NLP-Trend: Neuronale Sprachmodelle gewinnbringend in die Unternehmenspraxis integrieren - Live-Webinar
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Live-Webinar:
NLP-Trend: Neuronale Sprachmodelle
gewinnbringend in die
Unternehmenspraxis integrieren
dida Datenschmiede GmbH
29.06.2021 www.dida.do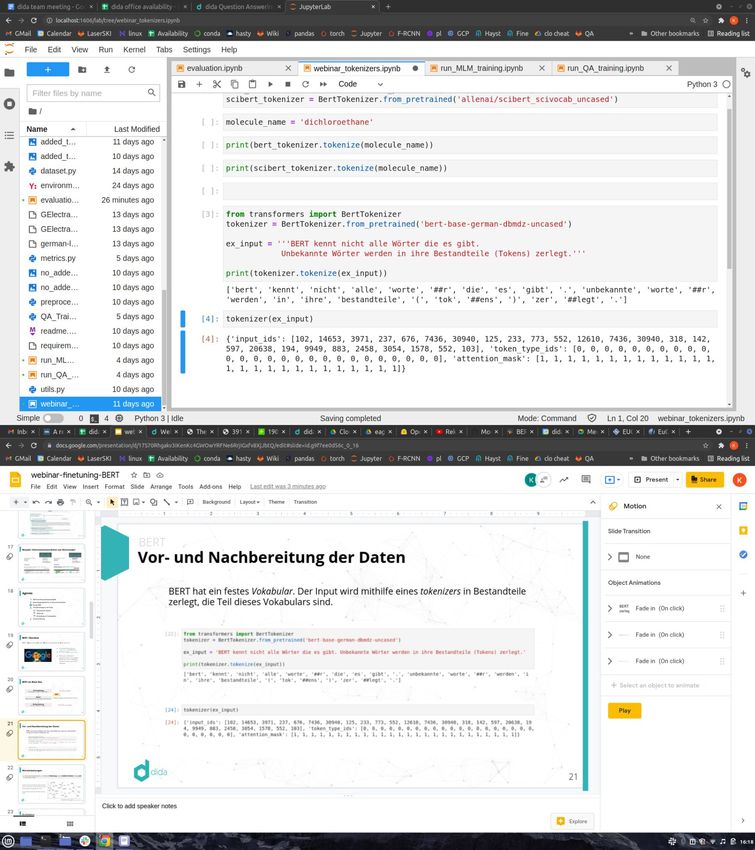
Dieser Vortrag wird gehalten von...
● Machine Learning Scientist bei dida
● M. Sc. Mathematik, Technische Universität
Berlin
Konrad Mundinger
E-Mail: Videoaufzeichnung und Slides:
konrad.mundinger@dida.do https://dida.do/de/webinare/
2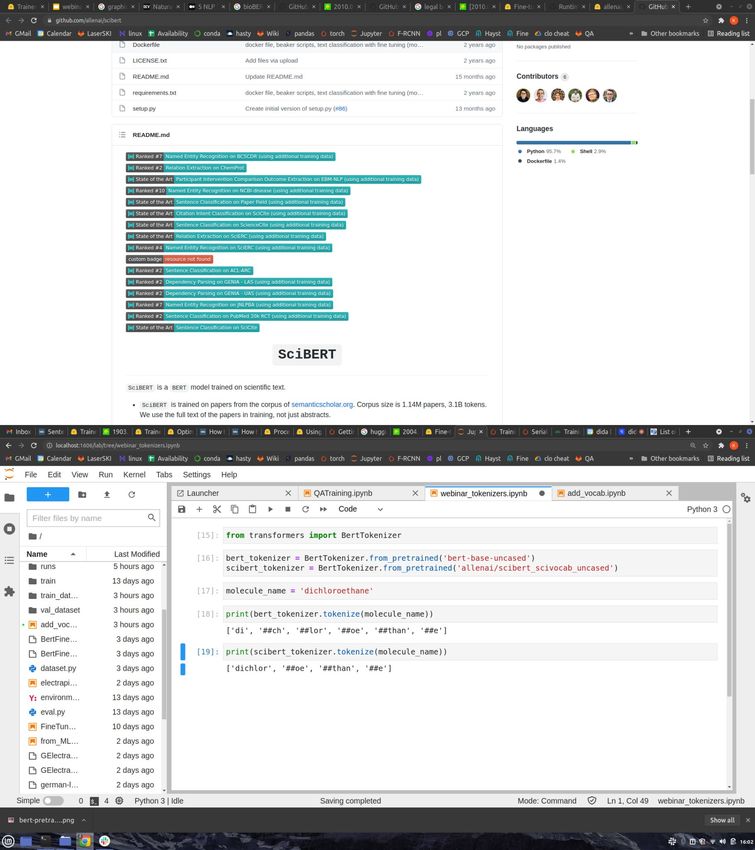
dida verfügt über ein erfahrenes Team von
Wissenschaftlern für maschinelles Lernen
30 Entwickler
25 Projekte
10 PhDs
3
dida ist auf Computer Vision und Natural Language
Processing spezialisiert
Computer Vision Natural Language Processing (NLP)
Beispielprojekt Beispielprojekt
4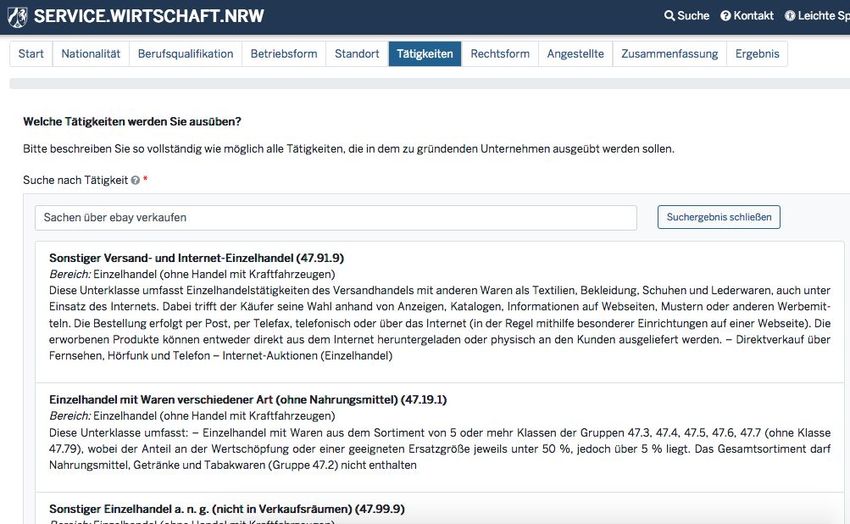
Agenda
1 NLP-Trend: Neuronale Sprachmodelle
2 Anwendungsmöglichkeiten im Unternehmenskontext
3 Beispiel BERT
4 Herausforderungen in der Praxis
4.1 Anpassung der Sprache
4.2 Skalierung
4.3 Beschaffung von Trainingsdaten
5 Zusammenfassung
dida.do
5
Agenda
1 NLP-Trend: Neuronale Sprachmodelle
2 Anwendungsmöglichkeiten im Unternehmenskontext
3 Beispiel BERT
4 Herausforderungen in der Praxis
4.1 Anpassung der Sprache
4.2 Skalierung
4.3 Beschaffung von Trainingsdaten
5 Zusammenfassung
dida.do
6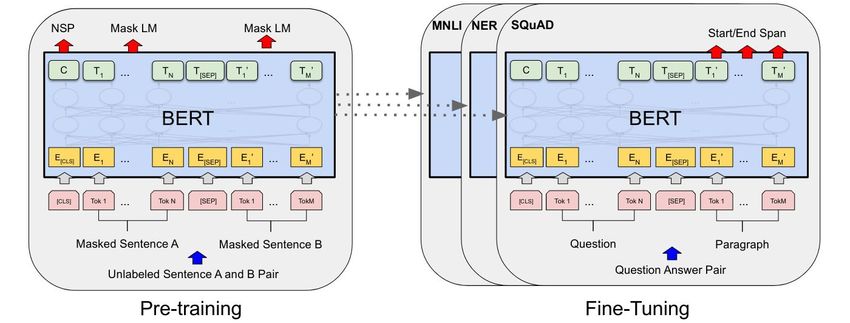
NLP-Trend
Neuronale Sprachmodelle
● (tiefe) neuronale Netze, deren Input Textdaten sind
● Vielzahl von Anwendungsmöglichkeiten:
➢ Übersetzung
➢ Semantische Suche
➢ Informationsextraktion
➢ Automatisierte Beantwortung von Fragen
➢ Klassifizierung von Texten (positive/negative
Bewertung) etc...
7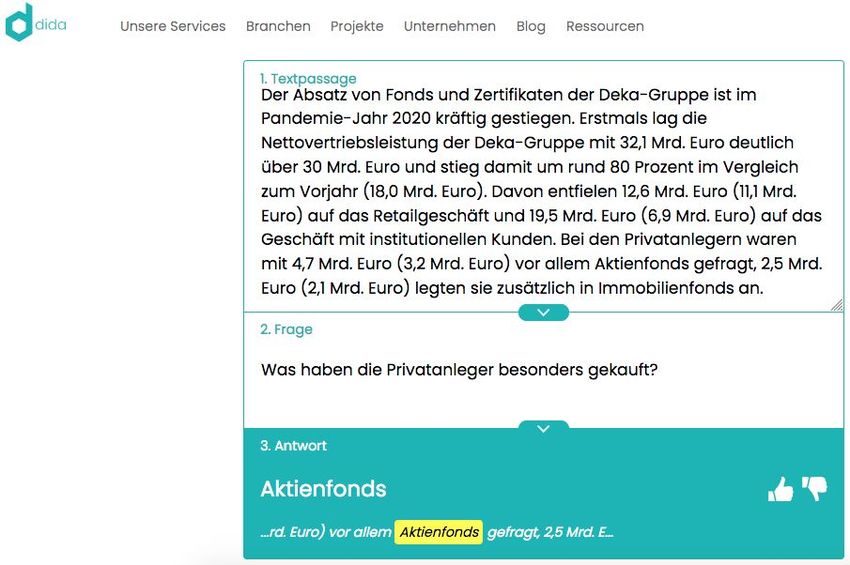
NLP-Trend
Neuronale Sprachmodelle: Geschichte (Teil 1)
● 2000 - Ein neuronales Netz zur Vorhersage des nächsten Wortes in einem Satz. [Bengio et. al]
● 2008 - Multi-task-learning: Die Idee, Neuronale Netze für eine Vielzahl von Aufgaben gleichzeitig zu
trainieren. [Collobert & Weston]
● 2013 - Worteinbettungen: Effizienter Algorithmus zur Berechnung eines embeddings, in dem
semantische Ähnlichkeit von Wörtern sich in der Geometrie der zugehörigen Vektoren widerspiegelt
[Mikolov et. al]
● 2013 - Einbeziehung fortgeschrittener Netzwerkarchitekturen in NLP-Aufgaben, insbesondere CNNs
[Kalchbrenner et. al] und RNNs [Graves et. al] - Stichwort LSTM
Quelle und weiterführende Informationen 8
NLP-Trend
Neuronale Sprachmodelle: Geschichte (Teil 2)
● 2015: Attention - Ein Meilenstein. Der Attention-Mechanismus erlaubt es einem neuronalen Netz
Beziehungen zwischen allen Elementen der Input-Sequenz abzubilden [Bahdanau et. al]
● 2017: Attention is all you need - Die Transformer Architektur beruht ausschließlich auf dem
Attention-Mechanismus und wurde zum neuen Standard in der NLP Welt [Vaswani et. al]
● Ab 2018: Vortrainierte Modelle: Große Modelle, die auf riesigen Datenmengen trainiert wurden und
für eine Vielzahl von Aufgaben geeignet sind. Beispiele: Google’s BERT [Devlin et. al], OpenAI’s GPT
[Radford et. al], XLNet [Yang et.al] ...
Quelle und weiterführende Informationen 9
Beispiel: DeepL Übersetzer
Link: deepl.com 10Beispiel: BERT-basierte Informationsextraktion
Link zu unserer QA-Demo 11Beispiel: BERT-basiertes Question Answering
Link zu unserer QA-Demo 12Agenda
1 NLP-Trend: Neuronale Sprachmodelle
2 Anwendungsmöglichkeiten im Unternehmenskontext
3 Beispiel BERT
4 Herausforderungen in der Praxis
4.1 Anpassung der Sprache
4.2 Skalierung
4.3 Beschaffung von Trainingsdaten
5 Zusammenfassung
dida.do
13Neuronale Sprachmodelle
Anwendungsmöglichkeiten im Unternehmenskontext
Kunden
Unternehmen
Lieferanten *
*
*
Interne
*
Datenbank
Unstrukturierter
* Text
14Neuronale Sprachmodelle
Anwendungsmöglichkeiten im Unternehmenskontext
Ein großer Teil von Textdaten im Neuronale Sprachmodelle sind in
Unternehmenskontext ist der Lage, unstrukturierten Text
unstrukturiert. zu verstehen.
Konkrete Anwendungsfälle:
Informationsextraktion Rechtliche Bewertung von
aus Rechnungen / Bestellungen Kostenaufstellungen/Verträgen
Semantische Suche / Question
Answering auf Grundlage einer
internen Datenbank
15Beispiel: Semantische Suche
Link 16Beispiel: Informationsextraktion aus Rechnungen
17Agenda
1 NLP-Trend: Neuronale Sprachmodelle
2 Anwendungsmöglichkeiten im Unternehmenskontext
3 Beispiel BERT
4 Herausforderungen in der Praxis
4.1 Anpassung der Sprache
4.2 Skalierung
4.3 Beschaffung von Trainingsdaten
5 Zusammenfassung
dida.do
18BERT
BERT: Überblick
BERT = Bidirectional Encoder Representations from Transformers
● Neuronales Netz, baut auf
Transformer-Architektur auf
● 2018 von Google veröffentlicht
● Wird quasi unüberwacht
(self-supervised) auf einer großen
Menge von frei zur Verfügung
stehenden Daten trainiert (z.B.
Quelle wikipedia)
19BERT
BERT als Black Box
Vorverarbeitung
“Von Text zu Zahlen”
Tokenization, initiales Embedding, ...
BERT
Modell
“Zusammenhänge zwischen Zahlen nutzen”
Mathematische Berechnungen (auf Vektoren)
Nachbearbeitung
“Von Zahlen zu Aussagen”
Scores, Textgenerierung, ...
20BERT
Vor- und Nachbereitung der Daten
BERT hat ein festes Vokabular. Der Input wird mithilfe eines tokenizers in Bestandteile
zerlegt, die Teil dieses Vokabulars sind.
21BERT
Worteinbettungen
Lerne eine Zuordnung Text → Vektorraum (Einbettung), sodass inhaltlich ähnliche Einträge nah
beieinander liegen.
Ähnliche semantische Beziehungen zwischen
Wörtern sollen durch ähnliche relative Lage im
Einbettungsraum ausgedrückt werden
Fertige Implementierungen: Word2vec, fasttext,
GloVe
Word2Vec Einbettungen (exemplarisch)
22BERT
Architektur
● BERT beruht auf der Transformer Architektur,
benutzt allerdings nur den Encoder Teil
● Nach dem embedding-layer folgen 12 bez. 24
identische Layer (Aufbau siehe rechts)
● Schließlich folgt ein aufgabenspezifischer
Output-Layer
● Dazwischen skip-connections und
Normierungslayer
Quelle
23BERT
Architektur
Aufgabenspezifischer Output Layer (Head)
Attention (und mehr)
.
.
.
Attention (und mehr)
Input Layer (Einbettungen)
24BERT
Attention
Idee: Beziehungen zwischen den Elementen einer Sequenz lernen
“Was” “wir” “brauchen,” “ist” “Aufmerksamkeit”
Attention Layer
“Was” “wir” “brauchen,” “ist” “Aufmerksamkeit”
25BERT
Attention
Idee: Beziehungen zwischen den Elementen einer Sequenz lernen
vs.
Quelle und weiterführende Informationen 26BERT
Attention: Berechnung
Berechne dafür für jeden
Berechne nun für jedes
Input-Vektor einen Key-, Query-
2. Wort i aus dem Input das
1. und Value-Vektor durch
Multiplikation mit Matrizen , Skalarprodukt .
und . mit allen anderen Wörtern j.
Wende (für festes i)
3.
= nach einer Normierung softmax ( ) =1
die softmax Funktion
an
=
4. Multipliziere die
Ergebnisse mit den softmax ( )
= Value-Vektoren
5. Bilde die Summe über die
gewichteten Value-Vektoren - fertig!
Weiterführende 27
InformationenBERT
Architektur
Aufgabenspezifischer Output Layer (Head)
Beispiele:
● QA-Head: gibt die Positionen aus,
an denen sich die Antwort auf die
Attention (und mehr) Frage befindet
● Classification-Head: gibt eine
. Wahrscheinlichkeitsverteilung
. über den Klassen aus
.
● NER-Head
.
.
.
Attention (und mehr)
● MLM- oder NSP-Head
Input Layer (Einbettungen)
28BERT
Pre-Training: MLM & NSP
Das Pre-Training von BERT beruht
auf
Masked Language Modeling und
Next Sentence Prediction.
Die Trainingsdaten werden aus
frei verfügbaren Textdaten
generiert (z.B. Wikipedia,
wissenschaftliche Publikationen,
etc.)
Quelle
29BERT
Masked Language Modeling
Baue allgemeines Sprachverständnis durch
ausfüllen von Lückentexten auf.
● Dazu wird ein spezielles [MASK] -
[Was] [wir] [brauchen] [,] [ist] [Auf] [##merk] [##sam]
Token benutzt [##keit]
● Ein Teil der Input-Tokens
(typischerweise 15%) wird zufällig
durch das [MASK] - Token ersetzt
● BERT wird darauf trainiert, die
“maskierten” Tokens
vorherzusagen
[Was] [wir] [MASK] [,] [ist] [Auf] [##merk] [MASK] [##keit]
30Pre-training
Masked Language Modeling
# Tokens
{
... ... ... ...
{ MLM - Head
Feedforward NN
…
BERT klassifiziert
also alle Tokens. Für
die Verlustfunktion
BERT werden aber nur die
berücksichtigt, die
… auch maskiert
waren.
Alternative: ELECTRA
[Was] [wir] [MASK] [,] [ist] [Auf] [##merk] + [Was] [wir] [brauchen] [,] [ist] [Auf] [##merk]
[MASK] [##keit] [##sam] [##keit]
“Was wir brauchen ist Aufmerksamkeit”
31Pre-training
Pre-Training auf einen Blick
Quelle
32BERT
Downstream Tasks
Als Downstream Tasks werden spezielle Beispiele (allgemein):
Aufgaben bezeichnet, für die es ein ● Question Answering
(meist manuell) gelabeltes Datenset ● Named Entity Recognition
benötigt wird. Das Anpassen des ● Information Extraction
BERT-Modells auf diese Aufgaben wird ● Klassifikation
als Fine-Tuning bezeichnet. ● ...
33BERT
Downstream Tasks
Aufgabenspezifischer Head
Dieses Setup wird dann
{ für eine vergleichsweise
Bidirektionale,
kontextbasierte [CLS] … sehr kurze Zeit auf einem
Darstellung
vergleichsweise sehr
kleinen Datenset
{
trainiert.
Gewichte
aus MLM
und NSP BERT Interessant: Meist
Pretraining
werden alle
Gewichte
nochmal
angepasst, nicht
nur die des
Input
Tokens { [CLS] …
neuen Heads.
34BERT
Downstream Tasks: Beispiel QA-Head
(Start) (Ende)
Frage
beantwortbar
?
{ { QA - Head
[CLS] [SEP] …
BERT
[CLS] [SEP] …
{
{
Frage Kontext
35Anpassung der Sprache
Klassische Pipeline
BERT sehr lange auf sehr Auf vergleichsweise
vielen Daten kleinem Datensatz für
self-supervised trainieren eine Downstream-Task
fine-tunen
36Agenda
1 NLP-Trend: Neuronale Sprachmodelle
2 Anwendungsmöglichkeiten im Unternehmenskontext
3 Beispiel BERT
4 Herausforderungen in der Praxis
4.1 Anpassung der Sprache
4.2 Skalierung
4.3 Beschaffung von Trainingsdaten
5 Zusammenfassung
dida.do
37Herausforderungen in der Praxis
Anpassung der Sprache
Für Domänen mit spezifischem Fachvokabular
Erinnerung: Modelle wie BERT (Biologie, Chemie, Jura ...) ist zu erwarten, dass
werden auf einem generischen ein Modell welches explizit auf Daten mit
Korpus trainiert. (wikipedia, etc.) diesem Vokabular trainiert wurde, eine bessere
Performance hat als das BERT-Grundmodell.
Verschiedene Möglichkeiten:
● Initialisierung des
Entwicklung von vortrainierten BERT-Modells
domänenspezifischen verwenden, damit
Modellen weitertrainieren
● From scratch ein neues Modell
trainieren
● Vokabular
behalten/erweitern/verändern
38Anpassung der Sprache
Beispiel SciBERT
Architektur gleicht der von BERT, allerdings ist
SciBERT nur auf wissenschaftlichen Papern
trainiert. Es wurden 1.14 M Veröffentlichungen
benutzt, davon 18% aus der Informatik und 82%
biomedizinische Paper.
Anderes Vokabular: SciBERT
verwendet das eigens
entwickelte SciVocab. Dieses
überschneidet sich nur zu
42 % mit dem
BERT-Vokabular!
39BERT: Fine-tuning
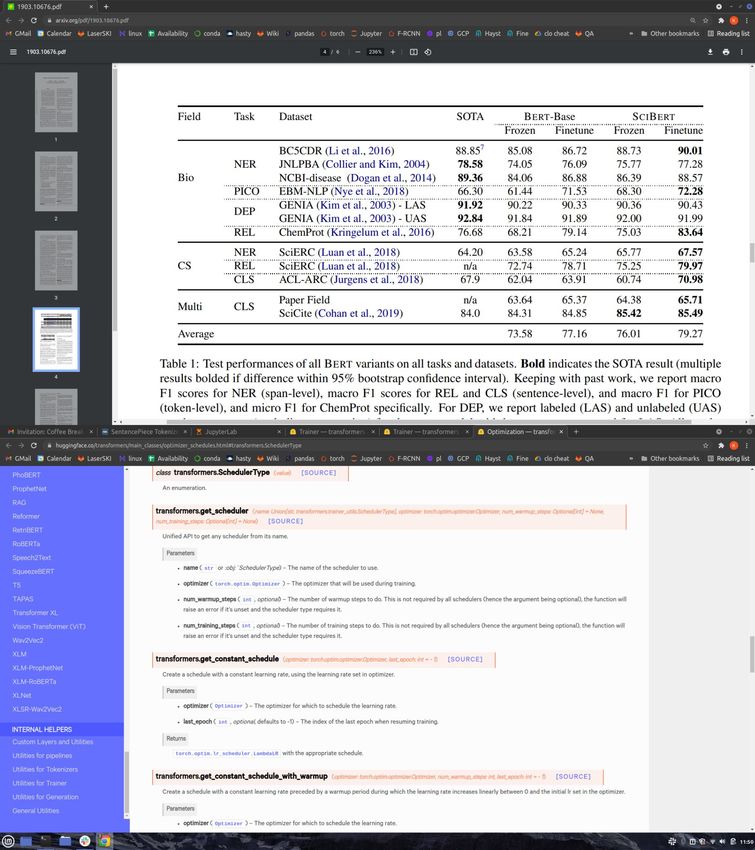
SciBERT: Auswirkungen des Trainingskorpus
Reportete
Metrik: F1-Score
Quelle (SciBERT paper)
PICO = Patients, Ähnliche Ergebnisse auf
Interventions, Comparisons, anderen Benchmarks aus der
Outcomes wissenschaftlichen Domäne.
40Domänenspezifische Modelle
Don’t stop Pre-Training!
Quelle
In dem Paper Don't Stop Pretraining: Adapt Language Models to Domains and Tasks
unterscheiden die Autoren zwischen 2 Kategorien des weiteren Pre-Trainings:
Domain-adaptive pretraining (DAPT): Task-adaptive pretraining (TAPT):
● Es wird frei verfügbarer Text ● Es wird Text benutzt, der
aus der Domäne verwendet direkter mit der konkreten
(große Datensätze) Aufgabe in Verbindung steht
(kleinere Datensätze)
41Domänenspezifische Modelle
Don’t stop Pre-Training!
● Als Baseline-Modell benutzen die Autoren RoBERTa (“robustly optimized BERT
Pretraining approach”). Die Architektur gleicht der von BERT, beim Pre-Training gibt
es deutliche Unterschiede (mehr Daten, kein NSP, andere Hyperparameter …)
● Beispiele für DAPT: MLM mit den RoBERTa Hyperparamtern auf verschiedenen
Domänen, u.a. Biomedizinischen Papern, Nachrichtenartikeln, Amazon Reviews
● Beispiele für TAPT: MLM auf dem aufgabenspezifischen Training-Datensatz,
beispielsweise CHEMPROT
Sowohl DAPT als auch TAPT erhöhten
die Performance von RoBERTa auf
beinahe allen untersuchten Aufgaben.
42Anpassung der Sprache
In der Anwendung
Konkrete Pipeline:
Vortrainiertes Modell Weiteres Pre-Training auf Fine-Tuning auf einem
(z.B BERT) domänen- bez. vergleichsweise kleinen
aufgabenspezifischen Datensatz (einige
Daten tausend Einträge)
Maßgeschneidertes
Modell mit guter
Performance
43Anpassung der Sprache
Beispiel
Aufgrund des Vorrangs des unmittelbar
geltenden Unionsrechts darf eine nationale
Regelung über ein staatliches
Sportwettenmonopol, die nach den Generisches
Kontext
“Beschränkungen”
Feststellungen eines nationalen Gerichts Modell
Beschränkungen mit sich bringt, die mit der
Niederlassungsfreiheit und dem freien
Dienstleistungsverkehr unvereinbar sind,
weil sie nicht dazu beitragen, die
Wetttätigkeiten in kohärenter und
systematischer Weise zu begrenzen, nicht
für eine Übergangszeit weiter angewandt
werden.
Auf juristischen “eine nationale Regelung
Daten vortrainiertes über ein staatliches
Modell Sportwettenmonopol”
Frage
Worüber urteilt das Gericht?
Quelle für den Kontext 44Agenda
1 NLP-Trend: Neuronale Sprachmodelle
2 Anwendungsmöglichkeiten im Unternehmenskontext
3 Beispiel BERT
4 Herausforderungen in der Praxis
4.1 Anpassung der Sprache
4.2 Skalierung
4.3 Beschaffung von Trainingsdaten
5 Zusammenfassung
dida.do
45Herausforderungen in der Praxis
Skalierung
Ein neuronales Sprachmodell allein ist oft nicht genug.
Beispiel Question Answering:
● Wird für viele Unternehmen
Verschiedene Möglichkeiten:
erst interessant, wenn Fragen
● Kombination von neuronalen
auf Grundlage einer Datenbank
Sprachmodellen (Dense
beantwortet werden können
Retrieval)
● Input von BERT ist auf 512
● Nicht-neuronale Lösung, z.B.
Tokens beschränkt
über TF-IDF (Sparse Retrieval)
● Zusätzlich zu einem Document
Reader wird also ein Document
Retriever benötigt
46Herausforderungen in der Praxis
Skalierung am Beispiel Question Answering
Document
Retriever Passage 1 Antwort 1
Passage 2 Antwort 2
Datenbank Dokument
Passage 3 QA-Engine Antwort 3
(z.B BERT) Finale
Antwort
. .
. .
. .
Frage Passage n Antwort n
47Agenda
1 NLP-Trend: Neuronale Sprachmodelle
2 Anwendungsmöglichkeiten im Unternehmenskontext
3 Beispiel BERT
4 Herausforderungen in der Praxis
4.1 Anpassung der Sprache
4.2 Skalierung
4.3 Beschaffung von Trainingsdaten
5 Zusammenfassung
dida.do
48Herausforderungen in der Praxis
Beschaffung von Trainingsdaten
Oft kann davon profitiert werden,
dass aufgaben- oder sogar
domänenspezifischer,
unstrukturierter Text zur Verfügung
steht.
In den meisten Fällen muss aber auch ein
Datenset manuell gelabelt werden.
Durch geschickte Erweiterung der Daten
(Data Augmentation) kann man die
Anzahl der verfügbaren Trainingsdaten
erhöhen.
49Agenda
1 NLP-Trend: Neuronale Sprachmodelle
2 Anwendungsmöglichkeiten im Unternehmenskontext
3 Beispiel BERT
4 Herausforderungen in der Praxis
4.1 Anpassung der Sprache
4.2 Skalierung
4.3 Beschaffung von Trainingsdaten
5 Zusammenfassung
dida.do
50Zusammenfassung
Take-Home-Message
Überall wo es unstrukturierten Text gibt, kann (und sollte)
ein neuronales Sprachmodell eingebunden werden.
Vortrainierte Modelle wie BERT
bilden eine passable Baseline.
Durch maßgeschneidertes Finetuning und
aufgabenspezifisches Pre-Training kann die Performance
deutlich verbessert werden. Dafür werden i.d.R. nicht allzu
viele manuell gelabelte Daten benötigt.
Anschließend muss das Modell geschickt in eine Pipeline
eingebunden werden, um maximalen Nutzen zu generieren.
51Ende
Vergangene Webinare (mit Video und Slides):
https://dida.do/de/webinare/
Linksammlung:
● Unsere QA-Demo
● Blog-Artikel über die Transformer-Architektur und den Attention-Mechanismus
● SciBERT - Paper
● Don't Stop Pretraining - Paper
● Blog-Artikel über die Geschichte neuronaler Sprachmodelle
● Wirtschaftszweig bestimmen mit semantischer Suche - zugehöriges dida-Webinar
52Sie können auch lesen

















































