Vorsortierer für Datenflut - Junge-Wissenschaft
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

Paper 04 / 2021 doi: 10.7795/320.202104 Verlag: Physikalisch- Technische Bundesanstalt JungforscherInnen publizieren online | peer reviewed | original Physik Vorsortierer DIE JUNGFORSCHERIN für Datenflut Neuronale Netze auf der Suche nach dunkler Materie Die Dunkle Materie des Universums besteht vermutlich aus neuartigen Elementarteilchen, den Axionen. Diese sucht Carolin Kohl (2001) das CAST-Experiment am CERN in Genf. Um Signal- von Paul-Klee-Gymnasium Untergrundereignissen zu trennen, wird das Potential eines Overath Multilayer-Perceptrons, ein bestimmter Typ eines Neuronalen Eingang der Arbeit: Netzwerks, als Klassifikationsmethode verwendet. Dies erweist 19.8.2019 sich als vielversprechender Ansatz. Arbeit angenommen: 16.12.2019

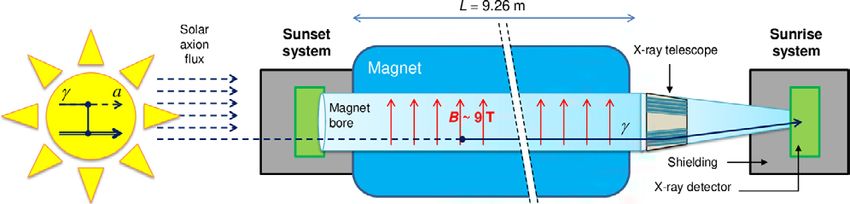
Physik | Seite 2 genphotonen bildet der Sikivie-Ef- fekt. Dieser Effekt sagt die Entstehung von Axionen durch Wechselwirkung thermaler Photonen mit den elektro- magnetischen Feldern im Plasma des Sonneninneren sowie eine (Rück-)Um- wandlung dieser Axionen in Röntgen- photonen in Gegenwart eines starken Magnetfeldes voraus [2]. Als Ziel des CAST-Experiments soll in einem bestimmten Massebereich nach der Kopplungskonstanten von Axio- nen und Photonen, welche die Häufig- keit und Wahrscheinlichkeit der Axion- Photon-Umwandlungen bestimmen, gesucht werden. Hierzu soll in einem nicht gebogenen Prototyp eines Large- Vorsortierer Hadron-Collider-Dipolmagneten die Axion-Photon-Umwandlung durch das angelegte magnetische Feld ermöglicht für Datenflut werden. Die im Falle einer Umwand- lung eines Axions entstehende schwa- che Röntgenstrahlung wird anschlie- ßend durch ein Spiegelsystem auf den Detektor fokussiert (siehe Abb. 1). Neuronale Netze auf der Suche nach dunkler Materie Die Röntgenphotonen gelangen durch ein dünnes transparentes Fenster in das Innere des Detektors. Dieser lässt sich grob in zwei Volumina untertei- len, die beide mit einer Mischung aus 1. Einleitung Argon-Gas und einem geringen An- teil Isobutan gefüllt sind und durch Obwohl die dunkle Materie über Doch auch zum Verständnis der baryo- ein feinmaschiges Metallgitter mit ei- 25 Prozent der gesamten Energie und nischen Materie kann das CAST-Expe- nem Lochdurchmesser von unge- Materie des Universums ausmacht, riment einen Beitrag leisten: Die Ent- fähr 30 µ voneinander getrennt sind stellt sie die Physik trotz intensiver For- deckung eines bisher nur theoretisch (siehe Abb. 2a.). Im oberen Bereich – schungsarbeit bislang vor große Rätsel. eingeführten Teilchens – das sogenann- „conversion gap“ genannt – sollen Die uns ausmachende baryonische Ma- te Axion – könnte das CP-Problems (Er- über den Photoeffekt mittels der ein- terie hingegen stellt nicht einmal 5 Pro- haltung der Charge-Parity-Invarianz) treffenden Photonen Elektronen aus zent der Materie- und Energiebilanz der starken Wechselwirkung lösen. den Gasatomen herausgeschlagen wer- des Kosmos dar [1]. Deshalb sucht das den. Durch die anliegende Hochspan- CAST-Experiment am CERN in Genf 1.1 Das CAST-Experiment nung werden die so ausgelösten Elek- nach möglichen Kandidaten für dunkle tronen zum darunterliegenden Gitter Materie und will diese indirekt in An- Mithilfe des CAST-Experiments (CERN gezogen, welches sie passieren und so wesenheit eines starken Magnetfeldes Axion Solar Telescope) sollen Axionen, in den zweiten Bereich des Detektors über deren Umwandlung in Röntgen- die vermutlich in der Sonne entste- – die sogenannte „amplification gap“ – photonen detektieren. So soll eine fun- hen und schließlich die Erde erreichen, eintreten (siehe Abb. 2b). Durch die an- damentale physikalische Frage geklärt durch deren Umwandlung in Röntgen- gelegte Spannung lösen die eintreten- werden: Welche Materieform dominiert photonen nachgewiesen werden. Das den Elektronen lawinenartig weitere im Universum? theoretische Fundament dieser indirek- Elektronen der umgebenden Gasatome ten Detektionsmethode mittels Rönt- aus. Alle ausgelösten Elektronen treffen doi: 10.7795/320.202104

JUNGE wissenschaft 04 15 / 21 18 | Seite 3 Abb. 1: Schematische Darstellung des Aufbaus und Detektionsprinzips des CAST-Experiments, unverändert übernommen aus [3]. nun – getrieben durch die Hochspan- sante Hintergrundereignisse herauszu- Die Unterscheidung der aufgenom- nung – auf den Auslesebereich, wo sie filtern. Ursache für diese Hintergrund- menen Ereignisse nach Signal und durch pixelbasierte Chips detektiert ereignisse kann beispielsweise das, trotz Untergrund erfolgt bereits mit Neu- werden. vorhandener Bleiabschirmung nicht ronalen Netzwerken. Für das Trai- vollständig auszuschließende, Eindrin- ning dieser wurden einerseits Bei einem genau senkrecht auf den gen kosmischer Strahlung sein. Teil- Messungen des Hintergrundes ver- Detektor treffenden Teilchen ist eine chen der kosmischen Strahlung, die zu- wendet, die aufgenommen wurden, sphärische Verteilung der detektier- fällig genau senkrecht auf den Detektor als das Teleskop nicht auf die Son- ten Ladungsträger zu erwarten (Abb. treffen, lassen sich ggf. nicht von einem ne gerichtet war. Andererseits wur- 3a). Hierbei handelt es sich um poten- Röntgenphoton unterscheiden, da sie den für die Trainingsdaten der Signal- zielle Signalereignisse, da diese durch ebenfalls eine sphärische Ladungsver- ereignisse Messdaten einer künstlichen Photonen aus der zu erforschenden teilung auf dem Auslesechip verursa- Röntgenquelle benutzt, die in das Expe- Axion-Photon-Umwandlung verur- chen. riment eingeführt wurde. sacht werden können. Erhält man hin- gegen eine Art Spur (Abb. 3b), handelt Aus der detektierten Ladungsmenge und es sich nicht um eines der gesuchten deren räumlicher Verteilung auf dem Photonen. Somit sind letztere Ereignisse Chip werden die in Tab. 1 genannten als für das Experiment weniger interes- Größen für jedes Ereignis errechnet [4]. photon vacuum window HV 1 Ar / isobutane: conversion gap micromesh HV 2 amplification gap strips / pads a) b) Abb. 2: (a) Aufbau des Detektors. Im Gegensatz zum hier gezeigten Vorgängermodell des Detektors mit einer Auslese über Metallstreifen und -pads arbeitet der Detektor nun mit einem pixelbasierten Chip und dem rechts gezeigten Gitter [2]. (b) Mikroskopische Aufnahme der amplification gap des Detektors [2]. doi: 10.7795/320.202104
Physik | Seite 4 250 250 10000 14000 Charge [electrons] Charge [electrons] 200 200 12000 8000 y [pixel] y [pixel] 10000 150 150 6000 8000 100 100 6000 4000 4000 50 2000 50 2000 0 0 0 0 0 50 100 150 200 250 0 50 100 150 200 250 x [pixel] x [pixel] a) b) Abb. 3: Beispielhafte Ladungsverteilung auf dem Chip für Signal- (a) und Hintergrundereignisse (b)[5]. 1.2 Fragestellung 2. Bisherige portionalen Zusammenhang von Ener- Datenklassifikation gie und Anzahl detektierter Ladungen Ziel des Projektes ist es, das Potenti- abgeleitet [4]. al eines Multilayer-Perceptrons (MLP), Zum Zeitpunkt der Arbeit existierten eines Typ Neuronalen Netzwerks, ab- bereits einige Ausarbeitungen in der Da hierbei nicht mit den echten Da- zuschätzen, wenn es als Klassifikati- CAST-Kollaboration zur Datenklassi- ten des Experimentes, sondern mit im onsmethode für Signal- und Unter- fikation mittels verschiedener Typen Labor erzeugten Datensätzen gear- grundereignisse eingesetzt wird. Neuronaler Netze, z. B. „Boosted Deci- beitet wurde und sich Detektoraufbau sion Trees“, „Support-Vector-Machines“ und -auslese ebenfalls verändert ha- In einer bereits bestehenden Arbeit und auch zwei Varianten von MLPs. Ei- ben, knüpft die vorliegende Arbeit in- [4] wurde ein Vergleich verschiedener nes der bereits existierenden MLPs, wel- sofern an die bisherigen Ergebnisse an, Netzwerktypen – MLPs eingeschlos- ches ebenfalls mittels Backpropagation dass nun die mit dem tatsächlichen Ver- sen – zur Datenauswertung vorgenom- trainiert wurde, erreichte u. a. eine Si- suchsaufbau und der weiterentwickel- men. Im Unterschied zu dieser bereits gnaleffizienz von 97,49 Prozent bei ei- ten Datenauslese gemessenen Daten existierenden Arbeit sollen nun die Op- ner Untergrundunterdrückung von verwendet werden [4]. timierungsmöglichkeiten eines MLPs 97,04 Prozent. Die entsprechende zur Datenklassifikation ausgelotet wer- Accuracy betrug ca. 97,31 Prozent. 3. Methodik den. Die zwischenzeitlich erfolgten Än- derungen des Detektoraufbaus, der Da- Dieses MLP verfügte über 20 Neuro- 3.1 Verwendetes Netzwerk tenauslese und die Neuberechnung der nen auf dem Input- und 25 Neuronen für das Training des Netzwerks verwen- auf dem Hidden-Layer. Die verwendete Das hier betrachtete Netzwerk ist in der deten Parameter aus den ausgelesenen Learning-Rate betrug 0,05. 30 Prozent Programmiersprache Python geschrie- Daten sind weitere Gründe für die er- der verfügbaren Daten wurden als Trai- ben worden. Diese Wahl ergab sich aus neute Betrachtung dieser Methode zur ningsdatensatz verwendet. Die verwen- der vergleichbar einfachen und intui- Datenklassifikation. Folglich stellt die deten Daten stammten hierbei aus Mes- tiven Syntax und durch die weite Ver- Abschätzung der zu erreichenden Si- sungen mit einem Detektorprototyp breitung dieser Sprache besonders im gnaleffizienz, also dem Verhältnis von unabhängig vom Versuchsaufbau am Bereich des Machine Learning, was Py- Signalempfindlichkeit zur Untergrund- CERN. Mangels künstlicher Röntgen- thon besonders durch leicht verfügbare unterdrückung, die Fragestellung der quellen, mit denen Ereignisse mit Pho- Literatur, Dokumentationen und viel- Arbeit dar. Anhand dieses Verhältnis- tonen einer besonders niedrigen Ener- fältige, sehr gut ausgebaute Bibliothe- ses ist zu entscheiden, ob dieser Ansatz gie erzeugt werden können, wurden ken besonders attraktiv macht. Für die zur Datenauswertung weiterverfolgt diese Ereignisse aus gemessenen Ereig- Programmierung wurden folgende Bi- werden kann und sollte. nissen höherer Energie über den pro- bliotheken verwendet: numpy version doi: 10.7795/320.202104
JUNGE wissenschaft 04 15 / 21 18 | Seite 5 1.18.1 [6], torch version 1.4.0 + cpu [7], Tab. 1: Kurzerläuterung der errechneten Parameter [4]. sklearn version 0.22.2 post1 [8]. Name des Parameters Kurzerläuterung Die Wahl des Multilayer-Perceptrons (MLP) anstelle anderer Netzwerkty- eventNumber Nummer zur Identifizierung des Ereignisses pen liegt in der hohen Flexibilität die- hits Anzahl der eingetroffenen Elektronen: ser Netzwerkstruktur begründet, so- dass eine große Wahrscheinlichkeit bestand, diesen Typ Netzwerk auch auf die gegebenen Messdaten des CAST-Ex- centerX, centerY x- bzw. y- Koordinaten des Mittelpunkts der periments sinnvoll anwenden zu kön- Ladungsdetektionen nen. Darüber hinaus gestaltet sich die length, width Länge bzw. Breite der Spur auf dem Chip Programmierung dieses Netzwerks- typs vergleichsweise einfach. So bot eccentricity Maßzahl für die Ellipsenförmigkeit, Verfor- die Wahl eines in Python geschriebe- mung relativ zum Kreis nen MLPs einen angemessenen Kom- KurtosisLongitudinal longitudinale bzw. transversale Kurtosis promiss aus komfortabler Handhabung Kurtosis: Maßzahl für die Stauchung in x-Rich- und Anwendbarkeit auf das gegebene kurtosisTransverse tung einer Verteilung im Vergleich zur Normal- Problem. Als Trainingsmethode wurde verteilung Backpropagation gewählt. rmsTransverse Root-Mean-Square (RMS) des Abstandes der getroffenen Pixel von der Haupt- bzw. kleinen Als anfängliche Vorlage diente ein MLP rmsLongitudinal' Halbachse der Spur zur Klassifizierung des MNIST-Daten- RMS: Quadratwurzel des Durchschnitts der satzes. Dieser enthält handgeschriebene quadrierten Abweichung vom Mittelwert einer Verteilung (skalarer Wert) Ziffern und wird gerne zum Trainieren und Testen im Zusammenhang mit Ma- fractionInTransver- Anteil derjenigen angesprochenen Pixel mit chine-Learning verwendet [7]. MNIST seRms einem Abstand kleiner oder gleich des als ist hierbei eine Abkürzung für ‚Modi- rmsTransverse errechneten Root-Mean-Squa- re des Abstands der detektierten Ladungen fied National Institute of Standards and zur kleinen Halbachse der Ladungsverteilung Technology‘. skewnessLongitudinal Asymmetrie der Verteilung der Ladungsträger in transversaler bzw. longitudinaler Richtung Aufgrund der für dieses Projekt leicht skewnessTransverse im Vergleich zur Normalverteilung zugänglichen Datenmengen wurde eine Unterteilung in einen Trainingsdaten- rotationAngle Winkel zwischen der Hauptachse der ellipti- satz und einen Testdatensatz mit dem schen Verteilung und den zur Lokalisation der Verhältnis 8:2 vorgenommen. Nach je- Pixel verwendeten Koordinatenachsen. der Trainingsepoche wurde jeweils zur Evaluierung der Testdatensatz im Test- modus, d. h. ohne Backpropagation und Anpassung der erlernbaren Netz- der Ergebnisse untereinander sicher- nissen eine höhere Aktivierung aufwies. werkparameter, durchlaufen. Nach zustellen, wurde der pseudo-random- Nach jeder Veränderung der Netzwerk- Abschluss des gesamten Trainings- number generator mit unverändertem parameter erfolgte die Entscheidung prozesses erfolgte abschließend eine Seed verwendet. Für die Label wurde über die nächste Variation anhand der Klassifikation des Testdatensatzes. One-Hot-Encoding mit je einer Katego- erzeugten Grafiken. rie für Signal- und Hintergrundereig- Die Test- und Trainingsdaten für Sig- nisse verwendet [10]. 3.2 Erzeugte Grafiken zur nal- und Hintergrundereignisse kamen Analyse des Netzwerks aus derselben Messreihe, sodass Test- Die Anzahl der Neuronen auf dem und Trainingsereignisse nicht anhand Input-Layer entsprach der Anzahl der In einem Histogramm wurde die Akti- messreihenspezifischer Unterschiede Parameter der Inputdaten (siehe Tab. 1), vierung eines der beiden Neuronen auf erkannt werden können. Die Einteilung die Anzahl der Neuronen auf dem Out- dem Output-Layer bei der Klassifikati- in Test- und Trainingsdatensatz erfolg- put-Layer betrug 2, sodass erwartungs- on des Testdatensatzes nach Abschluss te mittels eines pseudo-random number gemäß ein Neuron bei Signalereignissen des Trainings aufgetragen. Je klarer generators [9]. Um die Vergleichbarkeit und das andere bei Hintergrundereig- die Trennung der verschiedenen Akti- doi: 10.7795/320.202104

Physik | Seite 6 3.2 Erzeugte Grafiken zur Analyse des Netzwerks 100 In einem 100 Histogramm wurde die Aktivierung eines der beiden Neuronen auf dem O 90 Klassifikation 90 des Testdatensatzes nach Abschluss des Trainings aufgetragen. Je k 80 der verschiedenen 80 Aktivierungen, desto eindeutiger auch die Klassifizierung. Erg 70 Aktivierung 70 des Signalneurons gegen die Aktivierung des Hintergrundneurons aufge erreichte Accuracy in % erreichte Accuracy in % 60 die Leistungsfähigkeit 60 des Netzwerks wird hier die Accuracy verwendet. Die Accu 50 berechnet:50 40 40 30 30 Accuracy im 20 ���ℎ��� �������������� ��������������� + ���ℎ��� �������������� ����� Accuracy im Trainingsmodus �������20= Trainingsmodus 10 Accuracy im Testmodus 10 ������� ���ℎ� ��� �����ℎ��� Accuracy im Testmodus ���������������� 0 0 0 50 100 150 200 250 0 50 100 150 200 250 Anzahl absolvierter Trainingsepochen Die über die Trainingsepoche gemittelte Anzahl Accuracy wurde jeweils für den Trainings- absolvierter Trainingsepochen in der Accuracy-Kurve in Abhängigkeit der Trainingsdauer, hier dargestellt in a) b) aufgezeichnet. In ähnlicher Weise wurde mit dem über die Trainingsepoche gemittel Auch dieser wurde in Abhängigkeit der Trainingsdauer, wieder in Einheiten von Abb. 4: Accuracy der Klassifizierung des Testdatensatzes und des Trainingsdatensatzes. Die abgebildeten Netzwerke besaßen je 2 Hidden-Layer mit jeweils 40 veranschaulicht. Neuronen und wurden über 200 Epochen mit einer Learning-Rate von 10−5 trainiert. Als Aktivierungsfunktion wurde die obig erwähnte Sigmoid-Funktion (a) bzw. tanh(x) (b) verwendet. Beide Netzwerke verwendeten In der ROC-Kurve (receiver Mean-Squared Error alsoperating characteristic Loss-Funktion curve) ist der prozentuale A und Mini-Batch Stochastic Gradient Descent mit einem Moment von 0,9. Ein Mini-Batch Signalereignis umfasste klassifizierten hierbei Ereignisse 100Gesamtzahl an der Ereignisse.der Signalereignisse (T als Funktion des prozentualen Anteils der fälschlicherweise als Signalereignis klassi an der Gesamtzahl der Hintergrundereignisse (False Positive Rate) aufgetragen. Z entsprechenden Wertepaare wird ein Schnittwert auf die Aktivierung des Sign vierungen, desto eindeutiger auch die zentuale Anteil der richtig als Signal In Erwartung einer Steigerung der Leis- Klassifikation des Testdatensatzes nach Abschluss des Trainings gesetzt, sodass Klassifizierung. Ergänzend wurde die ereignis klassifizierten Ereignisse an der tungsfähigkeit des anfänglichen Netz- mindestens dem des Schnittwertes entsprechen muss, damit das Ereignis als Signale Aktivierung des Signalneurons gegen Gesamtzahl der Signalereignisse (True werks wurden verschiedene Netzwerk- wird. Für jeden Schnittwert ergibt sich dann eine True Positive Rate und die en die Aktivierung des Hintergrundneu- Positive Rate) als Funktion des prozen- parameter [12] unabhängig voneinander Positive Rate [11]. Des Weiteren wurde die True Negative Rate analog zum obigen rons aufgetragen. Als Maß für die Leis- tualen Anteils der fälschlicherweise als variiert und der Effekt der Variation an- und als Funktion der True Positive Rate dargestellt. tungsfähigkeit des Netzwerks wird hier Signalereignis klassifizierten Ereignisse hand der oben diskutierten Visualisie- die Accuracy verwendet. Die Accuracy an der Gesamtzahl der Hintergrunder- rungsmethoden beurteilt, um über wei- In Erwartung einer Steigerung der Leistungsfähigkeit des anfänglichen Ne wird wie folgt berechnet: Formel 1. eignisse (False Positive Rate) aufgetra- tere sinnvolle Variationsmöglichkeiten verschiedene Netzwerkparameter [12] unabhängig voneinander variiert und der E gen. Zur Berechnung der entsprechen- zu entscheiden. anhand der oben diskutierten Visualisierungsmethoden beurteilt, um über Die über die Trainingsepoche gemit- den Wertepaare wird ein Schnittwert Variationsmöglichkeiten zu entscheiden. telte Accuracy wurde jeweils für den auf die Aktivierung des Signalneu- 4. Optimierungsprozess Trainings- und Testdatensatz in der rons bei der Klassifikation des Testda- Accuracy-Kurve in Abhängigkeit der tensatzes nach Abschluss des Trainings 4.1 Variation der Trainingsdauer, hier dargestellt in Trai- gesetzt, sodass4 dessen Optimierungsprozess Aktivierung Aktivierungsfunktion ningsepochen, aufgezeichnet. In ähn- mindestens dem des Schnittwertes ent- licher Weise wurde mit dem über die sprechen muss,4.1 damit dasVariation Ereignis alsderBei Aktivierungsfunktion Einsatz von tanℎ( ) anstelle einer Trainingsepoche gemittelten Loss ver- Signalereignis klassifiziert wird. Bei Einsatz von Für je-anstelle ���ℎ(�) Sigmoid-Funktion, definiert einer Sigmoid-Funktion, als als definiert fahren. Auch dieser wurde in Abhän- den Schnittwert ergibt sich dann eine � �������(�) = �� , 3.2Trainingsdauer, gigkeit der Erzeugte Grafiken wieder in True zur Analyse Positive desdie Rate und Netzwerks entsprechen- Einheiten von Trainingsepochen, ver- de False Positive Rate [11]. Des Weite- In einem Histogramm wurde die Aktivierung eines derwarbeiden NeuronenBeschleunigung eine deutliche auf dem Output-Layer bei der zu bemerken. Da die zu Anfang ve des Trainings anschaulicht. ren wurde die True Negative Rate ana- war eine deutliche Beschleunigung des Klassifikation des Testdatensatzes nach Abschluss des Trainings aufgetragen. Sigmoid-Funktion aufgrundJe klarer der die Trennung geringeren ersten Ableitung zu kleineren Gradienten log zum obigen Verfahren ermittelt und Trainings zu bemerken. Da die zu An- der verschiedenen Aktivierungen, desto eindeutigerdasauch die Klassifizierung. Netzwerk Ergänzend mehr als doppelt so langewurde die zum Erreichen der von beiden Netzwerken In der ROC-Kurve (Receiver Opera- als Funktion der True Positive Rate dar- fang verwendete Sigmoid-Funktion Aktivierung des Signalneurons gegen die Aktivierung maximalen des Hintergrundneurons Accuracy vonaufgetragen. Als Maß rund 84 Prozent für zu benötigen (siehe Abb. 4a). Das mit ��� ting Characteristic curve) ist der pro- gestellt. aufgrund der geringeren ersten Ablei- die Leistungsfähigkeit des Netzwerks wird hier die Accuracy verwendet. Die Accuracy wird wie folgt berechnet: ���ℎ��� �������������� ��������������� + ���ℎ��� �������������� ��������������������� ������� = ������� ���ℎ� ��� �����ℎ��� ���������������� FormelDie 1 über die Trainingsepoche gemittelte Accuracy wurde jeweils für den Trainings- und Testdatensatz in der Accuracy-Kurve in Abhängigkeit der Trainingsdauer, hier dargestellt in Trainingsepochen, aufgezeichnet. In ähnlicher Weise wurde mit dem über die Trainingsepoche gemittelten Loss verfahren. Auch dieser wurde in Abhängigkeit der Trainingsdauer, wieder in Einheiten von Trainingsepochen, doi: 10.7795/320.202104 veranschaulicht.
JUNGE wissenschaft 04 15 / 21 18 | Seite 7 100 100 90 90 80 80 70 70 erreichte Accuracy in % erreichte Accuracy in % 60 60 50 50 40 40 30 30 Accuracy im Accuracy im 20 Trainingsmodus 20 Trainingsmodus 10 Accuracy im Testmodus 10 Accuracy im Testmodus 0 0 0 50 100 150 200 250 0 50 100 150 200 250 Anzahl absolvierter Trainingsepochen Anzahl absolvierter Trainingsepochen a) b) Abb. 5: Accuracy-Kurven bei Einsatz des Nesterov Moments (a) und des Adam-Trainingsalgorithmus (b) tung zu kleineren Gradienten führte, 4.2 Variation des durch mitteln sich starke Schwankun- scheint das Netzwerk mehr als doppelt Trainingsalgorithmus gen in den Gradienten zu einem gewis- so lange zum Erreichen der von bei- sen Grad heraus [13]. den Netzwerken gezeigten maximalen Um das Training weiter zu beschleuni- Accuracy von rund 84 Prozent zu benö- gen, wurden neben Mini-Batch Stochas- Durch den Einfluss des exponenti- tigen (siehe Abb. 4a). Das mit tanℎ( ) tic Gradient Descent (SGD) mit Moment ell gemittelten arithmetischen Mittels trainierte Netzwerk ließ sich durch eine SGD mit Nesterov Moment und Adam und der Quadrate der zuvor berechne- Verkleinerung der Learning Rate auf (Adaptive Moment Estimation) als Trai- ten Gradienten kombiniert der Trai- 10−6 weiter verbessern, da so die Fluktua- ningsalgorithmen erprobt. ningsalgorithmus Adam RMSProp (ex- tionen der Accuracy im Testdatensatz re- ponentielles Mitteln der Quadrate der duziert werden konnten (siehe Abb. 4b). Ziel der Verwendung des Nesterov Mo- Gradienten) und Moment (exponentiel- ments nach Definition in [7] ist der Ein- les Mitteln der zuvor berechneten Gra- bezug der über den Trainingsprozess dienten). Hierdurch ist ebenfalls eine bereits berechneten Gradienten. Hier- Beschleunigung des Lernprozesses zu a) b) Abb 6: Die Verteilungen der Parameter der Inputdaten (event shapes) im Trainingsdatensatz weist eine sehr große Varianz auf. Hier ist exemplarisch die Verteilung des Inputparameter fractionInTransverseRms (a) und hits (b) gezeigt (siehe Tab 1 für Erläuterung der Parameter). doi: 10.7795/320.202104
Physik | Seite 8 Aktivierung des Signalneurons bei Klassifizierung von Hintergrundereignissen Aktivierung des Signalneurons bei Klassifizierung von Hintergrundereignissen Aktivierung des Signalneurons bei Klassifizierung von Signalereignissen Aktivierung des Signalneurons bei Klassifizierung eines Signalereignisses 4000 4000 3500 3500 3000 3000 2500 2500 Häufigkeit Häufigkeit 2000 2000 1500 1500 1000 1000 500 500 0 0 0 1 und größer -1 0,8 0,9 1,1 -0,3 -0,2 -0,1 0,1 0,2 0,3 0,4 0,5 0,6 0,7 -0,6 -0,5 -0,4 -0,9 -0,8 -0,7 0 1 und größer -1 -0,1 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,1 -0,4 -0,3 -0,2 -0,6 -0,5 -0,9 -0,8 -0,7 Aktivierung des Signalneurons Aktivierung des Signalneurons 4.2Variation a) des Trainingsalgorithmus b) 4.2Variation des Trainingsalgorithmus 4.2Variation Um das Abb. 7: Training des Trainingsalgorithmus weiter (a) Aktivierung zudes beschleunigen, wurden Signalneurons neben Mini-Batch bei Klassifizierung Stochastic von Gradient Signal- und Descent Hintergrundereignissen Um das Training weiter zu beschleunigen, wurden neben Mini-Batch Stochastic Gradient Descent für das (SGD) Ummit das mit Moment Normalisierung Training SGD weiter zu mit trainierte Nesterov Netzwerk. beschleunigen, Moment und (b) Aktivierung wurden neben Adam (Adaptive des MomentGradient Signalneurons Mini-Batch Stochastic Estimation) bei als Klassifizierung Descent von Signal- und (SGD) mit Moment SGD für Hintergrundereignissen mit das Nesterov Moment und Adam ohne Normalisierung (Adaptive trainierte Moment Estimation) als Netzwerk. Trainingsalgorithmen erprobt. (SGD) mit Moment SGD mit Nesterov Moment und Adam (Adaptive Moment Estimation) als Trainingsalgorithmen erprobt. Trainingsalgorithmen Ziel der Verwendung erprobt. 4.2Variation des Trainingsalgorithmus des Nesterov Moments nach Definition in [7] ist der Einbezug der über den Ziel der Verwendung des Nesterov Moments nach Definition in [7] ist der Einbezug der über den Trainingsprozess Ziel das Um Training bereits der Verwendung desberechneten weiter zuNesterov Gradienten. Moments beschleunigen, nach wurden Hierdurch Definitionmitteln in [7]sich neben Mini-Batch ist starke Schwankungen der Einbezug der überin den den Trainingsprozess bereits berechneten Gradienten. Hierdurch mitteln sich Stochastic Gradient starke Schwankungen Descent in den Gradienten zu einem Trainingsprozess (SGD)Für mitdie Moment gewissen bereits SGD mit Grad heraus berechneten Nesterov [13] Gradienten. Moment . Hierdurch mitteln sich starke Schwankungen in den und Adam (AdaptiveMoments Moment Estimation) als erwarten. Gradienten zu Parameter einem gewissen und Die 1 Grad 2heraus [13]. Verwendung des Nesterov der Testdatensatz eine kleinere Varianz Gradienten zu einem Trainingsalgorithmen erweisen sich die gewissen erprobt. Standardwerte Grad von heraus [13]. resultierte lediglich in einer unwesent- aufweisen könnte. Zudem wurde durch Durch den Einfluss des exponentiell gemittelten arithmetischen Mittels und der Quadrate der zuvor Durch 0,9 bzw. den Einfluss 0,999Verwendung als des gute Wahl. exponentiell Die gemittelten erstenMoments lichennach arithmetischen Verbesserung Mittels des und der Netzwerks, Quadrate Adam der zuvor der Trainingsprozess beschleu- berechneten Durch Ziel derden Gradienten Einfluss des kombiniert Nesterov der desexponentiell Trainingsalgorithmus gemittelten DefinitionAdam arithmetischen [7]RMSProp inMittelsist und (exponentielles der der Quadrate Einbezug der der Mitteln überzuvor den und berechneten zweiten der Quadrate berechneten Gradienten Momente der der kombiniert Gradienten) Gradienten Verteilung und der Trainingsalgorithmus Moment kombiniert der die sich auf ca. (exponentielles Trainingsalgorithmus 0,1 Adam Prozent Mitteln der RMSProp Adam sich zuvor RMSProp (exponentielles beschränk- berechneten nigt. Mitteln Die Learning Gradienten). (exponentielles Mitteln Rate konnte für das Trainingsprozess bereits berechneten Gradienten. Hierdurch mitteln starke Schwankungen in den der der der Quadrate der Gradienten Hierdurch ist Quadrate Gradienten im Gradienten) ebenfalls zuder eine Gradienten) einem und Moment Iterationsschritt, Beschleunigung gewissenund GradMoment te.(exponentielles Bei des Einsatz Lernprozesses [13]Lernprozesses heraus(exponentielles . Mitteln des Adam zu der zuvor erwarten. berechneten Trainingsal- Für die Gradienten). mit ParameterAdam Mitteln der zuvor berechneten Gradienten). � � trainierte und Netzwerk von 10−6 Hierdurch hier als ist bzw. ebenfalls eine bezeichnet, Beschleunigung werden des gorithmus zu erwarten. Für die Ac- Parameter � und 0,999war eineWahl. Erhöhung der wieder �auf � 10 gesteigert werden. −5 �� erweisen Hierdurch istsich die Standardwerte ebenfalls von 0,9 eine Beschleunigung bzw. als gute des Lernprozesses zu Die ersten erwarten. Fürund die zweiten ParameterMomente � erweisen sich die Standardwerte von 0,9 bzw. 0,999 als gute Wahl. Die ersten und zweiten � und Momente in derder �in Durch [14] den vorgestellten Einfluss Verteilung �� erweisen der des Weise Gradienten im in exponentiell je- curacy gemittelten Iterationsschritt�, auf hier 96,8 als � Prozent arithmetischen bzw. � in Mittels und und bezeichnet, rund der sich die Standardwerte von 0,9 bzw. 0,999 als gute Wahl. Die ersten und zweiten Momente Quadrate werden in der der zuvor in [14] hier als � bzw. � RMSProp in [14] dem der VerteilungGradienten berechneten Trainingsschritt vorgestellten der Gradienten Weise berechnet. in jedem im Iterationsschritt�, kombiniert der Trainingsalgorithmus 98,6 Trainingsschritt Prozent berechnet. im Adam bezeichnet, Testdatensatz zu beob-werden in der Mitteln (exponentielles der Verteilung der Gradienten im Iterationsschritt�, hier als � bzw. � bezeichnet, werden in der in [14] 4.3 Normalisierung vorgestellten der Quadrate Weise in jedem Trainingsschritt der Gradienten) und Moment berechnet. (exponentielles achten. Die leicht Mitteln der zuvor höhere berechneten Accuracy im Gradienten). vorgestellten � = � � Weise + (1 in � − jedem ) ⋅ � Trainingsschritt berechnet. Hierdurch � =� � � ist ��ebenfalls � eine � + (1 − � ) ⋅ � �� Beschleunigung des Lernprozesses Testdatensatz � ist aufzu erwarten. die im Für die Vergleich Parameter Da die�Inputwerte � und eine große Spann- � � bzw. =nach � erweisen �� + (1 �� �Bias-Korrektur sich die− �� ) ⋅ � Standardwerte von 0,9 bzw.Trainingsdatensatz zum 0,999 als gute Wahl. geringere Die ersten und Da- zweiten breite Momente von mehreren Größenordnun- bzw. nach der Bias-Korrektur bzw.Verteilung nach Bias-Korrektur der Gradienten im Iterationsschritt�, tenmenge hier als � bzw. � zurückzuführen, bezeichnet, wodurch werden genin der in [14] abdeckten (siehe unten), erschien bzw. nach � Bias-Korrektur � = � Weise in jedem Trainingsschritt berechnet. vorgestellten � =1� − �� � = 1 − �� � =1 � ���� + (1 − � ) ⋅ � � = ���− ⋅ � �− 1 + (1 −��� ) ⋅ ��� 120 � = �� ⋅ � − 1 + (1 − �� ) ⋅ �� bzw. � nach = nach Bias-Korrektur − 1 + (1 − �� ) ⋅ � �� ⋅ �Bias-Korrektur bzw. 100 bzw. nach � Bias-Korrektur bzw. nach � Bias-Korrektur bzw.=nach � Bias-Korrektur � = 1 �− �� � =1− � �� erreichte Accuracy in % 80 � = 1 − �� � =1 ��−⋅ �� − 1 + (1 − �� ) ⋅ �� Wobei � � für die in Iterationsschritt � berechneten Gradienten steht. Die Parameter im Wobei � für die in Iterationsschritt � berechneten 60 Gradienten steht. Die Parameter im bzw. Wobei nach für �die Iterationsschritt�, � werden � Bias-Korrektur nach folgendem� Prinzip in Iterationsschritt in jedemGradienten berechneten Trainingsschritt berechnet: steht. Die Parameter im WobeiIterationsschritt�, für die in � werden nach Iterationsschritt � folgendem Prinzip in jedem Trainingsschritt berechnet: � Iterationsschritt�, �� � werden nach folgendem Prinzip in jedem Trainingsschritt berechnet: � = � ��Gradienten berechneten −�⋅ � steht. Die Pa- 40 � =1 �− �− � � ⋅ � ��+ � rameter � =im Iterationsschritt �� � �� − � ⋅ � � + �� werden Accuracy im Trainingsmodus nach Wobei folgendem �die � in + �Iterationsschritt Prinzip � als�Learning für jedem inund alsTrai- Konstante� fürberechneten Gradienten steht. Die Parameter im 20 mit Rate numerische Stabilität. Accuracy im Testmodus mit � alsberechnet: ningsschritt Learning��Rate Iterationsschritt�, und nach werden als Konstante folgendem für numerische Prinzip in jedemStabilität. Trainingsschritt berechnet: mit � als Learning Rate und als Konstante für numerische 0 Stabilität. � 0 100 200 300 400 500 600 700 � = � �� − � ⋅ Anzahl absolvierter Trainingsepochen � � + � Abb. 8: Accuracy in Abhängigkeit der Trainingsdauer in Trainingsepochen. mit � als Learning Rate und als Konstante für numerische Stabilität. Das abgebildete Netzwerk besaß 3 Hidden-Layer zu je 69 Neuronen und mit als Learning Rate und ϵ als Kons- wurde mit Adam als Trainingsalgorithmus über 600 Trainingsepochen tante für numerische Stabilität. trainiert. Als Aktivierungs- bzw. Loss-Funktion wurde tanh(x) bzw. MSE verwendet. Die Learning Rate betrug 10−5. doi: 10.7795/320.202104
JUNGE wissenschaft 04 15 / 21 18 | Seite 9 a) b) Abb. 9: (a) Korrelation der Aktivierungen der Neuronen auf dem Output-Layer für das vergrößerte Netzwerk mit 3 Hidden-Layern zu je 69 Neuronen. (b) Korrelation der Aktivierungen der Neuronen auf dem Output-Layer für das Netzwerk mit 2 Hidden-Layern zu je 40 Neuronen. die Normalisierung des Inputs sinnvoll. eine etwa dreimal so lange Trainings- unter Berücksichtigung einer wahr- Ebenfalls wurde die Normalisierung dauer bis zum Erreichen eines Plateaus scheinlichen Verbesserung durch Trai- der an die jeweils nächste Schicht von in der Accuracy nötig, da nun die An- ning mit mehr Inputdaten, zu einer Neuronen übergebenen Aktivierungen, zahl der zu erlernenden Parameter um vielversprechenden Alternative zur der- auch bekannt als Batch Normalization, die Anzahl der Gewichte und Bias-Wer- zeit verwendeten Likelihood-Methode. erprobt. te der zusätzlichen Neuronen und Hid- den-Layer erhöht ist. Die Aktivierungen Danksagung So wurde zunächst eine Transformation der beiden Output-Neuronen sind ge- vorgenommen, um eine Verteilung mit mäß Abb. 9 korreliert. Diese Arbeit entstand im Rahmen der einer Varianz von 1 und einem Mittel zweiwöchigen CERN-Projektwochen, von 0 zu halten. 5. Zusammenfassung eine Initiative des Netzwerks Teilchen- und Fazit welt. Während dieser Zeit ermöglichte Wider Erwarten resultierte die Normie- die Integration in die CAST-Kollabora- rung der Inputdaten in keiner merkli- Durch Variation der verschiedenen Pa- tion die Arbeit am Experiment vor Ort chen Verbesserung, sodass beispielswei- rameter wie die Learning Rate und die in Genf und die Erstellung dieser Ar- se die Verteilung der Aktivierungen des Aktivierungsfunktion konnte die Leis- beit. Signalneurons, wie in Abb. 7 gezeigt, tungsfähigkeit des selbstgeschriebenen nur wenige Unterschiede aufwies. Netzwerks drastisch gesteigert werden. An dieser Stelle möchte ich mich be- Zur Analyse des Einflusses der jeweili- sonders bei Sebastian Schmidt bedan- 4.4 Variation der Anzahl und gen Parameter wurden selbstgenerierte ken, der mich während des gesamten Größe der Hidden-Layer Grafiken herangezogen. Mit der besten Zeitraumes mit Rat und Tat unterstützt gefundenen Kombination der Parame- hat. Weiterhin gilt mein Dank Dr. Va- Die maximal im Testdatensatz erreichte ter konnten schlussendlich ca. 99,6 Pro- leriani-Kaminski, Priv.-Doz. Dr. Phil- Accuracy von ca. 99.6 Prozent im Trai- zent aller Ereignisse richtig klassifiziert lip Bechtle sowie Dr. Claudia Behnke ningsdatensatz (siehe Abb. 8) konnte werden. und Susanne Dührkoop, ohne die die durch Erweiterung des Netzwerks von 2 Durchführung des Projekts am CERN auf 3 Hidden-Layer und der Erhöhung Die anfängliche Hypothese über die nicht möglich gewesen wäre. Eben- der Anzahl der Neuronen auf diesen gute Eignung eines Neuronalen Netz- so möchte ich Dr. Schiffbauer für sei- Hidden-Layern auf jeweils 69 Neuronen werks dieses Typs für die Datenklassifi- ne Unterstützung bei organisatorischen noch gesteigert werden. Auch die Ac- kation konnte somit im Rahmen dieser Fragen und dem Gutachter für seine curacy im Trainingsdatensatz ließ sich Arbeit bestätigt werden. Die erreich- wertvollen Anregungen und Korrek- leicht auf ca. 97,8 Prozent erhöhen. Al- te Zuverlässigkeit der Klassifizierung turvorschläge zu diesem Artikel herz- lerdings ist, wie in Abb. 8 zu erkennen, macht diesen Typ Netzwerk, mehr noch lich danken. doi: 10.7795/320.202104
Physik | Seite 10 Literaturverzeichnis [12] Raschka, Sebastian. Python Machine Lear- ning. Birmingham, UK: Packt Publishing Ltd., [1] Welt der Physik. [Online] Deutsche Physikali- 2015. ISBN: 978-1-78355-513-0. sche Gesellschaft, Bundesministerium für Bil- [13] Gylberth, Roan. Momentum Method and Nes- dung und Forschung. [Zitat vom: 22.03.2020.] terov Accelerated Gradient. [Online] Medium, https://www.weltderphysik.de/gebiet/uni- 02.05.2018 [Zitat vom: 28.03.2020] https:// versum/dunkle-energie/. medium.com/konvergen/momentum-met- [2] Schmidt, Sebastian. Search for particles be- hod-and-nesterov-accelerated-gradient- yond the SM using an InGrid detector at CAST. 487ba776c987. [Masterarbeit] s.l.: Universität Bonn, 2016. [14] Kingma, Diederik P. and Jimmy Ba. Adam: [3] Anastassopoulos, V., Aune, S., Barth, K. et al. A Method for Stochastic Optimization. New CAST limit on the axion–photon Corrnell University. [Online] 2014. [Zitat vom: interaction. Nature Physics. Creative 21.03.2020] https://arxiv.org/pdf/1412.6980. Commons License siehe: http://creativecom- pdf. mons.org/licenses/by/4.0/, 2017. [15] CERN- Accelerating Science. CAST. [Online] [4] Schmidt, Sebastian. Verbesserung der Unter- 20.03.2020. https://home.cern/science/expe- grundunterdrückung eines neuen CAST-De- riments/cast. tektors mittels multivariater Methoden aus [16] Bin Shi, S.S. Iyengar. Mathematical Theories of TMVA. [Bachelorarbeit] s.l.: Universität Bonn, Machine Learning - Theory and Applications. 09 2013. s.l.: Springer Nature Switzerland AG, 2020. [5] Krieger, Christoph. Search for solar chame- ISBN 978-3-030-17075-2. leons with an InGrid based X-ray detector at [17] 17. Liao, Yuan-Hong. GitHub. [Online] the CAST experiment. Bonn: s.n., 2017. 13.03.2017. [Zitat vom: 20.03.2020] https:// [6] NumPy. NumPy v1.18 Manual. [Online] The github.com/andrewliao11/dni.pytorch/blob/ SciPy community, 05.02.2020 [Zitat vom: master/mlp.py. 20.03.2020] https://numpy.org/doc/1.18/. [18] (IAXO), The International Axion [7] PyTorch. [Online] Facebook, Inc, 2017. [Zitat Observatory. ResearchGate. [Online] [Zitat vom: 20.03.2020] https://pytorch.org/tutori- vom: 20.03.2020] https://www.researchgate. als/beginner/former_torchies/tensor_tutori- net/figure/Basic-setup-of-an-axion-heliosco- al_old.html. pe-converting-solar-axions-in-a-strong-labo- [8] Pedregosa et. al. Scikit-learn: Machine ratory_fig2_282535931. Learning in Python,. Journal of Machine [19] Bonaccorso, Guiseppe. Mastering Machine Learning Research. 2011. Learning Algorithms: Eypert techniques to [9] community, SciPy. Scipy.org. Random implement popular machine learning sampling (numpy.random). [Online] algorithms and fine-tune your models. 26.07.2019 [Zitat vom: 20.03.2020] https:// Birmingham, UK: Packt Publishing Ltd., 2018. docs.scipy.org/doc/numpy/reference/random/ ISBN: 978-1-78862-111-3. index.html. [10] Brownlee, Dr. Jason. Machine Learning Mastery – Making Developers Awesome at Machine Learning. Why One-Hot Encode Data in Machine Learning? [Online] 28.07.2017 [Zitat vom: 20.03.2020] https://machinelear- ningmastery.com/why-one-hot-encode-data- in-machine-learning/. [11] Brownlee, Dr Jason. Machine Learning Mastery – Making Developers Awesome in Machone Learning. ROC Curves and Precision- Recall Curves for Imbalanced Classification. [Online] 14.01.2020 [Zitat vom: 20.03.2020] https://machinelearningmastery.com/roc-cur- ves-and-precision-recall-curves-for-imbalan- ced-classification/. doi: 10.7795/320.202104
JUNGE wissenschaft 04 15 / 21 18 | Seite 11 doi: 10.7795/320.202104
Physik | Seite 12 Publiziere auch Du hier! Forschungsarbeiten von Schüler/Inne/n und Student/Inn/en In der Jungen Wissenschaft wer- den Forschungsarbeiten von Schüler- Innen, die selbstständig, z. B. in einer Schule oder einem Schülerforschungs zentrum, durch geführt wurden, ver- Wie geht es nach dem öffentlicht. Die Arbeiten können auf Einreichen weiter? Deutsch oder Englisch geschrieben sein. Die Chefredakteurin sucht einen ge- Wer kann einreichen? eigneten Fachgutachter, der die in- haltliche Richtigkeit der eingereichten SchülerInnen, AbiturientInnen und Arbeit überprüft und eine Empfehlung Studierende ohne Abschluss, die nicht ausspricht, ob sie veröffentlicht wer- älter als 23 Jahre sind. den kann (Peer-Review-Verfahren). Das Gutachten wird den Euch, den AutorIn- Was musst Du beim nen zugeschickt und Du erhältst gege- Einreichen beachten? benenfalls die Möglichkeit, Hinweise des Fachgutachters einzuarbeiten. Lies die Richtlinien für Beiträge. Sie ent- halten Hinweise, wie Deine Arbeit auf- Die Erfahrung zeigt, dass Arbeiten, die gebaut sein soll, wie lang sie sein darf, z. B. im Rahmen eines Wettbewerbs wie wie die Bilder einzureichen sind und Jugend forscht die Endrunde erreicht welche weiteren Informationen wir be- haben, die besten Chancen haben, die- nötigen. Solltest Du Fragen haben, dann ses Peer-Review-Verfahren zu bestehen. wende Dich gern schon vor dem Ein- reichen an die Chefredakteurin Sabine Schließlich kommt die Arbeit in die Re- Walter. daktion, wird für das Layout vorberei- tet und als Open-Access-Beitrag veröf- Lade die Erstveröffentlichungserklärung fentlicht. herunter, drucke und fülle sie aus und unterschreibe sie. Was ist Dein Benefit? Dann sende Deine Arbeit und die Erst- Deine Forschungsarbeit ist nun in ei- veröffentlichungserklärung per Post an: ner Gutachterzeitschrift (Peer-Review- Die Junge Wissenschaft wird zusätzlich Journal) veröffentlicht worden, d. h. Du in wissenschaftlichen Datenbanken ge- Chefredaktion Junge Wissenschaft kannst die Veröffentlichung in Deine listet, d. h. Deine Arbeit kann von Ex- Dr.-Ing. Sabine Walter wissenschaftliche Literaturliste auf- perten gefunden und sogar zitiert wer- Paul-Ducros-Straße 7 nehmen. Deine Arbeit erhält als Open- den. Die Junge Wissenschaft wird Dich 30952 Ronnenberg Access-Veröffentlichung einen DOI durch den Gesamtprozess des Erstellens Tel: 05109 / 561508 (Data Object Identifier) und kann von einer wissenschaftlichen Arbeit beglei- Mail: sabine.walter@verlag- entsprechenden Suchmaschinen (z. B. ten – als gute Vorbereitung auf das, was jungewissenschaft.de BASE) gefunden werden. Du im Studium benötigst. doi: 10.7795/320.202104
JUNGE wissenschaft 04 15 / 21 18 | Seite 13 ein. Für die weitere Bearbeitung und Richtlinien die Umsetzung in das Layout der Jungen Wissenschaft ist ein Word- für Beiträge Dokument mit möglichst wenig Formatierung erforderlich. (Sollte dies Schwierigkeiten bereiten, setzen Für die meisten Autor/Inn/en ist dies die Sie sich bitte mit uns in Verbindung, damit wir gemeinsam eine Lösung erste wissenschaftliche Veröffentlichung. finden können.) Die Einhaltung der folgenden Richtlinien hilft allen – den Autor/innen/en und dem ■ Senden Sie mit dem Beitrag die Redaktionsteam Erstveröffentlichungserklärung ein. Diese beinhaltet im Wesentlichen, dass der Beitrag von dem/der angegebenen AutorIn stammt, Die Junge Wissenschaft veröffentlicht Sponsoren, mit vollständigem Namen keine Rechte Dritter verletzt Originalbeiträge junger AutorInnen bis angefügt werden. Für die Leser kann werden und noch nicht an anderer zum Alter von 23 Jahren. ein Glossar mit den wichtigsten Stelle veröffentlicht wurde (außer Fachausdrücken hilfreich sein. im Zusammenhang mit Jugend ■ Die Beiträge können auf Deutsch forscht oder einem vergleichbaren oder Englisch verfasst sein und ■ Bitte reichen Sie alle Bilder, Wettbewerb). Ebenfalls ist zu sollten nicht länger als 15 Seiten mit Grafiken und Tabellen nummeriert versichern, dass alle von Ihnen je 35 Zeilen sein. Hierbei sind Bilder, und zusätzlich als eigene verwendeten Bilder, Tabellen, Grafiken und Tabellen mitgezählt. Dateien ein. Bitte geben Sie bei Zeichnungen, Grafiken etc. von Anhänge werden nicht veröffentlicht. nicht selbst erstellten Bildern, Ihnen veröffentlicht werden dürfen, Deckblatt und Inhaltsverzeichnis Tabellen, Zeichnungen, Grafiken also keine Rechte Dritter durch die zählen nicht mit. etc. die genauen und korrekten Verwendung und Veröffentlichung Quellenangaben an (siehe auch verletzt werden. Entsprechendes ■ Formulieren Sie eine eingängige Erstveröffentlichungserklärung). Formular ist von der Homepage Überschrift, um bei der Leserschaft Senden Sie Ihre Bilder als www.junge-wissenschaft.ptb.de Interesse für Ihre Arbeit zu wecken, Originaldateien oder mit einer herunterzuladen, auszudrucken, sowie eine wissenschaftliche Auflösung von mindestens 300 dpi auszufüllen und dem gedruckten Überschrift. bei einer Größe von 10 ∙ 15 cm! Beitrag unterschrieben beizulegen. Bei Grafiken, die mit Excel erstellt ■ Formulieren Sie eine kurze, leicht wurden, reichen Sie bitte ebenfalls ■ Schließlich sind die genauen verständliche Zusammenfassung die Originaldatei mit ein. Anschriften der AutorInnen mit (maximal 400 Zeichen). Telefonnummer und E-Mail- ■ Vermeiden Sie aufwendige und lange Adresse sowie Geburtsdaten und ■ Die Beiträge sollen in der üblichen Zahlentabellen. Fotografien (Auflösung 300 dpi bei Form gegliedert sein, d. h. Einleitung, einer Bildgröße von mindestens Erläuterungen zur Durchführung ■ Formelzeichen nach DIN, ggf. 10 ∙ 15 cm) erforderlich. der Arbeit sowie evtl. Überwindung IUPAC oder IUPAP verwenden. von Schwierigkeiten, Ergebnisse, Gleichungen sind stets als ■ Neulingen im Publizieren werden Schlussfolgerungen, Diskussion, Größengleichungen zu schreiben. als Vorbilder andere Publikationen, Liste der zitierten Litera tur. In z. B. hier in der Jungen Wissenschaft, der Einleitung sollte die Idee zu ■ Die Literaturliste steht am Ende der empfohlen. der Arbeit beschrieben und die Arbeit. Alle Stellen erhalten eine Aufgabenstellung definiert werden. Nummer und werden in eckigen Außerdem sollte sie eine kurze Klammern zitiert (Beispiel: Wie Darstellung schon bekannter, in [12] dargestellt …). Fußnoten ähnlicher Lösungsversuche enthalten sieht das Layout nicht vor. (Stand der Literatur). Am Schluss des Beitrages kann ein Dank an ■ Reichen Sie Ihren Beitrag sowohl in Förderer der Arbeit, z. B. Lehrer und ausgedruckter Form als auch als PDF doi: 10.7795/320.202104
Physik | Seite 14 @ Impressum Impressum wissenschaft Junge Wissenschaft c/o Physikalisch-Technische Bundesanstalt (PTB) www.junge-wissenschaft.ptb.de Redaktion Dr. Sabine Walter, Chefredaktion Junge Wissenschaft Paul-Ducros-Str. 7 30952 Ronnenberg E-Mail: sabine.walter@verlag- jungewissenschaft.de Tel.: 05109 / 561 508 Verlag Dr. Dr. Jens Simon, Pressesprecher der PTB Bundesallee 100 38116 Braunschweig E-Mail: jens.simon@ptb.de Tel.: 0531 / 592 3006 (Sekretariat der PTB-Pressestelle) Design & Satz Sabine Siems Agentur „proviele werbung“ E-Mail: info@proviele-werbung.de Tel.: 05307 / 939 3350 doi: 10.7795/320.202104
Sie können auch lesen

















































