieselbe Anwendung
verwendet wird, kann es stark unterschiedliche Verhaltensweisen aufweisen.
Wird aber das Verhalten bewusst anders eingesetzt als das von einem durchschnittlichen
Anwender, wird meist als Ursache ein Hackerangriff zugrunde gelegt. Diese werden durch
Anomalien in Untersuchungen festgestellt. Jedoch wird in dieser Arbeit nicht auf User-behavior-
Analytics im Cyber-Security Bereich eingegangen, da dies keinen Zusammenhang mit der
Datenvisualisierung besitzt.
4.2 Vorbereitung für die Analyse von User behavior
Noch bevor eine Untersuchung durchgeführt wird, bedarf es einer Vorbereitung. Dabei gilt es
zwei wichtige Faktoren zu berücksichtigen. Diese entscheiden über die Ergebnisse der
Untersuchung.
1. Art der Untersuchung
Unter der Art der Untersuchung ist verstehen, welche Methode eingesetzt wird. Dabei existieren
viele verschiedene Möglichkeiten. Das Aufzeichnen von Benutzerinteraktionen kann also auf
unterschiedliche Weise durchgeführt werden. Je nach Einsatz der Technik werden
entsprechende Ergebnisse erzielt. Daher sollte im vornherein festgelegt werden, welche Intention
sich hinter der Untersuchung verbirgt und welche Ergebnisse erzielt werden sollen. Im Folgenden
werden mögliche Arten von Untersuchungen, die ausschließlich die Computermaus betreffen,
näher erläutert:
Mouse Tracking
Durch Mouse Tracking wird das Verhalten des Users aufgezeichnet. Dabei wird die Nutzung der
Maus unter die Lupe genommen. Ergebnisse dieser Daten werden anschließend ausgewertet.
Es werden verschiedene Arten von Mouse Tracking unterschieden:
Clickmap
Bei der Anwendung einer Clickmap erlangt das System Informationen darüber, welche
Bereiche oder Schaltflächen einer Webseite oder Anwendung angeklickt werden. Durch
mehrmaliges Anklicken einer Stelle durch einen oder mehrerer Nutzer lässt sich ermitteln,
welche Stellen im Fokus des Users sind. So wird erkannt, welche Bereiche einer
Anwendung oder Webseite vom User wahrgenommen werden.
16User-behavior-Analytics
Abbildung 8: Clickmap [Ryte 2020] Abbildung 9: Clickmap – 2 [Abbamonte 2020]
Für die Darstellung der oft angeklickten Bereiche gibt es verschiedene Optionen. Eine
Möglichkeit ist das Zählen der Klicks auf entsprechende Bereiche. Eine weitere Option
ist das Ermitteln der Hotspots. Durch mehrmaliges Anklicken auf einen Bereich färbt sich
dieser immer röter. Eine beispielhafte Darstellung lässt sich aus den Abbildungen 8 und
9 entnehmen.
Mouse Movement Heatmap
Durch die Mouse Movement Heatmap lassen sich Bewegungen des Mauszeigers des
Anwenders erkennen. Daraus ergibt sich eine Reihenfolge an Bewegungen. Diese
zeigen auf, in welcher Abfolge Bereiche einer Anwendung vom Anwender
wahrgenommen werden.
Heatmap
Um wahrgenommene oder nicht wahrgenommene Elemente zu erkennen ist eine
einfache Heatmap ausreichend. Dadurch lassen sich ebenfalls oft wahrgenommene
Bereiche feststellen. Die Darstellung beider Heatmaps ist gleichermaßen wie die einer
Clickmap. Es werden verschiedene Farbtöne verwendet, um oft angesehene Bereiche
zu kennzeichnen. [vgl. Ryte 2020]
Clicked Checkbox (eigen entwickelte Methode)
Eine weitere Möglichkeit, um das Klickverhalten der Anwender zu analysieren, ist das
Überprüfen der Checkboxen. Diese Methode wird auf Webseiten mit Checkboxen
angewendet, welche der Mehrfachauswahl dienen. So lassen sich anhand von
Klickzählern oder durch Prüfung von zuletzt angeklickten Checkboxen erkennen, welche
Inhalte der Seite dem Interesse eines Benutzers entsprechen.
Es existieren noch weitere Arten zum Aufzeichnen des Nutzerverhaltens. Diese sind jedoch bei
der Umsetzung ein viel aufwendigerer Prozess. Daher sind sie in diesem Abschnitt der Arbeit als
nicht relevant anzusehen.
2. Testpersonen
Handelt es sich bei der Untersuchung um eine Anwendungs- oder Webseitenoptimierung, ist es
wichtig, bestimmte Probanden einzusetzen. Verschiedene Eigenschaften dieser Personen
können Testergebnisse unfreiwillig beeinflussen. So ist es wichtig, eine ausgewogene Mischung
17Sie können auch lesen

















































