DAS PARALLELKORPUS INTERCORP - Funktionen und Anwendungsbereiche. Ein Überblick.
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

EUROPEAN NETWORK OF GERMAN AND CONTRASTIVE LINGUISTICS (GerCoLiNet):
A RESEARCH-EDUCATION INTERFACE (METHODOLOGY, TEACHING AND IN-FIELD EXPERIENCE)
DAS PARALLELKORPUS INTERCORP
Funktionen und Anwendungsbereiche. Ein Überblick.
VĚRA HEJHALOVÁ
Institut für Germanistik, Philosophische Fakultät, Karlsuniversität Prag
PROGRAMM mehrsprachige Korpora und Möglichkeiten deren Nutzung InterCorp Suchanfragemöglichkeiten (KonText) Wiederholung gemeinsame Arbeit mit InterCorp

MEHRSPRACHIGE KORPORA
zwei- und mehrsprachig
Typen
Vergleichskorpora
qualitativ und quantitativ vergleichbare Texte (ähnliche Typen, Genres, Länge) für mehrere Sprachen (keine Übersetzungen)
bsp. Korpus Aranea (über KonText erreichbar)
Parallelkorpora
enthalten Texte im Original und dessen Übersetzung in eine oder mehrere Sprachen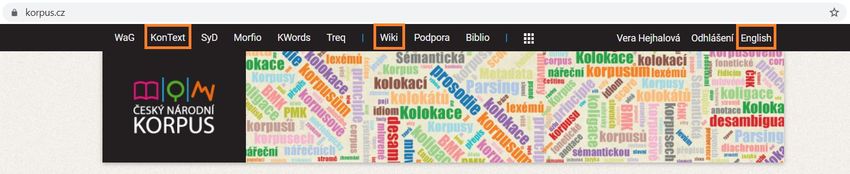
NUTZUNGSMÖGLICHKEITEN theoretische, kontrastiv orientierte linguistische Forschung ( Wortschatz, Grammatik, Stilistik, Phraseologie etc.) zwei-/mehrsprachige Lexikographie / Phraseographie Übersetzungswissenschaft Fremdsprachenunterricht Entwicklung weiterer Computerapplikationen (bsp. Treq) Zugänglichkeit für breite Öffentlichkeit

PRO UND CONTRA VORTEILE Analyse von Gemeinsamkeiten und Unterschieden verschiedenster Aspekte gewählter Sprachen Entdeckung und Analyse der Übersetzungsäquivalente Analyse des Übersetzungsverfahrens NACHTEILE unerreichbare Repräsentativität quantitative Unausgewogenheit bei mehrsprachigen Korpora

LAYOUT PARALLELER KORPORA Texte in allen Sprachen in gleiche Teile/Sequenzen aligniert = gleiche Teile (bsp. Sätze) in allen Sprachen einander zugeordnet manuell – weniger fehlerhaft, zeitlich anspruchsvoller automatisch – fehlerhafter, zeitlich nicht so anspruchsvoll Ansichtsweise parallel, in allen gewählten Sprachen (in Spalten)
INTERCORP Referenzkorpus* (seit der Version 6; jedes Jahr neue Version) synchrone Sprache akademisches, 1,554 Mrd. tokens (aktuelle Version 13, 2020, 40 Fremdsprachen + Tschechisch) nichtkomerzielles Projekt im Rahmen des Tschechischen Nationalkorpus (ČNK) entwickelt (Institut des Tschechischen Nationalkorpus, Philosophische Fakultät, Karlsuniveristät, Prag) enthält v.a. Sprachen, die an der Philosophischen Fakultät unterrichtet werden erarbeitet und erweitert von Studierenden und akademischen Mitarbeitern der Philosophischen Fakultät
ZUSAMMENSETZUNG (VERSION 13, 2020)
40 Fremdsprachen (davon 27 getaggt; 25 lemmatisiert)
+ Tschechisch als „Pivot“ (Hauptsprache)
getagged, lemmatisiert
Core – manuelles Alignment getagged, nicht lemmatisiert
weder getagged, noch lemmatisiert
Collections – automatisches Alignment
Albanisch Arabisch Bulgarisch Chinesisch Dänisch Deutsch Englisch Estnisch
Finnisch Französisch Griechisch Hebräisch Hindi Isländisch Italienisch Japanisch
Katalanisch Kroatisch Lettisch Litauisch Malaiisch Maltesisch Mazedonisch Niederländisch
Norwegisch Polnisch Portugiesisch Romani Rumänisch Russisch Schwedisch Serbisch
Slowakisch Slowenisch Spanisch Türkisch Ukrainisch Ungarisch Vietnamesisch Weißrussisch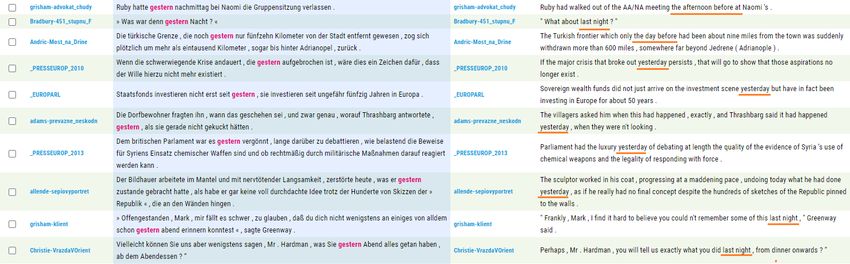
VERTEILUNG DER TEXTE IM INTERCORP NACH SPRACHEN
Tschechisch
Französisch
Italienisch
Deutsch
Polnisch
Dänisch
Quelle der Graphik:
https://wiki.korpus.cz/lib/ex
e/detail.php/cnk:intercorp:in
tercorp_wordcounts_v13.p
ng?id=cnk%3Aintercorp%3
Averze13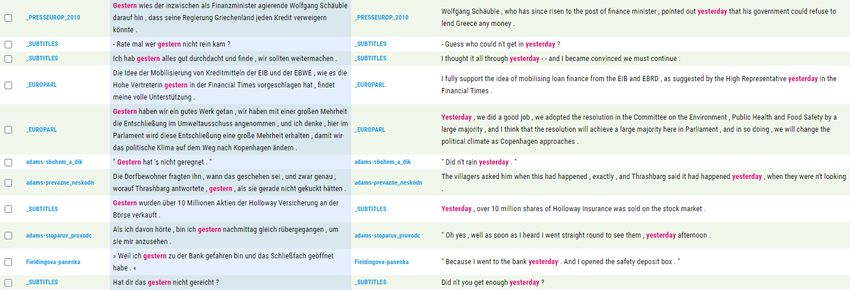
KORPUSMANAGER Seit 2013 neue Webschnittstelle KonText Zugänglich auf www.korpus.cz alle wichtigen Informationen auf Wiki (über Korpora, Umgang mit KonText, Glossar) Webseite zweisprachig (Tschechisch, Englisch)
VERLAUF DER RECHERCHE
SUCHANFRAGE
Wortform (Word)
Lemma
Buchstabenkette
Wortverbindung
BEARBEITUNG DER ERGEBNISSE
regulare Zeichen
Konkordanzenmischung/-sortierung
Klein-/Großschreibungbeachtung
Frequenzdistribution
CQL (incl. Tag-Zeichen) ERGEBNISANSICHT
KORPUSAUSWAHL Kookkurrenz- und
KWIC-Ansicht
Kollokationssuche
Volltext-Ansicht
positiven/negativen Filters
Export
SUCHANFRAGEABGRENZUNG
in vordefinierten Textgruppen
nach Texttypen
nach der Sprache des Originals
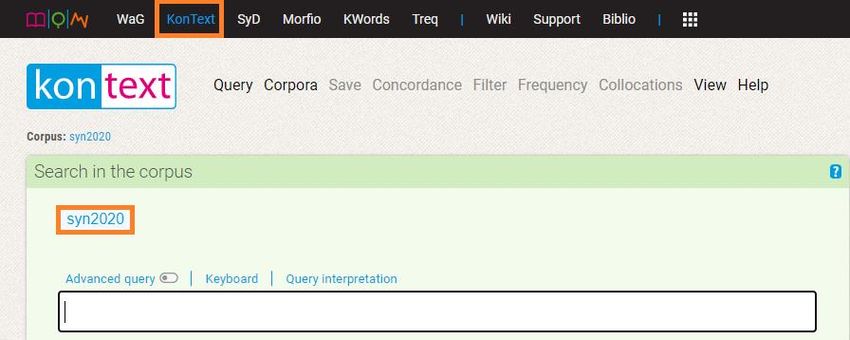
nach dem/der Übersetzer*inINTERCORP IM KORPUSMANAGER KONTEXT Verfahren 1) Auf der Webseite www.korpus.cz in der oberen Leiste „KonText“ wählen 2) Das automatisch vordefinierte Korpus (z.B. syn2020) anklicken und „all corpora“ wählen 3) Aus dem Gesamtangebot der Korpora „InterCorp“ wählen und die gewünschte sprachliche Variante wählen
SUCHANFRAGEFENSTER
SUCHANFRAGEFENSTER – KONTEXTSPEZIFIKATION
SUCHANFRAGEFENSTER – ALIGNIERTES KORPUS
SUCHANFRAGEFENSTER – ABGRENZUNG DER SUCHE
SUCHANFRAGE KONKRET in einer Sprache in beiden/mehreren Sprachen
SUCHERGEBNISSE I
SUCHERGEBNISSE II
BIBLIOGRAPHISCHE ANGABEN Doppeltes Anklicken der blauen Kurzzitierung der bibliographischen Angabe ermöglicht die volle bibliographische Information zu sehen.
VOLLTEXTANSICHT Durch doppeltes Anklicken der Konkordanz öffnet sich die Volltextansicht der konkreten Konkordanz.
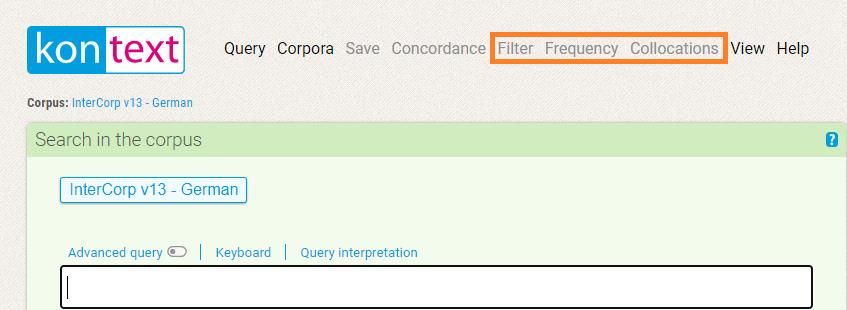
ZUSÄTZLICHE BEARBEITUNG DER ERGEBNISSE Filter Frequenz Kollokationen
FILTER weitere Bearbeitung des bereits analysierten Materials ermöglicht aus der Gesamtmenge der Ergebnisse nach weiteren Kriterien auszusortieren positiver Filter negativer Filter
FILTER – SCHRITT 1 Verfahren: 1) Suchwort heraussuchen 2) gefundene Belege analysieren
FILTER – SCHRITT 1I Verfahren: 3) In der oberen Leiste „Filter“ wählen 4) Positiven/Negativen Filter wählen 5) Das gewünschte Wort eingeben 6) Ergebnisse analysieren
FREQUENZLISTE – SCHRITT I Ermöglicht die Ergebnisse nach der Frequenz in verschiedenen Kategorien zu sortieren nach Lemmata nach Dokumenten nach Textgruppen, -typen, eigener Wahl Verfahren: 1) Suchwort heraussuchen 2) gefundene Belege analysieren
FREQUENZLISTE – SCHRITT II Verfahren: 3) In der oberen Leiste „Frequenz“ wählen 4) Das Kriterium, nach dem die Frequenz dargestellt wird 5) Ergebnisse beurteilen
KOLLOKATIONS-/KOOKKURRENZPROFIL – SCHRITT I
ermöglicht die signifikanten Kookkurrenzpartner zu entdecken
hängt vom eingestellten Kontext und vom gewählten statistischen Maß ab
vorhandene Maße
• Frequenz • LLR
• MI3 • Min. sensitivity
• MI • MI.log_f
• T-score • Relative freq. (%)
• logDice
Verfahren
1) Suchwort heraussuchen
2) gefundene Belege analysierenKOLLOKATIONS-/KOOKKURRENZPROFIL – SCHRITT II Verfahren: 3) In der oberen Leiste „Kollokationen“ wählen 4) Parameter der Kollokationsanalyse festlegen 5) Kollokationspartner nach einzelnen Maßen analysieren
WIEDERHOLUNG
IST DIE MUTTER
DER WEISHEIT
Wordwall-Quiz:
https://wordwall.net/play/17399/363/570GRAUE THEORIE – BUNTE PRAXIS Wählen Sie im InterCorp ein Sprachenpaar Ihrer Wahl und versuchen Sie nach einem beliebigen Wort / einer beliebigen Wortverbindung zu suchen. Referieren Sie uns darüber, was Sie festgestellt haben.
GRAUE THEORIE – BUNTE PRAXIS II Analysieren Sie im InterCorp in zwei separaten Recherchen die Wortpaare heilbar – heilsam (oder weitere ähnliche Paare wie furchtbar – furchtsam, mitteilbar – mitteilsam, achtbar – achtsam). Benutzen Sie dabei immer das Korpus German – v13 und das Korpus Ihrer Muttersprache. Sie können je nach Ihren sprachlichen Kenntnissen auch Korpora weiterer Sprachen einbeziehen. Bemühen Sie sich anhand von erworbenen Belegen und Übersetzungsäquivalenten den Unterschied zwischen den Suffixen –bar und –sam zu beschreiben. Sie arbeiten in internationalen Gruppen.
GRAUE THEORIE
BUNTE PRAXIS III
Hallo. – Ahoj. – Salut. – Ciao. – Cześć. – Hej.
Lehrbücher geben den Lernenden oft nicht
genügende Informationen. So ist in den meisten
Lehrbüchern des Deutschen die Begrüßung
„Hallo!“ als Begrüßung zweier
Freunde/Bekannten (die sich auch duzen)
dargestellt.
Funktioniert Hallo! wirklich als volles Äquivalent
zu den o.g. Begrüßungen?
Wählen Sie die Korpora des Deutschen und
Ihrer Muttersprache. Analysieren Sie die
deutsche Begrüßung Hallo und beobachten Sie
dabei die Kontexte/Situationen der Benutzung
und der benutzten Äquivalente.
Arbeiten Sie in nationalen Gruppen.
Berichten Sie uns dann darüber, wie diese
Begrüßung in Ihrer Muttersprache funktioniert.FRAGEN UND BEMERKUNGEN?
WEITERE BEKANNTE PARALLELKORPORA KAČENKA (1997)/KAČENKA2(2002/2003) – MUNI Brünn (Tschechische Republik); Englisch - Tschechisch EuroParl – Aufzeichnungen der Handlungen im Europäischen Parlament; 21 Sprachen; aligniert; mit dem Ziel entwickelt, die Methoden der maschinellen Übersetzung statistisch auswerten zu können ParaSol – Parallelkorpus der slawischen und anderen Sprachen; aligniert; Belletristik OPUS – The Open Parallel Corpus – Universtiät Uppsala (Schweden) – sammelt frei zugängliche Texte aus den Webseiten; über 90 Sprachen (über 3800 Sprachpaare)
QUELLEN Dovalil, V. – Káňa, T. – Peloušková, H. – Zbytovský, Š. – Vavřín, M.: Korpus InterCorp – němčina, verze 13 z 1. 11. 2020. Ústav Českého národního korpusu FF UK, Praha 2020. Dostupný z WWW http://www.korpus.cz Čermák, F. – Rosen, A. (2012): The case of InterCorp, a multilingual parallel corpus. In International Journal of Corpus Linguistics, 17(3), 411–427. https://www.korpus.cz https://wiki.korpus.cz/doku.php/cnk:intercorp https://ucnk.ff.cuni.cz/en/
DANKE FÜR IHRE AUFMERKSAMKEIT!
Sie können auch lesen

















































