Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018 Herausgeber
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Wissenstransfer in der
Wirtschaftsinformatik
Fachgespräch im Rahmen der MKWI 2018
Herausgeber:
Prof. Dr. Georg Rainer Hofmann
Prof. Dr. Wolfgang Alm
In Kooperation mit:
Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018
1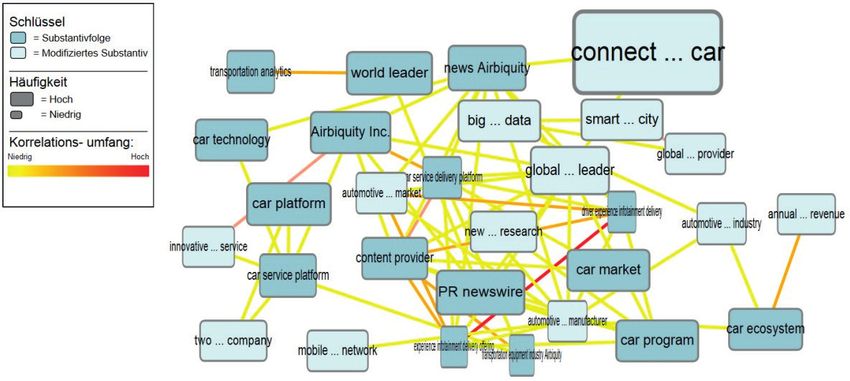
IMPRESSUM
Herausgegeben von Hochschule Aschaffenburg
Information Management Institut
Würzburger Straße 45
D-63743 Aschaffenburg
Redaktion: Meike Schumacher
Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018
2
Autoren:
Prof. Dr. Frank Bensberg, Hochschule Osnabrück, Caprivistr. 30a, 49076 Osnabrück
Prof. Dr. Gunnar Auth, Prof. Dr. Christian Czarnecki, Hochschule für Telekommunikation Leipzig,
Gustav-Freytag-Str. 43-45, 04277 Leipzig
Daniel Hilpoltsteiner, Prof. Dr. Christian Seel, Julian Dörndorfer, Hochschule Landshut, Institut
für Projektmanagement und Informationsmodellierung (IPIM), Am Lurzenhof 1, 84036 Landshut
Prof. Dr. Carsten Reuter, Prof. Dr. Erich Ruppert, Meike Schumacher, Hochschule Aschaffenburg,
Information Management Institut (IMI), Würzburger Straße 45, 63743 Aschaffenburg
Die Deutsche Bibliothek – CIP Einheitsaufnahme
„Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018“
Herausgegeben von:
Georg Rainer Hofmann, E-Mail: georg-rainer.hofmann@h-ab.de und
Wolfgang Alm, E-Mail: wolfgang.alm@h-ab.de
Information Management Institut, Hochschule Aschaffenburg
Aschaffenburg, 15. Juni 2018
ISBN 978-3-9818442-0-7
In Kooperation mit
HOCHSCHULE ASCHAFFENBURG
INFORMATION MANAGEMENT INSTITUT
Würzburger Straße 45
D-63743 Aschaffenburg
Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018
3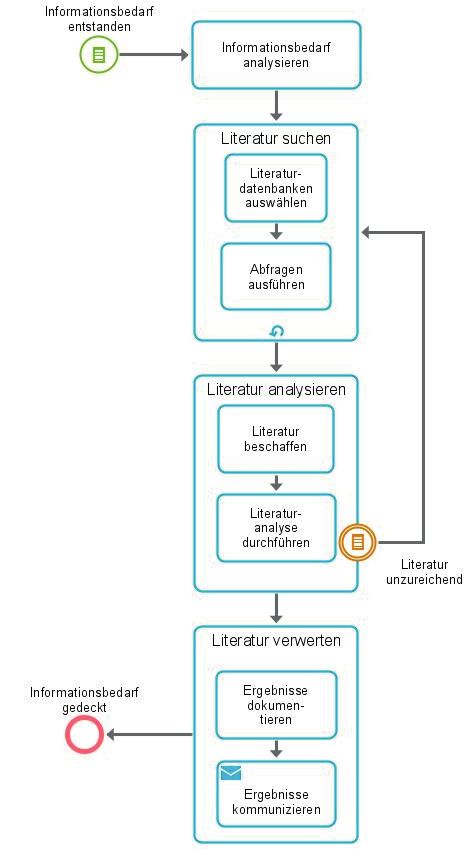
Vorwort
Die Multikonferenz Wirtschaftsinformatik (MKWI) fand im März 2018 in Lüneburg bereits zum
zehnten Mal statt. Seit dem Jahr 2000 trifft sich im zweijährigen Turnus die Scientific Community,
um diverse aktuelle Entwicklungen der IT und deren ökonomisches Umfeld zu erörtern. Die
beiden Fachgruppen der Gesellschaft für Informatik e.V. „Software- und Service-Markt“ (SWSM)
und „Wirtschaftsinformatik an Hochschulen“ (AKWI) haben zu diversen Thematiken rund um
den „Wissenstransfer in der Wirtschaftsinformatik“ in mittlerweile einigen Konferenzen der
Serie der MKWI mitgewirkt.
Der Wissenstransfer von den Hochschulen in die Praxis der gewerblichen Wirtschaft und der
Verwaltungspraxis in seinen verschiedenen Formen wird in der aktuellen politischen Diskus-
sion nachdrücklich gefordert und unterstützt. Durch ihren interdisziplinären und angewandten
Charakter erfordert die Wirtschaftsinformatik ein zum Teil sehr spezifisches Vorgehen beim
Wissenstransfer.
Im Rahmen des Lüneburger MKWI-Workshops am 06. März 2018 wurden konkrete Fragestellun-
gen im Wissenstransfer der Wirtschaftsinformatik adressiert:
• Wenn die Wirtschaftsinformatik den „Wissenstransfer“ akquisitorisch adressieren will, wer
sind die typischen Projektpartner und wie gestalten sich deren Interessen?
• Ist man weniger an Forschungsprojekten und neuen Forschungsergebnissen, als vielmehr
am Transfer und der Aufbereitung von gültigen und verwertbaren Erkenntnissen interes-
siert - eher Wissenstransfer statt Forschung?
• Hat man Interesse an Wissenstransfer im Vorwettbewerb („Awareness Service“), auch in
Verbindung mit der Arbeit in den diversen Verbänden?
• Hat man beim Wissenstransfer andere Entscheidungswege im Unternehmen; sind diese
kürzer? Erwartet man dafür aber auch schneller die Ergebnisse, kürzere Projekte, absolut
präzise und passende Zuarbeit, Effizienz?
Der Workshop brachte Vertreter von Wissenstransfermaßnahmen in einem Offenen Diskurs
zusammen, einschlägige Erfahrungen wurden ausgetauscht. Wir bedanken uns bei allen Be-
teiligten, die zum Erfolg der Veranstaltung beigetragen haben – insbesondere bei den Autoren
und Referenten der Beiträge.
Aschaffenburg im Mai 2018, für die GI-Fachgruppe „Software- und Service-Markt“
Prof. Dr. Georg Rainer Hofmann, Sprecher
Prof. Dr. Wolfgang Alm, stv. Sprecher
Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018
4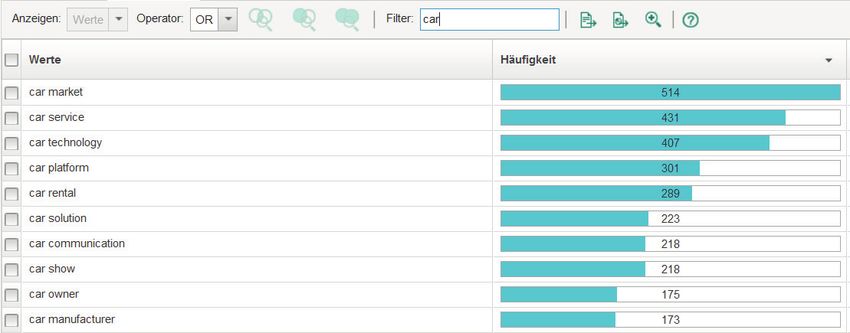
Inhalt
Vorwort4
Unterstützung von Wissenstransferprozessen durch Erschließung von 6
Literaturdatenbanken
1 Problemstellung 6
2 Werkzeugunterstützung für die systematische Literaturrecherche 7
3 Literaturanalyseprozess 9
4 Demonstration des Ansatzes 11
5 Fazit und Nutzenpotenziale 14
Konzeption und Implementierung eines Softwarewerkzeuges zum 16
Management von BPMN-Prozessvarianten
1 Motivation 16
2 Forschungsmethodik 18
2.1 Stand der Forschung 18
2.2 Erweiterung der BPMN 19
2.3 Konzeption und Implementierung der Softwarewerkzeuges 21
2.4 Evaluation 22
2.5 Fazit 24
Offline in die Digitale Transformation? Wie sollte der Wissenstransfer zur 26
Bewältigung von Herausforderungen im Zuge der Digitalen Transformation
gestaltet werden?
1 Rahmenbedingungen „mainproject2018“ 26
2 Formate des Wissenstransfers im „mainproject2018“ 27
3 Akzeptanz und Wünsche für den Wissenstransfer in KMU 29
3.1 Ein Blick in die Literatur 29
3.2 Ergebnisse aus einer Befragung im Unternehmensnetzwerk des „mainproject2018“ 29
3.3 Anekdotische Evidenz aus Gesprächen im Projektbeirat 33
4 Schlussfolgerung für den digitalen Wissenstransfer 34
5 Ausblick 35
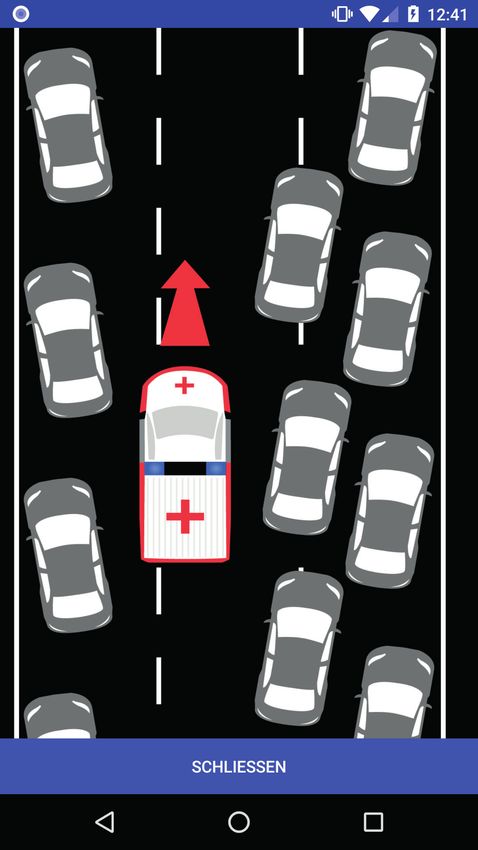
Mobiler Helfer zur Bildung einer Rettungsgasse - Anwendungsbeispiel für 37
Kontexterkennung durch Apps
1 Einleitung 37
2 Mobile kontext-sensitive Anwendungen 38
3 Algorithmus zur Erkennung der Staurelevanz 39
4 Architektur 41
4.1 Server 41
4.2 Client 42
5 Fazit und Ausblick 44
Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018
5
Unterstützung von Wissenstransferprozessen durch Erschließung von
Literaturdatenbanken
Frank Bensberg
Hochschule Osnabrück
Caprivistr. 30a, 49076 Osnabrück
F.Bensberg@hs-osnabrueck.de
Gunnar Auth
Christian Czarnecki
Hochschule für Telekommunikation Leipzig
Gustav-Freytag-Str. 43-45, 04277 Leipzig
auth@hft-leipzig.de
czarnecki@hft-leipzig.de
Abstract: Angesichts des anhaltenden Wachstums wissenschaftlicher Veröffentlichungen werden Instrumente benötigt, um Litera-
turanalysen durch Digitalisierung produktiver zu gestalten. Dieser Beitrag stellt einen Ansatz vor, der bibliographische Daten aus der
Literaturdatenbank EBSCO Discovery Service mithilfe von Text-Analytics-Methoden erschließt. Die Lösung basiert auf dem Text-ana-
lysesystem IBM Watson Explorer und eignet sich für explorative Literaturanalysen, um beispielsweise den Status quo emergierender
Technologiefelder in der Literatur zu reflektieren. Die generierten Ergebnisse sind in den Kontext der zunehmenden Werkzeugunter-
stützung des Literaturrechercheprozesses einzuordnen und können für intra- sowie interinstitutionelle Wissenstransferprozesse in
Forschungs- und Beratungskontexten genutzt werden.
Keywords: Wissenstransfer, Text Analytics, Literaturdaten, Literaturanalyse, Literaturanalyse-prozess, Literaturreview, Korrelations-
analyse, EBSCO Discovery Service, IBM Watson Explorer
1 Problemstellung
Durch die Möglichkeit des Zugriffs auf etablierte Literaturdatenbanken verfügen Hochschulen
über ein hohes Wissenspotenzial, das einem stetigen Wachstum unterliegt. So verdoppelt sich
die Anzahl der wissenschaftlichen Publikationen innerhalb von ca. 24 Jahren [BM15]. Damit
wird die Fragestellung aufgeworfen, wie dieses Potenzial für Wissenstransferprozesse effektiv
und effizient erschlossen werden kann. Zur Steigerung der Produktivität bei der Literaturanaly-
se bietet sich der Einsatz von Methoden der Textanalyse (Text Analytics) an, die Texte automa-
tisch verarbeiten können [FS06].
Dieser Beitrag stellt einen gestaltungsorientierten Ansatz vor, um Daten aus Literaturdatenban-
ken durch Text-Analytics-Methoden zu erschließen. Der Ansatz basiert auf dem EBSCO Disco-
very Service, der von zahlreichen Hochschulbibliotheken eingesetzt wird und eine einheitliche
Suchumgebung für Literaturrecherchen anbietet [Ba15]. Darauf aufbauend wird das Text-Ana-
lytics-System IBM Watson Explorer [ZFG14] genutzt, das die interaktive, explorative Analyse
bibliographischer Daten ermöglicht.
Grundsätzlich ist eine zunehmende Werkzeugunterstützung des Literaturrechercheprozesses zu
beobachten, wobei die Literaturanalyse noch stark manuell geprägt ist. Zur Veranschaulichung
wird zuerst die Werkzeugunterstützung aus Gesamtprozesssicht diskutiert und der in diesem
Beitrag vorgeschlagene Ansatz anhand eines allgemeinen Literaturanalyseprozesses einge-
führt. Aufbauend auf diesem fachkonzeptionellen Bezugsrahmen wird die Anwendung des
Ansatzes im Kontext eines Szenarios demonstriert und abschließend dessen Nutzenpotenziale
herausgestellt.
Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018
6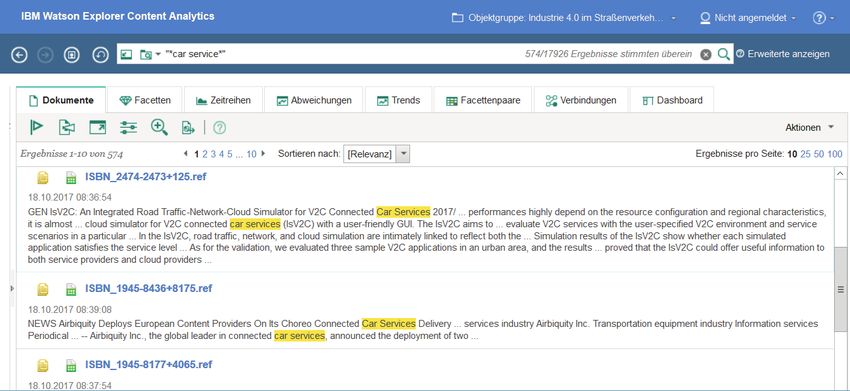
2 Werkzeugunterstützung für die systematische Literaturrecherche
Die Literaturrecherche gilt gemeinhin als unverzichtbarer Initialschritt für die methodische und
fundierte Bearbeitung wissenschaftlicher Fragestellungen, die auf einen Erkenntnisgewinn
über das bereits vorhandene Wissen hinaus zielt (z. B. [vB+15], [StSu17]). So wird beispiels-
weise auch bei gestaltungsorientierten Arbeiten erst durch die Verbindung zur bestehenden
Wissensbasis ein Erkenntnisgewinn ermöglicht [He+04]. Für die Wirtschaftsinformatik benen-
nen STURM und SUNYAEV drei grundlegende Anforderungen an eine „gute“ Literaturrecherche:
Vollständigkeit (comprehensiveness), Präzision (precision) und Reproduzierbarkeit (reproduci-
bility) [StSu17]. Diese Anforderungen stellen vom Brocke et al. zugleich an eine systematische
Literaturrecherche, die sich aus einer Methodenperspektive von einer narrativen Literaturre-
cherche unterscheiden lässt [vB+15]. Während die narrative Variante primär auf der fachlichen
Expertise des ausführenden Wissenschaftlers basiert – und damit anfällig für eine gewisse
Subjektivität bzgl. Quellenauswahl und -bewertung ist – basiert die systematische Literaturre-
cherche auf einem expliziten Prozess mit objektiv definierten Kriterien.
Betrachtet man die Literaturrecherche als Ergebnis des Rechercheprozesses (Outputperspek-
tive), so ist festzustellen, dass gerade bei manueller Durchführung die Ergebnisqualität im
Hinblick auf Vollständigkeit und Präzision stark vom eingesetzten Zeitaufwand abhängig ist
[StSu17]. Vor diesem Hintergrund sind bereits frühzeitig Softwaresysteme bzw. Werkzeuge
entwickelt worden, deren Einsatz die Effizienz und Effektivität des Rechercheprozesses verbes-
sert. Entlang der wesentlichen Schritte des Rechercheprozesses lassen sich unterschiedliche
Werkzeugtypen identifizieren, die im Folgenden zu erörtern sind.
Suchen
Wie viele andere Bereiche hat das Internet auch die Suche nach Literatur stark verändert. In
der Prä-Internet-Ära war die Suche nach Literatur quasi gleichbedeutend mit dem Aufsuchen
einer Bibliothek. Dort stand mit dem Bibliothekskatalog ein lokales Verzeichnis der in der
Bibliothek verfügbaren Bücher und Schriften bereit, um das Vorhandensein eines bestimmten
Werks zu prüfen und dessen Standort zu ermitteln. Bis in die 1990er Jahre bediente man sich
dabei häufig noch der Mikrofilm-Technik. Bibliographische Daten wurden dazu auf analoge
Filmkarten übertragen und konnten mit speziellen Lesegeräten vergleichsweise schnell durch-
sucht werden. Abgelöst wurde diese Technologie durch datenbankgestützte Bibliothekskata-
logsysteme, wie sie im Kern auch heute noch im Einsatz sind. Mit dem Internet erweiterten
sich die Möglichkeiten der Literatursuche erheblich. Zunächst konnten lokale Bibliothekskata-
loge einrichtungsübergreifend miteinander zu Verbundkatalogen vernetzt werden. Die Menge
der darin verzeichneten und von einem Standort durchsuchbaren Quellen vergrößerte sich
dadurch erheblich. Darüber hinaus entfiel aber auch die Notwendigkeit des Bibliotheksbesuchs
für die Literatursuche. Über einen an das Internet angebundenen Computer wurde dies prinzi-
piell auch vom Arbeitsplatz an der Hochschule oder auch von zuhause aus möglich – und später
ortsunabhängig mit mobilen Endgeräten (z. B. Laptop oder Smartphone). Diesen Entwicklungs-
schritt markiert das Akronym OPAC (Online Public Access Catalogue), das sich als Bezeichnung
für webbasierte Bibliothekskataloge etabliert hat. Neben dem Internetzugang erfordert die
bibliotheksunabhängige Literatursuche jedoch auch spezielle Software-Werkzeuge, die sich bis
heute in unterschiedlichen Ausprägungen entwickelt haben:
Auf Literatursuche spezialisierte Web-Suchmaschinen bzw. Online-Literaturdatenbanken, wie
sie von Bibliotheken, Fachbereichen, Forschungseinrichtungen u. a. bereitgestellt werden.
In dieser Kategorie gibt es ein breites Spektrum unterschiedlicher Angebote, das sich durch
Fachbezüge, Medientypen (z. B. nur Zeitschriften), technologische Realisierung, Zugriffsbe-
Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018
7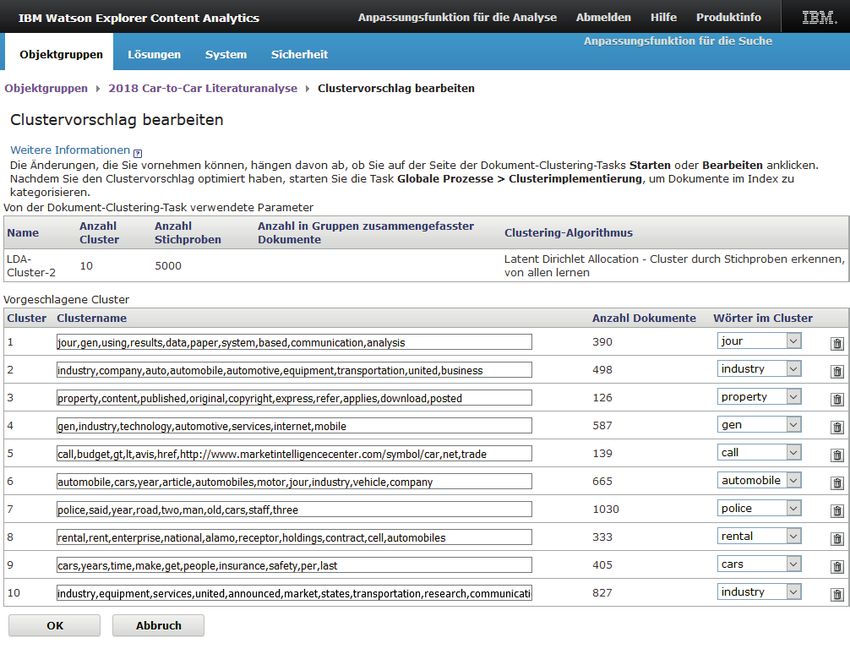
schränkungen und andere Merkmale differenziert. Als Ableger klassischer Web-Suchmaschinen werden auch Google Scholar und Microsoft Academic Search verortet. Auch für die Ziele der Open-Access-Bewegung haben spezialisierte Web-Suchmaschinen wie bspw. BASE (Bielefeld Academic Search Engine) eine große Bedeutung. Meta-Suchmaschinen, die es erlauben, über eine einzige Benutzeroberfläche Suchanfragen gleichzeitig an mehrere Literaturdatenbanken zu schicken und die Ergebnisse integriert zu be- trachten. Beispielsweise wird von der Bibliothek des Karlsruher Instituts für Technologie (KIT) seit 1996 der Karlsruher Virtueller Katalog (KVK) entwickelt und betrieben. Ein ähnliches Prinzip verfolgen Discovery-Systeme, die dazu allerdings einen eigenen integ- rierten Suchindex aufbauen, über den verschiedene Datenquellen durchsucht werden können. Neben Komfortfunktionen nach dem Vorbild führender Web-Suchmaschinen (z. B. Korrektur von Eingabefehlern und Autovervollständigen von Suchanfragen während der Eingabe mit Historie-basierten Vorschlägen) zeichnen sich diese Systeme durch das sog. explorative Suchen aus, bei dem das System neben den eigentlichen Suchtreffern auch weiterführende Vorschläge mit thematisch verwandten Literaturquellen liefert, die mit der originären Suchanfrage nicht selektiert wurden. Solche Systeme werden kommerziell (EBSCO Discovery Service, Ex Libris Primo etc.) und von Bibliotheken (z. B. VuFind von der Universitätsbibliothek der US-amerikani- schen Villanova Universität oder das darauf basierende finc der Universitätsbibliothek Leipzig) entwickelt. Noch einen Schritt weiter gehen die digitalen Bibliotheken von Verlagen (SpringerLink, Elsevier ScienceDirect, Emerald Insight, etc.) oder Fachgesellschaften (ACM Digital Library, IEEEXplo- re, AIS eLibrary, etc.), die neben Suchfunktionen auch den direkten Zugriff auf elektronische Volltextdokumente bieten und damit dem Nutzer – bei Vorhandensein der erforderlichen Lizenz – auch für die Literaturbeschaffung eine virtualisierte Durchführung ermöglichen. Die jüngste Entwicklung im Bereich der Literatursuche umfasst das Aufkommen von sozia- len Netzwerken, die sich eigens an Wissenschaftler und Forscher richten und das Prinzip des benutzergenerierten Inhalts (usergenerated content) auf wissenschaftliche Publikationen übertragen. Durch gezielte Anreizsetzung, wie beispielsweise durch einen eigenen Impact Score, werden Autoren dazu motiviert, die bibliographischen Daten ihrer Publikationen selbst zu erfassen und darüber hinaus auch Volltexte elektronisch bereitzustellen. Dem Autor wird die Möglichkeit eines selbstgepflegten elektronischen Publikationsverzeichnisses geboten, das durch den Netzwerkeffekt eine potenziell hohe Sichtbarkeit ermöglicht. Darüber hinaus entsteht nach dem Crowdsourcing-Prinzip eine umfassende Literaturdatenbank mit hoher Datenqualität. Dabei werden die bewährten Funktionalitäten der bisherigen Werkzeugtypen integriert und um kollaborative Funktionen sozialer Netzwerke erweitert. Beispiele hierfür sind ResearchGate, ScienceOpen und academia.edu. Analysieren Ist die als Ergebnis der Suche identifizierte Literatur beschafft, beginnt die Analyse mit der Prüfung der tatsächlichen Relevanz für die eigenen Erkenntnisziele durch zielgerichtetes Lesen und Auswerten. Suche und Analyse werden häufig zu einem iterativen Prozess verbunden, bei dem durch Filterung zunächst erfasste Literatur wieder als irrelevant verworfen und weitere Literatur über Quellenangaben (Vorwärtssuche) oder Ermittlung zitierender Literatur (Rück- wärtssuche) zur eigenen Literaturauswahl hinzugefügt wird. Durch inhaltliche Analyse und Interpretation können zudem Erkenntnisse erarbeitet werden, die zu einer Anpassung der ursprünglichen Suchanfrage führen. Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018 8
Verwalten und verwerten
Mit zunehmender Zahl der gefundenen und als relevant bewerteten Quellen entsteht schnell
der Bedarf, die Suchergebnisse zu sichern, zu ordnen und zu exzerpieren. Der früher gebräuch-
liche Zettelkasten wurde als Werkzeug für diesen Schritt schon lange durch Literaturmanage-
mentsoftware abgelöst, wie beispielsweise EndNote, RefWorks oder Citavi. Auch hier hat das
Internet neue Möglichkeiten erschlossen, wie etwa das kollaborative Erstellen und Nutzen von
Literatursammlungen oder die Synchronisierung von Literatursammlungen zwischen mehreren
(auch mobilen) Computern. Auf diese Möglichkeiten fokussieren beispielsweise Mendeley und
Zotero, die auch als Erweiterung (Plug-in) für gängige Webbrowser verfügbar sind.
Auch die Verwertung, beispielsweise durch Einfügen von Kurzreferenzen und Zitaten in eigene
Texte, Erstellung von Literaturverzeichnissen und Aufbereitung nach unterschiedlichen Zitiersti-
len, wird von den Werkzeugen für Literaturmanagement unterstützt, häufig auch in Form eines
Plug-in für Textverarbeitungssysteme.
Zusammenfassend ist festzuhalten, dass die gesamte Literaturrecherche vom Suchen bis hin
zum Verwerten durch unterschiedliche Werkzeugtypen unterstützt wird. Dabei sind zuneh-
mende Virtualisierung und Kollaboration als Entwicklungstendenzen erkennbar. Jedoch ist die
Literaturanalyse noch stark durch manuelle Tätigkeiten geprägt. Insofern erscheint die Frage-
stellung einer Werkzeugunterstützung des Literaturanalyseprozesses als logische Konsequenz
und wird in den folgenden Abschnitten diskutiert.
3 Literaturanalyseprozess
Die zentralen Aktivitäten des Literaturanalyseprozesses im Kontext der systematischen Litera-
turrecherche für die Zwecke des Wissenstransfers zeigt Abbildung 1.
Aus Gesamtprozesssicht wird die Literaturrecherche durch einen entstandenen Informations-
bedarf ausgelöst, der anschließend mithilfe von Methoden zur Informationsbedarfsermittlung
zu analysieren ist. Insofern ist zwischen Suchen und Analysieren ein iterativer Zusammenhang
gegeben. In Forschungsdesigns der Wirtschaftsinformatik bezieht sich dieser Informationsbe-
darf typischerweise auf Informationssysteme im Kontext bestimmter Anwendungsfelder (z.B.
Sektoren, Branchen, Funktionsbereiche) und die erforderlichen Werkzeuge (z. B. Technologien,
Sprachen, Konzepte) zu deren Entwicklung oder Betrieb. Auf Grundlage des ermittelten Infor-
mationsbedarfs werden Literaturdatenbanken ausgewählt und mit geeigneten Abfragen durch-
sucht (Suchphase). Die Ergebnisse umfassen Fundstellen mit ihren bibliographischen Daten, wie
z. B. Autorennamen, Publikationsjahr, Publikationsart, Schlagworte und Kurzzusammenfassung
(Abstract). Auf Grundlage der Fundstellen ist die als relevant erachtete Literatur zu beschaffen,
sodass anschließend das zielgerichtete Lesen und Auswerten erfolgen kann (Analysephase).
Dabei kann der Fall auftreten, dass sich die vorliegende Literatur als unzureichend herausstellt,
sodass die Suchaktivitäten zu wiederholen sind. Abgeschlossen wird der Literaturanalysepro-
zess durch Verwertungsaktivitäten. Zum Zweck des Wissenstransfers sind dabei die Ergebnisse
aus der Analysephase zu dokumentieren und schließlich an die relevanten Akteure zu kommu-
nizieren (Verwertungsphase), sodass der Literaturanalyseprozess mit der Deckung des Informa-
tionsbedarfs endet.
Zur Unterstützung der Analysephase sind dem Anwender einerseits solche Instrumente zur
Verfügung zu stellen, die seine kognitiven und motorischen Handlungen beim Lesen und Inter-
pretieren der Literaturquellen entlasten und somit die Effizienz von Literaturanalysen steigern
können. Andererseits sind auch solche Instrumente von Interesse, welche die Effektivität von
Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018
9
Literaturanalysen verbessern können, indem eine systematischere und somit ggf. objektivere
Auswertung von Literaturquellen ermöglicht wird. Damit geht etwa auch die Zielsetzung einher,
die Anwendung von Heuristiken und sonstige kognitive Verzerrungen bei der Erschließung von
Literaturdaten zu vermeiden.
Einen methodisch tragfähigen Ansatzpunkt hierfür bilden Verfahren zur Textanalyse (Text
Analytics), die auch unstrukturierte Textdaten verarbeiten können. Dabei können im Kontext
der Literaturanalyse nicht nur digitalisiert vorliegende Volltexte berücksichtigt werden, sondern
auch bereits diejenigen bibliographischen Daten, die Literatursuchmaschinen bzw. Literatur-
datenbanken in der Suchphase zurückliefern, wie beispielsweise Kurzzusammenfassungen
(Abstracts). Im Folgenden wird daher ein Ansatz demonstriert, der die Ergebnisse des EBSCO
Discovery Service für die explorative Analyse mithilfe textanalytischer Verfahren aufbereitet.
Abb. 1: Prozess zur datenbankgestützten Literaturanalyse (BPMN 2.0-Prozessdiagramm)
Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018
104 Demonstration des Ansatzes
Zur Demonstration wird ein praktisches Anwendungsszenario für einen hochschulinternen
Wissenstransferprozess zugrunde gelegt. Bei der Vorbereitung einer interdisziplinären, fakul-
tätsübergreifenden Lehrveranstaltung zum Thema Industrie 4.0 im Straßenverkehr ist die
Frage aufgeworfen worden, welche Konzepte in der Domäne Connected Car relevant sind. Zur
Schaffung einer Datenbasis ist daher im EBSCO Discovery Service eine entsprechende Abfrage
formuliert worden, die sämtliche Quellen lokalisiert, welche die Schlagworte Connected Car,
Car-to-Car, C2C, C2X oder C2I enthalten. Auf diese Weise wurden 17.926 Fundstellen mit Abs-
tracts identifiziert. Diese Daten können in unterschiedlichen Formaten (z. B. RIS, XML) expor-
tiert werden, sodass die folgenden bibliographischen Kernattribute für einzelne Fundstellen zur
Verfügung stehen:
• Typ der Fundstelle (z. B. Journal, Book, Article),
• Haupttitel bzw. Buchtitel der Fundstelle,
• Autor(en),
• Publikationsjahr,
• Schlagwörter und
• Kurzfassung (Abstract).
Zur Analyse der exportierten Literaturdaten wird auf das Analysesystem IBM Watson Explorer
zurückgegriffen, das unterschiedliche Verfahren zur Textanalyse bereitstellt. So können die
Fundstellen zunächst wie in einer Suchmaschine abgefragt werden. Abb. 2 zeigt die trunkier-
te Suche nach dem Schlagwort car service mit der entsprechenden Ergebnismenge und der
Verwendung des Schlagworts im Kontext (Keyword in Context, KWIC-Analyse). Dabei können
auch komplexere Abfragen mit logischen Operatoren (NOT, AND, OR) formuliert werden, wobei
die Suche auf einzelne bibliographische Attribute (z. B. Autoren, Schlagworte) oder auch Doku-
mentsprachen (z. B. Englisch, Deutsch) limitierbar ist.
Abb. 2: KWIC-Analyse durch Schlagwortsuche
Außerdem besteht die Möglichkeit, unterschiedliche Wortarten (z. B. Substantive, Verben) und
Satzteile (z. B. Substantivfolgen, Verb-Substantiv-Kombinationen) zu identifizieren. Abb. 3 zeigt
einen Ausschnitt der in den Fundstellen enthaltenen Substantivfolgen, in denen der Begriff car
auftritt, mit Angabe der absoluten Häufigkeiten (Frequenzanalyse). Auf diese Weise können
frequente Fachbegriffe (z. B. car service, car platform) in der Literaturdatenbasis identifiziert
werden, die letztlich Hinweise auf relevante Konzepte in bestimmten Forschungsfeldern liefern
können und für die Erstellung von Literaturreviews von Bedeutung sind [WW02].
Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018
11Abb. 3: Gefilterte Frequenzanalyse von Substantivfolgen
Mithilfe einer Zeitreihenanalyse kann die Fragestellung beantwortet werden, wie sich die
Publikationen im Zeitablauf entwickelt haben. Dabei kann nach beliebigen Begriffen gefiltert
werden, sodass die zeitliche Ausbreitung einzelner Fachbegriffe transparent wird. Die folgende
Abbildung zeigt die zeitliche Entwicklung des Fachbegriffs connected car nach Publikationsjahr,
sodass Aussagen über Entwicklungstrends möglich werden.
Abb. 4: Zeitliche Entwicklung des Fachbegriffs connected car nach Publikationsjahr
Durch Korrelationsanalysen können außerdem Zusammenhänge zwischen unterschiedlichen
Konzepten der Fachdomäne ermittelt werden. Abb. 5 zeigt ein Netz hochkorrelierter Substan-
tivfolgen und modifizierter Substantive, aus denen fachliche Zusammenhänge zwischen den
Konzepten deutlich werden (z. B. durch das Tripel connected car, big data, smart city).
Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018
12Abb. 5: Korrelationsanalyse für Substantivfolgen und modifizierte Substantive
Als weitere analytische Aufgabenstellung bietet sich die Segmentierung (Clustering) von Publi-
kationen an, um thematisch homogene Publikationstypen zu identifizieren [HQW12]. Zu diesem
Zweck stellt IBM Watson Explorer unterschiedliche Algorithmen zur Verfügung, wie etwa
K-Means oder LDA (Latent Dirichlet Allocation). Abbildung 6 zeigt das Ergebnis einer Clusterana-
lyse mithilfe des LDA-Verfahrens, das für jeden Cluster ein Set der clustertypischen Begriffe
umfasst. Die Publikationen können anschließend den einzelnen Clustern zugewiesen werden,
sodass die Literaturanalyse auf die Ebene einzelner Literatursegmente fokussiert werden kann.
Abb. 6: Ergebnisse eine Clusteranalyse mithilfe des LDA-Algorithmus
Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018
135 Fazit und Nutzenpotenziale
Für eine systematische Literaturrecherche haben sich in Forschung und Praxis unterschiedliche
Werkzeuge etabliert, um die Effektivität und Effizienz von der Suche bis zur Verwertung zu
verbessern. Da die Literaturanalyse jedoch noch stark manuell geprägt ist, wurde in diesem
Beitrag ein Ansatz basierend auf Text-Analytics-Methoden vorgestellt, der eine automati-
sierte Unterstützung des Wissenstransfers ermöglicht. Die Demonstration in einem konkre-
ten hochschulinternen Anwendungsszenario zeigt, dass sich der vorgeschlagene Ansatz zur
Literaturanalyse als effektiv erweist, um den Status quo eines emergierenden Technologiefelds
in der Literatur detailliert zu untersuchen und dessen zentralen Fachbegriffe, Konzepte und
Entwicklungstrends zu identifizieren.
Die mit diesem Ansatz erzielten Ergebnisse konnten für Wissenstransferprozesse in diversen
Forschungs- und Beratungskontexten erfolgreich genutzt werden. Auch vor dem Hintergrund
der digitalen Transformation von Beratungsdienstleistungen [SeNi16] ist der vorgestellte Ansatz
von praktischer Bedeutung. Sich schnell verändernde ökonomische und technische Rahmen-
bedingungen stellen Beratungsunternehmen vor die Herausforderung, Analysen und Empfeh-
lungen kontinuierlich anzupassen und dabei operative Tätigkeiten zunehmend zu virtualisieren.
Außerdem belegen die gesammelten Erfahrungen, dass Text-Analytics-Lösungen zur Digitalisie-
rung literaturbasierter Forschungsprozesse beitragen und somit eine effizientere Realisierung
ermöglichen, als dies mit traditionellen, manuellen Ansätzen der Literaturrecherche der Fall ist.
Darüber hinaus kann durch die Unterstützung der Literaturanalyse ein höherer Abdeckungsgrad
der verfügbaren Literaturquellen erzielt werden, sodass tendenziell auch eine Verbesserung
der Effektivität von Forschungsprozessen zu erwarten ist. Damit wird insgesamt ein Beitrag
zur zunehmenden Werkzeugunterstützung des Literaturrechercheprozesses geleistet, wobei
die Integration der Werkzeuge entlang des Gesamtprozesses sowie die praktische Nutzung in
Beratungsprojekten interessante Ansatzpunkte für zukünftige Forschungsarbeiten liefern.
Literaturverzeichnis
[Ba15] Bartlakowski, K.: Make the library really look more like google: Zur Einführung des
Discovery-Systems „scinos“ an der Hochschule Osnabrück. Bibliotheksdienst 6/15,
S. 643–648, 2015.
[BM15] Bornmann, L., Mutz, R.: Growth rates of modern science: A bibliometric analysis
based on the number of publications and cited references. J. Assoc. Inf. Sci. Technol.,
S. 2215–2222, 2015.
[FS06] Feldman, R, Sanger, J: The Text Mining Handbook: Advanced Approaches in Analyzing
Unstructured Data. Cambridge University Press, New York 2006.
[He+04] Hevner, A.R., March, S.T., Park, J., Ram, S.: Design Science in Information Systems
Research. MIS Quarterly 28:75–105, 2004.
[HQW12] Heyer, G., Quasthoff, U., Wittig, T.: Text Mining: Wissensrohstoff Text: Konzepte, Algo
rithmen, Ergebnisse. W3L GmbH, Bochum, 2012.
[SeNi16] Seifert, H., Nissen, V. (2016). Virtualisierung von Beratungsleistungen: Stand der For-
schung zur digitalen Transformation in der Unternehmensberatung und weiterer
Forschungsbedarf. Multikonferenz Wirtschaftsinformatik (MKWI) 2016, TU Ilmenau
09. - 11..03.2016.
[StSu17] Sturm, B., Sunyaev, A.: You Can‘t Make Bricks Without Straw: Designing Systematic
Literature Search Systems. Proc. of the 38th International Conference on Information
Systems (ICIS 2017).
Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018
14[vB+15] vom Brocke, J., Simons, A., Riemer, K., Niehaves, B., Plattfaut, R., Cleven, A.: Standing
on the Shoulders of Giants: Challenges and Recommendations of Literature Search in
Information Systems Research, Communications of the Association for Information
Systems: Vol. 37, Article 9, 2015.
[WW02] Webster, J, Watson, R: Analyzing the Past to Prepare for the Future: Writing a Litera-
ture Review. MIS Quarterly 02/2002, S. XIII–XXIII, 2002.
[ZFG14] Zhu, W., Foyle, B., Gagné, D., Gupta, V., Magdalen, J., Mundi, A., Nasukawa, T., Paulis,
M., Singer, J., Triska, M.: IBM Watson Content Analytics: Discovering Actionable Insight
from Your Content, 3. Auflage, IBM, 2014.
Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018
15Konzeption und Implementierung eines Softwarewerkzeuges zum
Management von BPMN-Prozessvarianten1
Daniel Hilpoltsteiner
Christian Seel
Julian Dörndorfer
Hochschule Landshut
Fachbereich Informatik
Am Lurzenhof 1
84036 Landshut
daniel.hilpoltsteiner@haw-landshut.de
christian.seel@haw-landshut.de
julian.doerndorfer@haw-landshut.de
Abstract: In der Praxis treten beim Geschäftsprozessmanagement häufig Prozessvarianten auf. Beispielsweise existieren bei der
Bank eines großen Automobilherstellers für den Leasingprozess eines PKWs spezifische Varianten für verschiedene Länder und
Märkte. Diese Varianten unterschieden sich aber in nur wenigen oder gar einzelnen Modellelementen. Betrachtet man nun aber
mehrere Prozesse, die jeweils mehrere Varianten aufweisen entsteht sehr schnell eine Vielzahl von Modellen, die aber zum Großteil
redundant sind. Um die Modellverwaltung effizient zu gestalten, bietet es sich an, mehrere Varianten in einem Modell zusammen-
zufassen und Gleichteile nur einmal zu modellieren. Allerdings bietet die inzwischen weitverbreitete BPMN bisher kein Konzept
zur Variantenmodellierung. Ferner gelingt der Umgang mit Varianten nur effizient und effektiv, wenn auch eine entsprechende
Softwareunterstützung vorhanden ist, die sowohl die Kennzeichnung mehrerer Varianten in einem Modell erlaubt, als auch die Mög-
lichkeit bietet einzelne Varianten anzuzeigen, z.B. für den entsprechenden Prozess Owner. Daher zielt der vorliegende Beitrag neben
einer Erweiterung der BPMN drauf ab, die Konzeption, Implementierung und Evaluation eines Softwarewerkzeugs zur Modellierung
von BPMN-Prozessvarianten vorzustellen.
Keywords: adaptive Modellierung, Softwarewerkzeug, BPMN 2.0, Geschäftsprozessmodellierung, Wissenstransfer
1 Motivation
Die Informationsmodellierung hat sich in der Wirtschaftsinformatik als zentrales Beschrei-
bungsinstrument für Geschäftsprozesse etabliert [WW02], [Sc98], [Se10]. In der Praxis treten
jedoch Probleme beim Umgang mit Modellvarianten auf [De06]. Probleme beim Management
von Geschäftsprozessvarianten zeigen sich in vielen Branchen und Anwendungsgebieten, zum
Beispiel in der Logistik, im Projektmanagement [TS16] und im Fahrzeugleasing der Bank eines
Automobilherstellers. Beispielsweise unterscheiden sich Einflussfaktoren, wie geltendes Recht
oder regionale Besonderheiten des Marktes in verschiedenen Ländern der Welt, weswegen ein
Informationsmodell für jedes Land einzeln abgewandelt werden muss. Erstellt man hierbei für
jedes Land ein separates Modell, obwohl diese sich nur in wenigen Details unterscheiden, sieht
man sich hier mit großem Aufwand bei der Modellpflege, Erweiterung, sowie mit Inkonsisten-
zen konfrontiert [Se17]. Zur Verdeutlichung der Situation zeigt Abbildung 1 vier verschiedene
Varianten eines Leasingprozesses, die sich lediglich in den rot gefärbten Teilschritten unter-
scheiden. Die schwarz gefärbten Elemente, die den Großteil des Modells ausmachen, sind in
allen Varianten identisch und demnach redundant. In der Praxis sind beispielsweise Varianten
für etwa 50 Länder vorhanden, weswegen in diesem Beispiel die Modellpflege für 30 Prozesse
insgesamt 1500 Modelle umfassen würde. Dadurch entstehen relativ schnell Inkonsistenzen in
den Varianten. Es bietet sich daher an, Varianten eines Prozesses in einem einzigen adaptiven
Informationsmodell zusammenzufassen, um eine Reduktion des Aufwandes zu erreichen.
Konsequent geführte, vollständige Informationsmodelle können zudem zu einer Verbesserung
des Wissenstransfers im Unternehmen führen.
1 Das Technologietransferprojekt „Kompetenznetzwerk Intelligente Produktionslogistik“ wird aus Mitteln des Europäischen Fonds für regionale
Entwicklung (EFRE) – Operationelles Programm mit Ziel „Investition in Wachstum und Beschäftigung“ Bayern 2014 – 2020 gefördert.
Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018
16Abbildung 1 Prozessvarianten im Fahrzeug-Leasing. Quelle: SEEL [SE17]
Das Management von Modellvarianten ist ein permanentes, ubiquitäres und normales Problem
in der Informationsmodellierung und Gegenstand der aktuellen Forschung, wie die Arbeit von
LA ROSA et al. [La17] aufzeigt. In der Literatur existieren bereits Ansätze zur Modellierung von
Prozessvarianten [Rv07], [Be02], [La11], [HBR09], [De15]. Diese weisen in der praktischen Um-
setzung Defizite auf, da die wenigstens eine Softwareunterstützung aufweisen oder auf eine
Standardmodellierungssprache wie BPMN 2.0 (Business Process Model and Notation) [Gr11]
setzen. Der Ansatz von HALLERBACH et al. [HBR09] setzt überwiegend auf Entfernen oder Hin-
zufügen von Teilmodellen über Adjustierungspunkte, anstatt die Informationen in einem ein-
zigen Modell zu pflegen. Das Meta-Modellierungswerkzeug „:em“ von DELFMANN et al. [De15]
unterstützt die Modellierungssprache BPMN 2.0, jedoch nicht die Modellierung von Prozessvari-
anten über Konfigurationsterme. Der Ansatz von LA ROSA unterscheidet sich durch die Verwen-
dung eines Questionaires und nicht der Verwendung von Konfigurationstermen, wodurch ein
erhöhter Aufwand bei der Erstellung und Integration des Questionaire-Modells entsteht [La09].
Auch führende kommerzielle Softwareprodukte wie zum Beispiel Aris Architekt2 unterstützen
die Modellierung mehrere Prozessvarianten in einem gemeinsamen Modell nicht.
Ziel dieses Beitrags ist die Konzeption, Implementierung und Evaluation eines Softwarewerk-
zeuges zum Management von Prozessvarianten. Dieses soll sowohl die Konstruktion (Build-
Time) des Informationsmodells mit verschiedenen Prozessvarianten als auch die Generierung
einzelner Prozessvarianten aus ihm (Run-Time) unterstützen. Bisherige Forschungsansätze
fokussieren mehrheitlich Softwarewerkzeuge zur Präsentation für Modellnutzer (Run-Time) und
2 http://www.softwareag.com/de/products/aris_alfabet/bpa/products/architect_design/capabilities/default.asp, zuletzt abgerufen am 25.09.2017
Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018
17weniger die der Modellerstellung [Th06]. Daher werden folgende Forschungsfragen in diesem Beitrag adressiert: RQ1 Wie kann man mehrere Modellvarianten in einem BPMN 2.0 Modell modellieren? RQ2 Wie kann aus einem BPMN 2.0 Modell, welches mehrere Varianten enthält, wieder einzelne Varianten generieren? RQ3 Wie kann eine Softwareunterstützung für BPMN Prozessvarianten effizient und benutzerfreundlich gestaltet werden? Zur Beantwortung der Forschungsfragen wird zunächst die verwendete Forschungsmethode dargelegt. Im Anschluss daran werden bestehende Ansätze zur Modellierung von Prozessvari- anten vorgestellt. Anschließend wird eine Erweiterung der BPMN 2.0 um Konfigurationsterme vorgestellt. Im nächsten Schritt wird auf die Konzeption und Implementierung des Soft- warewerkzeuges eingegangen. Abschließend wird das entwickelte Softwarewerkzeug evalu- iert. 2 Forschungsmethodik Im Forschungsbereich der Informationssysteme haben sich nach HEVNER et al. zwei komple- mentäre Forschungsparadigmen etabliert [HC10], [He04]. Unterschieden wird zwischen der be- havioristischen und der konstruktionsorientierten Forschung. Erstere stützt sich auf die Bildung und Überprüfung von Theorien über Artefakte. Darunter fallen auch die Suche und das empi- rische Absichern von Hypothesen. Ziel des Paradigmas ist die Prüfung der Korrektheit anhand der empirischen Eignung von Theorien. Die konstruktionsorientierte Forschung (Design-Science) hingegen, orientiert sich am ingenieurwissenschaftlichen Vorgehen und fokussiert die Kons- truktion und Bewertung von entwickelten Artefakten. Letztere können Implementierungen, Methoden, Modelle und Sprachen sein. Die Konzeption und Implementierung des Softwarewerkzeuges als Prototyp stellt dabei ein Artefakt als Ergebnis des Design-Science Prozesses dar. Zudem ist der Bau von Prototypen eine etablierte Forschungsmethode zur Evaluation und Analyse entwickelter Konzepte und dient als Wissenstransfer in der Wirtschaftsinformatik [HHR11], [Bu92], [Pe07], [Se14]. In der Motivation des Beitrags wird die Problemrelevanz verdeutlicht. Forschungsbeitrag, Stringenz und Forschung als Suchprozess werden im nachfolgenden Abschnitt adressiert, da der Beitrag auf einen klar definierten Stand der Forschung aufbaut und diesen erweitert. Mit der Veröffentlichung des Beitrags wird die Forderung nach einer Kommunikation der Forschungser- gebnisse erfüllt. 2.1 Stand der Forschung Generell ist das Ziel des Variantenmanagements mehrere Varianten derselben Domäne in einem Modell zusammenzuführen. Dieses kann durch Hinzufügen oder Entfernen von Teilmo- dellen angepasst werden. Die bestehenden Ansätze betrachten dabei konfigurierbare Knoten, Annotationen am Element, Spezialisierung durch verschiedene Aktivitäten und angepasste Modellfragmente. Den größten Umfang in der Forschung umfasst dabei die Annotation am Element [De06], [GvJ07], [BDK04], [Be03]. Alle vorgestellten Lösungen sind nur praktikabel, wenn man sie sinnvoll durch Softwarewerkzeuge unterstützt. Dass eine Softwareunterstützung Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018 18
für die Modellerstellung notwendig ist wurde bereits erkannt [Th06], [Ab05]. Diese ist jedoch
in besonderem Umfang für das Management von Prozessvarianten notwendig, da komplexe
Informationsmodelle nicht mehr manuell verwaltet werden können.
Zur Annotation der Konfigurationsterme an den Elementen des Informationsmodells (RQ1)
soll konkret das Konfigurationsverfahren „Elementselektion nach Termen“ verwendet werden
[Be03]. Problematisch ist bei diesem Verfahren nicht die Konfiguration der Modelle selbst,
sondern vielmehr die konsistente und effiziente Konstruktion der Informationsmodelle. Nach
der Ausführung einer Elementselektion, erhält man eine Modellprojektion, die nur Elemente
beinhaltet, deren Terme zu true terminieren [De06]. In der Theorie funktioniert dieser Ansatz
sehr gut, allerdings hat er sich aufgrund der Komplexität in der Praxis bisher nicht durchgesetzt
und wurde so noch nicht implementiert. Das liegt daran, dass mit Meta-Metamodellen gearbei-
tet wird und auf komplexe Mechanismen zur Konsistenzwiederherstellung zwischen Meta-Me-
tamodell, Metamodell und Modell gesetzt wird. Einen ähnlichen aber vereinfachten, nicht auf
Meta-Modellprojektion basierenden Ansatz zur Kennzeichnung von Modellvarianten bildet
die Auswertung der Informationsmodelle mithilfe von Konfigurationstermen [Se17]. Da dieser
Ansatz einer Implementierung einfacher zugänglich ist, wird er bei der Auswertung der Konfi-
gurationsterme im Softwarewerkzeug angewandt (RQ2). Um Konfigurationsterme in Informati-
onsmodellen mit BPMN 2.0 nutzen zu können muss allerdings zuerst die Modellierungssprache
erweitert werden, da diese bisher nicht vorgesehen sind.
2.2 Erweiterung der BPMN
Da ein nicht unerheblicher Teil der Modellierung von Prozessvarianten in einem gemeinsamen
Informationsmodell bei der „Elementselektion nach Termen“ das Annotieren der Konfigurati-
onsterme umfasst, lohnt sich ein Blick auf die Realisierung der Annotation. Um die BPMN 2.0,
um Konfigurationsterme zu erweitern, kann nach SEEL [Se17] dabei die Text Annotation
aus der BPMN 2.0 Spezifikation verwendet und das zugehörige Attribut textFormat, um
den Mime-Type text/confterm erweitert werden.
[BuergschaftNoetig]=true
Code Listing: XML Repräsentation der BPMN 2.0 Textannotation
Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018
19Abbildung 2 Informationsmodell mit den vier eingefärbten Varianten aus Abbildung 1, jedoch ohne Redundanzen. Die Text Annotation ist universell einsetzbar und kann mithilfe ihrer Attribute wiederverwendet werden, weswegen keine BPMN-Extension eingeführt werden muss. Nachfolgender XML-Aus- schnitt zeigt die textuelle Repräsentation einer Textannotation. Über die Beziehung zwischen der Textannotation als targetRef und dem zu annotierenden BPMN Element als sourceRef kann eine eindeutige Zuordnung des Konfigurationsterms an das Element sichergestellt werden. Durch die Unterscheidung der verschiedenen Prozessvarianten über ihre Konfigurationsterme ist es nun möglich diese in einem gemeinsamen Informationsmodell zu pflegen (RQ1). Darüber hinaus ermöglicht der Ansatz zur „Elementselektion nach Termen“ von BECKER et al. das Erzeugen einzelner Prozessvarianten aus dem Informationsmodell zur Laufzeit (RQ2). Dieser Punkt wird während der Konzeption und Entwicklung nochmals aufgegriffen. Die verschiedenen Prozessvarianten aus Abbildung 1 wurden in Abbildung 2 in ein gemeinsa- mes Modell überführt. Dies wurde durch die Verwendung von Konfigurationstermen möglich, die in Abbildung 2 an den farbigen Elementen annotiert wurden. Die Variante a aus der ersten Abbildung findet sich in Abbildung 2 in der Farbe Blau wieder. Variante b ist in Rot dargestellt. Die dritte Variante c findet sich in grüner Farbe, während die Variante d in einem hellen Blau- ton dargestellt ist. Identisch geblieben sind die schwarzen variantenunabhängigen Elemente. Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018 20
2.3 Konzeption und Implementierung der Softwarewerkzeuges
Bevor auf die entwickelte Funktionalität eingegangen wird, werden Anforderungen an das
Softwarewerkzeug in Form von User-Stories [CH10] definiert. Diese nehmen Bezug auf effizi-
entes annotieren sowie eine benutzerfreundliche Bedienung (RQ3), um die Modellierung eines
Informationsmodells mit mehreren Prozessvarianten für Modellersteller und Modellnutzer zu
vereinfachen.
US1 Als Modellersteller möchte ich mehrere Elemente im Informationsmodell
gleichzeitig annotieren können, um den Arbeitsaufwand zu verringern und
Zeit zu sparen.
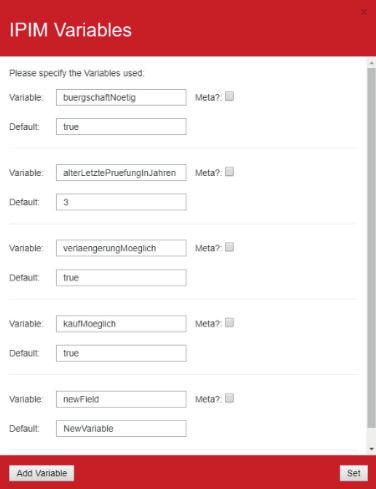
US2 Als Modellersteller möchte ich eine zentrale Übersicht über alle im Modell
verwendeten Variablen haben, damit die Einarbeitungsdauer bei einer nach
träglichen Anpassung des Informationsmodells verringert wird.
US3 Als Modellersteller möchte ich die Terme am Element so kurz wie möglich
definieren können, da diese schnell komplexe Strukturen aufweisen und
unübersichtlich werden können.
US4 Als Modellersteller/Modellnutzer möchte ich eine grafische Darstellung zur
besseren Unterscheidung der einzelnen Varianten im Informationsmodell, um
diese besser voneinander unterscheiden zu können.
US5 Als Modellersteller möchte ich schnell alle Elemente mit derselben Annotati
on finden, um die Korrektheit des Informationsmodells manuell verifizieren
zu können
US6 Als Modellnutzer möchte ich während der Laufzeit (Run-Time) eines Informa
tionsmodells eigene Variablenwerte eingeben können und als Resultat ein
maßgeschneidertes Informationsmodell erhalten.
Nachdem die Anforderungen an das zu entwickelnde Softwarewerkzeug definiert sind, werden
diese als Grundlage für die Implementierung verwendet. Die Entwicklung eines Softwarewerk-
zeugs ist meist sehr aufwandsintensiv und eine Neuimplementierung der Standardmodellie-
rungsfunktionalität für BPMN 2.0 birgt wissenschaftlich keine neuen Erkenntnisse. Deshalb
ist eine Wiederverwendung bereits vorhandener Lösungen wünschenswert [Vo15]. Jedoch ist
dabei der Zugriff auf den Quellcode notwendig, weswegen sich diejenigen, die auf Open-Sour-
ce-Lizenzen basieren für die Entwicklung am besten eignen. Eine Untersuchung von verschie-
denen Open-Source-Modellierungsanwendungen wurde von SEEL et al. durchgeführt [Se16].
Das im Folgenden vorgestellte Softwarewerkzeug baut dabei auf das Open-Source-Modellie-
rungswerkzeug Camunda Modeler3 auf. Ein Grund der für dessen Verwendung spricht ist die
leichte Änderbarkeit des Quellcodes, da dieser in der Programmiersprache JavaScript vorliegt
und dadurch auf allen Betriebssystemen einsetzbar ist. Mihilfe des Softwarewerkzeuges soll
dabei die Konstruktion (Build-Time) des Informationsmodells inklusive seiner Varianten (RQ1)
sowie die Generierung einzelner Prozessvarianten aus ihm (Run-Time) unterstützen (RQ2).
Das vorgestellte Softwarewerkzeug basiert auf dem Open-Source-Modellierungswerkzeug
Camunda Modeler. Dieses wurde um zusätzliche Funktionalität erweitert, auf die im Folgen-
den eingegangen wird. Zur Realisierung der ersten User-Story US1 wurde dazu eine einfache
Oberfläche bereitgestellt, die die Eingabe von Konfigurationstermen erlaubt und diesen Term
für alle selektierten Elemente übernimmt. Dazu wurde ein Modal Element implementiert, das
bei der Bestätigung der Eingabe, die selektierten Elemente aus dem Camunda Modeler in eine
separate Liste überträgt und diese sequentiell abarbeitet. Gespeichert werden die annotierten
Terme mit direktem Bezug zu den ausgewählten Elementen.
3 https://github.com/camunda/camunda-modeler zuletzt abgerufen am 25.09.2017
Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018
21In US2 sollen dem Modellersteller und dem Modellnutzer gleichermaßen eine Übersicht über alle im Informationsmodell verwendeten Variablen gegeben werden. Dazu wurde ein weiteres Modal Element (vgl. Abbildung 3a) definiert, das diese Informationen anzeigt. Dabei werden die Informationen des Modells aus dem Camunda Modeler exportiert und auf das Schlüsselwort IPIM _ Val überprüft. Für jede gefundene Variable wird Eintrag in der grafischen Oberflä- che erzeugt und dessen Standardbelegung angezeigt. Aufgrund der schnell wachsenden Länge der Konfigurationsterme ist eine Komplexitätsre- duzierung sinnvoll. Eine solche kann durch die Einführung von sogenannten Meta-Termen erreicht werden. Dabei werden einzelne Terme in einer eigenen Variable gekapselt, die global im Informationsmodell zur Verfügung steht. Zusätzlich wird ein solcher Term, mit einer Variab- lenbelegung, als Meta-Term gekennzeichnet. Mithilfe von Meta-Termen kann eine Strukturie- rung der Konfigurationsterme erreicht werden, da einzelne logische Blöcke gekapselt werden können. Die Konfigurationsterme am Element werden dadurch kürzer und übersichtlicher, was die Erfüllung der US3 darstellt. US4 stellt die Anforderung an den Prototyp zur grafischen Hervorhebung verschiedener Mo- dellvarianten im Informationsmodell dar. Dafür wird eine Liste zur Verfügung stehender Farben bereitgestellt wie sie von STARK et al. [SEB17] empfohlen wird, die für den Anwender leicht zu unterscheiden sind. Diese Farben werden dann nacheinander den Varianten zugeordnet. Eine Modellvariante zeichnet sich dadurch aus, dass sie bei gegebenen Variablenbelegungen zu demselben booleschen Ausdruck terminieren. Einerseits kann die grafische Darstellung für den Modellersteller genutzt werden, um sicherzustellen, dass das Modell richtig annotiert wurde. Andererseits birgt die grafische Hervorhebung von Modellvarianten auch eine Verbesserung für den Modellnutzern, da er bei der Ausführung des Modells diese besser unterscheiden kann. Dadurch ist auch US5 erfüllt, da alle gleichfarbigen Elemente denselben Konfigurationsterm besitzen. Die letzte User-Story US6 befasst sich mit der Generierung einer konkreten Variante aus einem Informationsmodell (vgl. Abbildung 3b). Als Resultat soll dabei nur der Teilbereich des Infor- mationsmodells zurückgegeben werden, der für die eingegebene Variablenbelegung gültig ist. Nach dem Konfigurationsverfahren „Elementselektion nach Termen“ von BECKER et al. [Be03] verbleiben nur Elemente im Informationsmodell deren Konfigurationsterm zum booleschen Ausdruck true terminieren. Dazu werden die Konfigurationsterme als String in die Java- Script-Funktion eval übertragen. Diese wiederrum interpretiert den übergebenen String als JavaScript Code und gibt den ermittelten Ausdruck – bei Konfigurationstermen ein boolescher Ausdruck – als String zurück. In der Dokumentation4 wird ausdrücklich vor unsachgemäßer Verwendung der Funktion gewarnt, weshalb weiterer Forschungsbedarf zur Interpretation von Konfigurationstermen besteht. 2.4 Evaluation Das Ziel des Design-Science-Prozesses besteht in der Erstellung von Artefakten, die ein pra- xisrelevantes Problem lösen [HC10]. Eine der Kernaktivitäten des Design-Science-Prozesses, stellt die Evaluation des geschaffenen Artefakts dar, um seine Nützlichkeit zu beweisen und zu rechtfertigen [Pe07]. Als Evaluationsgrundlage dient das in SEEL [Se17] vorgestellte Infor- mationsmodell eines Leasingprozesses, welches in BPMN 2.0 (Abbildung 1) modelliert wurde. Dieses wird mit Konfigurationstermen erweitert, um eine „Elementselektion nach Termen“ zu gewährleisten. In Abbildung 2 wurde das kombinierte Informationsmodell inklusive aller 4 https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/eval zuletzt abgerufen am 25.09.2017 Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018 22
im Ausgangsmodell existierenden Varianten (Abbildung 1) ohne Redundanzen dargestellt.
Durch die Kombination in einem gemeinsamen Informationsmodell wird die Verwaltung und
Pflege vereinfacht und Inkonsistenzen werden vermieden. Zur Evaluation des vorgestellten
Softwarewerkzeuges wird dieses mit dem existierenden Open-Source-Modellierungswerkzeug
Camunda Modeler verglichen. Dabei wird auf die User-Stories aus dem Kapitel der Konzeption
Bezug genommen. Bei der reinen Erstellung Modellelemente und deren Verlinkungen sind die
beiden Anwendungen identisch. Vorteile hat das entwickelte Softwarewerkzeug erst ab dem
Zeitpunkt der Annotation der Konfigurationsterme. Das Standardtool lässt zwar eine Mehrfach-
selektion der Elemente zu (US1), die Änderung der Eigenschaften wird jedoch nur für das erste
selektierte Element übernommen. Im erweiterten Softwarewerkzeug hingegen werden die
Konfigurationsterme über alle selektierten Elemente hinweg gespeichert, was die Benutzer-
freundlichkeit des Softwarewerkzeugs erhöht (RQ2). Je nachdem ob man die Konfigurations-
terme von Element zu Element kopiert oder vollständig neu eingibt, entsteht hier eine nicht
unerhebliche Zeitersparnis. Bei größeren Informationsmodellen nimmt diese Ersparnis weiter
zu, was zu einer höheren Effizienz der Modellerstellung (RQ1) führt. Eingabefehler, die durch
ein manuelles Übertragen hervorgerufen werden, können damit ebenso unterbunden werden.
Abbildung 3a Zentrale Übersicht aller Variablen Abbildung 3b generierte Prozessvariante aus dem Modell
und Meta-Terme des Informationsmodells
Eine Funktion zur Auswertung der verschiedenen Varianten des Modells existiert im Camunda
Modeler nicht und wurde im Softwarewerkzeug hinzugefügt. Diese erlaubt dem Modellersteller
bereits zur Design-Time, die inhaltliche Korrektheit des Modells sicherzustellen, indem ver-
schiedene Modellvarianten farblich hervorgehoben werden (US4). Aus dem Camunda Modeler
werden dazu alle Elemente des Modells abgefragt und durch Vergleich der Konfigurationsterme
den zur Verfügung stehenden Farben zugeordnet. Eine Validierung des Modells kann im Ca-
munda Modeler nur manuell durchgeführt werden und ist deshalb aufwendig und fehleranfäl-
lig. Dadurch ist die Effizienz im Vergleich zum erweiterten Softwarewerkzeug niedriger (RQ1).
Insgesamt besteht das Informationsmodell aus vier verschiedenen Varianten (vgl. Abbildung 1),
weswegen vier verschiedene Konfigurationsterme vorhanden sind. Elemente mit der gleichen
Farbe besitzen identische Konfigurationsterme (US5).
Um im Camunda Modeler eine Übersicht aller Variablen zu erhalten, besteht die Möglichkeit auf
eine leere Fläche des Modells zu klicken. Die Variablen und deren Standardbelegung erschei-
Wissenstransfer in der Wirtschaftsinformatik - Fachgespräch im Rahmen der MKWI 2018
23Sie können auch lesen

















































