Big Data - Data-driven Innovation - mgm Big Data
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
München/HQ Aachen Bamberg Berlin Köln Đà Nẵng Dresden Grenoble Hamburg Leipzig Nürnberg Prag Stuttgart Washington Zug Big Data - Data-driven Innovation

Wir bringen Anwendungen in Produktion!
mgm entwickelt seit über 25 Jahren Webapplikationen
für Commerce, Insurance und Public Sector: Hochskalierbar, sicher, robust.
Mehr als 700 Kolleginnen und Kollegen stehen für unsere Mission:
Innovation Implemented.
2
Inhalt 3
Einleitung
01
Leistungen Referenzen
Einführungsworkshop Milliarden von Händlerdaten handhabbar machen
02 Innovationspotenzial quantifizieren
Proof of Concept
03 Datengetriebene Entscheidungen im Einzelhandel
Bessere Qualität von Immobilienanzeigen mit Open Data
Umsetzung Exploration von Sensordaten
Weiterentwicklung
Monitoring und Betrieb
Themen Technologien
Datengetriebene Businessanalyse R & Python
04 Security / Governance / Stewardship
Change Management
05 Hadoop-Ökosystem
Spark
Daten-Lebenszyklus Presto
Hybride Datenhaltung Solr
Geodaten
Recommendation Engines 4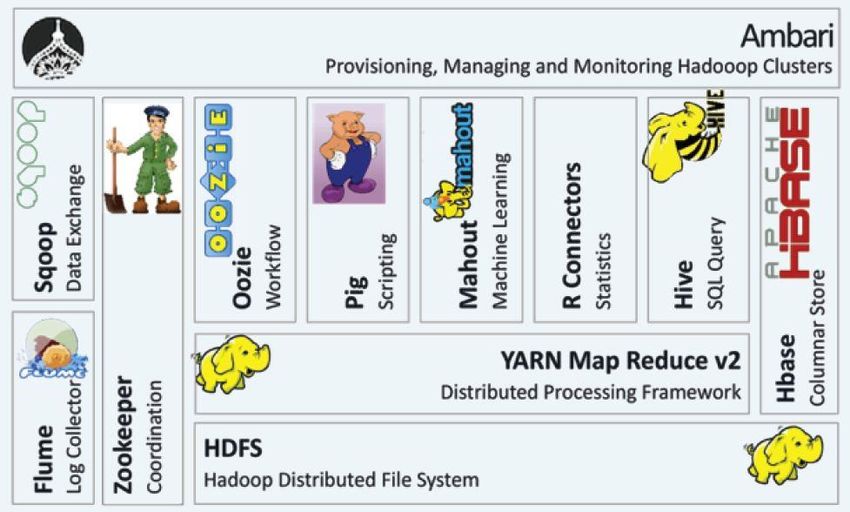
01 5

Einleitung
6
Big Data
Einleitung
Milliarden Sensordaten, zehntausende Formate, Analysen
in Sekunden? Klarer Fall für Big Data. Wir unterstützen Sie
von der Beratung bis zur Implementierung.
Mit mehr als 20 Jahren Erfahrung im Bereich geschäfts-
kritischer Daten begleiten wir Sie auf dem Weg zur daten-
getriebenen Organisation.
7
Was ist Big Data? Was bringt Big Data?
Aus technischer Sicht ist Big Data ein Sammelbegriff für Datengestützte Erkenntnisse helfen dabei,
neue Formen der Datenverarbeitung. Dazu gehören zum unternehmerische Zusammenhänge besser zu verstehen. Sie
Beispiel verteilte, hochskalierbare Datenbanken und führen zu fundierten Entscheidungen. Darüber hinaus bietet
Frameworks, die auf Computer-Clustern operieren. Oder Big Data die Möglichkeit, neue Geschäftsmodelle zu
Systeme, die Streams in Echtzeit analysieren. Aus unter- entwickeln und umzusetzen – zum Beispiel in Form von
nehmerischer Sicht eröffnet Big Data neue Möglichkeiten, individualisierten Produkten und Diensten. Big-Data-Tech-
Ihr Geschäft datengetrieben voranzubringen. nologien wie Apache Hadoop ermöglichen skalierbare
Speicher- und Rechenkapazitäten bei geringen Kosten.
Wer nutzt Big Data? Woher kommt Big Data?
Unternehmen jeder Größe und Branche setzen auf Big Data. Hintergrund von Big Data sind rasant wachsende,
Dafür müssen nicht riesige, unerschlossene Datenbestände unterschiedlich strukturierte Datenbestände mit hohen
im Unternehmen vorliegen. So können zum Beispiel auch Anforderungen an die Verarbeitungsgeschwindigkeit. Daten
eigene Daten mit Informationen aus Open-Data-Portalen unterscheiden sich durch Größe (Volume), Format (Variety),
gewinnbringend verknüpft werden. Erste Prototypen von Big- und Auswertungszeit (Velocity). Verantwortlich für das starke
Data-Anwendungen lassen sich bereits in kurzer Zeit zu Datenwachstum sind unter anderem benutzergenerierte
geringen Kosten erstellen – unter anderem dank der verfüg- Inhalte, immer mehr Sensoren und das Internet der Dinge.
baren Open-Source-Technologien.
8
02 9

Leistungen
10Big Data > Leistungen
Leistungen
Wir unterstützen Sie individuell bei Ihrem Big-Data-
Vorhaben. Von der strategischen Beratung über Prototypen
und erste Testprojekte bis zur Implementierung und dem
Betrieb komplexer, hochskalierbarer Systeme.
11Einführungsworkshop Innovationspotenzial quantifizieren
„Datengetriebene Innovationen“ Auf Basis Ihrer Testdaten entwickeln wir erste Prototypen für
Wie kann Ihr Geschäft von Big Data profitieren? die Datenanalyse. Sehen Sie konkret für eine Fragestellung,
Wir geben Ihnen einen Überblick zu Einsatzmöglichkeiten, welches Potenzial in Ihren Daten steckt.
Geschäftsansätzen und aktuellen Technologien.
Proof of Concept Umsetzung
Wir beraten Sie hersteller- und systemunabhängig zu allen Individuell für Ihre Anforderungen entwickeln wir die
Fragen rund um den idealen Technologie-Stack. Und passende Lösung. Außerdem unterstützen wir Sie dabei, Big
unterstützen Sie mit einer Test-Infrastruktur. Data langfristig im Unternehmen zu verankern.
Weiterentwicklung Monitoring und Betrieb
Holen Sie das meiste aus Ihrer datengetriebenen Unsere Leistungen für den verlässlichen Betrieb Ihrer
Anwendung. Wir helfen dabei – zum Beispiel, indem wir die Anwendung reichen von der Server- und System-
Datenqualität verifizieren oder die Aussagekraft der überwachung über die Revisionssicherheit bis zur Disaster
Prädiktion evaluieren. Recovery.
12Big Data > Leistungen
Einführungsworkshop „Datengetriebene
Innovation“
mgm A12 is a model-driven approach to business software. Big Data kennenlernen
It provides a set of concepts, components and tools for
creating modern, document-oriented web applications. Sie wollen mehr über Big Data erfahren? Unsere Experten
geben Ihnen gerne einen Überblick zu aktuellen Technologien
und Einsatzmöglichkeiten – sei es im Rahmen eines ganztägigen
Decouple domain-specific information from development Workshops oder einer Einführungsveranstaltung. Um Ihre
individuellen Fragen zu beantworten, schöpfen wir aus jahre-
The core idea of mgm A12 is to encapsulate domain-specific
langer Projekterfahrung in der Analyse sehr großer Daten-
knowledge in models. By using a set of powerful tools, domain
mengen – von Fahrzeug- und Maschinen-Sensordaten über
experts and business analysts are able to create and modify
Zugriffs- und Verkaufsdaten von Online-Händlern bis hin zu Log-
these models – without the need to touch any code. This
Daten im Bereich großer E-Government-Anwendungen.
concept significantly reduces custom development efforts.
Moreover, it enables domain-experts to adapt their applications
Technologien verstehen
rapidly – which is a competitive factor in a digitized world with
fast changing business requirements. Wie unterscheidet sich Big Data von existierenden Verfahren im
Focus on documents and forms Bereich Business Intelligence? Was bedeutet das für
bestehende Systeme wie ein Data Warehouse? Wie
Most business transactions are handled via some kind of funktionieren Hadoop, SAP Hana, Spark, Flink und Storm? Kann
documents. This includes contracts, purchase orders and man diese Technologien auch zusammen verwenden? Wenn Sie
different kinds of requests for example. When it comes to mehr über die aktuellen Big-Data-Frameworks wissen wollen,
digitizing documents, online forms play a vital role. They specify sind Sie bei uns an der richtigen Adresse. Über 20 Big-Data-
the structure of documents and determine which data is Technologien haben wir bereits erfolgreich in Projekten
eingesetzt und viele weitere intern evaluiert.
13Geschäftliche Auswirkungen abschätzen
Welche Rolle spielt Big Data für die Entscheidungsfindung im
Unternehmen? Wie lässt sich durch Datenanalysen ein tieferes
Verständnis für das eigene Geschäft und individuelle Kunden
gewinnen? Inwiefern verändern sich dadurch die Geschäfts-
modelle? Während unsere Entwickler die technischen Details
rund um Big-Data-Frameworks „aus dem Effeff“ kennen, sind
unsere Berater Feuer und Flamme für geschäftsbezogene
Fragen und den Wandel in eine datengetriebene Organisation.
14Big Data > Leistungen
Innovationspotenzial quantifizieren
Wert und Nutzen von Daten entdecken
“Wie wertvoll sind meine Daten? Welcher Nutzen lässt sich
daraus ziehen?” Solche Fragen lassen sich häufig erst durch
initiale Exploration und Analysen im Projektverlauf beant-
worten. Mit Tools wie R und Python untersuchen wir anhand
von Testdaten (bzw. Stichproben), welche Kennzahlen sich aus
Ihren Datenbeständen ableiten lassen und welche Vorhersagen
damit getroffen werden können. So wird ein Prototyp für die
Datenanalyse entwickelt, der erste Fragestellungen auslotet und
die Ergebnisse übersichtlich aufbereitet.
Eigene Daten mit externen Daten kombinieren
Die Mischung machts. Daten aus dem eigenen Unternehmen
sind nicht die einzigen Quellen für Big-Data-Lösungen. Häufig
entsteht der Wert und Nutzen gerade erst aus der Kombination
mit Daten aus Open-Data-Beständen – beispielsweise Daten
von Behörden und Crowd-Sourcing-Initiativen – oder Daten von
Drittanbietern. Bei der Datenexploration geht es deshalb auch
darum, auf Basis einer Fragestellung die richtigen Datenquellen
zu identifizieren und miteinander in Beziehung zu setzen.
15Erkenntnisse gewinnen, von kleinen zu großen Datenmengen
Data Mining (DM) und Verfahren rund um Knowledge Discovery
in Databases (KDD) wie statistische Methoden und Machine-
Learning-Algorithmen sind nicht nur für die Datenexploration
nützlich. Sie helfen dabei, Muster in Datensätzen zu erkennen,
Prognosen aufzustellen, und damit Entscheidungen zu unter-
stützen. Die Erkenntnisse aus der Erkundungsphase lassen sich
unter Berücksichtigung von Skalierungsfragen auch auf größere
Datenmengen übertragen.
16Big Data > Leistungen
Proof of Concept
Voraussetzungen schaffen
Bevor Sie mit einem Big-Data-Projekt starten, sollten Sie die
Verfügbarkeit der dazu notwendigen Daten sicherstellen. Dazu
gehören sowohl Datenschutz, rechtliche Absicherung, Form der
Daten als auch die Aktualität. Zusätzlich muss die Datenqualität
gewährleistet werden, damit abgeleitete Ergebnisse gut genug
sind, um damit Business-Entscheidungen richtig treffen zu
können.
Nachhaltigen Technologie-Stack auswählen
Wenn Sie bereits erste Vorstellungen über den Einsatz von Big
Data haben, stellen sich schnell Fragen hinsichtlich der
Realisierbarkeit: Lässt sich das auch umsetzen? Soll die Lösung
in der Cloud gehostet sein oder nicht? Ist die Skalierbarkeit
gewährleistet? Um eine dauerhaft effizient betreibbare Lösung
zu finden, beraten wir Sie hersteller- und systemunabhängig zu
allen Fragen rund um die Infrastruktur. Mit Hilfe von Best-
Practice-Entscheidungs- und Evaluierungsmodellen helfen wir
Ihnen dabei, einen idealen Technologie-Stack zu finden.
17Tests mit Beispiel-Infrastruktur durchführen
Für viele Aufgaben kann aus einem umfassenden Repertoire an
bereits existierenden Tools geschöpft werden. Die Kunst liegt
darin, die richtigen Werkzeuge zu finden und diese für die
jeweiligen Anforderungen geschickt zu kombinieren, um damit
den Grundstein für eine zukunftssichere Lösung zu legen.
Sobald der Technologie-Stack ausgewählt wurde, stellen wir
Ihnen zu Testzwecken gerne die entsprechende Infrastruktur
bereit – zum Beispiel einen individuell konfigurierten Hadoop-
Stack in Form von Docker-Images oder Vagrant-Rezepten.
18Big Data > Leistungen
Umsetzung
Individuelle Lösungen für Ihre Anforderungen Visualisierung und Web-Frontends
Wir sind auf Software-Projekte spezialisiert und finden für Wie möchten Sie die Ergebnisse Ihrer Big-Data-Analysen
unsere Kunden die optimale Lösung für ihre spezifischen Anfor- präsentiert bekommen? Welche Darstellung bringt die we-
derungen. Dabei wählen wir aus etwa 20 Kern- und vielen sentlichen Informationen schnell interpretierbar zum Ausdruck?
weiteren Peer-Technologien die richtigen für Sie aus. Am Ende Wir entwickeln für Sie passgenaue, intuitiv nutzbare Web-
steht immer eine produktionsreife, wartbare und zukunfts- Frontends – sei es für die Darstellung von Sensordaten auf
sichere Lösung von mgm. zoombaren Karten, die Hervorhebung von Clustern in Heat-
maps, oder die Zusammenfassung von Kennzahlen in
Effiziente Suche in großen Datenmengen klassischen Reports, Statistiken und Diagrammen. Auf Basis
Stehen Sie vor der Herausforderung, Informationen in stark Ihrer Anforderungen entwickeln wir Tools, mit denen Sie Ihre
wachsenden Datenmengen schnell auffindbar zu machen? Daten effektiv und flexibel visualisieren, erkunden und
Unsere Experten sind erfahren und praxiserprobt in der untersuchen können.
Anwendung und individuellen Erweiterung moderner Such- Big Data in der Unternehmensstrategie verankern
technologien wie Apache Solr und Elastic Search. Auf Basis von
Solr und der Datenhaltung in Hadoops verteiltem Dateisystem Der erfolgreiche Einsatz von Big Data im Unternehmen
HDFS lassen sich zum Beispiel Terabyte an Logdaten in Echtzeit erfordert nicht nur technisches Know-how, sondern auch
durchsuchen. organisatorisches Fingerspitzengefühl. Neben der Entwicklung
individueller Lösungen unterstützen wir Sie deshalb auch dabei,
die richtigen Weichen für eine auf datenbasierten Entschei-
dungen beruhende Unternehmenskultur zu stellen.
19Typischer Projektablauf bei mgm Big Data: Explorative, iterative, datenzentrierte Vorgehensweise
Business Case Daten Bereitstellung Abspeichern Berechnung von Visualisierung
erkennen analysieren der Infrastruktur der Daten Aggregaten der Erkenntnisse
Identifikation von Identifizieren des idealen Bei mgm im Labor Mittels ETL-Logik einfach Individuelle Algorithmen Erstellung von Prototypen
Geschäftsmodell und und realen Datensets möglich und schnell möglich oder fertige Pakete wie mit echten Daten
Wettbewerbsvorteil Presto etc.
Statistische Prädiktion / Cloud-basiert z.B. in mgm Hadoop- Explorative, iterative
Identifikation von Quick Modellierung mit R Infrastruktur Interpretation der Annäherung durch
Skalierungsfaktoren zur
Wins und langfristigen Ergebnisse geschickt gewählte
Erkennung von echten Hardware Unterscheidung zwischen
Zielen Datenprojektion
Mustern lang- und kurzfristiger Qualitätssicherung
Herausarbeiten relevanter Ablage
Fragen
20Big Data > Leistungen
Weiterentwicklung
Verifizierung Datenqualität (Variation)
Die Ergebnisqualität datengetriebener Anwendungen hängt
maßgeblich von der Qualität der Ausgangsdaten ab. Bei der
Weiterentwicklung einer Big-Data-Lösung muss daher darauf
geachtet werden, dass die Datengrundlage nicht zu viele Fehler
und Ausreißer enthält. Mit Hilfe von deskriptiver Statistik führen
wir Tests durch, die zum Beispiel Verteilungen, Mittelwerte und
Momente berechnen. Über diese Kennzahlen lassen sich
Veränderungen schnell erkennen. Dabei muss beachtet werden,
dass Daten sich nicht nur aufgrund interner Faktoren, sondern
zum Beispiel auch durch Umweltbedingungen ändern können.
Aussagekraft der Prädiktion evaluieren
Waren die Prognosen der datengetriebenen Anwendung hilf-
reich und aussagekräftig? Über den zeitlichen Verlauf lassen
sich ausgelöste Veränderungen beurteilen. Wenn das erwartete
Ergebnis eingetreten ist, können die Gewichte der betroffenen
Parameter verstärkt werden. Bei negativem Ausgang lassen sie
sich entsprechend geringer gewichten. So kann die Prognose
retrospektiv an die Realität angepasst werden und die Genauig-
keit der Aussage wird mit jeder Iteration verfeinert.
21Präzision erhöhen
Damit eine datengetriebene Anwendung nach und nach
präzisere Aussagen trifft, sollten zunächst die bisherigen
Ergebnisse kritisch überprüft werden. Um kontinuierlich die
Aussagekraft neuer Erkenntnisse zu beurteilen und zu schärfen,
arbeiten wir gerne in iterativen Prozessen. Das kann zum
Beispiel gelingen, indem neue Daten berücksichtigt werden, die
vorher nicht in der notwendigen Menge zur Verfügung standen
oder nicht relevant erschienen. Während des Betriebs muss
sichergestellt werden, dass die einbezogenen Daten stets
repräsentativ sind. Diese inhaltliche Überwachung ist besonders
wichtig, um Änderungen über den Zeitverlauf zu identifizieren
und darauf reagieren zu können. So kann bereits eine kleine
Anpassung der zugrunde liegenden Fragestellung beispiels-
weise die Justierung von Trainingsmengen bedingen.
22Big Data > Leistungen
Monitoring und Betrieb
Server- und Systemüberwachung
Aus technischer Sicht gehört vor allem die Server- und
Systemüberwachung zu einem reibungslosen Betrieb. Hier geht
es unter anderem darum, den Fluss der Datenströme zu
koordinieren, eine hohe Verfügbarkeit zu gewährleisten und
möglichst niedrige Latenz zu realisieren. Außerdem muss
überprüft werden, ob das System mit der Last umgehen kann
und Antwortzeiten nicht zu groß werden.
Revisionssicherheit
Je nach dem Kontext, in dem die datengetriebene Anwendung
eingesetzt wird, können Vorgaben und Regeln für die
Aufbewahrung von Informationen bestehen. Die Reproduzier-
barkeit früherer Ergebnisse sorgt in solchen Fällen für die
Revisionssicherheit. Dazu gehört zum Beispiel auch die
Archivierung von Algorithmen, sodass diese zu einem späteren
Zeitpunkt wieder ausgeführt werden können. Aber auch der
Datenlebenszyklus muss unbedingt berücksichtigt werden, um
eine Revisionssicherheit herzustellen.
23Disaster Recovery
Die Verfügbarkeit von IT-Systemen rund um die Daten-
speicherung, -analyse und -auswertung ist oft geschäftskritisch,
da wichtige Entscheidungen immer häufiger datenbasiert
getroffen werden. Maßnahmen im Bereich Disaster Recovery
zielen darauf, einen möglichst unterbrechungsfreien Betrieb
dieser Dienste zu gewährleisten und im Notfall Systeme und
Daten innerhalb kurzer Zeit wiederherzustellen. Durch die
Konzeption, Implementierung und Überprüfung einer Repli-
kation – bei Bedarf auch über mehrere Standorte – unterstützen
wir Sie dabei, Datenverlusten und Systemausfällen
vorzubeugen.
2403 25
Referenzen /
Beispielprojekte
26Big Data > Referenzen / Projektbeispiele
Referenzen / Projektbeispiele
Rasant wachsende Datenmengen handhabbar machen und
Erkenntnisse aus Analysen gewinnen?
Wir kennen Big-Data-Herausforderungen aus der Praxis.
27Milliarden von Händlerdaten handhabbar machen Datengetriebene Entscheidungen im Einzelhandel
Eine hochskalierbare Hadoop-Lösung von mgm unterstützt Transparente Abläufe dank Big Data. Der
ein Marktforschungsinstitut dabei, neue Märkte und Länder Informationsaustausch zwischen Filiale und
zu erschließen. Vertriebsgesellschaften ermöglicht eine bessere
Aufgabenverteilung.
Bessere Qualität von Immobilienanzeigen Exploration von Sensordaten
mit Open Data Mit Hilfe eines individuell entwickelten Tools untersuchen
Wo ist die nächste Schule oder der nächste Arzt? Big-Data- Forscher Fahrzeugdaten. Und entwickeln neue
Lösung reichert Anzeigen mit Zusatzinformationen an. Assistenzsysteme.
28Big Data > Referenzen / Projektbeispiele
Milliarden von Händlerdaten handhabbar machen
Ausgangssituation Vorgehensweise
Das System zur Datenhaltung eines Marktforschungs- Aufbau einer verteilten, hochskalierbaren Lösung auf Basis
instituts stieß an seine Grenzen von Hadoop
Weitere Panels, die auf die Messung von Veränderungen Transformation von 20.000 verschiedenen Ausgangsformaten
optimiert sind, konnten nur noch unter großen in ein Standardformat
Schwierigkeiten implementiert werden Durchstich für ein Panel, Nutzung der Erkenntnisse für
Weiterer Ausbau des Geschäfts war dadurch eingeschränkt globalen Rollout
Ziele Ergebnisse
Aufbau eines stabilen, skalierbaren Systems für Milliarden Die sehr großen Datenmengen sind handhabbar geworden.
von Händlerdaten Das System ist auf weiteres Wachstum vorbereitet.
Schnelle Zugriffszeiten, insbesondere bei Vergleichen mit Dank der besseren Kapazitäten in puncto Datenverarbeitung
historischen Daten kann das Institut problemlos neue Märkte und Länder
Positionierung der IT als Business-Enabler und -Treiber erschließen und umfangreichere Prognosen zu
Verkaufszahlen erstellen
29Field Audits Extrapolation Reporting Setup
& EPOS
Project Maintenance
Client Delivery
Data
Retailer
Formatting
Data QC Shop Relevant QC
Data In Output DWH Pre-Processing RB Data Out
Delivery Setup Market Data QC Data Files & Reporting Tools
Data Publish Client Access
Retailer
Management
Item-Matching
& Item-Coding
Channel Shop
Management
Master Data Management (MDM) for Shops and Products
30Big Data > Referenzen / Projektbeispiele
Datengetriebene Entscheidungen im Einzelhandel
Ausgangssituation Vorgehensweise
Hoher Aufwand eines internationalen Handelskonzerns, die Konzept und Implementierung des Datenaustauschs
richtigen Warenmengen für jede der über 10.0000 Filialen zu Agiles Vorgehen: Technischen Prototyp erstellt und
bestellen kontinuierlich weiterentwickelt bis hin zur Praxis-Applikation
Dezentrale Struktur mit Ländern, Lagergesellschaften etc. UI/UX als zentrale Eigenschaften der App durch Prototyping
Koordination der Aufgaben der Filialmitarbeiter überprüft
Personaleinsatzplanung Sukzessiver Rollout verbunden mit Change Management
Ziele Ergebnisse
Prognose des tatsächlichen Warenbedarfs in der Filiale Erhebliche Kosteneinsparungen durch Reduzierungen der
Informationsaustausch zwischen Filiale und Abschriften
Vertriebsgesellschaft durch digitalisierte Prozesse Schnellere Kommunikation zwischen allen Usergruppen dank
ermöglichen digitalisierter Prozesse
Verdichtung der Informationen und Übernahme in Zentrale Informationsaustausch in Echtzeit mit der Zentrale und
App als zentraler Informationshub im Filialbetrieb verankern bessere Aufgabenverteilung in der Filiale
und für die Verwaltung von Tasks bereitstellen Transparenz durch alle Bereiche ermöglicht datengetriebene
Entscheidungen und erhöht die Wettbewerbsfähigkeit
31Benutzerspezifisch aggregierte Daten optimieren Arbeitsabläufe
(Historische) Verkaufs- Mobile
und Bestelldaten Datenerfassung
in Filialen
ESB ESB
ESB ESB
Zentrale Personaldaten
Länderorganisationen Arbeitszeiten
Echtzeitdaten Vertriebsgesellschaften Urlaub
vom Verkauf Filialen
32Big Data > Referenzen / Projektbeispiele
Bessere Qualität von Immobilienanzeigen mit Open Data
Ausgangssituation Vorgehensweise
Immobilienportal erhält geolokalisierte Immobilienangebote Bewertung möglicher Zusatzinformationen
von Maklern in unterschiedlichem Detaillierungsgrad Entfernung zur nächsten Schule
Nutzer können Anzeigen nicht nach allen gewünschten Ärzte in der Umgebung
Kriterien durchsuchen Nutzung offener Daten aus Open Street Map
Realisierung: schnelle und skalierbarer Geo-Suche mit
Ziele Apache Solr
Auf Basis der geolokalisierten Daten sollen weitere, für die Integration in Prozess zur Aufnahme der Anzeigen
Nutzer interessante Informationen abgeleitet werden
Angebotene Immobilien sollen mit Zusatzinformationen über Ergebnisse
die Umgebung der Objekte angereichert werden Besserer Service für die Nutzer des Portals durch
Homogenisierung der Attribute über alle Anzeigen, um eine weitreichendere, semantische Suchmöglichkeiten
konsistente Erfahrung der Nutzer sicherzustellen Abrufbare Informationen zu der Umgebung von Objekten
erhöht die Qualität der Anzeigen
Bessere Erfahrung für Nutzer, die passende Immobilien
finden können
Geringer Aufwand für Portalbetreiber durch die
automatisierte Einbindung der Zusatzinformationen
33Immobilienportal qualifiziert Objekte und macht individuelle Kundenangebote
9 Ärzte
Grüngebiete
3 Schulen
Autobahnen
italienisch
15 Restaurants
chinesisch
Autobahn-
auffahrten
3 Supermärkte Öffnungszeiten
34Big Data > Referenzen / Projektbeispiele
Exploration von Sensordaten
Ausgangssituation Ausgangssituation
Automobilhersteller nutzt Crowd-Sourcing, um Sensordaten Automobilhersteller nutzt Crowd-Sourcing, um Sensordaten
aus Erprobungsfahrten zu protokollieren aus Erprobungsfahrten zu protokollieren
Viele hundert Millionen Datensätze stehen bereit Viele hundert Millionen Datensätze stehen bereit
Datensätze können von den Ingenieuren nicht direkt Datensätze können von den Ingenieuren nicht direkt
interpretiert werden interpretiert werden
Ziele Ziele
Interaktive Exploration der Daten Interaktive Exploration der Daten
Zeitliche, räumliche und inhaltliche Selektion zum Drill-Down Zeitliche, räumliche und inhaltliche Selektion zum Drill-Down
Daten sollen genutzt werden, um den Einfluss verschiedener Daten sollen genutzt werden, um den Einfluss verschiedener
Faktoren auf das Verhalten von Fahrer und Fahrzeug zu Faktoren auf das Verhalten von Fahrer und Fahrzeug zu
verstehen verstehen
Datenexploration soll Grundlage bilden, um Dienste wie Datenexploration soll Grundlage bilden, um Dienste wie
Assistenzsysteme weiterzuentwickeln Assistenzsysteme weiterzuentwickeln
35Maschinelles Lernen bringt Fahrzeuge sicherer an ihr Ziel
Glatteis
Kurvenradien
Wissensgewinn aus einzelnem Fahrzeug ist
schwierig
Stoppzeiten Fehlerhafte Erkennung (LKW)
Crowdsourcing von vielen Fahrzeugen
Ampelphasen Viele Daten: Clustering
Hohe Zuverlässigkeit
Gefahrstellen
Ölspur
36Big Data > Referenzen / Projektbeispiele
Change Management und Agile Coaching für Spin-off im Lebensmittel-Online-
Handel
Ausgangssituation
Ein Marktführer im deutschen Lebensmittel-Einzelhandel
wollte eine Online-Shop-Plattform erstellen und gründete
dazu ein agiles Start-up als 100%ige Konzerntochter.
Die Organisation musste aufgrund des Konkurrenzdrucks
sehr schnell wachsen.
Nicht-agile Teile des Mutterkonzerns sollten reibungsfrei
integriert, die transferierten Mitarbeiter in der agilen
Denkweise geschult werden.
Die anfängliche Entwicklungsarbeit wurde an zwei Scrum-
Teams der mgm tp ausgelagert, um möglichst schnell „live“
gehen zu können. Anschließend sollte das Wissen an die
neuen internen Mitarbeiter übergeben werden.
37Projektziele Vorgehensweise
Einbindung aller relevanten Stakeholder des Managements Entwicklung eines Leitbilds und einer „Sprache“
in den „agilen Prozess“, d.h. Bewusstsein schaffen für agile entsprechend der agilen Vorgehensweise
Werte, agile Entwicklungszyklen, entsprechendes Proaktives Stakeholder-Management mit Fokus auf die
Erwartungsmanagement, Entscheidungsprozesse, zahlreichen Feedbackschleifen
selbstorganisierte Teams inklusive Teamverantwortung Agile Coaching: Aufbau von Scrum-Strukturen, Skalierung
Unterstützung beim Aufbau der agilen Organisation auf mehrere Teams, Konzepte und Prozesse für verteilte
Hohe interne Akzeptanz für das agile Vorgehen erzeugen Teams
und Widerstände auflösen Trainingskonzeptionierung und –durchführung für interne
Endnutzer des zukünftigen Shops, z.B. Kundenservice
Ergebnisse
„Go-Live“ des neuen Online-Shops planmäßig nach nur
sechs Monaten Entwicklungsarbeit
Hohe Identifikation mit der agilen Vorgehensweise und dem
gemeinsamen Leitbild bei den Mitarbeitern
Trotz schnellen internen Wachstums wuchs eine stabile
Kundenorganisation heran
38Big Data > Referenzen / Projektbeispiele
Agiles Coaching und Requirements Engineering bei einem Energieversorger
Ausgangssituation
Die zunehmende Differenzierung des Energiemarktes führt
für Energieversorger zu einem steigenden Wechselrisiko von
Kunden
Das Anbieten von Mehrwert-Services ist eine Antwort auf
diese Herausforderung
Projektziele
Anbieten eines Mehrwert-Services, der den Kunden
Energieverbrauch erklärt und personalisierte
Handlungsmöglichkeiten aufzeigt
Erfolgreiches agiles Leuchtturmprojekt innerhalb eines nicht
agilen Umfeld
GoLive des Minimum Viable Products (MVP) in sechs
Monaten
Entscheidung über Marktfähigkeit des eingeführten Services
anhand des Kundenfeedbacks ZWEIWÖCHIG GETAKTETER, AGILER WORKFLOW DES
25-KÖPFIGEN PROJEKTTEAMS
39Vorgehensweise
mgm unterstützte das Projekt in den Rollen Agile Coach,
Scrum Master und Requirements Engineer
Erarbeitung, Einführung und Coaching agiler Werte, Rollen,
Tools und Vorgehensweise nach Scrum und Kanban
Grobe Definition des Funktionsumfangs der Web-App zu
Projektbeginn
Operative Steuerung des iterativ-inkrementellen Vorgehens
mit Fokus auf Risikominimierung und hohem Kundennutzen
Ergebnisse
Live-Gang der Web-App nach sechs Monaten mit allen
Schlüsselfunktionalitäten
Mit Übergabe in die Linienorganisation verzeichnet das
Produkt 160% mehr Nutzer als früher optimistisch geplant
Projektteam fühlt sich als „agile Keimzelle“ und möchte
erlebte Kultur in ihre neuen Projekte weitertragen
4004 41
Themen
42Big Data > Themen
Themen
Aktuelle Themenschwerpunkte sind unter anderem
Suchtechnologien, Geodaten und Daten-Lebenszyklen.
Gespannt verfolgen wir auch die Entwicklung von
schnellen, schlanken Key-Value-Datenbanken.
43Datengetriebene Business-Analyse Security / Governance / Stewardship Change Management
Für eine zielgerichtete datengetrie- Der verantwortungsvolle Umgang Datengetriebene Anwendungen
bene Analyse muss ein passender mit großen Datenmengen ist ein verändern Unternehmensabläufe
Business Case definiert werden. unerlässlicher Grundsatz bei Big- und Entscheidungsprozesse.
Anschließend gilt es, relevante Daten Data-Anwendungen. Wichtig für das Hilfreich sind eine „Daten-Vision“,
zu explorieren und den kontex- Datenmanagement sind Data die Befähigung der Mitarbeiter
tuellen Rahmen zu prüfen. Governance und Data Stewardship. und das richtige Erwartungs-
management.
Recommendation Engines Daten-Lebenszyklus Hybride Datenhaltung
Empfehlung gefällig? Mit Hilfe von Von der Erstellung bis zur Archi- Klassische relationale Daten-
lernenden Recommendation Engines vierung bzw. Entsorgung durchlau- banken und Big Data schließen
können Sie Ihren Nutzern passende fen Daten viele Stadien. Dabei sich nicht aus. In vielen Fällen ist
Inhalte vorschlagen. Das ist beson- müssen diverse Aspekte wie die die Kombination sinnvoll – zum
ders wichtig für einen höheren Zeitabhängigkeit berücksichtigt Beispiel im Bereich Data Ware-
Komfort in Online-Shops. werden. house.
Geodaten
Geokodierte Daten bilden die Grund-
lagen für eine Reihe von Diensten
wie die Fahrzeug-Telematik. Bereits
auf Basis offener Daten und Techno-
logien lassen sich Geoinformations-
systeme realisieren.
44Big Data > Themen
Geschäft verbessern: Datengetriebene Business-Analyse
Business Case definieren
Der datengetriebenen Analyse liegt ein für unsere Kunden
attraktiver Business Case zugrunde. Dafür identifizieren wir
gemeinsam mit unseren Kunden für deren Unternehmens-
zweck relevante Fragestellungen. Dann explorieren wir, ob und
Ent- Daten-
wie die dem Unternehmen zur Verfügung stehenden Daten
scheidung Exploration
Antworten auf diese Fragestellungen geben können. Die
Verfeinerung des geschäftsrelevanten Business Cases erfolgt
iterativ und in enger Zusammenarbeit mit Fachbereich und
Datenverantwortlichen.
Vergleich Modell-
Daten explorieren
rechnung
Am Anfang der Datenexploration steht die Frage, welche Daten
in einem lesbaren Format zur Verfügung stehen und gleichzeitig
für das Unternehmen interessant und relevant sind. Mit Hilfe
dieser ausgewählten Echtdaten lassen sich anschließend bereits Prognose
erste aufgestellte fachliche Hypothesen testen. Iterativ wird
schließlich das Potenzial der datengetriebenen Analyse
ausgelotet und relevante Daten und Fragestellungen sukzessive
präzisiert.
45Kontext-Checks durchführen
Eine umfassende datengetriebene Business-Analyse nützt erst
dann, wenn die Ergebnisse daraus auch umgesetzt werden
können. Um alle Hindernisse aus dem Weg zu räumen, muss
auch der kontextuelle Rahmen potenzieller Anwendungen und
Lösungen überprüft werden. Gibt es besondere Anforderungen
an Datensicherheit und Datenschutz? Birgt die datengetriebene
Herangehensweise ethische Risiken oder kulturelle Konflikte?
46Big Data > Themen
Sicher: Security / Governance / Stewardship
Security
Der verantwortungsvolle Umgang mit großen Datenmengen ist
ein unerlässlicher Grundsatz bei der Realisierung daten-
getriebener Anwendungen. Wir setzen dafür Techniken im
Bereich Anonymisierung und Pseudonymisierung ein und
arbeiten in enger Kooperation mit rechtlichen Ansprech-
partnern – insbesondere wenn personenbezogene Daten im
Spiel sind. Durch die große Datenmenge können teilweise auch
nicht direkt personenbezogene Daten noch Individuen
zugeordnet werden. Hier sprechen wir von Personenbezieh-
barkeit, die separat überprüft werden muss.
Data Governance
Data Governance regelt Prozesse rund um die Verwaltung und
Nutzung von Daten im Unternehmen. Dazu gehören
beispielsweise Methoden der Qualitätssicherung und Richtlinien
bezüglich autorisierter Datenverwendung. Außerdem muss die
Data Governance bei datengetriebenen Anwendungen
sicherstellen, dass zentrale Unternehmenswerte dabei nicht
verletzt werden.
47Data Stewardship
Die Verknüpfung mehrerer Datenquellen ist eines der
Aufgabengebiete, denen sich der Komplex Data Stewardship
widmet. Hier geht es darum, Fehlerrechnungen durchzuführen,
um Ungenauigkeiten in den Quelldaten so zu analysieren, dass
man die Fehler in den berechneten Daten kennt. Damit kann
auch bei nicht ganz verlässlichen Ausgangsdaten die Aussage-
kraft der Ergebnisse gewährleistet werden. Eine wichtige
Aufgabe der Disziplin ist die Dokumentation der Datenflüsse
und -schnittstellen. Bei Änderungen in den zuliefernden
Diensten können so Fehler bereits im Vorfeld vermieden
werden.
48Big Data > Themen
Befähigend: Change Management
Auf ein gemeinsames Ziel ausrichten
Der Einsatz von datengetriebenen Anwendungen bringt oft
Veränderungen in Unternehmensabläufen und Entscheidungs-
prozessen mit sich. Wir unterstützen Sie dabei, diese
Veränderungen frühzeitig unternehmensweit zu antizipieren
und Akzeptanz dafür zu schaffen. Um ein besseres Verständnis
zu entwickeln, skizzieren wir mit Ihnen eine „Daten-Vision“. Die
„Daten-Vision“ kann den „roten Faden“ der datengetriebenen
Weiterentwicklung Ihres Unternehmens bilden.
MitarbeiterInnen einbinden und befähigen
Um die Akzeptanz neuer Lösungen und die fachliche Qualität
datengetriebener Anwendungen zu fördern, binden wir Ihre
MitarbeiterInnen frühzeitig ein. Fachliche Unterstützung und
regelmäßige Feedbackrunden gehören zu den Maßnahmen, die
das gemeinsame Erarbeiten neuer Prozesse und Entscheidungs-
wege unterstützen. Sowohl das Expertenwissen als auch die
Sichtweisen Ihrer Mitarbeiter sollten in Big Data Projekte
einfließen.
49Erwartungen „managen“
Ein wichtiger Bestandteil einer Big Data-Initiative ist das
Erwartungsmanagement. Ganz entscheidend ist dabei der
direkte Austausch mit Stakeholdern. Die beteiligten oder
betroffenen Personen sollten individuell angehört und abgeholt
werden.
50Big Data > Themen
Orte nutzen: Geodaten
Geokodierung von Daten
Innerhalb der letzten Jahre ist der Bedarf an Anwendungen
gestiegen, die mit geokodierten Daten operieren müssen – von
Free-Floating-Carsharing bis hin zu Telematik-Diensten zur
Positionsbestimmung von Containern. Ein zentraler Treiber
dafür sind unter anderem die rasanten Fortschritte im Bereich
Mobile Computing. Wir verfolgen die Entwicklung mit großem
Interesse und interessieren uns für technische Aspekte der
Geokodierung und darauf aufbauende Anwendungen.
Geoinformationssysteme mit Open Source und Open Data reali-
sieren
Neben proprietären Diensten sind auch offene Geo-
informationsdienste wie OpenStreetMap entstanden. Eine
wachsende Community sammelt kontinuierlich GPS-Daten und
wandelt diese so, dass sie als Basis für OpenStreetMap offen
verwendet werden können. Was viele nicht wissen: Die Daten
lassen sich mit dem richtigen Know-how in eigenen
Anwendungen nutzen. Neben der offensichtlichen Verwendung
in Fahrzeugen oder zur Handy-Navigation kann das unter ande-
51rem für die Bewertung von Immobilien gewinnbringend zum
Einsatz kommen.
Wie groß ist die Entfernung zur nächsten Schule, zum Super-
markt oder bis zur Autobahnauffahrt? Wir beschäftigen uns
schon seit Jahren mit der Implementierung solcher Geo-
informationssysteme und –dienste auf Basis von Open-Source-
Technologien und Open Data.
52Big Data > Themen
Mit besten Empfehlungen: Recommendation Engines
Konzeption von Empfehlungsdiensten
Empfehlungsdienste sind für Portale wie Online-Shops ein
Muss, um den Komfort der Nutzer zu steigern und Ihnen
relevante Inhalte schnell anzuzeigen. Die Möglichkeiten reichen
von der Darstellung häufig zusammen gekaufter Produkte bis
zu personalisierten Empfehlungen. Grundlage ist in jedem Fall
das Sammeln aller verfügbaren Daten zu Kunden, Klickpfaden
und Warenkörben beziehungsweise Bestellungen. Wir unter-
stützen Sie bei der Konzeption für Ihre individuellen Ziel-
setzungen, um aus diesen Daten geschäftlichen Mehrwert zu
schaffen.
Implementierung von Empfehlungsdiensten
Als Spezialist im Bereich transaktionaler Online-Portale sind wir
mit der Implementierung von Empfehlungsdiensten seit Jahren
vertraut. Wir helfen Ihnen in allen Schritten der Umsetzung –
vom Sammeln der Daten, der Auswahl einer Recommendation
Engine oder der individuellen Entwicklung über die Berück-
sichtigung nicht-funktionaler Anforderungen wie die Anzahl der
Zugriffe bis zur künstlichen Intelligenz und der ständigen
Optimierung im Betrieb.
5354
Big Data > Themen
Wandelbar: Daten-Lebenszyklus
Heterogene Datenbestände
Die Vielfältigkeit der Daten („Variety“) gilt neben der Menge und
der Verarbeitungsgeschwindigkeit („Volume“ und „Velocity“) als
Intern / extern,
zentrales Merkmal von Big Data. Typischerweise treten Daten u.a. Open Data
aus unterschiedlichen Quellen zusammen, die teils strukturiert
und teils unstrukturiert sind. Dazu gehören beispielsweise Historische
Daten
Sensordaten und Logdaten oder aggregiertes Kundenfeedback Neue KPIs,
Korrelationen o.ä.
in Form von E-Mails. Sie können historisch sein (also bereits +
gespeichert) oder in Echtzeit entstehen und direkt nach der
Erzeugung in Analysen einfließen. Neben Daten aus dem Real-time -/
oder
Unternehmen selber, können auch externe Datenquellen – Echtzeit-Daten
beispielsweise aus Open-Data-Portalen – herangezogen werden. + Vorhersagen
Format-Wirrwarr bewältigen
Unstrukturierte
Vor allem dann, wenn sich in einer Big-Data-Lösung Daten aus Daten
(z.B. Kommentare des
vielen verschiedenen Quellen anhäufen, müssen sie in eine Kundenservice, E-Mails
mit Kunden, Protokolle)
gemeinsame Form gebracht werden. Hier stellen sich
Herausforderungen rund um den Umgang mit unterschied-
lichen Ausgangsformaten. In einem Projekt haben unsere
Experten beispielsweise eine Lösung zur Speicherung und
Verarbeitung von 20.000 unterschiedlichen Formaten
entwickelt.
55Zeitabhängigkeit und rechtliche Anforderungen
Eine weitere Schwierigkeit: Daten sind zeitabhängig. Wenn eine
Anwendung beispielsweise mit Geodaten operiert, muss sie auf
Änderungen gefasst sein. Neue Straßen werden gebaut und
Ländergrenzen verschieben sich, gleichzeitig müssen alte
Fahrzeugdaten aber auch noch zu den alten Karten passen.
Rechtliche Anforderungen können weitere Verarbeitungs-
schritte notwendig machen. Personenbezogene Daten müssen
beispielsweise nach einer bestimmten Zeit gelöscht werden.
56Big Data > Themen
Das Beste aus beiden Welten: Hybride Datenhaltung
Relationale Datenbanken mit Datenhaltung in Hadoop kombi-
nieren
In vielen Anwendungsfällen ist es sinnvoll, klassische relationale
Datenbanken mit NoSQL-Datenbanken und Big-Data-
Technologien zu kombinieren. Mit Hilfe einer zweispurigen
Lösung bleibt der gesamte Datenbestand handhabbar. Ein Teil
der Datenbestände wird weiterhin in einer relationalen,
transaktionalen Datenbank verwaltet, während ein anderer Teil
in eine verteilte Datenhaltung auf Basis von Hadoop überführt
wird.
Anwendungsbeispiel: Logdaten von Websites
In transaktionalen Applikationen wie Online-Marktplätzen treten
in der Regel auch unstrukturierte Daten auf. Ein typisches
Beispiel sind Logdaten, die sich aus vielen Einzelkomponenten
anhäufen und durchsucht werden müssen. Mit Hadoop lassen
sich die mitunter sehr großen, täglich wachsenden Daten-
mengen auch über längere Zeiträume speichern. Kombiniert
mit einer Suchplattform wie Apache Solr lassen sie sich schnell
durchsuchen und aggregieren.
57Anwendungsbeispiel: Data Warehouse
Ein weiteres Einsatzgebiet, in dem Big-Data-Technologien
derzeit Beachtung finden, ist der Data-Warehouse-Sektor. Die
Lizenz-, Support- und Hardwarekosten von moderner RDBMS-
Software verursachen hohe Kosten. Außerdem ist die
Implementierung sogenannter Cubes zur Auswertung sehr
aufwändig und muss für alle neuen Aggregate durchgeführt
werden. Hadoop-basierte Systeme gelten zunehmend als
kostengünstigere Alternativen – sei es als teilweiser oder
vollständiger Ersatz. Wir beschäftigen uns in dem
Zusammenhang beispielsweise mit Open-Source-Technologien
wie Presto und Jasper Reports. Presto ist eine von Facebook
entwickelte, verteilte SQL Query Engine. Das Besondere: Sie
ermöglicht Anfragen gegen die Hadoop-basierte Datenhaltung
mit Hive und Cassandra, aber eben auch gegen relationale
Datenbanken und proprietäre Datenspeicher. Mit dem auf Java
basierenden Jasper Reports können professionelle Reports
erzeugt werden.
5805 59
Technologien
60Big Data > Technologien
Technologien
Unsere Experten haben diverse Open-Source-Technologien
auf dem Radar. Hadoop, Spark, Storm, etc. Um die 20 davon
haben wir schon in konkreten Projekten eingesetzt.
61R & Python Hadoop-Ökosystem
R und Python sind bewährte Begleiter unserer Data Apache Hadoop bildet die Basis für eine hochskalierbare,
Scientists. Stichproben von Datenbeständen lassen sich performante und verteilte Datenhaltung und –verarbeitung.
damit schnell untersuchen. Statistische Analysen können Etliche Erweiterungen wie HBase und Hive ergänzen die
leicht visualisiert werden. Basistechnologie.
Presto Apache Spark
Presto schlägt die Brücke zwischen klassischen Data- Neben Hadoop hat sich Apache Spark als eines der
Warehouse-Szenarien und massiven Datenbeständen. Die wichtigsten Big-Data-Frameworks etabliert. Spark punktet
verteilte SQL Query Engine ermöglicht schnelle Analysen durch sehr schnelle Ausführungsgeschwindigkeiten und
und Reports. glänzt im Bereich Machine Learning.
Apache Solr
Die Open-Source-Suchplattform Apache Solr ist nicht nur die
beliebteste Suchmaschine im Enterprise-Umfeld. Auch im
Kontext von Big Data spielt die skalierbare Suchlösung ihre
Stärken aus.
62Big Data > Technologien
Toolbox für Data Scientists: R & Python
Daten-Stichproben untersuchen mit R
R ist eine freie Softwareumgebung für Statistik, die seit 1995 Boxplot: Schnelle Beurteilung
der Konfidenz (Mittelwert /
unter der GNU General Public License steht. Wir setzen R in
Outlier)
erster Linie ein, um im Rahmen eines Vor- oder Analyseprojekts
Stichproben größerer Datenbestände schnell und flexibel zu
untersuchen und datengetriebene Beratung anzubieten. Mit
Hilfe von Regressions- und Clusteranalysen lassen sich
beispielsweise Modelle erstellen, um Zusammenhänge zwischen
Clustering: Erkennung
Variablen zu analysieren und Vorhersagen zu treffen. Mit wiederkehrender Muster
Bibliotheken wie ggplot2 lassen sich die Daten einfach und
übersichtlich visualisieren. R verfügt über eine große
Community und viele Erweiterungen. Das CRAN Repository
bietet über 7.000 Pakete, die die Umgebung ergänzen.
Regression: Erkennung der Trends
in den Clustern
63Flexible und integrierbare Analysen mit Python
Während R explizit für Statistiker ausgelegt ist, erlebt mit Python
derzeit auch eine General-Purpose-Programmiersprache
Aufwind im Data-Science-Umfeld. Grund dafür ist einerseits die
steigende Maturität von Paketen für die Datenanalyse wie
NumPy und matplotlib. Andererseits bietet Python flexiblere
Integrationsmöglichkeiten. Datenanalysen und statistischer
Code können einfacher in Web-Applikationen einfließen oder
mit Datenbanken interagieren.
64Big Data > Technologien
Solides Fundament: Hadoop-Ökosystem
20 Kerntechnologien auf dem Radar
Hadoop entstand ursprünglich 2005 als freie Implementierung
von Googles MapReduce-Framework und gilt heute als de facto
Standard im Open-Source-Big-Data-Umfeld. Mit dem verteilten
Dateisystem HDFS und dem Ressourcen-Manager YARN bildet
das Apache-Projekt in der neuesten Version die Grundlage für
eine kostengünstige sowie skalierbare verteilte Datenhaltung
und –verarbeitung. Zahlreiche weitere Technologien bauen
darauf auf – von verteilten Datenbanken wie HBase bis zu
Workflow Engines wie Oozie. Zur Echtzeitverarbeitung kann
etwa Apache Storm in das Ökosystem integriert werden. Unsere
Experten haben um die 20 Kerntechnologien rund um Hadoop
auf dem Schirm.
Erfolgreich eingesetzt in diversen Projekten
Hadoop und die angrenzenden Technologien sind bereits in
vielen mgm-Projekten zum Einsatz gekommen. Ein Beispiel: Um
Millionen von Datensätzen in tausenden unterschiedlichen
Ursprungsformaten in einem verteilten Datenhaltungssystem
zu speichern, haben wir eine Lösung mit Hadoop und HBase
65realisiert. Ein genereller Vorteil für die Kunden beim Einsatz von
Hadoop: keine Lizenzkosten dank Open Source, damit eine
mögliche Skalierung nicht an teuren Software-Lizenzen
scheitert.
Nachhaltige Software-Stacks zusammenstellen
Das Hadoop-Ökosystem expandiert ständig. Bestehende
Technologien entwickeln sich weiter und neue Technologien
treten dazu, bei einigen Projekten wird aber auch die
Weiterentwicklung eingestellt. Eine Herausforderung besteht
darin, die Maturität und das Weiterentwicklungspotenzial der
einzelnen Bausteine im Blick zu behalten. Und passgenau für
die Anforderungen eines Projekts die richtigen Technologien zu
kombinieren. Soll es Echtzeit- oder Batch-Verarbeitung sein?
Wird ein konsistenter Datenzustand, sprich Transaktionalität,
benötigt? Sind die Daten strukturiert, semi-strukturiert oder
unstrukturiert? Um für alle Fälle die beste Lösung zu finden,
beobachten und evaluieren wir neben den Kernbausteinen viele
weitere Technologien.
66Big Data > Technologien
Brückenschlag: Presto
(Big) Data Warehouse
Presto ist eine verteilte SQL-Query-Engine, die interaktive
Anfragen an Datenquellen jeder Größe ermöglicht. Ursprünglich
wurde Presto von Facebook entwickelt. Ziel war es, ein Tool zu
schaffen, das auch Anfragen an große Datenmengen so schnell
beantwortet wie kommerzielle Data Warehouse Lösungen.
Facebook nutzt Presto für das 300 Petabyte große Data
Warehouse des Unternehmens. Seit Ende 2013 ist das Tool als
Open Source Projekt offen verfügbar. Weitere prominente
Nutzer sind Airbnb und Dropbox.
Analysen und Reports auf Basis verschiedener Datenquellen
Presto kann nicht nur auf Hadoop-Clustern mit HDFS operieren,
sondern auch auf anderen Datenquellen wie traditionellen
relationalen Datenbanken oder Cassandra. Presto ermöglicht
außerdem, Daten aus diesen heterogenen Datenquellen
miteinander zu verbinden. So können Aggregate aus der
“neuen” und “alten” Welt berechnet und daraus individuelle
Berichte erstellt werden. Presto übernimmt im Data
Warehouse-Kontext den Part der Datenanalyse, sprich Online
67Analytical Processing (OLAP). Es ist kein Ersatz für relationale
Datenbanken wie MySQL, PostgreSQL oder Oracle und
unterstützt kein Online Transaction Processing (OLTP).
68Big Data > Technologien
Funkenflug: Apache Spark
Schnell und unkompliziert
Bei Apache Spark ist der Funke schnell auf unser Big-Data-Team
übergesprungen. Die Engine ist schnell in der Ausführung –
sowohl In-Memory, als auch bei Operationen auf Festplatten –
und unkompliziert im Umgang. Kein Wunder, dass Spark
mittlerweile weit verbreitet ist und neben Hadoop als
populärstes Big-Data-Framework gilt. Der chinesische
Suchmaschinenhersteller Baidu setzt ebenso auf die Engine wie
die NASA für ihr Deep Space Network. Wir setzen Spark Shark Shark Mllib GraphX
beispielsweise in Big-Data-Projekten mit großen Mengen an (SQL) Streaming (machine (graph)
Sensordaten ein, um schnelle Auswertungen zu realisieren. learning)
Kombinierbar mit Hadoop
Apache Spark
Spark ist eine reine Engine, kein kompletter Stack wie Hadoop.
Deshalb wird Spark häufig mit Hadoop als Basis-Infrastruktur
kombiniert. Hadoop fungiert dann als System für verteilte
Datenhaltung, während Spark darauf aufsetzt. Je nach
Anwendungsfall lässt sich Spark aber auch ohne Hadoop
einsetzen – zum Beispiel in Kombination mit NoSQL-
Datenbanken wie Cassandra.
69Entwickelt mit Blick auf Machine Learning
Ursprünglich wurde Spark im Jahr 2009 von Matei Zaharia
entwickelt, der zu dem Zeitpunkt Doktorand an der UC Berkely
war. Der Ausgangspunkt: Limitierungen des MapReduce-
Ansatzes im Kontext von Machine-Learning-Algorithmen und
interaktiven Anfragen. Gemeinsam mit einer wachsenden
Community wurde aus Spark eine universell einsetzbare Engine,
die vor allem bei fortgeschrittenen Methoden der Daten-
verarbeitung wie eben Machine Learning oder Stream
Processing glänzt.
70Big Data > Technologien
Lupenreine Suchplattform: Apache Solr
Beliebteste Enterprise-Suchmaschine
Apache Solr ist eine Suchplattform, die auf Apache Lucene
basiert – einer Java API zur Volltextsuche. Ursprünglich wurde
Solr 2004 für das News-Portal CNET Networks entwickelt. Seit
2007 ist die Suchplattform ein Top-Level Projekt der Apache-
Stiftung und kann nicht nur Texte durchsuchen, sondern viel
mehr. Solr gilt heute als beliebteste Suchmaschine im
Enterprise-Umfeld. Die User-Liste reicht von AT&T über ebay
und Instagram bis hin zu Netflix. Wir setzen Solr schon seit
Jahren als Suchkomponente für komplexe Webapplikationen ein
– zum Beispiel bei Online-Shops und E-Government-
Plattformen. Eine Alternative ist das jüngere ElasticSearch. Da es
von einer privaten Firma betreut wird, ist hier jedoch offen, wie
sich die Suchmaschine langfristig weiterentwickelt und welche
Form die Lizenz annimmt.
Flexible Indexierung und schnelle Suche
Die zentralen zwei Schritte bei der Arbeit mit Solr sind
Indexierung und Suche. Die Indexierung ist konzeptuell
vergleichbar mit der Erstellung eines Index eines Buches, in dem
Stichwörter auf Seitenzahlen verweisen.
71Wenn ein neues Kapitel hinzukommt, muss der Index
aktualisiert werden. Wenn der Index erstellt wurde, lassen sich
darin Inhalte sehr schnell anhand eines Suchworts finden. In
einem Projekt konnten wir damit beispielsweise die
Echtzeitsuche in einem Bestand von 20 Milliarden Datensätzen
nach verschiedenen Kriterien bzw. Kombinationen realisieren,
um die Rückverfolgung von historischen Zuordnungen zu
ermöglichen. Neben Text unterstützt Solr viele weitere
Datentypen wie zum Beispiel Koordinatenpaare oder gar
geometrische Figuren.
Ausgelegt für verteilte Systeme
Eine der wichtigsten Eigenschaften von Solr im Kontext von Big
Data ist, dass die Technologie gut skaliert und für verteilte
Systeme ausgelegt ist. Wird der Index sehr groß, kann er ohne
großen Aufwand in sogenannte Shards und mehrere Server
aufgeteilt werden. Eine Suchanfrage wird dann in mehrere Sub-
Anfragen untergliedert, die jeweils auf den einzelnen Shards
laufen. Besonders im Zusammenspiel mit Hadoop kann Solr
aufgrund dieser Eigenschaften punkten. Hadoop kann
andererseits auch die Indexierung der Inhalte in einem Cluster
mit hoher Geschwindigkeit und Parallelität durchführen.
7273
74
Innovation Implemented.
München Aachen Bamberg Berlin Đà Nẵng Dresden Grenoble Hamburg Köln Leipzig Nürnberg Prag Stuttgart Washington Zug
mgm technology partners gmbh
Frankfurter Ring 105a
80807 München
Tel.: +49 (89) 35 86 80-0
Fax: +49 (89) 35 86 80-288
www.mgm-tp.com
Stand: 06 / 2019
75Sie können auch lesen

















































