Google Code Search Alternativen
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Google Code Search Alternativen
Ruhr-Universität Bochum
Master-Praktikum Netz- und Datensicherheit
Wintersemester 2012
Oliver Domke
oliver.domke@rub.de
19. März 2013
1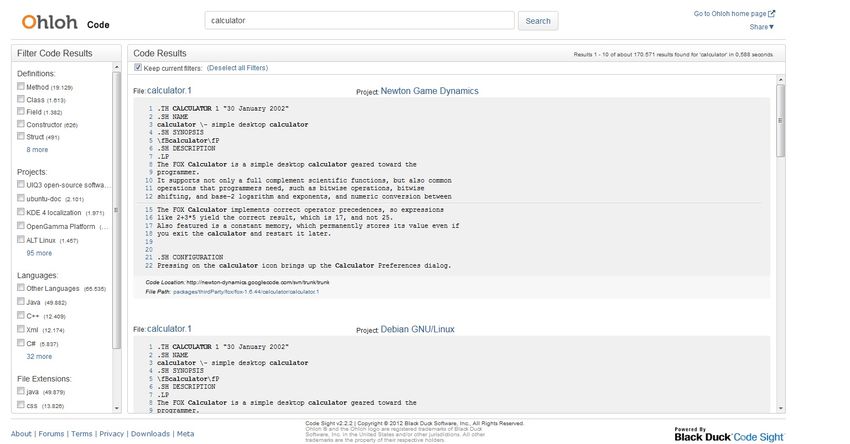
Inhaltsverzeichnis
1 Einleitung 3
2 Google Code Search & alternative Anbieter 4
2.1 Google-Dienste . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1.1 Google Code Search . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1.2 Google Project Hosting . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2 Code-Suchmaschinen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2.1 Krugle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2.2 Ohloh Code (ehemals Koders) . . . . . . . . . . . . . . . . . . . . . . 8
2.2.3 Merobase . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.4 MetaGer Code Search . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2.5 Searchcode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.3 Code-Repositorys . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.3.1 Snipt . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.3.2 GitHub . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.3.3 Antepedia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3 Testergebnisse & Diskussion 15
3.1 Codebasis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.2 Suchoptionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.3 Formate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.4 Treerquote . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.5 Bedienbarkeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4 Zusammenfassung & Empfehlung 22
2
1 Einleitung
Der US-amerikanische Internetdienstleistungsanbieter Google Inc. veröentlichte im Ok-
tober 2006 im Rahmen seiner Projektsammlung Google Labs 1 ein Tool, das e
ziente
Codesuchen im Internet ermöglichte. Google Code Search 2 (in Deutschland Google Co-
desuche ), welches nach einer geschlossenen Betaphase im Dezember 2006 auch von je-
dem Benutzer eingesetzt werden konnte, war ein Nachschlagewerkzeug für öentlich zu-
gängliche Quellcodes im Internet. Der Service richtete sich im wesentlichen an Entwickler
und Programmierer, die den Dienst einsetzen sollten, um beispielhafte Codeausschnitte,
die Verwendungsmöglichkeiten von APIs, Funktionsde
nitionen und ähnliches e
zient zu
recherchieren.[1, 2]
Die Anwendung sammelte dazu Daten aus frei verfügbaren OpenSource-Codes, darunter
auch aus Archiven und Repositorys; zudem konnte jeder Benutzer eigenen Quellcode über
ein Formular für eine Aufnahme in die Datenbank einreichen. Googles Codesuche war ein
sehr mächtiges Werkzeug; es ermöglichte neben optionalen Filtern für bestimmte Dateity-
pen, Lizenzarten und Programmiersprachen auch die Suche mit Hilfe regulärer Ausdrücke -
was damals durchaus ein Alleinstellungsmerkmal für Online-Codesuchen darstellte.[A01, 4]
Dem überwiegend positiven Feedback zum Trotz gab Google am 14. Oktober 2011 be-
kannt, dass man die Arbeiten an Code Search im Zusammenhang mit der Schlieÿung von
Google Labs einstellen werde, um sich auf aussichts- und ertragreichere Projekte konzen-
trieren zu können. Seit dem 15. Januar 2012 steht das Projekt nun nicht mehr oziell zur
Verfügung, ein Groÿteil der Technik
oss jedoch in andere Produkte ein, wie in diesem
Fall Google Project Hosting .[5] Aktuell ist jedoch das auf dem letzten Entwicklungsstand
be
ndliche Interface von Google Code Search immer noch online aufrufbar, beschränkt sich
jedoch auf die Suche in Projekten, die bei Google Project Hosting hinterlegt sind.[A01] In
Folge dieser inhaltlichen Einschränkung stellt sich die Frage nach Alternativen. Im Rahmen
dieses Praktikums wurden daher alternative Anbieter von Werkzeugen zur Code-Recherche
ermittelt und mit Blick auf ihre Features, Nutzbarkeit und Qualität untersucht.
Im nächten Kapitel folgt eine Vorstellung von Google Code Search und einiger alterna-
tiver Anbieter. Die Funktionalität und Qualität der Dienste werden in Kapitel 3 näher
untersucht. Eine abschlieÿende Zusammenfassung und Empfehlung folgt in Kapitel 4.
1
Google Labs war eine Sammlung von Produkten im Entwicklungsstatus zu Demonstrations- und Test-
zwecken. Das Angebot wurde am 17. Oktober 2011 eingestellt.
2
Nicht zu verwechseln mit Google Code (heute auch Google Developers ), einer Sammlung von Entwick-
lungssoftware für diverse Google-Produkte.[3]
3
2 Google Code Search & alternative Anbieter
Es existiert eine Vielzahl von Webseiten, welche eine Möglichkeit zur Code-Recherche an-
bieten - einige besitzen auf den ersten Blick eine ähnliche Funktionalität wie Google Code
Search . Eine Auswahl dieser Anbieter wurde in diesem Praktikum auf ihre Nutzbarkeit,
3
Handhabbarkeit, sowie ihre Features und Treerqualität untersucht . In diesem Kapitel
werden die einzelnen Dienste, sowie ihre jeweiligen Funktionen und Arbeitsweisen, vorge-
stellt.
2.1 Google-Dienste
2.1.1 Google Code Search
Webseite: http://code.google.com/codesearch Status: Entwicklung eingestellt
Nutzbarkeit: frei zugänglich
Codebasis: seit Einstellung ausschlieÿlich Google Code
Sprachen: über 70 unterstützt, weitere Sprachen suchbar
Besonderheiten: umfangreiche Filtermöglichkeiten, Suche mit regulären Ausdrücken
Labs
Trotz dem o
ziellen Ende ist das ehemalige Google Code Search
-Projekt weiterhin
online verfügbar und soll als Referenz für den Vergleich mit den anderen Anbietern die-
nen. Sämtliche Arbeiten an dem Dienst wurden eingestellt; das Interface und die dahinter
stehende Technik be
nden sich somit auf dem Stand von Januar 2012.[5] Die Codesu-
che war als Unterstützung von Programmierern und zum Lernen gedacht und ermöglichte
die Recherche von Muster-Codes, Anwendungsbeispielen und Funktionsde
nitionen. Seine
umfangreiche Datenbank erzeugte Code Search durch das Crawlen von öentlich zugängli-
chem Quellcode im Internet. Mit einbezogen wurden dabei neben gängigen Code-Hosting-
Webseiten auch Archive (darunter .zip oder .tar.gz) und Repositorys (wie etwa CVS
oder SVN). Darüber hinaus hatten die Benutzer die Möglichkeit, eigene Quellcodes über
ein entsprechendes Formular für die Aufnahme in die Datenbank einzureichen.[4, 6]
Abbildung 1: Google Code Search Suchmaske
3
Es wurden nur solche Anbieter betrachtet, die sich nicht auf eine bestimmte Programmiersprache
spezialisiert haben. Die Auswahl wurde im Vorfeld des Praktikums auf einige aussichtsreiche Kandidaten
beschränkt.
4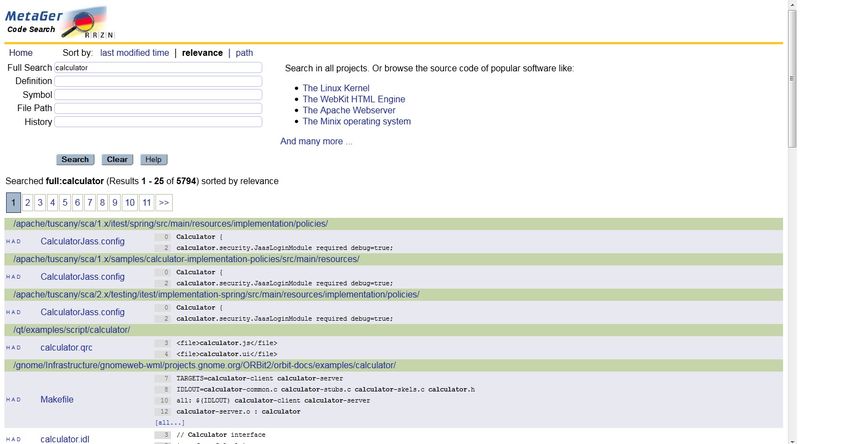
Das Alleinstellungsmerkmal zum Startzeitpunkt von Google Code Search war die Opti-
on zur Verwendung regulärer Ausdrücke als Suchanfrage (RegEx-Suche). Dadurch ist es
möglich, neben statischen Strings auch nach Mengen von Zeichen bzw. Zeichenketten zu
suchen, welche bestimmte Regeln erfüllen.[7] Diese Eigenschaft machte Code Search zu
einem sehr mächtigen Werkzeug zur Code-Recherche. Der Dienst unterstützt o
ziell über
70 Programmiersprachen; mit Hilfe regulärer Ausdrücke ist es jedoch möglich, uneinge-
schränkt nach jedem beliebigen Format zu suchen, selbst wenn dieses Google Code Search
selbst nicht bekannt sein sollte. Um die Suche noch e
zienter zu gestalten, können diverse
Filter eingesetzt werden, welche die Suchergebnisse noch weiter eingrenzen, zum Beispiel
hinsichtlich der Sprache, des Dateinamens oder der verwendeten (und zuvor automatisch
ermittelten) Softwarelizenz; eine Filterung nach Software für bestimmte Google-Produkte
wie das Android -Betriebssystem oder den Chrome -Browser wurde ebenfalls realisiert.[6]
Abbildung 2: Google Code Search Suchergebnisse
Die Suchergebnisse werden schlicht und übersichtlich präsentiert. Duplikate in den Treern
werden automatisch erkannt und ausgeblendet, um die Ergebnisse kompakter zu halten.
Jeder Treer kann angewählt werden, um zu einer Übersicht zu gelangen, die den kom-
pletten Code sowie die vollständige Verzeichnisstruktur des Projekts samt dazugehörigen
Quelltexten enthält. Eine automatische Syntaxhervorhebung bei kompatiblen Program-
miersprachen erhöht die Lesbarkeit der Quelltexte. Die in die Ergebnisdarstellung inte-
grierte Suchmaske ermöglicht eine tiefergehende Suche in ausgewählten Projekten. Auf
Wunsch gelangt man zudem über einen Backlink schnell zur Herkunft des Codes. Die ak-
tuell online verfügbare Codesuche beschränkt sich jedoch seit der Einstellung des Services
auf Quellcodes aus Projekten, die bei Google Project Hosting vorliegen.
2.1.2 Google Project Hosting
Webseite: http://code.google.com/ Status: aktiv
Nutzbarkeit: frei zugänglich
Codebasis: eigene
Sprachen: gängige, darunter HTML, Java(Script), C++, PHP u.a.
Besonderheiten: -
Code Search
Nach der Einstellung des -Angebots wurde ein Groÿteil der Funktionialität in
Google Project Hosting
den Service übertragen. Dieser Dienst sammelt nicht eigenständig
Daten, sondern bietet OpenSource-Entwicklern eine Umgebung für kollaboratives Arbeiten
an Software-Projekten. Zur Unterstützung der Entwicklungsarbeiten stehen unter anderem
eine Wiki-Software und Versionierungsservices verschiedener Anbieter zur Verfügung. Die
hinterlegten Daten aller Projekte sind für jeden Benutzer frei zugänglich.
5
Abbildung 3: Google Project Hosting
Die Suchfunktion der Seite, welche auch die Projekt-Hoster Eclipse Labs und Apache Ex-
tras einschlieÿt, erlaubt dank zahlreicher Filter ein schnelles Au
nden von Projekten zum
gewünschten Thema. Eine e
ziente Suche nach Mustercode gestaltet sich mit diesem Inter-
face jedoch recht schwierig, da lediglich die Dokumentationstexte der Projekte durchsucht
werden. Eine richtige Code-Recherche ist tatsächlich nur mit dem etwas versteckten, per
Direktlink [A01] aufrufbaren, und in Kapitel 2.1.1 beschriebenen Code Search -Interface
möglich.
2.2 Code-Suchmaschinen
2.2.1 Krugle
Webseite: http://opensearch.krugle.org/ Status: aktiv
Nutzbarkeit: frei zugänglich (Community-Funktion erfordern Registrierung)
Codebasis: Sourceforge, Google Code, CodePlex, Apache, JavaDocs, Wikipedia u.a.
Sprachen: alle gängigen, darunter Java, XML, C, PHP u.a.
Besonderheiten: Codeausschnitte als Suchanfrage verwendbar
Krugle ist eine Mitte 2006 veröentlichte Suchmaschine für OpenSource-Code, die ähn-
lichGoogle Code Search eigenständig Repositorys wie Sourceforge Google Project Hosting
,
oder MicrosoftsCodePlex , aber auch Datenbanken wie das Sun Developer Network und
Online-Lexika wieWikipedia nach wiederverwendbaren Quelltexten durchsucht und indi-
ziert. Dabei werden auch Dateien in Archiven, wie etwa .zip und .tar, berücksichtigt.
Verschiedene Filter ermöglichen eine e
ziente Suche nach Mustercode, beispielsweise ge-
trennt nach Programmiersprachen. Eine Suche mittels regulärer Ausdrücke ist nicht mög-
lich, dafür kann man neben Stichworten auch Codeausschnitte als Suchbegri verwenden;
Krugle sucht dann nach Projekten, in denen die angegebenen Segmente oder Funktions-
aufrufe bzw. Funktions- oder Klassende
nitionen vorkommen.
Die Suchergebnisse werden übersichtlich (und bei Erkennung der Sprache inklusive Syntax-
Highlighting) dargestellt und können im Anschluss weiter ge
ltert oder näher durchsucht
werden. Sofern verfügbar können auch die gesamte Dateistruktur sowie dazugehörige Do-
kumentationen abgerufen und ausgewählte Projekte einfach heruntergeladen werden. Um
die Herkunft nachvollziehen zu können, wird stets die Quell-URL und die eingetragene
Lizenz mit angegeben. Das Web-Interface ist jedoch lediglich eine Online-Demo der ei-
genständigen Krugle -Anwendung, die in erster Linie als Unternehmenslösung gedacht ist.
6
Abbildung 4: Krugle Suchergebnisse
In der kostenlosen, aber inhaltich eingeschränkten Basis-Version und der kostenp
ichti-
gen Enterprise-Fassung sind weitere Funktionen zur Inhaltsverwaltung oder kollaborativen
Projektarbeit verfügbar; mit Hilfe von Lesezeichen, Versionierungssoftware und der Opti-
on zum Anlegen von Codesammlungen wird so ein einfaches Code-Sharing möglich. Eine
weitere Funktion, die registrierten Nutzern der Anwendung vorbehalten ist, ist das Kom-
mentieren von Quellcodes und Projekten. Diese Kommentare werden auf Wunsch (auch im
Web-Interface) bei der Sucheanfrage berücksichtigt.
Abbildung 5: Krugle Detailansicht
Insgesamt ist die online verfügbare Suchmaschine zwar nur ein Teil der eigentlichen Krugle -
Software, für sich genommen ist es aber ein sehr nützliches Werkzeug zur Code-Recherche,
das in Bezug auf seinen Umfang und der Funktionalität Google Code Search sehr ähnlich
ist.
7
2.2.2 Ohloh Code (ehemals Koders)
Webseite: http://code.ohloh.net/ Status: aktiv
Nutzbarkeit: frei zugänglich (Community-Funktion erfordern Registrierung)
Codebasis: eigene, dazu Sourceforge, Google Code, GitHub u.a.
Sprachen: über 40 unterstützt, darunter alle gängigen wie HTML, C oder JavaScript
Besonderheiten: umfangreiche Filtermöglichkeiten
Ohloh Code ist das Ergebnis der Zusammenarbeit von Ohloh (ein Portal zur Katalogi-
sierung von OpenSource-Softwareprojekten) und der Code-Suchmaschine Koders . Durch
die Einbindung in die Services von Ohloh hat die Suchmaschine Zugri auf weitaus mehr
Quelltext-Datensätze als zuvor
4 und integriert dazu auch Community-Funktionen wie das
Kommentieren und Editieren von Informationen. Ohloh Code gewinnt seine Daten durch
das Crawlen gängiger Code-Repositorys (darunter Sourceforge Google Project Hosting
, und
GitHub ) und Versionsverwaltungssysteme (wie SVN oder CVS). Datensätze können zudem
auch, wie früher bei Google Code Search , direkt von den Benutzern über ein Formular ein-
gereicht werden.
Abbildung 6: Ohloh Code Suchergebnisse
Bei der Suche oder zur Sortierung der Suchergebnisse können zahlreiche Filter eingesetzt
werden. So ist es möglich, die Ergebnisse unter anderem nach Deklarationsarten, Funkti-
onsnamen, Objektde
nitionen, Programmiersprachen, Klassenbeschreibungen und vielem
mehr zu trennen. Eine Suche mit Hilfe regulärer Ausdrücke ist aktuell jedoch nicht mög-
lich. Die Darstellung der gefundenen Quellcodes ist - ähnlich der Optik von Google Code
Search und Krugle - sehr übersichtlich gestaltet. So wird zum Beispiel die Syntax der ent-
sprechenden Sprache hervorgehoben, sofern diese erkannt wird. Insgesamt werden derzeit
rund 40 verschiedene Programmiersprachen unterstützt.
4
Nach Angaben der Betreiber umfasst die Datenbank aktuell etwa 15,5 Milliarden Zeilen Code und ist
damit mindestens so umfangreich wie die konkurrierender Anbieter.[A05]
8
Abbildung 7: Ohloh Code Detailansicht
2.2.3 Merobase
Webseite: http://www.merobase.com/ Status: aktiv
Nutzbarkeit: frei zugänglich
Codebasis: gängige, darunter Sourceforge, Apache, Java.net u.a.
Sprachen: Java, C/C++/C# und WSDL
Besonderheiten: umfangreiche, einzigartige Suchoptionen
Die seit Anfang 2007 vom Lehrstuhl für Softwaretechnik der Universität Mannheim an-
gebotene Suchmaschine Merobase crawlt wie ihre Mitbewerber gängige Repositorys (wie
beispielsweise Sourceforge Apache
, oder Java.net ) und weitere öentlich im Internet zu-
gängliche Quelltexte. Bei der Suche bieten sich dem Nutzer diverse Filtermöglichkeiten an,
so können die Ergebnisse unter anderem nach Sprachen, Host, verwendeter Lizenz oder
5
Art des Programms (z.B. Anwendung, Servlet oder sogar Testroutinen ) sortiert werden.
Die Datenbank hat bereits rund 9 Millionen Einträge gelistet, jedoch unterliegt Merobase
- zumindest im Hinblick auf die suchbaren Programmiersprachen - einer deutlichen Ein-
schränkung: O
ziell unterstützt werden nur Java, C/C++/C# und Webservices (WSDL).
Abbildung 8: Merobase
5
Als Testroutine wird ein Programm bezeichnet, welches die zu testende Anwendung mit unterschiedli-
chen, vorab de
nierten Testfällen bzw. -parametern aufruft und sie auf mögliche Fehler in der Implemen-
tierung untersucht.
9
Die starke Fokussierung auf einige ausgewählte Programmiersprachen gleicht Merobase je-
doch mit einzigartigen Suchoptionen aus. Der Dienst ermöglicht nicht nur eine Suche nach
Mustercodes anhand von Stichworten, Strings, Methodenname oder ähnlichem; Software-
komponenten können auch anhand ihrer Schnittstellen gefunden werden. Bei einer funktio-
nalen Suche nach isEqual(int, int):boolean würde beispielsweise nach Code gesucht
werden, der eine Funktion mit dem Namen isEqual ist bzw. enthält, zwei int-Werte als
Eingabeparameter aufnimmt und einen Boolean-Wert zurückgibt. Eine objektorientierte
Suche ist nach dem gleichen Verfahren möglich. Darüber hinaus ermöglicht Merobase auch
die Suche nach JAR-Bibliotheken, JavaDocs und Webservices (letztere können auch direkt
ausgeführt werden). Alle Suchergebnisse sind stets mit einem Backlink, Kommentaren und
diversen Metriken versehen.
2.2.4 MetaGer Code Search
Webseite: http://code.metager.de/ Status: aktiv
Nutzbarkeit: frei zugänglich
Codebasis: eigene
Sprachen: alle gängigen
Besonderheiten: Datenbank umfasst viele populäre OpenSource-Projekte
MetaGer Code Search ist ein Ableger der deutschen Metasuchmaschine MetaGer und hat
sich auf eine Suche innerhalb OpenSource-Quelltexte spezialisiert. Betrieben wird die Such-
maschine von der Leibniz Universität Hannover. Anders als die bisher vorgestellten An-
bieter crawlt MetaGer Code Search jedoch das Internet nicht nach öentlich zugänglichen
Quellcodes, sondern stellt eine umfassende und (im Untersuchungszeitraum) regelmäÿig
aktualisierte Datenbank mit einer Auswahl mehr oder weniger bekannter OpenSource-
Projekte zur Verfügung, welche mit Hilfe des schlicht gehaltenen Interface durchsucht wer-
den kann. In der Liste der Projekte be
nden sich unter anderem aircrack-ng , der Linux -
Kernel, diverse Mozilla -Produkte und viele mehr.
Abbildung 9: MetaGer Code Search
Durchsucht werden kann die Datenbank anhand von Stichworten und einigen wenigen Fil-
tern, die sich auf Dateipfade oder De
nitionen beziehen. Insgesamt steht zwar eine durchaus
beachtliche Menge populärer Softwareprojekte zur Verfügung, dennoch ist der Suchraum
durch das fehlende Internet-Crawling stark eingegrenzt, so dass sich kaum allgemeine Code-
beispiele
nden lassen. Für Benutzer, die eine allgemeine Code-Recherche anstreben und
die nicht speziell an Quelltexten zu einem bestimmten OpenSource-Produkt interessiert
sind, erscheint MetaGer Code Search eher ungeeignet.
102.2.5 Searchcode
Webseite: http://searchco.de/ Status: aktiv
Nutzbarkeit: frei zugänglich
Codebasis: Sourceforge, Google Code, CodePlex, GitHub, Bitbucket, Fedora u.a.
Sprachen: über 100 unterstützt, weitere Sprachen suchbar
Besonderheiten: Suche mit regulären Ausdrücken möglich
Ein in gewisser Weise besonderes Projekt ist Searchcode. Diese Suchmaschine wurde von
einer einzelnen Person, Ben Boyter, entwickelt und steht im grundlegenden Funktionsum-
fangGoogle Code Search in fast nichts nach.[8] Searchcode indiziert selbstständig Einträge
aus mehreren Code-Repositorys, darunter nach eigenen Angaben Sourceforge Google Co-
,
de CodePlex GitHub Bitbucket
, , , und Fedora ; die Datenbank umfasst nach aktuellem Stand
über sechs Milliarden Zeilen OpenSource-Quelltext und Code-Ausschnitte, dazu kommen
noch unzählige Dokumentationstexte. Dank verschiedener Filteroptionen kann unter an-
derem getrennt nach Quellcode und Dokumentation, aber auch nach unterschiedlichen
Dateiendungen oder Programmiersprachen gesucht werden.
Abbildung 10: Searchcode Suchergebnisse
Wie bei Google Code Search ist auch eine Suche mittels regulärer Ausdrücke möglich.
Derzeit werden hierbei jedoch nur Prä
x-Suchen unterstützt, Ausdrücke in In
x-Notation
Searchcode
sind nicht zugelassen.[9] kennt knapp 100 Programmiersprachen (und somit
rund doppelt so viele wie die meisten Mitbewerber); weitere unbekannte Sprachen kön-
nen durch reguläre Ausdrücke gefunden werden.[10] Syntaxhervorhebungen werden bei
den gängigen Sprachen unterstützt, zudem liefert Searchcode umfangreiche Metriken zu
den gefundenen Datensätzen an.
Abbildung 11: Searchcode Detailansicht
112.3 Code-Repositorys
2.3.1 Snipt
Webseite: http://snipt.net/ Status: aktiv
Nutzbarkeit: frei zugänglich
Codebasis: eigene
Sprachen: alle gängigen, darunter HTML, Java(Script), C++, PHP u.a.
Besonderheiten: Testfälle und Webformate vorhanden
Code-Repositorys dienen zwar häu
g als Quellen der Suchmaschinen für Code-Recherchen,
sind in der Regel aber selbst nicht für eine Suche nach Mustercode geeignet, da die Ergeb-
nisse gröÿtenteils auf Kommentare und Dokumentationen zu Softwareprojekten verweisen.
Snipt ist ein Repository, das auf Wikis und Dokumentationstexte verzichtet und nur Co-
deausschnitte in seine öentlich zugängliche Datenbank aufnimmt, welche vom Benutzer
durchsucht werden kann. Zwar ist diese Datenbank mangels eigenständigem Crawling ver-
hältnismäÿig klein (im Untersuchungszeitraum waren etwa 50.000 Einträge vorhanden),
dennoch
nden sich darunter viele nützliche Beispiele und vorgefertigte Testfälle in allen
gängigen Programmiersprachen und für viele unterschiedliche Webformate wie etwa An-
wendungsbeispiele für WordPress.
Abbildung 12: Snipt
Für umfangreiche Recherchearbeiten bietet sich Snipt mangels vielfältiger Suchoptionen
jedoch nicht an. Die über Stichworte gefundenen Ergebnisse lassen sich zwar nach Sprache
oder Anwendungsfall
ltern, mehr Optionen sind darüber hinaus aber nicht möglich. Be-
nutzer, die auf der Suche nach vereinzelten Beispielen oder Anwendungsfällen sind, können
hier jedoch fündig werden.
2.3.2 GitHub
Webseite: http://github.com/ Status: aktiv
Nutzbarkeit: frei zugänglich (Community-Funktion erfordern Registrierung)
Codebasis: eigene
Sprachen: alle gängigen, darunter HTML, Java(Script), C++, PHP u.a.
Besonderheiten: -
Bei GitHub handelt es sich um ein Repository für Softwareprojekte, welches auch als
Grundlage für einige der bereits vorgestellten Suchmaschinen dient. Unter dem Claim So-
cial Coding verbindet es kollaboratives Arbeiten und eine Versionierung auf Basis von
Git mit Komponenten sozialer Netzwerke (zum Beispiele Kommentare oder eine Folgen-
Funktion). Für OpenSource-Projekte ist der Dienst kostenlos, es wird darüber hinaus
12aber auch ein kostenp
ichtiger Zugang angeboten, der das Erstellen privater Verzeichnisse
umfasst. GitHub ist einer der populärsten Anbieter für Projekt-Hosting; viele bekannte
Projekte wie PHP jQuery
, oder reddit nutzen diese Plattform für die Verwaltung ihrer
Quelltexte.[11]
Abbildung 13: GitHub
Das Suchfenster der Startseite durchsucht die gesamten Projekte und somit insbesondere
auch die Dokumentationstexte. Für reine Code-Recherchen im Stil von Google Code Search
bietet sich jedoch die erweiterte Suche unter https://github.com/search/advanced an,
denn hier kann eine Codesuche explizit ausgewählt werden. In diesem Fall liefert der Dienst
ausschlieÿlich in der Datenbank gefundene Quellcodes, welche wiederum automatisch nach
vielen verschiedenen Programmiersprachen ge
ltert werden können. Weitere Suchoptionen
stehen aber bei diesem eigentlich auf Projekt-Hosting spezialisierten Dienst nicht zur Ver-
fügung.
Anmerkung: Es existieren unzählige weitere Projekt-Hoster im Internet, die eine ähnli-
che Funktionalität wie aufweisen (zum Teil auch in Bezug auf Codesuche), zum
GitHub
Beispiel ,
Smipple ByteMyCode oder . Stellvertretend wurde einer der gröÿten und
Snippets
populärsten Dienste für die Untersuchung zu seiner Eignung als Code-Recherche-Tool her-
angezogen.
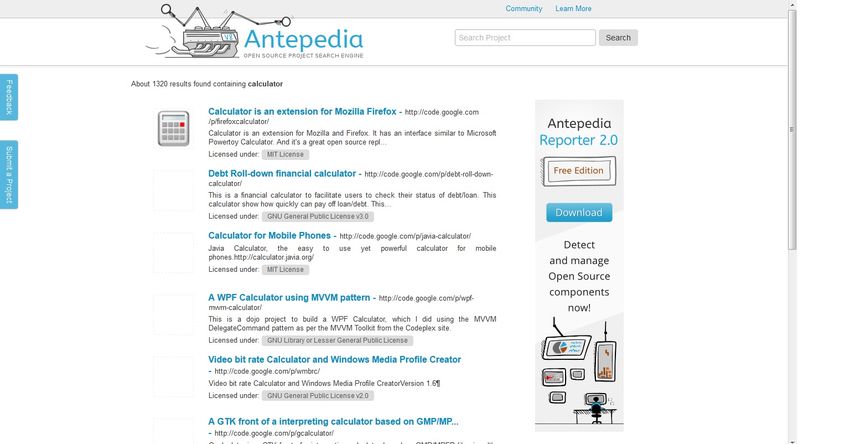
2.3.3 Antepedia
Webseite: http://www.antepedia.com/ Status: aktiv
Nutzbarkeit: frei zugänglich
Codebasis: Sourceforge, Google Code, GitHub, Eclipse, Apache u.a.
Sprachen: alle gängigen, darunter HTML, Java(Script), C++, PHP u.a.
Besonderheiten: Suche nach Sicherheitslücken möglich
Der letzte betrachtete Dienst eignet sich nur indirekt zur Code-Recherche, soll aber auf-
grund seiner verhältnismäÿig groÿen Datenbank an OpenSource-Projekten nicht unerwähnt
bleiben. Antepedia durchsucht das Internet nach öentlich zugänglichen Softwareprojekten
und nimmt sie in den eigenen Suchindex auf. Der Anbieter sammelt dazu Projektdaten
aus unterschiedlichen Quellen; zu den gröÿten durchsuchten Hostern gehören Google Co-
de Sourceforge GitHub Eclipse
, , , und Apache Antepedia
. aggregiert die zu Stichwörtern
gefundenen Ergebnisse aller Projekt-Hoster und listet die aufbearbeiteten Informationen
übersichtlich auf.
13Abbildung 14: Antepedia
Nach einer Weiterleitung zum ursprünglichen Hosting-Service lassen sich dann auch die
Quellcodes zum gewünschten Projekt abrufen - eine Ausgabe von Mustercodes direkt auf
der Antepedia -Webseite ist leider noch nicht möglich; derzeit liefert der Service lediglich
Backlinks. Die Datenbank, die jedoch eine beachtliche (und durch Crawling stetig wach-
sende) Anzahl an OpenSource-Projekten listet, kann dennoch bei der Suche nach Codebei-
spielen und Dokumentationen hilfreich sein. Als zusätzlichen interessanten Aspekt bietet
der Dienst die Möglichkeit an, die Codes und Projekte nach Sicherheitslücken zu durchsu-
chen. Dieser derzeit noch im Beta-Stadium be
ndliche Service führt zu jedem Projekt eine
regelmäÿig aktualisierte Liste aktueller potenzieller Schwachstellen. Somit sind einerseits
zu jedem Projekt bekannte Bugs übersichtlich zusammengefasst, andererseits sind explizi-
te Anfragen nach bestimmten Risiken wie zum Beispiel Password Encryption Weakness
möglich.
143 Testergebnisse & Diskussion
Um die alternativen Anbieter besser miteinander vergleichen zu können, wurden die Dienste
nach verschiedenen Kriterien in Bezug auf Funktionalität, Qualität und Nutzbarkeit unter-
sucht. Die Ergebnisse werden in diesem Kapitel vorgestellt und diskutiert. Eine Übersicht
aller untersuchten Kriterien be
ndet sich im Anhang ab Seite 24.
3.1 Codebasis
Eine wichtige Eigenschaft bei der Beurteilung von Codesuche-Anbietern ist die jeweils zu-
grunde liegende Codebasis. Grundsätzlich lassen sich bei dieser Art von Suchmaschinen
zwei Arbeitsweisen unterscheiden. Ein Teil der Anbieter setzt ausschlieÿlich auf eine eige-
ne Codebasis, welche nur durch regelmäÿige Updates der Entwickler oder das Einreichen
von Quellcodes durch die Benutzer anwächst. Alternativ dazu durchsuchen Dienste mit ei-
ner Crawling-Funktion selbstständig das Internet nach Repositorys und weiteren öentlich
zugänglichen OpenSource-Quelltexten, um diese dann in der eigenen Datenbank zu indi-
zieren und als Suchgrundlage zu verwenden.[12] In einigen Ausnahmefällen werden beide
Arbeitsweisen auch in Kombination eingesetzt.
Einer dieser Ausnahmefälle war - bis zu seiner Einstellung - Google Code Search . Die
Suchmaschine verwendete als Codebasis den
rmeneigenen Hosting-Dienst Google Code ,
durchsuchte aber das Internet zudem nach weiteren Quellcodes. Nutzer, die ihre eigenen
Mustercodes nicht selbst bei Google Project Hosting verwalten wollten, konnten diese auÿer-
dem auch über ein spezielles Formular für die Suchdatenbank zur Verfügung stellen. Mit
dem Entwicklungsstopp von Google Code Search wurde die Codebasis jedoch auf Google
Code beschränkt, Suchergebnisse anderer Herkunft werden seitdem nicht mehr aufgeführt.
Zwar steht somit immer noch eine beachtliche Menge an Projekten und Quelltexten zur
Verfügung, dennoch handelt es sich dabei nur noch um einen Bruchteil der ursprünglichen
Codebasis.
Einige der untersuchten Anbieter verwenden ausschlieÿlich ihre eigene Codebasis. Die deut-
sche Suchmaschine MetaGer Code Search arbeitet beispielsweise mit einer Datenbank aus
rund 4.000 Repositorys, in denen die Quellcodes von über 360 mehr oder weniger bekann-
ten OpenSource-Projekten hinterlegt sind. Die Datenbank wird nur durch Updates der
Entwickler aktualisiert, wodurch ein schnelles Wachstum der Datenbestände nahezu aus-
geschlossen sein dürfte. Ähnlich verhält es sich mit Snipt, einem Repository mit eigenem
Datenbestand. Der Dienst umfasst zwar viele einzigartige und spezielle Mustercodes, kann
aber mangels Crawling und häu
ger Updates nicht mit anderen Anbietern bei umfassen-
den Code-Recherchen mithalten. Favorit unter diesen Diensten ist GitHub , der mit über
drei Millionen Nutzern vor Sourceforge und Google Code gröÿte und populärste Hosting-
Dienst[11], der zudem auch ein Interface für Codesuchen im eigenen Datenbestand anbietet.
Im Gegensatz zu diesen Services arbeiten die untersuchten Anbieter Krugle Ohloh Co-
,
de Merobase
, und Searchcode mit Web-Crawling. Mittels dieser Methode wird der eigene
Datenbestand durch Indizieren groÿer Code-Repositorys und Durchsuchen des Internets
nach öentlich zugänglichen Codeausschnitten kontinuierlich erweitert. Dabei setzen die
oben genannten Anbieter im wesentlichen auf Code-Hoster wie Sourceforge Google Code
, ,
Microsoft CodePlex GitHub Bitbucket
, , und Fedora
, aber auch auf Projekte wie die Apache
15Software Foundation und Dokumentationstools wie JavaDocs . Diese gängigen Codebasen
werden von nahezu allen Anbietern als Suchgrundlage verwendet, die Unterschiede lie-
gen meist im Detail. So bezieht Krugle beispielweise auch Mustercodes von Wikipedia in
seine Datenbank mit ein. Sämtliche Crawling-Dienste durchsuchen aber nicht nur Hosting-
Webseiten nach öentlichen Quellcodes, sondern auch Archive (beispielweise .zip, .rar,
.tar, .tar.gz und .tar.bz2) und Repositorys bzw. Versionierungsverzeichnisse wie CVS
oder SVN.
Einzig Ohloh Code kombiniert - wie Google Code Search vor seiner Einstellung - beide
Ansätze und vereint die durch Crawling weiterhin stetig wachsende Datenbank der im
Jahr 2012 durch Ohloh übernommenen Code-Suchmaschine Koders mit der Codebasis des
namensgebenden Projekt-Hosters.[13] Mit derzeit weit über 15 Milliarden Zeilen Quelltext
besitzt Ohloh Code die gröÿte Codebasis der untersuchten Code-Recherche-Anbieter.
Insgesamt lässt sich sagen, dass die Suche nach Beispielcodes bei Anbietern mit Crawling
e
zienter ist, da dort mit deutlich gröÿeren und stetig wachsenden Datenbanken gearbei-
tet wird. Eine gröÿere Codebasis ist jedoch nicht zwangsläu
g mit einer höheren Qualität
der Suchergebnisse gleichzusetzen. Webseiten mit eigenem Datensatz bieten häu
g Inhalte
und Funktionen, die bei den anderen Suchmaschinenen in dieser Form nicht zu
nden sind.
Einen guten Kompromiss geht lediglich Ohloh Code ein, indem der Dienst die Vorteile aus
beiden Ansätzen miteinander verknüpft und somit in dieser Hinsicht auch dem ursprüng-
lichen Google Code Search am ähnlichsten ist - Ohloh Code baut sich als Projekt-Hoster
eine eigene Datenbank auf, die durch das Web-Crawling weiter ausgebaut wird und somit
einen enormen Datensatz für Code-Recherchen bietet.
3.2 Suchoptionen
In diesem Kapitel werden die Dienste auf ihre Möglichkeiten zur Formulierung von Suchan-
fragen untersucht. Wichtig sind hier neben der Art der Suchanfrage (Stichwort, Codeaus-
schnitt oder regulärer Ausdruck) auch die Filteroptionen, mit denen sich die Ergebnisse
übersichtlicher darstellen und ungewünschte Daten aussortieren lassen. Google Code Search
bietet dem Benutzer beispielsweise sechs verschiedene Tags an, mit denen die Suchergeb-
nisse im Voraus ge
ltert werden können. So wird mit dem Tag lang: nur nach einer be-
stimmten Programmiersprache gesucht und mit class: bzw. function: nach Quelltexten
mit vorgegebenen Klassen bzw. Funktionen. Mit den weiteren Filteroptionen können der
Dateipfad, die verwendete Lizenz und die Unterscheidung von Groÿ- und Kleinschreibung
( Case Sensitivity ) berücksichtigt werden.
Darüber hinaus bietet Google Code Search die Möglichkeit, mit regulären Ausdrücken nach
Quellcodes zu suchen. Die Suchmaschine versteht die POSIX-Syntax und
ndet somit auch
Codes, die bestimmten logischen Regeln statt statischen Zeichenketten entsprechen. Da-
durch ist es zum Beispiel möglich, Dateiformate zu
nden, die nicht o
ziell von dem Dienst
unterstützt werden. So könnte in Verbindung mit dem Filter-Tag für Dateipfade der exem-
plarische Ausdruck file:\.(nds|xyz)$ verwendet werden, um Dateien mit den Endungen
.nds und .xyz zu suchen. Diese Funktion ermöglicht den Nutzern eine e
ziente und prä-
zise Suche nach den benötigten Codebeispielen.
16Betrachtet man nun die untersuchten alternativen Anbieter fällt auf, dass vor allem bei
den Webseiten die kein Crawling verwenden, auch nur sehr wenige Suchoptionen angeboten
werden. Bei Snipt können die Suchergebnisse lediglich nach Sprache oder Anwendungsfall
ge
ltert werden; MetaGer Code Search bietet zusätzlich dazu Filter zur Suche nach kon-
kreten Dateipfaden oder Symbolde
nitionen an. Auch beim Hosting-Dienst GitHub sind
die Suchoptionen für Quelltexte sehr übersichtlich; neben einem Filter für die verwendete
Programmiersprache steht noch die Suche nach bestimmten Repositorys, Benutzern, Da-
teigröÿen und -pfaden zur Verfügung.
Die übrigen der in Kapitel 2 vorgestellten Dienste bieten weitaus mehr Such- und Filter-
optionen an. Bei jedem von ihnen existieren zahlreiche Tags, mit denen sich die Ergebnisse
sortieren lassen. So kann beispielsweise optional nach De
nitionen und Deklarationen von
Klassen, Funktionen, Methoden, Objekten und ähnlichem gesucht werden. Während Ohloh
Code die mit Abstand meisten Filter-Tags zur Verfügung stellt, bieten die anderen Anbie-
ter aber auch einige Besonderheiten an, die sie von ihren Mitbewerbern unterscheiden. Bei
Krugle gibt es die sehr praktische Option, Codeausschnitte als Suchanfrage zu verwenden,
wodurch sich Quelltexte
nden lassen, die einige spezi
sche Codezeilen beinhalten. Mit
Merobase und Searchcode bieten zwar auch andere Dienstleister diese Option an, jedoch
erwiesen sie sich im Test als weniger zuverlässig, da sie insbesondere bei mehrzeiligen Co-
deausschnitten die Suchanfrage häu
g falsch interpretieren.
Die Stärke von Merobase liegt in der Suche nach Schnittstellen und Funktionsaufrufen.
Bei einer Anfrage mit einer abstrakten Beschreibung einer Funktion oder eines Objekts
(siehe Kapitel 2.2.3)
ndet Merobase dazu passende Beispiele, die den abstrakten Code in
konkreter Form verwenden. Das Alleinstellungsmerkmal von Searchcode ist hingegen die
Unterstützung regulärer Ausdrücke - unter den aktiven Anbietern ist diese Suchmaschine
derzeit die einzige, die Anfragen dieser Form ermöglicht und damit allein in Bezug auf die
angebotenen Suchoptionen Google Code Search am ähnlichsten ist. Einen, zumindest im
Testfeld, auÿergewöhnlichen Service bietet der Aggregationsdienst Antepedia an, der den
Benutzer die Projektdatenbank nach Sicherheitslücken durchsuchen lässt, wodurch sich die
Ergebnisse auch nach bekannten Schwachstellen
ltern lassen. Dieser Dienst be
ndet sich
jedoch derzeit noch im Beta-Stadium.
Eine Referenz lässt dich in der Kategorie Suchoptionen nur schwer bennenen, da die
Eignung der verschiedenen Anbieter aufgrund ihrer unterschiedlichen Schwerpunkte stark
situationsabhängig ist. Eine Code-Recherche im Stil von Google Code Search ist am ehe-
sten mit Ohloh Code und Searchcode möglich, da sich dort mit vielfältigen Tags bzw.
regulären Ausdrücken die Suchergebnisse e
zient
ltern lassen. Krugle bietet hingegen ei-
ne zuverlässige Suche nach Quelltexten mit Hilfe von Codeausschnitten an und lässt sich
einfach verwenden, wenn bereits Codeteile vorliegen und passende Mustercodes gefunden
werden sollen. Merobase erweist sich hingegen als hilfreich, wenn konkrete Quelltexte eines
bestimmten Formats oder Funktionen mit vorgegebenen Schnittstellen und Parametern
gesucht werden. Nicht zuletzt dürfte es auch aus sicherheitstechnischer Sicht interessant
sein, wie sich die Bug-Suche von Antepedia in Zukunft weiterentwickelt.
173.3 Formate
Ein weiteres wichtiges Merkmal der Suchmaschinen sind die unterstützten Formate. Dies
bezieht sich zum einen auf die suchbaren Programmiersprachen, zum anderen auf die Da-
teiarten (in Bezug auf ihren Verwendungszweck), die gefunden werden können. Betrachtet
man die o
ziell unterstützten Programmiersprachen, stellt man fest, dass sich die meis-
ten Anbieter in diesem Kriterium kaum unterscheiden. Mit Ausnahme von Merobase lassen
sich überall nahezu alle gängigen und bekannteren Sprachen suchen, darunter C/C++/C#,
CSS, Fortran, Java und JavaScript, Matlab, HTML, Perl, PHP, Python, Ruby, SQL oder
XML. Generell ist beim Groÿteil der Anbieter lediglich die Menge der automatisch erkann-
ten Dateitypen begrenzt, was die eigentliche Suche aber in der Regel nicht einschränkt.
So lassen sich mitunter auch exotischere Programmiersprachen
nden, die noch nicht Be-
standteil der automatischen Erkennungssoftware der Suchmaschinen sind - in diesen Fällen
muss der Nutzer dann lediglich auf Komfortfunktionen wie die Auswahl der Sprache über
eine Dropdown-Liste oder das Syntax-Highlighting verzichten.
Gute Beispiele für eine Recherche nach unüblichen Sprachen sind Google Code und Search-
code . Die Suchmaschinen bieten Filtermöglichkeiten für mehr als 70 bzw. 100 unterstützte
Programmiersprachen an. Da beide Anbieter aber auch die Suche per regulärem Ausdruck
erlauben, ist es problemlos möglich, passende Anfragen zu formulieren und beliebige Datei-
typen zu
nden. Von den Anbietern ohne RegEx-Suche bietet GitHub mit rund 90 Sprachen
den gröÿten Katalog nativ unterstützter Dateitypen. Ohloh Code Krugle
und erkennen je-
weils rund 40 Sprachen. Aber auch bei diesen Suchmaschinen lassen sich weitere Sprachen
mit Hilfe der Filteroptionen zum Beispiel anhand der Dateiendungen
nden. Ähnlich ver-
hält es sich bei Snipt , hier können die Ergebnisse anhand von Tag-Links nach Sprachen
ge
ltert werden. Dies geschieht unabhängig davon, ob die Sprache von Snipt selbst un-
terstützt wird, denn die Tags werden von den Benutzern selbst gewählt bzw. formuliert -
was bisweilen der Übersichtlichkeit jedoch nicht zuträglich ist. Viele Tags in der mehrere
Hundert Einträge langen Liste sind nur genau einem Codebeispiel zugeordnet, aufgrund
unterschiedlicher Schreibweise mehrfach vorhanden oder schlicht nicht aussagekräftig.
Eine deutliche Einschränkung gibt es unter den untersuchten Anbietern nur bei Mero-
base . Diese Suchmaschine unterstützt o
ziell nur Java, C/C++/C# und WSDL-Dateien.
Als Ausgleich bietet Merobase aber auch Suchergebnisse an, die man in dieser Form bei
anderen Anbietern nicht
ndet, darunter (JAR-)Bibliotheken, JavaDocs und die zuvor ge-
nannten Webservices - letztere können auch direkt auf der Webseite getestet werden. Auch
bei Snipt liegen spezielle Mustercodes vor, darunter beispielsweise Anwendungsfälle für
Web-Formate wie WordPress. Sowohl Merobase als auch Snipt bieten darüber hinaus auch
eine Vielzahl von vorgefertigten Testroutinen für unterschiedliche Einsatzgebiete an.
In Bezug auf die suchbaren Formate sind sich die meisten Anbieter sehr ähnlich. Search-
code Krugle
, und Ohloh Code, aber auch der Code-Hoster GitHub erreichen im Grunde eine
ähnliche Qualität wie Google Code Search . Mit einer sehr umfangreichen Liste o
ziell un-
terstützter Sprachen und der Möglichkeit einer Suche durch reguläre Ausdrücke stellt sich
Searchcode mit minimalem Vorsprung als Empfehlung in diesem Kriterium heraus - was
aber ausschlieÿlich der durch die genannten Optionen komfortableren Suche zu verdanken
ist.
183.4 Treerquote
Bei diesem Kriterium wird untersucht, wie präzise die Suchmaschinen arbeiten bzw. ob die
zurückgegebenen Ergebnisse zu den Suchanfragen passen. Auÿerdem werden die Ergebnisse
der besonderen Suchoptionen verschiedener Anbieter sowie die Menge an Suchergebnissen
im Vergleich zu den jeweils anderen Diensten betrachtet. Es ist jedoch anzumerken, dass
die Anzahl der Treer kein Merkmal für die Güte der Suchergebnisse ist. Die Verwendbar-
keit der Ergebnisse der exemplarischen Suchen wird bewusst nicht beurteilt, da diese sich
aufgrund der Kontextabhängigkeit kaum miteinander vergleichen lassen.
Google zeigt mit der eigenen Codesuche, wie eine gute und hilfreiche Suchmaschine funk-
tionieren sollte. Code Search arbeitet schnell und präzise, der Dienst führt den Nutzer
zuverlässig zu passenden Beispielcodes. Auch die Suche über reguläre Ausdrücke funktio-
niert einwandfrei. Durch die Implementierung der POSIX-Engine werden auch bei Eingabe
komplizierter Suchanfragen passende Ergebnisse zurückgegeben. Der Dienst Searchcode ar-
beitet sehr ähnlich wie Google Code Search ; auch hier werden schnell passende Inhalte ge-
funden. Es fällt jedoch auf, dass der Service nicht so ausgreift ist wie das Google-Pendant.
Die RegEx-Suche versteht beispielsweise bislang nur sehr simple Ausdrücke, bereits bei
einer Filterung der Codes nach mehreren möglichen Dateiendungen per regulärem Aus-
druck (vgl. Kapitel 3.2) wird die Anfrage oft nicht mehr korrekt interpretiert und der
Nutzer erhält keine Ergebnisse. Genauso verhält sich Searchcode bei der Suche mit Hilfe
von Codeausschnitten - kurze Codezeilen werden korrekt verarbeitet, je komplizierter der
Mustercode jedoch ist, desto ungenauer arbeitet die Suchmaschine.
Letzteres wird hingegen von Krugle sehr gut umgesetzt. Die Suche anhand von Ausschnit-
ten des Quelltextes arbeitet sehr zuverlässig. Zudem kann der Nutzer mit einem Regler
bestimmen, wie exakt der vorgegebene Codeausschnitt in den Suchergebnissen vorliegen
soll. Wird der Regler auf präzise ( exact) eingestellt, werden nur solche Codes ausgegeben,
die eine identische Textstelle enthalten. Je weiter der Benutzer den Regler in die Richtung
der gegensätzlichen Option unscharf ( fuzzy ) bewegt, desto mehr Abweichungen von der
ursprünglichen Anfragen werden zugelassen. Krugle arbeitet insgesamt sehr zuverlässig
und bietet stets eine Vielzahl passender Suchergebnisse an. Eine Suche anhand von Code-
ausschnitten ist auch bei Merobase möglich. Das Alleinstellungsmerkmal des Dienstes - die
Suche nach konkreten Funktionen anhand abstrakter Funktionsaufrufen - arbeitet in den
meisten Situationen ebenfalls recht präzise, so dass ein zusätzliches manuelles Durchsu-
chen der Suchergebnisse nach den gewünschten Funktionsde
nitionen nur selten nötig ist.
Auÿerdem umfasst der Dienst einige Inhalte, die in dieser Form bei den anderen Anbieter
nicht zu
nden sind, wie etwa JavaDocs- oder Webservice-Lookups.
Ohloh Code liefert in der Regel aufgrund seiner sehr groÿen Datenbank im direkten Ver-
gleich zu den anderen Diensten die meisten Treer. Darüber hinaus gibt es keine Beson-
derheiten - die Suchmaschine arbeitet exakt und schnell und gibt mit nur wenig Aufwand
für den Nutzer passende Ergebnisse aus. Auch MetaGer Code Search und GitHub weisen
eine brauchbare Treerquote auf. MetaGer arbeitet genau, liefert aber aufgrund des einge-
schränkten Datenbestandes meist weitaus weniger Treer als die Konkurrenz. Bei GitHub
ist die Ergebnismenge wesentlich gröÿer, auällig viele Treer sind bisweilen jedoch nur
kurze Textdokumente mit Kommentaren oder Kon
gurationsinformationen. Dieser Um-
stand lässt sich aber durch ein optionales Suchfeld einfach umgehen, indem der Nutzer
19den Parameter Dateigröÿe auf einen entsprechenden Mindestwert setzt (zum Beispiel
size:>1000).
Die schlechtesten Treerquoten im Feld der untersuchten Anbieter weisen Snipt und An-
tepedia auf. Im Fall von Antepedia liegt das daran, dass nicht die Mustercodes, sondern
lediglich die dazugehörigen Dokumentationen durchsucht werden, wodurch eine Suche nach
konkreten Quelltextbeispielen deutlich erschwert wird. Snipt arbeitet allgemein sehr un-
präzise und gibt beispielsweise bei Suchausdrücken mit mehreren Begrien alle Dokumente
aus, in denen mindestens einer davon vorkommt - was sich mangels weiterer Suchoptionen
auch nicht umgehen lässt. Durch die sehr kleine Codedatenbank werden generell nur wenige
Ergebnisse gefunden, zudem be
nden sich unter den Treern auch häu
g belanglose Ein-
träge wie E-Mail-Verkehr, welche von Benutzern in den Datenbestand eingetragen wurden.
Im Hinblick auf die Treerquote erzielen Ohloh Code Krugle GitHub
, , und Google Code
Search die besten Ergebnisse. Diese Dienste arbeiten sehr zuverlässig und geben in der
Regel eine Vielzahl an passenden Mustercodes aus. Weitere Suchmaschinen, die im di-
rekten Vergleich weniger gut arbeiten, aber dennoch zufriedenstellende Ergebisse liefern
sind Merobase (starke Einschränkung der unterstützten Sprachen), Searchcode (zusätzli-
che Suchoptionen nicht ausgereift) und MetaGer (kleinerer Datenbestand durch fehlendes
Crawling). Es sei jedoch noch einmal betont, dass die tatsächliche Einsetzbarkeit und in-
haltliche Qualität aller Suchergebnisse stets vom entsprechenden Anwendungsfall abhängig
ist und keine direkten Vergleiche der Dienste untereinander ermöglicht.
3.5 Bedienbarkeit
Bei der Bewertung der Bedienbarkeit geht es darum, zu untersuchen, wie gut sich die ver-
schiedenen Dienste handhaben lassen, wie die Suchergebnisse strukturiert und dargestellt
werden und wie e
zient sich Recherchen mit Hilfe der verschiedenen Anbieter durchführen
lassen. Auällig sind dabei die Gemeinsamkeiten sämtlicher Anbieter im Testfeld: Bei allen
werden die Suchergebnisse übersichtlich aufgelistet, jeder Treer ist dabei mit einem kurzen
Ausschnitt der entsprechenden Codezeilen aufgeführt. Nach dem Önen der gewünschten
Quellcodes sind diese bei ausnahmslos jedem Dienst (im Rahmen der jeweils unterstützten
Programmiersprachen) mit hervorgehobener Syntax versehen, um die Lesbarkeit zu erhö-
hen.
Betrachtet der Benutzer bei Google Code Search ein Ergebnis genauer, werden am lin-
ken Bildschirmrand alle zum aufgerufenen Projekt gehörigen Dateien aufgeführt, sodass
sich das gesamte Programm und die Zusammenhänge der einzelnen Dateien schnell un-
tersuchen lassen. Eine In-File Suchfunktion ermöglicht zudem eine schnelle weiterführende
Suche innerhalb des gewünschten Projekts. Was bei Google Code Search jedoch fehlt, ist
eine nachträgliche Filterung der Suchergebnisse, beispielsweise nach Programmiersprache
oder Dateiart. Dies ermöglichen sowohl Krugle Ohloh Code
als auch , die ansonsten über
ein fast gleiches Interface und eine ähnliche Handhabung wie der Google-Dienst verfügen.
Beide Anbieter blenden am linken Rand der Ergebnisübersicht relevante Filter ein, die sich
bei Bedarf ein- und ausschalten lassen, um die Menge der gefundenen Mustercodes weiter
zu reduzieren. Im direkten Vergleich gestaltet Krugle diese Funktion etwas praktischer,
da sich hier die einzelnen Filterkategorien (z.B. Projekte, Dokumenttypen oder Autoren)
separat durchsuchen lassen und der Nutzer nicht durch unter Umständen sehr lange Listen
20navigieren muss.
Eine vergleichbare Bedienung ist auch bei der Codesuche des Hosting-Diensts GitHub vor-
zu
nden, jedoch ist die Handhabung des Interfaces minimal umständlicher. Die einzige
Option, die Suchergebnisse nachträglich zu
ltern, beschränkt sich auf die Programmier-
sprache - und dies auch nur auf die zehn am häu
gsten in den vorliegenden Ergebnissen
vertretenen. Insbesondere ein Eingrenzen auf weniger verbreitete Sprachen ist im Nachhin-
ein nur schwer möglich. Auch sind die weiteren zu einem Projekt gehörenden Dateien nicht
sofort ersichtlich, sondern müssen separat aufgerufen werden, was sich letztlich negativ auf
die Handhabung auswirkt. Ähnlich verhält es sich bei MetaGer Code Search , wo der Be-
nutzer ebenfalls erst in die übergeordnete Datei- und Verzeichnisstruktur wechseln muss,
um sich einen Überblick über die zusammengehörenden Dateien eines Projekts verschaen
zu können.
Merobase undSearchcode lassen die oben genannten Komfortfunktionen nahezu gänzlich
vermissen. Searchcode hat eine nachträgliche Eingrenzung der Suchergebnisse nur rudi-
mentär implementiert; hier wird über Links nur eine neue (auf eine Programmiersprache
begrenzte) Suchanfrage generiert. Bei Merobase ist eine spätere Filterung nicht möglich -
was aber im Hinblick auf die Spezialisierung auf nur wenige unterstützte Sprachen letztlich
kaum relevant ist. Was beiden Diensten fehlt, ist eine Möglichkeit, einfach in die übergeord-
nete Dateistruktur zu wechseln, um ein Projekt vollständig betrachten und untersuchen zu
können. Hier bleibt dem interessierten Nutzer nur die Möglichkeit, über den Backlink zur
Quelle des Codes zu gelangen und beim entsprechenden Projekt-Hoster weitere Recherchen
durchzuführen.
Bei Snipt gestaltet sich eine Code-Recherche als sehr schwierig. Die Seite bietet kaum
Such- und Filteroptionen, auch ein nachträgliches Eingrenzen oder Sortieren der Sucher-
gebnisse ist nicht implementiert. Im Grunde muss der Nutzer bereits seine Suchanfrage
möglichst exakt formulieren, da ein Stöbern durch die Suchergebnisse nicht möglich ist.
Schwierig erscheint auch eine e
ziente Recherche beim Aggregationsdienst Antepedia . Die
Seite gibt passend zur Suchanfrage Links zu entsprechenden Projekten aus, die unmittel-
bar zum ursprünglichen Hosting-Dienst führen. Eine Aufarbeitung oder Darstellung der
zugehörigen Quelltexte wird von Antepedia selbst nicht durchgeführt.
Bei Betrachtung der Bedienbarkeit und Handhabung haben sich im Test Krugle und Ohloh
Code als die e
zientesten Dienste zur Code-Recherche herausgestellt. Beide Anbieter stel-
len die gefundenen Mustercodes übersichtlich und gut strukturiert dar und bieten viele
Optionen, schnell zu gewünschten Quelltexten zu gelangen und diese eingehend zu unter-
suchen. Insgesamt übertreen beide Dienste in diesen Kriterien sogar Google Code Search ,
welchem beispielsweise eine einfache nachträgliche Filterung der Suchergebnisse fehlt.
214 Zusammenfassung & Empfehlung
Die Suchmaschine Google Code Search war mit vielen nützlichen Funktionen, einer einfa-
chen Handhabung und einer riesigen Datenbank ein äuÿerst hilfreiches Recherche-Tool für
Softwareentwickler. Auch nach der Einstellung dieses Projekts Anfang 2012 stehen seine
Dienstleistungen mit eingeschränktem Umfang weiterhin zur Verfügung. Das Interface ist
unverändert online, lediglich die durchsuchbare Codebasis ist stark geschrumpft und bietet
nur noch Projekte aus dem hauseigenen Google Code an; immerhin handelt es sich hierbei
um einen der gröÿten Hosting-Dienste weltweit. Im Rahmen dieses Praktikums konnten
einige Alternativen ermittelt werden, die Google Code Search in Bezug auf Funktionalität
und Bedienbarkeit zum Teil sehr ähnlich sind oder es in einigen Fällen sogar übertreen.
Als beste Alternativen haben sich die Dienste Ohloh Code und Krugle erwiesen. Beide
Anbieter unterscheiden sich nur marginal voneinander und haben jeweils minimale Vor-
und Nachteile dem anderen gegenüber. Jedoch konnten beide im Test überzeugen, so dass
es letztlich vom persönlichen Emp
nden des Benutzers abhängt, welche Webseite er bevor-
zugt. Ohloh Code arbeitet durch Crawling in Kombination mit eigenem Projekt-Hosting
auf einer gröÿeren Codebasis und bietet zudem vielfältige Filteroptionen. Krugle ist hin-
gegen etwas komfortabler zu bedienen und ermöglicht eine sehr gut funktionierende Suche
anhand von Codeausschnitten an. Insgesamt erzielen beide Anbieter schnell und präzise
hilfreiche Ergebnisse und sind daher empfehlenswert für umfassende Code-Recherchen im
Stil von Google Code Search .
Der Anbieter Merobase kann zwar nicht uneingeschränkt empfohlen werden, erweist sich je-
doch in einigen speziellen Anwendungsfällen als äuÿerst hilfreich. Die Menge der suchbaren
Sprachen ist sehr stark begrenzt; sucht ein Nutzer jedoch nach konkreten Programmierbei-
spielen anhand von abstrakt formulierten Funktions- oder Objektbeschreibungen in Java
oder C, wird er per Schnittstellensuche schnell fündig. Zudem bietet Merobase als weite-
res Alleinstellungsmerkmal einen Webservice-Lookup inklusive Ausführungsumgebung an.
Auch GitHub - nach Google Code einer der gröÿten Hosting-Dienste[11] - ermöglicht eine
brauchbare Suche nach Quellcodes im eigenen Datenbestand. Im Gegensatz zu den meis-
ten anderen Projekt-Hostern kann bei GitHub im Interface der erweiterten Suche (siehe
Kapitel 2.3.2) explizit eine Codesuche durchgeführt werden, wodurch ähnliche Ergebnisse
wie bei Google erzielt werden können. Allerdings kann GitHub aufgrund eingeschränkter
Suchoptionen nicht mit Ohloh Code oder Krugle mithalten.
Das Ein-Mann-Projekt Searchcode stellt ebenfalls eine erwähnenswerte Alternative dar.
Die Anwendung arbeitet auf einer sehr groÿen Datenbank, bietet vielfältige Such- und
Filteroptionen und unterstützt zumindest im Testfeld insgesamt die meisten Program-
miersprachen. Als einziger Anbieter neben Google Code Search versteht die Suchmaschine
auch einfache reguläre Ausdrücke. Jedoch mangelt es Searchcode derzeit noch an Komfort
bei der Handhabung; einige Suchoptionen (wie beispielsweise die erwähnte RegEx-Suche)
erscheinen aktuell noch unausgereift. Dennoch lohnt es sich zu beobachten, wie sich dieses
Projekt weiterentwickelt.
Drei Anbieter des Testfelds lassen sich abschlieÿend nicht für Recherchearbeiten empfehlen.
Die deutsche Suchmaschine MetaGer Code Search umfasst zwar eine Vielzahl mehr oder
weniger bekannter OpenSource-Projekte, dennoch stellt der Datensatz mangels Crawling-
22Funktion keinen Vergleich zu den vorgenannten Diensten dar. Zudem gibt es nur wenige
Suchoptionen und eine unnötig komplizierte Handhabung. Die Codesammlung Snipt weist
die mit Abstand kleinste Datenbank und wenigsten Suchoptionen auf. Auch aufgrund vie-
ler unnützer Einträge werden dem Nutzer nur selten hilfreiche Ergebnisse geliefert. Der
letzte Anbieter, Antepedia , ist dank besonderer Features wie der Bug-Suche ein sehr in-
teressanter Service, jedoch ermöglicht er keine zuverlässige Codesuche, da lediglich die
Dokumentationstexte der zugehörigen Projekte durchsucht werden.
23Sie können auch lesen

















































