A Direct Perception Approach for Autonomous Driving
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Seminararbeit
A Direct Perception Approach for Autonomous
Driving
Hauptseminar Sommersemester 2017
angefertigt von
Patrick Trojosky
Fakultät: FK07 Mathematik und Informatik
Studiengang: Master Informatik
Matrikelnummer: 08138116
Dozent: Prof. Dr. Nischwitz
München, 29.06.2017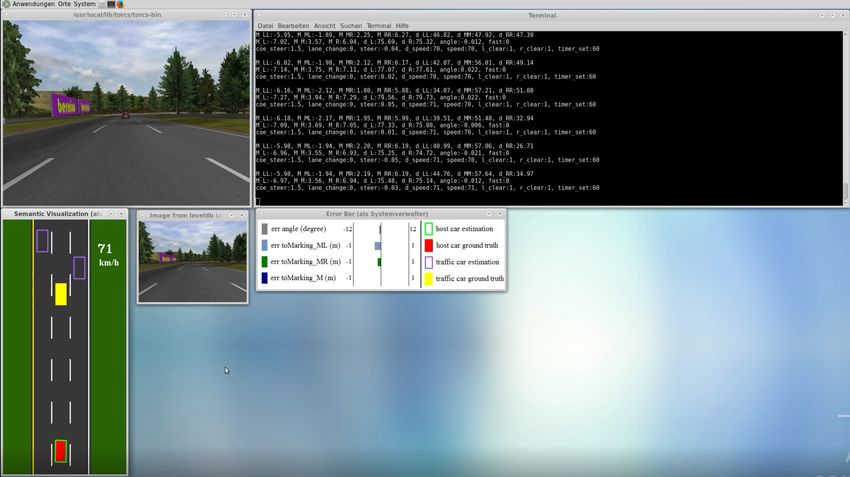
Eigenständigkeitserklärung Ich erkläre hiermit, dass ich diese Seminararbeit selbständig verfasst, noch nicht anderweitig für Prüfungszwecke vorgelegt, keine anderen als die angegebenen Quellen oder Hilfsmittel benutzt, sowie wörtliche und sinngemäße Zitate als solche gekennzeichnet habe. München, 29. Juni 2017
Abkürzungsverzeichnis TORCS The Open Racing Car Simulator ML Maschinelles Lernen CNN Convolutional Neuronal Network FC Fully Connected ReLu Rectified Linear Unit VM Virtuelle Maschine VGG Visual Geometry Group ILSVRC ImageNetLargeScaleVisualRecognitionChallenge SGD Stochastic Gradient Descent GPU Graphics Processing Unit SVM Support Vector Machine SVR Support Vector Regression SVC Support Vector Classification MEA Mean Absolut Error CUDNN Cuda Deep Neuronal Network MSE Mittlerer Standard Abweichung
Inhaltsverzeichnis
Eigenständigkeitserklärung i
Abkürzungsverzeichnis ii
1 Einleitung 1
1.1 Ziel der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Maschine Learning und Deep Learning . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Benötigte Grundlagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3.1 Grundlegende Bausteine . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3.2 Deep Neuronal Networks . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.3.3 Convolutional Neuronal Networks . . . . . . . . . . . . . . . . . . . . . . 3
1.3.4 Bilderkennung und Klassifikation . . . . . . . . . . . . . . . . . . . . . . . 4
1.4 Aktuelle Ansätze für autonomes Fahren . . . . . . . . . . . . . . . . . . . . . . . 5
1.4.1 Mediated Perception Approach . . . . . . . . . . . . . . . . . . . . . . . . 5
1.4.2 Behaviour Reflex Approach . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2 Learning Affordance for Direct Perception in Autonomous Driving 7
2.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2 Grundidee . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3 Modell - Ableitung der Indikatoren aus einem Bild . . . . . . . . . . . . . . . . . 8
2.4 Controller Berechnung der Fahraktion . . . . . . . . . . . . . . . . . . . . . . . . 11
2.4.1 Lenkbefehl . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.4.2 Geschwindigkeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.5 Convolutional Neuronal Network . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.5.1 Convolutional Layers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.5.2 Fully Connected Layers . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.5.3 Kostenfunktion, Parameter und Optimierung . . . . . . . . . . . . . . . . 15
2.6 Training . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.6.1 Vorverarbeitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.7 Test und Validierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.7.1 Behaviour Reflex ConvNet . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.7.2 Mediated Perception (Lane Detection) . . . . . . . . . . . . . . . . . . . . 17
2.7.3 Direct Perception with GIST . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.7.4 Test mit realen Eingangsdaten (KITTI) . . . . . . . . . . . . . . . . . . . 17
2.8 Zusammenfassung und Bewertung . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3 Analyse des Codes 19
3.1 Installation und Setup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.1.1 TORCS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.1.2 Caffe Driving . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.1.3 Schwierigkeiten und Hindernisse . . . . . . . . . . . . . . . . . . . . . . . 21
3.2 Einsatz von Caffe Driving . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.2.1 Sammeln von Trainigs-Daten . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.2.2 Trainieren des Netzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24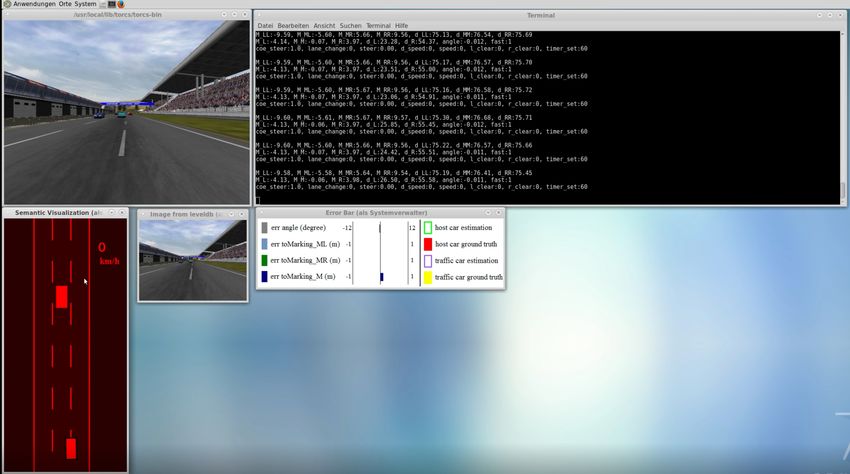
Inhaltsverzeichnis iv
3.2.3 Testen des Netzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.3 Auswertung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.3.1 Test 1: Halten der Spur . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.3.2 Test 2: Spurhalten und Kollisionsvermeidung . . . . . . . . . . . . . . . . 27
4 Weitere Untersuchungen des Direct Perception-Ansatzes 31
4.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.2 Paper: Deep Learning for Autonomous Cars . . . . . . . . . . . . . . . . . . . . . 31
4.2.1 Optimierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.2.2 Resultate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.3 Paper: Deeper Direct Perception in Autonomous Driving . . . . . . . . . . . . . . 32
4.3.1 Optimierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.3.2 Training . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.3.3 Resultate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.4 Eigene Realisierung eines VGG-16 Netzes . . . . . . . . . . . . . . . . . . . . . . 33
4.4.1 Ergebnisse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
5 Zusammenfassung 35
5.1 Bewertung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
5.2 Limitierungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
5.2.1 Geschwindigkeit anderer Verkehrsteilnehmer . . . . . . . . . . . . . . . . . 35
5.2.2 Gegenverkehr . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
5.3 Erweiterungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
5.4 Fazit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
Abbildungsverzeichnis 40
Literaturverzeichnis 41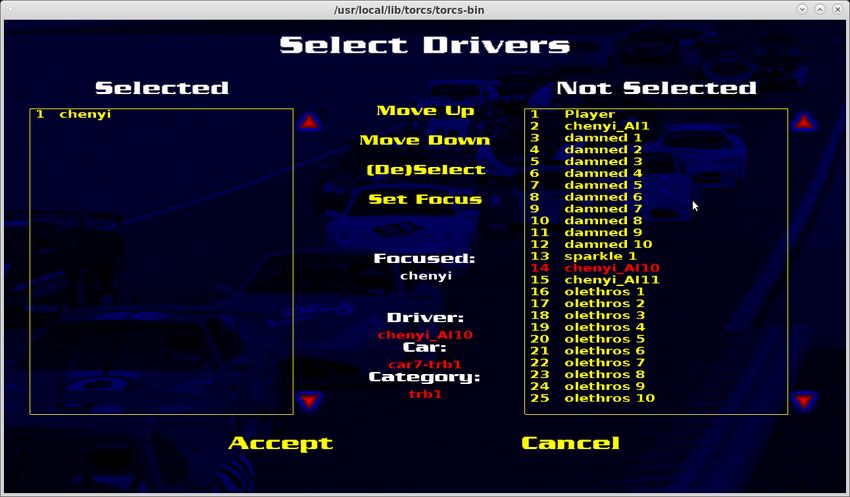
1 Einleitung
Das Mobilitätsverhalten der Menschen befindet sich aktuell stark im Wandel. Innerhalb der
letzten zwanzig Jahre hat sich das Automobil von einem rein mechanischen Fortbewegungsmittel
in ein hoch komplexes System aus Hardware und Software verwandelt.
Mit der ständigen Weiterentwicklung der Fahrzeuge beginnt sich das klassische Nutzungsverhal-
ten von Autos zu verändern. Der Fahrer möchte keine Zeit mehr für Alltagsstrecken, wie den
Weg zur Arbeit oder den täglichen Nachhauseweg, verschwenden. Vielmehr besteht das Interesse
die Zeit im Fahrzeugen effektiv zu nutzen. Dies ist allerdings nur möglich, wenn das Fahrzeug
eigenständig im Straßenverkehr agieren kann und der Fahrer nicht eingreifen muss. Aus die-
ser Motivation heraus entwickelte sich innerhalb der letzten fünf Jahre das Thema autonomes
Fahren.
Bereits aktuelle Modelle, wie der BMW 7er, sind in der Lage selbständig die Fahrspur zu er-
kennen und dieser zu folgen. Weiterhin kann das KFZ mittels eines Abstandshalte-Tempomaten
einem vorausfahrenden Fahrzeug folgen und bei Bedarf durch Bestätigung des Fahrers eigen-
ständig überholen1 .
Bei diesen Fahrerassistenz-Systemen spricht man von Level 1 und Level 2 Funktionen. Dabei wird
das System immer durch den Fahrer überwacht und agiert nicht hoch automatisiert, sondern
übernimmt spezifische Teilaufgaben zur Entlastung des Fahrers. Level 3 Systeme agieren hoch
automatisiert und der Fahrer kann sich zeitweise anderen Dingen zuwenden. Er muss im Warnfall
aber in der Lage sein korrigierend einzugreifen[1, S. 15]. Nach aktuellem Kenntnisstand werden
erste Fahrzeuge mit Level 3 Systemen im Jahr 2020 erwartet[1, S. 16].
Die größte Herausforderung des autonomen Fahrens ist die Erkennung und korrekte Interpre-
tation komplexer Verkehrssituationen. Nur wenn die Umgebung richtig eingeschätzt wird, kann
eine adäquate Steuerungsbefehlssequenz durchgeführt und das Fahrzeug sicher durch den Ver-
kehr geleitet werden.
1.1 Ziel der Arbeit
Im Rahmen dieser Seminararbeit soll auf Basis des Papers von Chen, Seff, Kornhauser et al.[2]
der aktuelle Stand der Technik im Bereich Maschine Learning im Einsatzgebiet des autonomen
Fahrens beschrieben und der Direct Perception-Ansatz detailliert dargestellt werden. Kapitel 2
zeigt diesen, neuen Ansatz zum Einsatz von Convolutional Neuronal Networks auf.
Darüber hinaus wird in Kaptiel 3 der Ansatz aus [2] praktisch eingesetzt, um damit alle Details
der Realisierung zu erschließen und mögliche Schwachstellen aufzuzeigen.
Kapitel 4 beschäftigt sich mit möglichen Optimierungen des Direct Perception-Ansatz auf Basis
der Ausführungen von Rait, Mohan und Selvaraj sowie von Liu und Wang. Grundsätzlich wird
dort die Möglichkeit evaluiert, den Trainingsprozess des Netzes durch vortrainierte Strukturen
zu beschleunigen.
Zum Abschluss zeigt Kapitel 5 die Grenzen des Direct Perception-Ansatz auf und lieferte zwei
konkrete Vorschläge, wie das System für ein weniger spezifisches Aufgabenfeld erweitert werden
kann.
1
http://www.bmw.de/de/neufahrzeuge/5er/limousine/2016/business-assistenzsysteme/fahrerassistenz.html#
driving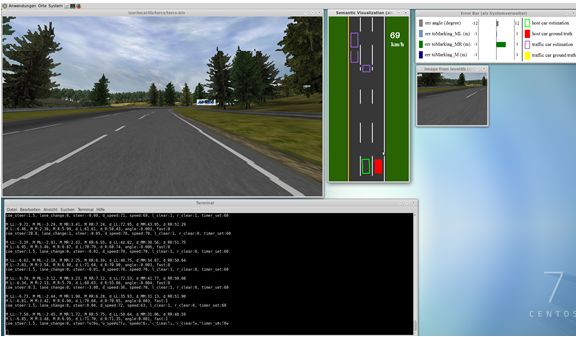
1 Einleitung 2
1.2 Maschine Learning und Deep Learning
Maschine Learning und Deep Learning sind zwei vergleichsweise junge Phänomene der Infor-
matik, welche innerhalb der letzten drei bis fünf Jahren ein rasantes Wachstum und Interesse
erfahren haben. Dies hängt zum einen mit der bereits im Consumer Bereich sehr hohen Rechen-
leistung aktueller Grafikkarten, aber auch mit den neuen Anwendungsgebieten, zusammen.
Ziel des maschinellen Lernens ist es Maschinen oder Computer intelligent zu machen, sodass diese
eigenständig Entscheidungen auf Basis früherer Erfahrungen treffen können. In der klassischen
Informatik wurden Probleme mit Hilfe von Algorithmen gelöst, die für ein konkretes Problem
oder einen speziellen Anwendungsfall dedizierte Lösungen beschreiben. Maschine Learning geht
hier neue Wege.
Eine sehr treffende Definition liefert Goodfellow, Bengio und Courville: „A computer program is
said to learn from experience E with respect to some class of tasks T and performance measure
P , if its performance at tasks in T , as measured by P , improves with experience E.“
Ziel ist damit nicht mehr einen Anweisungsalgorithmus zu entwickelt, der vorgibt wie sich das
System zu verhalten hat, sondern ein Modell zu finden, welches das Problem beschreibt. Auf
Basis von Trainingsdaten versucht dann der ML Algorithmus das Modell optimal zu lösen[5, S.
99].
Dieser Datensatz enthält im Falle von Supervised Learning 2 , sowohl den Input als auch das
gewünschte Ergebnis3 .
Mit dieser Technologie können komplexe Probleme gelöst werden, welche mit klassischen Ver-
fahrensalgorithmen nicht adäquat beschrieben werden können. Weshalb das Einsatzgebiet von
Maschine Learning Algorithmen fast grenzenlos ist. Beginnend bei Schrifterkennung über Klas-
sifizierung von Bildern hinzu intelligenten Steuerungssystemen für Roboter.
1.3 Benötigte Grundlagen
In diesem Abschnitt wird auf einige Grundlagen des Maschine bzw. Deep Learnings eingegangen,
welche für das Verständnis des Papers erforderlich sind. Zentrale Quelle ist dafür das Buch „Deep
Learning“ von Ian Goodfellow[5].
1.3.1 Grundlegende Bausteine
So gut wie jeder ML-Algorithmus besteht aus bestimmten Grundbausteinen, die je nach An-
wendung modifiziert werden. Diese Komponenten werden am Beispiel der lineare Regression
erläutert.
Datensatz
Der Datensatz in diesem Modell besteht aus den Eingabewerten X ∈ Rn und der Ausgabe Y als
Skalar ∈ R. Beide Variablen können als Vektor dargestellt werde:
Im Falle von Supervised Learning sind sowohl die X als auch die Y Werte bekannt und können
für das Training eingesetzt werden.
Datensätze mit diskreten Y-Werten werden meist als Klassifizierungen bezeichnet. Dazu zählen
die Bilderkennung oder eine Farbklassifizierung.
2
Bei Supervised Learning wird das Netz mit einem Datensatz trainiert, sowohl die Inputs als auch die Output
bekannt sind[5, S. 139 ff.].
3
Siehe 1.3.1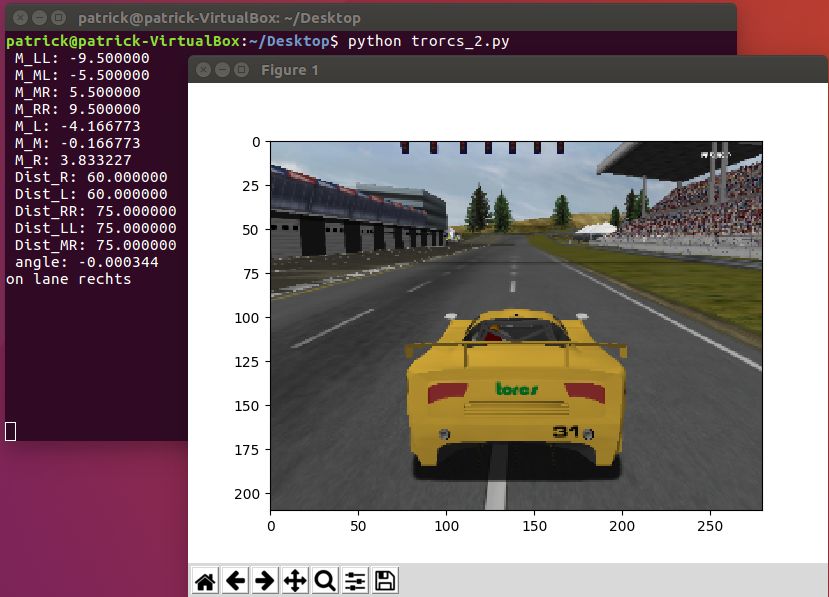
1 Einleitung 3
Model
Das Modell beschreibt das zu lösende Problem des Netzes. Im konkreten Beispiel der linearen
Regression bildet das Modell die Gleichung einer Regressionsgeraden.
y = w0 x + b (1.1)
Dabei ist w ∈ Rn ein Vektor bestehend aus Parametern, die Gewichte genannt werden. Diese
Werte kontrollieren das Verhalten des Systems und geben im konkreten Fall vor, wie stark der
x-Wert an der Gesamtheit aller Werte beteiligt ist. Der Wert B ist der Bias[5, S. 124]. Dieser
Wert gibt den Ursprungspunkt der Regressionsgeraden wieder. Damit kann diese besser justiert
werden.
Kostenfunktion
Die Kostenfunktion oder Loss-Funktion dient dem Algorithmus als Optimierungsfunktion. Ziel
ist es die Parameter des beschriebenen Modells so zu wählen, dass die Abweichung des prädizier-
ten Y Wertes zum tatsächlichen Wert minimal wird. Für das obige Beispiels kann die mittlerer
Standard Abweichung eingesetzt werden:
1
M SE = kŷ − yk22 (1.2)
m
Optimierung
Die Minimierung der Kostenfunktion wird typischerweise mit der Gradient Descent-Methode
durchgeführt werden. Diese Optimierung versucht iterativ durch Anpassung der Parameter im-
mer den größten Schritt in Richtung minimale Abweichung zu finden. Daher wird die Methode
auch als Verfahren des steilsten Abstiegs bezeichnet[5, S. 82]. Im Beispiel minimiert der Opti-
mierungsalgorithmus also den die MSE.
Neben dieser Methode existieren noch weitere Algorithmen zur Minimierung. Eine Liste ist in
[5, S. 83ff] enthalten.
1.3.2 Deep Neuronal Networks
Mithilfe dieser einfachen Maschine Learning Algorithmen lassen sich bereits viele Probleme lösen,
indem Perzeptronen4 miteinander verbunden werden. Jedes Perzeptron enthält das Modell mit
eigenen Gewichten. Die Outputs der ersten Schicht von Neuronen sind dabei die Inputs der
folgenden Schicht. Bei weiterer Verschachtlung spricht man von Deep Neuronal Networks. Für
die Anregung der Neuronen wird eine Aktivierungsfunktion eingesetzt. Bekannte Vertreter sind
die Sigmoid oder Softmax Funktion. Diese Funktionen sorgen für eine Nichtlinearität im System
und bestimmten damit den Beitrag eines Neurons an der Gesamtheit aller Output Werte.
1.3.3 Convolutional Neuronal Networks
Convolutional Neuronal Networks wurden entwickelten, um komplexere und mehrdimensionale
Probleme zu lösen, die mithilfe von normalen Fully Connected Netzen nicht darstellbar sind5 .
CNNs sind auf die Verarbeitung von Daten im mehrdimensionalen Matrix Format spezialisiert.
Dazu zählen insbesondere Zeitreihen und Bilddaten. Der Hauptunterschied zu normalen Neu-
ronalen Netzen ist, dass in mindestens einem Layer anstelle einer Matrixmultiplikation eine
Faltung durchgeführt wird[5, S.330]. Dabei handelt es sich aber nicht um den mathematischen
4
Ein Perzeptron besteht in der einfachsten Form aus einem Neuron.
5
Siehe [5, S. 153ff ] für die ausführlich beschriebenen Hintergründe.
1 Einleitung 4
Begriff der Faltung. Vielmehr werden neben der Inputmatrix weitere zweidimensionale Matri-
zen, bestehende aus Gewichten, definiert. Diese werden Kernel genannt. Aus diesen Matrizen
wird dann eine Feature Map generiert, indem der Kernel Pixelweise über das Input Bild gescho-
ben wird. Genau genommen handelt es sich bei dieser Operation um eine Korrelation[6]. Die
mathematische Darstellung zeigt die folgende Formel.
R
X R
X
J(x, y) = ws,t I x+s,y+t (1.3)
s=−R t=−R
Der Einsatz von Filtern ist eine bekannte Praxis aus der Bildverarbeitung. Hier werden die
Filter so gewählt, dass markante Merkmale eines Bildes verstärkt werden. Welche Merkmale
hervorgehoben werden, hängt dabei von der Wahl der Gewichte der Filter ab. In einem CNN
werden diese Gewichte automatisch durch das System gelernt und iterativ angepasst. Im Design
des Netzes wird lediglich die Anzahl der Kernel und deren Dimension vorgegeben.
Zur Reduktion der Menge an Gewichten wird bei der Convolution ein sogenannter Stride einge-
setzt. Dieser Wert gibt vor, wie viele Pixel beim Shifting des Kernels übersprungen werden.
Ergänzt wird ein Convolutional Layer meist durch eine Rectified Linear Unit und einen Pooling
Layer. Die ReLu verändert die Gewichte dahingehend, dass positive Werte übernommen werden
und negative Werte zu Null gesetzt werden [5, S. 192]. Für CNNs hat die Relu damit die klassische
Sigmoid Funktion6 , als Aktivierung abgelöst, da sie nachweislich bessere Ergebnisse erzielt[5, S.
226].
Der Pooling Layer reduziert die Anzahl der Gewichte, indem er einen definierten Bereich (Bsp.
2x2 )betrachtet und aus diesen Werten abhängig der Pooling Methode einen auswählt. Häufig
wird Max Pooling eingesetzt. Hierbei wird das Maximum der betrachteten Werte gewählt[5, S.
339].
Neben der Reduktion der Anzahl von Gewichten wird durch das Pooling zusätzlich eine gewisse
Invarianz bei der Erkennung der Merkmale eine Bildes eingeführt[6, Kap.5, S.11].
1.3.4 Bilderkennung und Klassifikation
Die alleinige Anwendung von Convolutional Layern hebt zwar die einzelnen Merkmale eines
Bildes hervor, ist aber nicht in der Lage diese miteinander zu kombinieren und zu interpretieren.
Aus diesem Grund werden für Problemstellungen aus dem Bereich der Bilderkennung meist
zusätzliche Fully Connected Layer nach den Convolutional Layern angefügt. Diese Schichten
führen auf Basis der Feature Maps eine Klassifikation aus und sind in der Lage beispielsweise
Gesichter oder Zahlen zu erkennen.
Eines der bekanntesten Netze dieser Form ist AlexNet, welches 2012 von Alex Krizhevsky entwi-
ckelt wurde[7]. Mithilfe dieses Deep-Convolutional-Neuronal Networks konnte 2012 im Rahmen
der ImageNetLargeScaleVisualRecognitionChallenge7 die Fehlerrate von 35% auf 16% halbiert
werden. Eine derartigen Sprung hatte es bis dato ohne den Einsatz von CNNs nicht gegeben.
Das AlexNet besteht aus fünf Convolutional Layern, gefolgt von drei Fully Connected Layern.
Zusätzlich wird nach den Convolution Operation eine ReLu für die Nichtlinearität und Max-
Pooling eingesetzt. Die Schichten sind auf zwei Pfad aufgeteilt, damit das Training des Netzes
parallel auf zwei GPUs durchgeführt werden kann. Weitere Details finden sich bei Srivastava,
Hinton, Krizhevsky et al.[7].
Die in Abbildung 1.1 gezeigte Architektur bildet die Grundlage für das eingesetzte ConvNet von
Chen, Seff, Kornhauser et al.
6
Bsp. Tangens Hyperbolicus
7
Die ILSVRC ist der wichtigste Wettbewerb zur Klassifizierung von Bildern. Siehe http://www.image-
net.org/challenges/LSVRC/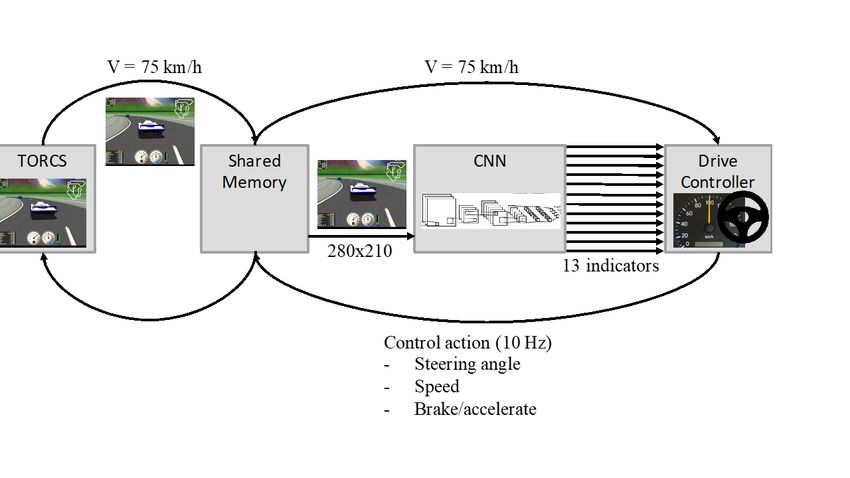
1 Einleitung 5
Abbildung 1.1: Aufbau AlexNet[7]
Eine Weiterentwicklung der AlexNet Architektur wurde von der Visual Geometry Group in Ox-
ford vorgestellt und ist unter dem Namen VGG Net bekannt. Im Unterschied zu AlexNet werden
auf allen Ebenen deutlich kleinere Filter (3x3) eingesetzt. VGG Nets bestehen typischerweise aus
mehr Schichten als AlexNet und sind damit deutlich tiefer. VGG-198 verwendet zum Beispiel
neunzehn Layer und erreichte damit 2014 eine Fehlerquote von 7.3% in der ILSVRC[4].
In Abschnitt 4.4 wird ein VGG-16 Netz analog der Ausarbeitung von Liu und Wang implemen-
tiert und trainiert.
1.4 Aktuelle Ansätze für autonomes Fahren
Der aktuelle Stand der Technik im Bereich des autonomen Fahrens unterscheidet zwischen zwei
grundlegenden Konzepten zur Realisierung eines selbst fahrenden Fahrzeugs. An dieser Stelle
werden die beiden Paradigmen Mediated perception und Behaviour Reflex dargestellt. Danach
wird eine dritte Variante erläutert.
1.4.1 Mediated Perception Approach
Der Mediated Perception-Ansatz wird aktuell bei allen großen Automobilherstellern als de facto
Standard für autonomes Fahren eingesetzt. Auf Deutsch übersetzt bedeutet der Begriff „ver-
mittelte Auffassung“. Grundlegend beschreibt dieser Ansatz ein indirektes Vorgehen bei der
Ableitung von Fahraktionen auf Basis eines Umgebungsmodells. Mit Hilfe sämtlicher Sensoren
im Fahrzeug9 wird über Sensordatenfusion ein digitales Abbild der aktuellen Situation und Um-
feld des Fahrzeugs erzeugt. Diese Abbild enthält Informationen über die Straßenführung, die
Position des zu steuernden Fahrzeuges, anderen Verkehrsteilnehmern und Hindernissen. Bildlich
gesprochen entwickelt das Fahrzeug ein Bewusstsein für die eigene Umgebung, mit dessen Hilfe
entschieden werden kann, welche Steuerungsbefehle für eine unfallfreie Fahrt notwendig sind.
Nachteile
Chen, Seff, Kornhauser et al.[2] nennen in ihrem Paper mehrere Nachteile dieses Ansatzes. Zum
einen wird die notwendige Rechenleistung für die Erstellung eines Umgebungsmodells angeführt,
da hierfür große Datenmengen in Betracht gezogen werden müssen. Insbesondere für den Ein-
satz von Stereokameras ist eine enorm leistungsfähige CPU bzw. GPU erforderlich. Zum anderen
8
https://gist.github.com/baraldilorenzo/8d096f48a1be4a2d660d
9
Hierfür werden unter anderem Radar- und Lidar-Sensoren in Verbindung mit Mono- und Stereo-Kameras ein-
gesetzt.1 Einleitung 6 wird die redundante Information erwähnt. Da für die Generierung des Modell diverse Sensoren eingesetzt werden, lässt sich eine Dopplung bestimmter Informationen nicht vermeiden. Diese muss bei der Datenfusion wieder gelöscht werden. Der letzte und schwerwiegendste Nachteil des Mediated Perception-Ansatzes laut „DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving“ ist die Flut an Daten. Für die autonome Steuerung eines Fahrzeuges seien deutlich weniger Informationen ausreichend, die Sensordatenfusion liefere zu viele, nicht relevante Daten. Das Problem ein Fahrzeug selbstständig zu steuern sei ein „low-dimensional“ Problem [2, S.1], wobei der Output des Umgebungsmodell „multi-dimensional“ ist. Zusätzlich wird angeführt, dass bereits die Subkomponenten im Umgebungsmodell teilweise Gegenstand der aktuellen Forschung auf dem Gebiet der Bildverarbeitung sind. Damit beschäftige sich der Mediated Perception-Ansatz zu sehr mit der Verarbeitung und Darstellung des Umgebungsmo- dells, als mit der eigentlichen Aufgabe ein Fahrzeug autonom zu steuern. 1.4.2 Behaviour Reflex Approach Der zweite Ansatz auf dem Gebiet des autonomen Fahrens wird als Behaviour reflex-Ansatz be- zeichnet. Im Gegensatz zu Mediated Perception findet hier eine direkte Reaktion auf den Input eines Sensors statt. Der Zwischenschritt zur Erstellung einer digitalen Realitätsabbildung ent- fällt. Damit wird beispielsweise der Lenkwinkel des Fahrzeug ausschließlich auf Basis eines Bildes der Frontkamera abgeleitet. Alle Merkmale des Bildes werden als Input für die Reaktion verwen- det. Voraussetzung hierfür ist ein bereits trainiertes System, um eine adäquate Fahrzeugaktion abzuleiten. In der Ausarbeitung von Pomerleau[8] wird dieser Ansatz detailliert dargestellt und für die Steuerung eines Offroad Fahrzeuges eingesetzt. Nachteile Der oben ausgeführte Ansatz weißt zwei grundsätzliche Probleme auf, die einen weiteren Einsatz für das autonome Fahren verhindern. Mit dem direkten Mapping einer Fahraktion auf ein Bild ist es nicht möglich das „Große Gan- ze“ zu erfassen. Es wird lediglich auf eine spezielle Situation, einen Teilaspekt der aktuellen Verkehrssituation reagiert. Das gesteuerte Fahrzeug entwickelt kein Bewusstsein für seine Um- gebung. Das Verzögern des vorausfahrenden Fahrzeuges wird beispielsweise erkannt, nicht aber der Grund dafür. Diese Information, möglicherweise eine rote Ampel, ist allerdings eine rele- vante Information für das Gesamtverständnis der Situation. Somit ist es dem Fahrzeug nicht möglich sich in komplexen Straßensituationen, wie Kreuzungen oder Abbiegevorgängen, zurecht zu finden. Der zweite große Nachteil der Methode ist die Tatsache, dass bestimmte Verkehrssituationen auf einem Bild sehr ähnlich wirken, aber eine komplett unterschiedliche Reaktion vom Fahrer erfordern. Als Beispiel will der Fahrer in Situation A dem vorausfahrenden Fahrzeug folgen. In Situation B will er überholen. Das Abbild der Situation über ein Kamerabild ist aber identisch. Dies macht das Training des neuronalen Netzes maximal schwierig, wenn nicht sogar unmöglich, da die Varianz an Situationen extrem groß ist.
2 Learning Affordance for Direct Perception in Autonomous Driving 2.1 Motivation Aus den in Kapitel 1.4 genannten Nachteilen entsteht die Motivation für Chen, Seff, Kornhauser et al. einen neuen, dritten Ansatz für den Einsatz von Deep Learning im Umfeld des autonomen Fahrens zu entwickeln, der im Paper „DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving“ beschrieben wird. Für die Autoren ist insbesondere die Masse an Infor- mationen, die für ein Abbild der aktuellen Umgebungssituation erforderlich ist, der Grund einen schlankeren Ansatz für die autonome Steuerung eines Fahrzeugs zu entwickeln. Im Folgenden wird der sogenannte Direct Perception-Ansatz beschrieben und die technische Umsetzung darge- stellt. Die Ergebnisse stammen aus dem genannten Paper[2] und werden daher nicht gesondert zitiert. 2.2 Grundidee Der Direct Perception-Ansatz positioniert sich zwischen den beiden bekannten Ansätzen Me- diated Perception und Behaviour Reflex, wobei er sich stärker an Letzterem orientiert. Die Grundidee besteht darin, dreizehn Indikatoren aus einem Input-Bild abzuleiten. Damit wird die Informationsmenge eines Bildes der Frontkamera auf das Wesentliche reduziert. Auf Basis dieser dreizehn Indikatoren ist ein nachgelagerter Controller in der Lage das Fahrzeug unfallfrei zu steuern. Die Autoren heben dabei hervor, dass aus den abgeleiteten Faktoren eine direkte Fahranweisung berechnet werden kann. Mediated Perception-Ansätze liefern eine Spline Re- präsentation der Fahrspuren und Bounding Boxen als Darstellung anderer Verkehrsteilnehmer. Diese beiden Informationen müssen erneut interpretiert werden, bevor eine Fahraktion abgeleitet werden kann. Nach Chen, Seff, Kornhauser et al. kann dieser Schritt zusätzliche Ungenauigkeit verursachen und sollte wenn möglich vermieden werden. Im Vergleich zum Behaviour Reflex-Ansatz wird nicht direkt aus dem Kamerabild eine Fahrak- tion abgeleitet, sondern indirekt über die Indikatoren. Damit besteht die Herausforderung des eingesetzten Convolutional Neuronal Networks darin, eine angebracht Belegung der Indikato- ren zu einem Eingangsbild zu finden und nicht darin, die direkte Reaktion zu kennen. Für den Controller, der die Fahraktion berechnet, wird kein Maschine Learning Algorithmus eingesetzt. Dessen Funktionalität wird im Abschnitt 2.4 erläutert. Im Kontrast zum Mediated Perception- Ansatz wird nur eine sehr reduzierte Repräsentation der Umgebung erstellt. Es existiert kein ausgereiftes Umgebungsmodell, sondern lediglich die dreizehn gelernten Indikatoren und zusätz- lich die Position und Geschwindigkeit des Fahrzeuges. Hiermit ist die Fehlerrate während der Erstellung des Modells deutlich kleiner, als bei bekannten Ansätzen[2]. Für die Lösung dieser Regressions-Aufgabe, der korrekten Bestimmung der dreizehn Indikatoren, wird Supervised Learning (siehe 2.6) eingesetzt.
2 Learning Affordance for Direct Perception in Autonomous Driving 8
2.3 Modell - Ableitung der Indikatoren aus einem Bild
Die Autoren fokussieren sich bei ihrer Umsetzung auf das autonome Fahren auf mehrspuri-
gen Highways. Das eingesetzte Convolutional Neuraonal Network unterstützt dabei einspurige,
zweispurige und dreispurige Straßen. Die verschiedenen Szenarien sind in der Abbildung 2.1 ver-
deutlicht. Mittels des gelb gefärbten Sichtfeldes des Fahrzeugs werden die relevanten Fahrspuren
dargestellt.
Dabei genügt es die eigene Fahrspur des zu steuernden Fahrzeugs, sowie die beiden angrenzenden
Spuren im Modell zu berücksichtigen. Befindet sich das Fahrzeug auf der linken oder rechten
Spur, ist es ausreichend diese und die jeweils angrenzende Spur zu betrachten. In diesem Fall
kann die linke bzw. rechte Außenspur vernachlässigt werden. Dies verringert die Komplexität
der Controller Einheit.
(a) Dreispuriger Setup Mitte (b) Dreispuriger Setup Rechts (c) Dreispuriger Setup On Lane
(d) Zweispuriger Setup Rechts (e) Zweispuriger Setup Links (f) Einspuriger Setup
Abbildung 2.1: Fahrszenario aus der Ego-Perspektive
Unabhängig von der Art der Straße führt das Fahrzeug folgende Aktionen autonom durch:
• Folgen der aktuellen Spur
• Spurwechsel, falls ein vorausfahrendes Fahrzeug zu langsam ist
• Bremsen, falls das vorausfahrende Fahrzeug zu langsam ist oder nicht überholt werden
kann
Diese Entscheidungen werden durch eine Controller Software getroffen. Als Eingangsgrößen die-
nen die Ausgangsgrößen des Convolutional Neuronal Networks. Dabei handelt es sich um drei-
zehn Indikatoren, welche in drei Teilbereiche, Distanz zu anderen Fahrzeugen, Distanz zu den2 Learning Affordance for Direct Perception in Autonomous Driving 9 Spurmarkierungen und Fahrzeuginformationen gegliedert werden. Die vollständige Liste aller Indikatoren und deren Wertebereich setzt sich wie folgt zusammen: 1. angle: Winkel zwischen Straßentangente und Fahrzeugwinkel - [-0.5, 0.5] 2. toMarking_LL: Distanz zur linken Straßenmarkierung der linken Spur - [-9.5, -4] 3. toMarking_ML: Distanz zur linken Straßenmarkierung der eigenen Spur - [-5.5, -0.5] 4. toMarking_MR: Distanz zur rechten Straßenmarkierung der eigenen Spur - [0.5, 5.5] 5. toMarking_RR: Distanz zur rechten Straßenmarkierung der rechten Spur - [4, 9.5] 6. dist_LL: Distanz zum vorausfahrenden Fahrzeug der linken Spur - [0, 75] 7. dist_MM: Distanz zum vorausfahrenden Fahrzeug der eigenen Spur - [0, 75] 8. dist_RR: Distanz zum vorausfahrenden Fahrzeug der rechten Spur - [0, 75] 9. toMarking_L: Distanz zur linken Straßenmarkierung - [-7, -2.5] 10. toMarking_M:Distanz zur mittigen Straßenmarkierung - [-2, 3.5] 11. toMarking_R: Distanz zur rechten Straßenmarkierung - [2.5, 7] 12. dist_L: Distanz zum vorausfahrenden Fahrzeug der linken Spur - [0, 75] 13. dist_R: Distanz zum vorausfahrenden Fahrzeug der rechten Spur - [0, 75] Zur Erfüllung der oben genannten Aufgaben verwendet das System zwei Sets zur Repräsen- tationen der aktuellen Verkehrssituation. Das In Lane System und das On Marking System. Abhängig davon welches System aktiv ist, setzt sich der Einfluss der Indikatoren auf die Ab- leitung der Fahraktion zusammen. Mithilfe der Indikatoren und des aktiven/inaktiven Systems kann die Fahrzeugposition zuverlässig festgestellt werden. Die Abbildungen 2.2 und 2.3 zeigen die beiden Situationen. Das In Lane System beschreibt alle Situationen, bei denen sich das Fahrzeug innerhalb einer der Spuren befindet. In diesem Zustand müssen die eigenen und die angrenzenden Spuren be- obachtet werden. Im maximal Fall, bei einer dreispurigen Straße mit der Fahrzeugposition auf der mittleren Spur, müssen drei Spuren bekannt sein. Bei aktivem In Lane System werden die Indikatoren 1-8 zur Steuerung des Fahrzeuges berücksichtigt. Befindet sich das Fahrzeug auf einer Außenspur werden zusätzlich die Indikatoren(toMarking_LL oder toMarking_RR, sowie dist_RR oder dist_LL) nicht verwendet.
2 Learning Affordance for Direct Perception in Autonomous Driving 10
Abbildung 2.2: In Lane System
Abbildung 2.3: On Marking System2 Learning Affordance for Direct Perception in Autonomous Driving 11
Das On Markings System beschreibt alle Situationen, bei denen sich das Fahrzeug zwischen zwei
Spuren befindet. In diesem Zustand werden jeweils die linke und rechte Fahrspur kontrolliert.
Es werden daher immer zwei Spuren, mit Ausnahme eines einspurigen Setups betrachtet. Das
On Markings System wird durch die Indikatoren 1 und 9-13 beschrieben.
Für einen gleitenden Übergang wird ein Überschneidungsbereich zwischen den beiden Systemen
definiert. Befindet sich das Fahrzeug innerhalb dieses Bereichs sind beide Systeme aktiv und es
werden alle Indikatoren für die Ableitung der Fahraktion miteinbezogen.
Abbildung 2.4: Überschneidungsbereich der beiden Systeme
2.4 Controller Berechnung der Fahraktion
Wie bereits im vorangegangenen Abschnitt beschrieben übernimmt eine Software die Steuerung
des Fahrzeuges auf Basis der Ergebnisse des trainierten ConvNets, sowie des aktuellen Fahrzeug-
winkels und Position. Der Controller berechnet mit einer Frequenz von 10 Hz die Steuerungsbe-
fehle.
2.4.1 Lenkbefehl
Das Ziel des Controllers ist es, die Distanz zur Mittellinie der aktuellen Spur zu minimieren.
Definiert man dist_center als Abstand zur dieser Linie, ergibt sich daraus für die Berechnung
des Lenkbefehls die Formel:
steerCmd = C ∗ (angle − distc enter/roadw idth) (2.1)
mit C als ein Koeffizient der unter verschiedenen Verkehrssituationen variiert und angle als
Fahrzeugwinkel zur Straße ∈ [π, -π ]
Verlässt das Fahrzeug die eigene Spur, wechselt die Mittellinie von der aktuellen zur Mittellinie
der Zielspur. Der Code für diese Auswahl ist im Codeauszug 2.1 dargestellt. Der Ausschnitt zeigt
die Logik für eine dreispurige Straße. Entsprechend existiert für die zwei und einspurige Straße
eine eigenen Funktion.2 Learning Affordance for Direct Perception in Autonomous Driving 12
i f ( lane_change ==0){
i f (−toMarking_ML+toMarking_MR2 Learning Affordance for Direct Perception in Autonomous Driving 13
2.4.2 Geschwindigkeit
Zur Kontrolle der Geschwindigkeit des Fahrzeugs wird pro Zeitschritt eine angestrebte Ge-
schwindigkeit berechnet. Der Controller orientiert sich an diesem Wert und lässt die tatsäch-
liche Geschwindigkeit des Fahrzeugs diesem Wert folgen, indem er beschleunigt oder bremst.
Der Ausgangswert der angestrebten Geschwindigkeit ist 72 km\h. Dieser Wert wird bei einer
Kurvenfahrt oder vorausfahrenden Fahrzeugen entsprechend verringert. Zur Berechnung der
Fahrzeuggeschwindigkeit wird folgende Formel eingesetzt.
c
v(t) = v max (1 − exp(− ∗ dist(t) − d)) (2.2)
v max
mit dist(t) als Distanz zu einem vorausfahrenden Fahrzeug, vmax als maximal erlaubte Geschwin-
digkeit und c, d als frei wählbare Koeffizienten.
Die Formel ermöglicht eine gedämpfte Kontrolle der Geschwindigkeit, kann das Fahrzeug aber
bis zum Stillstand bringen.
2.5 Convolutional Neuronal Network
Für die Realisierung des ConvNets zur Lösung des Regression-Problems, setzen die Autoren
des Papers das Framework Caffe[9] ein. Basis der Implementierung ist eine Standard AlexNet
Architektur, die für die Bedürfnisse der konkreten Problemstellung angepasst wird. Ein Unter-
schied ist das Format der Eingabebilder. Diese Trainingsdaten haben eine Auflösung von 280x210
Pixeln. AlexNet wurde mit Bilder im format 256x256 trainiert.
Das CNN besteht aus fünf Convolutional Layern, welche wiederum aus mehreren Unterschichten
(ReLu, Max-Pooling und Normalisierung) bestehen. Darauf folgen vier weitere Fully Connected
Layer. Als Kostenfunktion wird der Algorithmus der Euklidischen Distanz eingesetzt. Aufgrund
der unterschiedlichen Wertebereiche der dreizehn Indikatoren, wird eine Normalisierung der
Werte auf den Bereich [0,1 bis 0,9] vorgenommen.
2.5.1 Convolutional Layers
Die Convolutional Layer zeigen folgenden Aufbau:
1. ConvLayer 1
• Output: 96 Filter
• Kernel Size: 11
• Stride: 4
• ReLu
• Max Pooling 3x3 Stride: 2
2. ConvLayer 2
• Output: 256 Filter
• Kernel Size: 5
• Stride: 0
• ReLu
• Max Pooling 3x3 Stride: 2
3. ConvLayer 32 Learning Affordance for Direct Perception in Autonomous Driving 14
• Output: 384 Filter
• Kernel Size: 3
• Stride: 0
4. ConvLayer 4
• Output: 384 Filter
• Kernel Size: 3
• Stride: 0
• ReLu
5. ConvLayer 5
• Output: 256 Filter
• Kernel Size: 3
• Stride: 4
• ReLu
• Max Pooling 3x3 Stride: 2
Auffällig hierbei ist die Größe des Kernels des ersten und zweiten Convolutional Layers. Er-
fahrungen aktueller Netze zur Bilderkennung zeigen, dass große Filter weniger effektiv bei der
Extraktion von Bildmerkmalen sind, als tiefer verschachtelte kleine Filter (siehe Kapitel 4.3.1).
2.5.2 Fully Connected Layers
Während die Convolutional Layer weitestgehend aus der AlexNet Architektur übernommen sind,
setzen die Autoren bei den Fully Connected Layern auf vier statt drei Schichten und verwenden
einen Output von [4096, 4096, 256, 13]. Der detaillierte Aufbau ist:
1. FullyConnected Layer 1
• Output: 4096
• Bias: 1
• ReLu
• Dropout 0.5
2. FullyConnected Layer 2
• Output: 4096
• Bias: 1
• ReLu
• Dropout 0.5
3. FullyConnected Layer 3
• Output: 256
• Bias: 0
• ReLu
• Dropout 0.52 Learning Affordance for Direct Perception in Autonomous Driving 15
4. FullyConnected Layer 4
• Output: 14
• Bias: 0
• Sigmoid
2.5.3 Kostenfunktion, Parameter und Optimierung
Als Kostenfunktion setzen die Autoren eine angepasste Variante des euklidischen Verlusts ein.
Die Berechnung erfolgt nach der Formel:
m
1 X
L= k ŷ i − y i k22 (2.3)
2m i=1
Da die dreizehn Indikatoren unterschiedliche Wertebereiche aufweisen (siehe 2.3), wird eine
Normalisierung der Werte auf den Bereich [0.1 , 0.9] angewendet.
Als Optimierungsalgorithmus wird Stochastic Gradient Descent mit Momentum eingesetzt. Die-
ser Algorithmus ist eine Erweiterung des Gradient Descent Verfahrens. SGD verringert die enorm
große Rechenzeiten der Optimierung mittels Gradient Descent bei großen Datensätzen. Dies wird
erreicht, indem der Gradient auf Basis einer minimierten Anzahl von Trainingssamples (Mini-
batches) geschätzt wird und nicht über die volle Anzahl aller Daten berechnet wird[5, S.151 f].
Gerade im Bereich des Deep Learnings wird SGD als Optimierungsfunktion eingesetzt, obwohl
nicht die Genauigkeit eines reinen Gradient Descent Verfahrens erreicht wird1 .
Die initiale Lernrate wird auf 0.01 gesetzt. Dies entspricht der gängigen Praxis und der Empfeh-
lung des Caffe Frameworks[4, S. 4]. Aufgrund des Einsatzes von SGD kann keine fixe Lernrate
eingesetzt werden. Diese wird dynamisch nach einer bestimmten Anzahl von Wiederholungen
nach unten korrigiert. Weitere Hintergründe finden sich bei Goodfellow, Bengio und Courville,
S. 294.
Der Einsatz von Momentum verhindert, dass der SGD Optimierer zu stark auf eine Änderung
der Gradienten reagiert und damit ggf. in die falsche Richtung läuft[5, S. 296f].
Dazu bildet das Momentum einen exponentiell zerfallenden gleitenden Mittelwert über die ver-
gangenen Gradienten und folgt deren Richtung.
Der Wert für das Momentum wird im Paper[2]auf 0.9 gesetzt. Dies entspricht der aktuellen
Praxis für das Training eines bisher untrainierten Netzes[9].
2.6 Training
Für das Training des Netzes werden im Rennspiel TORCS Trainingsdaten mit entsprechenden
Labels aufgezeichnet. Für das Training des im Paper beschriebenen Netzes werden auf sieben
Strecken mit unterschiedlichen Straßenlayouts und Asphaltausprägungen Daten gesammelt. Da-
zu wurden 22 Fahrzeuge programmiert diversen Verhaltensmustern zu folgen. Das eigentliche
Testfahrzeug wird dann manuell im Spiel bewegt. Die Strecken wurden mehrfach befahren, um
eine maximale Varianz von Daten zu garantieren. Während der Fahrt zeichnet die Software die
Bilder aus der Egoperspektive auf, komprimiert diese auf 280x210 Pixel und speichert diese
gemeinsam mit den Labels in einer Datenbank. Da Caffe eingesetzt wird, ist die Datenbanktech-
nologie auf LevelDB festgesetzt2 von Google. In Summe wurden 484815 Bilder aufgenommen.
1
Dies ist allerdings nicht notwendig, da bei sehr großen Trainingsdatensätzen das tatsächliche Minimum nicht
in Realzeit erreicht werden kann.
2
https://github.com/google/leveldb2 Learning Affordance for Direct Perception in Autonomous Driving 16 Das Training erfolgt von Beginn mit einem vollkommen untrainierten ConvNet und einer in- itialen Lernrate von 0.01. Pro Batch wurden 64 Bilder zufällig aus dem Trainingsdatensatz ausgewählt. Nach 140000 Wiederholungen ist der Vorgang beendet. 2.6.1 Vorverarbeitung Bevor die Bilder für das Training genutzt werden, wird eine Normalisierung der Daten vor- genommen. Dies erfolgt über die Mittelwerts-Subtraktion. Es wird über alle Bilder aus dem Trainingsdatensatz jeweils der Mittelwert der drei Farbkanäle gebildet. Dieser wird dann von jedem Trainingssample pro Kanal subtrahiert. Die Operation ergibt eine Zentrierung um den Wert Null. Die Vorverarbeitung verbessert den Trainingsprozess erheblich[5, S. 318]. 2.7 Test und Validierung Der erste Test des Systems findet innerhalb der Simulation TORCS statt. Das Testing findet auf einer neuen Strecke, mit neuen Fahrzeugen statt, die nicht in den Trainingsdaten enthalten sind. In der Software ist es möglich die tatsächliche Position des gesteuerten, aber auch der anderen Fahrzeuge abzugreifen. Damit kann eine grafische Oberfläche generiert werden, die Realität der Einschätzung des trainierten Netzes gegenüberstellt. Darüber hinaus kann durch das Verhalten des kontrollierten Fahrzeuges abgeleitet werden, ob das System korrekt arbeitet. Der Testsetup wird im Abschnitt 3.2.3 gezeigt. Bei den Tests zeigt sich, dass das autonome Fahrzeug ohne Kollisionen und Fehlverhalten auf der Strecke bewegt wird. Bei vereinzelten Manövern zum Spurwechsel wird die Außenlinie der neue Spur kurzzeitig überfahren. Dieser Fehler wird aber schnell korrigiert. Insbesondere die Spurvorhersage funktioniert einwandfrei. Bei der Erkennung von fremden Fahrzeugen zeigte sich eine sehr gute Genauigkeit innerhalb von 30 Metern. Bei größeren Distanzen zwischen 30 und 60 Metern wird die Vorhersage ungenauer. Dieser Sachverhalt wird auf die geringe Auflösung der Trainingsdaten zurückgeführt, da hier ein Fahrzeug in 60 Metern Distanz lediglich als sehr kleiner Punkt wahrgenommen werden kann. Aus diesem Grund ist das System nur für Geschwindigkeiten bis 80 km\ einsetzbar. Nach der ersten Validierung in TORCS vergleichen die Autoren den Direct Perception-Ansatz zusätzlich mit weiteren Technologien, um weiterführende Aussagen über die Qualität der Um- setzung zu gewinnen. 2.7.1 Behaviour Reflex ConvNet Der erste Vergleich wird mit einem Behaviour Reflex-ConvNet durchgeführt. Dieses Netz bildet auf ein Eingangsbild direkt eine Fahraktion ab. Der Test bezieht sich zum einen auf das Halten der Spur. Hierbei besteht der Trainingsdatensatz (60000 Bilder) ausschließlich aus Bildern einer leeren Strecke. Zum andern soll das Fahrzeug im Verkehr keine Kollisionen verursachen. Für diesen Test werden Trainingsdaten (80000 Bilder) mit Verkehr aufgezeichnet. Als Resultat lässt sich festhalten, dass die Spur ohne fremde Fahrzeuge zuverlässig erkannt wird. Bei der Vermeidung von Kollisionen zeigt sich ein anderes Bild. Das System vermeidet zwar ab und an einen Crash, das Verhalten ist aber eher zufällig als kontrolliert[2, S. 5]. Bei der Evaluierung dieser Baseline muss erwähnt werden, dass der Trainingsdatensatz signi- fikant kleiner gewählt wurde als der des Direct Perception-Ansatzes. Damit sind die beiden Versuche aus Sicht des Autors dieser Arbeit nicht vergleichbar.
2 Learning Affordance for Direct Perception in Autonomous Driving 17
2.7.2 Mediated Perception (Lane Detection)
Im zweiten Vergleich tritt das Direct Perception-Modell gegen den Caltech3 Spurerkennungsalgo-
rithmus an. Für den Test wird ein Support Vector Machine4 System bestehend aus acht Support
Vector Regressions und sechs Support Vector Classification Modellen zusammengesetzt. Imple-
mentiert wird das System mit Hilfe von libsvm5 .
Für das Training des Systems werden ausschließlich Bilder ohne Verkehr aufgezeichnet. Die
Größe des Datensatzes beschränkt sich auf 2500 Bilder.
Die Ergebnisse zeigen, dass der Direct Perception-Ansatz trotz der geringen Anzahl von Da-
ten besser als der Caltech Algorithmus funktioniert. Die Ergebnisse werden in Abbildung 2.5
verdeutlicht. Sie zeigt den Mittleren Absolut Fehler beider Systeme.
Abbildung 2.5: MEA Caltech vs. ConvNet
2.7.3 Direct Perception with GIST
Als dritter Vergleich werden mittels eines GIST Deskriptors6 die dreizehn Indikatoren für ein
Eingangsbild abgeleitet. Dabei unterteilt der Deskriptor das Bild in 4x4 Segmente, wobei die
unteren beiden Segmente deutlich relevanter für die Ableitung der Indikatoren sind, da sie die
nähere Umgebung des Fahrzeuges zeigen. Das System wird mit ca. 90000 Datensätzen trainiert.
Damit der Vergleich zwischen den beiden Netzen fair ist, wird ein neues ConvNet auf Basis des
Direct Perception-Ansatzes mit einem angepassten Datensatz trainiert. Darin sind 8900 Samples
enthalten.
Auch in diesem Vergleich schneidet das ConvNet deutlich besser als der GIST Deskriptor ab.
Es zeigt sich aber, dass die Genauigkeit stark von der Anzahl der Trainingssamples abhängt.
2.7.4 Test mit realen Eingangsdaten (KITTI)
Zuletzt wird das ConvNet von Chen, Seff, Kornhauser et al. mit realen Daten getestet. Hierzu
wurden zwei unterschiedliche Szenarien geprüft. Im ersten Test wird das mit TORCS Daten
trainiert Netz auf realen Daten einer Smartphone Kamera getestet. Dabei wird deutlich, dass die
Spurerkennung zuverlässig funktioniert. Die Erkennung von fremden Verkehrsteilnehmern zeigt
Ungenauigkeiten. Dies ist darauf zurückzuführen, dass die einfach gehaltenen Fahrzeugmodell
aus der Rennsimulation zu stark von der Form realer Fahrzeuge abweichen. Im zweiten Szenario
wird dasselbe ConvNet mit den Daten aus dem KITTI7 Datensatz trainiert und getestet. Das
Hauptziel dieses Tests ist die korrekte Erkennung der Distanz zu vorausfahrenden Fahrzeugen.
3
http://www.mohamedaly.info/software/caltech-lane-detection
4
SVM sind sogeannte Large Margin Classifier, die das Ziel haben eine Menge von unterschiedlichen Objekten so
zu unterteilen, dass um die Klassengrenzen möglichst große Freiräume entstehen. Für weitere Ausführungen
siehe [5, S. 140ff]
5
https://www.csie.ntu.edu.tw/ cjlin/libsvm/
6
Ein GIST Deskriptor beschreibt ein Bild mit Fokus auf der Trennung unterschiedlicher Bereiche und ignoriert
die gezeigten Objekte an sich. Eingeführt wurde er von Olivia et al im Jahr 2001. Für weitere Ausführungen
zu GIST Deskriptoren siehe [10]
7
Das KITTI Datenset enthält 180 GB Bild und Sensordaten aus Fahrten mit einem Testfahrzeug aus ganz
Europa. [11].2 Learning Affordance for Direct Perception in Autonomous Driving 18
Als Referenz wird die Performance eines State of the Art DPM Algorithmus8 zur Erkennung
von Fahrzeugen herangezogen.
Da in den meisten KITTI Samples keine Fahrspurmarkierungen vorhanden sind, wird ein x,y
Koordinatensystem entworfen, indem das ConvNet die Position des Fahrzeugs feststellen kann.
Weiterhin wird eine Blickweite definiert, da das ConvNet bekannte Schwierigkeiten bei der Er-
kennung von weit entfernten Fahrzeugen hat. Die relevante Blickweite beträgt im Test 2 bis 25
Meter.
Zusätzlich werden die Bilder des Trainingsdatensatzes auf eine Auflösung von 497x150 Pixel
verkleinert.
Das Trainingsset besteht aus 61894 Samples. Dieses wird über 50000 Wiederholungen trainiert.
Im Vergleich zu einem DPM Ansatz schlägt sich das ConvNet passabel und weißt nur wenige
False Positive9 Fehler auf. Laut Chen, Seff, Kornhauser et al. kann dieses Problem durch eine
Vergrößerung des Trainingssets verringert werden.
2.8 Zusammenfassung und Bewertung
In den Ausführungen von [2] wird ein durchweg positives Fazit bezüglich des neuen Direct Per-
ception-Ansatzes gezogen. In fast allen Vergleichen zu anderen Systemen schneidet das ConvNet
besser oder gleich gut ab.
Diese positive Einschätzung wird allerdings durch die Beschränkungen des Ansatzes getrübt.
Beispielsweise funktioniert dieser ausschließlich auf einem Highway ohne Gegenverkehr mit an-
deren Verkehrsteilnehmern, die immer langsamer sind als das gesteuerte Fahrzeug. Eine weitere
Einschränkung ist die Geschwindigkeit. Das System funktioniert ausschließlich bis zu einer ma-
ximal Geschwindigkeit von 80 km\h, was dem Einsatzgebiet auf dem Highway widerspricht.
Gleichzeitig wirken die im Paper aufgeführten Vergleiche konstruiert. Insbesondere der Vergleich
zu einem GIST Deskriptor ist sehr aufwändig dargestellt und es sind etliche Mappings notwendig,
bis die beiden System vergleichbar sind.
Beeindruckend ist allerdings die Tatsache, dass ein virtuell trainiertes Modell in der Lage ist
Fahrspuren auf realen Bildern zu erkennen.
Kapitel 5 beschäftigt sich weiter mit den Schwachstellen und möglichen Verbesserungen des
Systems.
8
Deformable Part Modelle basieren auf dem Versuch Teilausschnitte in einem Bild zu erkennen, die in diversen
Blickwinkeln vorkommen. Nach dem Training werden diese Elemente zuverlässig erkannt. Weitere Ausführun-
gen finden sich bei [12].
9
Unter False Positive versteht man die Erkennung eines Objektes, obwohl diese nicht existiert.3 Analyse des Codes Im Rahmen dieses Kapitels wird im Detail auf die Implementierung des Convolutional Neuronal Networks, welches theoretisch im Kapitel 2 beschrieben wurde, eingegangen. Dazu wird der mitgelieferte Code auf einem Rechner im Labor für Bildverarbeitung installiert und eingesetzt. Zur Demonstration der Funktion werden zwei CNNs auf Basis der AlexNet Architektur aus [2] trainiert. Im ersten Versuch wird ausschließlich die Fähigkeit des Spurhaltens und im zweiten Versuch der komplette Umfang des autonomen Fahrens trainiert und getestet. 3.1 Installation und Setup Der Code zum Projekt Deep Driving kann über die Homepage der Universität Princeton1 ab- gerufen werden. Dort ist zum einen der Code für das ConvNet, die angepassten Komponenten für TORCs und das Framework Caffe und zum anderen auch das vollständige Trainingsset für die Versuche aus dem Paper verfügbar. Im Rahmen dieser Seminararbeit wird nicht das voll- ständige Trainingsset bestehend aus 480000 Bildern eingesetzt, da das Training des Netzes zu viel Zeit in Anspruch nehmen würde. Weiterhin weißt Liu und Wang[4] darauf hin, dass das Trainingsset fehlerhafte Bilder enthält. Bevor die Software eingesetzt werden kann müssen eini- ge Schritte zur Installation durchgeführt werden. Die mitgelieferte Anleitung der Autoren des Papers unterstützt diesen Vorgang. Die Installation wird auf dem Laborrechner CB06 des Labors für Bildverarbeitung der Hoch- schule München durchgeführt. Das eingesetzte Betriebssystem ist CentOs 7. Für die Installation wird der angemeldete Nutzer in das sudoer File hinzugefügt, da einige Software Bibliotheken nachinstalliert werden müssen. 3.1.1 TORCS Ein Teil der Installation ist das Open Source Rennspiel TORCS. Die Simulation ist ein Multi- Plattform2 Rennspiel, das neben der Verwendung als Rennsimulation für eine Vielzahl von For- schungsprojekten im Bereich KI und autonomes Fahren eingesetzt wird. Die Entwicklung des Spieles begann bereits 1997 unter der Feder von Eric Espié und Christophe Guionneau. Mittler- weile ist TORCS in der Version 1.3.8 verfügbar. Für die Realisierung des Papers wird die Version 1.3.7 eingesetzt. Programmiert wurde die Software in C++. Dies ermöglicht eine einfache und grenzenlose Erweiterung. Diese ist insbesondere für die Forschungsprojekt wichtig ist, da hier die Software speziellen Anforderungen angepasst wird. Weiterhin ist es möglich die Robots 3 voll- kommen frei zu programmieren. Somit können unterschiedlichste Verhaltensmuster dargestellt werden. Installation Bevor die Installation von TORCS starten kann werden die folgenden Bibliotheken auf dem System installiert. Dies geschieht über den CentOs Paketmanager „yum“: 1 http://deepdriving.cs.princeton.edu/ 2 Windows, Linux, MacOS, Free BSD 3 Computergesteuerte Fahrzeuge
3 Analyse des Codes 20
1. Hardware accelerated OpenGL
2. FreeGlut
3. PLIB 1.8.5 version
4. OpenAL
5. libpng und zlib
6. libogg/vorbis
Nachdem alle Abhängigkeiten aufgelöst wurden kann TORCS mithilfe der folgenden Komman-
dos installiert werden:
1. ./configure
2. make install
3. make datainstall
Nach erfolgreicher Installation kann das Spiel unter usr/local/bin/torcs ausgeführt werden.
Für die Anwendung im Deep Driving Projekt werden nach der Installation die zusätzlichen
Strecken in den entsprechenden Ordner des Spiels kopiert. Bei den Strecken handelt es sich
um ein-, zwei- und dreispurige Varianten der ursprünglichen Rennstrecken des Spiels. Diese
weisen ohne Manipulation keine dedizierten Fahrspuren auf. Zusätzlich wurden die Graustufen
der Fahrbeläge verändert, sodass ein weites Spektrum an Trainingsdaten generiert werden kann.
3.1.2 Caffe Driving
Für die Umsetzung des Convolutional Neuronal Networks wird im Projekt das Framework Caf-
fe4 eingesetzt. Das Framework wurde von Yangqing Jia im Rahmen seiner Doktorarbeit am
Vision und Learning Centre der University of California, Berkeley entwickelt. Die erste Version
wurde im Jahr 2014 veröffentlicht. Aktuell liegt das C++ Framework in der Version „1.0rc5“
vor. Mit Caffe wurde die Realisierung von schnellen CNNs von Matlab nach C++ portiert. Mit
der Unterstützung des Cuda5 Frameworks von Nvidia und dem Einsatz unterstützter Grafik-
karten können CNNs sehr schnell trainiert werden. Die Verarbeitung von CNNs kann zusätzlich
durch die Verwendung der Cuda Deep Neuronal Network Bibliothek von Nvidia6 beschleunigt
werden. Diese steht nach einer kostenfreien Registrierung bei Nvidia, für diverse Plattformen
zum Download bereit.
Für das Projekt wird das Framework an diversen Stellen modifiziert. Auf diese Änderungen wird
teilweise im folgenden Verlauf eingegangen. Eine Liste aller editierten und neuen Dateien findet
sich in der README Datei der Autoren.
Installation
Die Installation von Caffe unter CentOs folgt der Anleitung auf der Homepage des Frameworks:
http://caffe.berkeleyvision.org/install_yum.html
Für die Installation müssen folgende Bibliotheken vorhanden sein:
1. protobuf-devel
4
http://caffe.berkeleyvision.org/
5
http://www.nvidia.de/object/cuda-parallel-computing-de.html
6
https://developer.nvidia.com/cudnn3 Analyse des Codes 21
2. leveldb-devel
3. snappy-devel
4. opencv-devel
5. boost-devel
6. hdf5-devel
7. atlas-devel
Zusätzlich wird für den Einsatz einer Nvidia Grafikkarte das Cuda Framework inklusive aller
Treiber manuell installiert. Die Treiber finden sich auf der Homepage7 von Nvidia. Für das Pro-
jekt Deep Driving ist eine Nvidia Karte zwingend erforderlich, da die optionalen C++ Dateien
direkt auf die Grafikkarte zugreifen.Im Gegensatz zur reinen Caffe Version, kann ohne diese
Hardware das Projekt Caffe Driving nicht kompiliert und eingesetzt werden. Dies ist auch der
Grund weswegen das Projekt im Labor durchgeführt wird.
Nachdem alle Voraussetzungen erfüllt sind, wird Caffe mit dem Befehl „make all“ installiert.
Die folgend Abbildung zeigt den kompletten Aufbau des Systems und die Kommunikationswege
zwischen TORCS - ConvNet - Controller.
Abbildung 3.1: Gesamtsystem Caffe Drving mit TORCS
3.1.3 Schwierigkeiten und Hindernisse
Sowohl bei der Installation von TORCS als auch bei Caffe Driving kam es zu einigen Schwierig-
keiten, die den zeitlichen Aufwand der Installation deutlich vergrößerten. Beispielsweise mussten
für TORCS Modifikationen im Makefile durchgeführt werden, um die Pfade der benötigen Bi-
bliotheken anzupassen, da auf den Laborrechnern 32Bit und 64 Bit Varianten der jeweiligen
7
urlhttps://developer.nvidia.com/cuda-downloads3 Analyse des Codes 22
Bibliotheken vorhanden waren. TORCS setzt aber die 64 Bit Version voraus, da nur diese als
Shared Object kompiliert wurde.
Bei Caffe verursachte insbesondere die Bibliotheken „openBlas und Atlas“ Probleme. Da der
Build des Frameworks des Projektes auf einer Ubuntu Umgebung aufgesetzt wurde, gab es
Schwierigkeiten mit der Kompatibilität für CentOs. Für CentOs existiert keine Bibliothek für
„BLAS“, diese muss über „satlas“ und „tatlas“ aufgelöst werden. Diese Problem konnte mit
einer Veränderung des Makefiles und der Makefile.config Datei gelöst werden.
Der Einsatz von cuDNN ist für das Projekt Caffe Driving nicht möglich, da eine ältere Version
von Caffe eingesetzt wird. Das Framework unterstützt cuDNN in der Version 5 und 6 nicht. Für
die Kombination mit einer Nvidia Grafikkarte der Pascal Architektur8 ist dies aber zwingend
erforderlich. Diese Tatsache sorgt für deutlich längere Trainingszeiten der Netze.
3.2 Einsatz von Caffe Driving
Für die Analyse und Bewertung des Codes werden im folgenden zwei CNNs mit unterschiedli-
cher Zieldefinition trainiert. Das erste Netz soll ausschließlich für die Erkennung der Fahrspur
eingesetzt werden, sodass im Test ein Fahrzeug auf einem dreispurigen Rundkurs autonom Fah-
ren kann, ohne die Spur zu verlassen. Das zweite Netz soll ein Fahrzeug autonom auf einem
dreispurigen Rundkurs mit Verkehr steuern. Diese Aufgabe ist deutlich komplexer und benötigt
daher ein größeres Set von Trainingsdaten. Im Allgemeinen werden in den beiden Versuchen
deutlich weniger Trainingsdaten, als im Paper verwendet. Dies soll die Frage klären, ob sich
bereits mit einer kleineren Anzahl Daten, sinnvolle Erfolge erzielen lassen.
3.2.1 Sammeln von Trainigs-Daten
Das Framework Caffe Driving bietet eine Möglichkeit über das Rennspiel TORCS Trainingsbilder
mit den zugehörigen Labeln (siehe Beschreibung der Indikatoren im Abschnitt 2.3) aufzuzeich-
nen.
Dazu muss die Datei „torcs_data_collector.cpp“ angepasst werden. Im Code wird der Pfad zur
LevelDB Datenbank angegeben, in welcher die Daten gespeichert werden. Für das Sammeln der
Daten im Rahmen dieser Arbeit wird die Datenbank „TORCS_Training_Patrick“ gespeichert.
Zum Sammeln der Daten wird dann zuerst TORCS und danach die C++ Datei gestartet. Die
beiden Programme kommunizieren mittels Shared Memory miteinander. Innerhalb von TORCS
kann das Rennen konfiguriert werden. Dazu zählt die Auswahl einer Strecke und der Anzahl
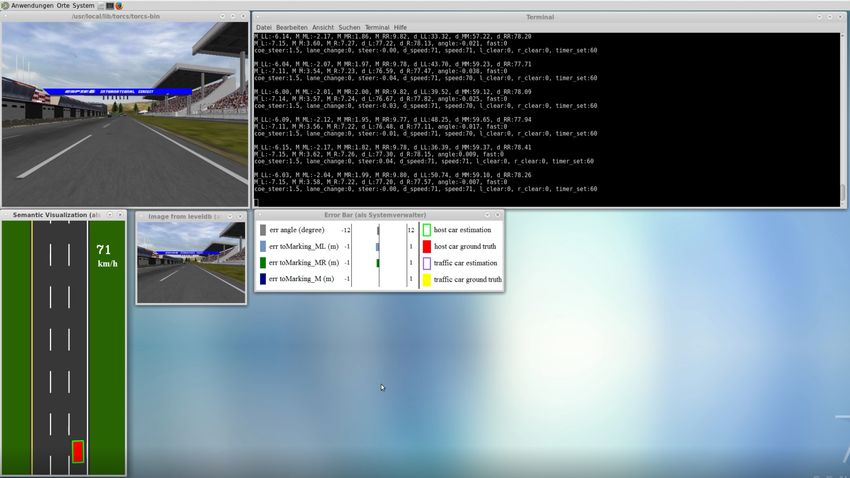
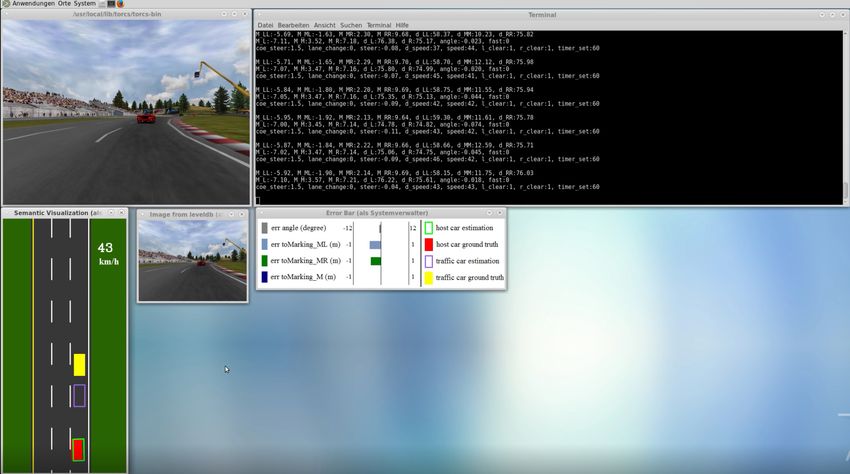
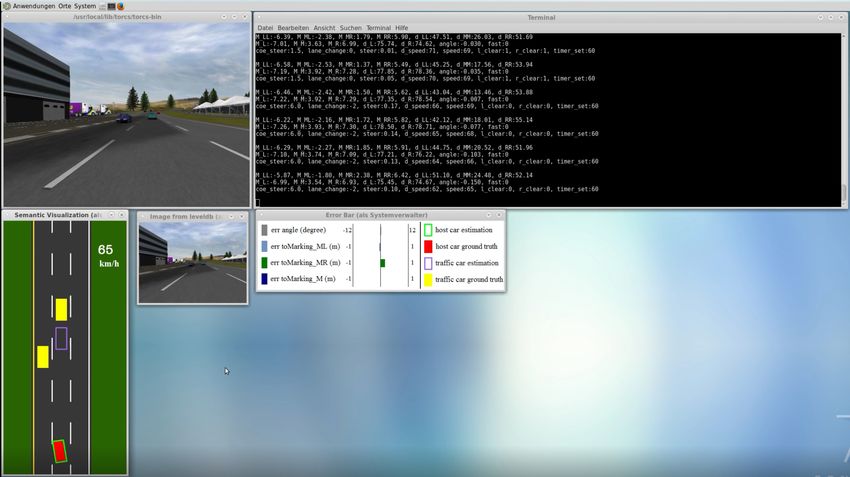
computergesteuerter Fahrzeuge. Der Setup ist in Abbildung 3.2 dargestellt. Wichtig bei der
Aufzeichnung ist, dass die Default Bildschirm Auflösung von TORCS nicht verändert wird, da
in diesem Fall die Belegung der Labels nicht mehr zu den Parametern der Controller Komponente
passen9 .
Sammeln ohne Verkehr
Für den ersten Versuch werden 3211 Bilder plus deren Labels aufgezeichnet. Dazu wird ein
Fahrzeug manuell auf einer dreispurigen Strecke für drei Runden bewegt. Dabei ist die Strecke
leer. Es gibt keine computergesteuerten Fahrzeuge, da das Ziel dieses Versuches ausschließlich
das Erkennen der Fahrspur ist. Abbildung 3.3 zeigt ein Trainingssample inklusive der dreizehn
Indikatoren.
8
http://www.nvidia.de/graphics-cards/geforce/pascal/
9
Aufgrund dieser Tatsache, musste das Trainig für beide Tests wiederholt werden, da die Auflösung initial
verändert worden war.Sie können auch lesen

















































