TÄTIGKEITSBERICHT 2019 - Institut für Medizinische Informatik, Statistik und Dokumentation Vorstand: Univ.-Prof. Dipl.-Ing. Dr. Andrea Berghold ...
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
TÄTIGKEITSBERICHT 2019 Institut für Medizinische Informatik, Statistik und Dokumentation Vorstand: Univ.-Prof. Dipl.-Ing. Dr. Andrea Berghold Auenbruggerplatz 2/V, 8036 Graz imi@medunigraz.at https://www.medunigraz.at/imi/
Inhaltsverzeichnis 1 Vorwort......................................................................... 1 2 Mitarbeiterinnen und Mitarbeiter .......................................... 2 3 Forschung ...................................................................... 4 3.1 Berichte aus den Forschungseinheiten ............................................ 4 3.2 Projektberichte ..................................................................... 17 4 Lehre ......................................................................... 27 4.1 Diplomstudium Humanmedizin (O 202) ......................................... 27 4.2 Doktoratsstudium der Medizinischen Wissenschaften (O 202 790) und PhD-Studium (O 094) ............................................................... 29 4.3 Masterstudium Pflegewissenschaft (O 331) ..................................... 29 4.4 Universitätslehrgänge .............................................................. 29 4.5 Abgeschlossene Diplomarbeiten und Dissertationen .......................... 30 5 Datenmanagement für Forschung und Lehre ........................... 31 5.1 Auswertungen aus klinischen Informationssystemen.......................... 31 5.2 Datenmanagement für klinische Studien ....................................... 33 5.3 iMAGIC Multimediadatenbank .................................................... 34 6 Publikationen ................................................................ 35 6.1 Beiträge in Zeitschriften .......................................................... 35 6.2 Zitierfähige Beiträge zu wissenschaftlichen Veranstaltungen ............... 46 6.3 Nicht zitierfähige Beiträge zu wissenschaftlichen Veranstaltungen ........ 54 6.4 Herausgeberschaften von wissenschaftlichen Sammelwerken .............. 56 6.5 Originalbeiträge in wissenschaftlichen Sammelwerken ...................... 56 6.6 Sonstige Veröffentlichungen ...................................................... 57 7 Allgemeines .................................................................. 58 7.1 Mitgliedschaften / Expertentätigkeit............................................ 58 7.2 Mitarbeit in Gremien ............................................................... 62
1 Vorwort Im Tätigkeitsbericht 2019 finden Sie einen Überblick über die Leistungen des Instituts für Medizinische Informatik, Statistik und Dokumentation in Forschung, Lehre und im wissen- schaftlichen Servicebereich. Am Institut wurden 2019 sehr erfolgreich Drittmittel eingeworben. So wurde Andreas Holzin- ger ein FWF-Einzelprojekt mit dem Titel „Towards a reference model of explainable Artifi- cial Intelligence for the Medical Domain“ (TAME-AI) zugesprochen und Alexander Avian konnte in einer der letzten Ausschreibungen der Österreichischen Nationalbank, die auch für den medizinisch-wissenschaftlichen Bereich zugänglich war, ein Projekt mit dem Titel „Post- operative Schmerzerhebung bei Kindern nach tageschirurgischen Eingriffen“ einwerben. Während Andreas Holzinger noch im Herbst eine Doktorandin im Rahmen des Projekts an- stellen konnte, das sich mit einem effizienten und ethisch verantwortungsvollen Einsatz von künstlicher Intelligenz für die Entscheidungsunterstützung in der Medizin beschäftigt, wird das zweite Projekt erst 2020 gestartet. Das Team um Stefan Schulz (Pablo López García, Jose Antonio Miñarro Giménez, Catalina Martínez Costa, Markus Kreuzthaler, Stefan Schulz) hat mit großem Erfolg die „Joint Onto- logy Workshops 2019“ (JOWO 2019) vom 23.09. bis 25.09. ausgerichtet. Diese Workshop- Reihe wurde zum fünften Mal abgehalten, wobei ein breites Spektrum von Themen im Zu- sammenhang mit formalen Ontologien in drei Keynotes, 12 Workshops und 5 Tutorials be- handelt wurde. Knapp 100 Teilnehmer*innen aus aller Welt haben an dieser Veranstaltung teilgenommen und einen regen wissenschaftlichen Austausch gepflegt. Wie jedes Jahr gab es auch personelle Veränderungen: Katharina Fink verließ uns Richtung Kärnten, Vendula Švendová ist in die Industrie gegangen, Catalina Martínez Costa und Jose Antonio Miñarro Giménez haben uns mit ihren beiden Kindern Richtung Spanien verlassen. Nach etwa 8-jähriger Tätigkeit am Institut werden die beiden Letztgenannten an der Uni- versität in Murcia (Universidad de Murcia), ihrer Heimatstadt, ihre Forschungs- und Lehrtä- tigkeit fortsetzen. Im Rahmen einer sehr netten Feier haben wir uns von ihnen verabschiedet und hoffen, dass wir weiterhin gut kooperieren werden. Andrea Borenich, Bastian Pfeifer, Josef Haas, Anna Saranti, Deepika Singh und für einige Monate Kathrin Benedikt sind zum Team dazugestoßen. Weiters gratulieren wir Michael G. Schimek sehr herzlich zur Verleihung des Berufstitels „Universitätsprofessor“ durch den Bundespräsidenten mit Entschließung vom 10. Juli 2019. Auf diesem Weg möchte ich mich bei allen Mitarbeiterinnen und Mitarbeitern für ihr Enga- gement sowie bei unseren Kooperationspartner*innen für die gute und produktive Zusam- menarbeit bedanken. Viel Spaß beim Lesen! Univ.-Prof. Dipl.-Ing. Dr. Andrea Berghold Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2019 Seite 1 von 62
2 Mitarbeiterinnen und Mitarbeiter E-Mail: vorname.nachname@medunigraz.at Telefon Name +43.316.385- Dipl.-Ing. Siegfried ACKERL 17875 PD Mag. Dr. Alexander AVIAN 17873 Mag. Dr. Gerhard BACHMAIER 12688 Kathrin BENEDIKT (ab 16.09.2019) 13201 Univ.-Prof. Dipl.-Ing. Dr. Andrea BERGHOLD 13201 Marcus BLOICE, BSc MSc 13589 Dipl.-Ing. Andrea BORENICH, MSc (ab 01.02.2019) 13205 Andreas DORN, BSc MSc 17879 Dipl.-Ing. Dr. Maximilian ERRATH 81828 Katharina FINK (bis 31.08.2019) - Univ.-Prof. Dr. Günther GELL (emeritiert) - ao. Univ.-Prof. i.R. Dipl.-Ing. Dr. Josef HAAS (ab 01.10.2019) 83477 Manuela HAID 84518 Larissa HAMMER (Studentische Mitarbeiterin) - David HASHEMIAN NIK (Studentischer Mitarbeiter) - Dipl.-Ing. Dr. Edith HOFER 80245 Magdalena HOLTER, BSc MSc 13203 Univ.-Doz. Ing. Mag. Mag. Dr. Andreas HOLZINGER 13883 Dr. Klaus JEITLER 77556 Ing. Andreas KAINZ 81374 Zdenko KASÁČ (Studentischer Mitarbeiter) - Dipl.-Ing. Dr. Markus KREUZTHALER 13591 Gabriele KRÖLL 12980 Pablo LÓPEZ GARCÍA, MSc PhD (Projektmitarbeiter / Gastforscher) - Astrid MANDL-POHL 17886 Catalina MARTÍNEZ COSTA, MSc PhD (bis 25.11.2019) - Bettina MASAREI 12512 Jose Antonio MIÑARRO GIMÉNEZ, MSc PhD (bis 31.08.2019) - Annemarie NUSSMÜLLER 12980 Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2019 Seite 2 von 62
Telefon Name +43.316.385- Mag. Dr. Petra OFNER-KOPEINIG 13588 Michel OLEYNIK, MSc (Gastforscher) 14518 Dr. Bastian PFEIFER (ab 30.09.2019) 17889 Rudolf PITZLER 83585 Dipl.-Ing. Gudrun PREGARTNER 14297 Mag. Dr. Franz QUEHENBERGER 17872 Astrid REICHER 83201 Dipl.-Ing. Dr. Regina RIEDL 17874 Dipl.-Ing. Anna SARANTI (ab 04.11.2019) 17988 Univ.-Prof. Mag. Dr. Dr. Michael G. SCHIMEK, MPhil (Univ. Bath) 14263 Andrea SCHLEMMER 84716 Dipl.-Ing. Erich SCHMIEDBERGER 17876 Michaela SCHNEIDER (Studentische Mitarbeiterin) - Univ.-Prof. Dr. Stefan SCHULZ 16939 Mag. Gerold SCHWANTZER 17867 Ass.-Prof. Dipl.-Ing. Dr. Klaus-Martin SIMONIC 13206 Deepika SINGH, PhD (ab 04.11.2019) 17880 Univ.-Prof. Dr. Josef SMOLLE 83588 Brigitte STROBL 83201 Mag. Dr. Vendula ŠVENDOVÁ (bis 30.06.2019) - Jose Antonio VERA RAMOS, BSc MSc 17889 Luca VITALE, MSc (Gastforscher) - Stefan VOGTBERG 14262 Univ.-Prof. Mag. Dr. Marco WILTGEN 13587 Mag. Dr. Gerit WÜNSCH 86939 Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2019 Seite 3 von 62

3 Forschung 3.1 Berichte aus den Forschungseinheiten 3.1.1 „Human-Computer Interaction for Medicine & Health Care” (HCI4MED) A. Holzinger Der Fortschritt in statistischen maschinellen Lernmethoden (ML) macht Anwendungen im Bereich der Künstlichen Intelligenz (KI) für die Medizin („Medical AI“) zunehmend erfolg- reich. Nach aktuellem Stand der Technik ist es für medizinische Expertinnen und Experten derzeit sehr schwierig, ja oft sogar unmöglich, nachzuvollziehen und zu verstehen, wie maschinelle Lernalgorithmen zu einer Entscheidung gelangen. Ein Beispiel sind typische Klassifikations- aufgaben, wie sie in der Medizin immer öfter Verwendung finden. Gerade die dabei erfolg- reichsten ML-Ansätze, wie z.B. „Deep Learning“ vermittels neuronaler Netze, sind letztlich sogenannte „Black-Box“-Modelle. Selbst wenn Expertinnen und Experten die zugrundelie- genden mathematischen Prinzipien verstehen, fehlt solchen Modellen eine explizite dekla- rative Wissensrepräsentation. Es gibt aber gerade in der Medizin bestimmte Aufgabenstellungen und bestimmte Situatio- nen, in denen eine nachvollziehbare Erklärung nicht nur hilfreich, sondern sogar notwendig ist. Insbesondere gilt dies in problematischen Situationen diagnostischer Entscheidungsfin- dung. Hier kann eine Erklärungskomponente dazu beitragen, den menschlichen Entscheidern zumindest eine Chance auf Überprüfung der kausalen Zusammenhänge und Plausibilität ei- nes Ergebnisses zu ermöglichen. Hier sind insbesondere Ansätze zur Messung der Qualität von Erklärungen notwendig1. Ein Beispiel sind medizinische Entscheidungsunterstützungssysteme, wo Lösungen nicht nur hilfreich, sondern notwendig sind, die es ermöglichen, Entscheidungen nachvollziehbar, transparent, verständlich und erklärbar zu machen. Gerade in der Medizin stellt sich nämlich zwangsläufig die Frage: „Können wir unseren Ergebnissen vertrauen?“. Hier ist das wissen- schaftliche Arbeitsgebiet „explainable AI“ (xAI) für die Medizin nicht nur nützlich, sondern stellt überdies eine Riesenchance dar, ethisch akzeptierbare KI-Lösungen in die Anwendung zu bringen, weil dadurch die oft zurecht vorgeworfene Undurchsichtigkeit („Black-Box-Cha- racter“) der KI vermindert und notwendiges Vertrauen aufgebaut werden kann. Genau dies kann die Akzeptanz von KI bei zukünftigen Benutzerinnen und Benutzern nachhaltig fördern. Ein weiterer und wichtiger werdender Bereich ist der juristische. Hier drängt die Zeit inso- fern, als dass hier international Lösungen gefunden werden müssen, da die neue Europäische Datenschutzgrundverordnung (DSGVO, vgl. auch mit ISO/IEC 27001) ein explizites „Recht auf Erklärung“ vorsieht. All die genannten Umstände machen das „Human-centered AI“ generell und „explainable AI“ speziell zu einem Thema für die Medizin, das weltweit enorm an Bedeutung zunimmt 1 Das Paper zu “Causability” von Andreas Holzinger et al. zählt zu den am meisten heruntergeladenen und höchst- zitierten Papers im Jahre 2019 bei Wiley. Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2019 Seite 4 von 62
und verstärkt zur Diskussion von Transparenz, Vertrauen, Interpretierbarkeit, Nachvollzieh- barkeit und Erklärbarkeit, aber auch von ethischen Aspekten von KI zwingt. Die große Chance liegt aber darin, nicht nur maschinelle Resultate transparent zu machen und damit Vertrauen in AI zu fördern, sondern vor allem ein tieferes Verständnis für vorher unbekannte Zusammenhänge und Kausalität (Frage nach dem „Warum“?) zu fördern. Man denke nur an die enorme Hilfestellung, die Ärztinnen und Ärzte aus der Kombination ihrer menschlichen Expertise („implizitem Wissen“) und datengetriebenen Algorithmen der KI (bspw. während einer Diagnosefindung) beziehen können: Menschen zeigen in niedrigdimen- sionalen Problemstellungen sehr gute Intuition, haben enormes implizites Wissen und sind in der Lage, erstaunlich gut aus wenigen Daten zu generalisieren und können kontextuelle Zu- sammenhänge erkennen. Daher ist ein human-in-the-loop bewusst in der Lage, KI-Techniken auf „interessante“ Daten anzusetzen und diese interaktiv zu hinterfragen, was neue Dialog- systeme („Human-AI Interaction“) erfordert. Umgekehrt können Algorithmen aus hochdi- mensionalen Datenräumen Resultate ermitteln, die kein Mensch je hätte finden können. Diese müssen jedoch für den Menschen verstehbar sein oder zumindest auf Plausibilität ge- prüft werden können. Vielleicht der wichtigste Beitrag ist es, aufzuklären, was Ursache ist und was Wirkung (und was nur Korrelation) ist — um zu vermeiden, dass man fälschlich Ar- tefakte und Surrogate miteinbezieht. Dies ist in vielen Anwendungsdomänen wünschenswert, in sicherheitskritischen Bereichen wie der Medizin jedoch zwingend erforderlich. Andreas Holzinger hat mit dem „Human-in-the-Loop“-Ansatz zu diesem Themenfeld interna- tional anerkannte Pionierarbeit geleistet, und er konnte im Jahre 2019 mit seiner Arbeits- gruppe weitere Erfolge erzielen: 3.1.1.1 Beginn des FWF-Projekts „Explainable AI in der Medizin“ Das FWF-Einzelprojekt P 32554 „Ein Referenzmodell für explainable AI in der Medizin“ wurde mit „exzellent“ in allen Punkten genehmigt. Das Projektvolumen umfasst € 392.773 und der offizielle Projektstart erfolgte am 4. November 2019. Die erste Doktorandin, die in diesem Projekt mitarbeitet, ist Frau Dipl.-Ing. Anna Saranti. Eine große Motivation für dieses Projekt sind steigende rechtliche, ethische und Daten- schutzprobleme, welche die Nutzung technisch erfolgreicher „Black-Box“-Lernmodelle er- schweren. Dies bedeutet kein Verbot automatischer Lernansätze oder eine Verpflichtung, alles ständig zu erklären. Es muss jedoch möglich sein, die Ergebnisse bei Bedarf nachver- folgbar zu machen. In diesem Projekt werden maschinelle Lernmethoden mit einem kontinuierlichen Eingangs- strom sensorischer Daten und (impliziter) Wissenserfassung kombiniert und dabei die kogni- tiven Fähigkeiten der Expertinnen und Experten (human-in-the-loop) genutzt. Das Ziel des Projektes ist, eine medizinische Expertin bzw. einen medizinischen Experten in die Lage zu versetzen, einen bestimmten Kontext zu verstehen und bei Bedarf eine maschinelle Ent- scheidung nach dem „Warum“ zu hinterfragen („Counterfactuals“). Dabei werden originäre Methoden entwickelt, um die Qualität von Erklärungen und deren Causability zu messen. Die Einsichten und Forschungsergebnisse werden die Entwicklung neuartiger „Human-AI Inter- faces“ ermöglichen, welche einen effizienten und ethisch verantwortungsbewussten Einsatz von künstlicher Intelligenz für die Entscheidungsunterstützung in der Medizin bieten. Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2019 Seite 5 von 62
3.1.1.2 Beginn des EU-Projekts „Feature Cloud“ Das EU-H2020-Projekt „FeatureCloud“ (Projekt-ID 826078) startete am 1. Februar 2019. Das Projekt mit einer Laufzeit von 5 Jahren und einem Fördervolumen von € 4.646.000 wurde im Rahmen des Calls H2020-SC1-FA-DTS-2018-2020 „Trusted digital solutions and Cybersecurity in Health and Care“ genehmigt. Das Projekt entwickelt eine neuartige AI-Infrastruktur, die auf einem sogenannten „föderierten maschinellen Lernansatz“ basiert: Es werden über eine Cloud nur erlernte Repräsentationen („Merkmale“) ausgetauscht („Merkmals-Eigenschaf- ten“, also Feature-Parameter, daher der Name "FeatureCloud"). Diese sind standardmäßig anonym („privacy-by-design“), d.h. es entstehen keine ethischen und datenschutzrechtli- chen Probleme bei ortsübergreifenden, gemeinsamen Arbeiten an sensiblen medizinischen Daten — die Echtdaten bleiben am Ursprungsort — die Lernalgorithmen arbeiten jeweils vor Ort. Die Arbeitsgruppe Holzinger widmet sich innerhalb des Gesamtprojektverlaufs drei kon- kreten Problemstellungen: i. In der ersten Projektphase wird ein Überblick und ein solides Verständnis verschie- dener Merkmalsräume experimentell erarbeitet, insbesondere über die Form und die Zusammensetzung dieser Merkmalsräume für medizinische Daten, die für das maschi- nelle Lernen von Bedeutung sind. Es wird dabei untersucht, ob und inwieweit be- stimmte Modalitäten (z.B. Graphen, Vektoren, Pixel, ...) für föderierte Lernansätze geeignet sind und in welchem Ausmaß. Ein besonderer Schwerpunkt werden dabei graph-basierte Ansätze sein. Maschinelles Lernen vermittels probabilistischer graphi- scher Modelle ist nicht nur generell ein vielversprechendes Thema in der KI, sondern ermöglicht die Grundlage für Nachvollziehbarkeit und Kausalität, da auf graphenthe- oretischen Strukturen abduktive und deduktive Schlussfolgerungen möglich sind, und ist daher ein Fundament für das Thema „explainable AI“. ii. Als medizinische Domäne fungiert die digitale Pathologie und als Datenbasis histopa- thologische Bilddaten. Dazu muss auch ein solides Verständnis pathologischer Arbeits- abläufe und Entscheidungsfindung aufgebaut werden. Im Weiteren wird eine föde- rierte Pathologie-Anwendung entwickelt, bestehend aus Docker-Container-imple- mentierten Modulen. Im weiteren Verlauf des Projektes wird sich die Arbeitsgruppe Holzinger auf das Design, die Entwicklung und Evaluierung von Human-AI-Interfaces konzentrieren, die eine Verwendung der in i) entwickelten Ansätze an einem medizi- nischen Arbeitsplatz ermöglichen. iii. Das dritte Thema betrifft das Gebiet „explainable AI“. Hier liegt die Aufgabenstellung in der Weiterentwicklung und der Evaluierung der in ii) entwickelten Human-AI- Interfaces, um a) die Interaktion von Expertinnen und Experten mit den verschiede- nen entwickelten Merkmalsräumen zu ermöglichen; und b) dabei Nachvollziehbarkeit und Interpretierbarkeit zu gewährleisten, um die gewonnenen Ergebnisse im Kontext der medizinischen Problemstellung zu erklären und zu verstehen. 3.1.1.3 Wahl von Andreas Holzinger als ordentliches Mitglied der Academia Europea Andreas Holzinger wurde als ordentliches Mitglied in die Sektion „Informatik“ der Academia Europea, der Europäischen Akademie der Wissenschaften, gewählt. 3.1.1.4 Gastprofessur an der University of Alberta in Edmonton Mit 15. Juli 2019 wurde Andreas Holzinger Gastprofessor für „explainable AI”, zunächst für die Dauer von 3 Jahren, am xAI-Lab des Alberta Machine Intelligence Institutes (AMII) der University of Alberta in Edmonton, Kanada. Das Institut in Edmonton ist eines der vier KI- Exzellenz-Institute auf dem Gebiet der KI, zusammen mit Montreal, Toronto und Vancouver. Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2019 Seite 6 von 62

Kanada gehört seit mehreren Jahrzehnten zur Weltspitze auf dem Gebiet der Künstlichen Intelligenz. 3.1.1.5 CD-MAKE-Tagung In seiner Funktion als National Representative für Artificial Intelligence im Technical Com- mittee TC 12 „Artificial Intelligence“ der IFIP (International Federation for Information Pro- cessing) organisierte Andreas Holzinger zum dritten Mal die CD-MAKE-Tagung, die 3rd Inter- national Cross-Domain Conference for Machine Learning and Knowledge Extraction an der University of Canterbury at Kent, UK. Dazu wurde wieder ein Springer-LNCS-Band publiziert: Andreas Holzinger, Peter Kieseberg, A. Min Tjoa & Edgar Weippl (eds.) 2019. Machine Learn- ing and Knowledge Extraction, Lecture Notes in Computer Science LNCS 11713, Cham (CH): Springer/Nature, doi:10.1007/978-3-030-29726-8_1. 3.1.1.6 TEDx-Event Die Med Uni Graz organisierte am 8. Oktober 2019 ein TEDxMeduniGraz-Event, bei dem An- dreas Holzinger einen TEDx talk „From Explainable AI to Human-Centered AI”2 gehalten hat. 3.1.1.7 Artikel in der KLEINEN ZEITUNG In der KLEINEN ZEITUNG vom Freitag, 15. November 2019, erschien ein Bericht über Andreas Holzinger und sein derzeitiges Arbeitsgebiet. 3.1.1.8 Lehrveranstaltung „Machine Learning for Health Informatics” Die Lehrveranstaltung „Machine Learning for Health Informatics”, die Andreas Holzinger in seiner Funktion als Gastprofessor an der TU Wien seit 2015 entwickelt hat (vollständig eng- lischsprachig, 3 ECTS, im Master Studiengang „Health Informatics" an der Fakultät für Infor- matik der Technischen Universität Wien), wurde auch im Jahre 2019 erfolgreich abgehalten. Das von Andreas Holzinger im Jahre 2016 editierte Springer-State-of-the-Art-Volume Lecture Notes in Artificial Intelligence (LNAI) “Machine Learning for Health Informatics” konnte im Jahr 2019 über 90.000 downloads auf Springerlink verzeichnen, was diesen Titel unter die Top 5 % in den Springer Lecture Notes gebracht hat. 2 https://www.youtube.com/watch?v=UuiV0icAlRs Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2019 Seite 7 von 62
3.1.2 „EBM (Evidence based Medicine) Review Center” K. Jeitler Die Research Unit „Evidence based Medicine Review Center“ hat in Kooperation mit dem Institut für Allgemeinmedizin und evidenzbasierte Versorgungsforschung auch 2019 wieder einige interessante Fragestellungen bearbeitet. Die Palette der selbst durchgeführten oder wissenschaftlich begleiteten Projekte ist breit. Neben Updates eigener Cochrane Reviews aus den Bereichen Diabetes und Hypertonie, Bewertungen der Wirksamkeit und Sicherheit neuer medizinischer Technologien (wie sondenlose Herzschrittmacher, bioresorbierbare Stents, lumbale Anulusverschlusssysteme) oder auch der methodischen und inhaltlichen Un- terstützung im Bereich der Entwicklung leitlinienbasierter Qualitätsindikatoren umfasst dies auch die Erarbeitung von Evidenzgrundlagen, die z.B. für die Erstellung evidenzbasierter Gesundheitsinformationen für Laien verwendet werden oder auch in Empfehlungen österrei- chischer medizinischer Fachgesellschaften einfließen, die eine Vermeidung von Über- und Fehlversorgung zum Ziel haben. Zwei dieser Projekte werden hier im Anschluss näher vorge- stellt. 3.1.2.1 Aktualisierung der Evidenz-Basis zur Erstellung von Gesundheitsinformationen Die Medien und insbesondere das Internet sind voll von Gesundheitsinformationen. Aber auch in Apotheken und Hausarztpraxen lassen sich viele Broschüren finden, die über Erkrankun- gen, Diagnose- und Therapie-Optionen informieren. Leider erfüllen viele der Informations- angebote nicht die Kriterien einer guten und ausgewogenen Gesundheitsinformation, die Betroffenen und ihren Angehörigen eine informierte Entscheidung ermöglichen und deren Gesundheitskompetenz erhöhen. So gehört z.B. eine zielgruppenspezifische und allgemeinverständliche Art der Darstellung und Kommunikation von Inhalten ebenso zu diesen Kriterien, wie Transparenz hinsichtlich Ersteller*in und etwaiger Interessenskonflikte, eine inhaltliche Ausgewogenheit oder auch Literatur- bzw. Quellangaben. Und hier kommt es insbesondere auch darauf an, dass diese auf Evidenz basieren. Erfreulicherweise gibt es inzwischen einige Organisationen, die sich bei der Erstellung von Gesundheitsinformationen streng an diesen Kriterien orientieren und insbesondere auch auf evidenzbasierte Quellen zurückgreifen. Manche Organisationen lagern die Suche und Aufbereitung der Evidenz ganz oder teilweise aus, was auch im nachfolgend vorgestellten Projekt der Fall war. Der Auftraggeber, das deutsche Institut für Qualität und Wirtschaftlichkeit im Gesundheitswesen, veröffentlicht qualitativ hochwertige Gesundheitsinformationen zu verschiedensten Erkrankungen und muss diese regelhaft auf deren Aktualisierungsbedarf prüfen. Die Identifizierung inhaltlich relevanter Evidenz und deren Synthese bilden dafür die Grundlage. Der Auftraggeber führte dazu selbst Recherchen zu zehn unterschiedlichen Gesundheitsthe- men durch. Inhaltlich ging es dabei um die Themenkomplexe Bluthochdruck, Morbus Parkin- son, Rheumatoide Arthritis, Blasenentzündung, Reizdarmsyndrom, Grauer Star (Katarakt), Grippe, Hernien, Wechseljahre und Depression. Die Recherche-Ergebnisse werden in einer Online-Datenbank zur Verfügung gestellt. Übermittelt wird auch die aktuell veröffentlichte Version der zehn Gesundheitsinformationen. Zunächst gilt es, qualitativ hochwertige, the- matisch relevante systematische Übersichten zu identifizieren. Anhand vorab vom Auftrag- geber festgelegter Einschlusskriterien prüfen in einem ersten Schritt zwei Personen unab- hängig voneinander alle Abstracts, ob diese die Kriterien erfüllen, und gleichen ihre Ergeb- nisse miteinander ab. Potenziell relevante Literatur wird im Anschluss in gleicher Weise im Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2019 Seite 8 von 62
Volltext gesichtet und abgeglichen. Inhaltlich relevante Übersichten werden danach einer Qualitätsbewertung (Oxman-Guyatt-Score) unterzogen und schließlich eingeschlossen, wenn sie die Mindest-Qualitätsanforderungen erfüllen. Alle Schritte erfolgen unabhängig durch zwei Personen und werden auch entsprechend dokumentiert. Es wird eine Evidenzsynthese erstellt. Dazu werden die neu identifizierten Übersichtsarbei- ten inhaltlich gruppiert und deren Fragestellungen, Inhalte und wichtigsten Ergebnisse bzw. Schlussfolgerungen in eine Tabelle extrahiert. Zusätzlich werden auch Informationen hin- sichtlich Anzahl der inkludierten Studien, Aktualität (Datum der Recherche) und das Ergebnis der Qualitätsbewertung in dieser Tabelle erfasst. Basierend auf diesen Informationen wird schließlich festgelegt, aus welchen Übersichten die detaillierten Ergebnisse extrahiert wer- den. Bei dieser Auswahl liegt die Herausforderung darin, eine möglichst gute Balance zwi- schen inhaltlichem Umfang, Aktualität und Qualität der Übersichten zu erreichen. Basierend auf den extrahierten Ergebnissen wird festgestellt, welche Aussagen bezüglich einer Therapie oder Diagnosemaßnahme sich daraus ableiten lassen. Dies wird schließlich mit den bereits vorhandenen Aussagen in der bisher veröffentlichten Gesundheitsinformation abgeglichen. Auf diese Weise kann festgestellt werden, ob es auf Basis der verfügbaren Evi- denz gleichlautende, abweichende oder auch neue Aussagen zu einem bestimmten Gesund- heitsthema gibt. Der so ermittelte Aktualisierung- oder Änderungsbedarf wird entsprechend dokumentiert und dem Auftraggeber als Vorschlag am Ende eines Gesamtberichts übermit- telt. Welche Vorschläge letztlich in die aktualisierten Gesundheitsinformationen übernommen werden, entscheidet der Auftraggeber. Diese werden meist einige Wochen danach auf des- sen Homepage veröffentlicht3. 3.1.2.2 Update des Pools an verlässlichen Empfehlungen internationaler Fachgesell- schaften für deren Verwendung im Projekt „Gemeinsam Gut Entscheiden“ Seit 2017 gibt es in Österreich die Initiative „Gemeinsam Gut Entscheiden“, ein Zusammen- schluss von zwei Einrichtungen aus dem Bereich der evidenzbasierten Medizin (konkret dem Institut für Allgemeinmedizin und evidenzbasierte Versorgungsforschung der Medizinische Universität Graz und Cochrane Österreich) mit nationalen medizinischen Fachgesellschaften. Ziel dieser Initiative ist es, eine Über- und Fehlversorgung von Patientinnen und Patienten zu vermeiden, indem nicht notwendige oder schädliche medizinische Serviceleistungen von den Fachgesellschaften explizit benannt werden und dies insbesondere auch mit wissen- schaftlichen Literaturzitaten belegt wird. Für die Zielgruppen — in erster Linie Ärztinnen und Ärzte im niedergelassenen Bereich und deren Patientinnen und Patienten — ist dabei wichtig, dass diese Empfehlungen auch verlässlich sind, was durch eine hohe Transparenz und Nachvollziehbarkeit sowohl hinsichtlich des Auswahl- und Erstellungsprozesses innerhalb der Fachgesellschaften als auch der zugrundeliegenden wissenschaftlichen Evidenz erreicht wird. Die Initiative ist Teil einer größeren weltweiten Bewegung, die mit der US-Choosing-Wisely- Initiative vor einigen Jahren ihren Ausgang genommen hat und inzwischen in zahlreichen weiteren Ländern (u.a. Kanada, Australien, Großbritannien, Schweiz, Deutschland, Italien) in gleicher oder ähnlicher Weise übernommen wurde. Die Empfehlungen werden von den 3 https://www.gesundheitsinformation.de Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2019 Seite 9 von 62
nationalen Fachgesellschaften zumeist in Form von sog. Top-5-Listen herausgegeben und von den Choosing-Wisely-Initiativen (CW-Initiativen) auf ihren Webseiten gebündelt und veröf- fentlicht. Bei den Empfehlungen gibt es durchaus Unterschiede, was die Angaben zum Er- stellungsprozess, zur zugrundeliegenden Evidenz oder auch deren Evaluation und ggf. Aktu- alisierung betrifft, sodass diese aus Sicht der Anwender durchaus unterschiedliche Grade an Verlässlichkeit aufweisen. Die Initiative „Gemeinsam Gut Entscheiden“ stellt den teilnehmenden medizinischen Fach- gesellschaften in Österreich einen Pool an ausreichend verlässlichen Empfehlungen zur Ver- fügung, die diese selbst als Basis für ihre eigenen Top-Listen verwenden können, aber auch um eigene, neue Empfehlungen erweitern können. Der Auswahl- und Erstellungsprozess muss jeweils transparent dargelegt werden und in dem Fall, dass neue eigene Empfehlungen for- muliert werden, muss auch die zugrundeliegende Evidenz entsprechend dargelegt oder er- arbeitet werden. Ziel des Update-Prozesses im Berichtsjahr 2019 war es, diesen Pool an verlässlichen Empfeh- lungen zu aktualisieren. In diesem Pool werden nur aktuell gültige Empfehlungen der ver- schiedenen internationalen CW-Initiativen gesammelt, die auch ein ausreichendes Maß an Verlässlichkeit aufweisen. Der Update-Prozess verläuft im Wesentlichen in folgenden Schrit- ten: Recherche nach aktuellen internationalen CW-Empfehlungen — Abgleich mit dem bis- herigen Pool — Bewertung der Verlässlichkeit neuer oder geänderter Empfehlungen — Aktu- alisierung des Pools. Bei der Recherche wurden die Websites von sieben internationalen CW-Initiativen durch- sucht und zunächst alle aktuellen Empfehlungen extrahiert (u.a. Wortlaut der Empfehlung, herausgebende Fachgesellschaft, angegebene Evidenzen, Datum der Veröffentlichung/Aktu- alisierung, Angaben zur Methodik und dem Abstimmungsprozess). Diese knapp 1.700 Emp- fehlungen wurden dann jenen gegenübergestellt, die in der letzten Recherche vier Jahre zuvor identifiziert und bewertet worden waren. Für einen kleinen Teil der Empfehlungen, deren extrahierte Informationen identisch waren, konnte so die ursprüngliche Bewertung übernommen werden. Für den Rest der Empfehlungen erfolgte eine Bewertung der Verlässlichkeit anhand von Kri- terien, die vier Jahre zuvor entwickelt und im Zuge des Updates methodisch noch einmal verfeinert wurden. Im Wesentlichen gilt eine Empfehlung dann als ausreichend verlässlich, wenn aus den verfügbaren Informationen hervorgeht, dass der Empfehlung eine systemati- sche Literaturrecherche zugrunde liegt, dass die Empfehlung das Ergebnis eines weitgehend ausgewogenen und transparenten Prozesses innerhalb der Fachgesellschaft darstellt (z.B. multidisziplinär, strukturierter Konsensusprozess, deklarierte Interessenskonflikte) und dass von einer ausreichenden Aktualität ausgegangen werden kann (rezente Literatur oder Up- date-Prozess angegeben). Empfehlungen, die diese Kriterien nicht erfüllen, können nicht in den Pool der ausreichend verlässlichen Empfehlungen eingeschlossen werden, weil deren Verlässlichkeit aufgrund fehlender Angaben nur unzureichend bewertbar ist, was jedoch nicht automatisch bedeutet, dass diese Empfehlungen unzuverlässig sind. In den aktualisierten Pool an ausreichend verlässlichen CW-Empfehlungen konnten so schließlich 461 Empfehlungen inkludiert werden, die von den teilnehmenden österreichi- schen Fachgesellschaften für die Erstellung ihrer eigenen nationalen Top-Liste verwendet werden können. Zwei Fachgesellschaften (Österreichische Gesellschaft für Allgemein- und Familienmedizin, Österreichische Gesellschaft für Geriatrie und Gerontologie) haben auf Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2019 Seite 10 von 62
dieses Weise bereits ihre Top-Listen erarbeitet, die von der Initiative „Gemeinsam Gut Ent- scheiden“ auf der Homepage4 veröffentlicht wurden und von dort auch heruntergeladen wer- den können. Das Interesse der Fachgesellschaften ist groß — derzeit sind gerade Top-Listen von zwei weiteren Fachgesellschaften (Österreichische Gesellschaft für Public Health, Ös- terreichische Gesellschaft für Gynäkologie und Geburtshilfe) in Arbeit. 4 https://www.gemeinsam-gut-entscheiden.at Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2019 Seite 11 von 62
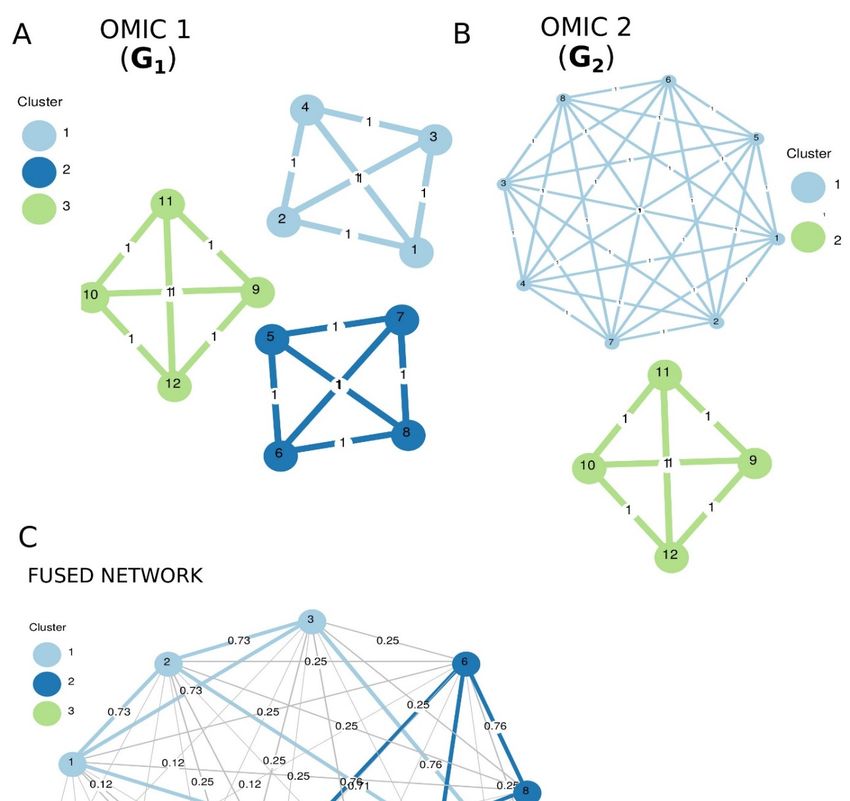
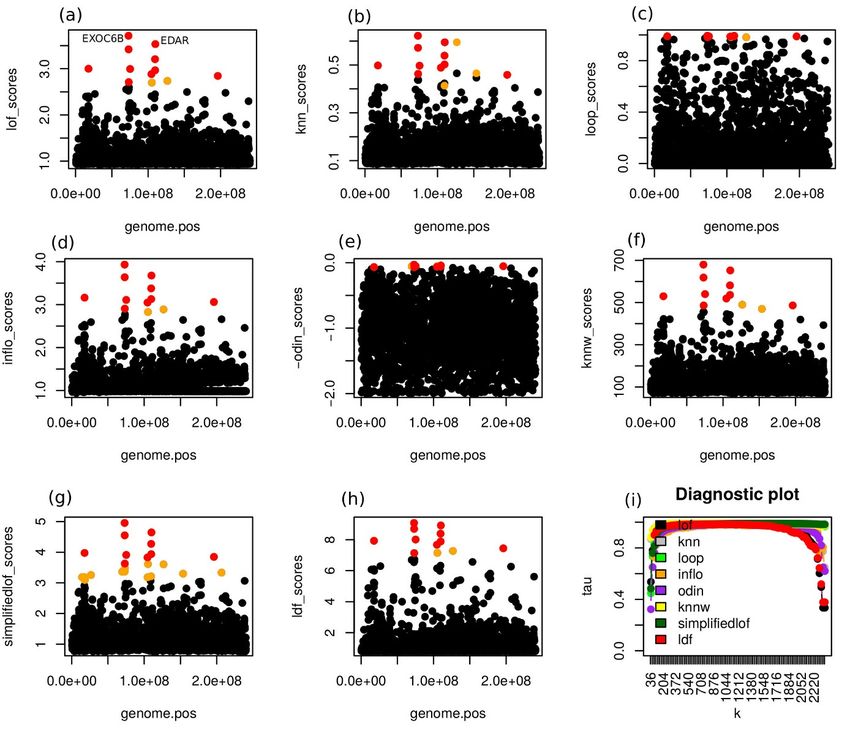
3.1.3 „Statistische Bioinformatik“ (StatBI) M.G. Schimek Die Forschungseinheit "Statistische Bioinformatik" wird von Herrn Univ.-Prof. Dr. Dr. Michael G. Schimek geleitet. Sie ist an der Schnittstelle zwischen Biostatistik und Bioinformatik an- gesiedelt. Als Teil eines weltweiten akademischen Netzwerkes arbeitet sie eng mit medizi- nischen und biowissenschaftlichen Forscherinnen und Forschern zusammen. Ein spezieller Arbeitsschwerpunkt liegt auf Methoden der statistischen Integration von „omics“-Daten sowie von anderen klinisch relevanten Daten. In letzter Zeit wird hierfür auch die Bezeichnung „data fusion technology“ verwendet. Neuesten internationalen Entwicklun- gen Rechnung tragend, ist ein weiterer Arbeitsschwerpunkt „Data Science“ in den medizi- nisch-biologischen Wissenschaften. Hierbei geht es nicht nur um die Verarbeitung großer komplexer Datenmengen, sondern auch um die Verknüpfung statistischer Methoden mit Ver- fahren des maschinellen Lernens und der mathematischen Optimierung. Jedes der neuen Projekte steht im Kontext dieses interdisziplinären Ansatzes. Zwei Projekte wurden bzw. werden gemeinsam mit dem Bioinformatiker Dr. Bastian Pfeifer, seit 2019 neu an der For- schungseinheit StatBI, durchgeführt. Die biologische Evolution, also das Weitervererben von genetischen Ausprägungen von Ge- neration zu Generation, ist der Baumeister eines jeden menschlichen Körpers. Menschen wanderten seit jeher rund um den Globus und stießen auf unterschiedliche Krankheitserre- ger. Natürliche Selektion ist der treibende Faktor, der es ermöglicht, sowohl für Krankheits- erreger als auch für den Menschen selbst, sich auf genetischer Ebene den vorhandenen Öko- systemen anzupassen. Moderne Hochdurchsatzverfahren zur DNA-Sequenzierung produzieren enorme Datenvolumina, die jedoch für das Studium der natürlichen Selektion notwendig sind. An der Forschungseinheit StatBI wurde das Projekt „Genome Scans for Selection and Int- rogression based on k-Nearest Neighbor Techniques“ durchgeführt. Hierbei geht es um Me- thodenentwicklung zur effizienten Analyse von populationsgenomischen Daten. Zum Einsatz kamen Techniken des maschinellen Lernens mit dem Ziel, Populationsstrukturen zu inferie- ren. Ausgangspunkt war die Forschungsannahme, dass Regionen mit spezifischen Abweichun- gen von globalen genomischen Strukturen Aufschlüsse über Selektionsprozesse liefern kön- nen und somit auf mögliche genetische Varianten hindeuten würden. Solche Varianten kön- nen beispielsweise die Reaktion auf Erregerinfektionen beeinflussen und mit der Fähigkeit einhergehen, Infektionskrankheiten zu überleben. Im Rahmen dieses Projektes wurde Soft- ware in der Programmiersprache R entwickelt und der wissenschaftlichen Community zur Verfügung gestellt. Um den praktischen Nutzen von k-Nearest Neighbor-Methoden zu de- monstrieren, wurde der zur Zeit größte fachöffentlich verfügbare populationsgenomische Datensatz (1000 Genomes Project Consortium, 2015) mit folgendem Fokus ausgewertet: In- ferenzielle Analyse der genetischen Populationsrelationen zwischen 183 Menschen mit nord- und westeuropäischer Abstammung (CEU), 108 Menschen ostasiatischer Abstammung (CHB) und 186 Menschen afrikanischer Abstammung (YRI), basierend auf Chromosom 2 des mensch- lichen Genoms (siehe Abbildung 1 als Illustration von Genomscan-Ergebnissen unterschiedli- cher Methoden; Abweichungen in rot oder orange). Einer der Topkandidaten unter Selektion ist das Gen EDAR. Mutationen in diesem Gen werden mit einer hypohidrotischen ektoderma- len Dysplasie (HED) in Verbindung gebracht, einer Erkrankung, die durch eine geringere Dichte der Schweißdrüsen gekennzeichnet ist. Ein weiterer Genkandidat ist EXOC6B. Genva- rianten dieses Gens sind assoziiert mit spondylometaphysären Dysplasien (SMD), einer Gruppe von Krankheiten, die im zweiten Lebensjahr mit Gang- und Wachstumsstörungen Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2019 Seite 12 von 62
manifest werden. Eine Veröffentlichung [Pfeifer, B. et al. (2019) “Genome Scans for Selec- tion and Introgression based on k-nearest Neighbor Techniques” BioRxiv] ist für das Fach- journal Molecular Ecology Resources in Revision. Abb. 1: Auffälligkeiten am Chromosom 2 beim Einsatz unterschiedlicher Methoden (siehe Vergleich im „Diagnostic Plot“). Ein weiteres Projekt an der Forschungseinheit StatBI beschäftigt sich mit der multiomics- basierten statistischen Analyse komplexer Krankheiten, insbesondere von Krebs. Die biolo- gischen Wechselwirkungen, die solchen Krankheiten zugrunde liegen, sind mehrdimensiona- ler Natur und können nur auf Systemebene ganzheitlich studiert werden. Statistische Ver- fahren, die multiomics-Daten integrativ verarbeiten können, sind weitgehend neu. Sie stel- len einen vielversprechenden Ansatz dar, um der krankheitsspezifischen molekularbiologi- schen Komplexität gerecht zu werden. Weltweit haben Wissenschaftler*innen große Mengen an Daten zu diversen Krebsarten generiert, bioinformatisch analysiert und in Datenbanken gesammelt. Ein Beispiel dafür ist das TGCA-Projekt (The Genome Cancer Atlas)5, das darauf abzielt, die wichtigsten krebsverursachenden Genomveränderungen zu katalogisieren, um einen umfassenden „Atlas“ der Krebsgenomprofile zu erstellen. Eine Zusammenführung sol- cher Daten ist nicht trivial, da verschiedene biologischen Entitäten (mRNA-Expression, DNA- 5 https://www.cancer.gov/ Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2019 Seite 13 von 62
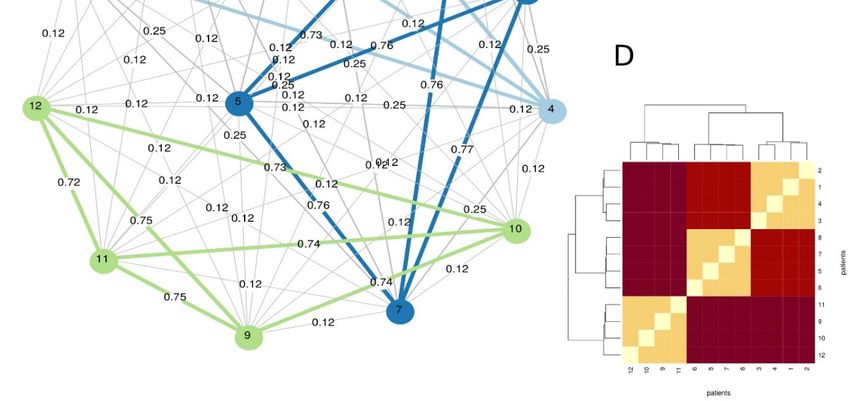
Methylierung, DNA-Sequenzdaten) fundamental unterschiedlichen statistischen Verteilungen unterliegen. Abb. 2: A und B sind Ausgangscluster, C die gemeinsame Netzwerkstruktur und D der Clusteraufbau. In dem Projekt „A Hierarchical Clustering and Data Fusion Approach for Disease Subtype Discovery“ wurde mit Unterstützung durch die Kurt-und-Senta-Herrmann-Stiftung (Vaduz, Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2019 Seite 14 von 62
Fürstentum Liechtenstein) eine integrative Clustermethode für die möglichst präzise Zuord- nung von Krebspatient*innen zu klinisch relevanten Subgruppen (i.e. statistischen Clustern) entwickelt. Die Grundidee dieser Methode besteht darin, die omics-spezifischen Informatio- nen zunächst in eine Netzwerkstruktur überzuführen, um die Clusterzugehörigkeiten der Krebspatient*innen in effizienter Weise normalisiert und formal abzubilden. Die omics-spe- zifischen Netzwerke werden dann in einem zweiten Schritt mittels eines neu entwickelten Algorithmus fusioniert (siehe Abbildung 2 zur Integration der Netzwerkstrukturen). Erste Er- gebnisse zeigen, dass die Methode zu einem besseren Verständnis des Krebsverlaufs beitra- gen kann und das Potential hat, die Behandlung von Krebspatient*innen zu optimieren. Diese Forschungsergebnisse liegen als Preprint vor [Pfeifer, B. and Schimek, M. G. (2020) „A Hie- rarchical Clustering and Data Fusion Approach for Disease Subtype Discovery“ bioRxi]. Ein weiteres Tätigkeitsfeld der Forschungseinheit StatBI sind Methoden zur Analyse von Da- ten blutzirkulierender DNA (ctDNA), hoch relevant für die aktuelle Krebsforschung. Im Jahr 2019 wurden zwei Dissertationen, die die Analyse von blutzirkulierender DNA zum Inhalt haben, von Prof. Schimek aus biostatistischer und bioinformatischer Sicht betreut. Der PhD-Kandidat Peter Ulz, MSc (Thema: „Using circulating tumor DNA (ctDNA) to identify therapy restistance mechanisms in HER2-positive breast cancer patients“) konnte sein Dis- sertationsprojekt mit folgender Publikation erfolgreich zum Abschluss bringen: Ulz, P. et al. (2019) „Inference of transcription factor binding from cell-free DNA enables tumor subtype prediction and early detection”, Nature Communications, 10: 4666. Auch der PhD-Kandidat Isaac Lazzeri, MSc (Thema: „Early detection of cancer from liquid biopsy”) beschäftigt sich mit Methoden für die Integration („data fusion“) genomischer Da- ten unterschiedlicher Entitäten. Auch hier bildet Information aus blutzirkulierender DNA die Basis seiner Arbeit. In Isaac Lazzeris laufendem Projekt liegt der Fokus auf einer speziellen Technik des maschinellen Lernens, genannt Autoencoder. Autoencoder gehören der Familie der künstlichen neuronalen Netze an und erlauben unüberwachtes Lernen („unsupervised learning“). Ziel ist eine komprimierte Repräsentation von komplexen Daten unter gleichzei- tiger Extraktion wesentlicher Merkmale. Das ist technisch gesehen eine Dimensionsredukti- onsaufgabe unter weitgehender Ausschaltung des Noise-Einflusses in den Daten. Dieser An- satz soll auch eine verbesserte Integration von multiomics-Daten, verglichen mit etablierten statistischen Verfahren wie jenes der Hauptkomponentenanalyse (nur unter Einsatz linearer Neuronen vergleichbar), ermöglichen. Simulationsergebnisse weisen auf eine mögliche Über- legenheit von Autoencodern, sind jedoch nicht unmittelbar auf reale Daten verallgemeiner- bar. Seit 1. Februar 2019 ist Luca Vitale, MSc, von der Universität Salerno (Italien) als Gastfor- scher und PhD-Kandidat an der Forschungseinheit StatBI. Er wird von Prof. Schimek, der auch sein PhD-Supervisor im Rahmen eines European Doctorate-Label-Programmes ist, betreut. Luca Vitales PhD-Thema lautet „Large Scale Statistical Learning“. Während seines Gastau- fenthaltes arbeitet er am Projekt „Estimation of the Latent Signals for Consensus Across Multiple Ranked Lists using Convex Optimization“. Ziel dieses Projektes ist die Schätzung jener unbeobachtbaren statistischen Parameter, die für das Ranking von vorgegebenen Ob- jekten nach Relevanz durch rangzuweisende Instanzen (z.B. durch Experten oder durch Ma- schinen) verantwortlich sind. Eine typische Anwendung in der Bioinformatik wäre die In- tegration von Daten mehrerer Sequencing-Plattformen, die Proben, die unter vergleichbaren diagnostischen Kriterien erzeugt wurden, verarbeiten. Ergebnis wäre die Rekonstruktion der molekularbiologischen Signale, die den nach Expressionswertigkeit gereihten Genen zu- Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2019 Seite 15 von 62
grunde liegen. Diese Signale können therapeutische Hinweise zu unterschiedlichen Krank- heitsverläufen, z.B. bei Krebs, geben. Eine weitere interessante Anwendung ist die Konsoli- dierung von Resultaten aus stochastischen Algorithmen. Für einen fixen Inputdatensatz va- riieren die Resultate solcher Algorithmen aufgrund ihrer Konstruktionsweise, die zufallsge- steuerte Operationen inkludiert. Häufig gibt es keine Alternativen zu solchen nicht-determi- nistischen Algorithmen. Ziel ist jedoch ein eindeutiges — also stabiles — Resultat, um einer unerwünschten Schätzunsicherheit oder Fehlklassifikation vorzubeugen. Eine typische An- wendung ist die Selektion von Prädiktoren oder Features im Kontext von Regressions- und Lernverfahren. Verfahren zur Schätzung von latenten Signalen aus beobachteten multiplen Rangreihen sind nicht neu. Prof. Schimek betreute vor einigen Jahren an der Forschungseinheit StatBI die Dissertation von Mag. Dr. Vendula Švendová mit einer vergleichbaren Zielsetzung. Funda- mental neu an dem Projekt mit Luca Vitale ist der formale Ansatz. Anstelle eines stochasti- schen Markov-Chain-Monte-Carlo-Schätzverfahrens wurde ein spezieller Optimierungsansatz entwickelt. Dieses methodisch neue Verfahren ist numerisch wesentlich weniger aufwändig und erlaubt, enorm große Rangdatensätze integrativ zu verarbeiten, also beispielsweise Be- obachtungen auf der Basis des kompletten Humangenoms vieler Patient*innen. Von der Forschungseinheit StatBI werden seit Jahren Open-Source-Softwaretools in R (kom- patibel mit dem Bioconductor-Projekt) für neue statistische Verfahren, Optimierungs- und Lerntechniken entwickelt. Das Software-Paket TopKLists6 ist sicher in der wissenschaftlichen Community am weitesten verbreitet. Während des Jahres 2019 war das Fortsetzungspaket TopKSignal in Entwicklung. Es bietet die Implementierung mehrerer konvexer Optimierungs- verfahren für die Signalschätzung auf der Basis multipler Rangreihen wie zuvor beschrieben. Prof. Schimek ist an der Medizinischen Universität Graz auch für die Lehre in Bioinformatik zuständig und betreute 2019 drei Doktoranden (Details siehe oben). Zusätzlich lehrte er im Wintersemester 2019/20 am Institut für Mathematik der Paris Lodron Universität in Salzburg Wahrscheinlichkeitstheorie und Statistik (Vertretung von Univ.-Prof. Dr. Arne Bathke wäh- rend seines Forschungs-Sabbaticals). Ehrungen: Verleihung des Berufstitels „Universitätsprofessor“ durch den Bundespräsidenten mit Entschließung vom 10. Juli 2019 an Herrn ao. Univ.-Prof. Dr. Dr. Michael G. Schimek, Leiter der Forschungseinheit Statistische Bioinformatik. 6 http://topklists.r-forge.r-project.org/ Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2019 Seite 16 von 62
3.2 Projektberichte 3.2.1 Quantum Imaging M. Wiltgen Die Quantenbildgebung (Quantum Imaging) nutzt das quantenphysikalische Phänomen der Verschränkung von Photonen aus, um Objekte mit einer Auflösung oder anderen Bildkriterien abzubilden, die über das hinausgehen, was in klassischen bildgebenden Verfahren möglich ist. In der Mikroskopie erhalten wir damit neue Einblicke in Struktur und Dynamik zellulärer Prozesse. Zusätzlich ermöglicht Quantum Computing neue Möglichkeiten der Bildverarbei- tung. Bei den bisher verwendeten Abbildungsverfahren bildet man einen Gegenstand ab, indem man ihn mit Licht bestrahlt und anschließend die von ihm kommenden Photonen (Reflektion oder Transmission) mit einem Detektor (z.B. einer Kamera) auffängt. Neuartige Verfahren, welche verschränkte Photonen verwenden, arbeiten nach dem folgen- den Prinzip: Ein Objekt wird mit infraroten Photonen bestrahlt, welche gar nicht detektiert werden. Anschließend wird ein Bild des Objektes mit Photonen im sichtbaren Bereich (rot) gewonnen, die nie in der Nähe des Objekts waren. Die infraroten Photonen und die Photonen im sichtbaren Bereich bilden quantenmechanisch verschränkte Paare, deren Verhalten kor- reliert ist. Wenn bei einer Messung ein Photon des Paares eine bestimmte Eigenschaft (z.B. eine Polarisationsrichtung) zeigt, geht das Partner-Photon augenblicklich in einen durch die Korrelation bestimmten Zustand über. BS1 L3 DM1 S M2 I LASER L1 L4 NL1 S Object L2 BS2 L5 DM3 S M1 DM2 L6 IP1 NL2 I I EMCCD IP2 Abb. 3: Konfigurationsaufbau für Quantum-Imaging-Verfahren. Der Konfigurationsaufbau derartiger Verfahren enthält typischerweise einen Laser, nichtli- neare optische Kristalle (NL), Strahlteiler (BS), diverse Linsen (L), mehrere Spiegel (M, DM) und eine Kamera (EMCCD) für Photonen im sichtbaren Bereich. Bei dem beschriebenen Ver- fahren wird grünes Laserlicht von einem Strahlteiler (BS1) in zwei Teilstrahlen aufgeteilt. Einer der beiden Strahlen (P1) wird zu einem optisch nichtlinearen Kristall (NL1) geleitet. Im Kristall entstehen durch einen Prozess, der Parametrische Fluoreszenz genannt wird, Pho- Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2019 Seite 17 von 62
tonenpaare aus jeweils einem roten (S1) und einem infraroten Lichtquant (I1). Diese Quan- ten werden anschießend mit einem Spiegel (DM1) getrennt, sodass nur die infraroten Photo- nen auf das Objekt, das abgebildet werden sollte, gelenkt wird. Nach der Wechselwirkung mit dem Objekt enthalten nicht nur die infraroten, sondern auch die mit ihnen verschränkten roten Photonen die optische Information über das Objekt. Die zweite Hälfte (P2) des grünen Laserstrahls wird nun mit den vom Objekt kommenden infraroten Photonen über einen Spiegel (DM2) zusammengeführt und auf einen zweiten op- tisch nichtlinearen Kristall (NL2) gelenkt. In diesem Kristall entstehen ebenfalls Paare von infraroten (I2) und roten Photonen (S1), die gemeinsam in einem Lichtstrahl weiterfliegen. Die in diesem Strahl enthaltenen infraroten Photonen (I1 und I2) überlagern sich und sind nun prinzipiell ununterscheidbar: es lässt sich nicht mehr feststellen, ob sie vom ersten oder vom zweiten Kristall stammen. Die Ununterscheidbarkeit der infraroten Photonen hat zur Folge, dass sie keine optische Information über das Objekt mehr enthalten. Deshalb brau- chen die nun wertlosen infraroten Photonen nicht mehr detektiert zu werden. und sie wer- den über einen Spiegel (DM3) von den roten Photonen (S2) getrennt. Die — nach der Interfe- renz der infraroten Lichtwellen — nur noch in den roten Photonen enthaltene optische In- formation muss nun sichtbar gemacht werden. Dazu werden die von den beiden Kristallen stammenden roten Lichtwellen (S1 und S2) mit Hilfe eines weiteren Strahlteilers (BS2) zu- sammengeführt und zur Interferenz gebracht (Interferenz-basierte Bildgebung). Die Lichtwellen in den beiden Ausgängen des Strahlteilers ergeben zwei einander ergänzende Bilder, ein helles Bild ergibt sich durch konstruktive Interferenz und ein dunkles Bild durch destruktive Interferenz. 200 Pixels 100 0 100 200 300 400 500 Pixels Abb. 4: Die sich durch konstruktive und destruktive Interferenz ergänzenden Bilder. Ein Nachteil der konventionellen bildgebenden Verfahren ist, dass es für viele interessante Wellenlängenbereiche keine geeigneten Detektoren gibt, während im sichtbaren Bereich viele verlässliche, empfindliche und kostengünstige Detektoren verfügbar sind. Ein großer Vorteil der Quantum-Imaging-Verfahren ist die Entkoppelung von äußeren Einflüssen durch die Detektion der ungestörten Photonen anstelle der tatsächlich wechselwirkenden Photo- nen. Mit der Parametrischen Fluoreszenz können verschränkte Photonen unterschiedlicher Wellenlängen erzeugt werden. Diese Option ermöglicht das Ausnutzen der Vorteile und Ei- genschaften beider Wellenlängenbereiche: optimale Wechselwirkung mit dem Objekt und die Verfügbarkeit von Detektoren aller Art im sichtbaren Bereich. Für mikroskopische An- wendungen ist die Verwendung von geringen Wellenlängen (im UV-Bereich) interessant, um eine höhere Auflösung zu erreichen, während die verschränkten Photonen im sichtbaren Be- Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2019 Seite 18 von 62
reich mit konventionellen Detektoren erfasst und für die Bildrekonstruktion verwendet wer- den. Einige Quantum-Imaging-Verfahren befinden sich weltweit bereits in der experimentel- len Erprobung („proof of concept“). Fortschritte müssen noch erzielt werden im Bereich der parametrisierten Erzeugung von verschränkten Photonen in optisch nichtlinearen Kristallen und der Entwicklung von Detektoren. In der EU werden Forschungsprojekte zu Quantum Ima- ging im Rahmen der Förderung von Quantenforschung unterstützt. In Österreich werden vom Wissenschaftsfond (FWF) regelmäßige Treffen zum Thema Quantenforschung organisiert und entsprechende Projekte gefördert. Am Institut für Medizinische Informatik, Statistik und Dokumentation wird eine Literatur- recherche zu Quantum Imaging im medizinischen Bereich durchgeführt. Ziel ist eine Evalu- ierung der Machbarkeit und Nutzen derartiger Verfahren für die medizinische Diagnostik. 3.2.2 CBmed — DBM4PM S. Schulz, M. Kreuzthaler, J.A. Vera Ramos, L. Hammer, Z. Kasáč, M. Oleynik Im Rahmen des österreichischen K1-Zentrums für Biomarkerforschung war Ende 2018 die erste Förderperiode abgelaufen und damit das vom IMI geleitete Projekt IICCAB (Innovative Nutzung von Information für klinische Versorgung und Biomarkerforschung) beendet. IICCAB hatte exemplarisch gezeigt, wie klinische textuelle Daten semantisch so aufgearbeitet und normiert werden können, dass sie für Anwendungen in Klinik und Forschung besser verfügbar sind. Das Folgeprojekt namens DBM4PM (Digital Biomarkers for Precision Medicine) war be- willigt und in mehreren Iterationen ein Arbeitsplan mit dem Industriepartner SAP ausgear- beitet worden. Für alle überraschend kam dann Ende 2018 der komplette Ausstieg von SAP aus der Kooperation mit CBmed, parallel zu dem Ausstieg aus anderen akademischen Koope- rationsprojekten. Abb. 5: NLP-unterstützte semantische Suche. Das Jahr 2019 begann daher mit der intensiven Suche nach einem neuen Industriepartner. Dieser wurde mit der Firma Roche Diagnostics schließlich gefunden. Schwerpunkt der Zu- sammenarbeit ist die Wissenserschließung aus klinischen textuellen Daten, deren Standardi- sierung, sowie die Aufbereitung der gewonnenen Informationen für klinische Szenarien. Institut für Medizinische Informatik, Statistik und Dokumentation, Tätigkeitsbericht 2019 Seite 19 von 62
Sie können auch lesen

















































