Eine Heuristik zur Lösung ganzzahliger Programme mit quadratischen Nebenbedingungen - Tobias Flister - Cottbus Mathematical Preprints COMP # ...
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Eine Heuristik zur Lösung ganzzahliger
Programme mit quadratischen
Nebenbedingungen
Tobias Flister
Cottbus Mathematical Preprints
COMP # 19(2021)
Bachelorarbeit
Eine Heuristik zur Lösung ganzzahliger
Programme mit quadratischen
Nebenbedingungen
vorgelegt von:
Tobias Flister
Studiengang: Wirtschaftsmathematik
03. Juni 2021
Fakultät MINT - Mathematik, Informatik, Physik, Elektro- und
Informationstechnik
Fachgebiet Ingenieurmathematik und Numerik der Optimierung
Betreuung: Prof. Dr. rer. nat. habil. Armin Fügenschuh
Zweitgutachen: Prof. Dr. rer. nat. habil. Ekkehard Köhler

i
Inhaltsverzeichnis
Abbildungsverzeichnis iii
Tabellenverzeichnis iii
1 Einleitung 1
1.1 Problemstellung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 Mathematische Grundlagen 3
2.1 Optimierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1.1 Gemischt-Ganzzahlige Optimierung . . . . . . . . . . . . . . . . . . . 3
2.1.2 Nichtlineare Optimierung . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2 CPLEX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2.1 Preprocessing und Probing . . . . . . . . . . . . . . . . . . . . . . . 5
2.2.2 Branch-and-Bound, Schnittebenenverfahren und Branch-and-Cut . . 5
2.2.3 Paralleles Rechnen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3 Heuristiken . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3.1 Genetische Algorithmen . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3.2 Tabu-Suche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.3.3 Simulated Annealing . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3 Technische Grundlagen 15
3.1 Schall im Wasser . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.2 Zielerkennung beim Sonar . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.2.1 Cookie-Cutter Erkennungswahrscheinlichkeiten . . . . . . . . . . . . 17
3.2.2 Probabilistische Erkennungswahrscheinlichkeiten . . . . . . . . . . . 18
3.2.3 Direct Blast Effect . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.2.4 Bresenham-Algorithmus . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.3 Bekannte Modelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.3.1 Modellformulierung DISC-LOC . . . . . . . . . . . . . . . . . . . . . 23
3.3.2 Modellformulierung von Oral-Kettani . . . . . . . . . . . . . . . . . . 25
4 Allgemeiner Modellaufbau 29
4.1 Annahmen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.2 Eingabedaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.3 Nichtlineare Modelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.3.1 Maximierung der Zielabdeckung . . . . . . . . . . . . . . . . . . . . 31
4.3.2 Minimierung der Kosten . . . . . . . . . . . . . . . . . . . . . . . . . 31
5 Heuristische Ansätze 33
5.1 Heuristik zur Maximierung der Zielabdeckung . . . . . . . . . . . . . . . . . 33
5.1.1 Lineare ganzzahlige Programme . . . . . . . . . . . . . . . . . . . . . 33
5.1.2 Ablauf und Algorithmus . . . . . . . . . . . . . . . . . . . . . . . . . 34
5.2 Heuristik zur Minimierung der Kosten . . . . . . . . . . . . . . . . . . . . . 35
5.2.1 Lineare ganzzahlige Programme . . . . . . . . . . . . . . . . . . . . . 35
5.2.2 Ablauf und Algorithmus . . . . . . . . . . . . . . . . . . . . . . . . . 35
5.3 Unterschiede und Besonderheiten der Algorithmen . . . . . . . . . . . . . . 36
5.4 Platzierung der Startsensoren . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.4.1 Startvarianten für das Problem der Abdeckungsmaximierung . . . . 37
5.4.2 Startvarianten für das Problem der Kostenminimierung . . . . . . . 38ii INHALTSVERZEICHNIS
6 Rechenergebnisse und Bewertung 39
6.1 Vergleich der Startvarianten . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
6.1.1 Startvarianten für das Problem der Abdeckungsmaximierung . . . . 39
6.1.2 Startvarianten für das Problem der Kostenminimierung . . . . . . . 44
6.2 Vergleich der Heuristik mit einem exakten Verfahren . . . . . . . . . . . . . 44
6.2.1 Modell CM-CC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
6.2.2 Modell CM-PRB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
6.2.3 Modell CR-CC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
6.2.4 Modell CR-PRB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
6.2.5 Vergleich am Beispiel . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
7 Fazit und Ausblick 51
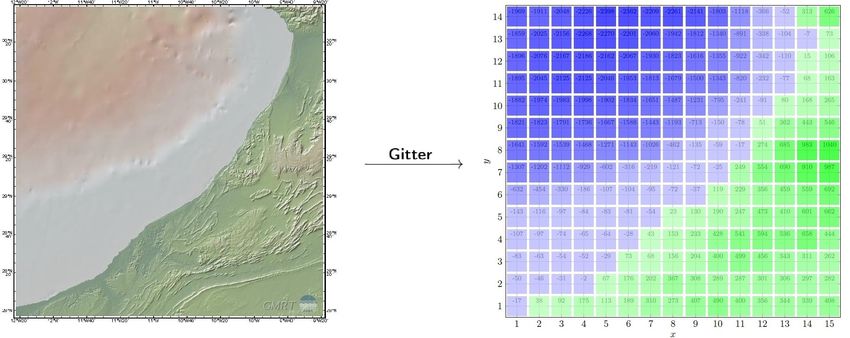
Literatur 53iii Abbildungsverzeichnis 1 Genetischer Algorithmus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8 2 Selektion und Kreuzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10 3 Tabu-Suche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 4 Simulated Annealing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 5 Cassinische Kurven . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 6 Direct Blast Effect . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20 7 Bresenham-Algorithmus Linie . . . . . . . . . . . . . . . . . . . . . . . . . . 23 8 Gitter am Beispielküstenabschnitt Agadir . . . . . . . . . . . . . . . . . . . 30 9 Teilung des Ozeanabschnittes RekaBuorYuryakh in zwei Teilbereiche . . . . 38 10 Vergleich heuristischer mit exakter Lösung . . . . . . . . . . . . . . . . . . . 50 Tabellenverzeichnis 1 Vergleich der Startvarianten für CM-CC . . . . . . . . . . . . . . . . . . . . 40 2 Vergleich der Startvarianten für CM-PRB . . . . . . . . . . . . . . . . . . . 41 3 Vergleich der Startvarianten für CR-CC . . . . . . . . . . . . . . . . . . . . 42 4 Vergleich der Startvarianten für CR-PRB . . . . . . . . . . . . . . . . . . . 43 5 Vergleich HEUR2-R mit OK1-S für CM-CC . . . . . . . . . . . . . . . . . . 45 6 Vergleich HEUR2-R mit OK1-S für CM-PRB . . . . . . . . . . . . . . . . . 46 7 Vergleich HEUR3-R mit OK1-S für CR-CC . . . . . . . . . . . . . . . . . . 47 8 Vergleich HEUR3-R mit OK1-S für CR-PRB . . . . . . . . . . . . . . . . . 48
1 1 Einleitung Die Menschheit kennt verschiedene Techniken, um Objekte aufzuspüren und ihre Lage im Raum zu bestimmen. Möchte man dies für ein Objekt im Wasser oder gar Unterwasser durchführen, so kommt das Sonar zum Einsatz. Sonar ist ein englisches Akronym und steht für Sound Navigation and Ranging, also Navigation und Bestimmung der Entfernung durch Schall. Das Sonar ist gewissermaßen eine Art Unterwasser-Radar, nur verwendet man hier Schall- wellen statt Funkwellen zur Ortung von Objekten. Der Grund dafür ist einfach. Funkwellen breiten sich relativ ungehindert in der Luft aus, Schallwellen hingegen nicht. Im Wasser kehrt sich diese Beziehung quasi um und Schallwellen sind hier in der Lage, sich bis zu mehrere tausend Kilometer weit auszubreiten [2]. Zunächst folgt ein kurzer Einschub zur geschichtlichen Einordnung des Sonars. Die Ent- wicklung von modernen Systemen zur Entdeckung und Standortbestimmung von Objekten unter Wasser nahm ihren Anfang zu Beginn des zwanzigsten Jahrhunderts. In Folge der Katastrophe des Untergangs der RMS Titanic im Jahre 1912 hatte man es sich zur Aufgabe gemacht, die Sicherheit auf See zu verbessern. So begab es sich, dass gleich drei Männer, namentlich Alexander Behm, Reginald Fessenden und Lewis Fry Richardson, unabhängig voneinander an der frühzeitigen Erkennung von Eisbergen forschten. In Folge dieser Bemü- hungen erfand Alexander Behm ein spezielles Sonar, das es ihm ermöglichte den Abstand zum Meeresboden zu messen. Auch wenn diese Erfindung leider nicht beim Aufspüren von Eisbergen half, so ist sie heutzutage doch weltweit als Echolot bekannt [2]. Im Jahre 1914 sollte ein weiteres geschichtliches Ereignis die Entwicklung des Sonars voran- treiben. Der Beginn des ersten Weltkriegs und der damit verbundene Einsatz von Schiffen, U-Booten und Seeminen erzeugte ein militärisches Interesse am Sonar und so dauerte es nicht lange, bis ein Jahr später das erste aktive Sonar entwickelt wurde, welches tatsäch- lich in der Lage war, U-Boote aufzuspüren. Der später folgende zweite Weltkrieg, sowie der kalte Krieg schafften weitere Einsatzmöglichkeiten für das Sonar und kurbelten so die Forschung in diesem Bereich noch weiter an [2]. In der heutigen Zeit hat das Sonar längst nicht nur militärische Einsatzmöglichkeiten. In der Fischerei kann man das Echolot nutzen, um Fischschwärme aufzuspüren. In der Forschung kann das Sonar genutzt werden, um die Beschaffenheit des Meeresbodens zu untersuchen oder um Meerestiere zu beobachten. Und allgemein kann das Sonar zur Navi- gation, besonders in flachen Gewässern, genutzt werden [1]. Die zuerst entwickelten Sonar Systeme lassen sich im Allgemeinen in zwei Typen unter- teilen. Das aktive Sonar arbeitet mit mindestens einem Sender und einem Empfänger. Der Sender sendet eine Schallwelle aus. Befindet sich ein Objekt in der Nähe, so wird die Schallwelle von diesem reflektiert und dann vom Empfänger aufgezeichnet. Anhand der benötigten Zeit und der Richtung lässt sich so die Lage des Objekts bestimmen. Das passive Sonar hingegen besteht nur aus einem Empfänger. Es sendet somit keine eigenen Schallwellen aus, sondern empfängt nur die von Objekten selbst verursachten Schallwellen [2]. Diese zwei Ausprägungsformen verfügen über ganz eigene Vorteile und Nachteile. So ist
2 1 EINLEITUNG das aktive Sonar in der Lage, Objekte zu orten, die selbst gar keinen Schall aussenden. Durch das Aussenden einer eigenen Schallwelle macht es sich aber selbst leicht sichtbar für fremdes Sonar. Das passive Sonar vermeidet hingegen diesen Nachteil, kann dafür aber nur Objekte orten, die Schallwellen aussenden. Typische Vertreter des aktiven Sonars sind das monostatische Sonar, bei diesem befinden sich Sender und Empfänger an derselben Stelle und das multistatische Sonar, dessen Sender und Empfänger an unterschiedlichen Positionen platziert werden. 1.1 Problemstellung Diese Bachelorarbeit befasst sich mit exakten und heuristischen Lösungsverfahren für li- neare und quadratische ganzzahlige Programme, welche für die optimale Platzierung von Sendern und Empfängern beim multistatischen Sonar angewandt werden. Ich betrachte dabei zwei Probleme. Beim Ersten möchte ich mit einer gegebenen Anzahl Sensoren mög- lichst viel Raum eines Meeresabschnitts abdecken, beim zweiten Problem möchte ich den gesamten Meeresabschnitt mit möglichst geringen Kosten abdecken. Im Kapitel 3.3 gehe ich auf bereits existierende exakte Verfahren ein, die in der Lage sind, eine optimale Lösung für die Probleme zu berechnen. Deren Rechenzeiten sind in der Pra- xis jedoch für große Eingabedaten zu langsam. Um sich der Realität besser anzunähern, soll es möglich sein, auch feinmaschige Diskretisierungen der zu überwachenden Ozeanab- schnitte als Eingabedaten zu verwenden. Um dieses Ziel zu erreichen, wird im Laufe dieser Arbeit eine Heuristik entwickelt, diese garantiert im Gegensatz zu den exakten Verfahren keine Optimalität mehr, aber soll dennoch zu guten Lösungen bei vergleichsweise niedriger Rechenzeit führen.
3
2 Mathematische Grundlagen
2.1 Optimierung
Es ist das Ziel der Optimierung, ein betrachtetes System zu verbessern und im Idealfall das
namensgebende Optimum zu erreichen. Um solch ein System zu beschreiben, nutzt man ein
mathematisches Modell, welches üblicherweise als Optimierungsproblem oder Programm
(P) bezeichnet wird [8]. Zentrale Rolle spielt dabei die Zielfunktion z = f (x) mit der Ab-
bildung f : Rn → R, n ∈ N [13]. Je nach Problemstellung sucht man nach dem Maximum
oder Minimum der Zielfunktion z. Diese Probleme lassen sich gemäß des Dualitätsprinzips
max z = −min(−z) und min z = −max(−z)
leicht ineinander überführen, weshalb ich im Folgenden nur das Minimierungsproblem be-
trachte [11]. Man beachte, x ist ein Variablenvektor mit x = (x1 , ..., xn )> . Die Variablen
der Zielfunktion sind dabei oft durch Nebenbedingungen gi , i = 1, ..., k, k ∈ N auf einen
zulässigen Bereich G := {x ∈ Rn |gi (x) ≤ 0, ∀i = 1, ..., k} beschränkt. Statt auf ganz Rn
sucht man dann auf Rn ∩ G. Im Allgemeinen hat ein Optimierungsproblem (P) die Gestalt
min z = f (x) (2.1)
unter x ∈ G (2.2)
mit G ⊆ Rn [11]. Gilt
f (x∗ ) ≤ f (x) ∀x ∈ G
für ein x∗ ∈ G, so bezeichnet man x∗ als Optimallösung und f (x∗ ) als das Optimum von
(P). Je nach Art der Zielfunktion und der Gestalt des zulässigen Bereichs lässt sich das
Problem klassifizieren [8]. Liegt beispielsweise eine lineare Zielfunktion vor und der zulässi-
ge Bereich wird ausschließlich durch lineare Gleichungen und Ungleichungen beschrieben,
so spricht man von einem linearen Optimierungsproblem [13].
2.1.1 Gemischt-Ganzzahlige Optimierung
Für einige Probleme ist es notwendig, einen Teil der Variablen als ganzzahlig anzunehmen.
Laut Kallrath [13] spricht man in diesem Fall von einem gemischt-ganzzahligen Programm
(engl. mixed-integer program, MIP). Für die in dieser Arbeit diskutierten Probleme be-
nötige ich im Speziellen Binärvariablen, da diese jeweils eine Entscheidung repräsentieren.
Gibt es nun nb binäre, nc reelle und nd ganzzahlige Variablen und k Nebenbedingungen,
so ergibt sich mit
x = (x1 , ..., xnb , ..., xnb +nc , ..., xnb +nc +nd )>4 2 MATHEMATISCHE GRUNDLAGEN
die folgende allgemeine Formulierung des Programms:
min z = f (x) (2.3)
unter gi (x) ≤ 0, i = 1, ..., k, (2.4)
x1 , ..., xnb ∈ B, (2.5)
xnb +1 , ..., xnb +nc ∈ R, (2.6)
xnb +nc +1 , ..., xnb +nc +nd ∈ Z, (2.7)
x ≥ 0. (2.8)
Die Äquivalenzen
gi (x) ≤ 0 ⇔ −gi (x) ≥ 0,
sowie
gi (x) ≥ 0 und gi (x) ≤ 0 ⇔ gi (x) = 0,
erlauben dabei auch die Verwendung von „≥“ und „=“ in den Nebenbedingungen. Liegt
der Spezialfall vor, dass man ausschließlich ganzzahlige Variablen hat, gilt also nb + nd >
0 und nc = 0, so handelt es sich um ein ganzzahliges Optimierungsproblem [13]. Falls
dabei ausschließlich Binärvariablen vorliegen, spricht man mitunter auch von einem binären
Programm.
2.1.2 Nichtlineare Optimierung
Ist mindestens eine der Funktionen f (x) oder gi (x), ∀i = 1, ..., k nichtlinear, so hat man es
mit einem nichtlinearen Optimierungsproblem zu tun [13]. Die in Kapitel 4.3 betrachteten
Modelle haben mit den Ungleichungen (4.1) und (4.7) jeweils quadratische Nebenbedingun-
gen. Da in den Modellen alle Variablen binär sind, handelt es sich dabei also um nichtlineare
ganzzahlige Optimierungsprobleme bzw. im Speziellen um quadratische binäre Optimie-
rungsprobleme. Für diese Klasse von Problemen existieren Linearisierungsansätze, um die
Nebenbedingungen zu vereinfachen.
Ich betrachte das Optimierungsprogramm
min f (x1 , ..., xn ) (2.9)
unter gi (x1 , ..., xn ) ≥ 0, i = 1, ..., m, (2.10)
x1 , ..., xn ∈ B, (2.11)
wobei gi (x) quadratische Funktionen sind [24].
Der älteste Ansatz basiert auf Watters [24] und wird von Fügenschuh et al. [10] aufgegriffen.
Er sieht vor, dass man x2j durch xj für alle j ersetzt, da das offensichtlich nichts am Wert
der Funktion ändert. Weiterhin führt man für alle j und k eine neue Binärvariable xjk
ein, welche nur den Wert 1 annehmen soll, wenn das Produkt xj xk den Wert 1 annimmt.
Dieser Zusammenhang lässt sich durch die linearen Nebenbedingungen
2xj,k ≤ xj + xk2 MATHEMATISCHE GRUNDLAGEN 5
und
xj + xk ≤ 1 + xj,k
beschreiben.
Die als Standard Linearisierung bezeichnete Methode nutzt das gleiche Vorgehen, jedoch
verwendet man statt einer binären die reelle Variable xj,k ∈ [0, 1], wodurch sich die linearen
Nebenbedingungen
xj,k ≤ xj ,
xj,k ≤ xk
und
xj + xk ≤ 1 + xj,k
ergeben [10].
Bei den Linearisierungen nach Glover, sowie nach Oral und Kettani, nutzt man Spalten-
oder Zeilensummen, um die Nebenbedingungen zu linearisieren [10]. In Kapitel 3.3.2 wird
die Linearisierung nach Oral und Kettani an einem Optimierungsproblem, welches in dieser
Arbeit betrachtet wird, verdeutlicht.
2.2 CPLEX
Da ich IBM ILOG CPLEX 12.8.0 für die Berechnungen verwende, möchte ich die dabei
verwendeten Verfahren in diesem Kapitel kurz vorstellen. CPLEX nutzt Preprocessing,
Probing, den Simplex-Algorithmus, Branch-and-Bound, Schnittebenen-Verfahren, Branch-
and-Cut sowie paralleles Rechnen [12].
2.2.1 Preprocessing und Probing
Preprocessing und Probing werden vor dem eigentlichen Lösen genutzt, um das Problem
zu vereinfachen.
Beim Preprocessing wird auf Zulässigkeit geprüft, redundante Nebenbedingungen werden
entfernt und die Schranken von Variablen, wenn möglich, verbessert [22]. Beim Probing
werden testweise nacheinander die Binärvariablen auf entweder 0 oder 1 gesetzt. Die so
entstehenden Programme werden mit den Methoden des Preprocessing ausgewertet, um
gegebenenfalls einzelne Binärvariablen zu fixieren oder ihre Koeffizienten zu verbessern
[22].
2.2.2 Branch-and-Bound, Schnittebenenverfahren und Branch-and-Cut
Unter Branch-and-Cut versteht man die Kombination aus Schnittebenen-Verfahren und
Branch-and-Bound. Zunächst möchte ich die beiden Verfahren vorstellen.
Branch-and-Bound ist ein Verfahren, welches aus den beiden namensgebenden Lösungs-
prinzipien Branching und Bounding besteht. Ich betrachte das Verfahren für Maximie-
rungsprobleme, bei Minimierungsproblemen müssen die Begriffe untere und obere Schran-
ke entsprechend vertauscht werden [26].6 2 MATHEMATISCHE GRUNDLAGEN
Ich möchte zunächst das Branching erklären. Sei P0 das Ausgangsproblem und X(P0 )
die Menge seiner zulässigen Lösungen, dann wird es gemäß
k
[
X(P0 ) = X(Pi )
i=1
und möglichst
X(Pi ) ∩ X(Pj ) = ∅ ∀i 6= j
in k Teilprobleme P1 , ..., Pk zerlegt bzw. verzweigt (engl. to branch). Die Vereinigung der
Lösungsmenge der Teilprobleme soll also die Lösungsmenge des Ausgangsproblems ergeben
und der Durchschnitt der Lösungsmenge zweier Teilprobleme soll möglichst leer sein. Nach
demselben Prinzip lässt sich jedes der Probleme P1 bis Pk erneut zerlegen und so weiter,
man erhält so einen Baum mit Wurzel P0 [8].
Die folgende Erklärung basiert auf Domschke et al. [8]. Das Bounding liefert die Grund-
lage, um festzustellen, wann eine weitere Verzweigung sinnvoll ist und wann nicht. Dafür
wird einerseits die beste bekannte zulässige Lösung als eine globale obere Schranke F
für den Zielfunktionswert der optimalen Lösung von P0 verwendet. Bei der Initialisierung
wird diese auf den Wert −∞ gesetzt, alternativ kann sie aber auch mit einer Heuristik
bestimmt werden. Andererseits bestimmt man für jedes Problem Pi für alle i eine lokale
untere Schranke Fi . Dafür benötigt man eine Relaxation Pi0 von Pi , also ein vereinfachtes
Problem mit X(Po ) ⊆ X(Pi0 ), welches man durch Vereinfachen oder Weglassen von Neben-
bedingungen erhält. Bei einem gemischt-ganzzahligen Problem kann man beispielsweise auf
die Ganzzahligkeitsforderung verzichten. Der Zielfunktionswert dieser Lösung dient dann
als untere Schranke [8].
Ein Problem Pi ist fertig bearbeitet und muss nicht weiter betrachtet werden, sobald einer
der folgenden drei Fälle erreicht ist:
Fall 1 (Es gilt Fi ≤ F ): Da die bestmögliche Lösung des Teilproblems schlechter als die
beste bekannte Lösung ist, kann hier keine Verbesserung erzielt werden.
Fall 2 (Es gilt Fi > F und die optimale Lösung von Pi0 ist auch zulässig für Pi ): Damit
ist eine zulässige neue beste Lösung von P0 gefunden und die untere Schranke kann gemäß
F := Fi aktualisiert werden.
Fall 3 (Es gilt X(Pi0 ) = ∅): In diesem Fall gibt es keine zulässige Lösung für Pi0 und somit
hat auch das Teilproblem Pi keine zulässige Lösung [8].
Sind alle Teilprobleme fertig bearbeitet, so endet das Verfahren mit einer optimalen Lösung
für P0 .
Für ein Schnittebenen-Verfahren betrachtet man eine Relaxation des Problems, welche
auf die Ganzzahligkeit der Variablen verzichtet. Man verschärft diese dann durch zusätz-
liche Ungleichungen, um so nach Möglichkeit ganzzahlige Lösungen zu erhalten. Für ein
gemischt-ganzzahliges Problem betrachte ich den zulässigen Bereich G = {x ∈ Rn |gi (x) ≤
0, xj ∈ Z, x ≥ 0, j ∈ I, ∀i = 1, ..., k}. Seine konvexe Hülle conv(G) stellt einen Polyeder dar.
Dieser lässt sich durch conv(G) = {x|αl x ≥ αl,0 , l = 1, ..., q} beschreiben, gilt (αl )> x ≥ αl,0
für alle x ∈ G, so handelt es sich um eine zulässige Ungleichung von G und man spricht
man von einem Schnitt beziehungsweise einer Schnittebene [16].2 MATHEMATISCHE GRUNDLAGEN 7 Das älteste Verfahren, um solche Schnittebenen zu bestimmen, ist das Schnittebenen- Verfahren von Gomory. Für eine genaue Beschreibung des Verfahrens siehe Zimmermann [26] Kapitel 3.6.2. Zur Durchführung von Branch-and-Cut nutzt man zuerst ein Schnittebenen-Verfahren, um die Relaxation des Problems zu verschärfen, indem man Schnittebenen hinzufügt. An- schließend führt man das Branch-and-Bound-Verfahren aus und verwendet dann wieder ein Schnittebenen-Verfahren für die so entstandenen Teilprobleme. Dies wiederholt man, bis das Problem gelöst ist. Auf diese Weise lässt sich gegenüber dem normalen Branch- and-Bound-Verfahren Rechenzeit einsparen [16]. 2.2.3 Paralleles Rechnen Grundsätzlich geht es beim parallelen Rechnen darum, ein Programm oder Teile davon so in Unterabschnitte zu unterteilen, dass diese von mehreren Prozessoren gleichzeitig be- ziehungsweise parallel ausgeführt werden können. Dadurch lässt sich unter Umständen Rechenzeit einsparen. Das Vorgehen lässt sich grob in drei Phasen unterteilen [20]. Während der Anlaufphase (engl. ramp-up phase) werden die Rechnungen oder Unterpro- gramme aufgeteilt und den einzelnen Prozessoren zugewiesen. Sobald ausreichend Aufga- ben verteilt wurden, beginnt die Hauptphase, während der der Algorithmus seine eigent- lichen Aufgaben abarbeitet. In der letzten Phase werden die geteilten Prozesse langsam heruntergefahren (engl. ramp-down phase) und ihre Ergebnisse ausgegeben [20]. Dieses Vorgehen eignet sich besonders für Baumalgorithmen, wie Branch-and-Bound und Branch-and-Cut, da sich dabei einzelne Teilprobleme ergeben, die parallel abgearbeitet werden können. Eine Kommunikation der einzelnen Prozesse untereinander ist begrenzt möglich, so können beispielsweise gewonnene Schranken direkt weitergegeben werden, al- lerdings sollte dabei darauf geachtet werden, dass der so gewonnene Nutzen größer als der zusätzliche Rechenaufwand ist [20]. 2.3 Heuristiken Der Begriff Heuristik wird in der Literatur mit verschiedenen Bedeutungen versehen, so gilt er beispielsweise als Zusammenfassung von Tricks, Techniken und Regeln zur Problem- lösung, als ganzer Gegenstandsbereich oder als Teil einer Wissenschaft [4]. Im Bereich des Operations Research versteht man unter dem Begriff in der Regel einen iterativen Algo- rithmus, welcher aber nicht gegen die Lösung des Problems konvergiert. Es gibt also keine Garantie, dass man die optimale oder gar eine mögliche Lösung findet [18]. An dieser Stelle muss man sich fragen, warum und wann man denn dann Heuristiken einsetzen sollte. Es gibt zahlreiche Probleme, wie beispielsweise die NP-Vollständigen (siehe Korte und Vygen [14]), für die kein Algorithmus existiert, welcher in akzeptabler Zeit gegen die Lösung kon- vergiert. Für diese Probleme können Heuristiken der einzige Weg sein, Lösungen in kurzer Zeit zu erhalten. Alternativ kann man Heuristiken aber auch für effizient lösbare Proble- me verwenden, um die Rechenzeit zu verkürzen. In Folge dessen werden Heuristiken auch innerhalb von konvergierenden Algorithmen verwendet, wie beispielsweise bei der Pivot- auswahl bei Linearen Programmen [18].
8 2 MATHEMATISCHE GRUNDLAGEN In den folgenden Unterkapiteln beschreibe ich drei typische Arten von Heuristiken, welche auf verschiedenste Problemstellungen angewandt werden können, weshalb man sie auch als Metaheuristiken bezeichnet. Ich orientiere mich dabei stark an Pham und Karaboga [19]. 2.3.1 Genetische Algorithmen Ganz allgemein ausgedrückt sind genetische Algorithmen Heuristiken, die Optima bestim- men, indem sie Methoden verwenden, welche sich an der Genetik und der natürlichen Selektion orientieren [19]. Bei der Optimierung von nichtlinearen multimodalen Funktionen stoßen herkömmliche Suchmethoden oft an ihre Grenzen, es bietet sich dann häufig die Verwendung einer Zu- fallssuche an. Geht man dabei aber einfach komplett zufällig vor, so erhält man gerade für große Instanzen hohe Rechenzeiten. Der genetische Algorithmus als Ansatz bringt eine Ordnung in diese Zufallssuche, um bessere Ergebnisse zu erzielen [19]. Abbildung 1: Die Darstellung zeigt den Ablauf eines einfachen genetischen Algorithmus als Flussdiagramm basierend auf Pham et al. [19]. Darstellungsform und erste Population Die zu optimierenden Parameter werden meist mit einer Zeichenfolge beziehungsweise Zei- chenkette dargestellt. Als beliebteste Methode hat sich dabei die binäre Darstellung durch- gesetzt, da diese aufgrund der heutigen Rechnerarchitektur eine maximale Speichereffizienz bietet, es existieren aber auch andere Methoden [19]. Eine solche Zeichenkette wird häufig
2 MATHEMATISCHE GRUNDLAGEN 9 als Genotyp oder Chromosom bezeichnet [25]. Zu Beginn benötigt man Startlösungen. Verfügt man bereits über geeignetes Vorwissen be- züglich des Problems, so können die Startlösungen in einem Bereich nahe der vermuteten optimalen Lösung gewählt werden. Ist dies nicht der Fall, so werden sie rein zufällig ge- wählt. Die so generierten Zeichenketten werden auch als Population der ersten Generation bezeichnet [19]. Sobald man über eine erste Population verfügt, wird jede Zeichenkette bewertet und an- schließend mit einem Wert versehen, welcher die reproduktive Fitness beschreibt. Die Zielfunktion wird dabei zur Bewertung einer Zeichenkette verwendet. Eine Fitnessfunk- tion wandelt dann den zugehörigen Zielfunktionswert in einen Fitnesswert um. Dieser be- schreibt die Möglichkeit zur Fortpflanzung. Zu beachten ist, dass der Zielfunktionswert einer Zeichenkette unabhängig von den Zielfunktionswerten anderer Zeichenketten ist. Der Fitnesswert hingegen steht in Relation zu den anderen Fitnesswerten der selben Generation [25]. Genetische Operatoren Aus der Population der ersten Generation sollen nun iterativ weitere Generationen gebildet werden. Dazu benötigt man genetische Operatoren. Die drei häufigsten genetischen Ope- ratoren sind Selektion, Kreuzung und Mutation, für manche Probleme bieten sich aber auch weitere Operatoren, wie beispielsweise ein Umkehrungsoperator an. Da die geneti- schen Operatoren unabhängig voneinander sind, kann man je nach gewählter Darstellung und nach Form des Problems ihre Art und Anzahl anpassen. Ich möchte an dieser Stelle die am häufigsten genutzten Operatoren vorstellen [19]. Die Selektion wird meist als erster genetischer Operator verwendet, da sie großen Einfluss darauf hat, ob und wie schnell eine geeignete Lösung gefunden wird. Ziel dieser Methode ist es, mehr Kopien beziehungsweise Nachkommen von Genotypen mit hohem Fitnesswert und weniger von Genotypen mit geringem Fitnesswert zu erhalten. Man wählt dabei be- wusst nicht ausschließlich Genotypen mit hohem Fitnesswert, damit das Verfahren nicht zu zeitig konvergiert und man den optimalen Zielfunktionswert erreichen kann. Bei der proportionalen Auswahl wird mehrfach zufällig ausgewählt. Der Fitnesswert bestimmt da- bei mit welcher Wahrscheinlichkeit ein Genotyp gewählt wird. Bei der Auswahl nach Rang werden die Genotypen entsprechend dem Fitnesswert in Ränge unterteilt und erhalten je nach Rang eine vorher festgelegte Anzahl an Nachkommen [19]. Einer der entscheidenden Punkte, in denen sich genetische Algorithmen von anderen Al- gorithmen unterscheiden, ist die Methode der Kreuzung. Hierbei werden aus zwei be- stehenden Genotypen, also den Eltern, zwei neue Genotypen, die Kinder, erschaffen. Es gibt zahlreiche Vorgehen, um aus den Genotypen der Eltern die Genotypen der Kinder zu kreieren, außerdem lässt sich auch die Anzahl der Eltern und Kinder variieren. In einem einfachen Beispiel wählt man zufällig zwei Eltern, zerschneidet ihre Genotypen am selben zufälligen Punkt, vertauscht dann zwei gleich lange Teilstücke und erzeugt so die beiden Kinder [19]. Bei der Mutation werden alle Bits der Zeichenketten durchlaufen und zufällig mit einer
10 2 MATHEMATISCHE GRUNDLAGEN gegebenen Mutationschance invertiert. Das erlaubt dem Algorithmus, andere Bereiche zu überprüfen, nicht frühzeitig zu konvergieren und somit bessere Lösungen zu finden. Auch hier existieren verschiedene Arten der Umsetzung, die sich zum Beispiel in der Wahl der Bits und der Art ihrer Veränderung beziehungsweise Mutation unterscheiden [19]. Abbildung 2: Aus der Generation t wird durch Selektion und Kreuzung die neue Generation t + 1 geschaffen. Die Darstellung basiert auf Whitley [25]. Die Abbildung 2 zeigt beispielhaft, wie aus einer Generation t durch die genetischen Opera- toren Selektion und Kreuzung die Nachfolgegeneration t + 1 erzeugt wird. Auf die Darstel- lung der Mutation wurde aus Platzgründen und im Sinne der Übersichtlichkeit verzichtet [25]. Der genetische Algorithmus erzeugt auf diese Weise immer neue Generationen von Zeichen- ketten und damit Lösungen der Zielfunktion. Die Abbildung 1 zeigt unter Verwendung der genetischen Operatoren Selektion, Kreuzung und Mutation, wie sich dieses Vorgehen wie- derholt, bis ein vorher festgelegtes Abbruchkriterium erreicht wird. Man erhält dann aus der Endpopulation eine Lösung für das Problem. Mögliche Abbruchkriterien sind eine feh- lende Verbesserung des Zielfunktionswerts über mehrere Populationen oder eine vorher bestimmte Anzahl an Generationen, es sind aber auch andere Kriterien denkbar. 2.3.2 Tabu-Suche Namensgebend für die Tabu-Suche sind dynamisch erstellte Einschränkungen, also Tabus, welche bei der Suche nach dem Optimum eingesetzt werden. Man kann durch diese Ein- schränkungen bei der Suche lokale Extrema vermeiden, um so das globale Extremum zu finden [19]. In jedem Schritt wird aus der Nachbarschaft der aktuellen Lösung die beste Lösung in Bezug auf die Zielfunktion und geltende Tabus ausgewählt. Eine Tabu-Liste speichert die dabei relevanten Eigenschaften der Auswahl, um sie später als Tabu festlegen zu können.
2 MATHEMATISCHE GRUNDLAGEN 11 Abbildung 3: Dieses Flussdiagramm zeigt das Vorgehen bei einer Tabu-Suche basierend auf Pham et al. [19]. Da in jedem Schritt auch eine Verschlechterung des Zielfunktionswerts erlaubt ist, kann es durch wiederholtes Besuchen der gleichen Lösung zu endlosen Zyklen kommen, dies wird durch geeignet gewählte Tabus verhindert. Die Tabu-Suche wird durch die drei Hauptstra- tegien Forbidding Strategy, Freeing Strategy und Short-Term Strategy bestimmt [19]. Die Forbidding Strategy beschreibt, was als Tabu festgelegt wird. Möchte man Zyklen vermeiden, reicht es aus zu überprüfen, ob man eine Lösung vorher bereits besucht hat. Theoretisch kann man dafür alle zuvor besuchten Lösungen speichern und diese in jedem Schritt überprüfen, allerdings benötigt dieses Vorgehen viel Rechenzeit und Speicher. Eine Alternative ist es, nur die besuchten Lösungen der letzten Ts Schritte zu überprüfen, auf diese Weise entfernt sich die Suche von diesen Lösungen. Man bezeichnet Ts als die Größe der Tabu-Liste. Wählt man diese zu klein, können wieder Zyklen auftreten, doch wählt man sie zu groß, könnten günstige Suchgebiete zu früh verlassen werden [19]. Durch die Freeing Strategy wird festgelegt, was aus der Tabu-Liste befreit beziehungs- weise entfernt wird, da es unter Umständen sinnvoll sein kann, Lösungen erneut in Betracht zu ziehen, wenn diese beispielsweise in einem günstigen Suchgebiet liegen. Ein möglicher Teil dieser Strategie ist, dass eine Lösung nach Ts Schritten aus der Tabu-Liste entfernt wird und dann als zulässig gilt. Im genauen Gegensatz zu den Tabus stehen die Aspirati- onskriterien, also günstige und erstrebenswerte Eigenschaften von Lösungen. Ein Aspirati- onskriterium beschreibt, was eine Lösung erfüllen muss, um trotz Eintrag in der Tabu-Liste zulässig zu sein und dient so dazu, das Suchverfahren zu steuern [19].
12 2 MATHEMATISCHE GRUNDLAGEN
Die Short-Term Strategy regelt die Zwischenschritte und damit das Zusammenspiel der
zuvor genannten Strategien. Für die Tabu-Suche ergibt sich so der in Abbildung 3 gezeigte
Ablauf. Ausgehend von einer Startlösung wird eine Liste für Kandidaten von in Frage kom-
menden Lösungen erstellt. Diese Kandidaten werden bewertet, um daraus im Anschluss
die beste zulässige Lösung auszuwählen. Dabei spielen die Tabu-Liste und die Aspirations-
kriterien die entscheidende Rolle. Ist ein festgelegtes Abbruchkriterium erreicht, so endet
der Algorithmus mit einer Lösung. Ist dies nicht der Fall, so werden die Tabu-Liste und
mögliche Aspirationskriterien aktualisiert und das Vorgehen wiederholt sich [19].
2.3.3 Simulated Annealing
Simulated Annealing (dt. simuliertes Abkühlen) umfasst alle Heuristiken, die sich an den
Prozessen beim Abkühlen von Metall orientieren, da dabei ein energiearmer Zustand nahe
dem Minimum erreicht wird [19].
Grundidee ist die Nachbildung eines Abkühlungsprozesses, etwa beim Glühen in der Me-
tallurgie. Dabei wird Metall stark erhitzt und anschließend langsam abgekühlt bis es kris-
tallisiert, also fest wird. Im hocherhitzten Zustand befinden sich die Atome des Materials
auf einem hohen Energieniveau und können sich freier anordnen, sobald sich die Tempe-
ratur reduziert, ordnen sie sich in einer Kristallstruktur an, für die das System minimale
Energie hat. Die Wahrscheinlichkeitsverteilung der Energie des Systems bei einer festen
Temperatur wird wie folgt durch die Boltzmann-Verteilung beschrieben:
P (E) ∼ e−E/(kT ) .
Hier ist E die Energie des Systems, k ist die Boltzmann-Konstante, T ist die Temperatur
und P (E) gibt die Wahrscheinlichkeit dafür an, dass sich das System im Zustand mit der
Energie E befindet. Daraus kann man folgern, dass das System selbst bei niedrigen Tempe-
raturen mit einer geringen Wahrscheinlichkeit höhere Energieniveaus annehmen kann [19].
Im Vergleich mit einem Optimierungsproblem bedeutet das, dass man ein lokales Opti-
mum auch wieder verlassen kann, um so eventuell ein besseres lokales Optimum zu finden.
Dabei stehen feste Aggregatzustände für zulässige Lösungen des Problems und die Energie
des Systems entspricht dem Zielfunktionswert. Somit ist der energieärmste Zustand die
optimale Lösung des Problems [19].
Aufbau und Ablauf des Algorithmus
Der Algorithmus bestimmt schrittweise Lösungen, dabei wird in jedem Schritt eine neue
Lösung in der Nachbarschaft der aktuellen Lösung generiert, indem diese zufällig verändert
wird. Bei diesem Vorgehen kann man sich teilweise an den genetischen Algorithmen (vgl.
Kapitel 2.3.1) orientieren. Wie bei diesen benötigt man zunächst eine geeignete Darstel-
lungsform für die Lösungen. Bei der zufälligen Veränderung der Lösung kann man sich
an den genetischen Operatoren orientieren oder andere Operatoren benutzen. Man führt
außerdem ähnlich der Fitnessfunktion eine Kostenfunktion ein, welche jedem Zielfunkti-2 MATHEMATISCHE GRUNDLAGEN 13
Abbildung 4: Dieses Flussdiagramm zeigt den Ablauf eines Simulated Annealing Algorith-
mus basierend auf Pham et al. [19].
onswert Kosten zuweist, um eine Vergleichbarkeit zu ermöglichen [19].
Die Änderung der Kostenfunktion zwischen aktueller und neuer Lösung wird genutzt, um
zu entscheiden, ob die neue Lösung akzeptiert werden kann. Ist diese Änderung negativ, so
wird die Lösung akzeptiert und aktualisiert. Ist dies nicht der Fall, so wird basierend auf
dem Metropolis-Kriterium entschieden. Das Metropolis-Kriterium nutzt die Boltzmann-
Verteilung und besagt, ist die Änderung der Kostenfunktion größer oder gleich Null, dann
erzeuge ein zufälliges δ ∈ [0, 1] mittels einer stetigen Gleichverteilung. Gilt dann
δ ≤ e(−∆E/T ) ,
so akzeptiere und aktualisiere die Lösung. Gilt dies nicht, behalte die aktuelle Lösung bei.
Die Änderung der Kostenfunktion wird dabei durch ∆E beschrieben [19].
Im Anschluss folgt die namensgebende Abkühlung, da abhängig vom Ablauf die Tem-
peratur verringert wird. Der Ablauf der Abkühlung beinhaltet die Starttemperatur, eine
Update-Regel für die Temperatur, die Anzahl durchzuführender Schritte je Temperaturstu-
fe und ein Abbruchkriterium für den Algorithmus. Wird die Temperatur nicht verringert,
so wird aus der aktualisierten Lösung eine neue aktuelle Lösung generiert und der nächste
Schritt beginnt von vorn. Wird die Temperatur verringert, so wird geprüft, ob das Ab-
bruchkriterium erreicht ist. Ist dies nicht der Fall, so wird ebenfalls aus der aktualisierten
Lösung eine neue aktuelle Lösung generiert und der nächste Schritt gestartet. Ein typischer
Ablauf des Algorithmus ist in Abbildung 4 zu sehen [19].15
3 Technische Grundlagen
3.1 Schall im Wasser
Die Schallgeschwindigkeit, der Wellenwiderstand und die Absorption von Schall sind ent-
scheidende Faktoren bei der Ausbreitung von Schall im Wasser. Sowohl die Temperatur
T , der Salzgehalt S, als auch der hydrostatische Druck P spielen dabei eine große Rolle,
da sie Einfluss auf die übrigen Parameter nehmen. Der Druck P hängt dabei direkt von
der Meerestiefe z ab, wobei z = 0 die Meeresoberfläche darstellt. Bei niedrigen Frequenzen
spielt außerdem der pH-Wert eine Rolle [2].
Für eine bessere Übersicht in den folgenden Formeln definiere ich folgende dimensionslose
Variablen:
P
P̂ ≡
1P a
z
ẑ ≡
1m
T
T̂ ≡
1K
Der hydrostatische Druck P steigt monoton mit der Tiefe z an. Für übliche Verhältnisse
lässt sich diese Abhängigkeit wie folgt beschreiben:
P̂ (z) = 98066.5[1.04 + 0.102506(1 + 2.64 · 10−3 )ẑ + 2.524 · 10−7 ẑ 2 ]
Die Temperatur T beträgt in vielen Gebieten der Tiefsee etwa 2◦ C, allerdings ist sie in
der Nähe der Wasseroberfläche stärkeren Schwankungen ausgesetzt, welche beispielsweise
durch die Jahreszeit ausgelöst werden. So besteht beispielsweise im Mittelmeer eine Tem-
peraturdifferenz von etwa 15◦ C zwischen Winter und Sommer. Weiterhin befindet sich
darunter die Thermokline, also ein Bereich, in welchem die Temperatur stark mit steigen-
der Tiefe abfällt. Möchte man also, statt mit Durchschnittswerten, mit genauen Werten
arbeiten, so sind Messungen nötig [2].
Die Salzhaltigkeit hat einen vergleichsweise geringen Einfluss auf die Schallgeschwindig-
keit im Wasser, außerdem liegen die meisten großen Ozeane mit Werten von 34.5 bis 35
Gramm Salz pro Kilogramm Wasser sehr dicht beieinander, weshalb es mitunter genügt
einen Durchschnittswert von 34.7 zu verwenden. Für spezielle Gewässertypen ist eine Mes-
sung nötig, welche die Salzhaltigkeit durch die Leitfähigkeit bestimmt und gleichzeitig mit
einer Temperaturmessung durchgeführt werden kann [2].
Ich betrachte nun die Schallgeschwindigkeit im Wasser, sie liegt in der Größenordnung
von cwasser ≈ 1500 m/s. Da aber sowohl Temperatur, Salzgehalt, als auch Druck von der16
Tiefe abhängen, wird die Schallgeschwindigkeit dadurch stark beeinflusst. Die tatsächliche
Schallgeschwindigkeit wird durch eine sehr komplizierte Funktion, welche von der Salzhal-
tigkeit S, der Temperatur T und dem Druck P abhängt, beschrieben. Für die Modellierung
von Sonartechnik genügt es glücklicherweise, die Schallgeschwindigkeit in m/s durch eine
vereinfachte Formel darzustellen:
ĉ(S, T, z) =1448.96 + 4.591T̂ − 0.05304T̂ 2 + 2.374 · 10−4 T̂ 3 + (1.340 − 0.01025T̂ )
· (S − 35) + 0.0163ẑ + 1.675 · 10−7 ẑ 2 − 7.139 · 10−13 T̂ ẑ 3 .
Diese Formel bestimmt die Schallgeschwindigkeit mit einer Präzision von ±0.07 m/s, für
−2 < T̂ < 30
25 < S < 40
0 < ẑ < 8000
und ist somit für die meisten Anwendungsgebiete geeignet [2].
Besonders bei Sonarsystemen für große Distanzen spielt die Absorption von Schall eine
große Rolle. Die Viskosität hat einen großen Einfluss auf Schallwellen mit hohen Frequenzen
von 1 M Hz oder höher. Die Temperatur und die Salzhaltigkeit spielen dabei die Hauptrolle.
Bei niedrigen Frequenzen von bis zu 300 kHz hängt die Absorption vor allem vom Druck
und vom pH-Wert ab. Doch auch Blasenbildung und eine große Anzahl an Fischen kann
einen Einfluss auf die Absorption des Schalls haben [2].
Breitet sich Schall ausgehend von einer Stelle gleichmäßig aus, so kommt es zu einem
Übertragungsverlust, welcher durch
T L = 20 log d
beschrieben werden kann. Dabei spielt lediglich der Abstand d zur Schallquelle eine Rolle
[17].
3.2 Zielerkennung beim Sonar
Sendet man eine Schallwelle von einem Gerät zu einem Ziel, so benötigt diese eine gewisse
Zeit. Ich gehe von der Annahme aus, dass sich Schallwellen mit einer konstanten Geschwin-
digkeit cwasser fortbewegen. So lässt sich jeder zurückgelegten Zeit τ eine Distanz d wie
folgt zuordnen [1]:
d = τ · cwasser .
Im Sinne der Übersichtlichkeit verwende ich ab jetzt nur noch Distanzen und nicht die
Reisezeit der Schallwellen. Im Folgenden werde ich Ziele mit t, Empfänger mit r und
Sender mit s bezeichnen. Sei nun die Distanz vom Ziel zum Empfänger dt,r , die Distanz
vom Ziel zum Sender dt,s und die Distanz vom Empfänger zum Sender dr,s . Die Range of
the Day ρ0 beschreibt die bekannte maximale Reichweite des monostatischen Sonars [5].3 TECHNISCHE GRUNDLAGEN 17
3.2.1 Cookie-Cutter Erkennungswahrscheinlichkeiten
Die Wahrscheinlichkeit, mit der das Sonar ein Ziel erkennt, lässt sich am einfachsten mit
dem Cookie-Cutter Modell angeben. Das bedeutet, dass diese Wahrscheinlichkeit innerhalb
der maximalen Reichweite bei 1 und außerhalb bei 0 liegt. Für das monostatische Sonar
ergibt sich so mit d = dt,s = dt,r folgende Erkennungswahrscheinlichkeit [9]:
1 für d ≤ ρ ,
0
pt,s,r = (3.1)
0 sonst.
Abbildung 5: Typisch auftretende Formen Cassinischer Kurven für verschiedene dr,s basie-
rend auf Craparo et al. [6].
Für das multistatische Sonar lässt sich die Entdeckungswahrscheinlichkeit nicht so trivial
angeben, da sich Sender und Empfänger nicht an derselben Stelle befinden. Ich betrachte
zunächst die auftretenden Übertragungsverluste T L beim Aussenden der Schallwellen. Laut
Fewell und Ozols [9] beschreibt dies im monostatischen Fall
T Lmono = 20 log d2 = 40 log d (3.2)18 3 TECHNISCHE GRUNDLAGEN
und im multistatischen Fall
T Lmulti = 20 log dt,r dt,s . (3.3)
Durch das Einführen der sogenannten äquivalenten monostatischen Reichweite
p
dequiv = dt,r dt,s (3.4)
lassen sich die Gleichungen (3.2) und (3.3) ineinander überführen [9].
Ersetze ich nun in der Gleichung (3.1) die Distanz d durch dequiv , so erhalte ich die Erken-
nungswahrscheinlichkeit für das multistatische Sonar mit:
1 für d d = ρ2 ≤ ρ2 ,
t,s t,r t,s,r 0
pt,s,r = (3.5)
0 sonst.
Betrachtet man jetzt den Fall dt,s dt,r = ρ20 , ergibt sich für die maximale Reichweite des
Sonars eine sogenannte Cassinische Kurve, deren Form vom Abstand dr,s und von der
maximalen monostatischen Reichweite ρ0 abhängt [6].
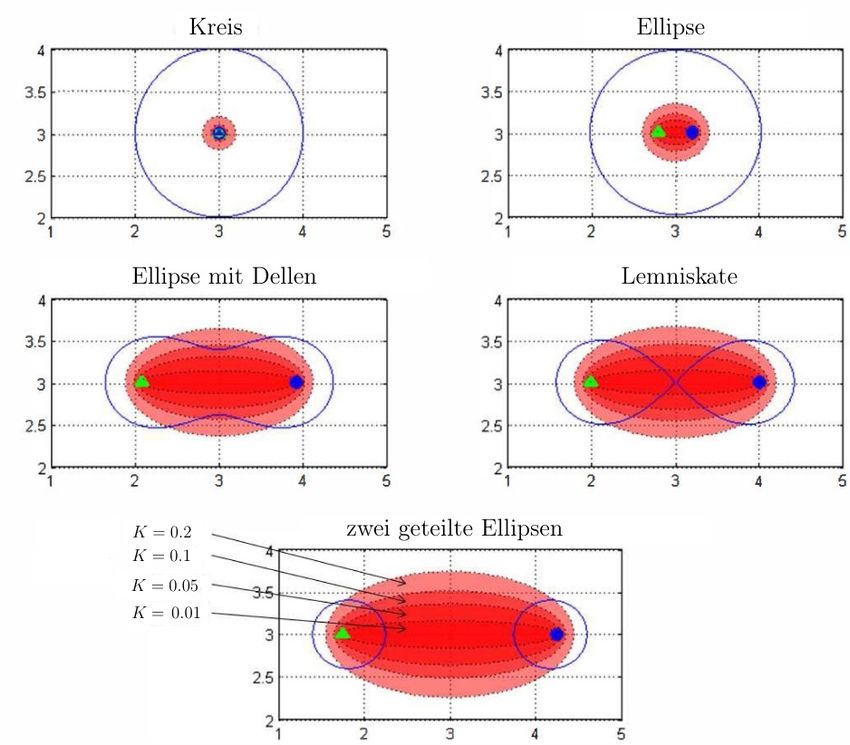
Die Abbildung 5 zeigt die typischen Arten der Cassinischen Kurve für ρ0 = 1. Wählt
man den Abstand dr,s = 0, so ergibt sich die für monostatische Sonare typische Form, ein
√
Kreis mit dem Radius ρ0 . Für 0 ≤ dr,s < 2 · ρ0 beschreibt die Kurve eine Ellipse. Für
√
2 · ρ0 ≤ dr,s < 2 · ρ0 bilden sich von oben und unten Dellen im Zentrum der Ellipse. Im
Spezialfall dr,s = 2ρ0 nimmt sie die Form einer Lemniskate an. Und für dr,s > 2ρ0 bilden
sich zwei geteilte Ellipsen [6].
3.2.2 Probabilistische Erkennungswahrscheinlichkeiten
In der Praxis nimmt die Erkennungswahrscheinlichkeit mit steigender Distanz ab, weshalb
neben dem simplen Cookie-Cutter Modell ein probabilistischer Ansatz verwendet wird.
Dabei wird ein Ziel t von einem Sender s und einem Empfänger r mit der Wahrschein-
lichkeit pt,s,r ∈ [0, 1] erkannt. Der Rand der Cassinischen Kurve dt,s dt,r ≤ ρ20 , beschreibt
dabei den Bereich, für den pt,s,r = 0.5 gilt. Bewegt man sich in das Innere des Ovals, so
erreicht die Erkennungswahrscheinlichkeit ein Maximum Pmax , bewegt man sich hingegen
nach Außen, so flacht sie auf den Wert 0 ab. In der praktischen Anwendung rundet man
die Wahrscheinlichkeit auf 0, sobald sie einen Wert Pmin unterschreitet, da dann das Signal
zu schwach ist [10].
In der Literatur werden zwei verschiedene Arten von Funktionen verwendet, um die Er-
kennungswahrscheinlichkeit möglichst gut zu beschreiben. Die Fermi-Funktion
1
ft,s,r := d−1 (3.6)
1 + 10 b1
mit
dt,s · dt,r
d :=
ρ20
ist die erste Möglichkeit, diese Wahrscheinlichkeit zu beschreiben. Der Parameter b1 beein-
flusst dabei, wie steil die Kurve verläuft, also wie schnell die Wahrscheinlichkeit von nahe 13 TECHNISCHE GRUNDLAGEN 19
für geringe Distanzen zu nahe 0 für große Distanzen wechselt. Lässt man b1 gegen 0 laufen,
so gleicht sich das Modell dem Cookie-Cutter Modell an [10]. Als zweite Möglichkeit kann
eine Exponentialfunktion der Gestalt
et,s,r := 10−0.30103·d (3.7)
genutzt werden. Die ungewöhnliche Zahl im Exponenten stellt dabei sicher, dass pt,s,r = 0.5
auf dem Rand des Cassini Ovals gilt [9].
Da ich mich stark am Artikel „Solving multistatic sonar location problems with mixed-
integer programming“ [10] orientiere, verwende ich in der weiteren Arbeit die Fermi-
Funktion.
3.2.3 Direct Blast Effect
Zwischen Sender und Empfänger gibt es einen Bereich, in dem Ziele nicht erkannt werden
können, genannt Blind Zone. Trifft die vom Ziel reflektierte Schallwelle beim Empfänger
ein, während dieser noch die ursprünglich ausgesendete Schallwelle empfängt, so kann dieser
die beiden Schallwellen nicht voneinander unterscheiden. Diesen Effekt nennt man Direct
Blast Effect [10]. Die Pulsdauer der ausgesendeten Schallwelle bezeichne ich als τ und ihre
Geschwindigkeit als ν. Schicke ich nun eine Schallwelle los, so erreicht diese den Empfänger
während des Zeitintervalls
ds,r ds,r
[ , + τ ].
ν ν
Das vom Ziel reflektierte Echo kommt während des Zeitintervalls
ds,t + dt,r ds,t + dt,r
[ , + τ]
ν ν
an. Überlagern sich diese Intervalle, gilt also
ds,t + dt,r ds,r
< + τ, (3.8)
ν ν
so trifft das Echo ein, während die ursprüngliche Schallwelle noch empfangen wird und
τ ·ν
es ist keine Zielerkennung möglich. Mit der Pulslänge kb := 2 erhalte ich die zu (3.8)
äquivalente Ungleichung
dt,s + dt,r < ds,r + 2kb , (3.9)
diese dient als Bedingung für die durch den Direct Blast Effect hervorgerufene Blind Zone
[7]. Die Pulslänge ist also entscheidend, da ein reflektierter längerer Puls sich eher mit
dem ursprünglichen Signal überlagert. Um diesen Effekt anschaulich darstellen zu können,
kb
führe ich den Parameter K := ρ0 ein. Die Abbildung 6 zeigt die Blind Zones für K = 0.01,
K = 0.05, K = 0.1 und K = 0.2 für die verschiedenen Formen der Cassinischen Kurven
[7].
Wird diese Ungleichung im Cookie-Cutter Modell erfüllt, liegt also ein Ziel in diesem
Bereich, so gilt für die Erkennungswahrscheinlichkeit pt,s,r = 0 [10]. Es genügt hier, wenn20 3 TECHNISCHE GRUNDLAGEN
Abbildung 6: Durch den Direct Blast Effect hervorgerufene Blindzone für mehrere K und
verschiedene Formen der Cassinischen Kurven basierend auf Craparo et al. [7].
man die Ungleichung (3.9) als Bedingung zur Gleichung (3.5) hinzufügt, man erhält so:
1 für d d = ρ2 ≤ ρ2 und dt,s + dt,r ≥ ds,r + 2kb ,
t,s t,r t,s,r 0
pt,s,r = (3.10)
0 sonst.
Für das probabilistische Modell beschreibt diesen Effekt eine Fermi-Funktion der Gestalt
1
Ft,s,r := 1−d˜
1 + 10 b2
mit
dt,s + dt,r
d˜ := .
ds,r + 2kb
Somit ergibt sich eine Erkennungswahrscheinlichkeit
p̃t,s,r := Pmax · ft,s,r · Ft,s,r . (3.11)
Die Menge G beinhaltet alle Platzierungsmöglichkeiten für Ziele, Sender und Empfänger.3 TECHNISCHE GRUNDLAGEN 21
Da ein Ziel von mehr als einem Paar, bestehend aus Sender und Empfänger, abgedeckt
werden kann und diese voneinander unabhängig sind, erhält man die Wahrscheinlichkeit,
dass wenigstens ein Paar das Ziel t erkennt, mit
Y
1− (1 − p̃t,s,r )
s,r∈G
Ein Ziel t wird genau dann erkannt, wenn diese Wahrscheinlichkeit einen vorher festgelegten
Wert φ ∈ (0, 1) überschreitet, also wenn
Y
1− (1 − p̃t,s,r ) ≥ φ (3.12)
s,r∈G
gilt. Durch das Ziehen des Logarithmus lässt sich diese Formulierung wie folgt linearisieren:
X
log1−φ (1 − p̃t,s,r ) ≥ 1.
s,r∈G
Dadurch lässt sich der Beitrag zur Gesamterkennungswahrscheinlichkeit eines Ziels t für
ein einzelnes Sender-Empfänger-Paar mit
pt,s,r := log1−φ (1 − p̃t,s,r ) (3.13)
angeben [10].
3.2.4 Bresenham-Algorithmus
Befindet sich irgendwo zwischen Sender und Empfänger, Ziel und Sender oder Ziel und
Empfänger ein Hindernis, wie zum Beispiel eine Insel, so können die Schallwellen nicht alle
nötigen Sonargeräte erreichen und eine Zielerkennung ist ebenfalls nicht möglich. Es ist
also nötig zu prüfen, ob solche Hindernisse existieren.
Da ich später mit diskreten Werten am Computer arbeiten möchte, nutze ich den Bresenham-
Algorithmus. Dieser ermöglicht das Zeichnen von Geraden auf Rastern. Prüfe ich jeden
Punkt einer solchen Geraden, so kann ich feststellen, ob sich ein Hindernis auf ihr befindet.
Um den ursprünglichen Bresenham-Algorithmus zu erklären, betrachte ich zunächst den
ersten Oktant, also eine Steigung zwischen 0 und 1. Für andere Oktanten muss man den
Algorithmus entsprechend anpassen [3]. Der Startpunkt sei (x0 , y0 ) und der Zielpunkt
(x1 , y1 ). Ich lege die Abstände dx = x1 − x0 und dy = y1 − x0 fest, wobei für diesen Oktant
0 < dy ≤ dx gelten muss. Da hier dx ≥ dy gilt, mache ich zunächst Schritte in x-Richtung
und auch immer wieder einen Schritt in y-Richtung, abhängig von der Steigung. Um zu
wissen, wann ich einen Schritt in y-Richtung machen muss, nutze ich die Fehlervariable err.
Bei einem Schritt in x-Richtung subtrahiere ich dy und bei einem Schritt in y-Richtung
addiere ich dx zu err [27].
Da der ursprüngliche Bresenham-Algorithmus nur auf den ersten Oktant angewandt wird,
verwende ich eine modifizierte Version, welche mir eine Linie in allen Richtungen erlaubt.
Außerdem möchte ich, anstatt eine Linie zu zeichnen, lediglich prüfen, ob sich ein Hin-22 dernis am jeweiligen Punkt befindet. Der folgende Pseudocode zeigt diesen modifizierten Algorithmus [27]: Algorithmus 1 Modifizierter Bresenham-Algorithmus Input: Startpunkt (x0 , y0 ), Endpunkt (x1 , y1 ) Output: true, wenn ein Hindernis vorhanden ist, sonst f alse 1: dx = |x1 − x0 |, dy = −|y1 − y0 | 2: if x0 < x1 then 3: sx = 1 4: else 5: sx = −1 6: end if 7: if y0 < y1 then 8: sy = 1 9: else 10: sy = −1 11: end if 12: err = dx + dy 13: while Endpunkt nicht erreicht und kein Hindernis gefunden do 14: e2 = 2 · err 15: if bei (x0 , y0 ) Hindernis gefunden then 16: return true 17: end if 18: if (x0 , y0 ) = (x1 , y1 ) then 19: return f alse 20: end if 21: if e2 > dy then 22: err = err + dy 23: x0 = x0 + sx 24: end if 25: if e2 < dx then 26: err = err + dx 27: y0 = y0 + sy 28: end if 29: end while Je nach Lage des Start- und Endpunkts wird die Schrittrichtung durch Veränderung der Vorzeichen der Schritte sx und sy angepasst. Die Abbildung 7 verdeutlicht das Vorgehen des Algorithmus an einem einfachen Beispiel, in der Abbildung gilt dx = 5 und dy = −4. Die grünen Kacheln zeigen die durch den modifizierten Bresenham-Algorithmus abgelaufe- ne Linie, dabei wird in jedem Schleifendurchlauf überprüft, ob e2 < dx und/oder e2 > dy gilt und der entsprechende Schritt durchgeführt. Bei einem Schritt in y-Richtung addiert man 2dx und bei einem Schritt in x-Richtung 2dy zu e2 hinzu. In allen bis auf den dritten Schritt gilt sowohl e2 < dx, als auch e2 > dy und es wird entsprechend ein Diagonal- schritt durchgeführt. Im dritten Schritt gilt lediglich e2 > dy und es wird nur ein Schritt in x-Richtung durchgeführt. Die Linie endet, als das Ziel (x1 , y1 ) erreicht wird [27].
3 TECHNISCHE GRUNDLAGEN 23 Abbildung 7: Beispiel für das Vorgehen des modifizierten Besenham-Algorithmus in An- lehnung an Zingl [27]. 3.3 Bekannte Modelle Um das im folgenden Kapitel 4 vorgestellte Modell zu lösen, existieren bereits einige Ver- fahren, bei denen man spezielle Modellformulierungen lösen muss. Ich möchte in diesem Kapitel zwei zugrunde liegende Modellformulierungen für den späteren Vergleich vorstel- len, um zu verdeutlichen, weshalb ein heuristischer Lösungsansatz sinnvoll ist. Das ursprüngliche Modell lässt sich nur unter großem Aufwand lösen, da die Ungleichun- gen (4.1) für das Problem der Abdeckungsmaximierung und die Ungleichung (4.7) für das Problem der Kostenminimierung nichtlinear sind. Aus Gründen der Übersicht betrachte ich dabei nur das Maximierungsproblem, da es das Kompliziertere von beiden ist. Für das Minimierungsproblem lässt sich die Formulierung analog aufstellen. Seien nun g, g 0 ∈ G Gitterpunkte und t ∈ G Ziele. Zunächst berechne ich für alle Tripel (t, g, g 0 ) die Erkennungswahrscheinlichkeiten pt,s,r mit den Gleichungen (3.10) bzw. (3.13). Dieser Schritt erlaubt mir die Berechnung außerhalb der Modelle [10]. 3.3.1 Modellformulierung DISC-LOC Diese Formulierung basiert vorwiegend auf dem Artikel „Optimizing source and receiver placement in multistatic sonar networks to monitor fixed targets“ [5] sowie „Solving mul- tistatic sonar location problems with mixed-integer programming“ [10]. Er verwendet die in Kapitel 2.1.2 vorgestellten Möglichkeiten, um die Nebenbedingung (4.1) zu linearisieren und soll die optimale Platzierung der Sender und Empfänger mit Methoden für lineare
24 3 TECHNISCHE GRUNDLAGEN
Optimierungsprobleme ermöglichen.
Notwendige Mengen und Variablen
Neben pt,s,r benötige ich folgende binäre Variablen:
sg : Nimmt Wert 1 an, falls sich ein Sender am Gitterpunkt g befindet.
rg : Nimmt Wert 1 an, falls sich ein Empfänger am Gitterpunkt g befindet.
hg,g0 : Nimmt Wert 1 an, falls sich ein Sender am Gitterpunkt g und ein
Empfänger am Gitterpunkt g 0 befindet.
ct : Nimmt Wert 1 an, wenn das Ziel t erkannt wird.
Nebenbedingungen
Wird ein Ziel t von einem Sender auf g und einem Empfänger auf g 0 erkannt, so muss
gewährleistet sein, dass die Bedingung dt,s dt,r ≤ ρ20 der Gleichung (3.5) eingehalten wird.
Dies wird durch die beiden folgenden Nebenbedingungen sichergestellt:
hg,g0 ≤ sg ∀g, g 0 ∈ G, (3.14)
hg,g0 ≤ rg0 ∀g, g 0 ∈ G. (3.15)
Jedes Ziel t darf nur dann erkannt werden, wenn die Bedingung dt,s dt,r ≤ ρ20 für wenigstens
ein Dupel aus Gitterpunkten erfüllt ist. Damit dies eingehalten wird, genügt die Nebenbe-
dingung
X
ct ≤ hg,g0 ∀t ∈ G. (3.16)
(g,g 0 ):(t,g,g 0 )∈D
Um nicht die maximale Anzahl an verfügbaren Sensoren und Empfängern zu überschreiten,
benötige ich außerdem noch folgende Nebenbedingungen:
X
sg ≤ |S|, (3.17)
g∈G
X
rg ≤ |R|. (3.18)
g∈G
Weiterhin gilt für die Variablen:
sg , rg ∈ {0, 1} ∀g ∈ G, (3.19)
ct ∈ {0, 1} ∀t ∈ G, (3.20)
hg,g0 ∈ {0, 1} ∀g, g 0 ∈ G. (3.21)
Als Folge verfügt diese Formulierung über n2 zusätzliche Binärvariablen und n2 zusätzliche
Nebenbedingungen.Sie können auch lesen

















































