Texte als Bausteine der Umweltforschung
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

Siedlungsforschung. Archäologie – Geschichte – Geographie 39, 2022, S. 541–565
Texte als Bausteine der
Umweltforschung
Von der analogen Analyse über Datenbanken
und virtuelle Forschungsumgebungen zum
Crowdsourcing und Maschinellen Lernen
Rüdiger Glaser, Michael Kahle, Franck Borel, Rafael Hologa, Oliver Rau und
Antje Kellersohn
1 Texte und Textinterpretation als Bausteine der
Klima- und Umweltforschung
Texte sind wesentliche Bausteine wissenschaftlicher Erkenntnisse und Kommunikation.
Ihre Erschließung erfordert spezifische Praktiken und Zugänge (Reuber 2020, Pfaffenbach
2020, Dzudzek, Glasze u. Matissek 2020). Die in der historischen Umweltforschung ver
wendeten Quellen stellen eine Sonderform dar, da nicht immer alle für die moderne Text
analyse notwendigen Informationen greifbar sind. So fehlen in historischen Kontexten
bisweilen Hinweise auf die Verfasser. Häufig sind auch der Kontext der Abfassung oder
die Intention nicht überliefert. Zwischen der Abfassung und dem öffentlichen Zugang
liegt bisweilen ein zeitlicher Versatz. Zudem müssen Datierungsfragen geklärt werden, da
Kalenderreformen durchgeführt wurden und die historisch übliche Zuweisung auf den
nächsten Heiligentag zu entsprechenden Zeitsprüngen führten. Handschriftliche Über
lieferungen stellen besondere Herausforderungen an die Transkription, ebenso der Bedeu
tungswandel von Begriffen und die unterschiedlichen Schreibweisen. Ähnlich anspruchs
voll ist oft auch die örtliche Zuordnung. Für die Erschießung und Auswertung historischer
Quellen wurden daher eigene Standards entwickelt.
541
Rüdiger Glaser, Michael Kahle, Franck Borel, Rafael Hologa, Oliver Rau und Antje Kellersohn
2 Analoge Analyse der Auswertung
historischer Textquellen
Grundsätzlich folgt die Analyse von Textquellen in der Historischen Klimatologie den
Grundprinzipien der Hermeneutik. Ein besonderes Augenmerk ruht dabei auf der Quel
lenkritik. Ziel ist das Verständnis von Texten in ihrem historischen Entstehungskontext.
Von wem wurde die Quelle und mit welcher Intention wurde der Text erstellt? Zentrale
Frage dabei ist, welcher Deutungskontext sich aus dem Zeitgeist ergibt. Mit welcher In
tention wurde die Quelle geschaffen, welche Umwelt- und vor allem Klimawahrnehmung
herrschte zur Zeit der Abfassung und welche zeitspezifischen Erkenntnisformen standen
überhaupt zur Verfügung (Glaser 2013). Ziel der Hermeneutik ist es nach Mayring (2015),
eine „Kunstlehre“ des Auslegens bzw. Interpretierens von Texten und der Realität zu ent
wickeln. Im hermeneutischen Zirkel werden verschiedene Zugänge und Interpretations
perspektiven eingenommen, indem der gleiche Text immer wieder aus dem jeweils aktuell
herrschenden Kontext mit dem entsprechenden Vorverständnis neu interpretiert wird.
Die Diskrepanz zwischen der Abfassung und dem jeweiligen Erkenntnishorizont nennt
man hermeneutische Differenz. Der Übergang zur darauffolgenden Interpretation ist flie
ßend (Winiwarter u. Knoll 2007).
In vielen Ansätzen wird über die qualitative Analyse hinaus mittels einer systematischen
Textanalyse eine Quantifizierung angestrebt (Mayring 2015). Unter der systematischen Text
analyse wird die Analyse der Semiotik als Lehre des allgemeinen Bedeutungsaustausches
kommunizierender Individuen verstanden, ebenso die der Syntaktik, der Semantik und der
Pragmatik als Relation zwischen Zeichen und den diese benutzenden Individuen sowie die
Sigmatik der Quellen. Insgesamt soll über die verschiedenen Schritte der Explizierenden
und der zusammenschauenden Kontextanalyse eine Objektivierung erreicht werden.
Besonders aufschlussreich sind historische Quellen, in denen über einen längeren Zeit
raum bzw. über mehrere Generationen hinweg kontinuierlich das Umweltgeschehen für
eine bestimmte Region dokumentiert ist. Da in solchen Chroniken oftmals dieselben
Aspekte Gegenstand der Dokumentation sind, sind sie prädestiniert, um längere Zeitrei
hen zu spezifischen Umweltparametern abzuleiten. Auf diese Weise kann das Umweltge
schehen nicht nur im quellenkritischen Kontext, sondern auch komparativ im Laufe der
Zeit oder im Verhältnis zu anderen Regionen gesetzt werden. So liefert beispielsweise die
Hauschronik der Wiesenbronner Familie Hüßner mit ihren Aufzeichnungen vielfältige
Hinweise zu Klima, Anbaufrüchten, Phänologie, Wirtschaft und Geschichte in Mainfran
ken in den Jahren 1750–1894. Darin heißt es beispielsweise für das Jahr 1762:
„Anno 1762 war ein rechts hartes jahr, maßen der weinstock zu anfang deß Meyen halb
erfroren und gegen zu ende deß Meyen folgent den garauß gemacht, daß dabey auch
war eine solche trockene dürr dabey, daß es 2 monath nichts regnen that, dan hero der
542
Texte als Bausteine der Umweltforschung
edle same auch nicht fort wacksen kont, und eine schlechte ernde; daß korn galt im
Juny schon 12 fl. und 30 kr. frk., biß gegen den Herpst 11 thl. frk., der eymer most, weil
eß wenig geben, ist er noch gut worden, gult 3 thl. und der habern galt 4 fl. 16 kr. frk.“
Der Text wurde aus dem Manuskript transkribiert und mit dem Anfang der 1990er Jahre
weit verbreiteten Textverarbeitungsprogramm WORD5 in eine erste digitale Form über
führt und schließlich publiziert (Glaser, Schenk u. Schröder 1991). Die inhaltlichen Aus
sagen beziehen sich sehr typisch für eine mit der Landwirtschaft betraute Familie am Rand
des Steigerwalds Mitte des 18. Jahrhunderts auf den Witterungsgang, die entsprechenden
Auswirkungen auf die Landwirtschaft und die Preise: Offensichtlich war der Jahresbe
ginn 1762 kalt. Weitere Kennzeichen sind die zwei Frostereignisse im Mai, die den Reben
folgenschwer zusetzten. Zudem wird eine zweimonatige Dürreperiode angeführt, in der
es keinen Niederschlag gab, was sich wiederum schlecht auf die Entwicklung der Anbau
produkte auswirkte und eine schlechte Ernte zur Folge hatte. Verschiedene Preisangaben
zu Getreide und Wein, der gering, aber gut ausfiel, runden das Bild ab.
Derartige Hinweise wurden oft in mehrjähriger Recherchearbeit in umfassenden Daten
sammlungen zusammengeführt und publiziert. Bekannt ist beispielsweise die Sammlung
Weikinn (1958–1963), die von Börngen u. Tetzlaff (2000) abgeschlossen wurde. Derartige
Sammlungen haben eine lange Tradition, wie etwa die zu den Hochwasserereignissen an
der Elbe von Pötzsch (1784) zeigt. Kritikpunkte an diesen Sammlungen sind der oft unkri
tische kompilative Charakter sowie die Verwendung von nicht überprüften Sekundärquel
len. Trotz dieser berechtigten Kritik bieten sie wichtige Ansatzpunkte für weiterreichende
wissenschaftliche Forschung (Muddelsee et al. 2002).
Die Erschließung historischer Quellen erforderte in der analogen Zeit oftmals zeitauf
wendige akribische Archivrecherchen. Findbehelfe, wie Repertorien, hatten in dem bis
dato geltenden Verständnis von „historisch“ oftmals keine eigenen Rubriken für Umwelt
oder Wetter, Witterung und Klima. Erst mit dem ökologischen Turn der 1970er Jahre setz
te sich schließlich ein entsprechendes Verständnis und mit einem zeitlichen Versatz auch
eine Integration in einschlägigen Findhilfen durch.
3 Datenbanken, neue Formate und Zugänge
im Rahmen der Digitalisierung
Die rasant voranschreitende Digitalisierung seit den 1990er Jahren mit der Verbreitung
des Internets eröffnete neue Recherche-, Erfassungs- und Auswertungsmöglichkeiten: Wo
früher mühsame, zeitaufwändige und kostenintensive Archivrecherche notwendig war
oder langwierige Fernleihen bemüht werden mussten, können heute zunehmend digitale
Quellenbestände und Informationen über das Internet erschlossen werden. Zusätzlich er
543
Rüdiger Glaser, Michael Kahle, Franck Borel, Rafael Hologa, Oliver Rau und Antje Kellersohn
leichtern komfortable Suchfunktionen das Erschließen von Textquellen, wodurch relevan
te Textbausteine systematisch mittels a priori festgelegter Kodierschemata oder alternativ
über thesaurierende Suchverfahren gesammelt und kodiert werden können.
Aktuelle Beispiele für neue Zugangsoptionen liefern die digitalisierten Bestände der
Monumenta Germaniae Historica MGH (www.dmgh.de), oder die der Freiburger Zeitung
(https://www.ub.uni-freiburg.de/recherche/digitale-bibliothek/freiburger-historische-
bestaende/freiburger-zeitung). Auch einschlägige Werke aus den digitalisierten Beständen
von Google Books oder von Archive.org bieten leicht zugängliche Informationen. Mitt
lerweile sind auch umfassende Bildergalerien von Hochwassermarken und viele andere
Digitalisate online verfügbar.
Für fachlich einschlägige Analysen stehen mittlerweile eine Reihe von beeindruckenden
Datenbanken online zur Verfügung. Zu diesen zählen u. a. Pediflood (Barriendos et al.
2014), ORRION (Martin et al. 2016), ICOADS (Woodruff et al. 2011), CLIWOC (García-
Herrera et al. 2005), euroclimhist.ch (Pfister 2015) oder REACHES (Wang et al. 2018).
Dazu kommen fachlich spezifizierte Datenbanken, beispielsweise zu Dürren wie EDII
(Stahl et al. 2016), oder von marinen sowie frühen instrumentellen Daten (Kaspar et al.
2015, Cram et al. 2015). Weitere Zugänge finden sich unter https://www.ncdc.noaa.gov/
data-access/paleoclimatology-data/datasets/historical. In den national geförderten Digi
talisierungsprojekten DADIGI und HISTOR des DWD wurden entsprechende Sammlun
gen aus deutschen Archivbeständen integriert (Kaspar et al. 2015).
Im Rahmen dieser Bemühungen kommen zunehmend auch Fragen der Datenstandar
disierung auf. So werden bei PAGES verschiedene Paläodaten in einem gemeinsamen
Datenformat (LiPD) nach den FAIR (Findable-Accessible-Interoperable and Reusable)
Prinzipien zusammengeführt. Damit eröffnen sich neue Möglichkeiten der Big Data
Analyse sowie der Reanalyse (McKay u. Emile-Geay 2016, Wilhelm et al. 2018, Khider et
al. 2019).
3.1 HISKLID – Kodierung, Indizierung und Cross Validierung
historischer Quellentexte
Die recherchierten Quellentexte für den mitteleuropäischen Raum wurden zunächst in
HISKLID digital erfasst. Zeit bzw. Zeiträume, Ort, Quelle und Inhalt wurden dazu ko
diert bzw. indiziert. Ein Teil der HISKLID Daten sowie das Kodierschema sind publiziert
(Glaser u. Militzer 1993, Glaser 1996). In Tab. 1 ist die Kodierung des obigen Textzitates
nach dem HISKLID Format abgebildet. Die Texte wurden dabei in einen numerischen,
„maschinenlesbaren“ Code überführt. Wesentlicher Bestandteil dieses Arbeitsschrittes ist
die Indizierung der klimatischen Angaben (Glaser 1996).
544
Texte als Bausteine der Umweltforschung
Tab. 1: Kodierung des Textzitates von 1762 in HISKLID.
1762 05 41 18711–55 40 01
1762 05 40 18711–55 -2
1762 06 18711–55 02 01
1762 18711–55 0124 01
1762 18711–55 0132 01
1762 18711–55 04 01
1762 16 18711–55 02 01
Die Cross-Validierung des oben wiedergegebenen Textauszuges mit den numerischen
Angaben der Baur’schen Temperaturreihe für Mitteleuropa bestätigt die inhaltlichen Ge
wichtungen und Beschreibungen. War der Januar gegenüber der Klimanormalperiode
1961–1990 um nicht ganz 1°C zu mild, blieb der Februar rund 1°C unter den langjährigen
Vergleichswerten, der März sogar 3,3°C, was die Bezeichnung eines „harten Jahres“ ver
ständlich macht. Da der April 2,2°C zu warm ausfiel und auch der Mai 0,8°C über den Ver
gleichswerten lag, erscheint auch der Hinweis auf die Trockenheit und das Fehlen von Re
gen plausibel. Die Werte von März und April überstiegen auch die Grenzen der einfachen
Standardabweichung, was sie als auffällig bzw. extrem einordnen lässt. Zudem handelt es
sich um, wie ebenfalls erwähnt, – agrarökologisch wichtige Monate.
Die Cross-Validierung mit den instrumentellen Daten ermöglicht eine Bewertung der
Quelle und zeigt, wie plausibel die schriftlichen Hinweise sind. Wenn derartige Instru
mentendaten nicht vorliegen, kann eine Plausibilitätsprüfung auch über die zusammen
schauende Interpretation mit anderen Quellen erfolgen. Benachbarte Regionen sind
aufgrund der Synopsis, d. h. des Gesamtbildes von Wettersituationen und Witterungs
abläufen nicht unabhängig voneinander, sondern kausal miteinander verknüpft. Im Fall
der Hüßner-Hauschronik bestätigen Quellen aus Stuttgart und dem Raum Bodensee so
wie Mainfranken den Witterungsgang, insbesondere die Kälte im Februar und März, die
Frostereignisse im Mai sowie die Hitze und Dürre im Sommer. Auch die gute Weinqualität
dieses Jahrganges findet mehrfach Erwähnung. Damit werden die Inhalte der Wiesen
bronner Hauschronik gleich mehrfach bestätigt.
Das HISKLID Format wurde schließlich in tambora.org übernommen und weiterentwi
ckelt. Dies bezieht sich zum einen auf die Erweiterung des hierarchischen Kodierschemas,
zum anderen auf die Bezugnahme auf eine Ortsdatenbank, die nunmehr mit Geokoordi
naten hinterlegt ist. Die Quellen wurden in gängigen Formaten abgelegt und damit weiter
standardisiert.
545
Rüdiger Glaser, Michael Kahle, Franck Borel, Rafael Hologa, Oliver Rau und Antje Kellersohn
4 tambora.org – kollaborative Forschungsumgebung als
neue IT-basierte Form der Wissenskommunikation und
Partizipation in der Historischen Klimatologie
Durch die rasante Entwicklung der letzten Jahre ergeben sich nicht nur effektive Möglich
keiten der Datenvorhaltung, sie eröffnen auch grundlegend neue Perspektiven einer weit
reichenden Wertschöpfung und Kollaboration. Kollaborative Forschungsumgebungen,
die oft auch virtuelle Forschungsumgebung (VFU), E-Portale, oder Englisch „Collabora
tive Research Environment“ (CREs) genannt werden, stellen neue Formen partizipativer
Datenablage und Nutzung dar. Sie wurden seit den 2000er Jahren entwickelt, um großen,
ortsübergreifenden Arbeitsgruppen eine geeignete Plattform zu bieten, um Daten, Metho
den und Erkenntnisse zu kommunizieren, zu teilen und zu verbreiten. Dabei wurden sie
stets nicht nur als technisches Vehikel, sondern auch als sozial integrierendes Instrument
angesehen (Kahle, Glaser u. Hologa 2020, Carusi u. Reimers 2010). Durch die Öffnung
nach außen beinhalten sie auch eine gesellschaftspolitische Komponente, insbesondere
durch die Adressierung weiterer Stakeholder oder die Einbeziehung von Bürgerwissen
schaften (Candela et al. 2013).
Auf tambora.org ist der komplette Workflow der Historischen Klimatologie stringent
umgesetzt, ergänzt um ein Rechte- und Verwaltungssystem sowie Publikationsmöglich
keiten (Riemann et al. 2015).
Abb. 1: Ablaufschema in der Historischen Klimatologie in tambora.org.
546
Texte als Bausteine der Umweltforschung
In einer langjährigen Kooperation mit dem Institut für Länderkunde (IfL) in Leipzig
wurden in zwei DFGfinanzierten Förderphasen auch die 66.000 Einträge umfassenden
Datenbestände von Weikinn in tambora.org überführt (Weikinn 1958; Börngen u. Tetzlaff
2000). Im Laufe der Vorhaben kamen weitere Datenbestände, u. a. aus dem ANFDFG
geförderten Vorhaben Transrisk hinzu (Himmelsbach et al. 2015). Gespiegelt werden diese
Datensätze im Datenbankprojekt ORRION des französischen Projektpartners. Das Geo
graphische Institut der Universität Augsburg beteiligte sich mit dem IBT Datenbestand
(Inundationes Bavariae Thesaurus), in dem Hochwasserereignisse aus dem Alpenvorland
enthalten sind (Böhm 2013; Böhm et al. 2014).
Die Universitätsbibliothek Freiburg, die ganz wesentlich zur Entwicklung und technischen
Realisierung beitrug, verpflichtete sich zudem, tambora.org zu hosten und damit die Daten
bestände, aber auch die Erkenntnisse und Methoden langfristig zu sichern. Die UB Freiburg
als eine Körperschaft des öffentlichen Rechts garantiert auch rechtliche Standards wie die
freie Zugänglichkeit und einen an guter wissenschaftlicher Praxis orientierten Umgang.
Besonders hervorzuheben ist die Möglichkeit einer arbeitsteiligen Vorgehensweise vor
allem für jene Arbeitsschritte, die ein Expertenwissen erfordern, beispielsweise bei der
Transkription von Handschriften, für die spezifische paläographische Kenntnisse unab
dingbar sind. Ähnlich verhält es sich bei den Kalibrierungsverfahren, die in aller Regel
eine Anwendung statistischer Verfahren voraussetzen. Für die Ableitung von Schätz
werten der Temperatur und des Niederschlages wurden die Indexwerte kalibriert. Dazu
wurden Verfahren wie das VarianzScaling und Regressionsansätze verwendet (Glaser u.
Riemann 2009, Glaser u. Kahle 2020).
Abb. 2: Temperatur- und Niederschlagsentwicklung in Mitteleuropa seit 1500. Im oberen
Teil sind die Temperaturen als die einjährigen (1y), zweijährigen (2y) usw., im unteren
die Niederschlagswerte analog abgebildet. Die schwarze Linie repräsentiert das gefilterte
5-jährige Mittel (Quelle: Glaser et al. 2020).
547
Rüdiger Glaser, Michael Kahle, Franck Borel, Rafael Hologa, Oliver Rau und Antje Kellersohn
Für die Interpretation wiederum ist klimatologisches Fachwissen notwendig. Ein derart
arbeitsteiliges Vorgehen und standardisiertes Werkzeugrepertoire verbessert die Quali
tät von Projekten. Somit trägt es zur methodischen und inhaltlichen Konsolidierung bei,
schafft neue Netzwerke und ermöglicht neue Formen kollaborativer Zusammenarbeit.
Zugleich regt tambora.org die Kooperation über die enge Wissenschaftsgemeinde hinaus
an und ist im Sinne von OpenScience auch für weitere Nutzergruppen erreichbar (Heim
et al. 2018). Diese Facetten unterstreichen die immer wieder vorgetragene Komponente
kollaborativer Plattformen als soziales Konstrukt und des Wissenstransfers. Auch ermög
licht eine derartige Arbeitsweise ein fachlich breit aufgestelltes Peer-Reviewing-Verfahren.
tambora.org bietet durch die Vergabe von DOIs (Digital Object Identifier) eine zufrieden
stellende Lösung für die wichtige und zugleich sensible Frage der Urheberrechte bzw. der
Rechteverwertung und Publikation an. Textsammlungen, Quellenkompilationen, Tran
skriptionen oder sonstige Editionen können zitierfähig publiziert werden (Schönbein et al.
2016; Vogt et al. 2016).
Perspektivisch können über Algorithmen neue Einträge in kausale klimatologische Zu
sammenhänge und in den bisherigen Gesamtkontext gestellt werden, um unplausible Ein
träge zu identifizieren. Nutzer sollen auf diese Weise nicht nur eine zeitnahe Einordnung
zu ihren Einträgen erhalten und damit einen ersten motivierenden Eindruck der eigenen
Beiträge, sondern vor allem auch eine vorläufige Verifikation. Eine derartige Rückkopp
lung und Verifikation kann entsprechend kartographisch visualisiert und unterstützt wer
den (Kahle u. Glaser 2020).
Ein wichtiges Desiderat ist und bleibt die Erschließung und Einbindung neuer Daten
bestände und Nutzungsformen über die Erweiterung des Nutzerkreises, ebenso wie die
Vernetzung mit bestehenden Datenbanken. Vor allem über die Einbeziehung aktueller
Daten und Darstellungsformen wie der Bürgerwissenschaften sind neue Akzente möglich.
4.1 Einbindung tagesaktueller Textquellen
Besonders hervorzuheben ist der inhaltliche Anschluss von historischen Quellen an ta
gesaktuelle Texte und Meldungen, wie sie in Zeitungsartikeln, Berichten und Dokumen
ten enthalten sind. Für diese „aktuelle Klimahermeneutik“ gilt, dass sie die numerischen,
instrumentell generierten Daten durch die Betonung von Folgen, Wahrnehmungen und
Reaktionen, wie sie in den Texten schwerpunktmäßig enthalten sind, strukturell ergänzt.
Gerade auch die Bewertung des aktuellen Klimawandels und seiner Folgen anhand von
verschiedenen Medienformaten ist mittlerweile wissenschaftlich etabliert (Kirilenko u.
Stepchenkova 2012; Schmidt, Ivanova u. Schaefer 2013, Boussalis u. Coan 2016). Rezente,
schriftliche Aufzeichnungen stellen eine wichtige Ergänzung zu instrumentellen Messun
gen dar. Ihre Bewertung und Analyse unterliegt den gleichen Arbeitsschritten. Dies be
548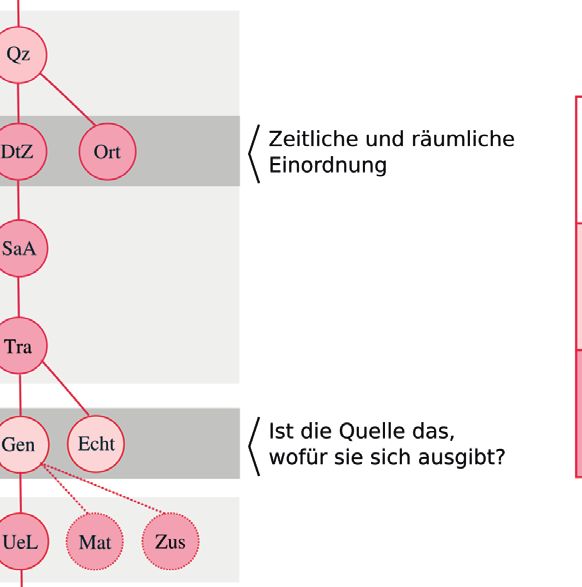
Texte als Bausteine der Umweltforschung
deutet auch, dass sie mit den aus historischen Texten extrahierten Daten direkt in Bezug
gesetzt werden können.
Der nachfolgende Artikel aus der MainPost (Amling 2018) veranschaulicht dies und
lässt aufgrund der regionalen Zuordnung Bezüge zur Hauschronik der Wiesenbronner Fa
milie Hüßner zu. Die MainPost hat 286.000 Leser, die digitale Ausgabe eine Gesamtreich
weite von 793.000.1 Das Verbreitungsgebiet liegt in Mainfranken um die Städte Würzburg
und Schweinfurt.
Abb. 3: Beispiel für die Integration rezenter Zeitungsartikel in
tambora.org aus der Main-Post.
Über geeignete Indexverfahren kann zudem der Zeitraum mit rein textbasierten Informa
tionen und den Abschnitten, die durch instrumentelle Messungen belegt sind, erweitert
werden. Zudem sind derartige, möglichst lange Überlappungen für die Kalibrierung der
Indexwerte sehr wichtig.
Insgesamt lassen sich damit durchgängige Zeitreihen ableiten, die gerade auch für heu
tige Fragestellungen wie Trendverhalten oder Wiederkehrzeiten von ausgewählten Klima
extremen wie Dürren und feuchten Perioden von Bedeutung sind (Glaser u. Kahle 2020,
Ionita et al. 2021). Die gesellschaftlichen Folgen von Dürren wurden von Erfurt et al. (2019
und 2020) dargestellt.
5 Crowdsourcing: Neue Medien und
digitale Beteiligungsformen
Gegenüber der historischen Umweltforschung stehen der aktuellen Analyse des Umweltge
schehens eine Reihe neuer Quellen zur Verfügung, die maßgeblich auf die Entwicklungen
neuer Medienformate und auf die Möglichkeiten vielfältiger digitaler Beteiligungsformate
1
https://www.mainpost.de/storage/med/mediadaten/936832_Online_Faltblatt_MainPost_
Einzelseiten.pdf (Zugriff: 15. April 2021).
549
Rüdiger Glaser, Michael Kahle, Franck Borel, Rafael Hologa, Oliver Rau und Antje Kellersohn
und des Crowdsourcings von relevanten Informationen zurückzuführen sind. Abhängig
vom Beteiligungs- und Medienformat sowie der Datenakquise werden Informationen ge
neriert, aus denen sich vielversprechende Daten für die Umweltforschung ableiten lassen.
Wettermelder auf diversen regionalen Radioprogrammen, imposante Bildsequenzen von
Sturmjägern, Twitter-Meldungen zu Klimakatastrophen, spontane Bottom-up-Initiativen,
die den Katastrophenschutz unterstützen, seien hierfür exemplarisch aufgeführt.
Somit bietet das digitale Zeitalter der Gesellschaft vielfältige Optionen, um den Ablauf,
aber auch Folgen und Maßnahmen zum aktuellen Wetter-, Witterungs- und Klimagesche
hen als Textnachricht, im Bild, oder in Ton- und Filmsequenzen festzuhalten. Neben dem
inhaltlichen Wert ermöglichen solche Informationen auch Einblicke in die gesellschaft
liche Perzeption von Umweltphänomenen.
Im Kontext von Wetter, Witterung und Klima lassen sich einerseits Quellen unterschei
den, deren Informationen sich auf ein konkretes Ereignis beziehen und bei denen Laien
aufgrund eines solchen indirekt Informationen für die Umweltforschung produzieren.
Andererseits entstehen zunehmend neue Beteiligungsformen in der Umweltforschung
durch bürgerwissenschaftliche Projekte. Dann erfolgt die Dokumentation von Umwelt
phänomenen vor dem Hintergrund einer spezifischen Agenda, beispielsweise bei phäno
logischen Beobachtungen.
Bei Informationsquellen, die vor dem Hintergrund eines konkreten Ereignisses entstan
den sind, handelt es sich meist um extreme Wetterereignisse, die Individuen dazu animie
ren, ihre Beobachtungen mittels sozialer Medien mit der allgemeinen Öffentlichkeit zu
teilen. Vor allem bei Unwettern und Klimakatastrophen steigt die Zahl von einschlägigen
Einträgen bzw. Meldungen rapide an. Solche Formen der „Umweltberichterstattung“ sind
in der Regel losgelöst von einer organisierten Beteiligung. Die auf diese Weise generierten
Informationen bzw. der mit Mitteln des Web 2.0 geteilte sog. user-generated content sind
hinsichtlich ihrer inhaltlichen Struktur sehr heterogen und unterscheiden sich abhängig
vom Medienformat. Aufgrund der großen Anzahl von Meldungen bei einem Wetterex
tremereignis ergeben sich vielfältige Möglichkeiten des Crowdsourcings, der statistischen
Auswertung. Insbesondere durch Verfahren des Textminings lassen sich beispielsweise
aus Twitter-Meldungen umfassende Einsichten über die gesellschaftliche Wahrnehmung
von Wetterphänomen und deren Kontextualisierungen ableiten.
Demgegenüber etablieren sich bei Informationen, die aus dem Kontext von bürger
wissenschaftlichen Aktivitäten stammen, oftmals feste, quasi institutionalisierte Beobach
tungs- und Meldestrukturen, die zum Teil auch von öffentlichen Trägern unterstützt wer
den. Im deutschsprachigen Raum haben sich insbesondere Projekte langfristig etablieren
können, die auf indirekte Umweltachtungen abzielen. Exemplarisch seien die Initiativen
„CrowdWater“, „Wettermelden.at“, das „Pollentagebuch“, „SenseBox“ und „Die Apfelblü
tenaktion“ genannt. Bei allen Projekten geht es darum, dass Laien ihre Beobachtungen
möglichst strukturiert melden. Die auf diese Weise überregional zusammengeführten
Daten können oft eine gute Grundlage bilden, um weitere Einblicke in die raum-zeitliche
550Texte als Bausteine der Umweltforschung
Dynamik der beobachteten Phänomene zu ermöglichen. Zugleich stellen sie einen wichti
gen Beitrag zur Dokumentation des Klimawandels im regionalen Kontext dar.
Ebenso tragen bürgerwissenschaftliche Aktivitäten vielversprechend zur Erschließung und
Auswertung historischer Datenbestände bei. Besonders weit gediehen sind die Transkriptio
nen von klimarelevanten Informationen aus unzähligen Schiffstagebüchern, etwa im Projekt
oldweather.org. Diese stehen im Zusammenhang mit dem International Comprehensive Oce
an-Atmosphere Data Set (ICOADS) (Freeman et al. 2016). Hierbei werden die handschrift
lichen und daher nur schwer automatisch auswertbaren Aufzeichnungen von Schiffstagebü
chern von Bürgerwissenschaftlern transkribiert und damit einer weiterführenden Auswertung
zugänglich gemacht. Von den Wetterdetektiven (www.weatherdetective.net.au) konnten, un
terstützt von den öffentlichen Medien, bis Oktober 2015 mehr als 400.000 Einträge von 11.000
Bürgerwissenschaftlern transkribiert werden.
Auch im Rahmen von Forschungsarbeiten zur Historischen Klimatologie auf t ambora.org
wurden die Möglichkeiten bürgerwissenschaftlicher Öffnungen anhand von Transkriptio
nen der Freiburger Zeitung und des Nordischen Mercurius getestet. Potenziale bestehen
u. a. in Historischen Vereinen, denkbar ist die Adressierung von einschlägigen universi
tären Seminaren oder Transkriptionen im Rahmen von Schulprojekten. Somit kann eine
größere Erschließung erzielt werden, bei der die Beteiligten auch zur Kreuzvalidierung
eingebunden werden können. Denn die breite Nutzung von Laien erfordert solche For
men der Rückkopplung und Qualitätssicherung, um den wissenschaftlichen Standard und
die Authentizität zu garantieren.
Neben institutionalisierter Bürgerwissenschaft sind auch weitere Praktiken zu beob
achten, bei denen Laien aus der Bevölkerung aktuelle Wetter-, Witterungs- und Klima
ereignisse dokumentieren und somit potentielles Quellenmaterial für die Umweltfor
schung liefern. So binden verschiedene regionale Sendeprogramme oder Wetterdienste
Laien als Wettermelder ein. Sie verbreiten individuelle instrumentelle Messdaten von
Freiwilligen als aktuelle Wetternews und stärken damit sowohl ihr regionales Profil als
auch die Aktualität ihrer Berichterstattung. Einige Themen sind nicht nur aufgrund ihres
Inhaltes spektakulär, sondern auch beeindruckend umgesetzt, etwa die zeitnahe Meldung
und Bilddokumente von Sturmjägern (storm-chasers.de). Besonders viele und kreative
Beteiligungsformen treten jeweils im Kontext von Klimakatastrophen auf. So finden sich
beispielsweise in einem regionalen Mitmachlexikon zum Katastrophenhochwasser von
2013 in Halle an der Saale zum Teil minutiös aufgelöste Text- und Bilddokumentatio
nen. Auch Bürgerreporter, die umfassende Vor-Ort-Analysen liefern, oder Inhalte auf
spontan eingerichteten Hilfsportalen und entsprechenden Blogs, in denen Hilfesuchende
während eines solchen Extremereignisses Aufrufe schalten können, repräsentieren das
breite Spektrum solcher Informationsquellen. Zur Einschätzung der räumlichen Dimen
sion eines Ereignisses sind gerade auch neue Formen des kollaborativen Webmappings
und der kartographischen Dokumentation von Schäden und Auswirkungen besonders
aufschlussreich.
551Rüdiger Glaser, Michael Kahle, Franck Borel, Rafael Hologa, Oliver Rau und Antje Kellersohn
Alle genannten Informationsquellen stellen neben den klassischen Textquellen ein eige
nes neues Genre aktueller hermeneutischer Vermittlung von Wetter, Witterung und Klima
dar. Aus deren Nutzung ergeben sich weitreichende Möglichkeiten einer inhaltlichen und
methodischen Brücke zwischen historischen und rezenten Daten. Um die Qualität der
Aussagen zu validieren, sind Verfahren zur Parallelisierung und zur komparativen Zu
sammenschau aktueller hermeneutischer Informationen einerseits und zeitgleich erhobe
ner Messdaten andererseits besonders aufschlussreich. Darüber hinaus könnten mit der
Nutzung aktueller hermeneutischer Einträge auch Schlüsse auf historische Informationen
gezogen werden. Im günstigsten Fall könnten damit durchgängige gleichartige Datenty
pen generiert und neue Möglichkeiten der Kalibrierung von Kodierschemata, Indizierung
und Kalibrierung getestet werden.
6 Maschinelles Lernen: Automatisierung
der Textanalyse
Als weiterer Schritt zur Bewältigung und Nutzung der enorm gestiegenen Datenmengen
werden zunehmend Verfahren der Automatisierung und deren Analyse mittels Statistik
und künstlicher Intelligenz angewandt. In diesem Kontext beschäftigen sich die „Digital
Humanities“ mit der Erforschung textbasierter geisteswissenschaftlicher Fragestellungen
mit digitalen Methoden. Eine methodologische Grundlage dieser Ansätze ist die her
meneutische Interpretation (Rabus 2019). Texte, die vor einigen Jahren noch selbst für
Menschen schwer lesbar waren, sind heute mittels automatischer Texterkennung (Optical
Character Recognition – OCR) in Sekundenbruchteilen erschlossen. In vielen Ansätzen
wird über die qualitative Analyse hinaus mittels Wortzerlegung (Tokenizing) eine Quanti
fizierung angestrebt. Um über Wortgrenzen hinweg zu kommen und die grammatikali
schen Zusammenhänge zu erkennen, kommen zunehmend Methoden aus dem Bereich
der Künstlichen Intelligenz und des Maschinellen Lernens zur Anwendung. Gängige Ver
fahren sind u. a. Text Mining (Matuschek 2014), Natural Language Processing (NLP), Re
inforcement Learning und Klassifizierung. Ihre Anwendung auf Zeitungsarchive und -in
formationen im Kontext klimatischer Fragestellungen zeigen u. a. Yzaguirre, Smit u.
Warren (2016) mit der beeindruckenden Analyse von über zwei Millionen Artikeln sowie
Kang u. Park (2018) anhand von koreanischen Zeitungen.
6.1 Automatisierung des quellenkritischen Ablaufschemas
Automatisierte Konzepte sind als Unterstützung bei der Erschließung und der Extrak
tion klimarelevanter Informationen aus schriftlichen Quellen gedacht. Nachfolgend ist
552Texte als Bausteine der Umweltforschung
dargestellt, wie eine Automatisierung des quellenkritischen Ablaufs mit Hilfe von Al
gorithmen, wie z. B. maschinellem Lernen, in der Historischen Klimatologie umgesetzt
werden kann.
Zunächst stellt sich die Frage, welche Arbeitsschritte des quellenkritischen Ablaufs
grundsätzlich automatisiert werden können. Kann man beispielsweise mit Hilfe neuro
naler Netze Zeit, Ort oder das semantische Profil aus schriftlichen Quellen automatisch
ermitteln? Wo können allenfalls nur Verbesserungen in der Verarbeitung erwartet wer
den, wo können sie den Bearbeiter gar ersetzen? Um diese Fragen zu beantworten, werden
der quellenkritische Arbeitsablauf und seine Bestandteile im Detail betrachtet, um sie zu
systematisieren und zu formalisieren. Bei dieser Aufgabe sind folgende Gedanken von
zentraler Bedeutung:
Jede schriftliche Quelle wird mit einer spezifischen und unveränderlichen Fragestellung
konfrontiert: Welche Klimainformation ist in der vorliegenden Quelle enthalten? Diese
simple Feststellung markiert den Unterschied zu den historischen Wissenschaften, die
eine Quelle immer wieder neuen Fragestellungen unterwerfen.
1. Jeder quellenkritische Arbeitsablauf kann als geordnete Menge von Arbeits
schritten beschrieben werden.
2. Jeder Arbeitsschritt ist ein Vorgang in der Zeit, welcher ein Objekt erzeugt oder
ein gegebenes Objekt verändert.
Ein Modell, welches diese Überlegungen berücksichtigt, definiert einen Arbeitsschritt wie
in Abb. 4 dargestellt ist.
Abb. 4: Ein vollständiger Arbeitsschritt besteht aus einem Anfangszustand s, einer
Transition t und einem Endzustand f. Die Erzeugung oder Zustandsänderung des
Objektes geschieht von s über t nach f. Im Speicher befinden sich die Endzustände.
Diese können festgesetzt sein oder aber auch wachsen.
553Rüdiger Glaser, Michael Kahle, Franck Borel, Rafael Hologa, Oliver Rau und Antje Kellersohn
Ein Arbeitsschritt ist eine Relation R zwischen der Menge der Anfangszustände S und den
Endzuständen F. Das entspricht der Abbildung von S auf F:
Rt:S → F
Automatisieren lassen sich jene Arbeitsschritte, bei denen der Definitionsbereich der An
fangszustände S mit einer Funktion f(S) auf die Zielmenge F abgebildet werden kann:
F = f(S)
Die Automatisierung bezeichnet somit den Vorgang, einen Anfangszustand mit einem
Endzustand paarweise in Relation zu stellen. Hierzu legen wir mögliche oder gegebene
Endzustände in einem Speicher ab. Solcherart sind wir auch für das Trainieren von Neuro
nalen Netzen gerüstet, wenn automatische Klassifikationen vorgenommen werden. Da der
Speicher die Menge der möglichen Endzustände darstellt, bildet er, fast schon nebenläufig,
die Grundlage einer Wissensbasis für die Historische Klimatologe: Mit jeder Aufnahme
eines neuen Urhebers oder Autors einer Quelle in den Speicher wächst die Kenntnis darü
ber, welcher Autor klimarelevante Beobachtungen gemacht hat. Dies ermöglicht dann z. B.
die gezielte Suche nach weiteren Quellen desselben Autors.
Es gibt Speicher mit endlichen Elementen, wie beispielsweise beim Arbeitsschritt zur
Bestimmung der Lesbarkeit der klimarelevanten Informationen einer Quelle. In diesem
Fall finden wir im Speicher die Elemente lesbar, zum Teil lesbar und nicht lesbar. Ande
re Speichertypen sind wachsende Speicher, deren Anzahl der Endzustände stetig wächst.
Dies ist z. B. der Fall bei der Verortung von Klimaereignissen.
Letzteres führt zur Frage, ob Arbeitsschritte mit wachsendem Speicher irgendwann ge
sättigt sind, bzw. ob die Grundmenge der Speicher, wie z. B. die Menge der schriftlichen
Quellen, endlich ist. Kenntnisse über die Grundmenge sind von entscheidender Bedeu
tung, wenn wir wissen wollen, wie zuverlässig ein Algorithmus mit unbekannten Quellen
umzugehen im Stande ist.
Da ein Arbeitsablauf nichts anderes als eine Abfolge von Arbeitsschritten ist, kann ein Arbeits
ablauf als lineare Ordnung, z. B. in Form eines Hasse-Diagramms, dargestellt werden (Abb. 5).
Bei näherer Analyse des Arbeitsablaufes werden Erkenntnisse über das Zusammenwir
ken der Arbeitsschritte, der Gestalt oder Typisierung von Arbeitsabläufen und die Mög
lichkeit, Arbeitsschritte zu parallelisieren, gewonnen.
Aus einem Arbeitsablauf lassen sich Ablaufpläne erstellen. Sie bestimmen, in welcher Rei
henfolge die einzelnen Arbeitsschritte erfolgen. Bei einem Ablaufplan handelt es sich um eine
lineare Erweiterung, welche auf den Arbeitsablauf angewandt wird. Die Anzahl der mögli
chen Ablaufpläne lässt sich auch berechnen (Abb. 6). Die fast schon absurd anmutende Anzahl
möglicher Ablaufpläne ist ein Zeichen für die Komplexität des quellenkritischen Ablaufes und
weist auf die Problematik der Nachvollziehbarkeit von Ergebnissen aus dem quellenkritischen
554Texte als Bausteine der Umweltforschung
Ablauf hin: Ohne Kenntnisse des Ablaufplans lassen sich Ergebnisse kaum rekonstruieren. Es
stellt sich die Frage, ob unterschiedliche Ablaufpläne zum selben Ergebnis führen. Hier wird
die Bedeutung von virtuellen Forschungsumgebungen besonders deutlich: Arbeitsabläufe und
Arbeitsschritte sind formalisiert. Einzelne Arbeitsschritte können nachvollzogen werden und
sorgen für zuverlässige Ergebnisse und damit auch für verlässliche Daten. Diese sind wiederum
Voraussetzung für die Automatisierung und die Anwendung des Maschinellen Lernens.
Abb. 5: Beispiel für einen vollständigen Arbeitsablauf zur Erschließung schriftlicher Quellen
in der Historischen Klimaforschung als Hasse-Diagramm.
555Rüdiger Glaser, Michael Kahle, Franck Borel, Rafael Hologa, Oliver Rau und Antje Kellersohn
Abb. 6: Anzahl möglicher Ablaufpläne eines Arbeitsablaufes gruppiert
nach der Anzahl der Arbeitsschritte.
6.2 Textanalyse mittels Statistik und Künstlicher Intelligenz
Nachfolgend werden ein historisches und ein modernes klimarelevantes Textzitat zu Main
franken mittels Statistik und künstlicher Intelligenz verarbeitet und analysiert. Dazu wurde
der Textkorpus aus tambora.org in Wörter zerlegt und mit den Indizes der Temperatur und
des Niederschlags der entsprechenden Monate verschnitten. Über bayessche Verfahren kön
nen so einzelnen Wörtern Wahrscheinlichkeiten für ihr Auftreten in bestimmten Klassen
zugeordnet werden. Aus diesen lassen sich Wortwolken in unterschiedlichen Größen und
Farben darstellen. Verwendet wurden die mitteleuropäischen Angaben aus tambora.org seit
1500. Dabei kristallisieren sich Schlüsselwörter heraus, welche die Wahrscheinlichkeit für
eine Klasse entweder besonders erhöhen oder auch herabsenken (Abb. 7).
Umgekehrt lassen sich die ermittelten Wortlisten verwenden, um ein Zitat einer Klas
se zuzuordnen. Dies soll anhand zweier Beispiele aus historischer und rezenter Zeit ver
deutlicht werden. Der erste Satz stammt aus dem Jahr 1756 der Hauschronik der Wie
senbronner Familie Hüßner (Glaser, Schenk u. Schröder 1991): „In meyen aber, als der
weinstock auß der wollen hervorging, ist ein frost eingefallen und sind die augen sehr
erfroren, jedoch gewann er wieder einen guten fortgang, und trieben wieder frische au
gen und ein gutes ansehen.“ Das zweite, moderne Textbeispiel aus dem MainPostArtikel
von 2018 lautet (Amling 2018): „Für den heutigen Nachmittag waren eigentlich Gewitter
gemeldet, doch die Sonne strahlt wie so oft in den letzten Wochen fast ungetrübt vom
Himmel.“
556Texte als Bausteine der Umweltforschung
Abb. 7: Wortwolken für aus dem tambora-Korpus generierte Schlüsselwörter in den sieben
Indexklassen für die Temperatur (links) von ‚sehr heiss‘ Indexwert +3, rot) bis ‚sehr kalt‘
(Indexwert -3, blau) und Niederschlag (rechts) von ,sehr feucht‘ (Indexwert +3, grün)
bis ‚sehr trocken‘ (Indexwert -3, braun). Wörter, die eher unwahrscheinlich
in der Klasse auftreten, sind grau dargestellt.
Das Tokenizing für die markantesten Begriffe der beiden Textzitate ergibt folgendes Bild:
Für das Zitat von 1756 und die Zuweisung zu den thermischen Indexklassen sind bei
spielsweise die Begriffe ‚Frost‘ und ‚erfrieren‘ besonders prägend. Interessant ist auch der
Begriff ‚eingefallen‘, da er auf ein extremes Ereignis hinweist, mit gleicher Wahrschein
lichkeit für sehr heiße und sehr kalte Temperaturen. Für das Zitat von 2018 dominiert
hingegen der Begriff ‚Sonne‘ die thermische Prägung (Abb. 8). Bei der jahreszeitlichen
Zuweisung in Abb. 9 ist der Begriff ‚Gewitter‘ ein eindeutiges SommerPhänomen. Der
Begriff ‚Meyen‘ wird dem Frühling zugewiesen. Problematisch ist der Begriff ‚hervor+geh‘
für hervorgehen, da dieser dem Herbst und erst in zweiter Präferenz dem Frühling zu
gewiesen wird.
557Rüdiger Glaser, Michael Kahle, Franck Borel, Rafael Hologa, Oliver Rau und Antje Kellersohn
Abb. 8: Tokenizing für die beiden Quellenzitate der Hüßner-Hauschronik von 1756 und
des Main-Post-Artikels von 2018 bezüglich der Temperatur-Indexklassen. Dargestellt
sind die Schlüsselbegriffe und die Wahrscheinlichkeit des Auftretens.
Abb. 9: Tokenizing für die beiden Quellenzitate der Hüßner-Hauschronik von 1756
und des Main-Post-Artikels von 2018 bezüglich der assoziierten Jahreszeiten.
In der automatischen Zuordnung zu den Jahreszeiten und Temperaturklassen (siehe
Abb. 10 und Abb. 11) wurden die Einzelwahrscheinlichkeiten aller Wörter multipli
ziert. Die Zuweisung ergibt aufgrund der besonderen Disposition von Wein wie dar
gestellt zu Frühjahr und Herbst eine präferierte Zuweisung in den Herbst, vor dem
Frühjahr, obwohl ein Großteil des Zitates sich auf den Frühling bezieht und explizit
der Mai erwähnt wird. Der Begriff ‚hervorgehen‘ ist für diese Gewichtung verantwort
lich. Eine monatsweise Klassifizierung erweist sich in einem solchen Fall als präzi
ser. Der Begriff ‚Frost‘ und ‚erfroren‘ schlägt sich in der Klassenzuweisung 2 wieder
(Abb. 10).
Für den Satz „Für den heutigen Nachmittag waren eigentlich Gewitter gemeldet, doch
die Sonne strahlt wie so oft in den letzten Wochen fast ungetrübt vom Himmel“ aus
dem MainPostArtikel von 2018 ergibt sich eine eindeutige saisonale Zuweisung in den
Sommer und auch in die entsprechende Temperaturklasse (Abb. 11).
558Texte als Bausteine der Umweltforschung
Abb. 10: Automatisch erzeugte Zuordnung der Jahreszeiten und der Temperaturklassen des
Hüßner-Zitates zum Jahr 1756.
Abb. 11: Automatisch erzeugte Zuordnung der Jahreszeiten und der
Temperaturklassen des Main-Post-Zitates von 2018.
559Rüdiger Glaser, Michael Kahle, Franck Borel, Rafael Hologa, Oliver Rau und Antje Kellersohn
Auch andere Dimensionen eignen sich für eine derartige Klassifikation, beispielswei
se Niederschlagsindizes, Windstärken, Hochwasserintensitäten oder Zeitepochen wie
Jahrhunderte. Die Auswertung weiterer Textstellen aus dem betreffenden Gebiet und
Zeitraum erhöht die Genauigkeit und wird einfach durch Zusammenfügen der Zitate
bewerkstelligt. Auch durch weiteres Training von Begriffen und entsprechenden Zu
weisungen wird die automatische Klassifizierung verbessert. Dies kann beispielsweise
durch Harvesting von rezenten Zeitungsartikeln in Kombination mit amtlichen Messda
ten erfolgen. Fehlzuweisungen in historischen Dokumenten können fortlaufend manu
ell korrigiert werden, wobei dazu auch Verfahren des Crowdsourcings denkbar wären.
Der hier skizzierte einfache Ansatz über einzelne kontextlose Wörter kann weiter ver
feinert werden, indem Wortpaare oder ganze Phrasen verwendet werden. Durch solche
verbesserten Verfahren können die Syntax und vor allem auch die sprachlichen Be
sonderheiten der historischen Texte berücksichtigt werden. Durch ausgefeiltere Wort-
Vektorisierung und die Verwendung von rekursiven, neuronalen Netzen kann auch der
Informationsgehalt von grammatikalischen und semantischen Strukturen erschlossen
werden.
Alles in allem ist der Weg zukunftsweisend, weil damit große Datenmengen, wie sie
durch die Digitalisierung anfallen bzw. angeboten werden, bewältigt werden können.
7 Fazit
Durch die neuen Möglichkeiten der Informationstechnologien und durch die Verbrei
tung des Internets ergeben sich vielfache neue Perspektiven der Datenakquise und der
weiterreichenden Erschließung neuer Bestände sowie der Nutzung von bereits vorlie
genden Digitalisaten im Bereich der historischen wie auch rezenten Umwelt- und Klima
forschung.
Leistungsfähige Datensammlungen und Datenbanken bieten schon heute vielfältige
neue Möglichkeiten der Datenkombination und Interpretation.
Virtuelle Forschungsumgebungen ermöglichen darüber hinaus arbeitsteilige und de
zentrale Arbeitsweisen, was sich für überregionale Projekte und Arbeitsgruppen geradezu
aufdrängt. In ihnen kann die komplexe Arbeits- und Verwertungskette, die für die histo
rische Umweltforschung besteht, abgebildet werden. Die Einbindung in öffentliche Ein
richtungen wie Bibliotheken ist ein wichtiger Garant für die nachhaltige Sicherung, den
Regelbetrieb und die rechtliche Handhabung.
Die Einbeziehung von Bürgerwissenschaften und sozialen Netzwerken bietet wei
terreichende Möglichkeiten, etwa für die Erschließung und Aufbereitung historischer
Bestände. Einige Aktivitäten wie die von Sturmjägern, Wettermeldern ergänzen das
bisherige Portfolio. Von besonderem Interesse ist aber auch, inwieweit die neuen Me
dien neue Formen der Darstellung und neue Formen der Nutzbarmachung hervor
560Texte als Bausteine der Umweltforschung
bringen. Oft sind diese räumlich dichter und zeitlich höher aufgelöst als andere In
formationen. Andererseits sind in sozialen Netzwerken auch viele Fakenews abrufbar
und Klimaleugner aktiv. Wie auch bei historischen Angaben ist eine kritische Sicht
unabdingbar.
Von besonderem Interesse ist aber die Erschließung tagesaktueller Klima- und Um
weltinformation, wie sie vielfach im Netz angeboten wird. Die Nutzung dieser aktuellen
hermeneutischen Klima- und Umweltangaben bietet die Möglichkeit, an die historischen
Informationen anzuschließen und kalibrierte lange Zeitreihen abzuleiten. Vor allem die
Umsetzung der Indexverfahren über Wort-Statistiken sind geeignet, die Schnittstelle zwi
schen textbasierten Informationen und instrumentellen Phasen zu überbrücken. Des Wei
teren können durch zeitgleich erhobene Messdaten Kalibrierungen und Abschätzungen
zur Qualität der aus Textangaben extrahierten Daten und Zeitreihen gemacht werden.
Das Ablaufschema, einschließlich der notwendigen quellenkritischen Bewertung, ist weit
gehend automatisierbar.
Textbasierte Quellen erlauben gegenüber instrumentellen Daten eine Bewertung von
Wahrnehmungen, Folgen, Reaktionen und gesellschaftlichen Kontexten, die durch instru
mentelle Messdaten nicht abbildbar sind. So gesehen ist die vielfach geäußerte Bewertung
der Objektivität von instrumentellen Daten gegenüber den a priori subjektiven Einschät
zungen der Betroffenen und Beteiligten zu relativieren bzw. durch geeignete Verfahren zu
evaluieren.
Die Digitalisierung hat auf die historische wie auch moderne Klima- und Um
weltforschung einen ähnlichen Einfluss wie die Erfindung des Buchdrucks durch
Gutenberg. Die Nutzung von Maschinellem Lernen und Künstlicher Intelligenz er
öffnet neue Möglichkeiten, was die Menge der bearbeiteten Daten anbelangt, und in
diesem Kontext auch neue Perspektiven der inhaltlichen Bewertung und methodi
schen Umsetzung.
Zusammenfassung
In dem Beitrag werden die weitreichenden methodischen Änderungen der textbasierten
historischen und aktuellen Umweltforschung thematisiert, wie sie sich seit den 1990er Jah
ren durch die Digitalisierung ergeben haben. In der Darstellung wird kurz die klassische,
analoge Analyse von Textquellen mit ihrer aufwendigen Archivarbeit, der Transkription
und quellenkritischen Interpretation skizziert. Darauf aufbauend wird die neuere Ent
wicklung, wie sie sich im Kontext der Digitalisierung ergibt, vorgestellt. Diese umfasst
die Einbindung in Datenbanken und die dafür notwendige Kodierung bis zur Integration
in virtuelle Forschungsumgebungen am Beispiel von tambora.org. Des Weiteren wird auf
die Besonderheiten der Verstetigung und nachhaltigen Sicherung sowie der Publikations
möglichkeiten eingegangen.
561Rüdiger Glaser, Michael Kahle, Franck Borel, Rafael Hologa, Oliver Rau und Antje Kellersohn
Schließlich werden die Potenziale neuer Auswertungsformate von Künstlicher Intel
ligenz und anderen Analyseverfahren sowie die Möglichkeiten von Crowdsourcing und
automatischen Verfahren wie Data Harvesting thematisiert.
Summary: Texts as basic elements of environmental research –
from classical analysis to databases and collaborative research
environments towards machine learning and crowdsourcing
This paper addresses the far-reaching methodological changes in text-based historical and
contemporary environmental research that have occurred since the 1990s as a result of
digitisation. The paper briefly outlines the classical analogue analysis of text sources with
its laborious archival work, transcription, and source-critical interpretation.
Based on this, the more recent development, as it arises in the context of digitisation, is
presented. This includes the integration into databases and the coding necessary for this
up to the integration into collaborative research environments (CRE) using the example of
tambora.org. In addition, the particularities of the continuation and sustainable preserva
tion as well as the publication possibilities will be discussed.
Finally, the potentials of new evaluation formats of artificial intelligence and other ana
lysis methods as well as the possibilities of crowdsourcing and automatic methods such as
data harvesting will be addressed.
Literatur
Amling, K. (2018): Bratwurst und Flamingos in Marktsteft, Main Post, https://web.archive.org/
web/20210408120805/https://www.mainpost.de/regional/kitzingen/bratwurst-und-flamingos-in-
marktsteft-art-10039397 (Zugriff: 31. Mai 2021).
Börngen, M. u. Tetzlaff, G. (2000): Quellentexte zur Witterungsgeschichte Europas von der Zeiten
wende bis zum Jahr 1850, Bd. 5. – Berlin u. Stuttgart.
Borel, F. (2010): HISKLIDCore, Expressum Nr. 6; UB Freiburg,
https://ojs.ub.uni-freiburg.de/exp/article/view/389/338 (Zugriff: 31. Mai 2021).
Bruijn, J. A. de; de Moel, H. u. Jongman, B. (2019): A global database of historic and real-time flood
events based on social media. – In: Sci Data 6, S. 311, https://doi.org/10.1038/s41597-019-0326-9.
Dzudzek, I.; Glasze, G. u. Mattissek, A. (2020): Diskursanalyse als Methode der Humangeographie. –
In: Lehrbuch Geographie. – Berlin.
Erfurt, M.; Glaser, R. u. Blauhut, V. (2019): Changing impacts and societal responses to drought
in southwestern Germany since 1800. – In: Regional Environmental Che, S. 1–13,
https://doi.org/10.1007/s10113-019-01522-7.
562Texte als Bausteine der Umweltforschung
Erfurt, M.; Skiadaresis, G.; Tijdeman, E.; Blauhut, V.; Bauhus, J; Glaser, R.; Schwarz, J.; Tegel, W.
u. Stahl, K. (2020): A multidisciplinary drought catalogue for southwestern Germany dating
back to 1801. – In: Nat. Hazards Earth Syst. Sci., 20 (11), S. 2979–2995, https://doi.org/10.5194/
nhess-20-2979-2020.
García‐Herrera, R.; Können, G. P.; Wheeler, D. A.; Prieto, M. R.; Jones, P. D. u. Koek, F. B. (2005):
CLIWOC: a climatological database for the World’s oceans 1750–1854. – In: Climatic Change 73,
S. 1–12.
Glaser, R.; Schenk, W. u. Schröder, A. (1991): Die Hauschronik der Wiesenbronner Familie Hüß
ner. Ihre Aufzeichnungen zu Wirtschaft, Geschichte, Klima und Geographie Mainfrankens von
1750–1894. – In: Materialien zur Erforschung früherer Umwelten (MEFU) 1, S. 1–57.
Glaser, R. (1996): Data and Methods of Climatological Evaluation in Historical Climatology. – In:
HSR (Historical Social Research) Vol. 21, 4, S. 56–88.
Glaser, R. (2013): Klimageschichte Mitteleuropas. 1200 Jahre Wetter, Klima, Katastrophen: [mit Pro
gnosen für das 21. Jahrhundert]. Sonderausgabe, 3., unveränd. Aufl. – Darmstadt.
Glaser, R. u. Riemann, D. (2009): A thousand-year record of temperature variations for Germany
and Central Europe based on documentary data. – In: Journal of Quaternary Science, 24 (5),
S. 437–449.
Glaser, R.; Himmelsbach, I. u. Bösmeier, A. (2017): Climate of migration? How climate triggered mi
gration from southwest Germany to North America during the 19th century. – In: Climate of the
Past, 13, S. 1573–1592, https://doi.org/10.5194/cp-13-1573-2017.
Glaser, R.; Riemann, D.; Vogt, S. u. Himmelsbach, I. (2018): Long- and Short-Term Central European
Climate Development in the Context of Vulnerability, Food Security, and Emigration. – In: Leg-
gewie, C. u. Mauelshagen, F. [Hrsg.]: Climate Change and Cultural Transition in Europe. – Berlin
(Climate und Culture 4), S. 85–118.
Glaser, R.; Hologa, R.; Bösmeier, A.; Heim, B.; Kahle, M.; Scholze, N. u. Schliermann-Krauss, E. (2020):
Klimageschichte der Frühneuzeit als Topos der universitären Forschung und Lehre. Die Kleine
Eiszeit (1430–1830) in Unterricht und Lehre, 120, S. 105–125.
Glaser, R. u. Kahle, M. (2020): Reconstructions of droughts in Germany sin
ce 1500 – combining hermeneutic information and instrumental records in historical
and modern perspectives. – In: Clim. Past (Climate of the Past), 16, S. 1207–1222:
https://cp.copernicus.org/articles/16/1207/2020/cp-16-1207-2020-discussion.html, (Zugriff: 31. Mai
2021).
Glaser, R.; Kahle, M.; Kellersohn, A. u. Rau, O. (2020): Dem Klimawandel auf der Spur. Der Weg
schriftlicher Quellen aus den Archiven in die virtuelle Forschungsumgebung. – In: Archivnach
richten, 60, S. 8–14.
Heim, B.; Glaser, R.; Kahle, M. u. Hologa, R. (2018): Westmittelfranken (1016–1840).
DOI: 10.6094/tambora.org/2018/c331/csv.zip.
Ionita, M.; Dima, M. u. Nagavciuc, V. (2021): Past megadroughts in central Europe were longer, more
severe and less warm than modern droughts. – In: Commun Earth Environ 2, 61,
https://doi.org/10.1038/s43247-021-00130-w.
Kahle, M.; Glaser, R. u. Hologa, R. (2020): Virtuelle Forschungsumgebungen – neue Formen kol
laborativer Zusammenarbeit. – In: Geographie. Physische Geographie und Humangeographie,
S. 205–212.
Kahle, M. u. Glaser, R. (2020): Fossgis2020: Javascript-Bibliotheken zur Einbindung von historischen
Umwelt-und Klimainformationen als Kartenlayer, DOI: 10.13140/RG.2.2.34723.40481 u. DOI:
10.5446/46488.
563Sie können auch lesen

















































