Stereotypisierter Kontinent?
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Humboldt-Universität zu Berlin
Philosophische Fakultät
Institut für Geschichtswissenschaften
BACHELORARBEIT
Stereotypisierter Kontinent?
Historische Datenauswertung der Afrikaberichterstattung
in „DER SPIEGEL“, „DIE ZEIT“ und „Hamburger Abendblatt“
- 24.01.2020 -
Matthias Meyer
E-Mail: kontakt@matthmeyer.de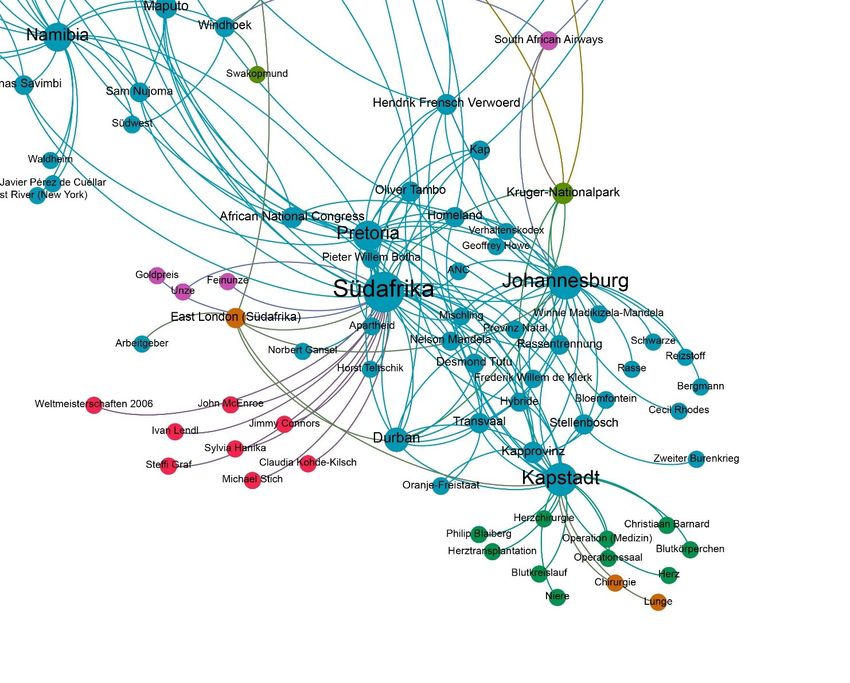
I NHALT
Einleitung – „Elends-Kontinent Afrika“ .................................................................................... 1
1 Vorüberlegungen und Methode ............................................................................................... 3
1.1 Quellenauswahl ................................................................................................................ 3
1.2 Erstellung des Korpus ...................................................................................................... 5
2 Auswertungsmethoden ............................................................................................................ 8
2.1 Schlüsselbegriffsanalyse .................................................................................................. 8
2.2 Zitate-Scanner ................................................................................................................ 10
2.3 Sentiment-Analyse ......................................................................................................... 11
2.4 Rubrik-Analyse .............................................................................................................. 12
2.5 Netzwerkanalyse ............................................................................................................ 13
3 Auswertungsergebnisse ......................................................................................................... 14
3.1 Unterrepräsentiert: Afrika und der Globale Süden ......................................................... 14
3.2 Sonderfall Ägypten: Kein afrikanischer Staat? .............................................................. 15
3.3 Sonderfall Nigeria: Abseits der Korrespondentenstädte ................................................ 18
3.3 Selektive Berichterstattung: Kriege und Krisen ............................................................. 23
3.4 Fremdbezeichnungen und Zitate .................................................................................... 27
3.5 Methodische Probleme ................................................................................................... 29
Schlussbetrachtung ................................................................................................................... 30
A. Quellenverzeichnis ............................................................................................................. 33
B. Literaturverzeichnis ............................................................................................................ 33
Anhang ..................................................................................................................................... 36
1 Wortlisten .......................................................................................................................... 36
1.1 Die zehn ersten von Newspaper3K erkannten Schlüsselbegriffe im Spiegel-Artikel „Ein schwarzer
Holocaust“ sortiert nach Gewichtung ........................................................................................................... 36
1.2 Von spaCy erkannte Entitäten im Spiegel-Artikel „Ein schwarzer Holocaust“ in alphabetischer
Reinfolge ...................................................................................................................................................... 36
1.3 Vom selbst entwickelten Schlüsselbegriffsscanner erkannte Schlüsselbegriffe im Spiegel-Artikel
„Ein schwarzer Holocaust“........................................................................................................................... 37
1.4 Liste für Nachrichtenartikel typischen Verben zur Einleitung direkter Rede ......................................... 37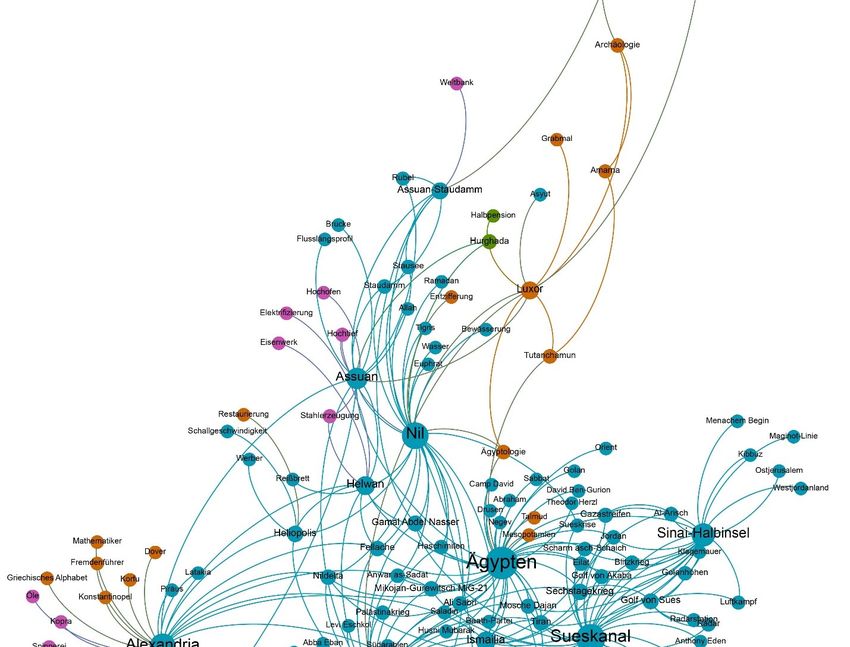
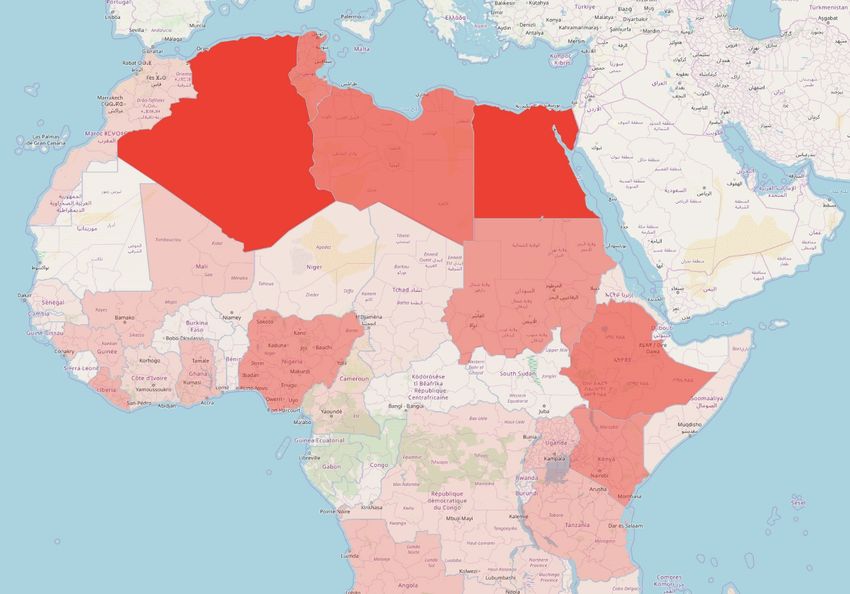
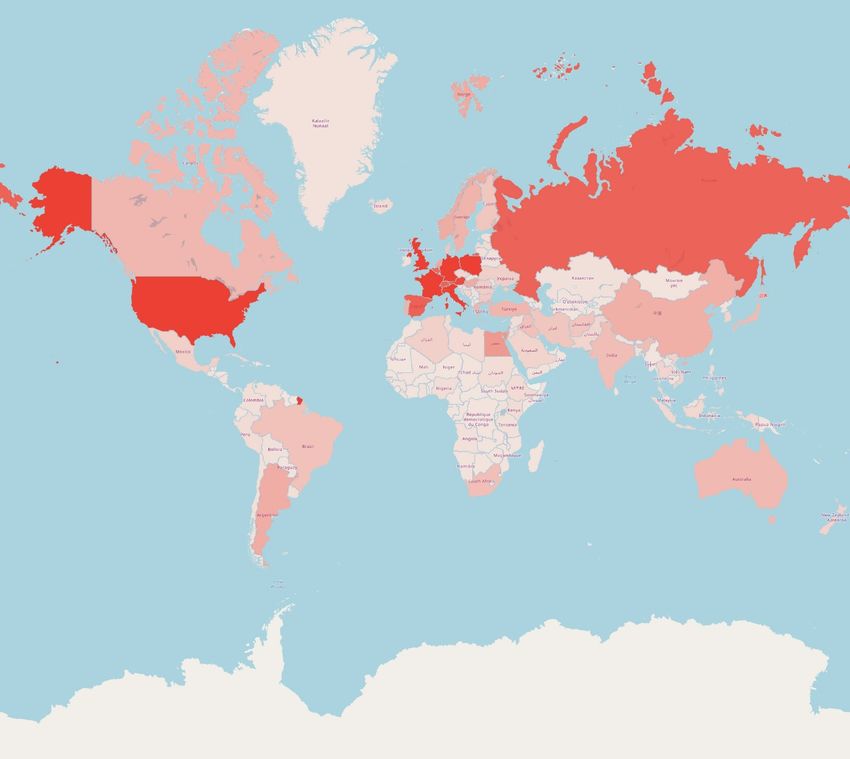
2 Tabellen ............................................................................................................................. 38 2.1 Ergebnis der Schlüsselbegriffsanalyse: Die 20 indirekt oder direkt meistgenannten Länder ................. 38 2.2 Ergebnis der Schlüsselbegriffsanalyse: Kontinente und Anzahl der Nennungen total beziehungsweise Anzahl der Nennungen pro 1.000 Einwohner .................................................................. 38 3 Grafiken ............................................................................................................................. 39 3.1 Länder der Erde eingefärbt nach Anzahl der direkten oder indirekten Nennungen im Korpus .............. 39 3.2 Ergebnis der Schlüsselbegriffsanalyse: Kontinente und Anzahl der Nennungen total beziehungsweise Anzahl der Nennungen pro Einwohner ........................................................................................................ 40 3.3 Länder Afrikas eingefärbt nach Anzahl der direkten oder indirekten Nennungen im Korpus ............... 41 3.4 Anzahl der Nennungen der Länder Afrikas in Abhängigkeit zu deren Bruttoinlandsprodukt ................ 42 3.5 Anteil der Artikel, die das Wort „Afrika“ beinhalten, an der Gesamtzahl der Artikel zu einem Land... 43 3.6 Netzwerkgraph: Ergebnis der Netzwerkanalyse ..................................................................................... 44 3.7 Ausschnitt Netzwerkgraph: Sonderrolle Ägyptens................................................................................. 45 3.8 Prozentualer Anteil an Artikeln über Ägypten, in denen entweder "Jerusalem" oder "Israel" vorkommt ........................................................................................................................................ 46 3.9 Ortsmarkierungen eingezeichnet nach der Häufigkeit ihrer Nennung auf einer Weltkarte .................... 46 3.10 Anzahl der Artikel mit den Suchbegriffen „Biafra“, „Hunger“ in Kombination mit „Biafra“ und „Kind“ in Kombination mit „Biafra“ 1967 bis Ende 1969 ........................................................................... 47 3.11 Anzahl Artikel mit dem Suchbegriff „Hunger“ in den Artikeln zu Afrika 1949-2019......................... 47 3.12 Anzahl der Artikel mit den Suchbegriffen „Holocaust“, „Genozid“ oder „Völkermord“ 1949-2019 .. 48 3.13 Anteil der Artikel mit den Suchbegriffen „Ägypten“ an der Gesamtartikelzahl 1949-2019 in ‰ ....... 48 3.14 Ausschnitt Netzwerkgraph: Sonderrolle Südafriaks ............................................................................. 49 3.15 Absolute Anzahl an Artikeln aus der Rubrik „Sport“ afrikanischer Länder ......................................... 49 3.16 Rubrikverteilung der Länder Ruanda, Libyen, Somalia und Kongo im Vergleich mit den Vereinigten Staaten von Amerika und Australien ........................................................................................ 50 3.17 Anteil der Artikel mit dem Suchbegriff „Südafrika“ an der Gesamtzahl der Artikel in ‰ 1949-2019 51 3.18 Anteil der Artikel mit dem Suchbegriff „Ruanda“ an der Gesamtzahl der Artikel in ‰ 1949-2019 ... 51 3.19 Anteil der Artikel mit dem Suchbegriff „Somalia“ an der Gesamtzahl der Artikel in ‰ 1949-2019 .. 52 3.20 Anteil der Artikel mit dem Suchbegriff „Kongo“ an der Gesamtzahl der Artikel in ‰ 1949-2019 .... 52 3.21 Anteil der Artikel mit dem Suchbegriff „Vietnam“ an der Gesamtzahl der Artikel in ‰ 1949-2019.. 53 3.22 Anteil der Artikel mit dem Suchbegriff „Chile“ an der Gesamtzahl der Artikel in ‰ 1949-2019....... 53 3.23 Durchschnittliches Sentiment der Artikeltexte nach Kontinent............................................................ 54 3.24 Länder der Erde eingefärbt nach ihrem Artikelsentiment..................................................................... 55 3.25 Die markantesten Substantive nach Kontinenten ................................................................................. 56 3.26 Anteil der Artikel mit den Suchbegriffen „Hunger“, „Terror“, „Armut“ und „Krieg“ nach Kontinenten in % .......................................................................................................................................... 58 3.27 Anteil an Artikeln mit verschiedenen Fremdbezeichnung als Suchbegriff in ‰ 1949-2019 ............... 60 3.28 Anteil der Artikel mit Kontinentsgruppenbezeichnung an der Gesamtzahl an Artikeln zu einem Kontinent in %.............................................................................................................................................. 61 3.29 Durchschnittliche Anzahl an erkannten Personen pro Artikel nach Kontinenten ................................. 61
E INLEITUNG – „E LENDS -K ONTINENT A FRIKA “
„Verrückte Krieger und verhungernde Kinder, Anarchie und Elend - das ist das Antlitz Afrikas
im letzten Jahrzehnt dieses Jahrtausends“,1 leitete der Journalist Hans Hielscher 1992 die Titelge-
schichte des Nachrichtenmagazins „DER SPIEGEL“ ein. Auf dem Cover der Ausgabe prangerte
„Elends-Kontinent Afrika“. Anlass für den Aufmacher war der amerikanische Eingriff der USA in
den Bürgerkrieg Somalias. Der entsprechende Text beginnt mit der Beschreibung eines an Unter-
ernährung sterbenden Kindes, leitet zu Kalaschnikows und Sonnenbrillen tragenden schwarzen
Soldaten über und mündet schließlich in folgender Frage: „Müssen also die Weißen zurückkehren,
um den Schwarzen Kontinent zu retten, über den sie einst Tod und Verderben gebracht hatten?“2
Die Antwort gibt der Autor in den nächsten Abschnitten selbst. Afrika sei ein Kontinent ohne Hoff-
nung und deshalb angewiesen auf die Hilfe der Weißen.
Der Artikel fußt dabei auf einer meinungsstark aufgemachten Dichotomie zwischen zivilisier-
ten Weißen und hoffnungslosen Schwarzen, die postkoloniale Forscher:innen als problematisch
herausstellen würden. Richtungsweisend für den Postkolonialismus war Edward Saids Werk „Ori-
entalism“ aus dem Jahr 1978.3 Darin entwickelte er am Beispiel des „Orients“ die These, dass
westliche Wissenschaftler:innen in ihrer Darstellung des Fremden einen Diskurs schufen, der die
Kulturen ehemaliger kolonialer Gebiete als unterlegenes Anderes konstruierte und dieses Andere
damit erst erschuf. Daran anschließend habe dieser Diskurs dazu beigetragen, koloniale Macht-
strukturen zu verfestigen und zu legitimieren. Fraglich ist, inwiefern sich solche Konstrukte abseits
des selektiven Beispiels vom „Elends-Kontinent Afrika“ flächendeckend in der journalistischen
Berichterstattung finden. Mit anderen Worten: Wurde in der Nachkriegszeit in der Nachkriegszeit
anders über die Länder Afrikas und über den Kontinent Afrika an sich berichtet als über andere?
Das Afrikabild in den publizistischen Medien des globalen Nordens ist kein neues Forschungs-
gebiet. Bereits in den 1990er Jahren kam Beverly Hawk zu dem Schluss, die westliche Afrikabe-
richterstattung sei vereinfachend, rassistisch und in ihrer Thematik und ihrem Ton überwältigend
negativ.4 Dieses als Afropessimismus zusammengefasste Phänomen spiegelt den Prozess wider,
dass Afrika als Kontinent wenig bis gar keine positiven Entwicklungschancen zugesprochen wer-
den.5 Darin zeigt sich ein medialer Modus, der den Kontinent auf negative Stereotype reduziert.
1
Hans Hielscher, Ein schwarzer Holocaust, in: DER SPIEGEL 1992 (51). 14.12.1992, https://www.spie-
gel.de/spiegel/print/d-13691854.html (Zugriff: 04.01.2020).
2
Vgl. ebd.
3
Vgl. Edward Wadie Said, Orientalism. New York 1978.
4
Vgl. Beverly Hawk, Africa’s Media Image. New York 1992.
5
Vgl. James Garrett/Sandra Schmidt, Reconstituting Pessimistic Discourses, in: Critical Arts 25,3. 2011, 423-440,
hier 423-424.
1
Wie die Medienwissenschaftlerin Mel Bunce argumentiert, sei weniger die Tatsache problema-
tisch, dass die Stereotype unwahr seien, sondern vielmehr, dass sie Afrika nur unvollständig ab-
bildeten.6
Obwohl in Studien wie der von Bunce, in der sie textimmanent 892 Artikel von internationalen
Nachrichtenagenturen analysierte,7 vor allem in den letzten zwei Jahrzehnten wissenschaftlich viel
zur Afrikaberichterstattung aufgearbeitet wurde, gibt es dennoch Forschungsbedarf. Zum einen
waren diese Studien immer kontemporär angelegt; eine historische Einordnung auch über länger
zurückliegende Zeiträume fehlt – nicht zuletzt im deutschsprachigen Raum. Zum anderen ist die
Medienlandschaft in ihrem Pluralismus und ihrer gerade über Jahrzehnte hinweg gesehenen Viel-
zahl an publizierten Beiträgen höchst komplex zu überblicken. Afrikastereotype wurden dabei an
selektiven Beispielen aus kurzen Zeiträumen oder anhand von händisch auswertbaren Artikelmen-
gen nachgewiesen.
Diese Arbeit setzt sich das ehrgeizige Ziel, sich der deutschsprachigen Afrikaberichterstattung
mit einer Makroperspektive anzunähern. Geschichtswissenschaftlich sind Makroperspektiven hei-
kel, müssen sie sich doch schnell dem Vorwurf der Undifferenziertheit in einem traditionell sehr
quellennah arbeitenden und eher qualitativ als quantitativ urteilenden Fach stellen. Insbesondere
die jüngere Neuzeit aber stellt die Geschichtswissenschaften vor das Problem, dass die Anzahl der
Quellen bei Weitem die mit klassischen Methoden bearbeitbare Menge übersteigt. Allen voran gilt
dies für die Mediengeschichte. Der wachsende Fachbereich der digitalen Geschichtswissenschaf-
ten versucht dem Problem mit der Entwicklung quantitativer computergestützten Methoden zu
begegnen. Solche Methoden sollen in dieser auf die Fragestellung übertragen, angewandt und auf
ihre Fruchtbarkeit und Aussagekraft überprüft werden.8
Als Quellenkorpus für diese Arbeit dienen die online verfügbaren Texte der Nachrichtenmaga-
zine „DER SPIEGEL“, „DIE ZEIT“ und die Tageszeitung „Hamburger Abendblatt“ (im folgenden
6
Vgl. Mel Bunce, The International News Coverage of Africa. Beyond the “Single Story”, in: dies., Suzanne
Franks, Chris Paterson (Hrsg.): Africa’s Media Image in the 21st Century. From the “Heart of Darkness” to “Af-
rica Rising”. London/New York 2017, 17-29, hier 17.
7
Weitere zu nennende Studien zur Afrikaberichterstattung sind Lutz Mükkes umfangreiche Analyse von 1.055
Artikeln über Afrika im Zeitraum von 2002 bis 2004 und Susanne Fenglers und Marcus Kreutlers Auswertung
von 211 Nachrichtenbeitragen mit Afrikabezug im Jahr 213. Vgl. Lutz Mükke, Journalisten der Finsternis. Ak-
teure, Strukturen und Potenziale deutscher Afrikaberichterstattung . (Reihe des Instituts für Praktische Journalis-
musforschung, Bd. 1.) Köln 2009, 92 und Susanne Fengler/Marcus Kreutler, Das Afrikabild aus journalistischer
Perspektive. Ergebnisse einer Inhaltsanalyse deutscher Zeitungen im Frühjahr 2013, in: Veye Tatah (Hrsg.), Af-
rika 3.0. Mediale Abbilder und Zerrbilder eines Kontinents im Wandel. Berlin 2014, 55-64. Dirke Köpp unter-
suchte inhaltsanalytisch anhand ausgewählter Beispiele das Afrikabild in den populären Zeitschriften „Bunte“,
„Neue Revue“, „Praline“, „Quick“ und „Stern“ im Zeitraum 1946 bis 2000. Vgl. Dirke Köpp, „Keine Hungersnot
in Afrika“ hat keinen besonderen Nachrichtenwert. Afrika in populären deutschen Zeitschriften (1946-2000).
Frankfurt am Main 2005.
8
Ein vergleichbares zeitgeschichtliche Datenprojekte mit anderer Themensetzung ist Daniel Burckhardts und Ale-
xander Geykens computergestützte Analyse der DDR-Presse, Vgl. Daniel Burckhardt/Alexander Geyken, Distant
Reading in der Zeitgeschichte. Möglichkeiten und Grenzen einer computergestützten Historischen Semantik am
Beispiel der DDR-Presse, in: Contemporary History 16,1. 2019, 177-196. Einen ähnlichen Ansatz verfolgte Ma-
riann Skog-Södersved bereits 1993. Vgl. Mariann Skog-Södersved, Wortschatz und Syntax des außenpolitischen
Leitartigels. Quantitative Analyse der Tageszeitungen „Neues Deutschland“, „Neue Zürcher Zeitung“. „Die
Presse“ und „Süddeutsche Zeitung“, Frankfurt am Main 1993.
2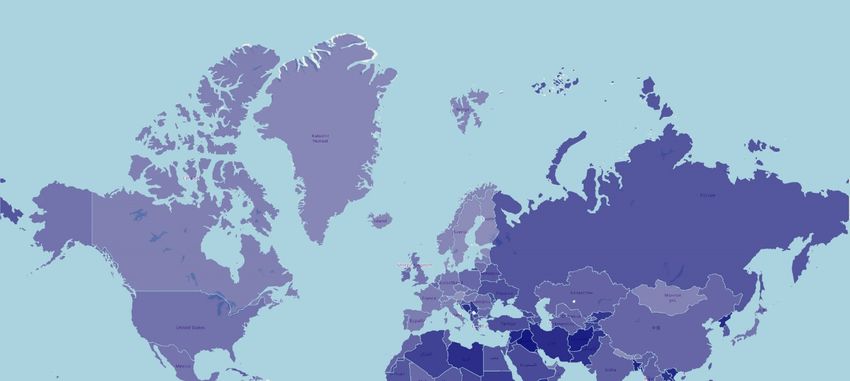
Spiegel, Zeit und Abendblatt genannt). Dabei soll untersucht werden, inwiefern die Berichterstat-
tung über Afrika von der über andere Kontinente abweicht, welche Auffälligkeiten sich in der Dar-
stellung Afrikas ergeben und in welcher Art die Medien Afrikaner:innen darstellen und zu Wort
kommen lassen.
Um sich diesen Fragen nähern zu können, soll nach der Korpus-Erstellung in einem ersten
Schritt ein Tool zur Schlüsselbegriffsanalyse erarbeitet werden, mit dessen Hilfe diejenigen
Schlüsselbegriffe erkannt werden können, die innerhalb der Artikel einen geographischen Bezug
zu Afrika aufbauen. Darüber hinaus sollen die Artikel auf ihr Sentiment, also ihre positive oder
negative Polarität, untersucht werden, um erkennen zu kennen, ob über Afrika negativer berichtet
wird als über andere Kontinente. Die Volltextsuche nach Ländernamen innerhalb des Korpus und
die Aufschlüsselung der Ergebnisse nach Jahreszahlen gibt Auskunft darüber, wann und in wel-
chem Kontext afrikanische Länder im Fokus der Medien standen. Des Weiteren soll ein Skript
entwickelt werden, das anhand statistischer Worthäufungen den Artikeln eine Nachrichtenrubrik
zuordnet, womit sich genauso der Frage nach den Themenschwerpunkten in der Afrikaberichter-
stattung angenähert werden kann wie mit der Analyse von markant häufig auftretenden Substanti-
ven in Artikeln mit Afrika-Bezug. Ein weiteres Tool, das wörtliche Zitate inklusive der zitierten
Personen erkennt, soll Auskunft darüber geben, ob nachweislich in Afrika geborene Personen sel-
tener zu Wort kommen als Menschen aus dem globalen Norden. Anhand dieser höchst verschie-
denen Analyseansätze und der Kontextualisierung anhand einzelner Beispiele wie dem Medien-
hype um den Biafra-Krieg soll ein möglichst umfangreiches Bild zur Darstellung Afrikas nach
dem Zweiten Weltkrieg entstehen.9
1 V ORÜBERLEGUNGEN UND M ETHODE
1.1 Q UELLENAUSWAHL
Die digitalen Geisteswissenschaften mit ihrem Teilgebiet der digitalen Geschichtswissenschaft
haben sich zum Ziel gesetzt, mittels statistisch-algorithmischer Methoden sowohl neue Erkennt-
nisse als auch neue Fragestellungen zu generieren.10 Damit reagieren die Geisteswissenschaften
auf einen wissenschaftlichen Technisierungs- und Mathematisierungsprozess. Wissenschaftsge-
schichtlich wurden auf Quantifizierung beruhenden Forschungserkenntnissen in den vergangenen
9
Die Ergebnisse der Datenauswertung finden sich aufgrund besserer Interaktivität der Grafiken finden auch unter
https://journospective.de/.
10
Vgl. Petra Missomelius, Medienbildung und Digital Humanities. Die Medienvergessenheit technisierter Geistes-
wissenschaften, in: Heike Ortner/Daniel Pfurtscheller/Michaela Rizzolli/Andreas Wiesinger (Hrsg.), Datenflut
und Informationskanäle. Innsbruck 2014, 101-112, hier 101.
3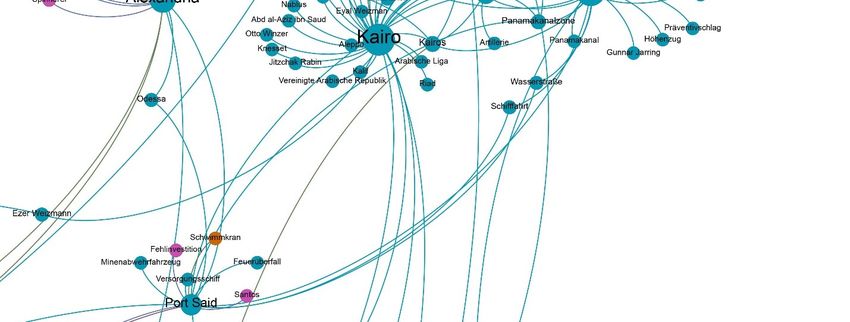
Jahrzehnten mehr und mehr Bedeutung zugemessen. Die Mathematik avancierte dabei zum Leit-
modell objektiver und allgemeingültiger Erkenntnis.11 Dennoch gilt nach wie vor der historische
Leitsatz, dass es keine objektive Perspektive auf die Geschichte gebe, die für sich Allgemeingül-
tigkeit beanspruchen könnte. Reinhart Koselleck fasste dies unter der Denkfigur des „Vetorechts
der Quellen“ zusammen, dass nämlich alle geschichtswissenschaftlichen Deutungen historische
Wahrheiten abbilden, solange sie nicht durch Quellenkritik als unwahr falsifiziert werden.12
Als Quellengrundlage dieser digitalgeschichtlichen Arbeit werden Daten dienen. Dabei werden
nicht nur zur Auswertung mathematisch Methoden angewandt werden, sondern die aus binären
Zeichen bestehenden Quellen basieren an sich schon auf einer mathematischen Grundlage. Nichts-
destotrotz soll nicht der Trugschluss begangen werden, mittels Datenanalyse zu objektiver Er-
kenntnis hinsichtlich der Fragestellung gelangen zu können.13 Im Gegenteil: Aufgrund der Neuar-
tigkeit der Methodik sind die Ergebnisse umso kritischer zu hinterfragen. Dabei werden die digi-
talgeschichtlichen Ansätze im Folgenden als Erweiterung des ohnehin eklektischen Methodenka-
nons der Geschichtswissenschaften betrachtet.
Journalistische Erzeugnisse eignen sich besonders für datenhistorische Arbeiten – erst recht für
studentische Arbeiten mit begrenztem Umfang. Die Mehrzahl der Geschichtsarchive sind bisher
nicht in digitaler Form zugänglich, scheiden damit also aus, wenn nicht selbst aufwendig eine
Digitalisierung vorgenommen werden soll.14 Hingegen liegen Zeitungen und Magazine in zuneh-
mender Zahl auch digital vor.15 Erstens existieren groß angelegte wissenschaftliche Digitalisierun-
gen wie das von der Deutschen Forschungsgemeinschaft geförderten Projekte „Amtspresse Preu-
ßens“16 und „DDR-Presse“.17 Zweitens haben Nachrichtenverlage selbst ein Interesse daran, ihr
Archiv für Recherchearbeiten zu digitalisieren. Einige stellen diese sogar für Zahlende online,18
11
Vgl. Theo Hug/Josef Perger, Instantwissen, Bricolage, Tacit Knowledge. Ein Studienbuch über Wissensformen
in der westlichen Medienkultur. Innsbruck 2003, 7.
12
Vgl. Reinhart Koselleck, Standortbindung und Zeitlichkeit. Ein Beitrag zur historiographischen Erschließung der
geschichtlichen Welt, in: ders./Wolfgang Justin Mommsen/Jörn Rüsen (Hrsg.), Objektivität und Parteilichkeit
(Theorie der Geschichte, Beiträge zur Historik. Bd. 1.) München 1977, 17-46, hier 45-46.
13
Die Digitalhistoriker Shawn Graham, Ian Milligan und Scott Weingart schrieben in ihrem Standardwerk zu Big
Data in den Geschichtswissenschaften, dass die maschinelle Auswertung großer Datenmengen „does not offer
any change to the fundamental questions of historical knowing facing historians.“ Shawn Graham/Ian Milli-
gan/Scott Weingart, Exploring Big Historical Data. The Historian’s Macroscope. London 2016, 32. Egal, wie
groß die Datenmengen würden, es handle sich dabei immer noch nur um Ausschnitte der Vergangenheit. Aller-
dings sehen sie die Chance, mittels Datenauswertung den Blick auf die Vergangenheit zumindest zu schärfen.
14
Vgl. Peter Haber, Digital Past. Geschichtswissenschaften im digitalen Zeitalter. München 2011, 99-103.
15
Vgl. zum Stand der digitalen Mediengeschichte Huub Wijffjes, Digital Humanities and Media History, A Chal-
lenge for Historical Newspaper Research, in: Tijdschrift voor Mediageschiedenis 20,1. 2017, 4-24.
16
Vgl. Albrecht Hoppe/Rudolf Stöber, DFG-Projekt Digitalisierung der Amtspresse Preußens in der zweiten Hälfte
des 19. Jahrhunderts und Erstellung eines Sachkommentars, in: Holger Böning/Arnulf Kutsch/Rudolf Stöber
(Hrsg.), Jahrbuch für Kommunikationsgeschichte (Bd. 9.) Stuttgart 2006, 220-246 und die Projektbeschreibung
Staatsbibliothek zu Berlin, ZEFYS Zeitungsinformationssystem. Die Korrespondenzen. 2017, http://zefys.staats-
bibliothek-berlin.de/index.php?id=korrespondenzen (Zugriff: 06.01.2020).
17
Vgl. die Projektbeschreibung Staatsbibliothek zu Berlin, Informationen zum Projekt. Von der gedruckten Zeitung
zur Volltextrecherche auf Artikelebene. 2017, http://zefys.staatsbibliothek-berlin.de/index.php?id=153 (Zugriff:
06.01.2020).
18
Wie zum Beispiel die reichweitenstarken Tageszeitungen „Süddeutsche Zeitung“ und „Frankfurter Allgemeine
Zeitung“. Deren Archive sind zwar auch über Bibliothekskataloge abrufbar, allerdings wird der automatisierte
4
manche sogar frei abrufbar.
Dazu zählen alle Ausgabe des wöchentlich erscheinenden Nachrichtenmagazins Spiegel und
eingeschränkt19 die Ausgaben der Wochenzeitung Zeit. Beide gelten als Leitmedien in Deutsch-
land.20 Soweit dem Autor bekannt ist lediglich das Archiv einer deutschen Tageszeitung unbe-
schränkt zugänglich. Dabei handelt es sich um das Hamburger Abendblatt. Die 1948 gegründete
Zeitung erschien über 60 Jahre lang im Springer-Verlag und gehört seit 2014 zur Funke Medien-
gruppe.
Alle drei genannten Magazine beziehungsweise Zeitungen bilden die Basis der folgenden Da-
tenanalyse. Kriterien für die Auswahl waren eine gewisse journalistische Relevanz, das heißt eine
Reichweite von mehreren 100.000 Leser:innen über den Untersuchungszeitraum hinweg, Erschei-
nungsort in der Bundesrepublik Deutschland und allen voran Datenverfügbarkeit. Bewusst in Kauf
genommen wurde bei der Erstellung des Korpus, dass sich Spiegel und Zeit an ein deutschland-
weites Publikum und das Hamburger Abendblatt primär an eine lokale Zielgruppe richtet. Die
Prämisse für die verwendeten computergestützten Verfahren ist eine möglichst große Datengrund-
lage, wobei sich die Schwerpunktsetzung des Abendblattes auf Hamburg in den Ergebnissen deut-
lich zeigen wird. 21 Da allerdings keine innerdeutschen Vergleiche angestellt werden, sondern die
Afrikaberichterstattung im Fokus steht, lässt sich dieser Punkt vernachlässigen.
Eine möglichst große Datengrundlage verspricht aber auch deshalb fruchtbare Ergebnisse einer
Untersuchung möglicher stereotypisierter Berichterstattung, da Stereotype via Sozialisation „er-
lernt“ werden, den Massenmedien dabei eine entscheidende Rolle zukommt und die sozialisie-
rende Wirkung dieser in Einzelbeispielen kaum erkennbar ist.22 Mit anderen Worten: Die Makro-
perspektive bietet sich an in der historischen Stereotypenforschung.
1.2 E RSTELLUNG DES K ORPUS
Abruf von Artikeln ausgeschlossen, weshalb sie für diese Arbeit nicht infrage kamen.
19
Die Zeit stellte im Juni 2007 alle ihre seit 1995 publizierten Texte online. Im Dezember 2007 schließlich alle
weiteren Jahrgänge seit Bestehen, also ab 1946. Dies waren laut eigener Aussage zusätzliche 250 000 Artikel.
Vgl. Gero von Randow, Zeit-Archiv seit 1946 frei. 21.12.2007, https://blog.zeit.de/zeitansage/2007/12/21/zeit-
archiv-seit-1946-frei_110 (Zugriff: 06.01.2020). Leider wurde die Archivgröße nachträglich wieder reduziert. Für
den entsprechenden Zeitraum konnten im Dezember 2019 nur noch 112 869 Artikel aufgefunden werden. Das
entspricht durchschnittlich 2303 Artikel pro Jahr. Florian Müller konnte in einer vergleichbaren Bachelorarbeit
aus dem Jahr 2015 noch etwa 5800 bis 5900 Zeit-Artikel pro Jahrgang im Zeitraum 1969 bis 1989 finden. Vgl.
Florian Müller, Digitale Zeitungskorpora als Quellen für die historische Forschung. Anwendung digitaler Werk-
zeuge und Methoden zur Untersuchung der Ökonomisierung der Sprache der Wochenzeitung „DIE ZEIT“ zwi-
schen 1969 und 1989. 2015, https://github.com/ImdWf/Publications/blob/master/BA%20thesis.pdf (Zugriff:
06.01.2020).
20
Vgl. Maja Malik/Armin Scholl/Siegfried Weischenberg, Journalismus in Deutschland 2005. Zentrale Befunde der
aktuellen Repräsentativbefragung deutscher Journalisten, in: Media Perspektiven 7. 2006, 346-361, hier 359.
21
So ergibt sich beispielsweise eine deutliche Häufung der Ortsmarkierung „Hamburg“. Vgl. Kapitel 3.3.
22
Vgl. zum Ansatz und zur Definition des Stereotypenbegriffs als sozial konstruierte Gruppenzuschreibung Martina
Thiele, Medien und Stereotype. Konturen eines Forschungsfeldes. Bielefeld 2015, 50-52.
5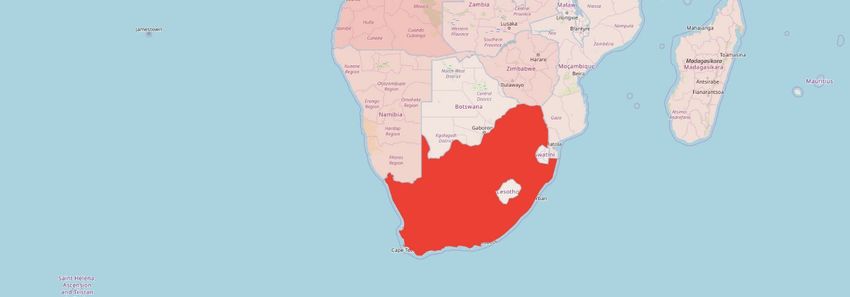
Einer der aufwendigsten Prozesse bei Datenauswertungen ist die Beschaffung der Daten, das
sogenannte Data Mining.23 Um die Nachrichtenartikel überhaupt erst auswerten zu können, muss-
ten diese zunächst von den Servern der Medienportale heruntergeladen werden. Es ist für kom-
merzielle Medien unüblich, wissenschaftlichen Projekten direkten Zugang zu den internen Daten-
banken zu bieten oder eine Datenschnittstelle zur Verfügung zu stellen, weshalb einzelne Artikel
über deren URL aufzurufen und die vom Server zurückgeschickte HTML-Seite auszuwerten wa-
ren. Dazu müssen aber die URLs zu allen jemals erschienen Artikeln bekannt sein. Die Zeit und
der Spiegel machen das Auffinden der URLs vergleichsweise einfach, da sie zu ihren Ausgaben
Übersichtsseiten bieten, die alle zugehörigen Artikel auflisten. Die Adressen der Übersichtsseiten
folgen einem simplen Schema, bei denen lediglich fortlaufend Jahres- und Wochenzahl der Aus-
gabe ersetzt werden mussten.24 Dies konnte mit einem Python-Skript automatisiert werden. Aus
dem HTML-Dokument der Übersichtsseiten konnten mithilfe der Python-Bibliothek Beautiful
Soup, die das Auslesen von HTML-Dateien unterstützt, alle Links gefiltert werden. Dabei wurde
darauf geachtet, dass die Links auf Archivartikel zeigen und nicht beispielsweise auf das Impres-
sum oder die Datenschutzerklärung.25
Schwieriger gestaltete sich das Auffinden der Artikellinks beim Hamburger Abendblatt. Deren
Webseite bietet keine Übersichtsseiten. Die Sitemap – eine Sammlung von XML-Dateien, die für
Suchmaschinen Unterseiten einer Webseite auflisten – des Abendblattes erwies sich als unvoll-
ständig. Stattdessen blieb nur der Umweg so an die Artikellinks zu gelangen, wie es auch Seiten-
besucher:innen tun würden: über die Suchmaske. Gesucht wurde nacheinander nach den drei häu-
figsten Wörtern der deutschen Sprache „der“, „die“ und „und“.26 Dies resultierte in etwa 228.000,
170.000 und 210.000 Ergebnisseiten (Stand Dezember 2019). Aufgabe des entsprechenden Skripts
war es, diese Ergebnisseiten nacheinander zu öffnen und wie oben beschrieben nach Artikellinks
zu durchsuchen.27 Die meisten Artikel beinhalteten mehr als eines der Suchwörter und wurden
23
Vgl. Missomelius, Medienbildung, 101-102.
24
So sind die Artikelauflistungen der Zeit unter https://www.zeit.de/{{ Jahr }/{{ Woche }}/index auffindbar und
die des Spiegels unter https://www.spiegel.de/spiegel/print/index-{{ Jahr }}-{{ Woche }}.html, wobei {{ Jahr }}
und {{ Woche }} jeweils durch die entsprechenden Zahlen zu ersetzen sind.
25
URLs zu Print-Artikel haben bei der Zeit die Form https://www.zeit.de/{{ Jahr }/{{ Woche }}//{{ Titel des Arti-
kels }} beim Spiegel die Form https://www.spiegel.de/spiegel/print/d-{{ 8-stellige Zahl }}.html. Die Einhaltung
dieser Form lasst sich durch die Nutzung von Regular Expressions prüfen.
26
Listen der häufigsten Wörter der deutschen Sprache lassen sich von der Webseite des Projekts „Leipzig Corpora
Collection“ herunterladen: https://wortschatz.uni-leipzig.de/de/download. Vgl. Thomas Eckart/Dirk Gold-
hahn/Uwe Quasthoff, Building Large Monolingual Dictionaries at the Leipzig Corpora Collection. From 100 to
200 Languages, in: Nicoletta Calzolari (Hrsg.), Proceedings of the 8th International Language Ressources and
Evaluation. Istanbul 2012, 759-765.
27
Auch die URLs zu Print-Artikel beim Hamburger Abendblatt haben eine bestimmte Form: https://www.abend-
blatt.de/archiv/{{ Jahr }}/article{{ neunstellige Nummer }}/{{ Titel des Artikels }}. Allerdings wird diese Form
nur bis zum Jahr 2002 eingehalten. Von da an sind Print-Artikel nicht mehr anhand ihrer URL von online publi-
zierten Inhalten zu unterscheiden. Um den Korpus möglichst über die Jahrzehnte hinweg homogen zu halten,
wurden die Optionen die auf 2002 folgenden Jahrgänge wegzulassen beziehungsweise ab 2002 vollständig auch
die in viel größerer Stückzahl erscheinenden Online-Artikel mit einzubeziehen verworfen. Stattdessen wählte das
Skript von da an pro Jahrgang aus der Masse an Online-Artikeln zufällige so viele Artikel aus, wie auch in den
Jahrgängen zuvor durchschnittlich im gedruckten Abendblatt erschienen (28.000).
6
dadurch mehrfach gefunden, weshalb vor weiteren Auswertungsschritten Duplikate entfernt wer-
den mussten. Nicht auszuschließen ist der unwahrscheinliche Fall, dass ein Artikel keines der drei
Wörter enthält, sodass sich eine Vollständigkeit des Korpus bei dieser Methode nicht garantieren
lässt.
Nachdem das Auffinden der URLs abgeschlossen war, konnten die einzelnen Artikel herunter-
geladen werden. Zur Archivierung solch großer Datenmengen bieten sich relationale Datenbanken
an. In dieser Arbeit kam MySQL zum Einsatz. Es ist weltweit eines der am verbreitetsten Daten-
bankverwaltungssysteme. Relationale Datenbanken wie MySQL ermöglichen das tabellenbasierte
Abspeichern von Daten und ermöglichen Operationen über mehrere Tabellen hinweg auf Grund-
lage der relationalen Algebra. Abfragen und Manipulieren der Daten erfolgt dabei über die Daten-
banksprache SQL.28
Ein Python-Skript öffnete also nacheinander die Artikellinks, machte im HTML-Dokument den
Titel, gegebenenfalls den Teaser, den Fließtext und das Erscheinungsdatum ausfindig und fügte
diese als je eine Zeile in die Tabelle „articles“ der MySQL-Datenbank ein. Bekanntlich finden sich
auf einer Webseite viele verschiedene Textelemente. Für menschliche Betrachter:innen ist auf-
grund der visuellen Gestaltung dieser Webseiten in der Regel klar erkennbar, was zum Fließtext
gehört und was zum Beispiel Werbung ist. Für Maschinen, die nur mit dem Quellcode arbeiten, ist
es das vielfach nicht. Unterstützend kam deshalb die Bibliothek Newspaper3k zum Einsatz, die
darauf ausgelegt ist, Nachrichtenartikel zu parsen, also dabei hilft, die relevanten HTML-Elemente
zu erkennen. Zusätzlich wurden nach mehreren Testdurchläufen vereinzelt auftretenden Fehler-
quellen manuell korrigiert, das heißt fälschlich erkannte Fließtextelemente oder Überschriften
wurden anhand ihrer HTML-IDs oder Klassen ausgeschlossen. Zusätzlich als problematisch er-
wies sich, dass die Zeit Artikel teilweise auf mehrere Seiten erstreckt.29 Glücklicherweise sind
weiterführende Seiten verlinkt und folgen einer leicht erkennbaren Struktur, sodass auch Artikel
mit weiterführenden Seiten vollständig miteinbezogen werden konnten.30
Durch das beschriebene Verfahren war es möglich, einen Korpus von 2.686.309 Artikeln zu
erstellen.31 Dafür sind die Artikel der letztgenannten im Schnitt deutlich länger und lassen auf-
grund einer weniger lokalen Ausrichtung auch mehr Afrikabezüge vermuten, womit sich dieser
28
Schon Ende der 80er Jahre erschienen erste Monografien zum Nutzen von Datenbanken in den Geschichtswis-
senschaften. Vgl. Manfred Thaller, Datenbanken und Datenverwaltungssysteme als Werkzeuge historischer For-
schung. St. Katharinen 1986. Zum aktuellen Stand, Nutzen und Anwendung von Datenbanken in den Geisteswis-
senschaften vgl. ausführlich Jon Bath/Harvey Quamen, Databases, in: Constance Crompton/Richard Lane/Ray
Siemens, Doing Digital Humanities. Practice, Training, Research. London/New York 2016, 145-162.
29
So verteilt sich beispielsweise der Artikel „Anbar Lulu“ auf insgesamt 65 Seiten. Vgl. Nagib Mahfuz, Anbar Lulu.
21.11.1969, https://www.zeit.de/1969/47/anbar-lulu (Zugriff: 06.01.2020).
30
Den Artikellinks wird lediglich ein „/seite-{{ Seitenzahl }}“ angehangen.
31
Den größten Anteil daran nehmen erwartungsgemäß Artikel des täglich erscheinenden Hamburger Abendblattes
mit 2.257.454 Artikeln ein. Spiegel und Zeit kommen auf je 288.810 und 140.045. Damit ergibt sich eine entspre-
chend gefüllte Datenbank, die fortgeschrittene Informatik-Kenntnisse zur Datenbankoptimierung erfordert, um
Abfragezeiten nicht ins unermessliche dteigen zu lassen.
7existente Unterschied in der Quellengröße relativiert.32 Mit über 9,1 GB an reinen Textdaten – also
Titel, Teaser und Fließtext – ist der Korpus enorm groß. Zu beachten ist zusätzlich die Download-
zeit bei der Erstellung solch großer Korpusse. Selbst unter optimalen Bedingungen, wenn also
aufgrund schneller Internetanbindung eine Download- und Auswertungszeit von einer Sekunde
pro Artikel erreicht wird, müsste bei mehr als 2,5 Millionen Artikeln mit einer Gesamtlaufzeit von
über 31 Tagen kalkuliert werden. Mithilfe von Multiprocessing, also dem Abarbeiten mehrerer
Prozesse gleichzeitig, konnte die Laufzeit auf 10 Tage verkürzt werden.33
2 A USWERTUNGSMETHODEN
2.1 S CHLÜSSELBEGRIFFSANALYSE
Um Aussagen über die Afrikaberichterstattung treffen zu können, ist es notwendig, diejenigen
Artikel des Korpus zu identifizieren, die sich auf Afrika beziehen. Eine Stichwortsuche nach dem
Begriff „Afrika“ ist dazu nicht ausreichend, da ein geographischer Bezug in Artikeln auch durch
die Nennung Landes, einer Region, einer Stadt, eines Gewässers, einer Landmarke oder Ähnli-
chem hergestellt werden kann. Entscheidender Teilbereich dieser Auswertung war es also, ein Ver-
fahren zu entwickeln, das die Artikel automatisiert auf Schlüsselbegriffe hin untersucht, um so
unter ihnen diejenigen ausmachen zu können, die sich auf Afrika beziehen.
Das maschinelle, quantifizierte Auslesen von Texten nennt sich Distant Reading.34 Die Schlüs-
selbegriffsanalyse (englisch auch Keyword Analysis oder Keyword Extraction genannt) ist ein
wichtiger Teil davon. Das Ziel einer Schlüsselbegriffsanalyse ist generell gesprochen das Heraus-
filtern relevanter Begriffe aus einem Fließtext, um diesen mit weiteren vergleichen zu können.
Relevanz kann dabei unterschiedlich definiert sein. In der Regel wird diese aber als Bedeutung des
Begriffs für den Fließtext gesehen. Dazu existieren bewährte methodische Ansätze und auch nutz-
bare Umsetzungen in verschiedenen Programmiersprachen. Auch die zur Textextraktion verwen-
dete Bibliothek Newspaper3k beinhaltet bereits ein einfaches statistisches Verfahren zur Schlüs-
selbegriffserkennung. Dieses zählt die Häufigkeit einzelner Wörter – Stoppwörter ausgenommen
– im Text und gibt die häufigsten n Wörter als Schlüsselbegriffe aus. Für die angedachte Analyse
ist ein solches Verfahren aber gänzlich ungeeignet, da erstens n nicht sinnvoll definierbar ist, zwei-
tens nur Einzelwörter erkannt werden, drittens Synonyme ignoriert werden und viertens zusätzlich
32
Die durchschnittliche Artikellänge der Artikel von Zeit, Spiegel und Hamburger Abendblatt im Korpus beträgt
858, 686 und 268 Wörter.
33
Das Herunterladen und die folgende Textanalyse liefen auf einem dafür eingerichteten Linux-Server mit acht
CPU-Kernen und 32 GB RAM.
34
Vgl. Matt Erlin/Lynne Tatlock, „Distant Reading“ and the Historiography of Nineteenth-Century German Litera-
ture, in: dies. (Hrsg.), Distant Readings. Topologies of German Culture in the Long Nineteenth Century. Cam-
bridge 2014, 1-25, hier 2-4.
8manuell Metainformationen wie die geographische Zugehörigkeit zu Ländern oder Kontinenten
manuell ergänzt werden müsste.35
Die Python-Erweiterung spaCy ist ein auch für die deutsche Sprache optimiertes computerlin-
guistisches Tool, das zumindest die ersten beiden Probleme ausmerzen kann. Die Open-Source-
Software nutzt statistische Modelle – mit anderen Worten maschinelles Lernen –, um zu einzelnen
Wörtern eines Textes die Wortart, die grammatikalische Abhängigkeit und das Lemma, also die
unreflektierte Form des Wortes, möglichst präzise vorherzusagen.36 Ebenfalls beinhaltet spaCy
eine sogenannte Entitätserkennung, das bedeutet, die Software erkennt Einzelwörter oder auch
zusammengehörige Wörter, die für das Programm mit hoher Wahrscheinlichkeit einen Eigennah-
men darstellen, wozu zum Beispiel Personen, Länder, Städte oder auch Buchtitel zählen. Obwohl
das eingesetzte deutsche Sprachmodell mit einem aus Nachrichtenartikel bestehenden Korpus er-
stellt wurde und damit dem in dieser Arbeit zu analysierendem Korpus ähneln dürfte, erwies sich
die Erkennung als sehr fehleranfällig.37
Deshalb war eine weitere Instanz von Nöten, die die Entitäten überprüft. Die größte frei zu-
gängliche Sammlung an Entitäten ist die Online-Enzyklopädie Wikipedia. Bedeutender Vorteil ist,
dass diese auch Metadaten zu den Entitäten zur Verfügung stellt, und zusätzlich die Möglichkeit
bietet, Synonyme aufzulösen. So leitet Wikipedia zum Beispiel die verschiedenen Schreibweisen
der mauretanischen Hauptstadt „Nuwakschut“, „Nouakchott“ oder „Nuakschott“ allesamt auf die
Seite „Nouakchott“ weiter. Um also auch die anderen beiden ausgemachten Probleme zu lösen,
wurde die deutsche Wikipedia heruntergeladen und in die zuvor angelegte Datenbank eingefügt.38
So stand eine Tabelle mit 1.751.840 Titeln von Wikipedia-Seiten39 zur Verfügung und zusätzlich
eine 1.328.404 Einträge umfassende mit Begriffen, die auf andere Artikel weiterleiten. Zusätzlich
finden sich in den Wikipedia-Daten auch eine Vielzahl an Aliase zu einzelnen Wikipedia-Artikeln,
die nicht zwangsläufig auch Weiterleitungen sein müssen.40 Auch diese 807.455 Aliase wurden in
einer Tabelle gespeichert.
Nun konnte jede von spaCy gefunde Entität mit der Titel-, der Weiterleitungs- und der Aliasliste
35
Vgl. die Liste der ersten zehn von Newspaper3K erkannten Schlüsselbegriffe im eingangs zitierten Spiegel-Arti-
kel „Ein schwarzer Holocaust“ im Anhang 1.1.
36
Vgl. zur Funktionsweise von spaCy Bhargav Srinivasa-Desikan, Natural Language Processing and Computa-
tional Linguistics. A Practical Guide to Text Analysis with Python, Gensim, spaCy and Keras. Birmingham/Mum-
bai 2018, 33-50.
37
Vgl. die Liste der von spaCy erkannten Entitäten im eingangs zitierten Spiegel-Artikel „Ein schwarzer Holo-
caust“ im Anhang 1.2.
38
Verfügbare Daten zu einzelnen Wikipedia-Artikeln können über eine Datenschnittstelle heruntergeladen werden:
https://www.mediawiki.org/wiki/API:Main_page. Gleichzeitig bietet Wikipedia aber auch sogenannte Daten-
bankdumps, also vollständige Kopien der eigenen Datenbank. Verfügbar sind diese für die deutsche Wikipedia
unter: https://dumps.wikimedia.org/dewiki/latest/.
39
Die tatsächliche Anzahl an Seiten in der deutschen Wikipedia liegt bei über 2 Millionen. Vgl. Wikipedia-Autoren,
Wikipedia:Statistik. Zuletzt bearbeitet 01.01.2020, https://de.wikipedia.org/w/index.php?title=Wikipedia:Statis-
tik&oldid=195383284 (Zugriff 08.01.2010). Der Unterschied rührt daher, dass interne Seiten wie Benutzer-, Dis-
kussions- und Kategorie-Seiten nicht abgespeichert wurden.
40
Der Unterschied zwischen Aliasen und Weiterleitungen ist, dass Weiterleitungen eindeutig sind und Aliase für
mehrere Wikipedia-Artikel stehen können.
9abgeglichen werden. Gab es einen Treffer, galt die Entität als bestätigt und wurde als zum Nach-
richtenartikel zugehörig in die Datenbank aufgenommen. Erzielte die Suche mehrere Treffer – so
ist „Togo“ zum Beispiel nicht nur der Name eines westafrikanischen Landes, der Nachnahme eines
amerikanischen Schauspielers, sondern steht auch für eine Hunderasse, ein Schiff und eine Maß-
einheit –, musste abgewogen werden, welcher Wikipedia-Eintrag der im Artikel gefundenen Enti-
tät entspricht. Der geschriebene Schlüsselbegriffsscanner erreicht dies dadurch, dass er für jeden
in Frage kommenden Wikipedia-Eintrag die im Vergleich zu den anderen Einträgen markantesten
Wörter herausfiltert und diese im Artikeltext sucht. Somit können für die entsprechenden Einträge
Wahrscheinlichkeitswerte errechnet und der wahrscheinlichste ausgewählt werden. Damit die
nicht zu vermeidende Fehlerquote möglichst gering bleibt, wählte das Skript bei Uneindeutigkeit
keines der Einträge.41
Mit der oben beschriebenen Methode war es möglich, allen Artikeln als Wikipedia-Einträge
definierte und damit qualitativ hochwertige Schlüsselbegriffe zuzuordnen.42 Über einen Abgleich
mit dem Datensatz von OpenStreetMap, der in seinen Geodaten Referenzen zu Wikipedia-Einträ-
gen aufweist, konnten mögliche Zugehörigkeiten von Schlüsselbegriffen zu Ländern ergänzt wer-
den.43 Somit wurde die Bedingung für weitere Analysen, innerhalb des Korpus die Artikel heraus-
filtern zu können, die einen Bezug zu afrikanischen Ländern aufweisen erreicht.
2.2 Z ITATE -S CANNER
Zur Beantwortung der Frage, ob in Afrika geborene Menschen seltener zu Wort kommen, also
seltener direkt zitiert werden als solche von anderen Kontinenten, kam ein eigens entwickeltes
Skript zum Einsatz. Dieses suchte nach Zitaten, indem es im Artikeltext nach Anführungszeichen
Ausschau hielt und prüfte, ob das potenzielle Zitat durch ein auf direkte Rede hindeutendes Prä-
dikat im Begleitsatz eingeleitet wurde.44 Mithilfe der grammatikalischen Abhängigkeitsbestim-
mung, die spaCy bietet, konnten typische Konstruktionen – wie ein vorausgehender Begleitsatz
41
Vgl. die Ergebnisliste der der vom selbst entwickelten Schlüsselbegriffsscanner erkannten Schlüsselbegriffe im
eingangs zitierten Spiegel-Artikel „Ein schwarzer Holocaust“ im Anhang 1.3.
42
Der Programmcode für die Schlüsselbegriffsanalyse findet sich auf der beigefügten CD und unter
https://github.com/matthmeyer/keyword-scanner. Das Skript kann ohne Programmierkenntnisse hier ausprobiert
und auf seine Funktion getestet werden: https://journospective.de/tools/text/.
43
OpenStreetMap ist ein 2004 begründetes Projekt, das frei nutzbare Geodaten sammelt und für jedermann in einer
dem Open-Data-Prinzip folgenden Datenbank zur Verfügung stellt. Vgl. überblicksartig Frederik Ramm/Jochen
Topf, OpenStreetMap. Die freie Weltkarte nutzen und mitgestalten. (3. Aufl.) Berlin 2010. Damit beziehen sich
die im weiteren Verlauf genannten Länderzuordnungen leider undifferenziert auf heutige Ländergrenzen. Hier
ergäbe sich Verbesserungsbedarf.
44
Eine Auflistung der zur Analyse herangezogenen Verben ist in Anhang 1.4 aufgeführt. Insbesondere in journalis-
tischen Texten fehlt oft das Prädikat im Begleitsatz und stattdessen findet sich eine Konstruktion mit „so“ – bei-
spielsweise heißt es im eingangs dieser Arbeit zitierten Spiegel-Artikel: „‚Nur die Vereinigten Staaten‘, so Bush
stolz, ‚haben die globale Reichweite, eine so große Streitmacht an einem so weit entfernten Ort einzusetzen.‘“ Für
diesen Fall findet sich eine Ausnahmeregelung im Skript.
10mit Doppelpunkt zwischen Begleitsatz und direkter Rede oder ein nachgestellter beziehungsweise
eingeschobener Begleitsatz mit Komma zwischen direkter Rede und Begleitsatz – erkannt und als
Validierung herangezogen.45
Entscheidend ist, dass es bei diesem Untersuchungsaufbau auch möglich war, das Subjekt des
Begleitsatzes ausfindig zu machen. Unter Zuhilfenahme der im vorangegangenen Kapitel vorge-
stellten Schlüsselbegriffserkennung konnten den Subjekten, wenn es sich um einen Namen han-
delte, der entsprechende Wikipedia-Eintrag zugeordnet werden. Dieser beinhaltete, sofern öffent-
lich bekannt, auch Informationen zum Geburtsort der Person.46 Durch dieses Verfahren war es
möglich 158.629 Zitate einer konkreten Person zuordenbare Zitate ausfindig zu machen.47
2.3 S ENTIMENT -A NALYSE
Ob bestimmte Texte eine positive oder negative Tendenz aufweisen, das heißt, ob im konkreten
Beispiel über afrikanische Länder in der deutschen Presse negativer berichtet wurde als über an-
dere, ist nicht leicht zu bestimmen – insbesondere wenn dies für einen großen Korpus geschehen
soll. Eine Annäherung bietet eine Sentimentanalyse.48 Sentimentanalysen beruhen auf sogenann-
ten Polaritätslexika. Ein solches Lexikon listet positive und negative Wörter auf und gibt zu jedem
Wort eine als Zahl ausgedrückte Polarität an, in der Regel normalisiert von -1 für negativ über 0
für neutral bis 1 für positiv. Anhand eines Übergewichts an negativen oder positiven Wörtern lässt
sich die Tendenz eines Artikels bestimmen.49 Entscheidend ist die Existenz eines guten Polaritäts-
lexikons in der entsprechenden Sprache, das im besten Fall auch für die entsprechende Textgattung
erstellt wurde.50
Große Vorarbeit für die deutsche Sprache haben dazu Gerhard Heyer, Uwe Quasthoff und Ro-
bert Remus geleistet. Unter dem Projekttitel „SentiWS“ veröffentlichten die Leipziger Computer-
linguisten ein Polaritätslexikon, das in der letzten am 19.10.2018 veröffentlichten Version 1.644
positive und 1.827 negative Wörter beinhaltet. Damit besteht das Lexikon nicht nur aus Adjektiven
45
Im Kern beruht das Skript damit auf Erkenntnissen der als „Dependency Parsing“ bezeichneten Methode. Diese
stammt aus der Computerlinguistik. Vgl. zu den Funktionsmechanismen Wenliang Chen/Min Zhang, Semi-Su-
pervised Dependency Parsing. Singapur 2015.
46
Der Geburtsort findet sich in den Wikipedia-Artikeln meist in Klammern hinter dem Namen im ersten Abschnitt
oder seltener erkennbar an einem „geboren in“ im Fließtext. Somit lässt sich der Ort mit Regular Expressions
aufspüren. Von 408.281 als Schlüsselbegriff erfassten Personen in der Datenbank, konnten so 281.779 Personen
Informationen zum Geburtsort ergänzt werden. Die entstandene Liste von Personen und Geburtsorten kann auf
der beigefügten CD und unter https://github.com/matthmeyer/Bekannte-Personen-und-deren-
Geburtsort/ eingesehen werden.
47
Das verwendete Skript zur Zitaterkennung findet sich auf der beigefügten CD.
48
Vgl. Alessandro Marchetti/Giovanni Moretti/Rachele Sprugnoli/Sara Tonelli, Towards Sentiment Analysis for
Historical Texts, in: Digital Scholarship in the Humanities 31,4. 2016, 762-772.
49
Vgl. ebd., 762-763.
50
Der Forschungsschwerpunkt liegt dabei bisher auf der englischen Sprache. Dabei fokussierten sich die Auswer-
tungen meist auf soziale Netzwerke, Rezensionen und politische Reden, die sich allesamt nur bedingt auf Nach-
richtenartikel übertragen lassen. Vgl. ebd., 763.
11und Adverbien, die unmittelbar negativ wie „schädlich“ oder positiv wie „hervorragend“ sind,
sondern auch aus Substantiven und Verben, die implizit auf eine negative oder positive Tendenz
schließen lassen, da sie überproportional häufig in entsprechend tendenziösen Texten vorkom-
men.51 Die Initiatoren von „SentiWS“ entwickelten das Projekt ursprünglich zur Auswertung von
Finanznachrichten. Damit kommt die Textgattung des in dieser Arbeit verwendeten Korpus dem
des von den Initiatoren intendierten nahe, auch wenn die hier untersuchten Nachrichtenrubriken
über Finanznachrichten hinausgehen.
Die letztendliche Sentimentanalyse der Nachrichtenartikel fand folgendermaßen statt: Der
Fließtext wurde in Einzelwörter unterteilt. Die Einzelwörter wurden mithilfe von spaCy lemmati-
siert, also in ihre Grundform gebracht, und im Polaritätslexikon nachgeschlagen. Die aufaddierten
Polaritätswerte geteilt durch die Gesamtanzahl an Wörtern im Fließtext ergibt das Sentiment des
Artikels. Für eine bessere Lesbarkeit wurden die Ergebnisse mit dem Faktor 10.000 multipliziert.
2.4 R UBRIK -A NALYSE
Journalistische Zeitungen und Magazine teilen ihre Artikel in der Regel in Rubriken auf. Für
eine Datenanalyse sind diese als Merkmal höchst interessant. Probleme ergeben sich allerdings
aus der untereinander stark abweichenden Aufteilungspraxis. So existieren im Spiegel folgende
Rubriken: „Titel“, „Meinung“, „Deutschland“, „Gesellschaft“, „Wirtschaft“, „Ausland“, „Wissen-
schaft+Technik“, „Sport“ und „Kultur“. Die Zeit unterteilt in die Rubriken „Politik“, „Dossier“,
„Geschichte“, „Fußball“, „Wirtschaft“, „Wissen“, „Feuilleton“, „Glauben und Zweifel“, „Entde-
cken“ und „Chancen“.
Um dennoch eine konstante Einteilung in Rubriken zu ermöglichen, wurde ein Tool entwickelt,
das mittels statistischer Annäherung dem Artikeltext eine Rubrik zuordnet. Als Grundlage für die-
ses Tool dienten 400.000 Artikel von „SPIEGEL ONLINE“ aus den Rubriken „Politik“, „Pano-
rama“, „Sport“, „Wirtschaft“, „Kultur“, „Technik“, „Reise“, „Auto“, „Gesundheit“ und „Wis-
sen“.52 Zunächst wurde die Häufigkeit aller in diesem Korpus befindlichen Wörter aufsummiert,
anschließend die Häufigkeit des Wortes in den jeweiligen Rubriken. Je stärker die prozentuale
Häufigkeit eines Wortes innerhalb einer Rubrik im Vergleich zur Häufigkeit im gesamten Korpus
ist, desto markanter ist das Wort für Rubrik. Für jedes Wort in diesem Korpus konnte so für jede
51
Vgl. Gerhard Heyer/Uwe Quasthoff/Robert Remus, SentiWS. A Publicly Available German-language Resource
for Sentiment Analysis, in: Nicoletta Calzolari (Hrsg.), Proceedings of the Seventh International Language
Ressources and Evaluation. Valletta 2010, 1168-1171.
52
„SPIEGEL ONLINE“ bot sich als Grundlage an, da die dort verwendete Aufteilung in Rubriken schlüssig erschien
und zu dem Portal als reichweitenstärksten deutschsprachiges Online-Nachrichtenangebot eine ausreichend große
Artikelmenge leicht zum Herunterladen bereitstand. Die Rubriken der Artikel auf dem Portal lassen sich prob-
lemlos aus den Artikel-URLs auslesen.
12Sie können auch lesen

















































