Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau Masterarbeit - unipub
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau Masterarbeit zur Erlangung des akademischen Grades eines Masters of Arts an der Karl-Franzens-Universität Graz vorgelegt von Ing. Michael Fleck, BA am Zentrum für Informationsmodellierung Austrian Centre for Digital Humanities Begutachter: Univ. Prof. Dr. Georg Vogeler, MA Graz, am 27. Mai 2022
Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau Inhaltsverzeichnis 1. Einführung ................................................................................................................................. 3 2. Theoretischer Rahmen ............................................................................................................... 6 2.1. Deutsche Wochenschau (1940-1945) ........................................................................................6 2.2. Einbettung der Projektarbeit in den Kontext der Digitalen Geisteswissenschaften................9 2.3. Stand der Forschung zur automatischen Annotation audiovisueller Quellen .......................11 2.4. Grundlagen künstlicher Intelligenz .........................................................................................14 2.5. Zusammenfassung...................................................................................................................17 3. Automatische Spracherkennung .............................................................................................. 19 3.1. Grundprobleme der automatischen Spracherkennung ..........................................................19 3.2. Open-Source Modelle ..............................................................................................................22 3.3. Evaluierung der Qualität von automatischer Spracherkennung............................................28 3.4. Rechtliche Hindernisse in der Cloud ........................................................................................33 3.5. Zusammenfassung...................................................................................................................35 4. Automatische Annotation und Erschließung ............................................................................ 36 4.1. Optimieren der Spracherkennung ...........................................................................................37 4.2. Erschließungen basierend auf den transkribierten Text ........................................................39 4.3. Erschließung des graphischen Inhalts .....................................................................................41 4.4. Automatische Erstellen eines TEI-Dokuments ........................................................................46 Exkurs: Erschließung eines Sujets der Tobis-Wochenschau (um 1930) .........................................50 4.5. Zusammenfassung...................................................................................................................51 5. Ausblick & Conclusio ................................................................................................................ 53 Bibliographie ............................................................................................................................... 56 Literatur ..........................................................................................................................................56 Online-Ressourcen ..........................................................................................................................58 Anhang ........................................................................................................................................ 61 Code-Repositorien ..........................................................................................................................61 Abkürzungsverzeichnis ...................................................................................................................61 2
Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau 1. Einführung Seit im Jahr 1860 der Franzose Édouard-Léon Scott de Martinville Schallwellen mit einem Phonoautographen aufzeichnete, 1877 der Phonograph von Thomas A. Edison und 1887 die Schallplatte von Emil Berliner erfunden wurde, der erste öffentliche Rundfunk 1923 in Berlin seinen Betrieb aufnahm, die ersten Lichtspieltheater um die Jahrhundertwende öffneten und dort seit den 1920er Jahren Tonfilme gezeigt werden, wurden bis heute Unmengen an Ton- und Filmdokumente produziert. Bild, Ton und Video sind die entscheidenden Informationsmedien des 20. und 21. Jahrhunderts. Für die Geisteswissenschaften bedeutet dies eine kaum zu überblickende Menge an audiovisuellen Daten. Die leichte Verfügbarkeit von Aufnahme- und Verbreitungsgeräten macht es heute möglich, dass jede Sekunde mehrere hundert Stunden an Videos auf Plattformen wie YouTube oder TikTok hochgeladen werden. Es ist klar, dass diese Datenmengen in Zukunft automatisiert (vor-)erschlossen werden müssen, um sie jemals einer wissenschaftlichen Analyse zugänglich zu machen. Dieses Projekt widmet sich der Deutschen Wochenschau von 1940 bis 1945. Sie erschien zu einer Zeit als das Medium Film bereits zu einem Massenphänomen aufgestiegen war und es im nationalsozialistischen Deutschland dazu diente, die Bevölkerung zur Erreichung der Kriegsziele zu mobilisieren. Aufgrund der hohen Popularität und des medialen Eindrucks, direkt in das Kriegsgeschehen eingebunden zu sein, war sie eines der wichtigsten Propagandamittel im Dritten Reich. Die Kriegswochenschauen wurden bereits vielfach rezipiert, jedoch wurden Forschungen aufgrund technischer Hürden bislang primär auf qualitativer Ebene durchgeführt. Die Erfolge der letzten zehn Jahre im Bereich Künstlicher Intelligenz erlauben es den Digitalen Geisteswissenschaften Natural Language Processing (NLP) nicht mehr nur ausschließlich auf textuelle Daten anzuwenden, sondern Quellen in Bild und Ton einzubinden. Deep-Learning-Algorithmen erreichen in Bereichen wie automatischer Sprach- und Bilderkennung Erkennungsraten, welche ausreichend hoch sind, um die durch sie gewonnenen Daten einer belastbaren Analyse zuzuführen. Dies ergibt nun die Möglichkeit, historische Videoaufnahmen automatisiert zu erschließen und zu annotieren, um mit den daraus gewonnenen Informationen eine tiefgreifende Indexierung durchzuführen und daran anknüpfend neue analytische Möglichkeiten zu eröffnen. Aufgrund der starken Fokussierung der Digitalen Geisteswissenschaften auf textuelle Daten gibt es bis dato kaum etablierte Werkzeuge und Methoden, welche diesen Erschließungsprozess begleiten. 3

Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau Ziel dieser Masterarbeit ist es, am Beispiel der Deutschen Wochenschau aufzuzeigen, wie mit audiovisuellen Daten im Kontext der Digitalen Geisteswissenschaften umgegangen werden kann und für den Prozess der Erschließung audiovisueller Quellen passende Werkzeuge bereitzustellen. Um dieses Ziel zu erreichen, teilt sich diese Arbeit in die drei folgenden Abschnitte. Der erste Abschnitt beinhaltet den theoretischen Rahmen, in den das folgende Projekt eingebettet ist. Es wird erläutert, warum sich, neben dem historischen Wert als Quelle, die Deutsche Wochenschau ideal eignet, um sie automatisiert zu annotieren und zu erschließen. Nachfolgend wird am Beispiel der Editionswissenschaft gezeigt, warum Digitale Geisteswissenschaften historisch stark auf textuelle Daten fokussiert sind, um anschließend den aktuellen Stand der Forschung zur automatisierten Annotation audiovisueller Daten zu erheben. Da die meisten in dieser Arbeit verwendeten Technologien auf künstlicher Intelligenz basieren, ist es weiters nötig, sich den Grundlagen dieser Technologie und ihrer wichtigsten Begriffe anzunähern. Der wohl wichtigste Teil im Prozess der Erschließung der Deutschen Wochenschau ist die automatische Erkennung von Gesprochenem, um die ausgiebige Moderation aus dem Off weiterverarbeiten zu können. Aus diesem Grund dient die automatische Spracherkennung (englisch Automatic Speech Recognitionn; ASR) in dieser Arbeit als Beispiel für den Vergleich zwischen quelloffenen und proprietären Lösungen. Dazu wird basierend auf dem von Meta (vormals Facebook) entwickelten ASR-Framework Wav2Vec und einem vortrainierten multilingualen Sprachmodell ein eigenes, den neuesten Entwicklungen entsprechendes, deutsches Spracherkennungsmodell entwickelt, um dessen Erkennungsleistung mit jenen proprietären – vor allem cloudbasierten – Anbietern zu vergleichen. Wie gezeigt wird, erzielen in allgemeinen KI-Anwendungsbereichen, die von kommerziellen Anbietern abgedeckt werden, proprietäre Lösungen bessere Ergebnisse als quelloffene. Im letzten Abschnitt wird mithilfe von Software des Cloudanbieters Amazon Web Services (AWS) ein Python-Skript entwickelt, welches automatisiert übergebene Videodateien erschließt. Zum einen wird mit einer an den NS-Sprachgebrauch angepassten Vokabelliste versucht, die Erkennungsleistung des Spracherkennungsdienst von AWS zu maximieren. Auf Basis des transkribierten Textes werden anschließend einige in den Digitalen Geisteswissenschaften weit verbreitete Methoden wie Entity- Recognition, Sentimentanalyse und Part-of-Speech-Tagging eingesetzt. Die Videospur wird durch Objekt-, Text- und Gesichtserkennung erschlossen. Zuletzt werden die erhaltenen Ergebnisse so transformiert, um sie in ein ebenso automatisiert erstelltes TEI-Dokument einzufügen. Im Vordergrund steht eine einfache Nachnutzbarkeit des erstellten Skripts. Im Schlussteil werden die zentralsten Erkenntnisse und Resultate, welche bei der Durchführung dieses Projektes erzielt wurden, wiedergegeben und ein Ausblick gestellt, wie die in dieser Arbeit 4
Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau verwendeten Technologien und Methoden in weiterer Folge dazu verwendet werden können, um neue wissenschaftliche Fragestellungen hinsichtlich audiovisueller Quellen beantworten zu können. Diese Masterarbeit hat nicht den Zweck eine vollständige Erschließung der Deutschen Wochenschau durchzuführen, sondern prototypisch die Möglichkeiten und Limitationen automatischer, KI- basierter Annotation und Erschließung aufzuzeigen. Aufgrund der Menge an nötigen Rohdaten und der damit verbundenen Probleme aufgrund begrenzter Rechnerkapazitäten (bei freier Software) bzw. der für ein studentisches Projekt zu hohen Kosten (bei Cloudanbietern) beinhaltet diese Masterarbeit keine weiterführende quantitative Analyse der erschlossenen Informationen. Aus sprachlichen Gründen berücksichtigt diese Arbeit lediglich deutsch- und englischsprachige Literatur und Projektarbeiten. Aus Gründen der besseren Lesbarkeit werden anstelle geschlechtsneutraler Sprache männliche und weibliche Formen alternierend verwendet. 5
Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau 2. Theoretischer Rahmen In diesem Kapitel wird der theoretische Rahmen behandelt, in dem die nachfolgende Projektarbeit eingebettet ist. Zunächst wird die Deutsche Wochenschau als historische Quelle vorgestellt und dargelegt, warum sich dieser Quellenkorpus eignet, um ihn automatisiert zu annotieren. Anschließend wird am Beispiel des (digitalen) Edierens erläutert, warum sich die Digitalen Geisteswissenschaften historisch stark auf textuelle Daten konzentrierten. Weiters wird auf den aktuellen Stand der Forschung in den Digitalen Geisteswissenschaften zum Thema Erschließung audiovisueller Quellen eingegangen. Da viele der in dieser Arbeit eingesetzten Werkzeuge auf künstlicher Intelligenz basieren, findet sich zuletzt eine allgemeine Übersicht zu den Konzepten und Begriffen dieser Thematik. 2.1. Deutsche Wochenschau (1940-1945) Gab es in den 1930er Jahren mit der Ufa-Tonwoche, der Deulig-Ton-Woche, Tobis und Fox-Tönende Wochenschau noch vier voneinander unabhängige Wochenschauproduzenten, wurde mit 20. Juni 1940 (Vereinheitlichung des Inhalts, aber weiterhin mit vier verschiedenen Vorspannen) bzw. 21. November 1940 (auch einheitlicher Vorspann) nur mehr eine Wochenschau unter dem Titel Deutsche Wochenschau produziert. Hatte die dezentralisierte mediale Kriegsberichterstattung im Ersten Weltkrieg noch improvisierten Charakter, kontrollierte die Wehrmacht durch ihre Propagandakompanien vom ersten Tag des Krieges an, welches Bildmaterial in den Wochenschauen gezeigt wird.1 Anders als die Vorkriegswochenschauen, die der Vermittlung langfristiger ideologischer Ziele dienten, war der Zweck der Kriegswochenschauen die Mobilisierung der Massen für die Erreichung der gesetzten Kriegsziele, wobei die Kluft zwischen Realität und Anspruch im Laufe des Krieges infolge der Niederlagen an den Fronten deutlich zunahm. 2 Dabei folgen die meisten Wochenschauen im Aufbau einem ähnlichen Muster. Nach dem markanten Intro mit der Wochenschau-Fanfare (bis 1941) 1 Hoffmann 1988, S. 200-201 2 Bartels 2004, S. 519-520. 6
Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau bzw. der Russland-Fanfare 3 (ab dem Krieg gegen die Sowjetunion) basierte das Gestaltungsschema ähnlich wie in Spielfilmen auf einer sich stetig steigenden Spannungskurve, unterbrochen von einzelnen retardierenden Szenen, welche sich in einem finalen Höhepunkt, meist einer kriegerischen Handlung, entlädt. Ulrike Bartels führte in ihrer Dissertation neben einer Zusammenfassung aller Ausgaben eine statistische Analyse der Kriegswochenschauen durch.4 Sie zählte wie häufig einzelne Themenfelder5 pro Jahr vorkamen. Dabei zeigt sich, dass große Teile der Deutschen Wochenschau dazu dienten, Berichte über deutsche Truppen und die Situation an der Front zu schildern (Kriegsberichterstattung) und die Anzahl derartiger Berichte im Laufe des Krieges zunahm („Totaler Krieg“), während andere Themen (Wirtschaft, Sport, Unterhaltung, etc.) stark abnahmen. Die Deutsche Wochenschau für die Jahre 1940-1945 bietet sich aus vielerlei Gründen als Prototyp für eine digitale Tiefenerschließung an. Neben ihrem historischen Wert ist sie zum einen thematisch eng abgegrenzt, da sie sich hauptsächlich mit den Geschehnissen des Zweiten Weltkrieges und dessen unmittelbaren Folgen für das Deutsche Reich beschäftigt. Die einzelnen Ausgaben werden aus dem Off von einem einzigen Sprecher 6 moderiert, während andere Wortmeldungen (z.B. Reden oder Interviews) die Ausnahme bilden. Des Weiteren findet diese Moderation durchgängig statt, es gibt kaum Szenen, in denen ausschließlich Bildsprache vorherrscht. Die in den Wochenschauen verwendete Sprache ist zwar weit von moderner Alltagssprache entfernt, jedoch wird sehr deutlich in Standarddeutsch gesprochen. Es finden sich viele Begrifflichkeiten des Nationalsozialismus und der Wehrmacht, welche in heutigen Wortschätzen nicht mehr vorkommen. Diese Begriffe eignen sich besonders dafür, sie einem Spracherkennungsprogramm explizit beizubringen. 3 Die „Wochenschau-Fanfare“ ist eine Sequenz aus dem Horst-Wessel-Lied. Die „Russland-Fanfare“ wurde aus „Les Préludes“ von Ernst Liszt entnommen. 4 Bartels 2004, S. 422-427 5 Einzelne Themen wurden in eine der folgenden Überkategorien eingeteilt: • Berichte über Deutsche im Ausland u. in • Städte- / Landschaftsbild ehemals dt. Gebieten • Religion • Leben und Arbeit des Bauern • Sport • Feste und Feiern im Jahreslauf • Unterhaltung • Politische Lage Deutschlands • Auslandsberichterstattung • Ausgrenzung bestimmter Bevölkerungsteils • Aufrüstung / kriegsvorbereitende • Arbeitseinsatz / Arbeitsbeschaffung Maßnahmen • Maßnahmen zur Stärkung der • Kriegsberichterstattung Opferbereitschaft • Berichte über eroberte Gebiete • Wissenschaft / Technik • Sonstiges • Kultur (Kunst / Architektur) 6 Hauptsprecher war Harry Giese, der während seiner Gelbsucht-Erkrankung von Walter Tappe vertreten wurde. 7
Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau Ein großer Nachteil dieser Wochenschauen ist ihre sehr geringe Aufnahme- und Digitalisierungsqualität. Im Ton findet sich das für Aufnahmen aus dieser Zeit typische Hintergrundrauschen. Weiters werden die Bilder durch pompöse Musik untermalt, was sich auf die Spracherkennungsqualität negativ auswirken kann. Die Deutsche Wochenschau ist eine der wichtigsten Quellen zur nationalsozialistischen Propaganda. Sie wurde im gesamten Deutschen Reich, den besetzten Ländern und teils im neutralen Ausland gezeigt. Ihre Inhalte erreichten große Teile der Bevölkerung, denn der Besuch von Lichtspieltheatern war eine populäre Freizeitbeschäftigung, wobei die Wochenschauen vor bzw. nach dem Hauptfilm gezeigt wurden. Die propagandistische Wirkung der Wochenschauen überstieg teilweise jene von Presse und Rundfunk. 7 Trotzdem sind ihre Episoden der Jahre 1940-1945 noch kaum online erschlossen. Die hier verwendeten Aufnahmen stammen vom Onlinearchiv Archive.org. Die Videos sind im Jahr 2009 von einer unbekannten Person hochgeladen worden. Von wo diese Digitalisate ursprünglich stammen, konnte nicht eruiert werden. Es sind sehr viele Ausgaben auf Archive.org zu finden. Ob die Sammlung vollständig ist, ist schwer zu beantworten, da es kaum Möglichkeiten zur Kategorisierung auf der Plattform gibt und einzelne Videos nur in Teilen fragmentarisch hochgeladen wurden. In analoger Form liegt die Deutsche Wochenschau vollständig8 im Deutschen Bundesarchiv vor. Die deutschen Wochenschauen (inklusive der Jahre 1940-45) wurden im Bundesarchiv bereits erschlossen und teilweise in SD-Qualität digitalisiert. Dabei wurden die analogen Bänder lediglich mit einer Digitalkamera abgefilmt. In Band 8 der Findbücher zu Beständen des Bundesarchives (1984) ist neben einer stichpunktartigen Zusammenfassung des Inhalts jeder Episode auch ein Personen-, Ort- und Sachregister vorhanden. Es umfasst jedoch nur die Nennungen in diesen Zusammenfassungen, nicht jenen in den Filmaufnahmen. Das Bundesarchiv-Filmarchiv arbeitet bis 2024 daran, alle Wochenschauen in ihren Beständen in 4K- Qualität zu digitalisieren, wobei ein Verfahren angewandt wird, in dem alle Einzelbilder eines Filmbands separat aufgenommen und anschließend digital rekonstruiert werden und somit eine weitaus höhere Videoqualität beinhalten. Bis dato sind einige Wochenschauen aus dem Ersten Weltkrieg, der Weimarer Republik und der Nachkriegszeit online zugänglich9, wobei ein Großteil des 7 Bartels 2004, S. 523 8 Nach Bartels 2004, S. 421, gibt es insgesamt 286 Ausgaben, einige davon jedoch nur noch fragmentarisch. 9 https://www.filmothek.bundesarchiv.de 8
Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau Bestandes des Bundesarchiv aus rechtlichen Gründen nicht online gestellt werden darf.10 Ob die stark politisierenden NS-Wochenschauen dort ebenfalls zugänglich gemacht werden, ist noch unsicher. 11 2.2. Einbettung der Projektarbeit in den Kontext der Digitalen Geisteswissenschaft Digitale Editionen mit den mit ihnen mitgelieferten Analysemethoden gehören zu den zentralen Forschungsinstrumenten der Digitalen Geisteswissenschaft. Wissenschaftliche Editionen sind mit zusätzlichen Informationen aufbereitete Ausgaben von literarischen (Ur-)Texten oder historischen Quellen. Das Edieren gehört seit Jahrhunderten zur geisteswissenschaftlichen und philosophischen Praxis. In den frühen Handschriftkulturen mussten Texte einzeln per Hand abgeschrieben werden, während das Original im Laufe der Zeit verloren ging. So entstanden bewusst und unbewusst Änderungen am originalen Text. Die Editionsphilologie beschäftigt sich damit, aus einzelnen Abschriften Abstammungslinien zu erschließen, um den Ausgangstext möglichst authentisch zu rekonstruieren. Diese als „Lachmannsche“ genannte Methode zur Urtexterschließung ist aber nur ein Aspekt von Editionen. Weitere Zielsetzungen des Edierens kann das Identifizieren der besten verfügbaren Zeugen sein (Leithandschriftenprinzip), die Varianz aller verfügbaren Ausgaben aufzuzeigen (Variorum-Edition), die Art der Entstehung nachzuvollziehen (genetische Edition), einen möglichst lesbaren Text herzustellen, durch diplomatische Ausgaben die Form des überlieferten Dokumentes möglichst nahe zu kommen oder durch Erschließungen den Informationsgehalt eines Textes aufzuzeigen. Unter Erschließung versteht man alle kritischen Eingriffe in einen Text wie die Identifizierung von referenzierbaren Daten, wissenschaftliche Sachanmerkungen bis hin zur allgemeinen Textkritik.12 Der große Nachteil gedruckter Editionen ist die Eindimensionalität von Büchern und letztlich auch deren sehr limitierte Platzverhältnisse. Die Grundeinheit eines gedruckten Werkes ist die Seite, eine Begrenzung, welche es im Digitalen kaum gibt. Während sich aufgrund dessen gedruckte Editionen auf eine der oben genannten Varianten konzentrieren und dabei eine einzige Sicht auf die zugrundeliegende Quelle bietet, kann eine digitale Edition wesentlich offener gestaltet werden und einen Text quellen- und benutzernah (parallel) darstellen. In der Regel sind heutige digitale Editionen 10 https://www.filmothek.bundesarchiv.de/contents_weimar_republic 11 So die Auskunft der Leiterinnen des Filmarchivs, Dr. Petra Rauschenbach und Dr. Adelheit Heftberger, in einem Online-Meeting im April 2022. 12 Sahle 2017, S. 237-239 9
Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau 13 Webapplikationen basierend auf den Standardlösungen HTML, CSS und JavaScript. Die Veröffentlichung im Web und die dadurch große Nähe zum Endnutzer erlaubt es auch, eine Edition bereits im frühen Stadium für zukünftige Benutzer einfach zugänglich zu machen, beispielsweise mit der Veröffentlichung von Teilstücken oder von Vorstufen einer Gesamtedition.14 Die Darstellung einer Edition im Digitalen ermöglicht der Benutzerin interaktiv mit dieser umzugehen. Entschied bei analogen Editionen noch die Autorenschaft, wie und wo etwas dargestellt wurde, erlauben digitale Editionen dem Benutzer selbst auszuwählen, wann welche Elemente auf dem Bildschirm erscheinen. In der Regel bieten digitale Editionen ihre zugrundeliegenden Datensätze zum Download an, um Nutzerinnen die Möglichkeit zu geben, diese weiterzuverwenden oder selbst zu analysieren.15 Für das Anreichern mit zusätzlichen Informationen wird in digitalen Editionen in den meisten Fällen die Text Encoding Initiative (TEI)16 verwendet, welche auf den XML-Standard basiert. Die TEI ist eine Sammlung und Grammatik von etwa 500 verschiedenen Elementen und wird von einer großen Community gepflegt. Die TEI folgt dem Ansatz, dass Texte hierarchisch aufgebaute Abfolgen von Inhaltsobjekten sind.17 Es können sowohl Form als auch Inhalt eines Dokuments erschlossen werden. Mit TEI annotierte Texte sind sowohl maschinen- als auch menschenlesbar. Da die TEI noch wenig zur Beschreibung audiovisueller Quellen verwendet wird, fehlen für einige Annotationsschritte passende Elemente und Attribute, weshalb in diesem Projekt ein leicht adaptiertes Schema des TEI-Standards zum Einsatz kommt. Gedruckte Editionen waren aus technischen und ökonomischen Gründen arm an Bildern und somit zumeist monomedial. Dies ändert sich mit digitalen Editionen, in denen das Darstellen von Scans des originalen Dokuments neben Transkription, diplomatischen Text und eventuell annotierten Text gängige Praxis ist. Dieses Paradigma der Multimedialität kann als Ausgangspunkt weg von der Beschäftigung mit schriftlichen Dokumenten hin zu audiovisuellem Quellen gesehen werden. 13 Sahle 2017, S. 240, 245 14 Sahle 2013, S. 132 15 Fritze 2019, S. 433 16 https://tei-c.org 17 Sahle 2017, S. 245-247 10
Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau 2.3. Stand der Forschung zur automatischen Annotation audiovisueller Quellen „Automatisierte Analysen, Annotierungen und Visualisierungen von Videomaterial sind derzeit in der Entwicklung und werden die Auseinandersetzung mit Bewegtbildern und der ihnen eigenen Sprache auch in den Digital Humanities unterstützen.“18 Wie aus dem vorherigen Unterkapitel hervorgeht, fokussierten sich die Digitale Geisteswissenschaften lange fast ausschließlich auf textuelle Quellen (Manuskripte, Urkunden, Briefe, etc.) und klammerten audiovisuelle Quellen weitgehend aus. Zum einen liegt dies daran, dass neue Technologien zuerst für das Lösen alter Fragestellungen verwendet werden, bevor neue potentielle Fragestellungen erkannt werden, welche durch neue Technologie überhaupt erst beantwortbar sind. Zum anderen brauchte es auch lange Zeit, bis Bestände audiovisueller Quellen erschlossen wurden, wobei chronologisch neue Bestände noch wenig historisches Potential bieten, da sie noch im zeitgenössischen kollektiven Gedächtnis vorhanden sind. Weiters beschränken sich Ton- und Filmarchive weitgehend auf die bloße Digitalisierung ihrer Bestände und weniger auf eine breite inhaltliche Erschließung. 19 Des Weiteren wurden die Digitale Geisteswissenschaften lange von Historikern und Literaturwissenschaftlerinnen geprägt und sind somit primär ergänzend zu diesen textfokussierten Disziplinen tätig. In den Medienwissenschaften werden unter (digitale) Filmeditionen häufig Restaurierungsprojekte verstanden, welche dem Benutzer bei der Wiedergabe historischer Aufnahmen die Möglichkeit geben, zwischen Originalfassung, verschiedenen Überlieferungsfassungen oder redaktionellen Eingriffen zu wählen.20 Als Editionsobjekte dienen bedeutende Werke der Filmgeschichte, wobei das Werk selbst im Mittelpunkt und der historische Wert als Quelle im Hintergrund steht.21 Die historisch- kritische Filmedition kontextualisiert ähnlich der literarischen Edition den Inhalt des Films. Filmeditionen standen vor allem in den 2000er Jahren im Fokus der Medienwissenschaft, weshalb als Trägermedium lange die DVD genutzt wurde. 22 23 Erst in den letzten Jahren wurden Werkzeuge und Methoden der Medienwissenschaft mit jenen der digitalen Geisteswissenschaften verknüpft. Bhargav et al. 2019 filterte und analysierte Untertitel aus 18 Rapp 2017, S. 266 19 Als Beispiel dienen die Filmothek des Bundesarchivs (https://www.filmothek.bundesarchiv.de) und die österreichische Mediathek (https://www.mediathek.at). 20 https://www.udk-berlin.de/universitaet/fakultaet-gestaltung/institute/institut-fuer-zeitbasierte- medien/filminstitut/dvd-als-medium-kritischer-filmeditionen 21 Beispielsweise https://filmeditio.hypotheses.org/film 22 Keitz 2013, S. 33-37 23 Rieger 2021 11
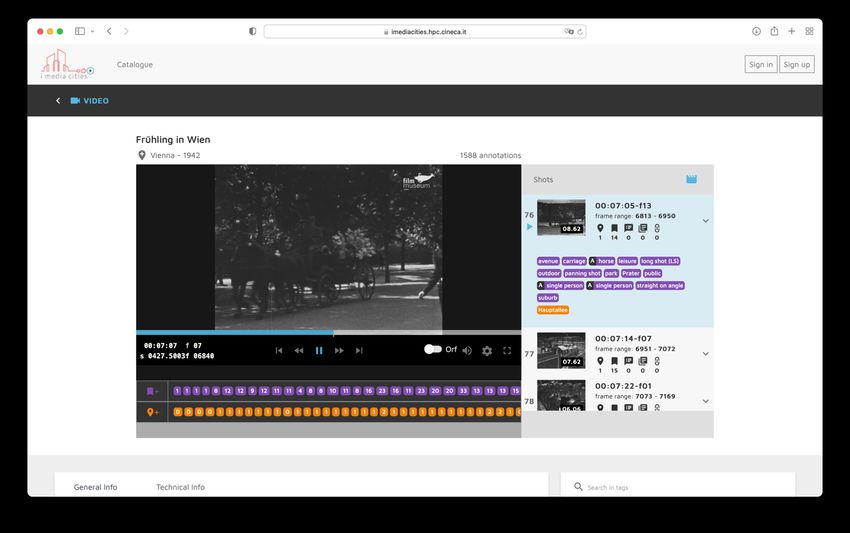
Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau der frühen Stummfilmzeit. Lincoln et al. 2020 und Wevers, Smits 2020 arbeiteten mit Deep-Learning- Algorithmen, um automatisiert Metadaten zu historische Bildaufnahmen hinzuzufügen.24 Lee et al. 2020 entnahmen und analysierten visuelle Inhalte aus 16 Millionen Seiten von amerikanischen Zeitungen und Zeitschriften. Taylor, Lauren 2019 formulierten das Konzept des Distant Viewing, welches dabei helfen soll, Bilder in hoher Skalierung automatisiert zu interpretieren. In der Archäologie wird bereits lange auf KI-unterstütze Algorithmen gesetzt. 25 Engel et al. 2019 nutzen die Google Vision API zur automatischen Bilderkennung. Ein Team der Universität Paderborn entwickelte Modelle zur automatischen Erkennung von Abschnitten, Boxen, Sprechblasen und Text aus Comics und fügten diese Informationen in einem hierarchischen XML-Dokument ein.26 27 Taiwanesische Wissenschaftler entwickelten eine Software, welche althistorische Texte aus China mithilfe externer Datenquellen automatisiert annotiert.28 EUscreen29 ist ein Zusammenschluss von rund 30 Rundfunkanstalten und audiovisuellen Archiven aus ganz Europa. Es stellt für diese Organisationen eine Plattform zur Verfügung, auf der Ton- und Videoinhalte hochgeladen werden können, um sie so einem größeren Publikum zugänglich zu machen. Das Projekt Europeana Subtitled wendet automatische Spracherkennung und Übersetzung an, um Teile des Inhalts von EUscreen zu erschließen und durchsuchbar zu machen.30 Das Team des Sensory Moving Image Archive (SEMIA) Projektes31 erarbeitete einen Prototyp, welcher Medienarchive automatisch anhand von syntaktischen Merkmalen („syntactic features“) kategorisierte. Darunter werden beispielsweise Farben oder Formen, welche in den Videos vorkommen verstanden. Die Entwickler gingen somit weg von der klassischen semantischen Beschreibung der Videos hin zur automatisierten Annotation graphischer Merkmale zur Metadatengenerierung. Im Projekt I-Media-Cities32 wurde eine Videoplattform geschaffen, in welche historische Aufnahmen von Städten und Straßen integriert wurden. Automatisch erschlossen bzw. annotiert wurden Szenen, der Inhalt nach Konzepten (Person, Gebäude, Straßenbahn, etc.) und Gebäude bzw. Monumente mit ihren Geotags. Die Plattform erlaubt daraufhin die Suche mit Volltext, Ort oder nach Kategorien. Die 24 Literatursammlung entnommen aus Van Noord et al. 2021, S. 634. 25 https://www.nytimes.com/2020/11/24/science/artificial-intelligence-archaeology-cnn.html 26 Dunst, Hartel, Laubrock 2017 27 Dubray, Laubrock 2019 28 Chen, Chen, Liu 2018 29 https://euscreen.eu 30 https://pro.europeana.eu/project/europeana-subtitled 31 https://sensorymovingimagearchive.humanities.uva.nl 32 https://www.imediacities.eu/ 12
Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau Videoansicht erlaubt die gleichzeitige Wiedergabe des Videos sowie die annotierten Tags der aktuellen Szene: Abbildung 1: https://imediacities.hpc.cineca.it/app/catalog/videos/a4cb3b82-8771-495f-b2ad-11d479258216 CLARIAH arbeitet am Aufbau einer Audiovisual Processing (AVP) Infrastruktur inklusive Webplattform, welche Archiven bereitgestellt werden soll. Als Hauptgrund für die Vernachlässigung von audiovisuellen Quellen in den Digitalen Geisteswissenschaften sehen die Entwicklerinnen von CLARIAH-AVP das Fehlen geeigneter Werkzeuge zur Analyse großer Bestände.33 CLARIAH bietet digitale Forschungsinfrastrukturen für die Geisteswissenschaft und angrenzenden Disziplinen an. Das Projekt teilt sich in drei Gruppen, welche durch die zu bearbeitenden Datentypen geteilt sind. Die erste Gruppe beschäftigt sich mit textuellen Daten für linguistische Anwendungen, während sich die zweite auf strukturierte Daten für den sozial-wirtschaftlichen und historischen Bereich fokussiert. Für diese Masterarbeit relevanteste Gruppe drei arbeitet mit audiovisuellen Daten. Audio und Video sind Datentypen, welche stark in den Medienwissenschaften, den Geschichtswissenschaften und insbesondere den Oral History verbreitet sind.34 33 Van Noord et al. 2021, S. 634 34 Melgar-Estrada et al. 2019, S. 373-374 13
Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau Als Basis ihrer Arbeit diente die Media Suite35, eine niederländische Videoplattform zur Sammlung von Filmen, TV- und Radio-Beiträgen, Zeitungen und Oral History Interviews bereitgestellt vom Netherlands Institute for Sound and Vision (NISV), dem Eye-Filmmuseum und der Nationalbibliothek der Niederlande. Die Inhalte dieser Media Suite wurde anschließend mit automatisierten AVP- Werkzeugen in drei folgenden Anwendungsfällen annotiert: Metadatengenerierung für den Inhalt, Analyse von Posen zur Genreklassifizierung und automatische Spracherkennung insbesondere für Interviews. Die Inhalts-Metadaten werden durch semantische Objekterkennung, Farbanalyse und automatische Spracherkennung generiert.36 Die Arbeiten von CLARIAH hinsichtlich automatischer Spracherkennung sind in erster Linie zwar interessant, aber bei genauem Hinblick für diese Arbeit kaum relevant, da lediglich Modelle für Niederländisch zur Verfügung gestellt werden, aber in dieser Arbeit auf die Sprache Deutsch trainierte Modelle nötig sind. Die Leistungsfähigkeit ihres Kaldi37-Modells wird mit einer Wortfehlerrate von etwa 10% angegeben.38 Jedoch ist hier zu bedenken, dass diese Wortfehlerrate gegen einen sehr standardisierten Test-Datensatz erzielt wurde und bei Nutzung gegen historische Aufnahmen wesentlich schlechtere Ergebnisse zu erwarten sind.39 Weiters ist zu bedenken, dass das Framework Kaldi technisch bereits in die Jahre gekommen ist. Leider konnte die Media Suite nicht vollständig getestet werden, da entscheidende Funktionen nur für angemeldete Benutzer verfügbar sind und die Universität Graz keinen Zugang besitzt.40 CLARIAH stellte die genutzte Infrastruktur als Open-Source auf GitHub zur Verfügung.41 2.4. Grundlagen künstlicher Intelligenz Die meisten in dieser Arbeit eingesetzten Werkzeuge zur automatischen Extraktion von Informationen aus audiovisuellen Quellen basieren auf dem Konzept der schwachen Künstlichen Intelligenz, weswegen es nötig ist, die wichtigsten Begriffe und Konzepte im Vorfeld zu behandeln. Ziel der Forschung zu Künstlicher Intelligenz ist es, ein System zu entwickeln, das die gleichen 35 https://mediasuite.clariah.nl 36 Van Noord et al. 2021, S. 634-638 37 https://kaldi-asr.org 38 Ordelman, van Hessen 2018, S. 166 39 Siehe dazu Auswertungen von ASR-Lösungen in dieser Arbeit. 40 „The organisation you are authenticating from is not authorized access to the CLARIAH Media Suite“ 41 https://github.com/CLARIAH/DANE 14
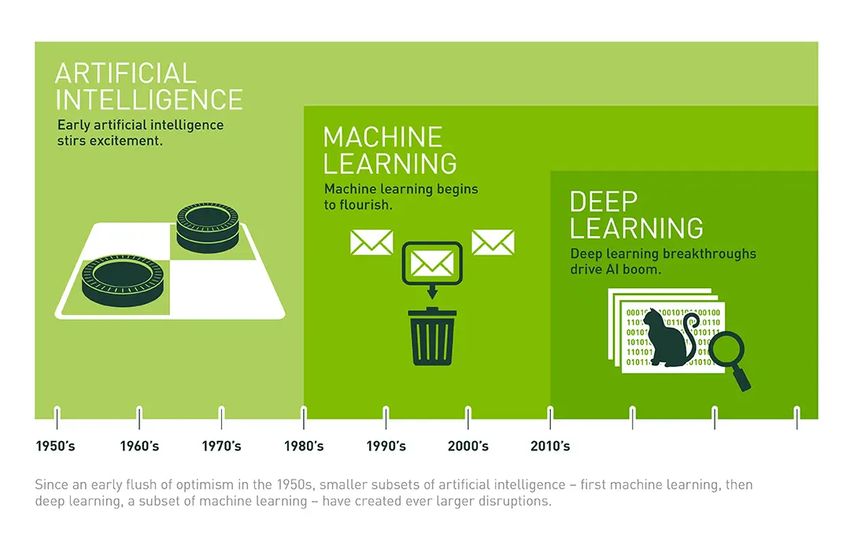
Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau intellektuellen Kompetenzen – Logisches Denken, Treffen von Entscheidungen bei Unsicherheit, Planen, Lernen, Kommunikation in natürlicher Sprache, Bewusstsein und Gefühle – aufweist wie der Mensch. Dabei muss ein solches System nicht den Menschen imitieren können 42 , sondern wird voraussichtlich eine andere kognitive Architektur aufweisen. Wird allgemein von Künstlicher Intelligenz (Artificial Intelligence), Maschinellem Lernen (Machine Learning) und Tiefem Lernen (Deep Learning) gesprochen, werden diese Begriffe häufig synonym verwendet. Sie bezeichnen jedoch unterschiedliche Konzepte, welche sich teilweise überschneiden. Diese Konzepte sind historisch gewachsen und wurden ineinander integriert:43 Abbildung 2: https://blogs.nvidia.com/blog/2016/07/29/whats-difference-artificial-intelligence-machine-learning-deep- learning-ai/ Die Idee einer artifiziellen Intelligenz gibt es seit der Frühphase des Computers und war geprägt von der hohen Erwartungshaltung an diese neue Technologie. Diese frühen Systeme basierten auf Entscheidungsbäumen, welche formale (Prädikaten-)Logik beinhalteten. Dabei durchläuft eine Abfrage mittels Heuristiken verschiedene Verknüpfungspunkte, welche anschließend eine Aussage 42 Anders als es allgemein durch den Turing-Test impliziert wird. 43 Copeland 2016 15
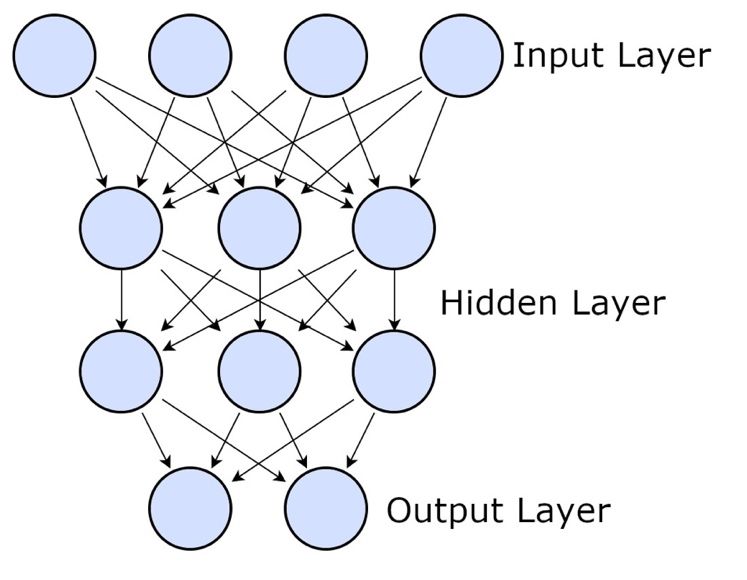
Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau zurückgeben.44 Die Logiken der Entscheidungsbäume mussten in dieser Zeit sehr zeitintensiv manuell entwickelt werden, weswegen diese Systeme nicht sehr leistungsstark waren. Erst seit den späten 80ern sind Computersysteme leistungsstark genug, um sich selbst Logiken beizubringen, indem sie in Rohdaten nach Mustern suchen und diese dann auf unbekannte Abfragen anwenden. Das Erkennen von Mustern in unstrukturierten Daten erfordert zuvor einen Lernvorgang, wobei unterschiedliche Verfahren zum Einsatz kommen:45 Beim überwachten Lernen (Supervised Learning) bekommt das Computersystem die Rohdaten gemeinsam mit der in ihnen vorhandenen Interpretationsmöglichkeiten. Im Lernvorgang sollen dann verallgemeinbare Regeln gefunden werden, welche im Anschluss für unbekannte Eingabedaten angewendet werden können. Im unüberwachten Lernen (Unsupervised Learning) entfällt die vorgegeben Interpretation der Daten, sodass das System selbständig nach Mustern in den Rohdaten suchen muss und diese dann anschließend in verschiedene Cluster zu teilen. Im Verstärkten Lernen (Reinforcement Learning) interagiert ein System direkt mit seiner Umgebung und versucht aufgrund vorheriger Erfahrungen Entscheidungen zu treffen. Ziel ist es, dass das System sich die Konsequenzen seiner Handlung merkt und diese in nachfolgenden Durchläufen berücksichtigt. Das im folgenden Kapitel zur Spracherkennung verwendete Framework Wav2vec wendet selbstüberwachtes Lernen (Selfsupervised Learning) an, welches aufgrund der sehr zeitaufwendigen Annotation von Trainingsmaterial versucht, die Rohdaten selbständig zu beschriften. Dies erlaubt ein anschließendes überwachtes Lernen mit weit weniger zuvor händisch annotieren Trainingsdaten.46 Heutige Neuerungen im Bereich künstlicher Intelligenz basieren fast ausschließlich auf Deep Learning. Darunter versteht man neuronale Netze, welche datengesteuerte Entscheidungen treffen können und dem menschlichen Gehirn ähneln. Ein Eingangssignal wird durch Reihen von Synapsen geleitet, welche miteinander verbunden sind. Einige Verbindungen sind höher gewichtet als andere. Erreichen die Eingangssignale einer Synapse einen gewissen Wert, so gibt diese das Signal an die nächste Ebene 47 weiter. Diese Synapsen werden automatisch generiert, wobei die Stärke der einzelnen Verbindungen, sowie die Grenzwerte bei dem eine Synapse das Signal weiterleitet konfigurierbar sind. Durch diese Konfigurationen kann ein neuronales Netz auf eine gewünschte Ausgabe hintrainiert werden.48 Neuronale Netze sind somit im Grunde (komplexe) mathematische Funktionen. 49 44 Wittpahl 2019, S. 22-23 45 Wittpahl 2019, S. 24-29 46 https://datadrivencompany.de/self-supervised-learning 47 Spezialformen wie Recurrent Neural Networks, welche Verbindungen zu Synapsen gleicher oder vorheriger Ebene aufweisen, werden hier ausgeklammert. 48 Specht 2019, S. 227 49 Kelleher 2019, S. 8 16
Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau Abbildung 3: Synapsen eines Deep-Learning-Algorithmus (eigene Darstellung) Neben den vielfältigen Möglichkeiten, welche auf künstliche Intelligenz basierende Werkzeuge und Methoden schaffen, ist festzuhalten, dass es hierbei auch negative Aspekte gibt. Zum einen gibt es kein KI-Tool, dass eine hundertprozentige Genauigkeit besitzt. Je nach Anwendungsfall und Lösung, reichen die Fehlerquoten teils bis über 50 Prozent. Dies hängt von einem von der Qualität der Ausgangsdaten, mit denen Algorithmen trainiert werden, wie auch vom Algorithmus selbst ab. Bei Interpretationen von Datensätzen, welche von diesen Tools generiert und nicht nachbearbeitet wurden, ist dies stets zu beachten. Auch wenn, wie im Idealfall, Open-Source-Software zur Anwendung kommt, handelt es sich aufgrund der schieren Komplexität mancher Frameworks nach wie vor für die meisten Anwender um Black Boxes. De facto gibt es kein komplettes unsupervised Training von Algorithmen, denn Algorithmus und Ausgangsdaten werden vom Menschen ausgewählt und können somit einen gewissen Bias aufweisen.50 2.5. Zusammenfassung Die Deutsche Wochenschau von 1940-1945 ist eine der zentralen Quellen zur nationalsozialistischen Propaganda des Zweiten Weltkrieges. Obgleich ihrer historischen Bedeutung, ist sie bis dato noch kaum digital erschlossen. Sie zeichnet sich zum einen durch ihr Alter und der damit einhergehenden schlechten Video- und Tonqualität als relativ herausfordernd für die nachfolgenden Arbeitsschritte 50 Dobson 2019 im Kapitel Can an Algorithm Be Disturbed? Machine Learning, Intrinsic Criticism, and the Digital Humanities, unpaginiertes E-Book 17
Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau aus, zum anderen ist ihr Korpus sehr abgegrenzt und homogen, was zu einer einheitlichen Prozessierung der Ausgaben führen wird. Mit diesen Vor- und Nachteilen sind die Ausgaben der Deutschen Wochenschau ein ideales Experimentierfeld zur Anwendung automatisierter Verfahren zur Annotation audiovisueller Quellen. Die analoge Editionswissenschaft beschäftigt sich aus praktischen und technischen Gründen zumeist mit textuellen Quellen, ein Umstand, den Digitale Editionen lange folgten. Durch die Multimedialität einer digital erscheinenden Edition ist es möglich, auch audiovisuelle Quellen mit bekannten Methoden der Digitalen Geisteswissenschaften zu verknüpfen. Doch erst in den letzten fünf Jahren erschienen Publikationen, die sich der Brücke zwischen Medienwissenschaften und Digitalen Geisteswissenschaften zur Aufgabe machten. Aufgrund der einfacheren technischen Handhabung beschäftigten sich diese Arbeiten meist mit der quantitativen Analyse großer Bildbestände. Dieses Projekt unterscheidet sich insofern von bisherigen Arbeiten, als dass hier keine vollständige Infrastruktur bereitgestellt werden soll. Vielmehr wird auf eine niederschwellige Nachnutzbarkeit des entstehenden Quellcodes gesetzt. Das folgende Forschungsvorhaben wird erst dadurch ermöglicht, dass im letzten Jahrzehnt ein sehr großer Schritt vorwärts im Bereich künstlicher Intelligenz gemacht wurde. Erst durch diese Technologie wurde es möglich, große audiovisuelle Quellkorpora automatisiert zu erschließen. 18
Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau 3. Automatische Spracherkennung Wie im Kapitel zum theoretischen Rahmen gezeigt, verwendet die Digitale Geisteswissenschaft Methoden und Werkzeuge, welche für die Prozessierung von textuellen Daten zugeschnitten sind. Somit ist die automatische Umwandlung vom Gesprochenem zu Text der wichtigste Baustein für die weitere Verarbeitung audiovisueller Quellen. Seit der Frühzeit des Computers wird an automatischer Spracherkennung (englisch Automatic Speech Recognition; ASR) geforscht, doch erst in den letzten zehn Jahren kam es aufgrund der Nutzung von Deep Learning zu einem wesentlichen Fortschritt in der allgemeinen Erkennungsqualität, sodass diese Technologie für den Einsatz in den Geisteswissenschaften nun relevant wird. Nach einer Einführung, in der dargelegt wird, warum aktuelle Spracherkennungsdienste selbst heute noch weit entfernt von hundertprozentig richtiger Erkennung sind, wird ein auf aktueller Technologie basierendes, quelloffenes Spracherkennungsmodell trainiert, um es anschließend mit proprietären Lösungen zu vergleichen. Am Ende des Kapitels wird ferner noch die rechtliche Komponente der Nutzung cloudbasierter ASR-Software behandelt. 3.1. Grundprobleme der automatischen Spracherkennung Die Kernaufgabe der automatischen Spracherkennung ist die Umwandlung von gesprochener Sprache zu verschriftlichen Text. Sprachsignale entstehen, wenn eine Person etwas spricht und die dabei entstehenden Schallwellen über einen elektroakustischen Wandler (Mikrofon) in ein elektrisches Signal umgewandelt werden. Dieses Signal wird vor allem durch den Inhalt der Sprachnachricht diversifiziert, jedoch wird es von einer Vielzahl von weiteren Faktoren beeinflusst. Hierzu zählen beispielsweise der Dialekt, die Sprechgewohnheiten, die Physiologie des Vokaltraktes, aber auch der emotionale und gesundheitliche Zustand des Sprechers. Weiters wirkt sich die jeweilige Umgebung auf den Sprecher aus. Auch die technischen Gegebenheiten, wie Signalkodierung und 19
Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau -kompression, wirken sich letztlich auf das Sprachsignal aus.51 Diese Einflussfaktoren bewirken, dass ein Sprachsignal für eine Silbe oder ein Wort sehr variabel ist, selbst wenn dasselbe gesagt wurde. Diese Variabilität zeigt sich im Sprachsignal an den folgenden Merkmalen:52 • Die Dauer eines Lautes, Wortes oder Satzes variiert zwischen 50 und 200 Prozent der Normallänge. • Die Lautstärke wirkt sich direkt auf das Sprachmuster aus. Dies hängt von der Sprechweise (nuscheln bis schreien), sowie vom Abstand des Sprechers zum Mikrofon ab. • Die Grundfrequenz von menschlicher Sprache kann zwischen 50 Hertz (tiefe Männerstimme) und 400 Hertz (hohe Kinderstimme) liegen. • Die größte Varianz innerhalb eines einzelnen Sprechers ergibt sich aus der Koartikulation, so klingt als Beispiel ein k-Laut bei einem nachfolgenden i-Laut anders als ein k-Laut mit nachfolgenden u-Laut. • Zwischen verschiedenen Sprecherinnen in verschiedenen Kontexten unterscheiden sich die Lautfolgen. Dies ist hauptsächlich bedingt durch sogenannte Verschleifungen, die im schnellen und ungenauen Sprechen passieren. Das Wort „fünf“ wird häufig nicht als [fʏnf], sondern als [fʏmf] oder [fʏmpf] ausgesprochen. Es wird dabei ein Laut dem nachfolgenden angeglichen. (Assimilation) • In Regionen mit sehr hohen Dialektfärbungen erfährt auch die Hochsprache bei vielen Menschen merkliche Änderungen. Neben diesen physiologischen Problemen in der Erkennung ergeben sich noch praktische Hürden, da sich gesprochene Sprache von verschriftlicher Sprache unterscheidet. Bei fließendem Sprechen ist es schwierig auszumachen, wann ein Wort endet und das nächste beginnt. Wortlokalisierung und Lauterkennung beeinflussen sich gegenseitig. Weiters gibt es in sprachlichen Aussagen keine Satzzeichen, womit eine Strukturierung des Gesprochenen kaum möglich ist. Zudem treten in mündlicher Kommunikation häufig unkorrekte Wortfolgen, Füllwörter und Aussetzer auf. Zuletzt ergibt sich das Problem, dass lautsprachliche Äußerungen mehrdeutig sein können. Die Zahlenfolge drei hundert zehn drei zehn kann 3 100 10 3 10, 310 13, 300 10 3 10, etc. bedeuten.53 All diese Aspekte stören bei der Spracherkennung, bei der lediglich die linguistische Aussage des Sprechers rekonstruiert werden soll. Bei dieser Rekonstruktion kommen zwei unterschiedliche Ansätze zur Anwendung. Im ersten Ansatz werden eingehende Sprachsignale nach eintrainierten Mustern bzw. daraus berechneten Merkmalsequenzen durchsucht. Dieses Akustikmodell wird für die 51 Pfister, Kaufmann 2017, S. 25-26. 52 Fleck 2020, S.7-8 53 Pfister, Kaufmann 2017, S. 329-330 20
Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau Erkennung von Phonemen, Silben oder kurzen Wörtern verwendet. Es gilt dasjenige Phonem/Silbe/Wort als erkannt, dessen Muster die höchste Ähnlichkeit aufweist. Ein reiner Mustervergleich ist zur korrekten Erkennung jedoch nicht ausreichend.54 Im linguistischen Modell wird mittels Stochastik versucht für Silben und Wörter eine Wahrscheinlichkeit festzulegen, welche angibt, wie häufig welche Merkmalsequenzen im Sprachkorpus vorkommen oder einander folgen können. Dazu werden Sprachkorpora erstellt, welche auf Transkriptionen natürlicher Sprache basieren. 55 In diesem letzten Schritt können die so erkannten Wörter einem Vergleich mit einem Wörterbuch unterzogen werden, um sie so orthographisch korrekt abbilden zu können. Die folgende Abbildung fasst zusammen, wie eine gemachte Mitteilung (W) durch einen elektroakustischen Wandler (Mikrofon) in ein elektronisches Signal (s) umgewandelt wird, welches anschließend mittels automatischer Spracherkennung dekodiert werden soll. Dazu wird im Sprachsignal nach bekannten Merkmalen (X) gesucht, welche als Basis zur statistischen Rekonstruktion der gemachten Aussage W dienen. Abbildung 4 entnommen aus Pfister, Kaufmann 2017, S. 369 Um die Qualität einer automatisiert erstellten Transkription zu bewerten, benötigt es objektive Kennzahlen. Die Bewertung erfordert den Abgleich der automatisch erstellten Transkription mit der (manuell) erstellten, richtigen Transkription. Die häufigste genutzten Metrik ist die Wortfehlerrate (Word Error Rate; WER). Sie addiert die Anzahl der Ersetzungen (ein korrektes Wort wurde durch ein falsches ersetzt), Auslassungen (ein Wort wurde vom Erkennungsprogramm weggelassen) und Einfügungen (das Erkennungsprogramm hat ein zusätzliches Wort eingefügt), um diese Summe durch die Gesamtanzahl der Wörter zu dividieren:56 54 Pfister, Kaufmann 2017, S. 28 55 Alpaydin 2016, S. 68 56 Pfister, Kaufmann 2017, S. 335. 21
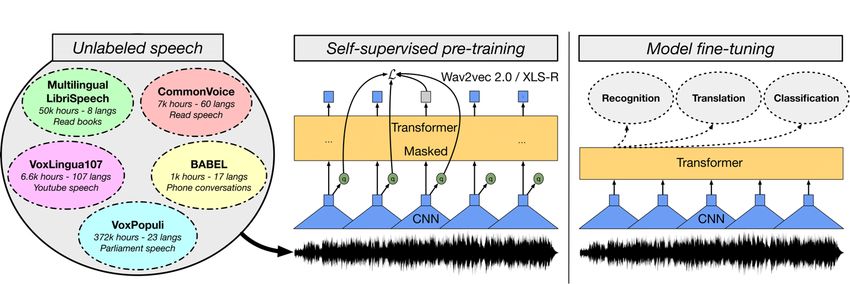
Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau # #$%&'()*+&*,# -)%./%%)*+&*,# #0*1ü+)*+&* ℎ = (× 100%) # 3ö$'&$ Je niedriger die Wortfehlerrate, desto besser ist die Transkription. Eine weitere leicht nutzbare Metrik ist die Worterkennungsrate (Word Recognition Rate; WRR). Bei ihr wird die Anzahl der richtig erkannten Wörter durch die Gesamtanzahl der Wörter des Referenztextes dividiert. Es gilt somit, je höher der Wert, desto besser die Transkription. # #$5/**'&$ 3ö$'&$ = # 3ö$'&$ (× 100%) Auch wenn Wortfehlerrate und Worterkennungsrate miteinander korrelieren, unterscheiden sich die beiden Metriken voneinander, sodass Rankings nach WER und WRR unterschiedlich ausfallen können. Für die Berechnung der WER und WRR bietet sich das Python Modul asr-evaluation57 an, welches den Abgleich zwischen einer korrekten und einer automatisch generierten Transkription durchführt. Die in dieser Arbeit durchgeführten Abgleiche werden case-insensitive durchgeführt, das heißt, ein Wort wird als korrekt eingestuft, auch wenn die Groß- und Kleinschreibung nicht korrekt ist. Ebenso werden Satz- und Sonderzeichen ignoriert. 3.2. Open-Source Modelle Die in den 2010er Jahren entwickelten quelloffenen Frameworks zur automatischen Spracherkennung – Kaldi58 und DeepSpeech59 – benötigen eine große Menge (über 1.000 Stunden) an detailreich annotierten Trainingsdaten, um ansprechende Resultate zu liefern. Sie funktionieren nach dem Prinzip; je mehr Trainingsdaten, desto bessere Transkriptionen werden erreicht. Dies führt dazu, dass diese Frameworks ausschließlich für Sprachen gut verwendbar sind, für die es genügend annotierte Rohdaten gibt, was jedoch nur für Englisch (und eventuell Chinesisch) der Fall ist. Das vom AI-Team von Meta (Facebook) entwickelte ASR-Framework Wav2vec in der Version 2 setzt mit einer Self-Supervised-Lernmethode an dieser Schwachstelle an. Dieses Framework trainiert Modelle in drei Schritten: Im ersten Schritt werden Zehntausende bzw. sogar Hunderttausende Stunden an nicht-annotierten Audiodaten genutzt, um ein Sprachmodell zu trainieren. Dazu werden die Eingangssignale in 25 Millisekunden lange Einheiten unterteilt, welche 57 https://github.com/belambert/asr-evaluation 58 https://github.com/kaldi-asr/kaldi 59 https://github.com/mozilla/DeepSpeech 22
Automatische Annotation und Erschließung von audiovisuellen Quellen am Beispiel der Deutschen Wochenschau sogar kürzer als Phoneme sind. Diese Einheiten werden dann einem Quantisierer übergeben, welcher eine bereits gelernte Spracheinheit dieser neuen Einheit zuordnet. Ungefähr die Hälfte des Eingangssignals wird verdeckt, bevor die Einheit dem Transformer übergeben wird, der Informationen über das gesamte Signal hinzufügt. Die Ausgabe des Transformer wird vom Sprachmodell verwendet, um die korrekt quantifizierte Einheit für die verdeckte Position zu identifizieren. Das Sprachmodell trainiert sich also selbst, um Muster in den Eingangssignalen zu erkennen.60 Anschließend wird dieses Sprachmodell mit annotierten Audiodaten verknüpft, um ein Spracherkennungsmodell für Sprache-zu-Text zu erhalten. Den gelernten Mustern werden in diesem Prozess Zeichen und Silben zugeordnet. Der große Vorteil von Wav2vec2 liegt nun darin, dass für diese Laut-Zeichen-Zuordnung nur sehr wenig annotierte Sprachdaten (weniger als 100 Stunden) nötig sind, um ausreichend gute Ergebnisse zu erzielen. Wie von den Forschern von Meta demonstriert, muss das vortrainierte Sprachmodell nicht zwingend monolingual in der Sprache der späteren Erkennung trainiert werden, sondern kann auch aus einem Pool mehrerer Sprachen bestehen.61 Das zurzeit größte öffentlich zur Verfügung stehende XLSR-300 Pretrained-Modell wurde mit 436.000 Stunden in 128 Sprachen trainiert.62 63 Ziel ist es nun, dieses Modell 64 mit den ebenfalls öffentlich zugänglichen deutschen Trainingssatz des CommonVoice Projektes 65 zu verfeinern, um ein offenes Spracherkennungsmodell für die Sprache Deutsch zu entwickeln. Die folgende Grafik verdeutlicht nochmal das Prinzip von Wav2vec2. Nichtannotierte Audiodaten in einer Vielzahl von Sprachen werden in einem selbstüberwachten Training genutzt, um ein Sprachmodell zu erstellen, welches anschließend als Basis für ein verfeinertes Akustikmodell dienen kann. 60 Baevski et al.2020, S. 1-3. 61 Conneau et al. 2020, S. 4-6 62 Babu et al. 2021 63 Zum Zeitpunkt des Schreibens dieser Masterarbeit wird ein Pretrained-Modell mit über 300 Milliarden Token entwickelt. Das Modell wird mehrere Monate auf einem Cluster mit 384 A100 GPUs trainiert und wird vermutlich im Juli 2022 verfügbar sein: https://bigscience.huggingface.co 64 https://huggingface.co/facebook/wav2vec2-xls-r-300m 65 https://commonvoice.mozilla.org/de 23
Sie können auch lesen

















































