OCR-D in der Praxis: Ein gemeinsamer Ausblick mit Dienstleistern und Anwendern - Bibliothekskongress Leipzig, 18.03.2019 - OPUS 4
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

OCR-D in der Praxis: Ein gemeinsamer
Ausblick mit Dienstleistern und
Anwendern
7. Bibliothekskongress
Leipzig, 18.03.2019
18.03.2019 Matthias Boenig
Gliederung
2
1. Projektvorstellung
2. Arbeiten in OCR-D
3. Modulprojekte
4. Dissemination
5. Ausblick
Diskussion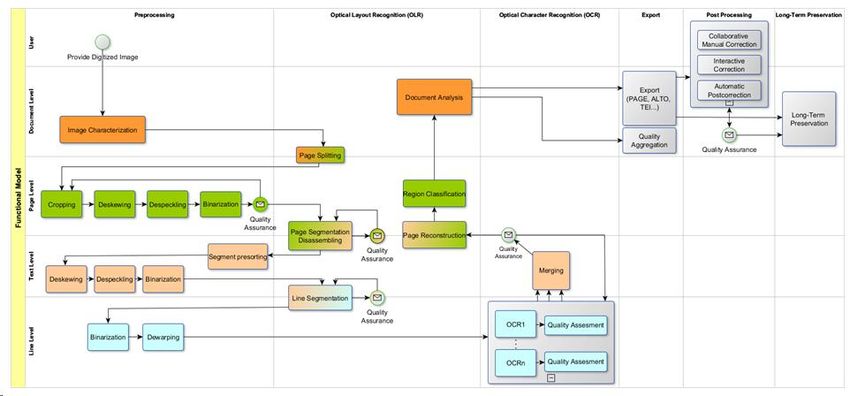
Verzeichnisse der im deutschen Sprachraum erschienenen
Drucke des 16-18. Jh. (VD)
(ab 2020?)
*gerundete Werte
Herzog August Bibliothek
© Susanne Hübner, Stadt Wolfenbüttel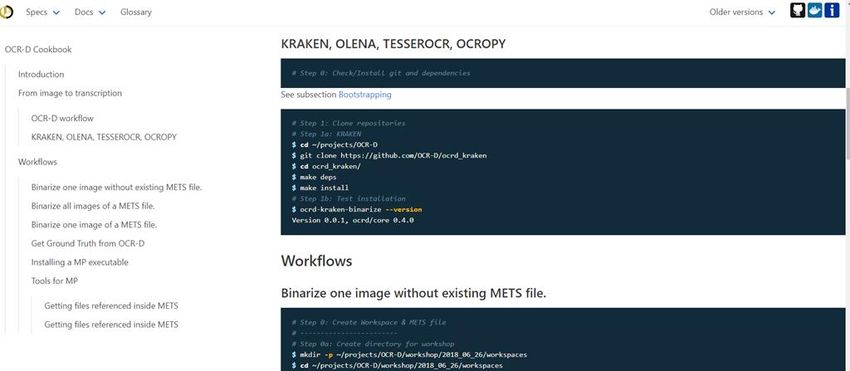
Hintergrund
4
Digitale Wende in den Wissenschaften
Prof. Dr. Christof Schöch:
Professor für Digital Humanities an der Universität Trier und Ko-Direktor des Trier Center for Digital Humanities.
“Mit der digitalen Wende, die wir derzeit erleben, werden die Mittel der Repräsentation,
Reproduktion, des Austauschs und der Manipulation von Texten erneut radikal verändert.
Insbesondere durch zahlreiche groß angelegte Digitalisierungs-Projekte weltweit erweitert sich das
digital verfügbare kulturelle Erbe in Textform ständig, die Texte sind untereinander vernetzt und
liegen in fluiden Formen vor. Immer größere Anteile des kulturellen Erbes liegen in elektronischer
Form buchstäblich unter unseren Fingerspitzen und fordern uns dazu auf, sie zu nutzen.”
Quelle: Schöch, Christof (2014): „Corneille, Molière et les autres. Stilometrische Analysen zu Autorschaft und Gattungszugehörigkeit im
französischen Theater der Klassik“, in: Schöch, Christof / Schneider, Lars (eds.): Literaturwissenschaft im digitalen Medienwandel
(=Philologie im Netz Beiheft 7) 130-157 http://web.fu-berlin.de/phin/beiheft7/b7t08.pdf [letzter Zugriff 25.September 2017].
Hintergrund
6
DFG-Workshop 2014: Verfahren zur Verbesserung von OCR-Ergebnissen kommt zu folgenden
Erkenntnissen:
1. Notwendigkeit des Auf- und Ausbaus sowie freier Zugang zu historischen Textkorpora und
lexikalischen Ressourcen zum Training von vorhandener Software zur Texterkennung
2. Weiterentwicklung von Nachkorrekturanwendungen
3.Weiterentwicklung von Open-Source-OCR-Engines zur Verbesserung der Textgenauigkeit
4.der gesamte Workflow der Volltextgenerierung mit OCR im Blick, um Standards, Verfahren zur
Langzeitarchivierung sowie persistente Adressierung zu entwickeln
5.Services, Standards, interoperable Datenfomate zur Verbesserung des Zugriff auf Volltexte
6.Eine koordinierte Fördermaßnahme der DFG ist notwendig.
1. Projektvorstellung
7
Koordinierte Förderinitiative zur Weiterentwicklung von Verfahren der Optical Character
Recognition (OCR-D)
● gefördert von der Deutschen Forschungsgemeinschaft (2015-2020)
● 1. Projektphase (2015-2018):
○ Ermittlung von Entwicklungsbedarfen
○ Erstellung eines Funktionsmodells für den OCR-Prozess
○ Erarbeitung eines Koordinierungskonzeptes für die Modulprojektphase
○ Vorbereitung der Ausschreibungsunterlagen
● 2. Projektphase (2018-2020):
○ Aufbau des OCR-D-Frameworks
○ Koordinierung der Modulprojekte
○ Zusammenführung1. Projektvorstellung
8
Hauptziel von OCR-D ist die konzeptionelle Vorbereitung der Transformation der
VD-Drucke (16.-19. Jh.) in maschinenlesbare Form.
● die Erstellung von Ground Truth
● die Erarbeitung von Standards hinsichtlich Metadaten
● die Weiterentwicklung der Optical Layout Recognition (OLR)
● die Analyse vorhandener Tools, auch zur Nachkorrektur
● die Entwicklung von technischer Dokumentation, Schnittstellen, Spezifikationen
● die Erstellung eines Workflows zur Massenvolltextdigitalisierung
● die Erstellung von Verfahren der QualitätssicherungOCR-D 9
2. Arbeiten in OCR-D
2. Arbeiten in OCR-D
11
Modular
Monolithisch2. Arbeiten in OCR-D 12
2. Arbeiten in OCR-D
13
OCR-D Framework, Module:
1. Bildvorverarbeitung
2. Layouterkennung
3. Textoptimierung
○ OCR-Verbesserung
○ Nachkorrektur
4. Modelltraining
5. Langzeitarchivierung und Persistenz
6. Qualitätssicherung2. Arbeiten in OCR-D
14
Koordinierungsprojekt:
● Koordination der Kommunikation
● Spezifizieren der technischen Anforderungen der Modulprojekte
○ Austauschformate
○ Interfaces
○ Best Practices Software-Entwicklung
● Implementierung
○ Softwarebibliothek zur einfachen Implementierung der Anforderungen
○ Validierung von Formaten und Interfaces
○ von existierenden Tools (ocropy, kraken, OLENA …)
○ Werkzeuge für verwandte Anwendungen (tocrify, page-xml-cropper, mollusc…)OCR-D-Specification (spec) https://ocr-d.github.io/
ocrd-tool.json
ocrd cookbook
ocr-d/core
https://github.com/OCR-D/core/
● Referenzimplementierung der Spezifikationen
● Python-Bibliothek
● Werkzeuge zum Validieren, Serialisieren, Prozessieren
● APIs für METS, PAGE, EXIF …
● Kommandozeilentool
● …
Batteries included!OCR-D-Toolset
OCR-D-Toolset : Preprocessing
Tool Developer Functionality Wrapper
anyOCR DFKI Kaiserslautern binarization, cropping, deskewing, dewarping python
OLENA OCR-D binarization shell
tesseract UB Mannheim, binarization python
ASV Leipzig
OCRopus OCR-D binarization python
kraken OCR-D binarization python
ImageMagick OCR-D binarization, conversion shellOCR-D-Toolset : Layout recognition
Tool Developer Functionality Wrapper
anyOCR DFKI Kaiserslautern block+line seg8n, python
block class7n,
document analysis
segmentation-runner Uni Würzburg block+line seg8n, block class7n (shell)
OCRopus OCR-D line seg8n python
kraken OCR-D line seg8n python
tesseract UB Mannheim, block+line seg8n python
ASV Leipzig
dh_segment OCR-D block+line seg8n (shell)
typegroups_classifier font recognition pythonOCR-D-Toolset : Text recognition
Tool Developer Functionality Wrapper
OCRopus OCR-D text recognition python
kraken OCR-D text recognition python
tesseract UB Mannheim, text recognition python
ASV Leipzig
calamari OCR-D text recognition (python)
ocrad OCR-D text recognition (shell)OCR-D-Toolset : Postprocessing Tool Developer Functionality Wrapper cor-asv-fst ASV Leipzig post correction (python) PoCoTo CIS München post correction python keraslm ASV Leipzig post correction python ocrevalUAtion OCR-D evaluation (shell)
OCR-D : Ground-Truth-Daten
24
Ground-Truth
● Erstellung von Ground-Truth-Daten aus OCR-D heraus und Anreicherung des Korpus um Daten
des Deutschen Textarchivs (DTA)
○ Korpus: http://www.ocr-d.de/daten
● Ground-Truth-Guidelines: https://ocr-d.github.io/gt
● erweiterte Dokumentation von PAGE XML
○ https://ocr-d.github.io/gt/trans_documentation/trPage.htmlOCR-D : Ground-Truth-Daten
25
● Ziel:
○ Training von Erkennungssoftware
○ Evaluation der Erkennungsergebnisse
● GT für Texterkennung
○ zeilen- und wortweise Transkription
○ Texte mit Fraktur und Antiqua (Zeitraum 16. - 19. Jahrhundert)
○ Sprachen: Deutsch, Latein, Griechisch, Hebräisch
● GT für Layouterkennung
○ semantische Auszeichnung der Dokument- und Seitenstruktur
○ u.a. Kapitelüberschriften, Marginalien, Fußnoten3. Modulprojekte
3. Modulprojekte
27
Modul 1: Bildvorverarbeitung
optimale Vorbereitung der Bilddigitalisate für den Erkennungsprozess
Projekt:
● Skalierbare Verfahren der Text- und Strukturerkennung für die Volltextdigitalisierung
historischer Drucke: Bildoptimierung
Deutsches Forschungszentrum für Künstliche Intelligenz (DFKI)3. Modulprojekte
28
Modul 2: Layouterkennung
Erfassung der 1) Struktur der Dokumente, 2) Lokalisierung des Texts
Projekte:
● Skalierbare Verfahren der Text- und Strukturerkennung für die Volltextdigitalisierung
historischer Drucke: Layouterkennung
DFKI
GitHub: https://github.com/syedsaqibbukhari/docanalysis
● Weiterentwicklung eines semi-automatischen Open-Source-Tools zur Layout-Analyse und
Regionen-Extraktion und -Klassifikation (LAREX) von frühen Buchdrucken
Julius-Maximilians-Universität Würzburg, Institut für Informatik: Lehrstuhl für Künstliche Intelligenz und
angewandte Informatik
GitHub: https://github.com/ocr-d-modul-2-segmentierung3. Modulprojekte
29
Modul 3: Textoptimierung
Reduzierung der Texterkennungsfehler durch Optimierten Einsatz von OCR-Verfahren
Projekte:
● Optimierter Einsatz von OCR-Verfahren – Tesseract als Komponente im OCR-D-Workflow
Universität Mannheim, Universitätsbibliothek Mannheim
GitHub: http://github.com/tesseract-ocr/tesseract/3. Modulprojekte
30
Modul 3: Textoptimierung
Reduzierung der Texterkennungsfehler durch Optimierten Einsatz von Nachkorrektur
Projekte:
● NN/FST – Unsupervised OCR-Postcorrection based on Neural Networks and Finite-state
Transducers
Universität Leipzig, Institut für Informatik: Abteilung Automatische Sprachverarbeitung
GitHub: https://github.com/ASVLeipzig/cor-asv-fst
● Automatische Nachkorrektur historischer OCR-erfasster Drucke mit integrierter optionaler
interaktiver Korrektur
Ludwig-Maximilians-Universität München, Centrum für Informations- und Sprachverarbeitung (CIS)
GitHub: https://github.com/cisocrgroup/ocrd-postcorrection,
https://github.com/cisocrgroup/cis-ocrd-py3. Modulprojekte
31
Modul 4: Modelltraining
Erstellung spezifischer OCR-Modelle für historische Daten, Trainingsinfrastruktur, Mikrotypographisches
Formeninventar, Modellrepositorium
Projekt:
● Entwicklung eines Modellrepositoriums und einer Automatischen Schriftarterkennung für
OCR-D
Universität Leipzig, Institut für Informatik: Lehrstuhl für Digital Humanities
Friedrich-Alexander-Universität Erlangen-Nürnberg, Department Informatik: Lehrstuhl für Informatik 5:
Mustererkennung
Johannes Gutenberg-Universität Mainz, Gutenberg-Institut für Weltliteratur und schriftorientierte Medien:
Abteilung Buchwissenschaft
GitHub: https://github.com/Doreenruirui/OCRD ,
https://github.com/seuretm/ocrd_typegroups_classifier3. Modulprojekte
32
Modul 5: Langzeitarchivierung und Persistenz
Sicherstellung der nachhaltigen Verfügbarkeit der Volltexte
Projekt:
● OLA-HD – Ein OCR-D-Langzeitarchiv für historische Drucke
Georg-August-Universität Göttingen, Niedersächsische Staats- und Universitätsbibliothek
Gesellschaft für Wissenschaftliche Datenverarbeitung mbH Göttingen
GitHub: https://github.com/subugoe/OLA-HD-IMPL3. Modulprojekte
33
Modul 6: Qualitätssicherung
(Ground-Truth-freie) Evaluierung der einzelnen Verarbeitungsschritte
Ziel:
“Die erwarteten Entwicklungen in diesem Modul haben zwei Dimensionen: Zum einen sollen
Metriken zur Qualitätseinschätzung ohne dokumentspezifische Ground-Truth-Daten konzipiert
werden. Zum anderen sind Verfahren zu entwickeln, die die Qualitätsmessung auf Basis dieser
Metriken prozessfähig machen und deren automatische Erhebung ermöglichen.
[Die Qualitätssicherung umfasst folgende]... Ebenen Vorverarbeitung, Layoutanalyse,
Volltexterstellung und Textoptimierung. Neben der Evaluierung der Teilergebnisse soll auch deren
Verrechnung zu einem Gesamtergebnis realisiert werden.”OCR-D in a Box Quelle: Wikimedia https://commons.wikimedia.org/wiki/File:US_Navy_110415-N-KK330- 088_pecial_Warfare_Operator_1st_Class_Quinn_Pearson_passes_a_box_of_books_to_Special_Warfare_Boat_Oper
4. Dissemination
4. Dissemination
36
Dreisäulenkonzept
● verschiedene (Text-)Digitalisierungsworkflows in Bibliotheken und wissenschaftlichen
Einrichtungen
1. Dienstleister: Aufgabe der Text- und Struktur an außerhäusige, meist
kommerzielle Anbieter ausgelagert
2. standardisierte Workflows: In-house Digitalisierung unter Verwendung
allgemein verfügbarer Softwarelösungen
3. Eigenentwicklung: In-house Digitalisierung unter Verwendung
einrichtungsspezifischer Workflows (Software oder Kooperationen)4. Dissemination
37
Säule 1: Dienstleister4. Dissemination
38
Säule 2: Standardisierter, nachnutzbarer Workflow
● Kitodo als Zielarchitektur
○ quelloffen und architekturunabhängig
○ kompletter Digitalisierungsworkflow vom Buch über das Digitalisat bis zur LZA
● OCR-D liefert eine funktionierende OCR-Option für Kitodo
● »Kitodo. Key to digital objects« e.V. als unterstützendes Element für Verbreitung und
Akzeptanz4. Dissemination
39
Säule 3: Spezielle Digitalisierungsinfrastrukturen
● Veröffentlichung der OCR-D- sowie der Modulprojektergebnisse in einem Software-
Repositorium (GitHub)
○ Zentralisierung und Bündelung von Fehlermeldungen, Featurewünschen, Patches und
Funktionserweiterungen
● Potentieller Anwender auch außerhalb der Bibliothekslandschaft
● Transparente Entwicklung und offene KommunikationTestphase mit Pilotprojekten
● Testeinsatz in der Praxis in Pilotbibliotheken, die
○ mit Goobi/Kitodo digitalisieren (2. Säule)
○ mit eigenen Workflows digitalisieren (3. Säule)
○ mit den Materialien der VD16-18 vertraut sindDiskussionsrunde
OCR-D mitverfolgen
42
Ausprobieren: https://github.com/OCR-D/
Lernen: https://ocr-d.github.io
Mitreden: https://gitter.im/OCR-D/Lobby
Nachlesen: https://www.ocr-d.deFragen
43
● Haben Sie Erfahrungen mit neueren OCR-Werkzeugen auf Basis von neuronalen Netzen?
● Welche technischen Anforderungen sehen Sie bei der Volltextdigitalisierung von Beständen aus
dem 16. bis 18. Jahrhundert und deren Integration in den Bibliotheksalltag?
● Wie sehen Sie den Umgang mit der Granularität der Parameter für die OCR (spezifische
Modelle, Toolchains) während der Volltextdigitalisierung?Sie können auch lesen

















































