TÄTIGKEITSBERICHT 2020 - Institut für Medizinische Informatik, Statistik und Dokumentation
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
TÄTIGKEITSBERICHT 2020
Institut für Medizinische Informatik,
Statistik und Dokumentation
Vorstand: Univ.-Prof. Dipl.-Ing. Dr. Andrea Berghold
Auenbruggerplatz 2/V, 8036 Graz
imi@medunigraz.at
https://imi.medunigraz.at/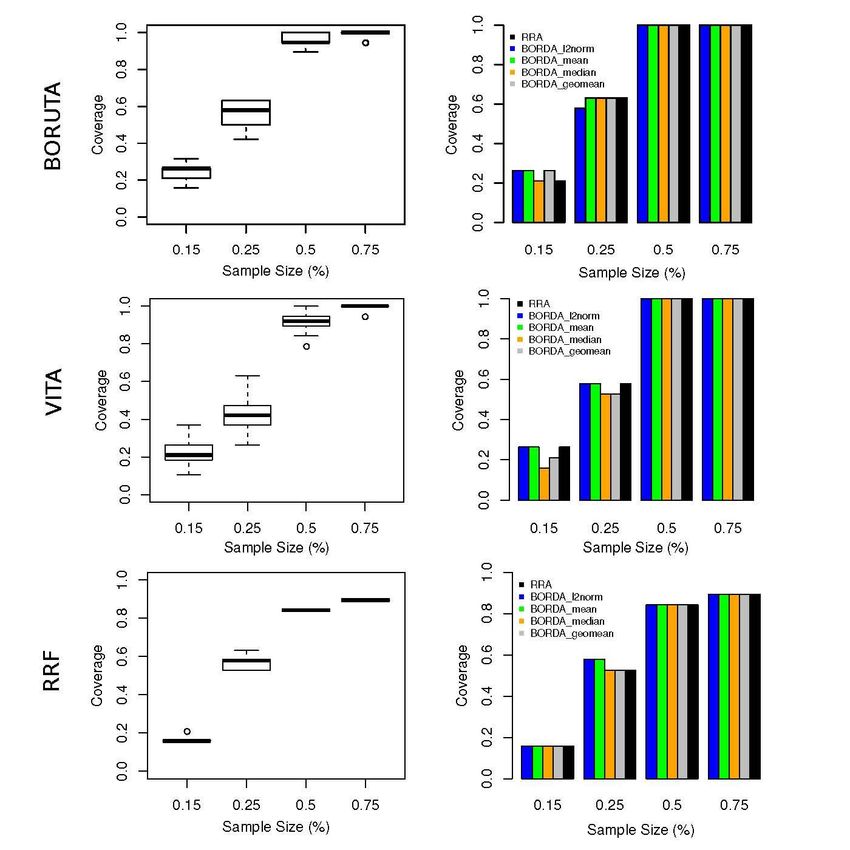
Inhaltsverzeichnis
1 Vorwort......................................................................... 1
2 Mitarbeiterinnen und Mitarbeiter .......................................... 2
3 Forschung ...................................................................... 4
3.1 Berichte aus den Forschungseinheiten ........................................... 4
3.2 Neue Forschungsschwerpunkte (UG §99(5)) .................................... 13
3.3 Projektberichte ..................................................................... 15
4 Lehre ......................................................................... 25
4.1 Diplomstudium Humanmedizin (O 202) ......................................... 25
4.2 Doktoratsstudium der Medizinischen Wissenschaften (O 202 790) und PhD-
Studium (O 094) .................................................................... 26
4.3 Masterstudium Pflegewissenschaft (O 331) ..................................... 27
4.4 Universitätslehrgänge.............................................................. 27
4.5 Abgeschlossene Diplomarbeiten und Dissertationen .......................... 28
4.6 Erweiterungsstudium „Digitalisierung in der Medizin“ ....................... 28
5 Datenmanagement für Forschung und Lehre ........................... 31
5.1 Auswertungen aus klinischen Informationssystemen .......................... 31
5.2 Datenmanagement für klinische Studien ....................................... 32
5.3 iMAGIC Multimediadatenbank .................................................... 33
6 Publikationen ................................................................ 34
6.1 Beiträge in Zeitschriften .......................................................... 34
6.2 Zitierfähige Beiträge zu wissenschaftlichen Veranstaltungen ............... 44
6.3 Herausgeberschaften von wissenschaftlichen Sammelwerken ............... 49
6.4 Originalbeiträge in wissenschaftlichen Sammelwerken ...................... 49
6.5 Sonstige Veröffentlichungen ...................................................... 50
7 Allgemeines .................................................................. 51
7.1 Mitgliedschaften / Expertentätigkeit ........................................... 51
7.2 Mitarbeit in Gremien............................................................... 55
1 Vorwort
2020 war ein sehr spezielles und intensives Jahr! Mit Beginn des ersten Lockdowns, am
16.3.2020, „sperrten wir das Institut zu“ und die Mitarbeiter*innen wurden ins Homeoffice
geschickt. Das führte zu sehr hektischen Tagen: Bereitstellung von erforderlichen Hilfsmit-
teln für die Arbeit von zu Hause aus, Umstellung der Kommunikation (Webex etc.), Online-
Lehre (da wir gerade mitten im Unterricht zu Modul PMXVII waren), viele Anfragen zu Pro-
jekten etc. Die großen organisatorischen und inhaltlichen Herausforderungen konnten je-
doch durch den guten Zusammenhalt im Team hervorragend gemeistert werden. Ab Mitte
Mai entspannte sich die Situation und wir „sperrten wieder auf“, alternierendes Homeoffice
war das Gebot bis Ende des Jahres. Einige Fixpunkte fielen leider aus, doch durch Hybrid-
Vollversammlungen bis hin zu Online-Kaffeetreffen wurde der Austausch und das Institutsle-
ben doch aufrechterhalten. Der Tätigkeitsbericht dokumentiert, dass trotz verschiedener
Widrigkeiten konsequent an neuen Projekten und der Weiterentwicklung bestehender Pro-
jekte gearbeitet wurde.
Im Bereich Lehre wurde im Frühjahr 2020 die Bitte an uns herangetragen, einen Studienplan
für das Erweiterungsstudium „Digitalisierung in der Medizin“ zu erarbeiten. Klaus-Martin
Simonic und ich machten uns sogleich an die Arbeit. Der Studienplan durchlief alle Gremien
und wurde noch vor dem Sommer beschlossen, mit dem ehrgeizigen Ziel einer Umsetzung im
WS 2020/21. Mit einigen Studierenden und viel Einsatz der Lehrenden, allen voran Klaus-
Martin Simonic, konnte dieses Ziel erreicht und das Erweiterungsstudium erfolgreich gestar-
tet werden.
Für das Institut sehr erfreulich ist, dass im Jahr 2020 zwei Tenure-Track-Assistenzprofessuren
(nach UG §99(5)) besetzt werden konnten. Im Bereich Biostatistik (Nachbesetzung von Mi-
chael G. Schimek) konnte Sereina Herzog gewonnen werden. Sie beschäftigt sich mit mathe-
matischen Modellen und Infektionskrankheiten. Bei der internen kompetitiven Ausschreibung
waren wir mit dem Konzept der Professur “Computational Semantics for Health” erfolgreich.
Der Schwerpunkt dieser Professur liegt in der Anwendung von Methoden des maschinellen
Lernens zur nicht-symbolischen Repräsentation von medizinischen Inhalten, mit dem Ziel,
die Extraktion relevanter Information aus heterogenen Klinikdaten zu verbessern. Für diese
Stelle konnte sich Markus Kreuzthaler qualifizieren. Beide stellen ihre Forschungsschwer-
punkte im Tätigkeitsbericht kurz vor.
Auch sonst hat sich personell einiges getan: Andrea Borenich und Gudrun Pregartner sind in
Mutterschutz/Karenz gegangen. Wir gratulieren beiden ganz herzlich zur Geburt ihrer Töch-
ter. Michael G. Schimek hat sich in den (Un-)Ruhestand verabschiedet. Drei Gastforscher —
Michel Oleynik, Luca Vitale und Pablo López García — haben uns im Laufe des Jahres wieder
verlassen; Marko Stijic, Simone Findling und die studentischen Mitarbeiter*innen Buchegger,
Grassauer, Schneeberger und Schneider sind zum Team gestoßen.
Ich möchte mich bei allen Mitarbeiter*innen für ihren Einsatz und ihr Engagement sehr herz-
lich bedanken. Ihr seid ein tolles Team! Mein Dank gilt auch unseren Kooperationspartner*in-
nen für die durchgehend gute Zusammenarbeit.
Univ.-Prof. Dipl.-Ing. Dr. Andrea Berghold
Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2020 Seite 1 von 55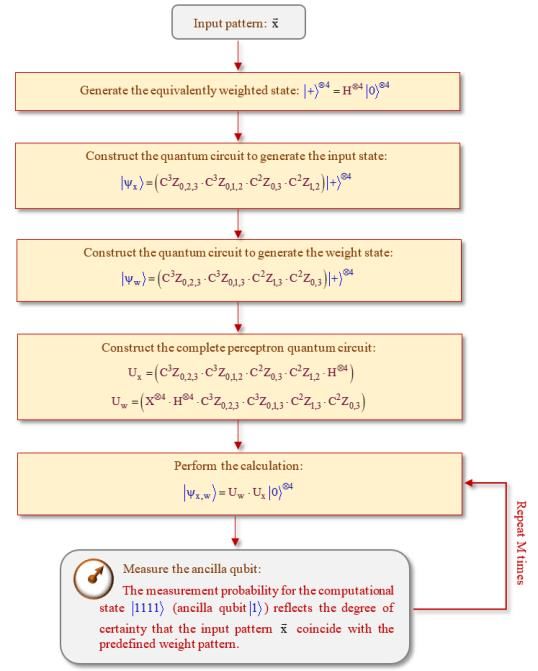
2 Mitarbeiterinnen und Mitarbeiter
E-Mail: vorname.nachname@medunigraz.at
Name Telefon
+43.316.385-
Dipl.-Ing. Siegfried ACKERL 17875
PD Mag. Dr. Alexander AVIAN 17873
Mag. Dr. Gerhard BACHMAIER 12688
Univ.-Ass. Dr. Chiara BANFI 13205
Kathrin BENEDIKT (bis 06.01.2020) -
Univ.-Prof. Dipl.-Ing. Dr. Andrea BERGHOLD 13201
Marcus BLOICE, BSc MSc 13589
Dipl.-Ing. Andrea BORENICH, MSc (karenziert ab 24.06.2020) -
Cornelia BUCHEGGER (Studentische Mitarbeiterin ab 01.10.2020) -
Andreas DORN, BSc MSc 17879
Dipl.-Ing. Dr. Maximilian ERRATH 81828
Simone FINDLING, BSc (ab 03.08.2020) 31383
Univ.-Prof. Dr. Günther GELL (emeritiert) -
Lukas GRASSAUER (Studentischer Mitarbeiter ab 08.06.2020) -
ao. Univ.-Prof. i.R. Dipl.-Ing. Dr. Josef HAAS 83477
Manuela HAID 84518
Larissa HAMMER (Studentische Mitarbeiterin) -
David HASHEMIAN NIK (Studentischer Mitarbeiter) -
Ass.-Prof. PD Sereina Annik HERZOG, MSc PhD (ab 30.12.2020) 14263
Dipl.-Ing. Dr. Edith HOFER 80245
Magdalena HOLTER, BSc MSc 13203
Univ.-Doz. Ing. Mag. Mag. Dr. Andreas HOLZINGER 13883
Dr. Klaus JEITLER 77556
Ing. Andreas KAINZ 81374
Dipl.-Ing. Dr. Markus KREUZTHALER 13591
Gabriele KRÖLL 12980
Pablo LÓPEZ GARCÍA, MSc PhD (Gastforscher bis 30.09.2020) -
Dipl.-Ing. Bernd MALLE (Projektmitarbeiter ab 13.07.2020) -
Astrid MANDL-POHL 17886
Bettina MASAREI 12512
Annemarie NUSSMÜLLER 12980
Mag. Dr. Petra OFNER-KOPEINIG 13588
Michel OLEYNIK, MSc (Gastforscher bis 31.08.2020) -
Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2020 Seite 2 von 55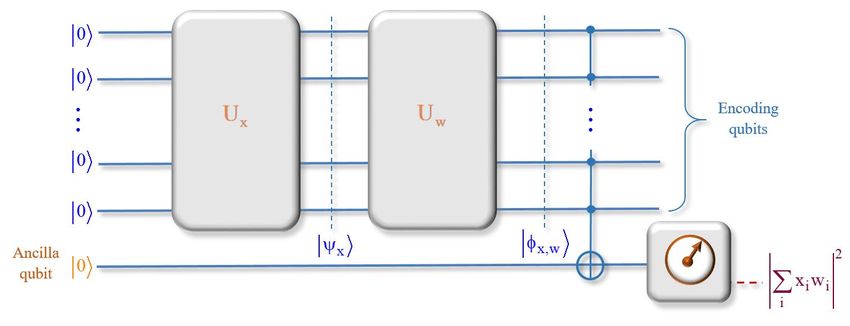
Name Telefon
+43.316.385-
Dr. Bastian PFEIFER 17889
Rudolf PITZLER 83585
Dipl.-Ing. Gudrun PREGARTNER (karenziert ab 17.12.2020) -
Mag. Dr. Franz QUEHENBERGER 17872
Astrid REICHER 83201
Dipl.-Ing. Dr. Regina RIEDL 17874
Dipl.-Ing. Anna SARANTI 17988
Univ.-Prof. Mag. Dr. Dr. Michael G. SCHIMEK, MPhil (Univ. Bath) 14263
Andrea SCHLEMMER 84716
Dipl.-Ing. Erich SCHMIEDBERGER 17876
Mag. David SCHNEEBERGER, BA MA (Studentischer Mitarbeiter ab
-
02.06.2020)
Michaela SCHNEIDER (Studentische Mitarbeiterin ab 03.02.2020) -
Univ.-Prof. Dr. Stefan SCHULZ 16939
Mag. Gerold SCHWANTZER 17867
Stephanie SIMON -
Ass.-Prof. Dipl.-Ing. Dr. Klaus-Martin SIMONIC 13206
Deepika SINGH, PhD -
Univ.-Prof. Dr. Josef SMOLLE 83588
Marko STIJIC, BSc MSc (Projektmitarbeiter ab 15.10.2020) -
Brigitte STROBL 83201
Jose Antonio VERA RAMOS, BSc MSc 17889
Luca VITALE, MSc (Gastforscher bis 30.07.2020) -
Stefan VOGTBERG 14262
Univ.-Prof. Mag. Dr. Marco WILTGEN 13587
Mag. Dr. Gerit WÜNSCH 86939
Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2020 Seite 3 von 55
3 Forschung
3.1 Berichte aus den Forschungseinheiten
3.1.1 „Human-Computer Interaction for Medicine & Health Care” (HCI4MED)
A. Holzinger
Der Fokus des Forschungsteams Holzinger liegt auf der Nachvollziehbarkeit, der Erklärbarkeit
und Interpretierbarkeit maschineller Lernmethoden. Es wird an mehreren Projekten gear-
beitet. Künstliche Intelligenz (KI) ist derzeit bemerkenswert erfolgreich und übertrifft bei
gewissen Klassifikationsaufgaben in der Medizin sogar die menschliche Performanz. Die Kom-
plexität solcher Ansätze macht es allerdings schwierig bis unmöglich, nachzuvollziehen, wa-
rum ein Algorithmus zu einem bestimmten Ergebnis gekommen ist.
Andreas Holzinger hat mit seinem „Human-in-the-Loop“-Ansatz zu diesem Themenfeld in-
ternational anerkannte Pionierarbeit geleistet, wofür er in die Academia Europea der Euro-
päischen Akademie der Wissenschaften in die Sektion Informatik aufgenommen wurde und
kürzlich als ordentliches Mitglied in das European Laboratory for Learning and Intelligent
Systems.
Der „Human-in-the-Loop“, also menschliche Expert*innen, können manchmal (natürlich
nicht immer) Erfahrung, kontextuelles Verständnis, implizites und konzeptionelles Wissen
einbringen. Die Verwendung von konzeptionellem Wissen als Leitmodell der Realität soll da-
bei mithelfen, robustere maschinelle Lernmodelle zu entwickeln, die idealerweise aus we-
niger Daten lernen können.
Das Forschungsteam Holzinger ist intern mit dem Forschungsteam Müller des Diagnostik- &
Forschungsinstituts für Pathologie vernetzt und international mit dem xAI-Lab des Alberta
Machine Intelligence Institute, Edmonton, Canada, dem Life Sciences Discovery Center
Toronto in Canada und dem Human-Centered AI Lab an der University of Technology, Sydney,
Australien.
Die drei wichtigsten Projekte:
3.1.1.1 EXPLAINABLE-AI
Das FWF Forschungsprojekt P-32554 "Ein Referenzmodell erklärbarer Künstlicher Intelligenz
(KI) für die Medizin" arbeitet an grundlegenden Fragestellungen, z.B. warum KI manche Auf-
gaben besser lösen kann als menschliche Expert*innen, wie KI zu den Ergebnissen gekommen
ist, und was passiert, wenn Eingabedaten kontrafaktisch verändert werden. Dazu werden
Methoden, Erklärungsmuster und Qualitätskriterien für Erklärbarkeit und kausales Verständ-
nis von Erklärungen entwickelt. Bis dato wurden erfolgreich die folgenden Beiträge geleistet:
a) Die Entwicklung einer experimentellen Testumgebung zur Erzeugung von mathematisch
kontrollierbaren synthetischen Datenmengen, welche zur gleichen Zeit auch für Menschen
erkennbar und erklärbar sind. Dadurch können kontrollierte Muster sowohl von Menschen als
auch von Lernalgorithmen beschrieben werden und damit elementare Beiträge zum Ver-
ständnis, zum Testen, zur Evaluierung und zur Weiterentwicklung von Explainable-AI-
Algorithmen gewonnen werden.
Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2020 Seite 4 von 55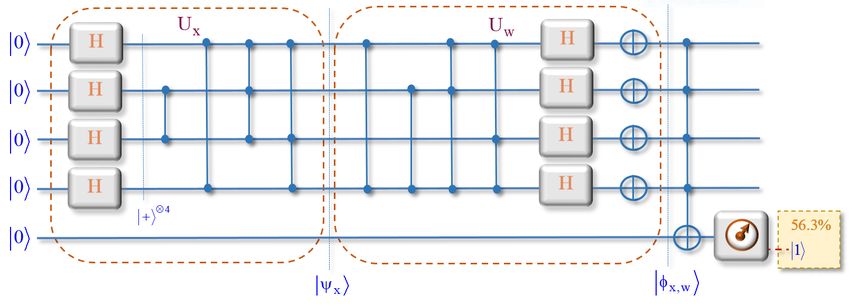
b) Die Entwicklung des Causability-Konzeptes. Der Name Causability wurde in Anlehnung an den etablierten Begriff Usability eingeführt. Während es bei dem Konzept der Erklärbarkeit im Sinne der internationalen Forschergemeinde der explainable AI (xAI) um die Umsetzung von Transparenz und Nachvollziehbarkeit geht, geht es bei Causability um die Messung der Qualität von Erklärungen. „Explainable AI“ hebt technisch entscheidungsrelevante Teile in maschinellen Lernmodellen hervor, d.h. Teile, die zur Modellgenauigkeit im Training oder zu einer bestimmten Vorhersage beigetragen haben. Diese bezieht sich jedoch nicht auf ein menschliches Modell. Causability (auf Deutsch am besten übersetzt mit „Ursachenerkenn- barkeit”) ist das messbare Ausmaß, in dem eine Erklärung einer Aussage für einen Benutzer (das menschliche Modell!) ein spezifiziertes Niveau eines kausalen Verständnisses mit Effek- tivität, Effizienz und Zufriedenheit in einem spezifizierten Nutzungskontext erreicht. Dieses Konzept bezieht sich also auf ein menschliches Modell und kann daher wichtige Erkenntnisse zur Entwicklung neuer Mensch-KI-Schnittstellen liefern, welche ein kontextuelles Verständ- nis ermöglichen und es den Domänenexpert*innen erlauben, Fragen und sogenannte „Was- wäre-wenn-Fragen“ (Counterfactuals) zu stellen. Hier schließt sich der Kreis, denn dies un- terstützt idealerweise wieder die Einbindung eines „Human-in-the-Loop“. Die theoretisch gewonnenen Einsichten aus diesem Grundlagenforschungsprojekt werden im EMPAIA-Projekt experimentell am Beispiel der Histopathologie angewandt. 3.1.1.2 FEATURE CLOUD Im Rahmen des EU-RIA-Projekts 826078 "Privacy preserving federated machine learning". Das Ziel des föderierten maschinellen Lernens ist es, nur gelernte Merkmals-Repräsentationen (also die Features Theta – von daher kommt der Projektname) auszutauschen. Das bedeu- tet, dass keine lokalen Daten den Ursprungsort verlassen, d.h. eben nicht an zentrale Server wie derzeit üblich übergeben werden müssen. Innerhalb dieses Projekts arbeitet das For- schungsteam Holzinger insbesondere an der Fragestellung, wie ein multimodaler Merkmals- repräsentationsraum aufgebaut werden kann. Das ist für die Medizin relevant, denn hier tragen verschiedenste Modalitäten zu einem einzigen Ergebnis bei. Die Prämisse bei dieser Entwicklung ist, dass neue Ansätze den beiden Anforderungen Robustheit und Erklärbarkeit genügen müssen, wo sich die Erfahrung in Graph-basierten Techniken bezahlt macht und der Einsatz neuartiger Graphen-basierter Neuronaler Netzwerken sehr vielversprechend ist, weil diese Ansätze es erlauben, kausale Verbindungen zwischen einzelnen Merkmalen direkt über Graphen-Strukturen zu definieren. 3.1.1.3 EMPAIA Im FFG-Projekt "Ökosystem für die Pathologiediagnostik mit KI-Unterstützung", dem öster- reichischen Schwesterprojekt der deutschen KI-Plattform www.empaia.org, arbeitet das Forschungsteam Holzinger gemeinsam mit dem Forschungsteam Müller an praktischen Ansät- zen, maschinelle Entscheidungen in der digitalen Pathologie transparent, rückverfolgbar und damit für medizinische Expert*innen interpretierbar zu machen, mit dem Ziel, neuartige Mensch-KI-Schnittstellen zu entwickeln, die von medizinischen Expert*innen trainiert wer- den können, um die zugrundeliegenden Prinzipien verständlich zu machen. Diese Beiträge sind wichtig, um zukünftig die Zuverlässigkeit, Verantwortlichkeit, Fairness und das Ver- trauen in die KI zu verbessern. Derzeit erfolgt der Aufbau eines sogenannten Causability-Labors, in dem die theoretischen Erkenntnisse, die im FWF-Grundlagenforschungsprojekt „Explainable AI“ gewonnen werden, in der Praxis erprobt werden und zur Entwicklung neuartiger Mensch-KI-Interfaces beitragen. Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2020 Seite 5 von 55

3.1.2 „EBM (Evidence based Medicine) Review Center”
K. Jeitler
Im berichtsrelevanten Zeitraum 2020 bestand wieder eine enge Kooperation der Research
Unit „Evidence based Medicine Review Center“ mit dem Institut für Allgemeinmedizin und
evidenzbasierte Versorgungsforschung. Beide Einrichtungen sind von Beginn an in die Erstel-
lung und Aktualisierung von insgesamt sechs bei der Cochrane Collaboration veröffentlich-
tern systematischen Übersichten eingebunden. Sie alle befassen sich mit internistischen The-
men, konkret aus den Bereichen Hypertonie und Diabetes mellitus. Dabei geht es einerseits
um die Effekte von gewichtsreduzierenden Diäten bzw. Medikamenten auf einen erhöhten
Blutdruck, andererseits wird für Diabetes mellitus untersucht, welche Effekte bei einer in-
tensivierten Blutzuckersenkung bei Typ-1-Diabetes zu beobachten sind, wie sich kurzwirk-
same Insulinanaloga bei Typ-1- oder Typ-2-Diabetes auswirken und welche Effekte langwirk-
same Insulinanaloga bei Typ-2-Diabetes aufweisen.
Das Cochrane Review zum letztgenannten Thema musste 2020 dringend aktualisiert werden,
nicht nur, weil die letzte Aktualisierung schon einige Jahre zurücklag und seither neue Stu-
dien veröffentlicht worden waren, sondern auch, weil zwischenzeitlich ein neues, ultralang
wirkendes Insulin-Analogon auf den Markt gekommen war.
Insulinanaloga sind dem menschlichen Insulin ähnliche Proteine, die künstlich verändert wur-
den, um eine raschere (kurzwirksame Insulinanaloge) oder verzögerte (langwirksame Insuli-
nanaloga) blutzuckersenkende Wirkung zu entfalten. Sie sollen bei Diabetespatient*innen
eine bessere Blutzuckereinstellung ermöglichen und so einerseits zu einer Verringerung von
Folgeschäden dieser Erkrankung beitragen, andererseits aber auch weniger Nebenwirkungen
der Therapie (in erster Linie Unterzuckerungen) aufweisen.
Das Cochrane Review untersucht dabei bei Patient*innen mit Typ-2-Diabetes, inwieweit sich
Wirksamkeit und Sicherheit von (ultra-)lang wirksamen Insulinanaloga von jener eines klas-
sischen Insulins unterscheiden, also von menschlichem Insulin, dessen Wirkung dadurch ver-
zögert wird, dass es an ein spezielles Protein (NPH) gebunden ist. Von Interesse sind dabei
die Unterschiede bei sog. patient*innenrelevanten Endpunkten, beispielsweise Tod, diabe-
tesbedingte Folgeerkrankungen wie kardiovaskuläre Ereignisse oder Nierenversagen, Augen-
schäden, Unterzuckerungen infolge der Therapie oder die gesundheitsbezogene Lebensqua-
lität der Patient*innen.
Die Datenbank-Recherche nach möglichen neuen Studien erfolgte dieses Mal zum Teil direkt
durch die Cochrane Metabolic and Endocrine Disorders Group, eine von acht Gruppen, die
bei der Cochrane Collaboration die Erstellung von Reviews begleiten und deren hohe Qualität
sicherstellen. Gesucht wurde in bibliografischen Datenbanken wie MEDLINE, Embase und den
Cochrane Libraries, aber auch in Studienregistern und über Handsuche in weiteren Quellen.
Eine Herausforderung bestand nun darin, die Treffer aus den verschiedenen Recherchen mit-
einander abzugleichen, ebenso mit allen Treffern aus früheren Recherchen. Ziel dabei war
es, im Sinne eines ressourcenschonenden Vorgehens möglichst alle Duplikate und alle Treffer
auszuschließen, die bereits im Rahmen eines früheren Update-Prozesses schon einmal be-
gutachtet wurden, was nicht immer trivial ist.
Im ersten Screeningschritt mussten etwa 2.200 neue Titeln und Abstracts von Publikationen
gesichtet werden, ebenso zirka 1.500 Einträge aus Studienregistern sowie einzelne weitere
Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2020 Seite 6 von 55Treffer aus der Handsuche. In der Folge mussten im zweiten Screeningschritt 30 Studienre- gistereinträge eingehender geprüft bzw. 69 Publikationen auf Volltextebene auf ihre Rele- vanz für das Review durchgesehen werden. Beide Screeningschritte wurden jeweils durch zwei Personen unabhängig voneinander durchgeführt und danach abgeglichen. Unterschied- liche Bewertungen wurden durch Diskussion oder gegebenenfalls durch Hinzuziehen einer dritten Person aufgelöst. Hauptgründe für einen Ausschluss waren, dass es sich bei den Studien entweder nicht um randomisierte kontrollierte Studien handelte, diese mit einer Beobachtungszeit von unter einem halben Jahr zu kurz waren oder dass die darin verglichenen Interventionen in den Studiengruppen nicht den Einschlusskriterien des Reviews entsprachen, also nicht ein lang- wirksames Insulinanalogon mit dem klassischen langwirksamen NPH-Insulin verglichen wurde. Durch das Update konnten schließlich 16 neue Studien identifiziert werden, sodass die aktu- elle Version des Cochrane Reviews nun insgesamt 24 Studien umfasst: 16 davon untersuchen das langwirksame Insulinanalogon Glargine und acht das Insulinanalogon Detemir. Damit er- höht sich auch die Zahl der Studienteilnehmer*innen insgesamt auf mehr als das Doppelte im Vergleich zur bisherigen Fassung des Cochrane Reviews, sodass in den aktuellen Analysen gut 3.400 Personen mit Glargine-Behandlung und etwa 1.300 mit Detemir eingeschlossen werden konnten. Zu den neueren, ultralang wirksamen Insulinanaloga Degludec und Glargine U300 gab es lei- der keine Studien, in denen diese gegen das herkömmliche NPH-Insulin verglichen wurden, sodass auch keine entsprechenden Studien im Review berücksichtigt werden konnten. Alle eingeschlossenen Studien mussten einer Qualitätsbewertung unterzogen werden, die wiederum von zwei Forscher*innen unabhängig voneinander durchgeführt wurde. Hierbei geht es darum, das Verzerrungpotenzial der einzelnen Studien und der darin erhobenen End- punkte jeweils als gering, hoch oder unklar einzustufen. Dazu gibt es im Handbuch der Cochrane Collaboration zur Erstellung von Systematischen Übersichten vorgegebene Bewer- tungskriterien, unter anderem zur Randomisierung, Gruppenzuteilung, zu Verblindungsas- pekten, Vollständigkeit der ausgewerteten Daten bzw. zum Umgang mit fehlenden Daten sowie zu weiteren Aspekten. Diese Bewertung wird am Ende in der Beurteilung der Vertrau- enswürdigkeit der Evidenz berücksichtigt. Die Cochrane Collaboration stellt für die Erstellung und Pflege der systematischen Übersich- ten eine eigene Software bereit – den Review Manager (RevMan). Damit werden nicht nur die Textteile erstellt, sondern auch die Studiencharakteristika einschließlich Qualitätsbe- wertung und Studiendaten erfasst. Darüber hinaus ist auch eine Software inkludiert, mit der Metaanalysen gerechnet und grafisch dargestellt werden können. Alle relevanten Studienergebnisse wurden zunächst von einer Person in Tabellen extrahiert und von einer zweiten Person kontrolliert. Die Daten wurden für die statistische Auswertung aufbereitet und einerseits intern besprochen, mussten andererseits aber auch noch mit der betreuenden Review-Gruppe der Cochrane Collaboration diskutiert und abgestimmt werden. Ziel ist immer, nach Möglichkeit auch Metaanalysen durchzuführen. Schließlich wurden am Ende des Erstellungsprozesses Überblickstabellen zu den Ergebnissen (sog. Summary-of-findings-Tabellen) angefertigt. Darin wird für jeden relevanten Endpunkt Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2020 Seite 7 von 55
die gesamte eingeschlossene Evidenz betrachtet und die Vertrauenswürdigkeit der Ergeb- nisse bewertet. Es handelt sich im Prinzip um eine Einschätzung, wie robust die Ergebnisse sind und wie groß die Wahrscheinlichkeit ist, dass weitere Studienergebnisse ein Ergebnis noch ändern können. Für diese Einschätzung wurde das GRADE-Instrument verwendet. Aus- gehend von der Art der zugrundeliegenden Studien (RCT, systematische Übersicht, Beobach- tungsstudie, etc.) fließen hierbei auch Aspekte wie die zuvor bewerteten Verzerrungspoten- ziale, die Heterogenität der Studienergebnisse, die Übertragbarkeit (Direktheit), Effektgrö- ßen und anderes in die Gesamtbewertung mit ein. Die wesentlichen Ergebnisse aus dem aktualisierten Cochrane Review lassen sich wie folgt zusammenfassen. Die untersuchten langwirksamen Insulinanaloga zeigen eine vergleichbar gute Blutzuckersenkung wie NPH-Insulin, führten in den Studien dabei aber seltener zu Un- terzuckerungen. Hinsichtlich schwerwiegender Unterzuckerungen zeigte sich, dass diese un- ter Insulin Detemir seltener vorkamen. Informationen zu diabetesbedingten Komplikationen (wie Herz-, Nierenerkrankungen, Schäden an der Netzhaut der Augen und Amputationen), Tod und gesundheitsbezogene Lebensqualität waren nur spärlich vorhanden und ließen ins- gesamt keine klaren Unterschiede zwischen Insulinanaloga und NPH-Insulin erkennen. Auch hinsichtlich Nebenwirkungen der Insulintherapie und Gewichtszunahmen zeigten sich keine klaren Unterschiede. Die Publikation wurde im November 2020 mit dem Titel „(Ultra-)long-acting insulin ana- logues versus NPH insulin (human isophane insulin) for adults with type 2 diabetes mellitus“ in der Cochrane Library veröffentlicht1. Während der Einschluss von zusätzlichen Studien und damit auch von mehr Patient*innen in die Analysen die Ergebnisse insgesamt robuster macht, muss man sich am Ende immer auch die Frage stellen, inwieweit die Studienergebnisse auf die Versorgungsrealität im Alltag übertragbar sind. Die eher niedrigen Blutzucker- und HbA1c-Zielwerte in den Studien werden heute von Ärzt*innen nicht zuletzt auch aufgrund der aktuellen Empfehlungen in Leitlinien nicht allen Patient*innen empfohlen. Dies gilt vor allem für ältere Personen mit einer langen Vorge- schichte von Typ-2-Diabetes, die beispielsweise einen Herzinfarkt oder Schlaganfall haben. Indem bei höheren Blutzuckerzielwerten Unterzuckerungen seltener auftreten, sind die Stu- dienergebnisse auf diese Personengruppe nur bedingt übertragbar. In vielen Studien ließ das Protokoll außerdem keine optimale Dosisanpassung für NPH-Insulin an sein spezielles Wirkungsprofil zu, sodass der tatsächliche Nutzen von langwirksamen In- sulinanaloga geringer ausfallen könnte. 1 https://doi.org/10.1002/14651858.CD005613.pub4 Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2020 Seite 8 von 55
3.1.3 „Statistische Bioinformatik“ (StatBI)
M.G. Schimek
Die Forschungseinheit "Statistische Bioinformatik" wird von Herrn Univ.-Prof. Dr. Dr. Michael
G. Schimek geleitet. Sie ist an der Schnittstelle zwischen Biostatistik und Bioinformatik an-
gesiedelt. Als Teil eines weltweiten akademischen Netzwerkes arbeitet sie eng mit medizi-
nischen und biowissenschaftlichen Forscher*innen zusammen.
Ein spezieller Arbeitsschwerpunkt liegt auf Methoden der statistischen Integration von
"omics"-Daten sowie auch von anderen klinisch relevanten Daten. In letzter Zeit wird hierfür
auch die Bezeichnung „data fusion technology“ verwendet. Neuesten internationalen Ent-
wicklungen Rechnung tragend, ist ein weiterer Arbeitsschwerpunkt „Data Science“ in den
medizinisch-biologischen Wissenschaften. Hierbei geht es nicht nur um die Verarbeitung gro-
ßer komplexer Datenmengen, sondern auch um die Verknüpfung statistischer Methoden mit
Verfahren des maschinellen Lernens und der mathematischen Optimierung. Jedes der neuen
Projekte steht im Kontext dieses interdisziplinären Ansatzes. Die aktuellen Projekte an der
Forschungseinheit StatBI wurden gemeinsam mit dem Bioinformatiker Dr. Bastian Pfeifer und
dem Gastforscher bzw. PhD-Kandidaten Luca Vitale (dieser wurde über ein European Docto-
rate Label-Programm finanziert) durchgeführt. Mit Ende Juni 2020 verließ Luca Vitale Graz
und ging zurück an seine Universität in Salerno (Italien), wo er seine Dissertation „Large
Scale Statistical Learning“ im Kontext des StatBI-Projektes weiterführte.
An der Forschungseinheit StatBI gibt es eine lange Tradition der Forschung und Anwendung
von rangbasierten statistischen Verfahren, bei denen eine festgelegte Anzahl von Objekten
(z.B. die Expression von Genen in einer genomischen Studie) nicht mittels numerischer
Werte, sondern mittels Rangpositionen charakterisiert werden. Das bietet viele Vorteile,
insbesondere, wenn Messskalen unbestimmt oder heterogen sind. Derartige Überlegungen
spielen aber auch in anderen Bereichen der angewandten Forschung eine Rolle. Das Projekt
„Stabilizing Random Forest based All-Relevant Feature Ranks using Consensus Signals“ ist ein
Beispiel dafür.
Die Motivation für das genannte, gemeinsam mit Dr. Bastian Pfeifer durchgeführte Projekt
ist folgende: aus computertechnischen oder mathematischen Gründen gibt es häufig Ein-
schränkungen bei der analytischen Lösbarkeit von (Un-)Gleichungssystemen. Das können so-
genannte NP-schwere Probleme sein, aber auch andere numerische Einschränkungen führen
zu vergleichbaren Problemen, die man mit herkömmlicher – auch noch so leistungsfähiger –
Computerarchitektur nicht bearbeiten kann. In jüngster Zeit ist man zunehmend mit hoch-
dimensionalen Datensätzen konfrontiert. Sie entstehen beispielsweise bei der statistischen
oder maschinellen Zusammenführung (Integration) von genomischen mit klinischen Pati-
ent*innendaten, insbesondere, wenn unterschiedliche Entitäten von Labordaten verknüpft
werden sollen. Aber nicht nur die Hochdimensionalität solcher Daten wirft Probleme auf.
Die große Anzahl der beteiligten Variablen (in der Statistik) oder Features (im maschinellen
Lernen) muss derart reduziert werden, dass nur informative, möglichst unkorrelierte Vari-
ablen oder Features in das zu lösende Schätzproblem (z.B. einer Regressionsanalyse) einge-
hen. Ein technisch gangbarer, häufig gewählter Weg, eine fehlende analytische Lösungsmög-
lichkeit zu substituieren, sind stochastische (nicht-deterministische) Verfahren. Man kann
Lösungen erhalten, allerdings um den Preis einer, wenn auch geringfügigen, Kontamination
mit Zufallseinflüssen. In der Praxis hat das zur Folge, dass für ein und denselben Datensatz
der verwendete Algorithmus unterschiedliche Lösungen liefert. Einzelne können auch we-
sentlich von der Menge der typischen Lösungen abweichen, bleiben jedoch unerkannt. Die
Variablen- oder Featureselektion mittels stochastischer Algorithmen ist davon betroffen.
Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2020 Seite 9 von 55Eine solche Selektion ist im Regelfall nur ein erster Schritt in einer komplexen, darauf auf-
bauenden Datenanalyse. Das hier genannte Projekt hatte das Ziel, weit verbreitete stochas-
tische Selektionsverfahren auf ihre Lösungsstabilität zu untersuchen und eine Methode zu
entwickeln, die solche Lösungen stabilisieren kann. Hierzu wurden Konzepte der rangbasier-
ten Statistik zum Einsatz gebracht. Im Detail wurden folgende Verfahren zu Variablen- oder
Featureselektion untersucht: RRF, VITA und BORUTA. Für die Rangaggregation zur Verbesse-
rung der Coverage (i.e. Erfassungsgrad der Auswahl relevanter Variablen) wurden mehrere
traditionelle Boruta-Varianten und das moderne Verfahren der Robust Rank Aggregation ein-
gesetzt. Die untenstehende Graphik zeigt die erzielte Coverage für die drei stochastischen
Selektionsverfahren in Abhängigkeit von der Ausschöpfung in Prozenten des Trainingssamp-
les. Ab 50 % Ausschöpfung sind bei BORUTA und VITA die Ergebnisse, unabhängig vom Ran-
gaggregationsverfahren, sehr zufriedenstellend, nicht jedoch bei RRF, für das die Coverage
nicht an den notwendigen Wert von Eins herankommt. Detailuntersuchungen zeigten, dass
die Lösungsschwankungen von BORUTA und VITA gut durch den vorgeschlagenen rangbasier-
ten Ansatz abgefedert werden können.
Abb. 1: Coverage für die drei stochastischen Selektionsverfahren RRF, VITA und BORUTA.
Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2020 Seite 10 von 55Ein weiteres, langfristig laufendes Projekt hat den Titel „Estimation of the Latent Signals for Consensus Across Multiple Ranked Lists using Convex Optimization“. Im Rahmen dieses Pro- jektes war als Gastforscher Luca Vitale, neben Dr. Bastian Pfeifer, tätig. Ziel dieses Projek- tes ist die Schätzung jener unbeobachtbaren (latenten) statistischen Parameter, die für das Ranking von vorgegebenen Objekten nach Relevanz durch rangzuweisende Instanzen (z.B. durch Expert*innen oder durch Maschinen) verantwortlich sind. Eine typische Anwendung in der Bioinformatik wäre die Integration von Daten mehrerer Sequencing-Plattformen, die Pro- ben, die unter vergleichbaren diagnostischen Kriterien erzeugt wurden, verarbeiten. Ergeb- nis wäre die Rekonstruktion der molekularbiologischen Signale, die den nach Expressions- wertigkeit gereihten Genen zugrunde liegen. Diese Signale können therapeutische Hinweise zu unterschiedlichen Krankheitsverläufen, z.B. bei Krebs, geben. Eine weitere interessante zukünftige Anwendung wäre die Konsolidierung von Resultaten aus stochastischen Algorith- men (vergleiche das oben beschriebene Projekt). Eine Schätzmethode auf der Basis latenter Signale anstelle von Rangaggregationsverfahren könnte die Coverage von Variablen- bzw. Featureselektionsverfahren, die zufallsgesteuerte Operationen umfassen, weiter verbes- sern. Das wäre zum großen Vorteil von Ansätzen in der personalisierten Medizin, unabhängig davon, ob statistische Algorithmen oder maschinelle Lernalgorithmen zum Einsatz kommen, weil man zum Beispiel Fehlklassifikationen deutlich reduzieren könnte. In diesem Projekt konnten 2020 deutliche Verbesserungen bei der numerischen Effizienz er- reicht werden. Ziel ist es ja, im Kontext der aktuellen Data-Science-Diskussion Problemlö- sungen zu erarbeiten. Hierbei liegt der Fokus auf enorm großen Datenmengen und sogenann- ten p-wesentlich-größer-n-Problemen (p sei Anzahl der Variablen und n die Samplegröße). Schon 2019 konnte ein Weg gefunden werden, der das aufwändige stochastische Markov- Chain-Monte-Carlo-Verfahren (frühere Dissertation von Mag. Dr. Vendula Svendova an der StatBI) durch ein numerisch wesentlich günstigeres konvexes Optimierungsverfahren ersetzt. Um jedoch vollständige Genomdatensätze analysieren zu können, mussten weitere rechen- technische Einsparungen erzielt werden. Das ist einerseits durch eine neue Repräsentation der Ordnungsrelationen zwischen den ranggereihten Objekten gelungen und andererseits durch den Einsatz des bisher kaum bekannten Poisson-Bootstrap-Verfahrens. Die Kombina- tion dieser beiden Konzepte ermöglichte erst, das ehrgeizige Ziel der Einsparung von Re- chenzeit zu erreichen. Nunmehr sind für die Schätzung der latenten Signale, aber auch der notwendigen diagnostischen Tools, wesentlich weniger Bedingungen in der mathematischen Optimierung und ausschließlich Diagonalmatrizen involviert. Ein weiteres Tätigkeitsfeld der Forschungseinheit StatBI sind Methoden zur Analyse von Da- ten blutzirkulierender DNA (ctDNA), die einen wichtigen Beitrag zur Krebsforschung leisten. Im Jahr 2020 wurde hierzu folgende Dissertation von Isaac Lazzeri, MSc, durch Prof. Schimek aus biostatistischer und bioinformatischer Sicht betreut: “Early detection of cancer from liquid biopsy”. Diese beschäftigt sich mit Methoden für die Integration genomischer Daten unterschiedlicher Entitäten. Der Fokus liegt auf einer speziellen Technik des maschinellen Lernens, genannt Autoencoder. Autoencoder gehören der Familie der künstlichen neurona- len Netze an und erlauben unüberwachtes Lernen („unsupervised learning“). Ziel ist eine komprimierte Repräsentation von komplexen Daten unter gleichzeitiger Extraktion wesent- licher Merkmale. Das ist technisch gesehen eine Dimensionsreduktionsaufgabe unter weitge- hender Ausschaltung des Noise-Einflusses in den Daten. Dieser Ansatz soll auch eine verbes- serte Integration von multiomics-Daten, verglichen mit etablierten statistischen Verfahren wie jenes der Hauptkomponentenanalyse (nur unter Einsatz linearer Neuronen vergleichbar), ermöglichen. Eine endgültige vergleichende Bewertung bei der Anwendung auf reale Daten steht noch aus. Die bislang erzielten Ergebnisse mit künstlichen Daten lassen sich nicht un- mittelbar auf medizinische Aufgabenstellungen übertragen. Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2020 Seite 11 von 55
Von der Forschungseinheit StatBI werden seit Jahren Open-Source-Softwaretools in R (kom- patibel mit dem Bioconductor-Projekt) für neue statistische Verfahren, Optimierungs- und Lerntechniken entwickelt. Das Software-Paket TopKLists2 ist seit Jahren in der wissenschaft- lichen Community etabliert. Das 2019 begonnene Software-Paket TopKSignal wurde deutlich erweitert und liegt nunmehr in einer Beta-Version vor. Es bietet die Implementierung meh- rerer konvexer Optimierungsverfahren in Kombination mit zwei Bootstrapverfahren für die Signalschätzung auf der Basis multipler Rangreihen wie zuvor beschrieben. Zusätzlich um- fasst es graphische Verfahren für die Exploration von Rangdaten. Auch eine über TopKLists hinausgehende Möglichkeit zur Rangaggregation ist enthalten. Wie in den vergangenen Jahren hielt Prof. Schimek Privatissima in Biostatistik und Bioinfor- matik. An der Medizinischen Universität Graz betreute er 2020 zwei Doktoranden. 2 http://topklists.r-forge.r-project.org/ Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2020 Seite 12 von 55
3.2 Neue Forschungsschwerpunkte (UG §99(5))
3.2.1 Mathematische Modelle und Infektionskrankheiten
S. Herzog
Infektionskrankheiten tragen wesentlich zur weltweiten Krankheitslast bei, was auch durch
die aktuelle COVID-19-Pandemie wieder aufzeigt wird. Um gezielt Interventionen setzen zu
können, werden einerseits Schätzungen zu Änderungen der Inzidenz bzw. Prävalenz von In-
fektionskrankheiten benötigt, und andererseits müssen auch die Effekte von Interventionen
im Bereich Prävention und Therapie bestimmt werden.
Bei Infektionen beeinflusst eine Intervention nicht nur die Personen, welche in die Studie
eingeschlossen werden, sondern auch die Menschen im Umfeld der Studienteilnehmer*innen,
die nicht Ziel dieser Interventionen sind. Beispielsweise infiziert eine erfolgreich behandelte
Person wegen einer verkürzten Infektionsdauer weniger Menschen in ihrer Umgebung und
schützt damit indirekt auch potentiell infizierbare Menschen und kann somit auf längere
Sicht auch den Infektionsdruck auf die anderen Studienteilnehmer*innen beeinflussen. Des-
halb stellen Infektionen eine besondere Herausforderung für die Planung von Studien dar,
da diese übertragen werden und sich nicht wie eine chronische Krankheit in einer Person
unabhängig von anderen entwickeln. Somit erfordert die Planung der Fallzahl sowie die Aus-
wahl und Anzahl der Zeitpunkte der getätigten Stichproben besondere Methoden bzw. Über-
legungen, damit die direkten und indirekten Effekte einer Intervention in der Planung be-
rücksichtigt werden können. Gegenwärtig gibt es wenig interdisziplinäre Grundlagenfor-
schung, welche sich mit der Weiterentwicklung von Studiendesign und Monitoring bei Infek-
tionsstudien beschäftigt.
Mathematische Modelle können solche Einflüsse von Interventionen auf die Übertragungsdy-
namik sowie die Wechselwirkungen zwischen den Individuen abbilden. D.h., um eine Verän-
derung in der Prävalenz oder Inzidenz einer Infektion aufzuzeigen bzw. zu untersuchen, soll-
ten mathematische Modelle in der Planung genutzt werden, um die Anzahl der teilnehmen-
den Personen sowie die Auswahl und Anzahl der Zeitpunkte der getätigten Stichproben zu
bestimmen. Bislang werden mathematische Modelle vor allem dafür genutzt, um Epidemien
zu analysieren, Dynamiken von Infektionskrankheiten zu verstehen oder zu prognostizieren,
ob und in welchem Umfang Eingriffe/Behandlungen die Krankheitslast von Infektionen redu-
zieren. Sie werden auch ergänzend zu statistischen Ansätzen bei der Datenanalyse verwen-
det, aber trotz Empfehlungen von Expert*innen ist der Einsatz bei der Planung fast nicht
existent.
Der Schwerpunkt der Professur liegt also in der Nutzung von mathematischen Modellen in
der Infektiologie, d.h. Analyse von Daten, Szenarienanalyse und Planung von Studien, insbe-
sondere in der Entwicklung von mathematischen Modellen für die Weiterentwicklung von
Studiendesigns bei Infektionskrankheiten.
3.2.2 Computational Semantics for Health
M. Kreuzthaler
Digitalisierung hat Krankenversorgung und klinische Forschung nachhaltig geprägt. Inhalte
der elektronischen Patient*innenakte, sogenannte klinische Real-World-Daten (RWD), wer-
den zunehmend als wichtige Datenquelle wahrgenommen, sowohl zur Unterstützung der kli-
nischen Versorgung als auch der medizinischen Wissenschaft und der universitären Lehre. Im
Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2020 Seite 13 von 55Gegensatz zu kodierter Information für administrative Zwecke oder hochselektiven Daten zu klinischen Studien, repräsentieren RWD die im Krankenhaus vorgenommene Diagnostik, The- rapie und die damit verbundenen Prozesse. RWD bestehen zum Großteil aus Texten, die für medizinisch versierte Leser*innen geschrieben sind und durch große Heterogenität auffallen. Knappheit der Formulierung, großzügiger Umgang mit sprachlichen Normen und eine spezi- elle Medizinterminologie mit regionalen und lokalen Eigenheiten sind charakteristisch. Eine computertechnische Verwertung dieser Inhalte erfordert eine aufwändige Modellierung der klinischen Fachsprache und deren Übertragung in klinische Standards, die im Idealfall internationale Interoperabilität ermöglichen, wie z.B. SNOMED CT. Verarbeitung natürlicher Sprache, sogenanntes Natural Language Processing (NLP), ist in diesem Zusammenhang ein wichtiges Forschungsgebiet. In jüngster Zeit hat die Kombination von neuronalen Netzen mit NLP einen enormen Aufschwung erfahren und bietet weite wissenschaftliche Betätigungsfel- der für spezialisierte Fachsprachen. Wie man die Extraktion relevanter Information aus he- terogenen semistrukturierten Klinikdaten verbessern kann, ist dabei unter anderem eine der anwendungsorientierten Forschungsfragen. Speziell diese Ansätze werden im Rahmen der Professur durch interdisziplinäre Kooperatio- nen auf nationaler und internationaler Ebene untersucht und stellen somit eine Vertiefung der Aktivitäten am Institut im Bereich der medizinischen Semantik der letzten Jahre dar. Neben der verstärkten internen und externen Vernetzung dieses Fachgebiets werden ausge- wählte Kapitel im Bereich der Lehre vertreten bzw. finden Einzug in dem seit dem Winter- semester 2020 angebotenen Erweiterungsstudium „Digitalisierung in der Medizin“ der Medi- zinischen Universität Graz. Selektierte Inhalte werden hier gemeinsam mit Studierenden in- teraktiv erarbeitet, mit dem Ziel, dass Teilnehmer*innen Potenziale, Chancen aber auch Limitationen zum Thema "Künstliche Intelligenz und maschinelles Lernen in der Medizin" in ihrem Umfeld in Zukunft besser beurteilen können. Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2020 Seite 14 von 55
3.3 Projektberichte
3.3.1 Das Quanten-Perzeptron
M. Wiltgen
Künstliche Intelligenz (KI) und maschinelles Lernen (ML) sind zwei aktuelle Themen in Wis-
senschaft und Technik. Bei KI geht es darum, mit Hilfe von Computern die menschliche In-
telligenz nachzuahmen. Bei ML geht es um Mustererkennung in strukturierten und unstruk-
turierten Daten (Texte, Bilder usw.). Beide Themen beanspruchen jährlich beträchtliche In-
vestitionen an Forschung und Kapital. Bereits gute Ergebnisse zeigt KI im Bereich der auto-
matischen Diagnostik, aber es gibt auch Misserfolge, wie die Unfälle mit autonom fahrenden
Autos zeigen. KI und ML gehören ohne Zweifel zu den Computing-Herausforderungen unserer
Zeit.
Die Grundbausteine vieler ML-Systeme bilden künstliche neuronale Netzwerke. Schon die
ersten Versuche, künstliche Neuronen — McCulloch-Pitts-Neuronen — zu entwerfen, orien-
tierten sich (mehr oder weniger) an der Biologie. Das biologische Neuron nimmt Eingaben
über seine Dendriten auf und gibt die daraus resultierenden Werte über sein Axon aus. Die
Entscheidung, ob ein Reiz über den Ausgang abgegeben wird, das heißt ob das Neuron feuert,
erfolgt durch einen Prozess, der als Aktivierung bezeichnet wird. Entsprechen die Eingaben
einem gelernten Muster, feuert das Neuron, andernfalls nicht. Es ist schnell zu erkennen,
dass Ketten miteinander verbundener biologischer Neuronen im Gehirn sehr komplexe Mus-
ter erkennen können.
Die einfachen McCulloch-Pitts-Neuronen, auch Entscheidungsnetzwerke genannt, konnten
die Funktion von Logikgattern nachahmen. Die Werte an den Eingängen (Dendriten) des
Perzeptrons werden mit ihrer Gewichtung multipliziert und aufsummiert. Die Entscheidung,
den Ausgang (Axon) zu aktivieren, wird über eine lineare Schwellwert-Einheit realisiert.
Abb. 2: Perzeptron.
Ein früher Meilenstein in der Geschichte Neuronaler Netze war die Entwicklung des Perzept-
rons durch den Psychologen Frank Rosenblatt. Sein Perzeptron (Abbildung 2) hat, wie die
McCulloch-Pitts-Neuronen, binären Eingänge x1, , x n und eine lineare Schwellwert-Ent-
scheidungseinheit („Activation function“). Die Eingänge des Perzeptrons werden mit ihren
Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2020 Seite 15 von 55Gewichtungen w1 , , w n multipliziert und aufsummiert ( i w i x i ). Die Entscheidung, den
Ausgang des Perzeptrons zu aktivieren, wird über die Schwellwertfunktion realisiert. Wenn
das Ergebnis der Summe gleich oder größer als der gegebene Schwellwert ist, wird eine 1
ausgegeben, ansonsten eine 0. Der Schwellwert für die Entscheidung über den Ausgabewert
ist einstellbar, und es wird eine begrenzte Form des Lernens unterstützt. Heutzutage wird
das Perzeptron als ein einlagiges neuronales Netz betrachtet. Die Deep-Learning-Netze, die
in den letzten Jahren viel Interesse verzeichnet haben, sind direkte Abkömmlinge davon.
Heute steckt in der Informationsverarbeitung und auch im KI-Bereich eine weitere Revolution
in den Kinderschuhen: der Quantencomputer. Und das wirft die Frage auf, ob es möglich ist,
ein Perzeptron in einem Quantencomputer zu implementieren. Der große Vorteil von Quan-
tencomputern ist, dass sie eine exponentielle Erhöhung der Zahl der verarbeiteten Dimensi-
onen ermöglichen. Wenn ein klassisches Perzeptron einen Input von N Daten verarbeiten
kann, schafft ein Quanten-Perzeptron 2 hoch N Daten.
Abb. 3: Quanten-Schaltkreis-Darstellung des Quanten-Perzeptrons.
Abbildung 3 zeigt die großen Blöcke in der Quanten-Schaltkreis-Darstellung des Quanten-
Perzeptrons. Der erste Block enthält einen Unitären Operator ( Ux ), welcher den initialen
Quantenzustand x im Quantenregister präpariert. Der zweite Block ( U w ) berechnet das
Skalarprodukt des initialen Zustandes und der Gewichte ( x,w ). Das sogenannte Ancilla
Qubit speichert den Output über ein multiples CNOT Gate. Die Schwellwertfunktion, welche
bei einem klassischen Perzeptron den Output-Wert bestimmt, ist im Allgemeinen nichtlinear.
Die Unitären Operatoren der Quantentheorie sind lineare Operatoren und können die
Schwellwertfunktion nicht implementieren. Deshalb übernimmt beim Quanten-Perzeptron
eine (irreversible) Messung diese Aufgabe. Gemessen wird dabei nur das Ancilla Qubit. Die
möglichen Messwerte sind „0“oder „1“. Wenn nun ein Eingangsmuster, repräsentiert durch
den initialen Quantenzustand x , das Quanten-Perzeptron aktiviert, ergibt die Messung
des Ancilla Qubit den Zustand 1 . Das heißt, das Muster wurde erkannt mit der Wahrschein-
2
lichkeit c N 1 . Nach der Theorie der Quantenmessung ist diese Größe die Wahrscheinlich-
keit, dass bei einer Messung der Wert „1“ erhalten wird. (N ist dabei die Größe des zugrun-
deliegenden Hilbert-Raums). Die Amplitude des Basiszustandes (computational state) N 1
ist:
c N 1 w x
Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2020 Seite 16 von 55Daraus resultiert die Messwahrscheinlichkeit:
p 11 1 | c N 1 |2
Die Abbildung 4 zeigt die detaillierte Darstellung eines Quanten-Perzeptrons als Quanten-
Schaltkreis. Dabei wird ein Bild („Input Pattern“) mit einem vorgegebenen Muster („Weight
Pattern“) verglichen (Abbildung 5). Die Aufgabe des Quanten-Perzeptrons ist es, festzustel-
len, wie gut das Eingabebild mit dem Gewichtemuster übereinstimmt. Dabei bestimmt die
Messwahrscheinlichkeit für den Zustand 1111 den Grad der Übereinstimmung, es werden 24
= 16 Basiszustände verwendet. Das Eingangsmuster und das Gewichte-Muster werden durch
folgende Quantenzustände dargestellt:
x
1
4
0000 0001 0010 0011 0100 0101 0110 0111
1000 1001 1010 1011 1100 1101 1110 1111
w
1
4
0000 0001 0010 0011 0100 0101 0110 0111
1000 1001 1010 1011 1100 1101 1110 1111
Abb. 4: Detaillierte Darstellung eines Quanten-Perzeptrons als Quantenschaltkreis.
Die negativen Amplituden der Basiszustände beziehen sich auf die hellblauen Flächen in den
Mustern (Abbildung 5).
Abb. 5: Input pattern und Weight pattern.
Die Simulation des Quanten-Perzeptrons wurde auf einem klassischen Computer durchge-
führt. Der finale Zustand ist:
Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2020 Seite 17 von 551 1 1 1 1 1 1 3
x,w 0000 0001 0010 0011 1100 1101 1110 1111
4 4 4 4 4 4 4 4
Der Basiszustand 1111 hat mit c15 0.75 eine höhere Amplitude als alle anderen Basiszu-
ständen (mit Amplituden 0.25 und 0.00 ). Daher resultiert eine Messwahrscheinlichkeit für den
Zustand von:
2
p( 1111 ) c15 0.563
Das bedeutet, das Eingangsmuster stimmt zu 56.3 % mit dem vorgegebenen Muster überein.
Die Simulation erfolgte mit dem Quirk „quantum circuit simulator“3 (Abbildung 6).
Abb. 6: Simulation mit dem Quirk „quantum circuit simulator“.
Zusätzlich wurde das Quanten-Perzeptron auch mit MATLAB simuliert (Abbildung 7).
Abb. 7: MATLAB-Simulation des Quanten-Perzeptrons.
3 http://algassert.com/quirk
Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2020 Seite 18 von 553.3.2 CBmed — DBM4PM
M. Kreuzthaler, J.A. Vera Ramos, L. Hammer, S. Schulz
Im Rahmen des österreichischen K1-Zentrums für Biomarkerforschung leitet Markus
Kreuzthaler das Projekt DBM4PM (Digital Biomarkers for Precision Medicine). Mit dem
Industriepartner Roche Diagnostics verfolgen wir als Schwerpunkt die Wissenserschließung
aus klinischen textuellen Daten, deren Standardisierung, sowie die Aufbereitung der gewon-
nenen Information für die Tumorboardanwendung NAVIFY.
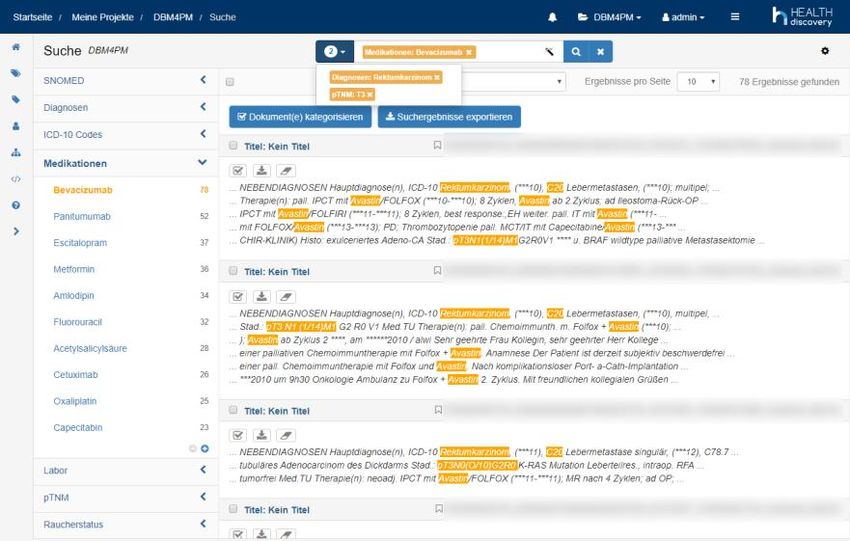
Abb. 8: Semantische Suche unterstützt durch die NLP-Plattform Averbis Discovery.
Zur Analyse klinischer Freitexte mittels Natural Language Processing (NLP) kommt die Ana-
lyseplattform Averbis Health Discovery zum Einsatz, in die eigene Terminologien und Extrak-
toren eingebunden werden.
Abb. 9: .
Die Extraktion und Standardisierung von Lifestylefaktoren wurde dabei neben Medikationsin-
formationen in dem Projekt als relevant identifiziert. Meistens ist die Erhebung nur in semi-
strukturierter, freitextlicher Form in der klinischen Routinedokumentation erfasst und daher
an keine standardisierte Dokumentation gebunden. Freie sprachliche Formulierungen er-
schweren eine strukturierte Erhebung für retrospektive und vergleichende Auswertungen,
z.B. im Rahmen von klinischen Studien. Eine strukturierte und standardisierte Klassifikation
der freitextlichen Ausprägungen ist daher wünschenswert. Des Weiteren werden Unter-
schiede der Dokumentationsvollständigkeit im Vergleich zu vorhandenen internationalen In-
formationsmodellen herausgearbeitet. Im Rahmen von zwei Diplomarbeiten wurden Gold-
standards für die Lifestylefaktoren Raucherstatus und Alkoholstatus erstellt, mit dem Ziel
der Beurteilung, inwieweit mit Methoden des maschinellen Lernens eine korrekte Interpre-
tation in festgelegten Klassen möglich ist. Ein bestehender Goldstandard für Medikationsin-
formationen wurde überarbeitet und wird für die Methodenevaluierung verwendet.
Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2020 Seite 19 von 553.3.3 Klinische Terminologien
S. Schulz, M. Kreuzthaler, M. Schneider, D. Hashemian Nik, L. Hammer
Die Entwicklung der deutschen Interface-Terminologie für SNOMED CT (SCT-GIT) wurde wei-
tergeführt. Stefan Schulz wurde bei dieser Aufgabe von insgesamt drei Medizinstudierenden
unterstützt. Die Terminologie wurde innerhalb des NLP-Tools Averbis Health Discovery in-
tensiv getestet. Gemessen an einem sprachübergreifenden Goldstandard, in welchem klini-
sche Texte manuell mit SNOMED-CT-Konzepten annotiert sind, ergab sich bezüglich der Kon-
zepterkennung kein signifikanter Unterschied zwischen SCT-GIT und der offiziellen englisch-
sprachigen Version von SNOMED CT.
An der Weiterentwicklung des Standards SNOMED CT ist Stefan Schulz in zwei internationalen
Aktivitäten involviert, zum einen in der Modelling Advisory Group von SNOMED International,
zum anderen in der Arbeitsgruppe zur deutschen Übersetzung. In ersterer war ein Schwer-
punkt die Harmonisierung von SNOMED CT mit der Toplevel-Ontologie BFO2020. Die zweite
Arbeitsgruppe wurde 2020 ins Leben gerufen und von der ELGA GmbH koordiniert, mit BfArm
als deutschem und eHealth Suisse als Schweizer Repräsentanten. Die Arbeitsgruppe widmet
sich in der Anfangsphase primär der Erstellung von Übersetzungsrichtlinien.
3.3.4 Precise4Q — Personalized Medicine by Predictive Modelling in Stroke for
better Quality of Life
S. Schulz, C. Buchegger
Precise4Q4 verfolgt das Ziel, für Schlaganfall in vier Phasen datengetriebene Vorhersagemo-
delle zu erstellen. Nach dem Weggang der bisherigen PI Catalina Martínez-Costa nach Spa-
nien wurde das Projekt und die Fördersumme zwischen der Universität Murcia und der Med
Uni Graz gesplittet. Stefan Schulz ist nun PI seitens des IMI und koordiniert gemeinsam mit
Catalina Martínez-Costa die Annotation von Freitexten zu Schlaganfallrehabilitation des Pro-
jektpartners Institutto Guttmann aus Barcelona.
3.3.5 Postoperative altersentsprechende Ruheschmerzerfassung bei Kindern
und Jugendlichen
A. Avian, A. Berghold
Ein essentielles Ziel in der patient*innenorientierten Behandlung ist eine adäquate
Schmerztherapie. Unbehandelter Schmerz verursacht große physische und psychische Bean-
spruchungen und führt zur Entwicklung eines sogenannten Schmerzgedächtnisses. Die Vo-
raussetzung einer adäquaten Schmerztherapie ist die „Sichtbarmachung“ des Schmerzes,
also das Erkennen, dass Schmerzen vorhanden sind. Während für die Diagnose und Therapie
bei chronischen Schmerzen für Kinder ein deutschsprachiger mehrdimensionaler Fragebogen
vorliegt, der neben den Schmerzen auch Begleitaspekte wie z.B. schmerzbeeinflussende Fak-
toren und schmerzbezogene Beeinträchtigungen beinhaltet, werden stationär bei Akut-
schmerzen zumeist die Begleitaspekte außer Acht gelassen.
Ziel dieses Projektes ist es, ein Erhebungsinstrument zu entwickeln, welches den akuten
Schmerz und die Begleitaspekte, Befindensbeeinträchtigungen und körperlichen Beschwer-
den nach chirurgischen Interventionen bei Kindern und Jugendlichen altersgerecht, reliabel
und valide erhebt.
4 https://precise4q.eu/
Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2020 Seite 20 von 55Sie können auch lesen

















































